操作系统
深入理解CPU#
CPU基础理论#
内核态和用户态#
-
什么是内核
- 是一组应用程序,这类程序能够控制所有硬件及计算机活动
- 内核抽象计算机内部硬件资源,并统一管理对外提供支持,内核操作 = 计算机硬件操作
- 是计算机资源的最大管理者,比如:CPU进程管理、内存管理、文件系统管理、网络接口管理等
-
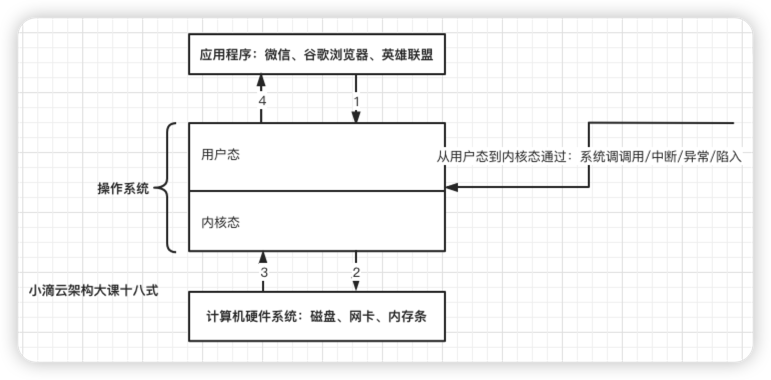
什么是内核态和用户态
- 操作系统把进程的运行空间分为内存分两个区域
- 内核空间(kernel space) ,只有内核程序访问, 也叫进程内核态,可以直接访问内存、硬盘等资源
- 用户空间(user space),专门给应⽤程序使⽤,也叫进程用户态, 只能访问受限的用户资源,
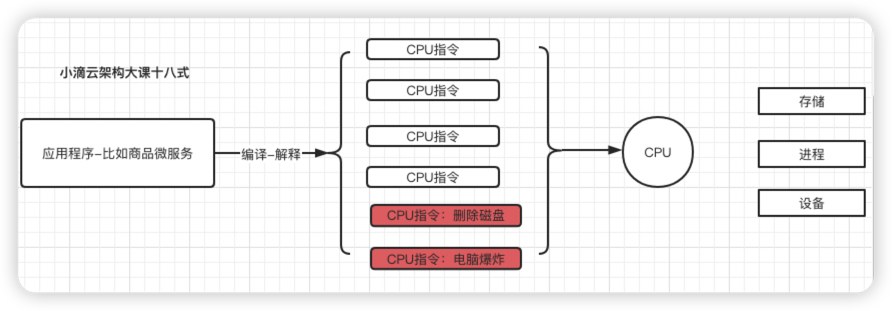
- 其实就是CPU的两种工作状态:内核态和用户态,权限高和权限低
- 程序最终编译、解释成一条一条的 CPU 指令,然后指令都是 CPU 都在执行
-
那为啥要分 内核态和用户态?搞那么复杂,变态?
-
目标:提高操作系统的稳定性及可用性,确保和平稳定
-
在 CPU 的所有指令中,有些指令是非常危险的,如果错用将导致系统崩溃,比如申请-释放内存、杀进程等
-
如果所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加
-
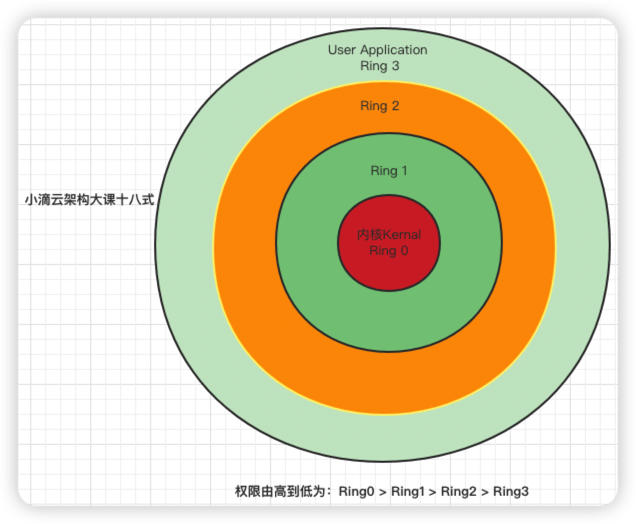
CPU 将指令分为特权指令和非特权指令:
- 常规将CPU 将特权等级分为 4 个级别:Ring0~Ring3
- Linux 系统只使用了【 Ring0 和 Ring3 】
- 进程运行在 Ring3 级别时称为运行在用户态,CPU 可以执行部分指令
- 运行在 Ring0 级别时称为运行在内核态,CPU 可以执行任何指令
- Linux 系统只使用了【 Ring0 和 Ring3 】
- 常规将CPU 将特权等级分为 4 个级别:Ring0~Ring3
-
CPU处于空间什么态,实际上代表的是当前 CPU 正在执行什么级别的指令
-
-
比如
-
在古代,老王是一个国家安全负责人
- 和平年代:发号施令 军队做些简单的 事情,只有部分命令的权限
- 战火年代:发号施令 军队做些全部的 事情,没有约束,全部权限都有
-
-
什么时候会从用户态切换到内核态
- 用户态的程序需要向操作系统申请更高权限的操作时,就通过【系统调用】向内核发起请求
- 系统调过程中,会发生CPU的上下文切换,CPU 寄存器会先保存用户态的状态,然后加载内核态相关内容
- 系统调用结束之后,CPU 寄存器要恢复原来保存的用户态,继续运行进程
- 所以一次系统调用,发生两次 CPU 上下文切换
- 操作系统把进程的运行空间分为内存分两个区域
中断和上下文切换#
-
什么是 操作系统的【中断】
-
类似java开发中的【监听器Listener】【发布-订阅】功能
-
介绍
- CPU在执行【当前程序】时系统出现了【某种信号】使得CPU必须停止当前程序,去执行【另一段程序】来处理的紧急事务
- 处理结束后CPU再返回到原先暂停的程序继续执行,这个过程就称为中断
-
分类
- 内部中断:指令执行时由CPU主动产生
- 外部中断:系统外部设备引发的程序中断
-
例子
- 1个CPU,系统里面有A、B、C任务处理,那CPU什么时候处理哪个任务?进程调度大家能想到
- 假如根据【基于时间片的优先级调度算法】时间到后,就发一个【信号】告诉CPU处理下个任务,信号就是【中断】
- 还有 系统需要接收网络数据、键盘输入、鼠标点击等,系统总不可能一直监听着
- 合理的解决办法:数据包来到之后通知CPU处理器,然后CPU再对任务做处理
-
-
Linux 是一个多任务操作系统
-
支持的任务同时运行的数量远远大于 CPU 的数量
-
CPU运行程序,每个任务运行之前,CPU 需要知道在哪里加载和启动任务
-
这些信息存储-依赖CPU 寄存器和程序计数器
-
寄存器是 CPU 里面空间小但速度极快的内存,程序计数器存储 CPU 正在执行的或下一条要执行指令的位置
-
好比:小滴课堂老王-同时有5个项目正在开发,轮流切换
-
-
什么是cpu的上下文切换
- cpu寄存器和程序计数器是cpu在运行任务前依赖的环境,也叫cpu上下文
- cpu的上下文切换先把前一个任务的cpu上下文保存起来【下次才知道任务从哪里加载+运行】
- 再加载新任务的上下文到寄存器和程序计数器进行运行任务,每次切换 在【保存和恢复】上下文耗时几十纳秒 或 微秒
- 1μs【微秒】 = 1000ns【纳秒】
-
cpu的上下文切换的场景
- 【系统调用切换】
- 即内核态和用户态的切换,一直是同一个进程在运行,不切换进程
- 一次系统调用的过程发生两次cpu上下文切换,切换过去,切换回来
- 【进程上下文切换】
- 每个cpu都维护了一个就绪队列,存放活跃进程,根据情况进行调度
- 进程是由内核来管理和调度的,进程的切换只能发生在【内核态】
- 比如你用【网易云听着歌、玩着英雄联盟】因为现在电脑多CPU多核心配置好,所以感觉不到切换
- 【线程上下文切换】
- 进程是资源拥有的基本单位,线程是调度的基本单位,当进程只有一个线程的时候,可以认为进程就等于线程
- 前后线程同属于一个进程,切换时虚拟内存资源不变
- 上下文切换时需要保存的是线程私有数据,比如栈和寄存器
- 同进程内的线程切换,要比多进程间的切换消耗更少的资源,所以开发中用多线程代替多进程的原因
- 【中断上下文切换】
- 快速响应硬件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件
- 打断其他进程时,就需要保存该进程状态,这样在设备事件结束后,就可以从原来的状态恢复
- 比如老王挪了下鼠标,按了下键盘,CPU就必须中断正在执行的程序,转而去响应这些硬件的事件
- 【系统调用切换】
平均负载与使用率#
平均负载
-
CPU平均负载
-
单位时间内 系统处于【可运行状态】和【不可中断状态】的平均进程数,就是平均活跃进程数,和 CPU 使用率并没有直接关系
- 可运行状态
- 正在使用 CPU 或者正在等待 CPU 的进程
- 用 ps aux命令看到的,处于 R 状态(Running 或 Runnable)的进程
- 不可中断状态
- 正处于内核态关键流程中的进程,且流程不可打断的,
- 比如 等待硬件设备的 I/O 响应,为了保证数据的一致性,进程向磁盘读写数据时,在得到磁盘响应前是不能被其他进程或者中断打断的
- ps aux命令中 D 状态 的进程 Uninterruptible Sleep
- 可运行状态
[root@iZwz90pegu9budx5tk4ruyZ ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 10933 0.0 0.0 0 0 ? S 11月17 0:05 [kworker/u8:2]
root 10976 0.0 0.0 157320 6028 ? Ss 17:44 0:00 sshd: root@pts/0
root 10988 0.0 0.0 115544 2048 pts/0 Ss+ 17:44 0:00 -bash
root 11303 0.2 0.0 157320 6024 ? Ds 17:46 0:00 sshd: root@pts/1
root 11347 0.0 0.0 155472 1872 pts/1 R+ 17:46 0:00 ps aux
root 21456 0.2 2.6 5574940 204168 ? Sl 9月03 300:57 java -jar -Dfile.encoding=UTF-8 agent.jar -s https://server-agent.g
root 27670 0.1 0.1 813512 10552 ? Ssl 11月03 31:11 /usr/local/share/aliyun-assist/2.2.3.349/aliyun-service
root 32475 0.0 0.0 0 0 ? R 11月20 0:03 [kworker/3:0]
| PS中常见STAT状态 | 描述 |
|---|---|
| D | 无法中断的休眠状态(通常 IO 的进程) |
| R | 正在运行,或在队列中的进程 |
| S | 处于休眠状态 |
| T | 停止或被追踪; |
| Z | 僵尸进程 |
| < | 优先级高的进程 |
| n | 优先级较低的进程 |
| L | 有些页被锁进内存 |
| s | 进程的领导者(在它之下有子进程) |
| l | 多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads); |
| + | 位于后台的进程组 |
-
如何查看平均负载 uptime
- load average后的3个数字就分别代表着1分钟,5分钟,15分钟的CPU平均负载
- 查看服务器总的逻辑cpu个数【cat /proc/cpuinfo| grep "processor"| wc -l】
- 如果平均负载为2,那在2个CPU核数时则刚好利用,如果是4个CPU核数,则有50%的空闲
[root@iZwz90pegu9budx5tk4ruyZ ~]# uptime 17:49:46 up 80 days, 15:20, 1 user, load average: 0.00, 0.02, 0.05-
分析
-
1,5,15分钟的数值相差不大,说明负载很平稳
-
如果 1 分钟的值远小于 15 分钟的值,说明系统最近 1 分钟的负载在降低,而过去 15 分钟内却有很大的负载
-
如果 1 分钟的值远大于 15 分钟的值,最近 1 分钟的负载在增加,平均负载接近或超过了 CPU 的个数,意味着系统正在 发生过载的问题,持续的长时间则说明出现了问题需要优化
-
在一个单核CPU 系统平均负载为 1.80,0.90,5.48
- 在过去 1 分钟内,系统有 80% 的超载,而在 15 分钟内,有 448% 的超载,从整体趋势来看,系统的负载在降低
-
- load average后的3个数字就分别代表着1分钟,5分钟,15分钟的CPU平均负载
使用率
-
CPU使用率
-
CPU 非空闲态运行的时间占比,反映 CPU 的繁忙程度,和平均负载不一定完全一致
-
生产系统的 CPU 总使用率不要超过 70~80%
-
比如
- 单核 CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%
- 双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,总体 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%
-
Linux的 top 命令查看 CPU 使用率(核心指标,不常用的忽略)
-
us(user): CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙,值高则cpu使用率高
-
sy(sys):CPU 在内核态运行的时间百分比(不包括中断),内核态 CPU 越低越不忙,值高则cpu使用率高
-
id(idle):CPU 处于空闲态的时间占比,CPU 会执行一个特定的虚拟进程,名为 System Idle Process
- 值高的话,则说明CPU比较空闲,
-
wa(iowait)
- CPU 在等待 I/O 操作完成所消耗的时间,该指标越低越好,高表示可能 I/O 存在瓶颈,用 iostat 命令进一步分析
-
hi(hardirq):CPU 处理硬中断所花费的时间,由外设硬件(如键盘控制器、硬件传感器等)发出的中断信号,快速执行
-
si(softirq): CPU 处理软中断所花费的时间,由软件程序(如网络收发、定时调度等)发出的中断信号,延迟执行
-
st(steal): CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景,指标过高的话,检查下宿主机或其他虚拟机是否异常
