【cs231n】lecture 6 课程笔记
课程6 训练神经网络(part 1)
key:
- epoch指一次使用全部数据的完整训练
- 开始(激活函数、数据预处理、权重初始化、正则化、梯度检查)
- 动态训练(监督学习过程、参数更新、超参数优化)
- 评估(模型评估)
激活函数
1.Sigmoid函数:将输出固定在[0 , 1],曾经很受欢迎,因为可以很好的演绎神经元的饱和放电率
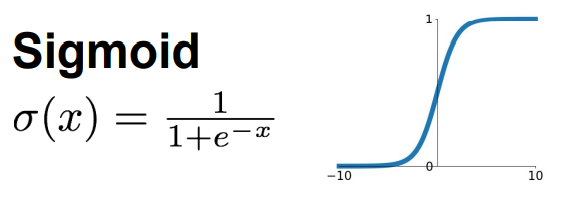
- 会造成饱和神经元,进而造成梯度消失
- 非0中心化,造成梯度总为正或负,让权重W总是向着正或负的方向前进,总是无法达到最优值
- 算指数,计算量大
2.tanh函数:将输出固定在[-1 , 1],零中心化
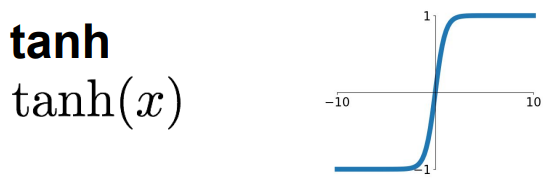
- 有梯度消失现象
3.ReLU函数:正半轴不会饱和,好计算,比前两个收敛快,比第一个更符合生物学(2001年有相关研究)
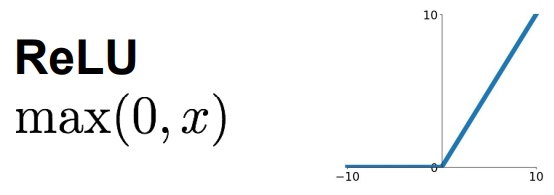
- 非零中心化
- 负半轴梯度消失,且神经元永不激活或不更新(dead ReLU)--》所以人们初始化时会选特别小的正偏置
4.Leaky ReLU函数:不会饱和,计算高效,收敛快,不会die
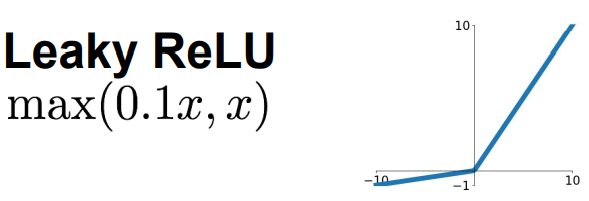
- 演变出PReLU,参数α是可以反向传播和学习的参数,即斜率有学习产生
![image]()
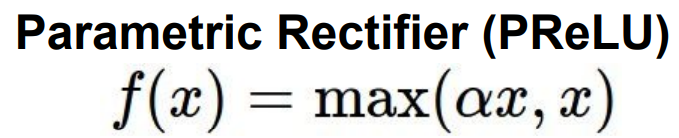
5.ELU函数:指数线性单元,有ReLU的所有有点,输出接近均值为零,负饱和区域相对Leaky ReLU增加了对噪音的鲁棒性
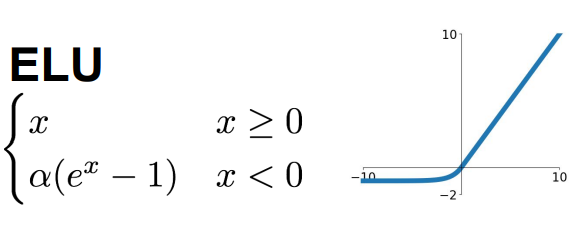
- 计算复杂,有指数
6.Maxout函数:泛化的ReLU和Leaky ReLU函数,都是线性区域(结合两个函数的图像可知),不会饱和,不会有四区
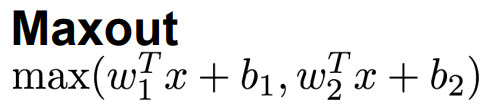
- 参数太多
小结:多用ReLU,注意学习率设置;可以试试其他的,但不要指望tanh有好结果,不要使用sigmoid
数据预处理
1.方法:零中心化(零均值化,就是减去均值);归一化,PCA,白化(whitening)
- 通常只用零中心化,但是减去的均值不同,有的减去全部均值(AlexNet),有的减去每个通道的均值(VGGNet)
权重初始化
1.方法:根据输入来调整采样(缩放比例),通常让输入方差=输出方差

- 使用ReLU会让值减半,除二分布情况会好一些
批量归一化
1.目的:为了得到单位高斯激活(正态分布的激活值);在训练开始前做归一化;使用方差和均值
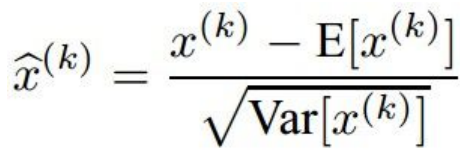
2.步骤:
- 对每一维度计算经验均值和方差
- 归一化(使用那个公式)
3.使用:通常在全连接层or卷积层之后,在激活函数(非线性层)之前进行归一化
4.放缩:使用两个参数进行缩放,恢复恒等映射;参数是可以学习的

5.小结:可以改善整个网络的梯度流;允许有高学习率;不依赖初始化;可以看作正则化,减少对dropout的依赖

- 算均值
- 算方差
- 归一化
- 放缩与平移
监督学习过程
1.过程:
- 数据预处理
- 选择网络结构
- 检查损失函数合理性(先不用正则化,得到一个损失值,看是否合理,再加入正则化,看损失是否会上升);需要注意保证能对少量数据时的训练结果过拟合(完美拟合)
- 用小的正则项开始训练,找到让损失变小的学习率
2.经验:
- 损失不变小:学习率太低
- 损失爆炸:学习率太高
- 损失为nan,也是学习率太高
- 使用交叉验证
超参数优化
1.策略:使用交叉验证策略
2.过程:从粗略到精细的交叉验证;如果损失比初始代价大3倍以上,尽早听下
- 第一步 只使用几个epoch,大致确定较好的参数区间
- 第二步 较长的运行时间,对上一步结果中好的结果进行更精细的寻找
- 重复(如果需要)
3.经验:最好用对数空间进行优化;梯度是乘法计算得来,最好用一些值得乘除来估计学习率
4.验证结果的好坏? 随即搜索 or 网格搜索? 随机更好一点

5.一些问题:
- 好的学习率下,损失变化是平滑向下的
- 训练一段时间后损失才突变下降,可能是初始化没设置好
- 训练与验证结果相差太大:可能是正则化强度不够;如果没有差距?可以尝试增加模型容量
- 注意权重更新值与权重值之比,0.001左右是好的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号