
【cs231n】lecture 2 课程笔记
课程二 KNN 和 Linear Classifier
key: KNN,线性分类器,数据驱动
KNN相关
1.Nearest Neighbor 最近邻居分类器:分训练集和测试集
- 先训练:记住训练集的图片和标签(只是记住,无操作)
- 再测试:为测试集中每一张图片,在训练集中找到最相近的,将其标签赋给测试图
- 数据集:CIFAR10
- 匹配方法:L1 distance(or 曼哈顿距离),对应位置像素之差的绝对值加和,最小即最近
2.K-Nearest Neighbor(KNN):由K个最近邻居投票得出分类结果,即K个邻居中,属于哪一类的邻居多,则被分类点就属于哪一类
- 两个距离:L1距离和L2距离(欧式几何距离,差的平方求和再开根),后者的处理结果试得边界更平滑
- 局限性 :测试时很慢;对于像素的整体移动变化不敏感(甚至无法识别);维度灾难(维度升高后计算量几何级增长)
3.Hyperparamenters 超参数:无法直接获得的or自行设定的,非直观的参数,如上述的K or distance metric(度量距离)
4.好的训练过程:将数据集分为训练集、验证集和测试集;先训练,再验证,最后测试;前两者知道图片与标签,后者只在算法训练即将完成时,开发流程的最后时间中用且只使用一次,且算法不可知标签
- 注意 训练验证与测试必须分隔
- 交叉验证:将数据集的一大部分分为容量相同的几个集合,分别作为验证与训练,且多次互换角色,注意设定好测试集后不可变
Linear Classification 线性分类
1.概览:线性分类器(Linear Classifier)在神经网络中如同一块块积木;模板化的思想,即W
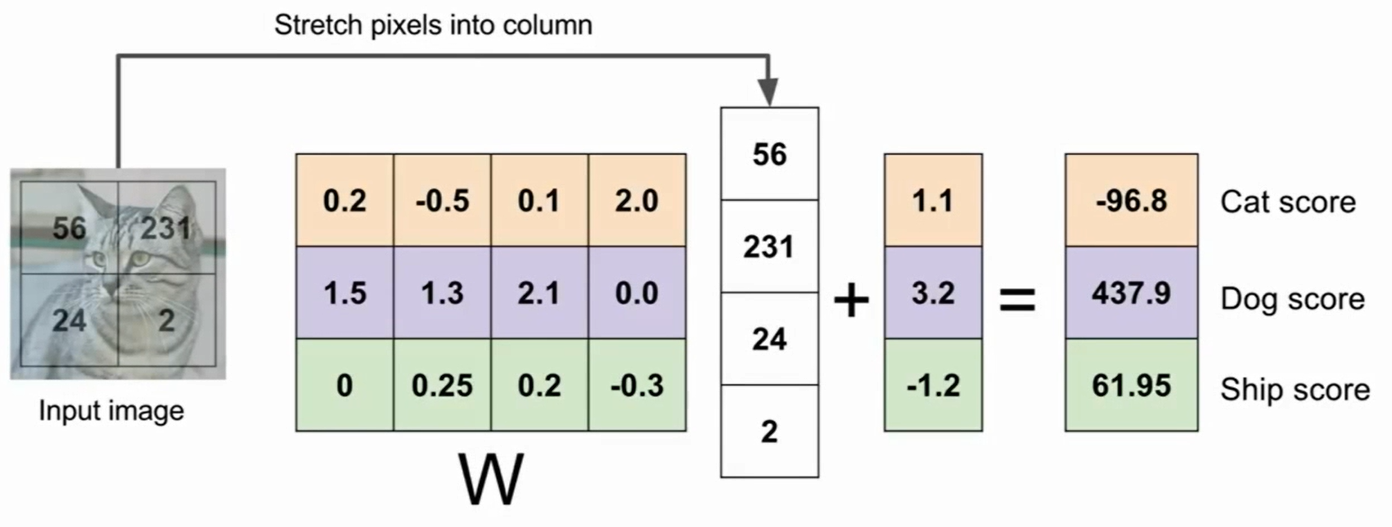
2.线性分类的形式化表示:f(x,W)=Wx + b ,其中x为输入(这里是将图片的像素,由二维转成n * 1的向量);W是分类器(设定好的),是一组针对不同类型图片的权重值,是一个m * n的矩阵,每行对应一类图片(or感兴趣的特征);b为偏置项,用以调整数据的独立缩放比例,偏移量,设置数据独立偏好值,针对某一类的(如数据集中cat多于dog,则cat对应的偏置值会高于狗)
- 如图:四个像素,三个类的模板,得出一个分数,靠近哪一类
![image]()
- 局限性:种类很少,多分类问题,种类独立等方面不适用
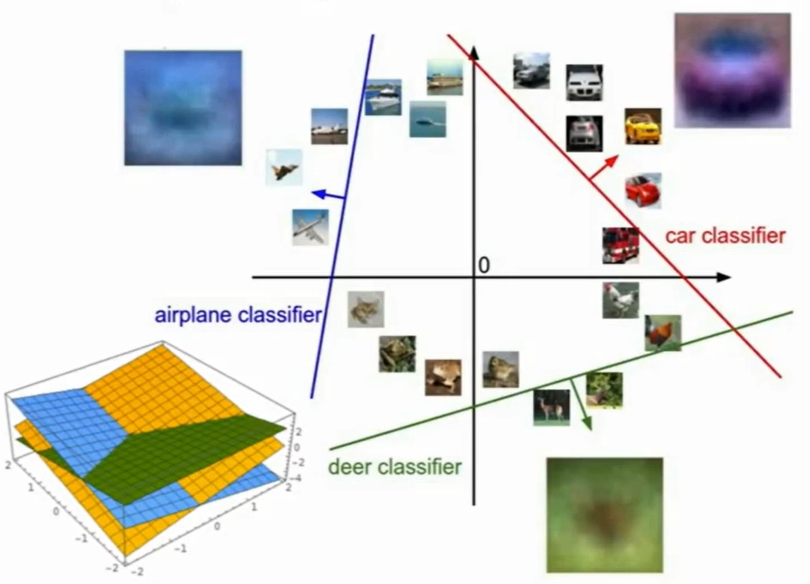
- 具象化表示:一条线为边界,告诉我们什么是什么
![image]()
数据驱动
1.概述:不人为设置参数,由数据提供大量选择(后续补充)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号