top - 18:12:32 up 80 days, 15:43, 3 users, load average: 0.02, 0.07, 0.06 Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie ———————————————————————————————————————————————————————————————————————————————— %Cpu(s): 0.5 us, 0.3 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ———————————————————————————————————————————————————————————————————————————————— KiB Mem : 7733012 total, 192788 free, 1142076 used, 6398148 buff/cache KiB Swap: 0 total, 0 free, 0 used. 6284820 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12303 root 10 -10 140108 14068 6716 S 1.7 0.2 1917:38 AliYunDun 1561 root 20 0 5573112 211120 6888 S 0.7 2.7 287:39.33 java 10518 root 20 0 20.4g 124080 23984 S 0.7 1.6 37:57.16 node /app/.outp 2329 root 20 0 1954676 41920 10204 S 0.3 0.5 217:56.93 dockerd-current 10463 root 20 0 326888 50712 21144 S 0.3 0.7 23:02.56 node -
-
-
CPU使用率和平均负载区别
-
【CPU平均负载】指单位时间内活跃进程数,包括正在使用 CPU 的进程,还包括等待 CPU和 等待 I/O 的进程
- 【可运行状态】和【不可中断状态】的平均进程数
-
【CPU使用率】是单位时间内CPU繁忙情况的统计
-
区别说明
-
CPU 密集型进程,使用大量 CPU运算 会导致平均负载升高,这个场景这两者是一致的;
-
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
- CPU 的效率要远高于磁盘,磁盘读写请求过多就会导致大量 I/O 等待
- 进程在 CPU 上访问磁盘文件,CPU 会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候CPU会切换到其他进程或者空闲
- 任务会转换为 不可中断睡眠状态,当这种读写请求过多会导致不可中断睡眠状态的进程过多,导致CPU负载高,利用率低的情况
-
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
-
-
拓展
- CPU密集型应用也叫计算密集型,表示该任务需要大量的运算,没有阻塞CPU一直全速运行
- 对视频进行高清解码、机器学习和深度学习的模型训练等
- IO密集型应用 程序需要大量I/O操作,大部分的时间是CPU在等IO (硬盘/内存) 的读写操作
- CPU使用率低,但等待IO 也会导致平均负载升高
- 例如:数据库交互,文件上传下载,网络数据传输
- 当线程进行 I/O 操作 CPU 空闲时,启用其他线程继续使用 CPU,提高 CPU 的使用率
- 老王没干太多活,时间光在5个项目中来回启动切换,导致老王【压力大】但是对公司来说【利用率低】没产出
- CPU密集型应用也叫计算密集型,表示该任务需要大量的运算,没有阻塞CPU一直全速运行
-
常用命令#
【全局命令】mpstat#
- 全称 Multiprocessor Statistics,多核 CPU 性能分析程序,实时查看每个 CPU 的性能指标和全部 CPU 的平均性能指标
- 场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 格式
mpstat [-P {|ALL}] [ <时间间隔> ] [ <次数> ]比如mpstat -P ALL 2 3每隔2秒出一个报告数据,共出具3次 - 参数说明
| 参数 | 说明 |
|---|---|
| -P | 指定监控哪个CPU,范围是[ 0 ~ (N-1)], ALL表示监控所有CPU都监控 |
| internal | 两次采样的间隔时间 |
| count | 总采样次数 |
- 显示信息(参数很多,只关注重点,不要想一口吃掉全部)

| 字段 | 说明 |
|---|---|
| CPU | 全部CPU 和 某个CPU,从0开始。 下面每一行项加起来就是100% |
| %usr-- | 用户态所使用 CPU时间的百分比,CPU使用率 |
| %nice | nice值为负进程的CPU时间,即使用 nice 命令对进程进行降级时 CPU 的百分比 |
| %sys-- | 内核态所使用 CPU时间的百分比,CPU使用率 |
| %iowait-- | CPU 在等待 I/O 操作完成所消耗的时间,高表示可能 I/O 存在瓶颈 |
| %irq | 用于硬中断的 CPU 百分比 |
| %soft | 用于软中断的 CPU 百分比 |
| %steal | 虚拟机强制CPU 等待的时间百分比(基本很少关注) |
| %guest | 虚拟机占用CPU时间的百分比(基本很少关注) |
| %gnice | CPU运行niced guest虚拟机所花费的时间百分比(基本很少关注) |
| %idle-- | CPU空闲且系统没有未完成的磁盘I/O请求的时间百分比; CPU使用率低,iowait高,idle低的话可能是等待IO |
【全局命令】vmstat#
-
全称是 Virtual Meomory Statistics(虚拟内存统计)的缩写,是对系统整体的情况进行统计,不细化到某个进程,是宏观命令
-
格式:
vmstat [选项] [时间间隔[次数]](参数很多,记住常用的即可)vmstat n每隔n秒后输出一行信息, 一般会加个 -w 进行加宽显示,比如vmstat -w 1vmstat -SM指定单位显示,默认KB,M表示是MBvmstat -t带上时间戳信息- 更多参数信息
vmstat -h或man vmstat
-
实时查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等
- 和mpstat命令有交集,都是可以看出cpu使用率,在内核态、用户态等
#用户态占比高 stress --cpu 8 --timeout 600s #内核态占比高 stress --io 8 --timeout 600s- Linux里面很多分析工具都是有交集的,但主要用途有差别
-
上下文切换和中断的合理范围:没啥CPU负载的时候也有每秒1万次内,不过也取决cpu的性能,
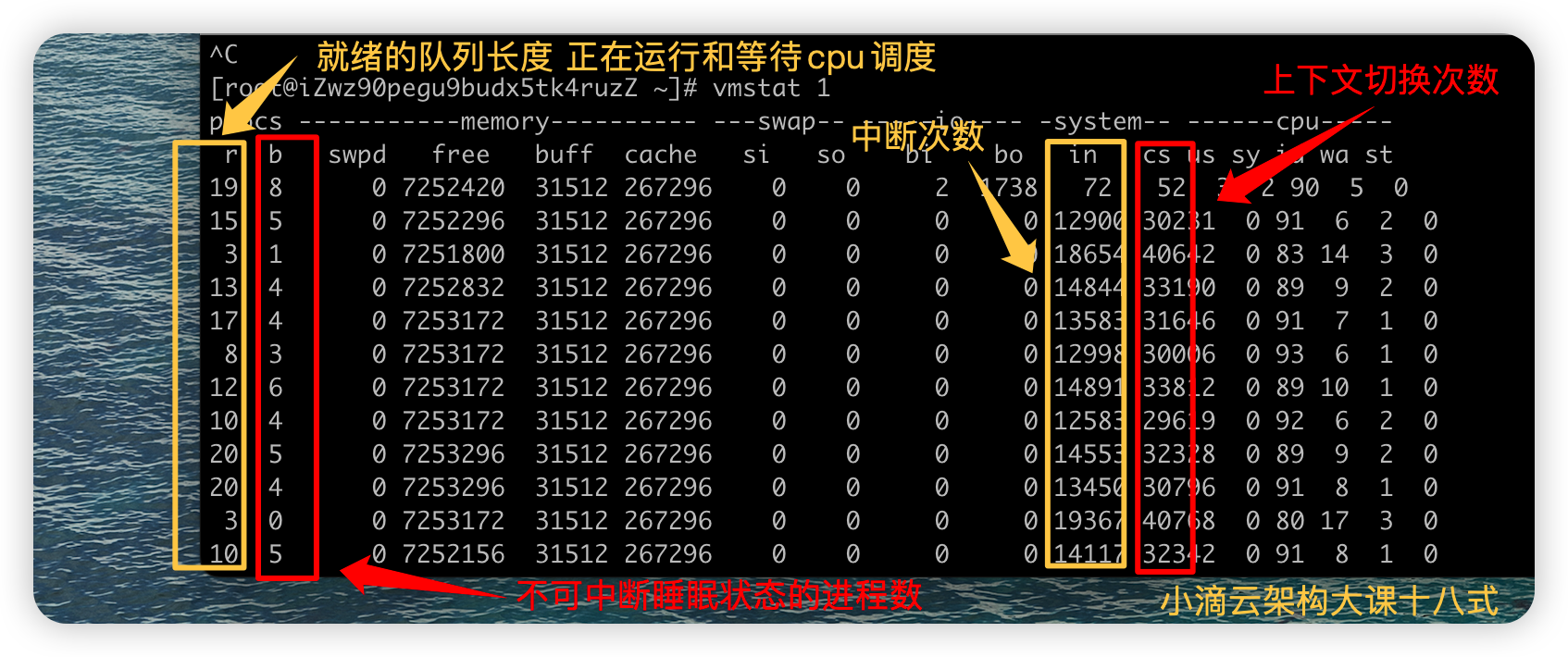
| 字段 | 说明 |
|---|---|
| r | r (runnning or runnable)就绪队列的长度,包括 正在运行和等待CPU的进程数 |
| b | b (Blocked) 处于不可中断睡眠状态的进程数,stress --io 或者 --hdd 即可产生 |
| swpd | 虚拟内存使用情况,单位KB |
| free | 空闲内存空间,单位KB |
| buff | 缓冲的内存空间 ,单位KB |
| cache | 缓存的内存空间,单位KB |
| si | 从磁盘中交换至内存的数据量,单位KB,数值越大代表内存和磁盘之间的转换越频繁,系统的性能越差 |
| so | 从内存中交换到磁盘中的数据量,单位KB,数值越大代表内存和磁盘之间的转换越频繁,系统的性能越差 |
| bi | 从块设备中读入的数据的总量,单位是块,值越大代表系统的 I/O 越繁忙 |
| bo | 写到块设备的数据的总量,单位是块,值越大代表系统的 I/O 越繁忙 |
| in | (interrupt) 每秒中断的次数 |
| cs | (context switch) 每秒上下文切换次数, 会浪费较多的cpu资源 比如我们调用系统函数,数值应该越小越好 |
| us | 在用户态进程所使用 CPU时间的百分比,CPU使用率 |
| sy | 在内核态进程所使用 CPU时间的百分比,CPU使用率 |
| id | 空闲 CPU 的百分比,在Linux 2.5.41之前,这部分包含IO等待时间 |
| wa | 等待 I/O 的 CPU 时间百分比 |
| st | 被虚拟机所盗用的 CPU 百分比(基本很少用) |
【局部命令】pidstat#
- 实时查看进程的 CPU、内存、I/O 、上下文切换等指标
- 格式
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]比如pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次 - 输出排序 pidstat -u | sort -k 8 -r
- sort 排序
- 指定排序用哪一列,下面的例子中是第8列:%CPU
- -r : 倒序
- 参数说明
| 参数 | 说明 |
|---|---|
| -u | 默认的参数,显示各个进程的cpu使用统计,监控cpu,pidstat 和 pidstat -u -p ALL 是等效的 |
| -r | 显示各个进程的内存使用统计,监控内存 |
| -d | 显示各个进程的IO使用情况,监控硬盘 |
| -p | 指定进程号,比如 pidstat -p 5 |
| -w | 显示每个进程的上下文切换情况 |
| -t | 显示选择任务的线程的统计信息外的额外信息 |
- 默认显示信息

| 字段 | 说明 |
|---|---|
| PID | 进程ID |
| %usr | 进程在用户态所使用 CPU时间的百分比,CPU使用率 |
| %system | 进程在内核态所使用 CPU时间的百分比,CPU使用率 |
| %guest | 进程在虚拟机占用cpu的百分比(基本很少关注) |
| %wait | 进程等待cpu 的时间百分比, 进程处于就绪队列中的状态等待CPU调度运行的百分比【新版才有】 |
| %CPU | 进程占用cpu的百分比,和top命令一样 等于 用户态CPU+内核态 CPU,如果要区分cpu哪个态多则用pidstat,不包括 %wait |
| CPU | 处理进程的cpu编号 |
| Command | 当前进程对应的命令 |
-
pidstat -w进程上下文切换情况,显示各活动进程的上下文切换情况统计-
cswch/s 每秒自愿上下文切换(voluntary context switches)的次数
- 进程获取不了所需要的资源导致的上下文切换
- 比如 出现 I/O问题瓶颈、内存等系统资源不足,会发生自愿上下文切换
-
nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数
- 进程由于调度算法,时间片已到等原因,被系统【强制调度】发生上下文切换
- 比如 大量进程再抢夺CPU资源时,会发生非自愿上下文切换,CPU出现了瓶颈

字段 说明 PID 进程ID cswch/s 每秒自愿上下文切换(voluntary context switches)的次数 nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数 Command 当前进程对应的命令
-
-
pidstat -t -p pid显示进程里面的线程的统计信息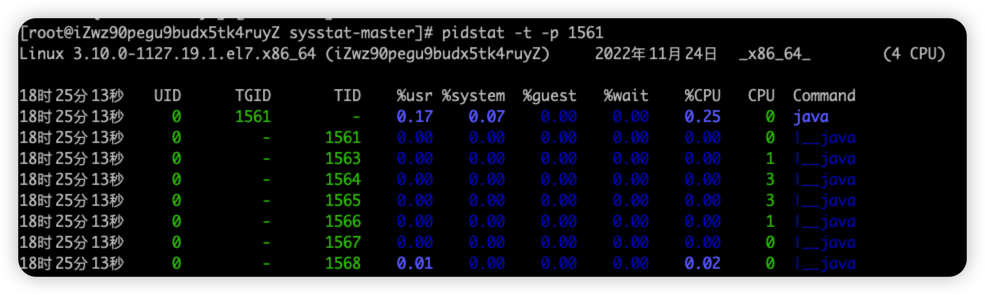
字段 说明 TGID 主线程ID TID 线程id %usr 进程在用户空间占用cpu的百分比 %system 进程在内核空间占用cpu的百分比 %guest 进程在虚拟机占用cpu的百分比. (基本很少用) %CPU 进程占用cpu的百分比 CPU 处理进程的cpu编号 Command 当前进程对应的命令 -
pidstat -wt 1组合命令 ,看具体进程里面的线程上下文切换情况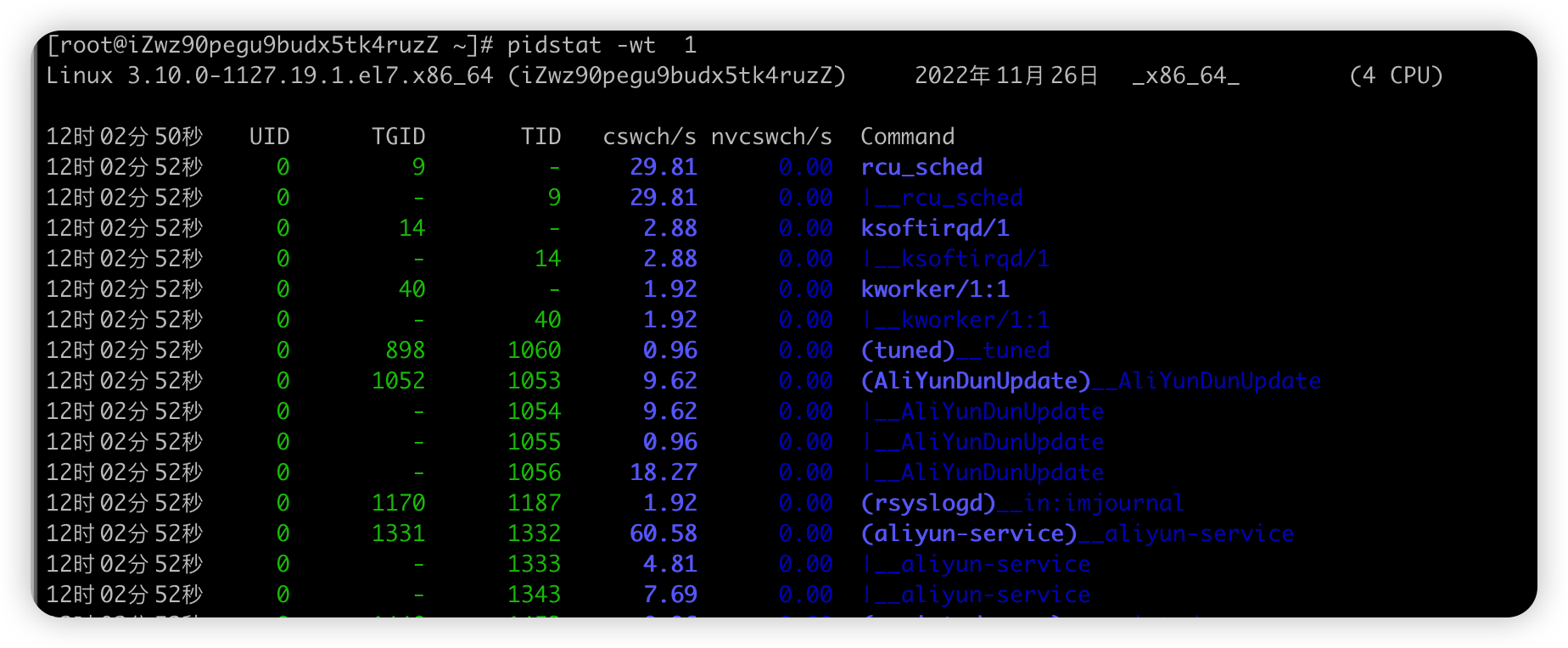
【压测工具】 stress#
- 多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测
- 参数说明
| 参数 | 说明 |
|---|---|
| --timeout | 指定运行多少秒 |
| --cpu N | 产生多个处理sqrt()函数的CPU进程,每个进程高频的计算随机数的平方根,模拟 CPU 计算密集型场景 |
| --io N | 产生多个处理sync()函数的磁盘I/O进程,每个进程高频调用 sync(),刷内存缓冲区到磁盘,模拟 I/O 密集型场景 |
| -vm N | 每个进程高频调用内存分配 malloc() 和 内存释放 free() 函数 |
