
【cs231n】lecture 3 课程笔记
课程三 损失函数与优化
key: 损失函数 优化 梯度
Loss Function 损失函数
1.概述:对W进行定量的评估,即评估分类结果的正确性损失了多少,可以告诉我们当前分类器有多好or有多坏
2.形式化描述:xi和yi均由分类器通过训练集所得,是同一个图片(训练对象)的对应不同类的分数,xi为图片每个像素点构成的数据集,也是输入;yi为正确分类(是个整数,这里是因为举例有10个类,所以是10个整数,即目标or标签,也是我们所期望得到的结果)的分数;Li即损失函数,L为整个数据集的损失(即所有损失的平均),N是样本数
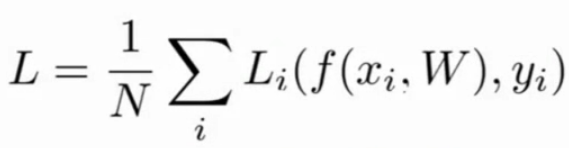
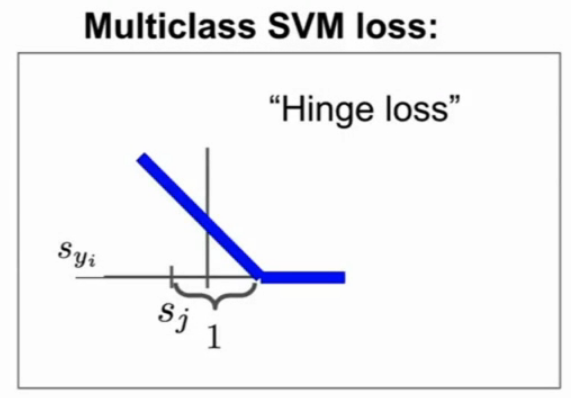
3.多分类SVM损失:这里“1”是一个安全尺度or阈值,当正确的分数超过错误的分数达到多少时,就认为没有损失,即0,否则计算损失,最后求和;根据其图像,称之为合页损失;这里面sj实为sxi,计算过程见视频;基本不用,可用于验证,看初始时损失是否为分类数减一
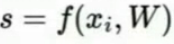
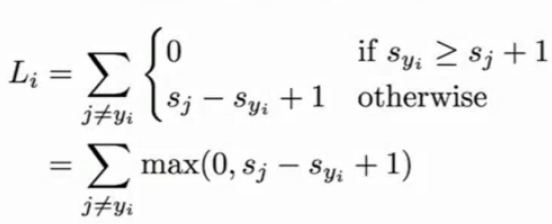
4.正则化:分类器可能会拟合训练集,对每个点都很好的分类,但很可能用了很复杂的策略,需要用正则化来促使分类器使用更简单的策略(W);有很多选择,L1orL2,见视频
5.Softmax Classifier 多项逻辑斯蒂回归(损失函数):
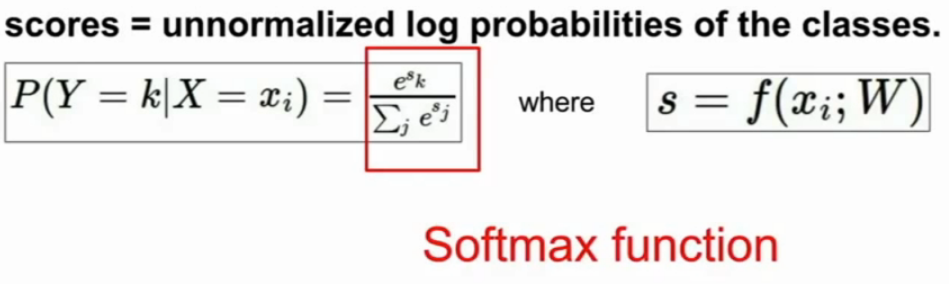
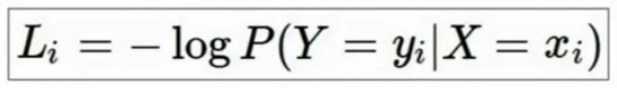
这里,exp即指数化,保证为正,normailze为归一化,使之和为一(就是算一下比例),最后取负对数(要描述损失or坏的程度,使之向下增加)

6.对比:SVM对一个点评估之后不再关心(小于阈值的点);softmax则会让好的愈好,坏的愈坏
7.小结:
Optimization 优化
1.概述:希望找到损失最小的地方,用方向去找;在二维使用斜率表示变化方向,即导数;更高维使用偏导数,进而形成梯度(梯度方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值);在计算机中,多用有限差分法
2.梯度:分数字梯度和分析梯度,多用后者,但可用前者验证
3.梯度下降:梯度指向函数增大点,则用负的表示下降,找到损失最小点
4.SGD stochastic gradient descent 随机梯度下降:数据量很大,计算量太大,用小批量数据估算整体,通常取2的幂次
5.图像特征:一般将图像取一些特征,合起来作为输入放入分类器;但有些特征无法进行线性分类,需要进行特征转换;神经网络出现之前都是先记住特征再训练,现在是有数据驱动,训练得出特征再继续训练
- 颜色直方图
- 方向梯度HoG
- 词袋 bag of words(随机采样,聚合后形成codebook再编码图片)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号