| --vm-bytes | 指定 malloc() 时申请内存的字节数,默认256MB |
| --hdd N | 产生N个高频执行write和unlink函数的进程 (创建/写入/删除 文件) , 属于磁盘IO进程 |
| --hdd-bytes | 每个 hdd worker进程写的byte数,默认1G |
-
pidstat 查看进程IO使用情况,显示各活动进程的IO使用统计
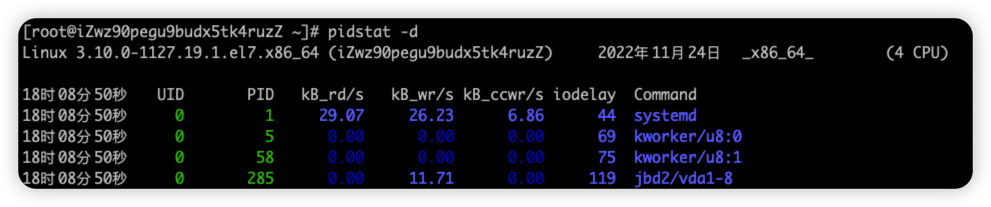
字段 说明 PID 进程ID kB_rd/s 每秒从磁盘读取的KB kB_wr/s 每秒写入磁盘KB kB_ccwr/s 每秒进程被取消向磁盘写的数据量(以kB为单位) iodelay 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间 Command 当前进程对应的命令
【压测工具】 sysbench#
-
是一款开源的多线程性能测试工具,模拟线程上下文切换过多场景等
-
可以执行CPU/内存/线程/IO/数据库等方面的性能测试
-
常用命令
sysbench --threads=32 --time=300 threads run32 个线程持续运行 5 分钟,多线程压测
性能诊断案例#
模拟CPU密集型应用-用户态#
-
需求一 :模拟CPU密集型应用,系统是4核
- 终端一 模拟两个 CPU核的使用率 100%,对2个cpu 进行压力测试 持续600s
stress --cpu 2 --timeout 600 - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 5 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 5
- 终端一 模拟两个 CPU核的使用率 100%,对2个cpu 进行压力测试 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是2,高负荷可以到4
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- CPU的两个核在用户态使用率是100%,两个核数空闲的,总的CPU使用率是50%,% iowait 为0,不存在io瓶颈
- sqrt()函数的 CPU进程是在用户态,所以是%usr升高,而%sys没啥变化
-
局部
-
pidstat: 对进程和任务的使用情况进行,发现stress进程对2块cpu使用率过高,导致CPU平均负载增加
-
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程,包括压测4个核
-
CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高
-
-
模拟CPU密集型应用-内核态#
-
需求二:模拟CPU密集型应用,系统是4核
- 终端一 模拟四个IO进程, 持续600s
stress --io 4 --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 5 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 5
- 终端一 模拟四个IO进程, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
- 全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,内核态CPU使用率%sys 比较高,iowait也有一定数值
- 局部
- pidstat: 对进程和任务的使用情况进行,发现stress进程对cpu使用率比较高,导致CPU平均负载增加
- %wait有一定数值,但是不高,使用
pidstat -d查看 没太多磁盘读写,但是有iodelay
- 全局
模拟IO密集型应用#
-
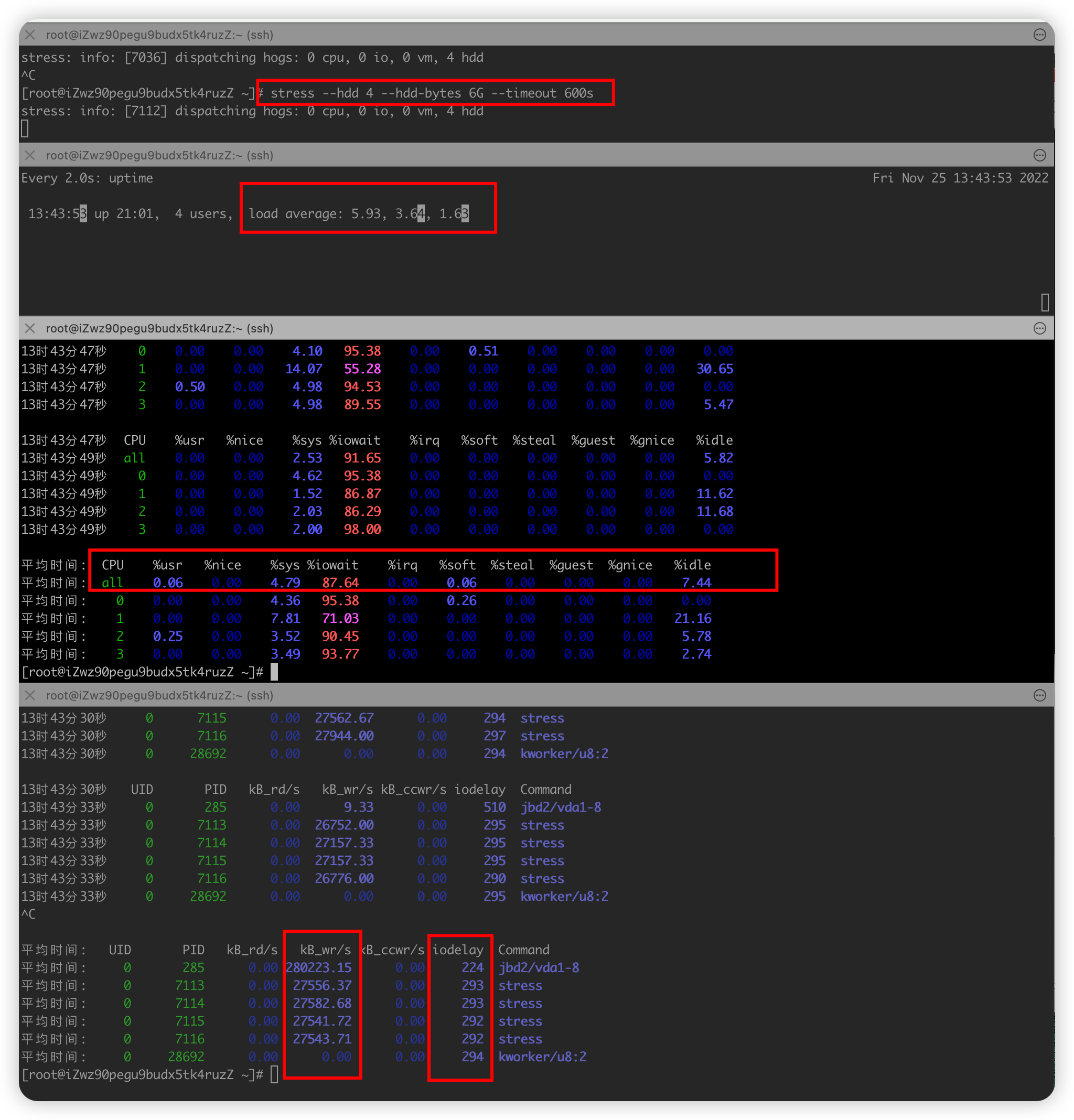
需求三 :模拟IO密集型应用,系统是4核
- 终端一 模拟两个磁盘IO进程, 持续600s
stress --hdd 2 --hdd-bytes 6G --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 2 3每隔2秒出一个报告数据,一共出具3次 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次
- 终端一 模拟两个磁盘IO进程, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,但是CPU使用率没啥变化,iowait大于50%值比较高
- 一直在等待IO处理,说明进程是IO密集型,进程频繁进行IO操作,导致系统平均负载很高,而CPU使用率不高
-
局部
- ps aux 里面stat字段D的状态一般是I/O出现了问题,说明进程在等待I/O,比如 磁盘I/O,网络I/O或者其他
- pidstat : 对进程和任务的使用情况进行,发现stress进程对cpu使用率不高,但CPU平均负载高
- pidstat -u
- pidstat -d
- 举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
- CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高,则可能IO瓶颈
-
模拟多进程调度应用#
-
前言
-
CPU密集型进程,使用大量CPU会导致平均负载高,此时cpu使用率也高
-
I/O密集型进程, 等待I/O导致负载升高,但CPU使用率不一定高
-
大量进程等待CPU调度也会导致平均负载升高,CPU使用率也会比较高
-
-
需求四 :大量等待CPU的进程调度 导致平均负载升高,CPU使用率也会比较高,系统是4核
- 终端一 模拟8个进程,也可以更多, 持续600s
stress --cpu 8 --timeout 600s - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况
mpstat -P ALL 2 3每隔2秒出一个报告数据,一共出具3次 - 终端四 查看运行中的进程和任务,每5秒刷新一次
pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次
- 终端一 模拟8个进程,也可以更多, 持续600s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
- uptime :运行1分钟后,4个核的CPU负载是比较高
- mpstat :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,持续观察, 平均负载升高,每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
- 再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU
-
局部
- pidstat : 对进程和任务的使用情况进行,发现%wait高,说明cpu不够用在等待cpu调度上花费了不少时间
- 结论:8个进程在竞争4个cpu,每个进程等待cpu的时间达到50%(%wait),超出cpu计算能力的进程,导致了负载变高
- pidstat -u CPU情况,默认
- pidstat -d 磁盘IO情况 , 基本很低
- 举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
-
模拟CPU上下文切换应用#
-
需求五 :大量线程进行上下文切换,导致平均负载升高,CPU使用率也会比较高,系统是4核
- 终端一 模拟32个线程进行压测, 持续300s
sysbench --threads=32 --time=300 threads run - 终端二 -d 参数表示高亮显示变化的区域
watch -d uptime - 终端三
vmstat -w 1查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等- 和mpstat命令有交集,都是可以看出cpu使用率,在内核态、用户态等
- 终端四
pidstat -w查看运行中的进程和任务上下文切换情况统计,显示各活动进程的上下文切换情况统计pidstat -t -p pid显示进程里面的线程的统计信息pidstat -wt 1组合命令,查看进程里面具体线程的上下文切换情况
- 终端一 模拟32个线程进行压测, 持续300s
-
宏观思路
- 先看全局,找系统哪个资源问题,是CPU还是IO还是啥瓶颈
- 知道具体后,再看啥哪个进程导致的这个资源有问题
-
详细分析思路
-
全局
-
uptime(全局) :运行1分钟后,4个核的CPU负载是比较高
-
mpstat(全局) :
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用
mpstat -P ALL 2 2,持续观察, 每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
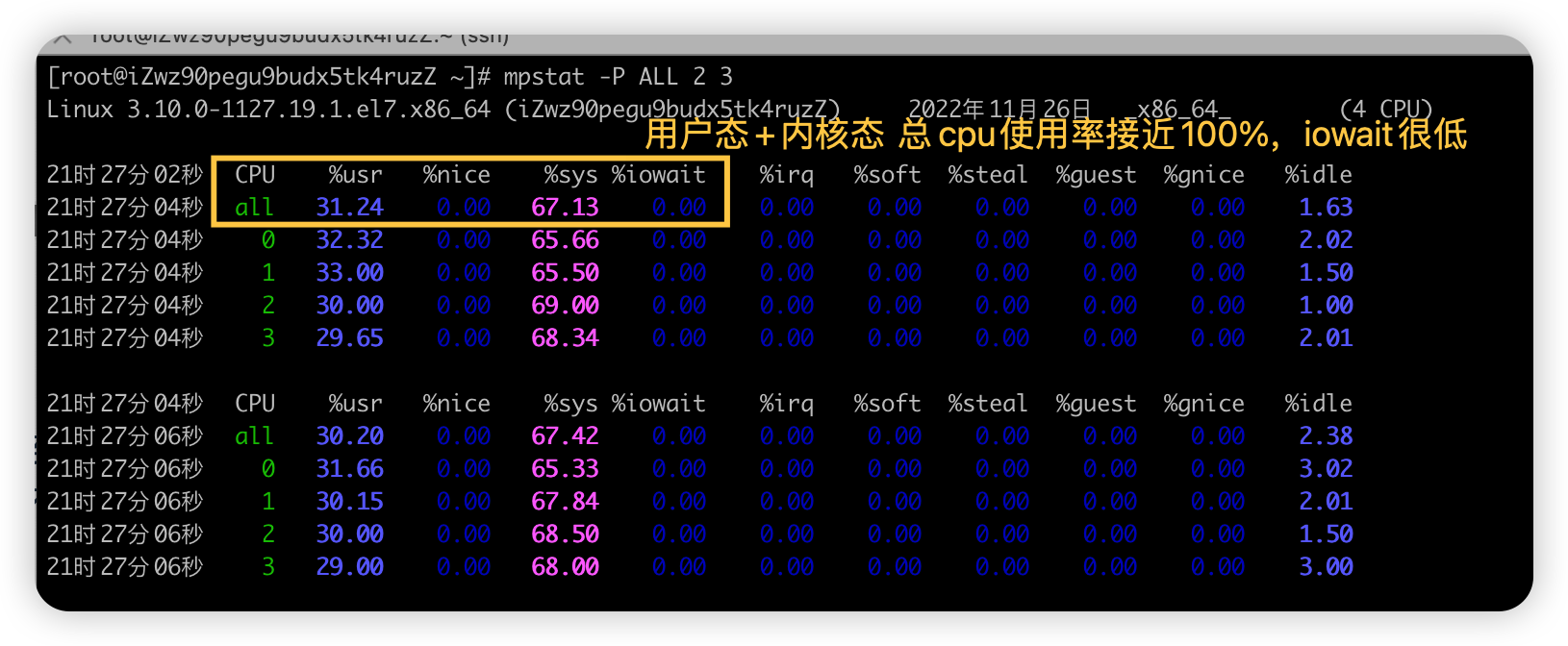
- 再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU
-
vmstat (全局) :系统总的上下文切换情况,就绪队列里面的线程数,不可中断睡眠状态的进程数等
vmstat -wt 1发现:上下文切换次数和中断次数数值比较高
-
-
局部
- pidstat -u 2 2: 对进程和任务的使用情况进行,发现CPU使用率接近100%,前面知道是大量上下文切换导致
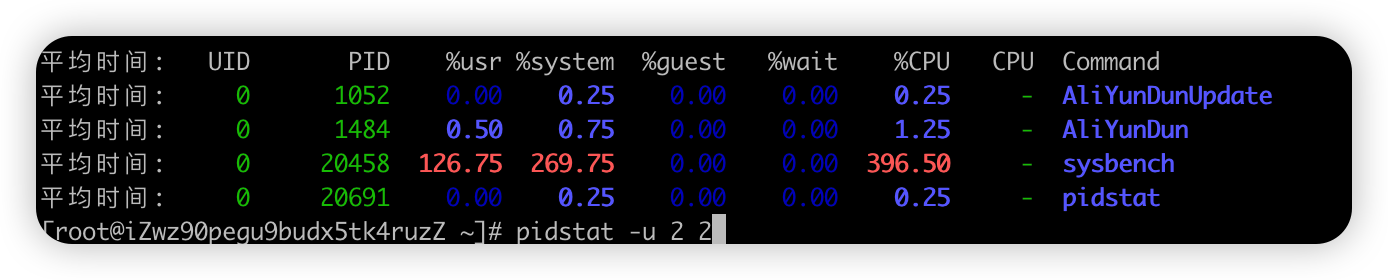
-
pidstat -wt 2 2查看哪个进程大量占据上下文切换,到进程里面的具体线程,大量上下文切换,导致了负载变高-
pidstat -u CPU情况
-
pidstat -d 磁盘IO情况
-
pidstat -t 显示进程里面的线程的统计信息
-
pidstat -w 进程上下文切换情况,查看是哪种上下文切换占比高
- 如果没加 -t则是进程上下文切换,和vmstat的数据不一样,所以推断出是进程内部的大量线程切换导致
- 加 -t 发现 nvcswch 高,大量线程抢夺CPU资源导致
平均时间: UID PID cswch/s nvcswch/s Command 平均时间: 0 9 25.44 0.00 rcu_sched 平均时间: 0 30139 0.00 64.84 stress 平均时间: 0 30140 0.00 65.09 stress 平均时间: 0 30153 0.50 0.00 pidstat- cswch/s 每秒自愿上下文切换(voluntary context switches)的次数
- 进程获取不了所需要的资源导致的上下文切换
- 比如 出现 I/O问题瓶颈、内存等系统资源不足,会发生自愿上下文切换
- nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数
- 进程由于调度算法,时间片已到等原因,被系统【强制调度】发生上下文切换
- 比如 大量进程再抢夺CPU资源时,会发生非自愿上下文切换,CPU出现了瓶颈
-
-
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
-
深入理解内存#
内存基础理论#
ROM-RAM#
-
ROM
- 全称 Read Only Memory 只读存储器或者固化存储器
- 在系统停止供电的时候仍然可以保持数据,但是电脑硬盘不是ROM 内存,硬盘是外存
- 只能读取,用来存储和保存永久数据,不能随意更新,在任何时候都可以读取,即使是断电,ROM也能够保留数据
- 常见的计算机的ROM内的存储是BIOS程序、机器码和出厂信息等
- Basic Input Output System 是在通电引导阶段运行硬件初始化,为操作系统提供运行时服务的固件,是开机时运行的第一个程序
-
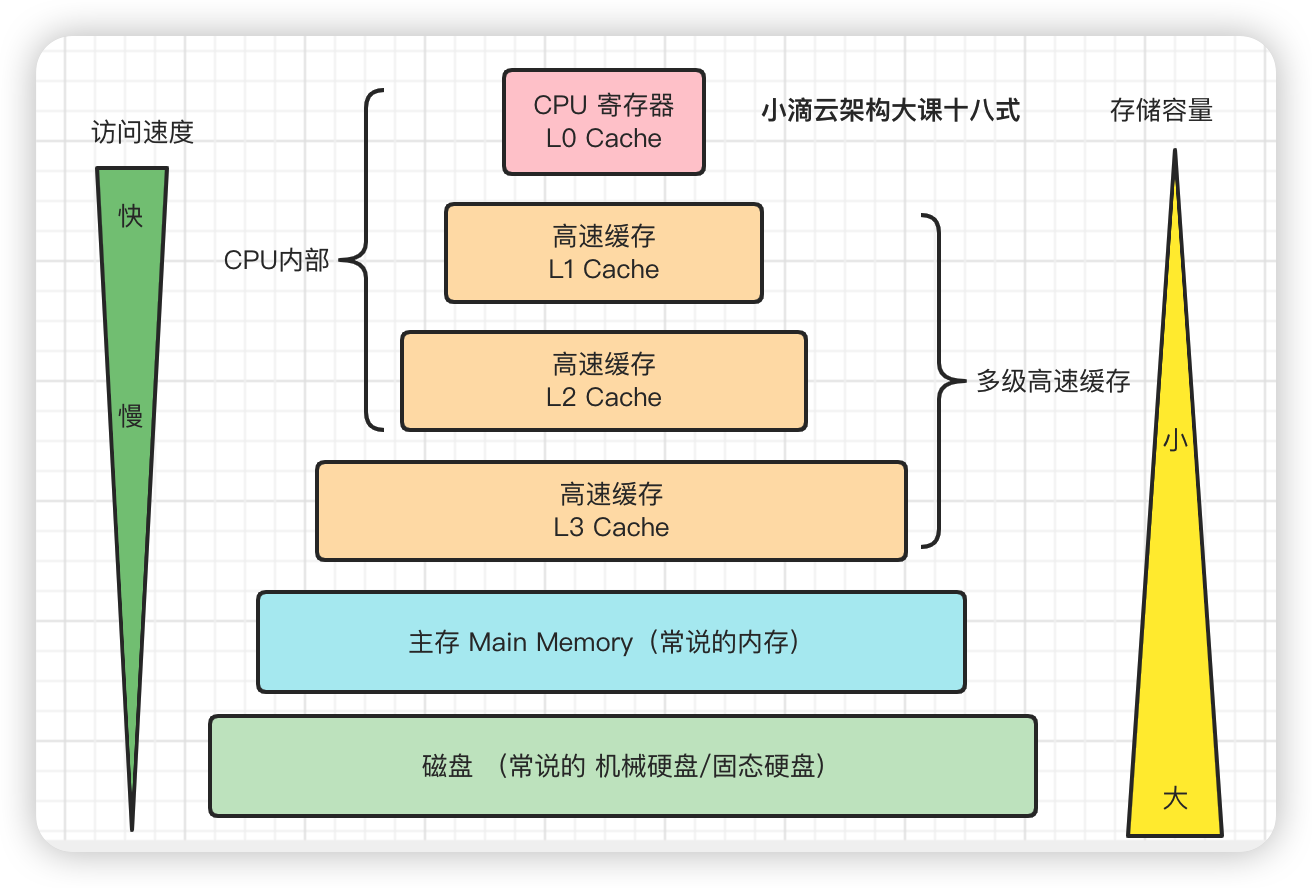
RAM 全称 Random Access Memory 随机存取存储器
- 掉电之后就丢失数据,常见的RAM就是计算机的内存,RAM有两大类
- 静态RAM(Static RAM/SRAM)
- 速度非常快,是目前读写最快的存储设备但是非常昂贵
- 只在要求很苛刻的地方使用,比如CPU的一级缓存,二级缓存, 三级缓存 是SRAM
- 动态RAM(Dynamic RAM/DRAM)
- 保留数据的时间很短,速度也比SRAM慢,不过比任何的ROM都要快,
- 价格上来说DRAM相比SRAM要便宜很多,比如常见的计算机内存就是DRAM
-
不同类型存取速度和存储容量
虚拟内存#
-
前言
-
计算机的物理内存上每字节都有一个唯一的物理地址
-
进程直接使用物理内存空间有很多问题
- 进程malloc分配一块很大的连续的内存空间,可能会出现有足够多的空闲物理内存,却没有足够大的连续空闲内存
- 四处分散的内存块就是内存碎片,这样就被浪费掉了
- 进程读写内存的安全性问题,物理内存本身是不限制访问的,任何地址都可以读写
- 进程执行错误指令可以修改其它进程的数据,包括只读的数据,这样不安全
-
-
什么是虚拟内存
- Linux 给每个创建的进程分配一个【独立且连续】的虚拟地址空间就是虚拟内存,超级大的字节数组(32位和64位系统不一样)
-
计算机处理器的地址有32位和64位两种,对应的虚拟地址空间大小分别为232字节和264字节
- 它使得应用程序认为拥有【一个连续完整的地址空间】的可用内存,只是【虚拟的】
-
实际上进程用了多少空间,操作系统就会给他划出多少空间
-
所有的进程共享一块物理内存,每个进程只把目前需要的虚拟内存映射到物理内存上
-
增加了虚拟内存后怎么操作? 进程如果要访问内存时就需要通过虚拟内存映射实现
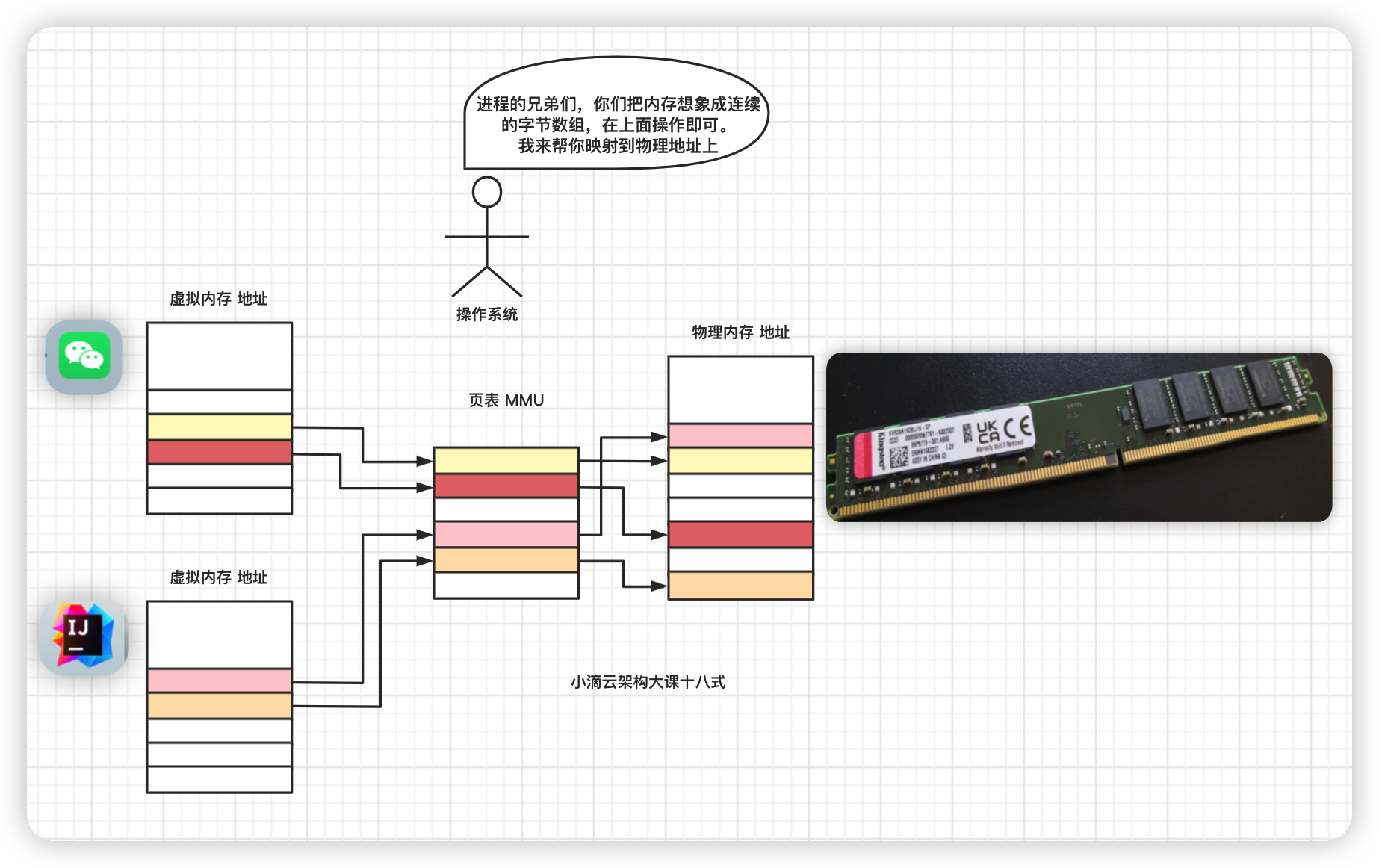
-
-
什么是内存映射
-
不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存
-
分配后的物理内存,是通过内存映射来管理的,即将不同进程的虚拟地址和不同内存的物理地址映射起来
-
内存映射,其实就是将虚拟内存地址映射到物理内存地址
-
总结:
-
CPU 要访问虚拟内存地址,要经过地址翻译成物理地址才能访问,通过内存管理单元(memory management unit)MMU
-
MMU是一种硬件电路,速度很快,主要工作是进行内存管理(CPU并不直接和物理内存打交道)
-
MMU来翻译成对应的内存物理地址,利用存放在主存中的页表来动态翻译虚拟地址,该表的内容由操作系统管理
-
-
-
什么是页表
- 一种特殊的数据结构,进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,靠用页表来记录
- 页表每个表项就是一个记录,好比数据库的一个表,有多个字段存储不同的信息

-
当进程访问某个虚拟地址,就会先去看页表,如果发现对应的数据不在物理内存中,则发生缺页异常
-
注意
-
使用malloc申请内存时是延时分配,并未真实分配物理内存,到真正开始使用malloc申请的物理内存时
-
发现没有记录才会触发申请,出现Page Fault缺页异常 (进程从用户态切换到内核态),这就是内存的惰性分配机制
-
触发Page Fault的原因有多种 (对应的缺页异常的处理也不一样)
- 没有建立Virtual Address 虚拟地址->Physical Address 物理地址的映射
- 访问的地址在物理内存中不存在,要从磁盘/swap分区读入才能使用,因为磁盘太慢,所以性能影响比较大
- 访问的地址内存非法,可能会导致进程宕掉
-
-
总结
- 一个运行中的进程,不是所有的虚拟地址在物理内存中都有对应的页
- 当进程还没有开始运行的时候,程序的代码段和数据段实际上都放在磁盘中
- 当进程开始运行的时候,进程需要从内存中读出这段程序的代码
- 进程去寻找页表,页表中的地址不在物理内存上,因此就会发生缺页异常
页表和页表项#
-
常见基础知识回顾
1字节(Byte)=8位(bit) 1KB( Kilobyte,千字节)=1024Byte 1MB( Megabyte,兆字节)=1024KB-
这边举例
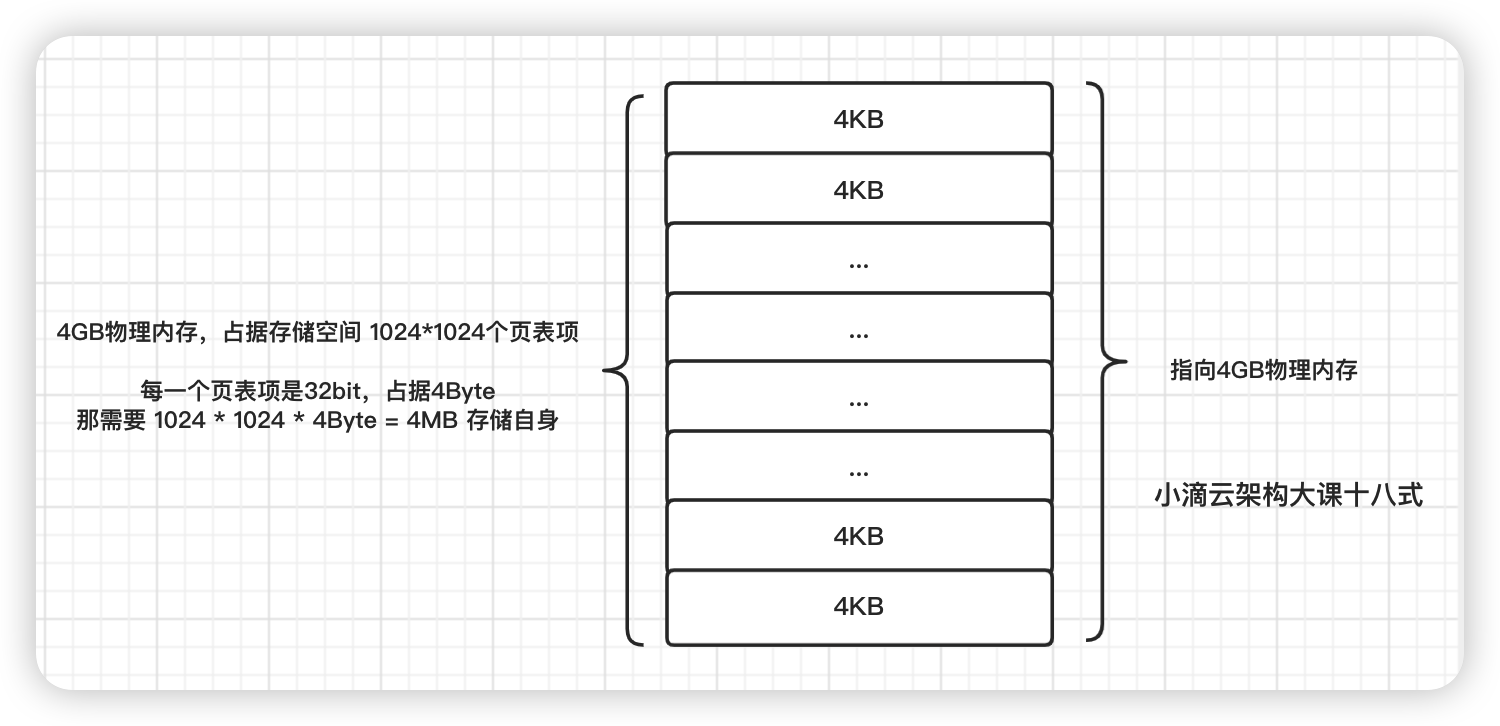
x86架构的例子,在x86系统中,物理地址中每4KB作为一页,以页为单位映射 -
应用程序使用虚拟内存,通过MMU 找映射表,把连续的虚拟内存空间,映射到分散的物理内存空间
-
映射表中的每一个页表项,指向4KB物理地址, 4GB空间可以分割为1024 * 1024个页表项
-
32位处理器的操作系统创建的进程分配4GB虚拟内存, 每页指向4KB物理地址,共有4GB/4KB个页表项 = 1024 * 1024 个页表项
- 映射表自身是需保存在物理内存中
- 换算:页表中每一个表项大小是32bit,占据4Byte , 那需要 1024 * 1024 * 4Byte = 4MB 来存储映射表
- 有些程序用不了那么多,但系统也分配了4MB来存储这个映射表,造成浪费
-
解决方案(称为多级页表)
- 大表拆小表,单一大映射表拆分成 1024 个体积更小的映射表
- 共使用 1024 个映射表,每一个映射表中 只有 1024 个表项
- 每一个小的映射表也称作 页表,所以一共有
1024个页表 - 一个页表中共有
1024个页表项,每一个页表项占用4个字节,一个页表占用4KB的物理存储内存空间 (4Byte * 1024条)
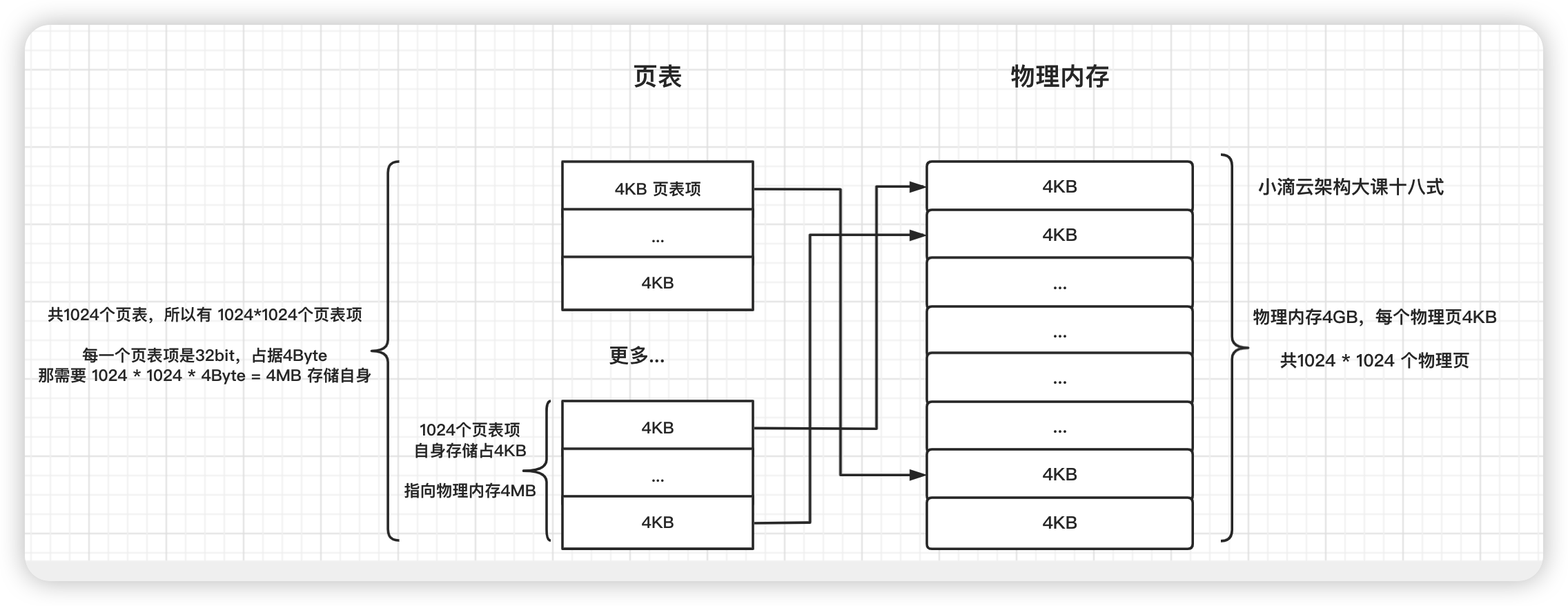
-
疑惑:一个页表占用4KB,那1024个页表一共占用 4MB的物理内存空间,不也造成浪费了?
-
总数是没错,但是程序 现在不一定要一次要1024个页表,可以根据情况选择 部分小页表使用
-
比如
- 王者荣耀程序的一共就需要
10 MB的空间,那使用3个页表就足够,加上页目录,一共需要16 KB的空间 - 计算方式
- 一个页表 有1024 个页表项,每一个页表项指向一个 4KB 的物理页,指向 4MB 的物理内存空间(1024 * 4 KB)
- 10MB 的程序 ,向上取整,只需要3个页表即可
- 王者荣耀程序的一共就需要
-
总结
-
一个页表项 占用
4Byte的物理存储内存空间 -
一个页表项 指向存储
4KB的物理内存空间 -
一个页表 占用
4KB的物理存储内存空间 -
一个页表 指向存储
4MB的物理内存空间
-
-
-
页目录表
- 一个页表中的一个表项来指向了每一个物理页
- 4GB内存的共有1024个页表,而页目录表就是管理指向这 1024个页表
- 页目录的字段属性和页表是一样的,所以页目录中共有
1024个表项,指向1024个页表的物理地址 - 总结
- 在页目录表中,每一个表项指向一个页表的开始的物理地址
- 常规每个应用程序都有自己的页目录和页表
- 从 页目录表 到 页表,这样多层级控制的方式 ,称为 多级页表
- 映射表自身是需保存在物理内存中
-
交换分区#
-
操作系统内存不够怎么办?
-
回收内存: 把不常用的内存 算法淘汰,比如LRU回收内存
-
内存置换:把不常用的内存通过交换分区直接写到磁盘中,置换一部分空间使用
-
杀死进程:内存紧张时系统还会通过 OOM(Out of Memory),会选择杀掉一些进程释放掉一些内存
-
-
什么是交换分区Swap
-
进程占用内存很大,会导致内存消耗完,为解决该问题操作系统中运用Swap技术,拿部分硬盘空间来充当内存使用
-
操作系统欺骗进程,内存很多你放心大胆去用 ;好比CPU的超线程,欺骗 操作系统 1个核变成两个核
-
一句话:就是Linux下的虚拟内存分区,作用是在物理内存使用完之后,将磁盘空间(也就是SWAP分区)虚拟成内存来使用
-
换页机制
-
操作系统把物理内存中放不下的数据临时放到磁盘上,等到需要的时候再放回到物理内存中,提供超过物理内存容量的空间
-
访问数据被swap换出
- 物理内存是有限资源,运行多进程时并不是每个进程都活跃,系统会启动 内存页面置换 (操作系统的页面置换算法)
- 将长时间未使用的物理内存页帧放到swap分区,让出资源给其他进程
- 当存在于swap分区的页面被访问时就会触发Page Fault 缺页异常,从而再置换回物理内存
-
-
预取机制
- 换页过程涉及的磁盘IO操作,读取耗时比较多,因此操作系统会引入预取机制进行优化
- 当发生换入操作时,预测还有哪些页会被访问,提前将它们一并换入物理页内存,减少发生缺页异常的次数
-
swap配置参数:swappiness
-
参数可以从0-100进行设置,默认值swappiness=60,表示内存使用率超过100-60=40%时开始使用交换分区
-
swappiness=0的时候表示最大限度使用物理内存,尽量不用 swap空间,有些云服务器厂商直接设置为0
- 注意:把swappiness设置成0不会禁止swap, 是最大限度不用, 不是一定不用,想要禁止,就不要开启swap
-
swappiness=100的时候表示积极的使用swap分区,把内存上的数据及时的搬运到swap空间
-
命令
- 查看
cat /proc/sys/vm/swappiness - 临时修改
echo 10 > /proc/sys/vm/swappiness - 永久调整
vim /etc/sysctl.conf加上.vm.swappiness=10
- 查看
-
配置建议
-
根据不同的应用,有不同的配置,比如有些性能要求高中间件,由于硬盘io较慢,会要求禁用 swap,
-
分配太多的Swap空间会浪费磁盘空间,而Swap空间太少,则系统内存不够就会发生错误
-
redhat官方建议:
物理内存小于等于2GB的swap应设置为物理内存的2倍
物理内存大于2GB小于等于8G时swap应设置为等同与物理内存的大小
物理内存大于8GB时swap应设置为大于等于4GB但不超过8GB
-
个人建议:生产环境 最好是设置swappiness=10,不要设置swappiness=0
-
-
-
-
应用场景
- kubernetes集群一般要关闭swap
- Java 的应用一般也是要关闭swap,像Rocketmq、ElasticSearch 等
- Java应用会用到堆,开启了swap就会部分存储到磁盘上
- 程序在 GC 的时候会遍历所有堆的内存,如果这部分内存是被 swap 到磁盘上,GC遍历的时候就会有磁盘IO影响性能
-
常见的内存页面置换算法
- 进程访问的页面不在内存中而需将其调入,但内存已无空闲空间时,就需要从内存中调出一页程序或数据,送入磁盘的对换区
- 选择调出页面的算法就称为页面置换算法,决定应该换出哪个页面
- 页面的换入换出需要有磁盘的I/O,会有较大的开销,好的页面置换算法追求更少的缺页率
- 分类
- 最佳置换算法(OPT)
- 选择的被淘汰页面是以后永不使用的页面,或是在最长时间内不再被访问的页面,以便保证获得最低的缺页率
- 性能最好,但没法预知哪个页未来不被访问,无法实现
- 先进先出页面置换算法(FIFO)
- 优先淘汰最早进入内存的页面,即再内存中驻留时间最久的页面。
- 实现简单,但算法性能差
- 最近最久未使用置换算法(LRU)
- 选择最近最长时间未访问过的页面进行淘汰,它认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问
- 算法性能好,但是开销大,需要硬件支持
- 时钟置换算法(CLOCK)
- 性能和开销较均衡的算法,比LRU差一些,与FIFO差不多
- 最佳置换算法(OPT)
进程评分机制#
什么是oom_score
在Linux系统中,当内存不足(Out of Memory,简称 OOM)时,内核就需要决定杀掉哪个进程来释放内存,以保持系统的正常运行。这个决定过程与每个进程相关联的一个称为“oom_score”的值有关。
"oom_score" 是一个反映进程被OOM Killer选中进行杀死的倾向或可能性的评分值。这个值越大,表示该进程越有可能在内存不足时被选为杀掉的目标。"oom_score" 不是固定不变的,而是会根据进程的状态(如其使用的内存量等)动态变化。
"oom_score"的值在 /proc/[进程ID]/oom_score 文件中进行存储维护,你可以通过查看这个文件来获取指定进程的当前"oom_score"值。
总的来说,"oom_score"是Linux内核在面临内存不足时,用于评估和选择需要结束的进程的一个衡量标准。
什么是oom_score_adj
在 Linux 系统中,“oom_score_adj”是一个特殊的参数,系统管理员或者程序可以通过修改这个参数来影响进程的 "oom_score",即调整系统在内存不足时杀掉该进程的倾向性。
"oom_score_adj" 的值的范围是 -1000 到 1000,这个值将直接被加到 "oom_score" 对应的值上。
- 如果 "oom_score_adj" 设置为 -1000,那么该进程会被系统认为是不可杀的,即使在内存极度紧缺的情况下,OOM Killer 也不会选中这个进程。
- 如果 "oom_score_adj" 设置为 1000,那么该进程在内存紧缺时,会首先被系统考虑进行杀掉。
可以通过修改 "/proc/[进程ID]/oom_score_adj" 文件来调整指定进程的 "oom_score_adj" 值。
总的来说,通过调整 "oom_score_adj",我们可以微调 Linux 内存管理的行为。例如,保护一些重要的进程(将它们的oom_score_adj设置为-1000),或者在内存紧张时优先结束一些不那么重要的进程(将它们的oom_score_adj设置为相对较高的值)。
- 对某一个task进程进行打分(oom_score),实际得分需要考虑两方面,然后把
oom_score最大的进程先杀死- 一部分是系统打分,主要是根据该task的内存使用情况,进程的内存开销是变化的,所以该值也会动态变化
- 另一部分是用户打分,也就是oom_score_adj,默认是0,取值范围是-1000~1000
- 0表示用户不调整oom_score,负值表示要在实际打分值上减去一个折扣
- 正值表示要惩罚对应的进程,也就是增加该进程的oom_score
- 如果用户将该进程的 oom_score_adj 设定成
-1000,表示禁止OOM killer 杀死该进程,特别重要的服务可以配置
Buffer-Cache#
-
什么是Buffer/Cache
-
在计算机技术中高频出现的名词,在不通语境下会有不同的意义
-
操作系统也是一个程序,为了提高性能也加了缓存,比较通用的缓存,也可以不用
-
在Linux的内存管理中, buffer和cache是为了提高IO性能 由OS管理,是两个不同的概念
-
Buffer指Linux内存的 Buffer cache(缓冲区)
- 用内存和硬盘的缓冲,是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行
- 存放要输出到disk磁盘(块存储)的数据,对磁盘块的读写,用来缓存磁盘的数据,不会特别大 常规就是几十MB
- 操作系统内核把 分散的写集中起来, 把多次小的写合并成单次大的写,减少磁盘碎片和硬盘的反复寻道提高的写入速度
buffers: Memory used by kernel buffers (Buffers in /proc/meminfo) 内核缓冲区的内存,是/proc/meminfo 中的 Buffers 值 -
Cache指Linux内存中的 Page cache(缓存区)
- 用于 CPU 和内存之间的缓冲, 用来缓存从磁盘文件读取的数据,下次访问这些文件数据时,直接从内存中获取,不用再次访问缓慢的磁盘
- 一般来说,cache会比buffers的数量大很多,频繁访问到的文件都被cache,那磁盘的读IO会非常小
- Cache不是缓存文件的,是缓存块的 (块是I/O读写最小的单元),一般会用在I/O请求上
- 在Linux系统中程序频繁读写文件后,可用物理内存会很少,Cache Memory在需要使用内存的时候会自动释放,不必担心没有内存可用
- 如果多个进程要访问某个文件 把此文件读入Cache中,下次获取CPU控制权读取文件直接从Cache读取,提高性能
cache: Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo) 页缓存和 Slab 用到的内存,是 /proc/meminfo 中的 Cached 与 Slab之和
-
-
总结
- Buffer 是对磁盘数据的缓存, Cache 是文件数据的缓存,两者既会用在读请求,也会用在写请求,只不过是多和少区别
- 缓冲(buffer)是用来加速数据"写入"硬盘,保存即将要写入到磁盘上的数据
- 缓存(cache)是保存从磁盘上读出的数据,用来加速数据从硬盘中"读取"
Cache和Buffer的是为了解决 高速设备和低速设备之间的问题而设计的中间层,通过“流量整形”提高系统性能Cache将低速设备中常被访问的数据缓存起来- 当高速设备需要再次访问这些数据时,命中
Cache中的数据,以减少对低速设备的访问
- 当高速设备需要再次访问这些数据时,命中
Buffer用于缓冲高速设备把数据写到低速设备时带来的压力- 当数据量比较大时,
Buffer能将数据分割成合适的大小,分批回写到磁盘 - 当数据量比较小的时候,
Buffer能将分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道
- 当数据量比较大时,
-
-
手工释放
- Linux系统频繁存取文件会导致物理内存被用光, buff/cache缓存使用后并不会马上释放 ,就会造成 buffers和cached占用过高
- buffers/cache占用的较多,但是不要紧,这部分内存是当空闲来用的. available = free + buff/ cache
- 那为什么操作系统不会主动回收呢? 是因为drop_caches的默认参数设置的就是不释放的
#用命令来释放缓存, 建议先执行sync命令, 将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、延迟的块 I/O 等 # 0:不释放(系统默认值) sync #1:释放页缓存 echo 1 > /proc/sys/vm/drop_caches #2:释放dentries和inodes,即清除回收slab分配器中的对象 echo 2 > /proc/sys/vm/drop_caches # 3:释放所有缓存 echo 3 > /proc/sys/vm/drop_caches
常用命令#
【全局命令】free#
-
free命令(宏观命令 mpstat 、 vmstat )
-
显示Linux系统中空闲的、已用的物理内存、swap内存 和 被内核使用的buffer
-
格式
free [参数]参数 说明 -b Byte为单位显示内存使用情况 -k KB为单位显示内存使用情况 -m MB为单位显示内存使用情况 -g GB为单位显示内存使用情况 -h 自动化更好的可读性方式显示 -w 将buffer和cache拆分单独的两个列显示 -s <间隔秒数> 持续观察内存使用状况, 比如每隔两秒显示一次 free -s 2-t 显示内存总和列 比如 free -th
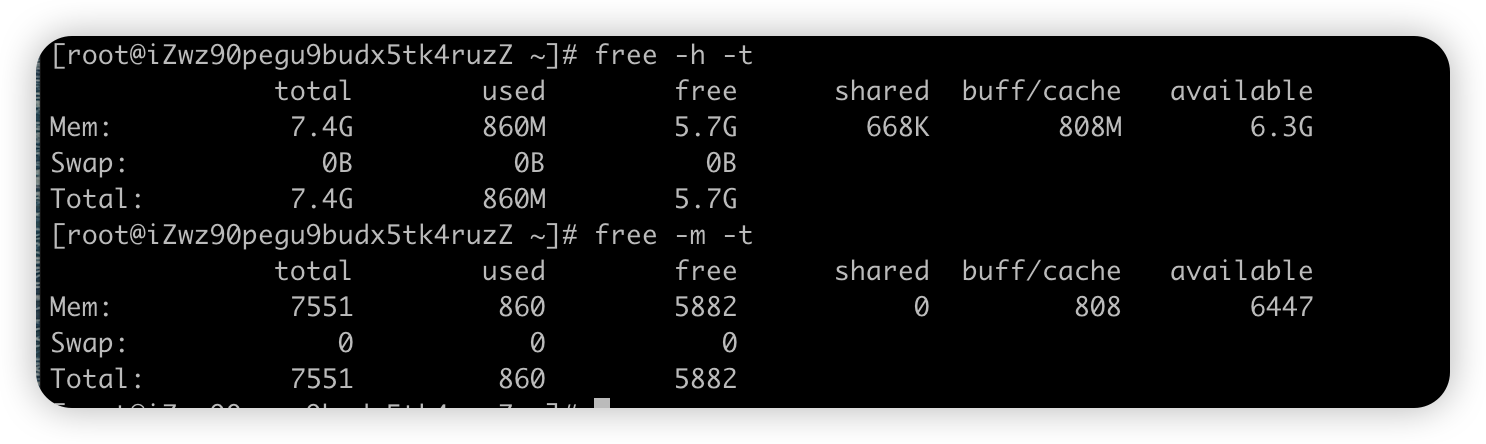
-
显示结果说明
数值 解释 taotal 总计物理内存 + Swap的大小 used 已使用物理内存 + Swap的大小 free 可用的物理内存 + Swap的大小 shared 被共享使用的物理内存大小 buff/cache 磁盘的缓冲和缓存大小,buffers是块设备做的缓冲大小,cached是给文件做缓存大小 available 可以被程序使用的内存大小 -
疑惑点: 有一个 free 列,还有一个 available 列,这二者到底有何区别?
- free 是真正未被使用的物理内存数量
- available 是应用程序的角度看到的可用内存数量
- Linux 为了提升读写性能,会消耗一部分内存资源缓存磁盘数据 ,就是buffer 和 cache
- 没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存
- 大概计算
- available = free + buff/ cache
- **total = used + free + buff/cache **
-
【全局 + 局部 命令】top#
-
top命令( 全局 + 局部 )
-
能够实时显示系统中各个进程的资源占用状况,包括进程ID、内存占用率、CPU占用率等
-
格式
top [参数],按1后 显示各个cpu明细情况[root@iZwz90pegu9budx5tk4ruzZ ~]# top ———————————————————————————————————————————————————————————— # 任务队列信息,CPU 1 5 15分钟负载 top - 23:52:24 up 5 days, 7:10, 1 user, load average: 0.08, 0.03, 0.05 ———————————————————————————————————————————————————————————— # 任务进程信息 total 总进程数,running运行着进程数,sleeping睡眠进程数,stopped停止进程数,zombie僵尸进程数 Tasks: 106 total, 1 running, 104 sleeping, 0 stopped, 1 zombie ———————————————————————————————————————————————————————————— # us用户态占用CPU的百分比,sy内核态占用CPU的百分比, id — 空闲CPU百分比 # wa等待IO占用CPU的百分比, hi硬中断(Hardware IRQ)占用CPU的百分比, si软中断(Software Interrupts)占用CPU百分比 %Cpu0 : 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu2 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu3 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ———————————————————————————————————————————————————————————— # 内存状态 total物理内存总量,free空闲内存总量, used使用中的内存总量, buff/cache缓存的内存量 KiB Mem : 7733012 total, 6023384 free, 878228 used, 831400 buff/cache ———————————————————————————————————————————————————————————— # swap交换分区信息 total交换区总量, free空闲交换区总量, used使用的交换区总量, avail进程可用内存空间 KiB Swap: 0 total, 0 free, 0 used. 6605468 avail Mem ———————————————————————————————————————————————————————————— # 进程的状态信息 PID 进程id,USER进程所有者,PR进程优先级 是动态优先级 ;NI nice负值表示高优先级,静态优先级一般不变 # VIRT 进程使用的虚拟内存总量 VIRT=SWAP+RES,申请过的内存没有真正分配物理内存也会计算在内,进程的虚拟内存比常驻内存大得多 # RES 进程实际使用的、未被换出的物理内存大小,即不包括 Swap 和共享内存,单位kb # SHR共享内存大小,单位kb # S进程状态,D=不可中断的睡眠状态 R=运行 S=睡眠 T=停止 Z=僵尸进程了;%CPU上次更新到现在的CPU时间占用百分比 # %MEM 进程使用的物理内存百分比;TIME+ 进程使用的CPU时间总计,单位1/100秒; COMMAND 进程名称(命令名/命令行) PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9476 root 10 -10 129360 12988 10236 S 1.7 0.2 23:02.91 AliYunDunMonito 8054 polkitd 20 0 2836776 566736 15756 S 0.3 7.3 12:38.53 mysqld 9364 root 10 -10 42380 4556 3036 S 0.3 0.1 1:12.27 AliYunDunUpdate 9466 root 10 -10 100876 8572 6492 S 0.3 0.1 6:09.75 AliYunDun VIRT virtual memory usage RES resident memory usage SHR shared memory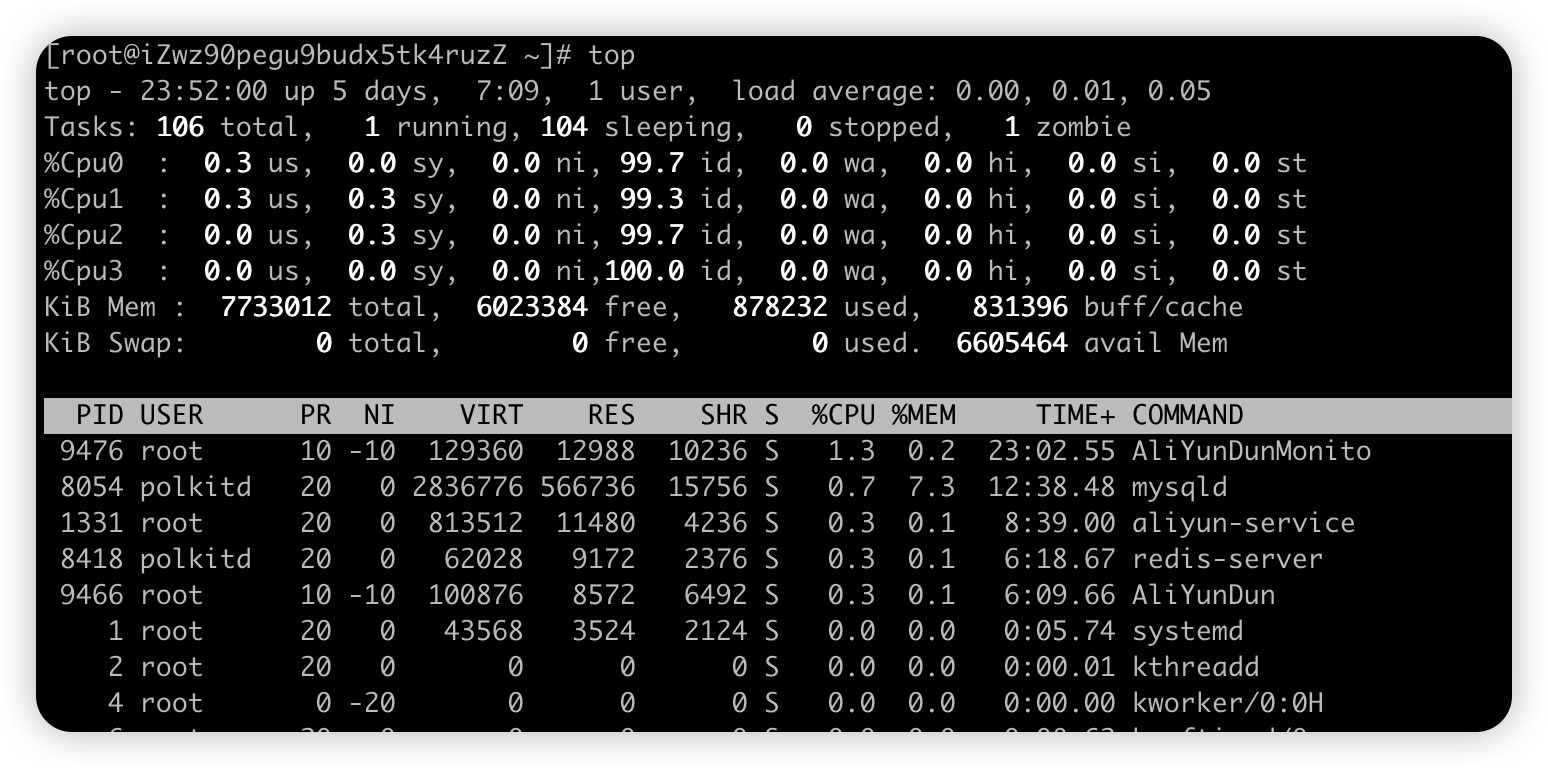
-
性能诊断与案例#
前置工作#
基础知识
- gcc 是一个编译器,没有界面,在命令行模式下使用,通过 gcc 命令可以将源文件编译成可执行文件。
- gcc 命令如果不指定目标文件名时默认生成的可执行文件名为 a.out(linux) 或 a.exe(windows)。
- 可用 gcc [源文件名] -o [目标文件名] 来指定目标文件路径及文件名
- C语言中,malloc函数的作用是动态分配内存,不能自动释放,申请的内存单位是字节
- 安装 gcc
yum install gcc -y
将以下代码保存为user_service.c
#include <stdlib.h>
#include <stdio.h>
int main(void)
{
printf("等会我就OOM啦 \n");
while(1)
{
printf("...");
char *p = malloc(1024 * 200);
if (p == NULL)
{
return -1;
}
}
return 0;
}
模拟进程OOM#
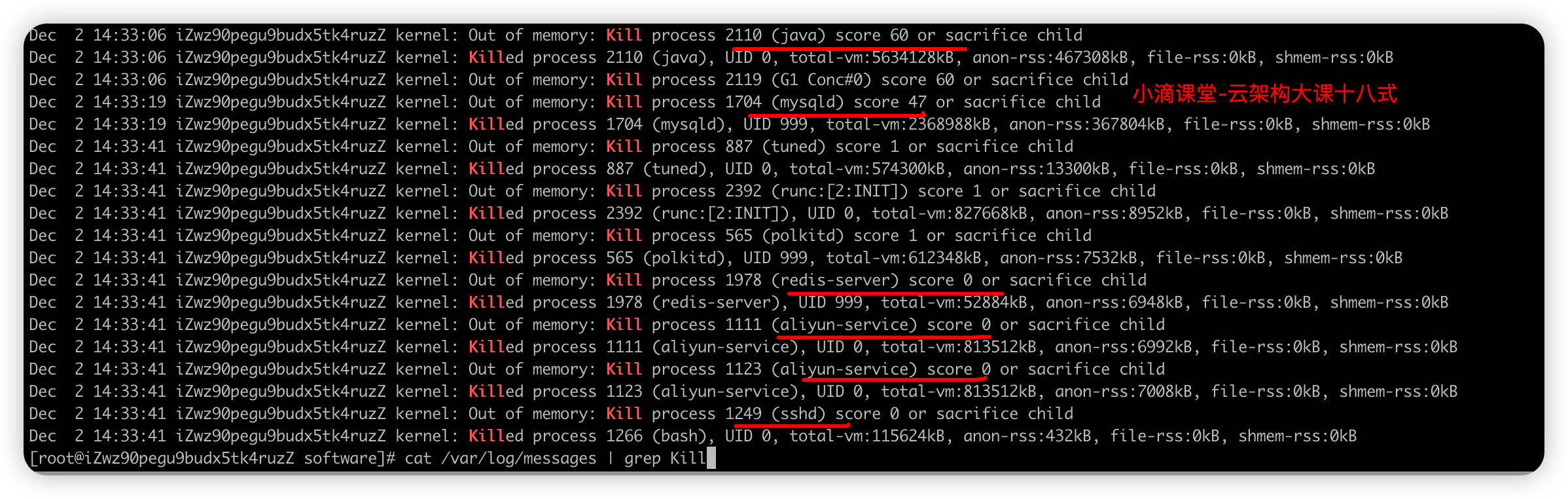
-
进程消失重现分析
终端一 # 释放所有缓存 echo 3 > /proc/sys/vm/drop_caches # 动态查看机器内存 free -h -s 1 终端二 # 实时查看top,进程的内存、CPU运行情况 top 终端三 # 编译程序 gcc user_service.c -o user_service.out # 运行程序 ./user_service.out -
原因分析
-
Linux服务器上有多个应用进程运行,应用压力突增情况下容易出现各种问题,在多应用部署时需要注意对内存分配和资源隔离
-
比如
-
Linux系统在内存不足等条件下会主动干预进程(OOM-Killer机制)
-
OOM killer 给进程打分,把
oom_score最大的进程先杀死, 打分主要有两部分组成-
一种系统根据该进程的内存占用情况打分,进程的内存开销是变化的,所以该值也会动态变化
-
另一种用户可以设置的
oom_score_adj,范围是-1000到1000
-
-
-
当然,另外一个常见情况,也可能是老王这个逗比,重启了机器,导致程序没开机自启动运行
- 通过执行last reboot 查看机器都什么时间是否重启过
- 或者top查看系统运行了多久
-
类似案例
- Rocketmq消息队列、Naocs服务注册发现、Java微服务jar 等进程常规运行,突然消失
- JVM本身的内存会启动的时候指定,但是JVM还有堆外内存,主要包括
- JVM 自身运行占用的空间、线程栈分配占用的系统内存、Java 8 开始的元数据空间
- DirectByteBuffer 占用的内存、JNI 里分配的内存、Unsafe 调用分配的内存;
- 这些技术在中间件、复杂技术业务项目等都高频出现
- 不由JVM触发也不由JVM管理,是系统内核的一种安全保护措施,包括可用内存(含swap)不足, 就有可能会影响系统稳定
- 这时候 Out of memory killer 就会设法找出进程并杀死,引起 Out of memory: kill process or sacrifice child 错误
- 配置Swap有好有坏,Full GC总比OOM 进程消失好吧
-
-
如何发现问题
-
/var/log/messages 日志
- 是核心系统日志文件,包括整体系统信息、系统启动时的引导消息、系统运行时的其他状态消息
- 在做故障诊断时可以首先查看该文件内容,比如IO 错误、网络错误和其他系统错误都会记录到这个文件中
#查看最新的10行 tail -10 /var/log/messages #过滤kill进程相关的日志 cat /var/log/messages | grep Kill- 格式
事件的日期和时间 事件的来源主机 产生这个事件的程序[进程号]日志信息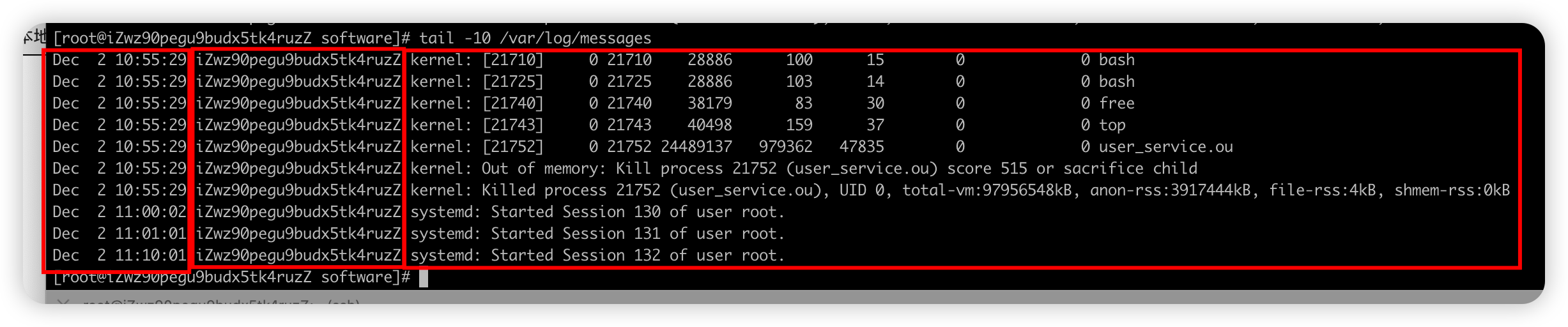
-
/var/log/dmesg
- 用dmesg查看,包含内核缓冲信息,在系统启动时,会在屏幕上显示许多与硬件有关的信息
#egrep 详细: -i 忽略大小写 -C n key 输出匹配key关键字及关键字上下的n行 #过滤出 killed process 上下10行日志 dmesg | egrep -i -C10 'killed process' #增加人类可读的时间戳 dmesg -T #常用完整命令 dmesg -T | egrep -i -C10 'killed process'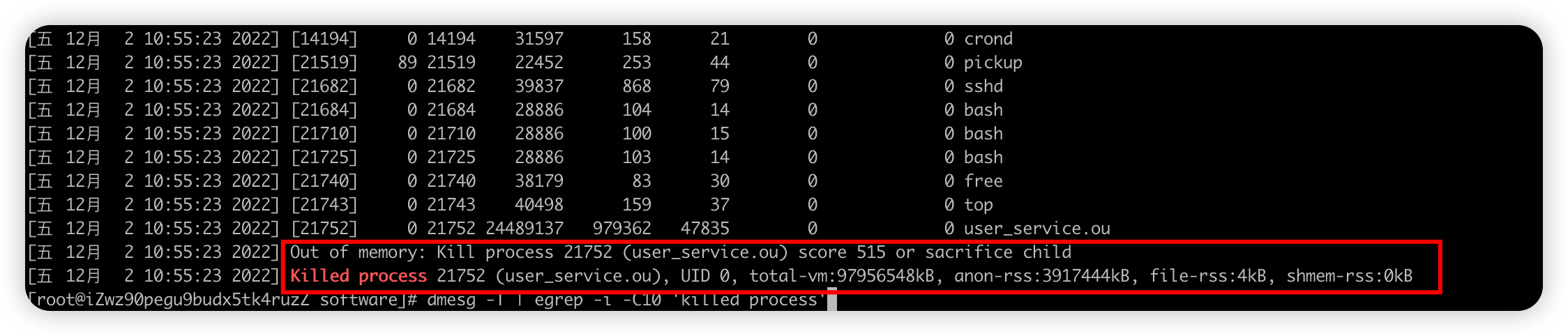
-
进程评分低,模拟OOM导致进程雪崩#
-
什么是oom_score
- 对某一个task进程进行打分(oom_score),实际得分需要考虑两方面,然后把
oom_score最大的进程先杀死- 一部分是系统打分,主要是根据该task的内存使用情况,进程的内存开销是变化的,所以该值也会动态变化
- 另一部分是用户打分,也就是oom_score_adj,默认是0,取值范围是-1000~1000
- 0表示用户不调整oom_score,负值表示要在实际打分值上减去一个折扣
- 正值表示要惩罚对应的进程,也就是增加该进程的oom_score
- 如果用户将该进程的 oom_score_adj 设定成
-1000,表示禁止OOM killer 杀死该进程,特别重要的服务可以配置
- 对某一个task进程进行打分(oom_score),实际得分需要考虑两方面,然后把
-
说明
- proc 文件系统是虚拟文件系统, 某个进程被杀掉, 则 /proc/pid/ 目录也就被销毁
-
验证(大家可以不做实操,避免系统坏死,重启才可以正常连接)
-
课程这个系统用几个程序,java、mysql、redis 等,都是大家熟悉的
-
查看系统本身对进程的评分,内存是变化的,所以该值也会动态变化
#执行这个程序,调用多次 cat /proc/$(pidof user_service.out)/oom_score -
用户手工修改进程的评分(大量申请内存,操作的时候回卡顿)
#先查看系统的评分 cat /proc/$(pidof user_service.out)/oom_score #先查看用户默认的评分 cat /proc/$(pidof user_service.out)/oom_score_adj #手工修改评分 sudo sh -c "echo -500 > /proc/$(pidof user_service.out)/oom_score_adj" #查看修改后的评分 cat /proc/$(pidof user_service.out)/oom_score_adj #再查看系统的评分 cat /proc/$(pidof user_service.out)/oom_score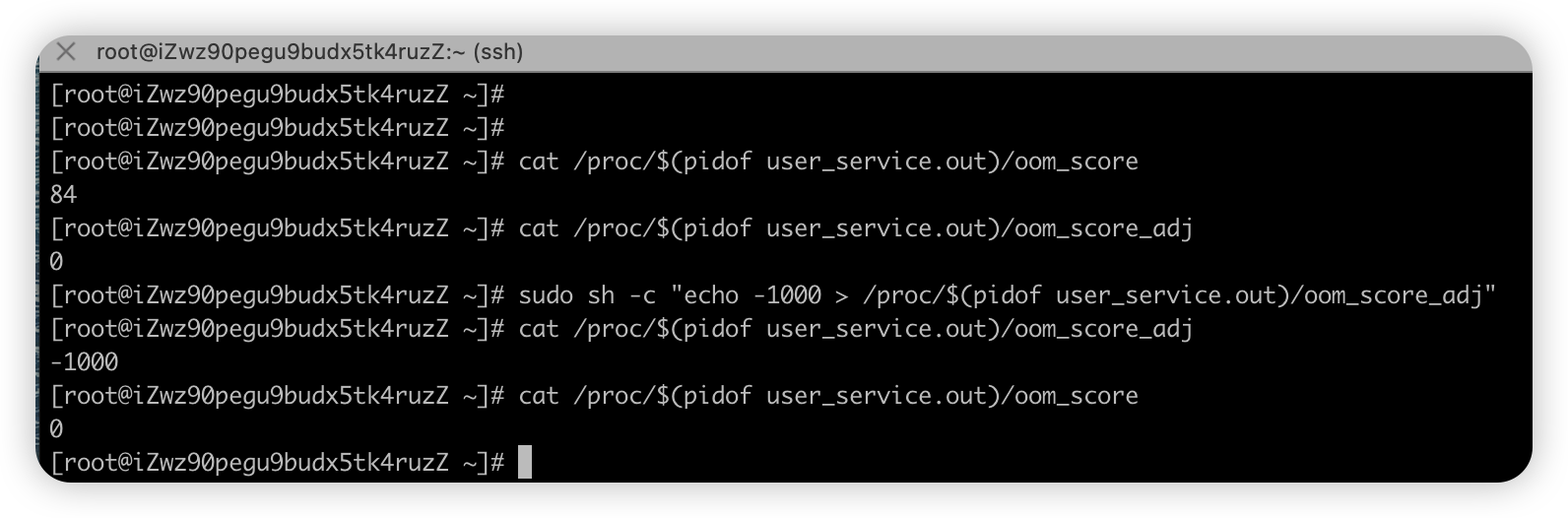
-
注意
- 把一个一直申请内存的进程的 oom_score_adj 设置为-1000,会导致大量的都进程被kill
- 因为使用了bash所以这个bash挂了,user_service.out也停止了,如果是后端运行,则更多进程都会被kill
#进程的 oom_score_adj 设置为-1000 sudo sh -c "echo -1000 > /proc/$(pidof user_service.out)/oom_score_adj" #过滤kill进程相关的日志 cat /var/log/messages | grep Kill #常用完整命令, 可能损坏查询不到信息 dmesg -T| grep "Out of memory"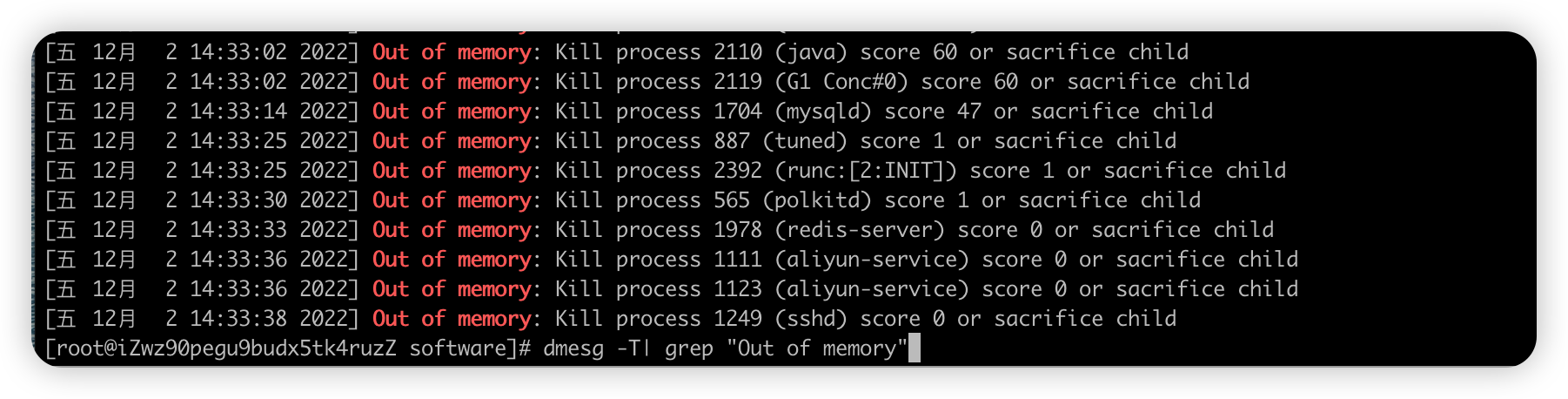
-
Buffer与Cache演示#
-
什么是磁盘块设备
- 磁盘是一个块设备,创建分区,再创建文件系统,挂载目录,就可以在目录中读写文件
- Linux 中 全部都是文件,课程中提到的“文件”是普通文件,磁盘是块设备文件, 块是文件系统的抽象,不是磁盘本身的属性
- 块设备读取和写入的大小,单位为块 / 秒, 假如在 Linux 中块(block)的大小是 1KB, 磁盘读写也等价于 KB/s
- 与内存操作,是虚拟一个页的概念来作为最小单位; 与硬盘打交道,就是以块为最小单位
- Linux中的虚拟设备
#读它的时候,它会提供无限的空字符; 另一个常见用法是产生一个特定大小的空白文件 /dev/zero #随机数设备,提供不间断的随机字节流, 当系统中断过多时,/dev/random设备会 挂起 ,产生数据速度较慢,但随机性好 /dev/random #随机数设备,提供不间断的随机字节流, 不依赖系统中断,数据产生速度快,但随机性较低 /dev/urandom #看作"黑洞",它等价于一个只写文件,所有写入它的内容都会永远丢失 /dev/null -
需求
-
通过 文件读写 ,验证buffer和cache使用情况和性能影响
-
磁盘读写 不做验证,没有多个磁盘直接操作
-
-
命令回顾
-
vmstat (全局)
- 全称是 Virtual Meomory Statistics(虚拟内存统计)的缩写,是对系统整体的情况进行统计,不细化某个进程,是宏观命令
- 格式:
vmstat [选项] [时间间隔[次数]](参数很多,记住常用的即可) vmstat n每隔n秒后输出一行信息, 一般会加个 -w 进行加宽显示,比如vmstat -w 1vmstat -SM指定单位显示,默认KB,M表示是MBvmstat -t带上时间戳信息- 更多参数信息
vmstat -h或man vmstat - 实时查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等
-
dd:用指定大小的块 拷贝一个文件,并在拷贝的同时进行指定的转换,下面是参数
-
if = 文件名:输入文件名,缺省为标准输入,即指定源文件。< if = input file >
-
of = 文件名:输出文件名,缺省为标准输出,即指定目的文件。 < of = output file >
-
bs = bytes:同时设置读入/输出的块大小为bytes个字节, 即是每次读或写的大小, 一个块的大小
-
count = blocks:仅拷贝blocks个块,块大小等于指定的字节数, count是读写块的数量
-
-
-
操作
-
终端一 查看当下内存使用情况
free -h -w,释放全部缓存echo 3 > /proc/sys/vm/drop_caches -
终端二 实时查看系统内存和IO使用情况
vmstat 1 -SM -t -
终端三
- 测试 **文件写命令 **
- 现象: Cache增长快 接近写入文件的大小, Buffer有少量增长
# 通过读取随机设备,生成一个 1GB 大小的文件, 通过 ls -lh /tmp/xdclass_file.txt 查看 dd if=/dev/urandom of=/tmp/xdclass_file.txt bs=1M count=1024- 测试 文件读命令
- Cache增长快 接近写入文件的大小, Buffer有少量增长
#读文件,写入到黑洞里面 dd if=/tmp/xdclass_file.txt of=/dev/null- 磁盘 直接读写(需要有多个未用的磁盘,这个不做测试,会系统坏死,需要重装系统或者联系云厂商)
#查看机器所挂硬盘个数及分区情况 fdisk -l 现象:Buffer增长快,而Cache增长慢,读写磁盘时,数据有缓存Buffer里面 - 测试 **文件写命令 **
-
深入理解磁盘和IO#
文件系统与虚拟文件系统VFS#
文件系统#
- 在 Linux 中一切皆文件,文件系统是管理磁盘上的全部文件,文件管理组织方式多种多样,所以文件系统存在多样化
- 问题:系统把文件持久化存储在磁盘上,那很多文件怎么管理和使用呢?
- 答案
- 这个就是文件系统的职责,实现文件数据的查询和存储
- 文件系统是管理数据,而存储数据的物理设备有硬盘、U 盘、SD 卡、网络存储设备等
- 不同的存储设备其物理结构不同,不同的物理结构就需要不同的文件系统去管理
- 例子
- Windows有FAT12、FAT16、FAT32、NTFS、exFAT等文件系统
- Linux有Ext2、Ext3、Ext4、tmpfs、NFS等文件系统
- 答案
- 查询系统用了哪些的文件系统
df -h -T

- 两个核心概念
- 索引节点(index node)
- 简称inode ,记录文件的元信息,比如文件大小、访问权限、修改日期、数据存储位置等
- 索引节点也需要持久化存储,占用磁盘空间。
- 目录项(directory entry)
- 简称为 dentry,记录目录结构,比如 文件的名字、索引节点指和其他目录项的关联关系等,树状结构居多
- 存储在内存中,也叫目录项缓存。
- 索引节点(index node)
虚拟文件系统VFS(virtual File System)#
-
问题:操作系统上有那么多的文件系统和物理存储介质,应用程序怎么编写使用呢?
-
答案
- 虚拟文件系统就是做这个,调用读写位于不同物理介质上的不同文件系统, 为各类文件系统提供统一的接口进行交互
- 在应用程序和具体的文件系统之间引入了一个抽象层,开发者不用关心底层的存储介质和文件系统类型就可以使用
-
下图是Linux的IO存储栈
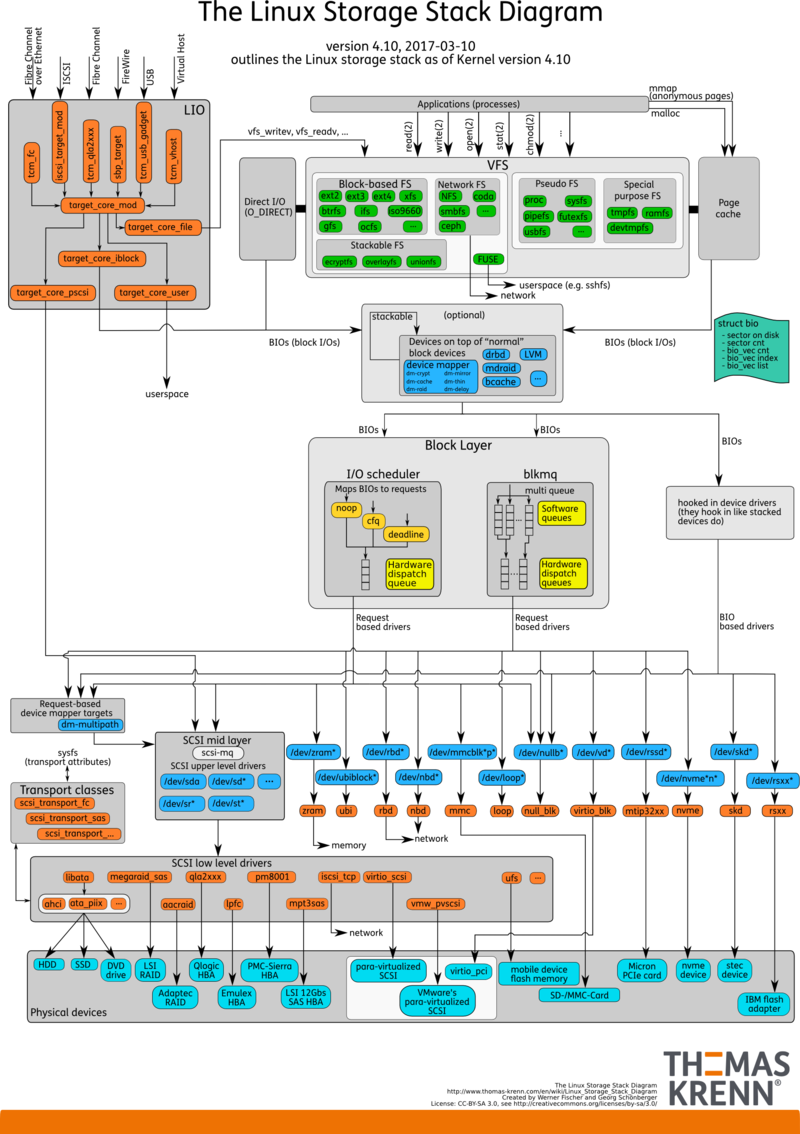
- 简略图
- 平时调用 write 的时候,数据是从应用写入到了C标准库的IO Buffer(用存在户态)
- 在关闭流之前flush下文件,通过flush将数据主动写入到内核的Page Cache中,应用挂了,数据也安全(存在内核态)
- 将内核中的Page Cache中的数据写入到磁盘(缓存)中,系统挂了,数据也安全,需要调用fsync(存在持久化介质)
- 简略图
-
-
最终答案
-
操作系统的多级缓存和数据的可用性
- 操作系统也是程序,人家程序员也要考虑高性能
- 高性能:多线程 异步、多级缓存
-
是否很熟悉,我们日常开发的java微服务项目
-
多线程异步操作,响应快
-
微服务里面的多级缓存 ,guava本地缓存和redis分布式缓存
-
又回到了一开始说的,重学操作系统,很多知识点你在用或者用过了,但是没人提醒你 导致理解记忆困难
-
你就是缺这样的架构大课,帮你总结思想,触类旁通
-
不会像大学那样打瞌睡,是的话,要不大课群里给我点个赞,后续还有更多
-
-
磁盘#
机械硬盘常见性能指标#
-
大家最熟悉的外存-磁盘:主要机械硬盘和固态硬盘
-
机械磁盘HDD
-
组成结构很多,重点关注:磁盘、磁头臂、磁头
- 每个盘片的正反两面都有对应的磁头
-
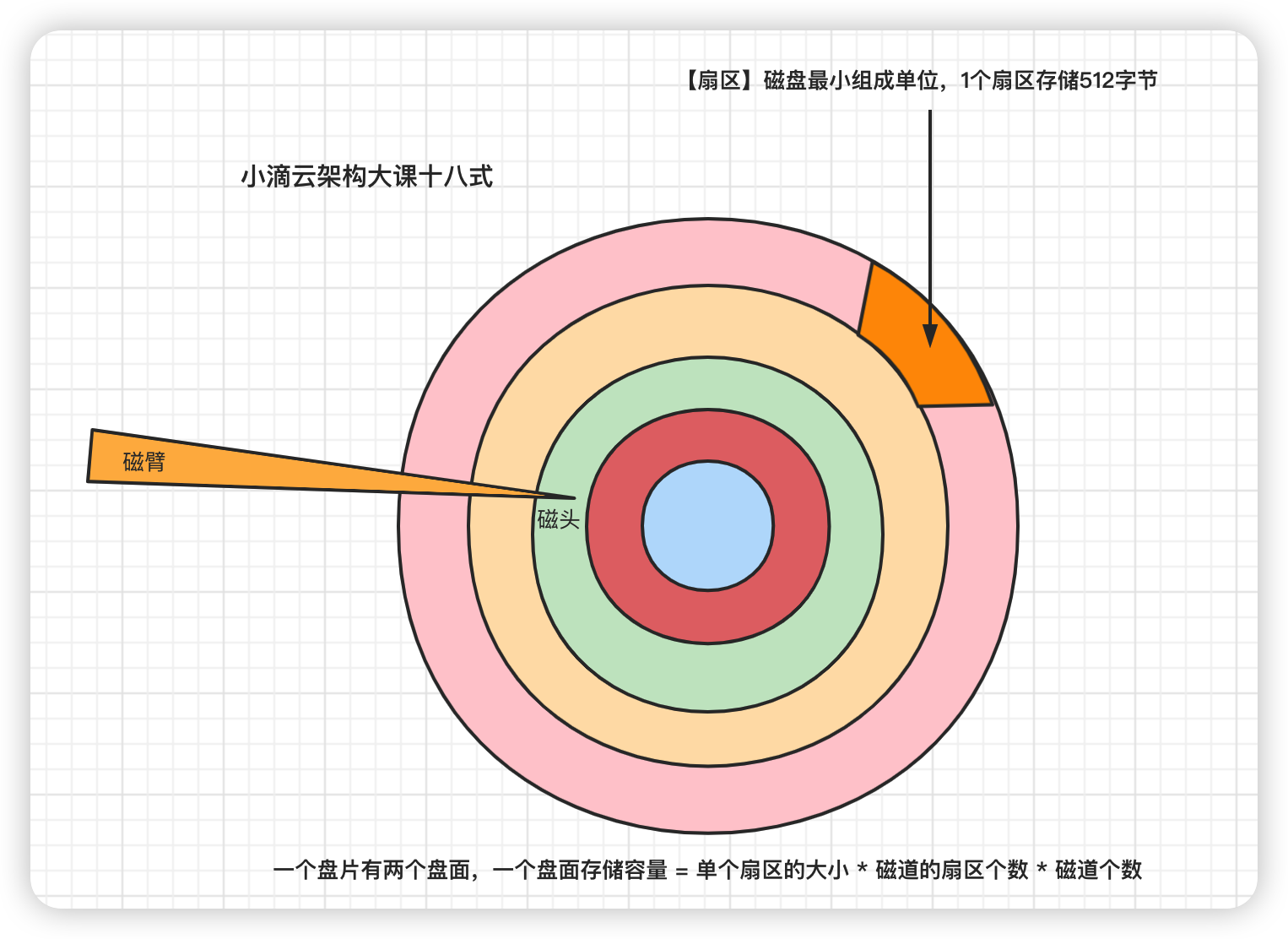
数据存储在盘片的环状磁道中,最小读写单位是扇区,一般大小为 512 字节
-
如何读取数据:
- 磁臂摆动+盘片转动(耗时大所以导致慢,随机在硬盘上找一个数据,需要 8-14 ms),定位到目标扇区读取数据
- 磁臂在一定范围内摆动,来找到目标扇区,靠磁头把某个扇区的数据传输到总线上
- 磁臂摆动范围有限,触达不到比较远的扇区,靠转轴来带动盘片,比如磁盘转速有7200转/分,1秒就是120圈
- 常规1秒可以做100次随机IO,所以高并发业务单靠磁盘上扛不住的,基本都是要结合缓存
- 想要优化,不用随机IO,采用顺序IO,节省了大量的物理耗时,比如Kafka、RocketMQ都是
-
概念划分
-
磁盘读写的最小单位是扇区sector,常规扇区是512Byte,这样的话读写单位太小,性能不高
-
文件系统把连续的扇区组成逻辑块 block,以逻辑块为最小单元来管理数据
-
一般逻辑块大小为 4KB,是由连续的 8 个扇区组成
-
-
-
-
磁盘读写常见指标
-
IOPS(Input/Output Operations per Second)
- 指每秒能处理的I/O个数,表示块存储处理读写(输出/输入)的能力,单位为次,有顺序IOPS和随机IOPS
- 比如100次/秒,那iops就是100次/秒,例如数据库类应用等典型场景重点提升这个指标,下面是阿里云盘性能
- 高效云盘:2120 IOPS
- ESSD云盘:2280 IOPS
- SSD云盘:3000 IOPS
- 参考:https://help.aliyun.com/document_detail/25382.html
-
吞吐量/带宽(Throughput)
- 是指单位时间内可以成功传输的数据数量,单位为MB/s
- 比如 一个硬盘的读写 IO 是 1MB,硬盘的 IOPS 是 100,那么硬盘总的吞吐率就是 100MB/s
- 带宽 = IOPS * IO大小
- 如果需要部署大量顺序读写的应用,例如Hadoop离线计算型业务等典型场景,需要关注吞吐量
-
访问时延(Latency)
- 是指IO请求从发出到收到响应的间隔时间,常以毫秒ms或者微妙us为单位
- 硬盘响应时间 = 硬盘访问时间 + IO排队延迟
- 过高的时延会导致应用性能下降或报错。
- 如果应用对高时延比较敏感,例如数据库应用,建议使用ESSD AutoPL云盘、ESSD云盘、SSD云盘或本地SSD盘类产品。
- 普通的HDD磁盘,随机IO读写延迟是10毫秒,IO带宽大约100MB/秒,随机IOPS一般在100左右
-
容量(Capacity) 查看。
df -h- 是指存储空间大小,单位为TiB、GiB、MiB或者KiB,块存储容量按照二进制单位计算,例如
1B(byte 字节)=8bit 1KB(Kilobyte 千字节)=1024B, 1MB(Megabyte 兆字节 简称“兆”)=1024KB, 1GB(Gigabyte 吉字节 又称“千兆”)=1024MB, 1TB(Terabyte 万亿字节 太字节)=1024GB, 1PB(Petabyte 千万亿字节 拍字节)=1024TB, 1EB(Exabyte 百亿亿字节 艾字节)=1024PB
-
固态硬盘标记整理回收#
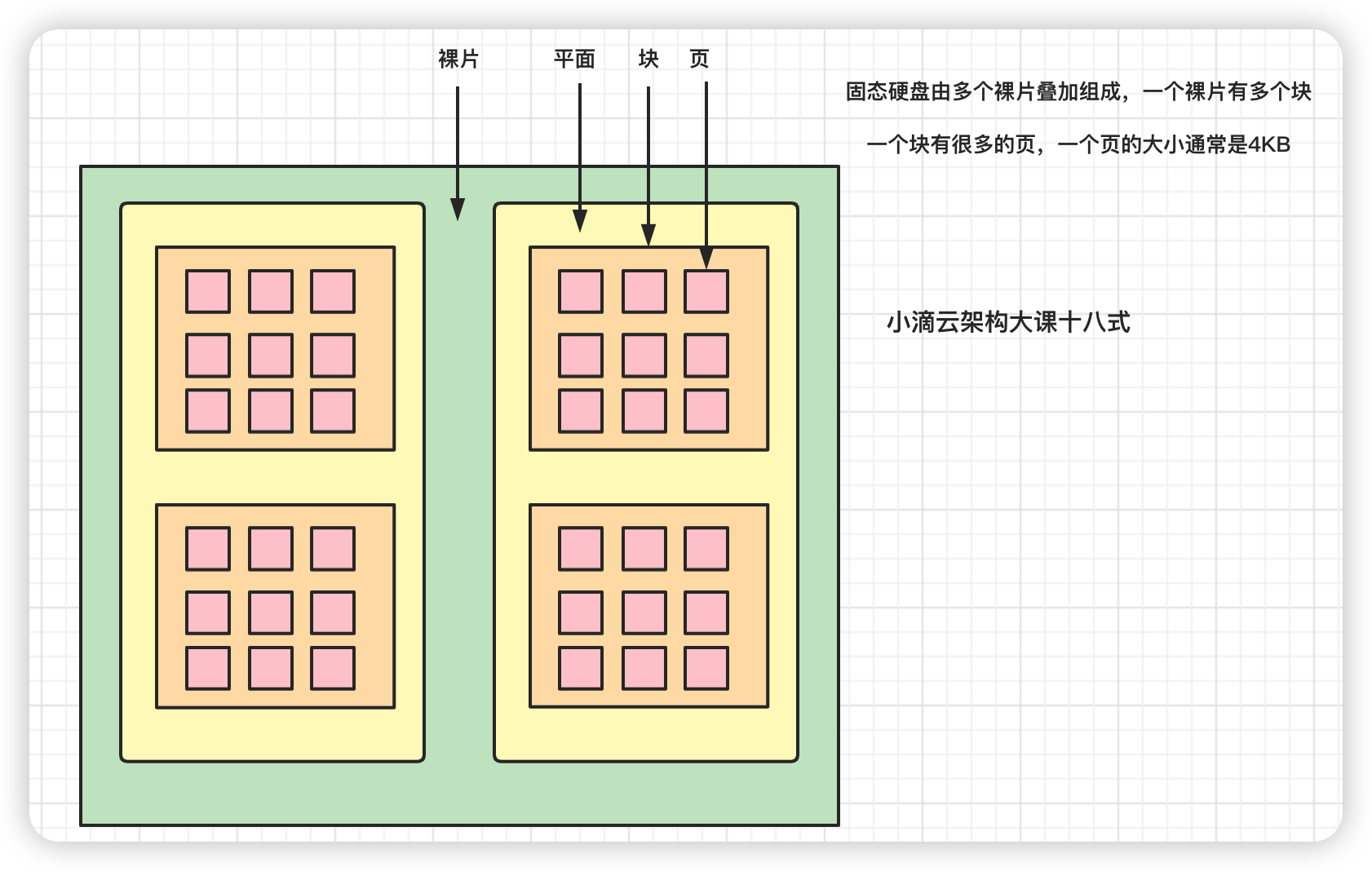
- 固态磁盘SSD
- 固态电子元器件组成,没有盘片、磁臂等机械部件,不需要磁道寻址,靠电容存储数据,
- 某块区域存在数据,机械硬盘写入可以直接覆盖;而固态硬盘需要先擦出,再写入
- block块 擦的越多寿命就越短,业务数据高频更新,则不太建议使用固态硬盘
- 最小读写单位是页,通常大小是 4KB、8KB
- 性能高,IOPS可以达到几万以上;价格比机械硬盘贵,寿命较短
- 组成结构
- SSD 多个裸片组成
- 裸片 多个平面组
- 平面 plane(多个blcok组成)
- 块 block(通常64个page组成一个block)
- 页 page 4k
-
磁盘的擦除数据
-
SSD里面最小读写单位是page,但是最小擦除单位是block
- 一个块上的某些页的数据被标记删除,不能直接擦除这些的页,除非整个块上的页都被标记删除
- 块还有其它有效数据,当有新数据只能写入白色区域,并不能利用红色区域,时间越长,不能被使用的碎片越多
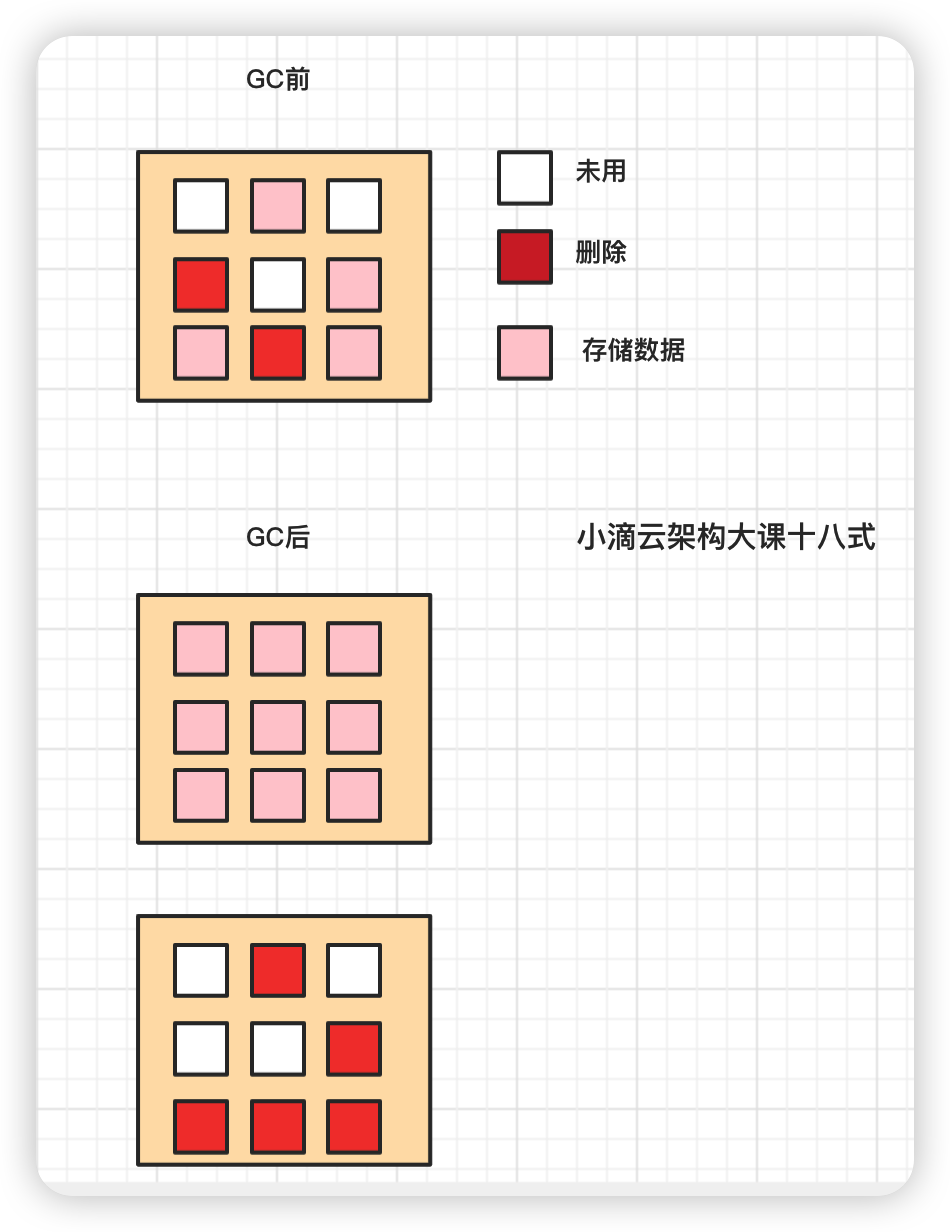
-
解决方案 GC(Garbagecollection)垃圾回收
- 有一套标记整理机制程序,"有效"页数据复制到一个"空白"块里,然后把这个块完全擦除
- 那些被移动出数据的块上面的页要么没数据,要么是标记删除的数据,直接对这个块进行擦除
- **擦除数据 类似JVM的GC ,标记整理 Mark Compact **
- 先对对象进行一个标记,看看哪些对象是垃圾
- 整理会在清除的过程中,把可用的对象向前移动,让内存更为紧凑,避免内存碎片的产生
- 整理之后发现内存更紧凑,连续的空间更多,就不会造成内存碎片的问题
-
-
业务选择(没有绝对,公司有钱另说)
- 业务大量写日志系统,时间滚动会定期清除老旧的日志,日志一般读的少
- 大量擦出会导致SSD寿命变短,所以不适合存放在SSD硬盘上,应该用HDD硬盘
磁盘冗余整列#
磁盘阵列(开发人员做了解即可,一般专业运维负责)
-
独立磁盘冗余阵列 RAID(Redundant Array of Independent Disks)
-
一种提供高可用性和数据容错性的数据存储技术,把几块硬盘组成一个阵列,并将它们的数据分布在不同的磁盘上
-
在硬盘发生故障时保护数据,还可以提高I/O性能,使系统能够更快地完成任务。
-
简单来说:是把相同的数据存储在多个硬盘的不同的地方的方法,储存冗余数据增加了容错
-
根据 性能、容量、可靠性,有多个级别,如 RAID0、RAID1、RAID5、RAID10
-
RAID方案
- RAID0 磁盘阵列:
- 至少需要两块硬盘,磁盘越多,读写速度快,一个磁盘吞吐 * 磁盘数量* 0.8,没有冗余
- 磁盘利用率100%,安全性最低
- 优点是读写性能比一般硬盘好,缺点是没有数据冗余,一块硬盘出现故障可能导致数据损坏。
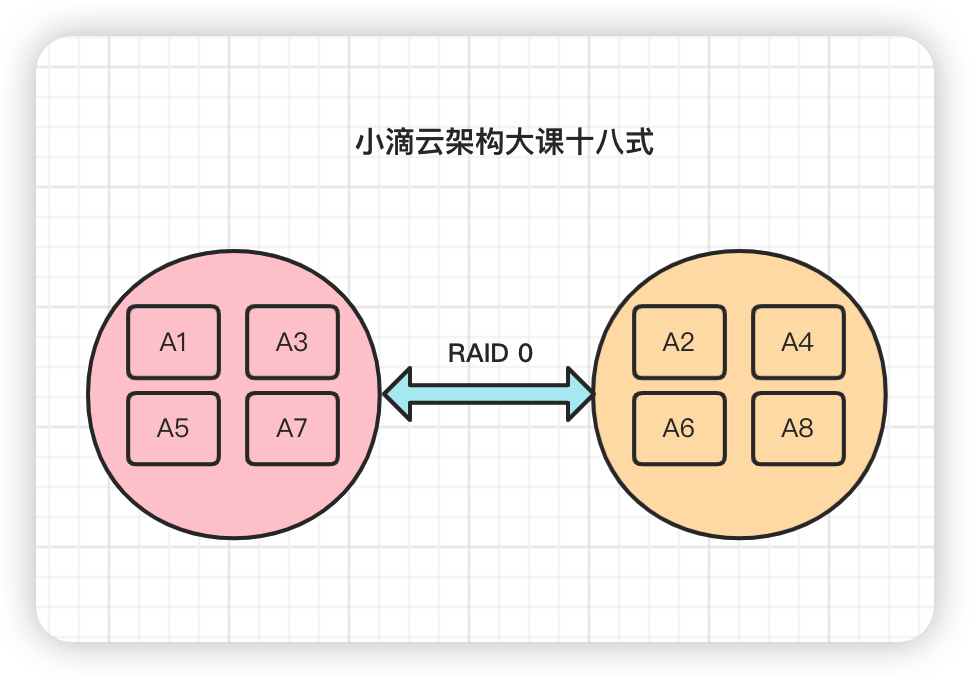
-
RAID1 镜像阵列
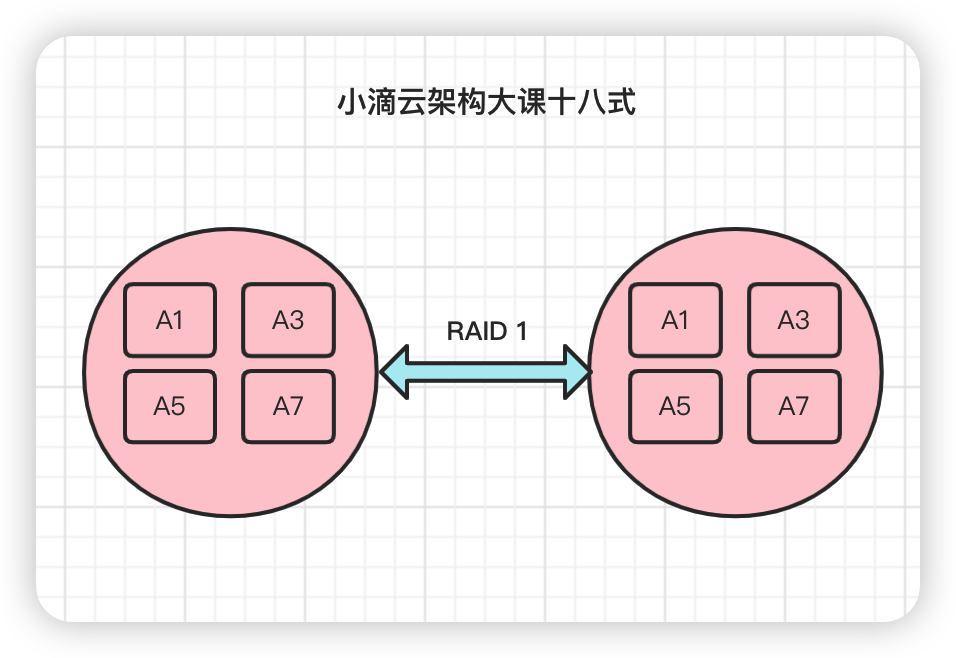
- 全部数据都分别复制到多块盘上,当其中一块盘出现故障时另外一块盘的数据可以被立即使用,从而保证数据的安全性
- 每次写数据时会同时写入镜像盘,读写性能较低,只能用两块硬盘, 一块磁盘冗余,磁盘的利用率只有50%
- 优点是数据冗余性高,缺点是读写性能比一般硬盘差
- 适合服务器、数据库存储等领域
-
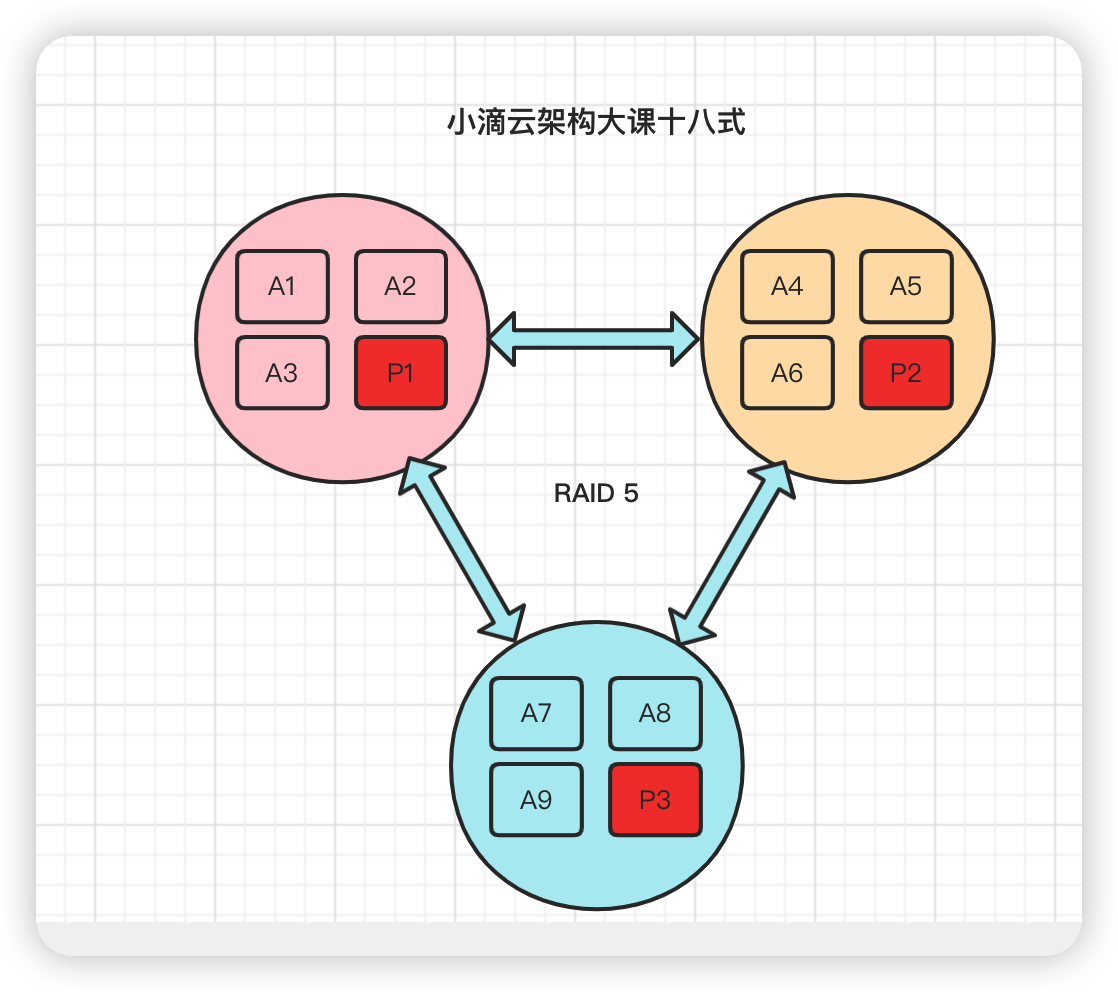
RAID5 条带阵列
- 至少需要3块硬盘,一块磁盘冗余, 是最通行的配置方式,是将多块硬盘按特定顺序组合起来
- 在每块硬盘上都会存储1份数据和1份校验信息,1块硬盘出现故障时,根据另外2块硬盘的校验信息可以恢复数据
- 这种存储方式只允许有一块硬盘出现故障,出现故障时需要尽快更换
- 综合了RAID-0和RAID-1的优点和缺点,是RAID0和RAID1的折中方案
- 适合需要安全和成本兼顾的领域,性能要求稍高,比如金融数据库存储
-
RAID 10 、RAID 50
- 安全性和读写性能高,缺点是成本较高(有钱就行)
- RAID0 磁盘阵列:
DMA与零拷贝#
DMA (Direct Memory Access)
- 直接内存访问,直接内存访问是计算机科学中的一种内存访问技术
- DMA之前:要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过 CPU控制完成,利用中断技术
- 允许某些硬件系统能够独立于 CPU 直接读写操作系统的内存,不需中央处理器(CPU)介入处理
- 数据传输操作在一个 DMA 控制器(DMAC)的控制下进行,在传输过程中 CPU 可以继续进行其它的工作
- 在大部分时间CPU和 I/O 操作都处于并行状态,系统的效率更高
DMA与普通拷贝的区别
需求
- 应用程序 从 磁盘读写数据 的时序图(未用DMA技术前)
- 角色:用户程序、CPU、磁盘
普通拷贝
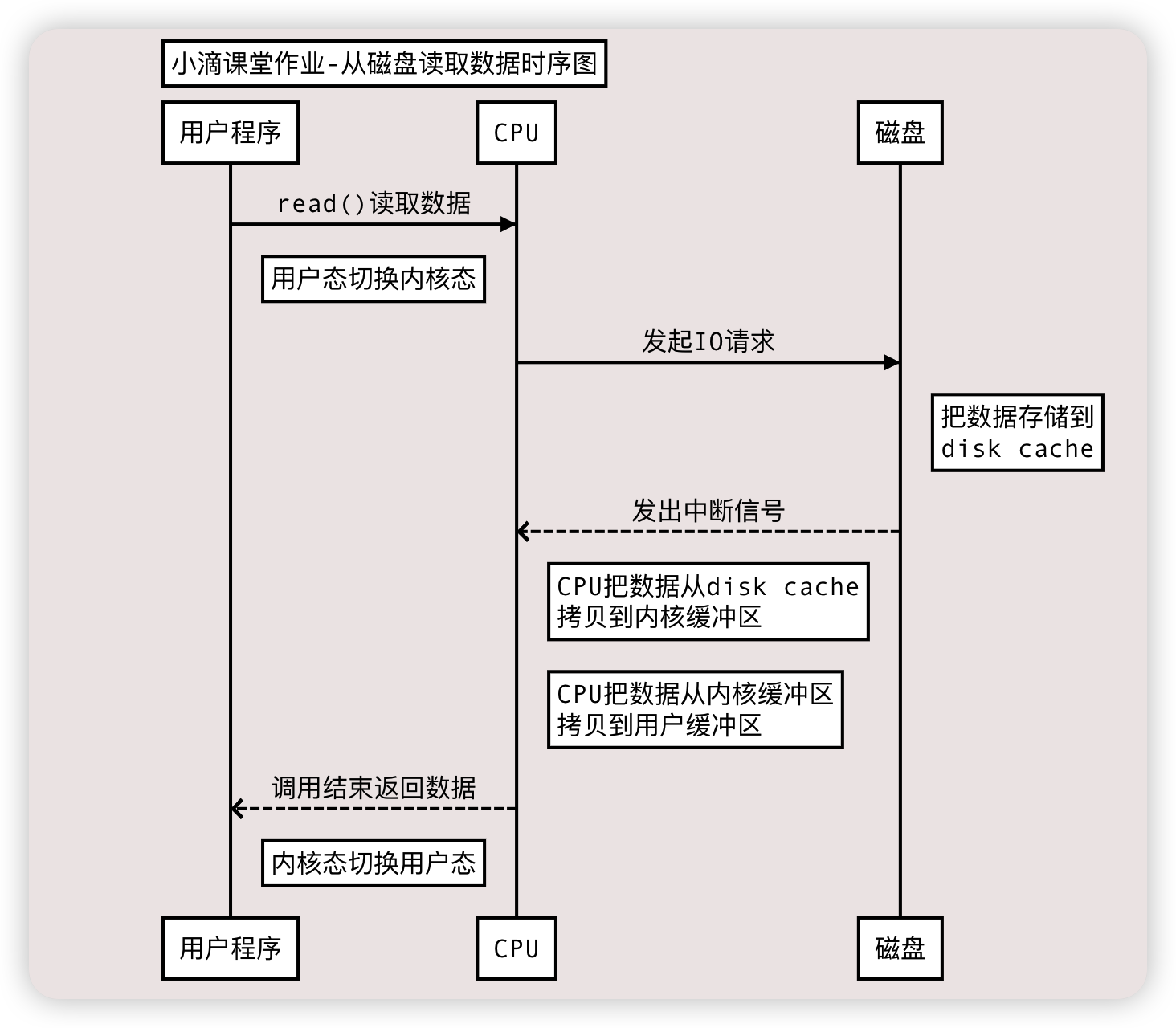
Title: 小滴课堂作业-从磁盘读取数据时序图
用户程序->CPU:read()读取数据
Note right of 用户程序: 用户态切换内核态
CPU->磁盘:发起IO请求
Note right of 磁盘: 把数据存储到 \n disk cache
磁盘-->>CPU:发出中断信号
Note right of CPU: CPU把数据从disk cache \n 拷贝到内核缓冲区
Note right of CPU: CPU把数据从内核缓冲区 \n 拷贝到用户缓冲区
CPU-->>用户程序:调用结束返回数据
Note right of 用户程序: 内核态切换用户态
使用DMA
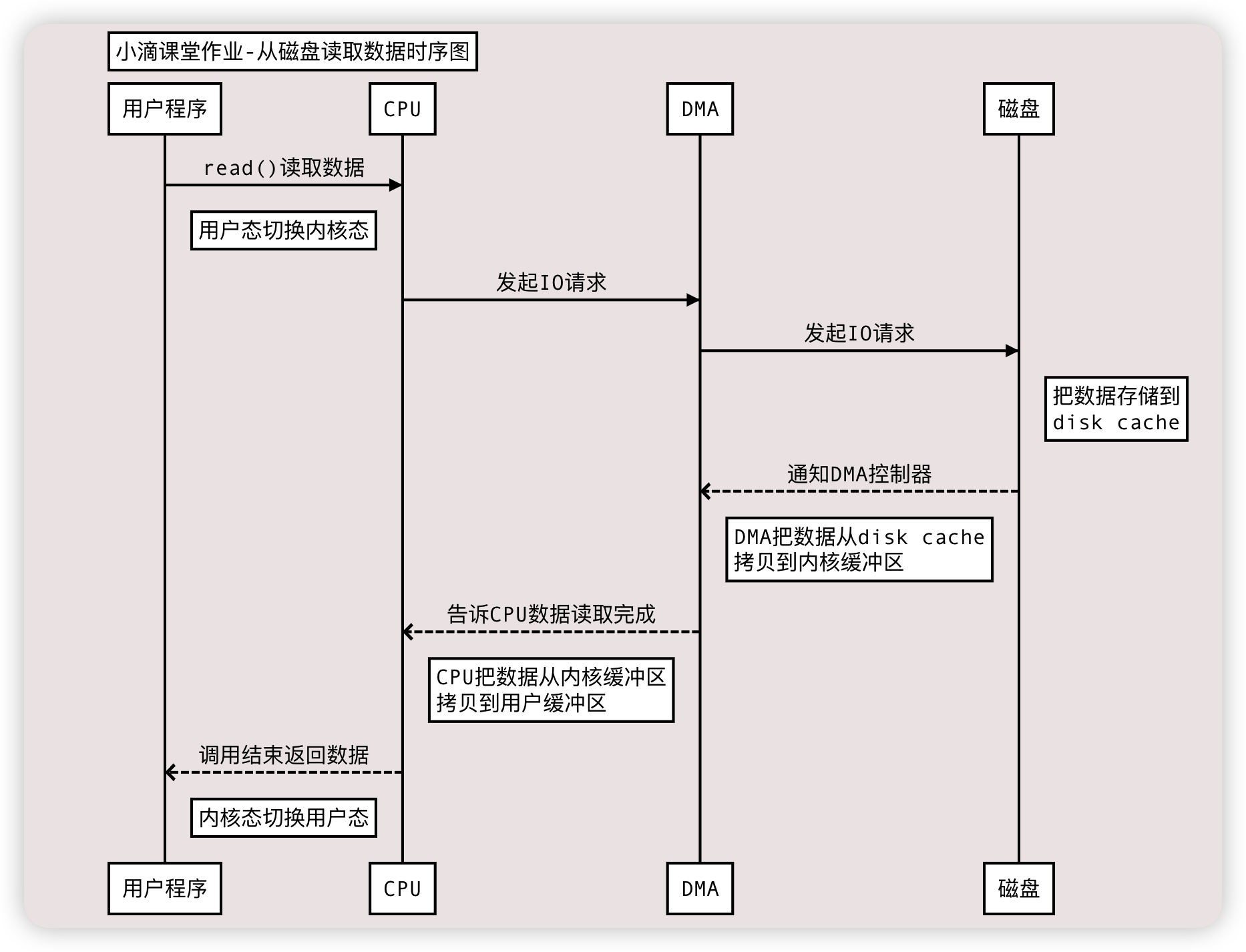
Title: 小滴课堂作业-从磁盘读取数据时序图
用户程序->CPU:read()读取数据
Note right of 用户程序: 用户态切换内核态
CPU->DMA:发起IO请求
DMA->磁盘:发起IO请求
Note right of 磁盘: 把数据存储到 \n disk cache
磁盘-->>DMA: 通知DMA控制器
Note right of DMA: DMA把数据从disk cache \n 拷贝到内核缓冲区
DMA-->>CPU:告诉CPU数据读取完成
Note right of CPU: CPU把数据从内核缓冲区 \n 拷贝到用户缓冲区
CPU-->>用户程序:调用结束返回数据
Note right of 用户程序: 内核态切换用户态
-
应用程序的读写数据
-
读本地磁盘
- 操作系统检查内核缓冲区读取,如果存在则直接把内核空间的数据copy到用户空间(谁负责 CPU),应用程序即可使用
- 上步没数据,则从磁盘中读取到内核缓冲区(谁负责 DMA),再把内核空间的数据copy到用户空间(谁负责 CPU),应用程序即可使用
- 硬盘->内核缓冲区->用户缓冲区
-
写操作本地磁盘
- 根据操作系统的写入方式不一样,buffer IO和direct IO ,写入磁盘时机不一样
- buffer IO
- 应用程序把数据从用户空间copy到内核空间的缓冲区(谁负责CPU),再把内核缓冲区的数据写到磁盘(谁负责DMA)
- direct IO:应用程序把数据直接从用户态地址空间写入到磁盘中,直接跳过内核空间缓冲区
- 减少操作系统缓冲区和用户地址空间的拷贝次数,降低了CPU和内存开销
- 用户缓冲区->内核缓冲区->硬盘
-
读网络数据
- 网卡Socket(类似磁盘)中读取客户端发送的数据到内核空间(谁负责DMA)
- 把内核空间的数据copy到用户空间(谁负责CPU),然后应用程序即可使用
-
写网络数据(下面是程序直接发送,如果从磁盘读取则不一样)
- 用户缓冲区中的数据copy到内核缓冲区的Socket Buffer中(谁负责CPU)
- 将内核空间中的Socket Buffer拷贝到Socket协议栈(网卡设备)进行传输(谁负责DMA)
-
-
DMA的工作总结
-
(读)从磁盘的缓冲区到内核缓冲区的拷贝工作
-
(读)从网卡设备到内核的soket buffer的拷贝工作
-
(写)从内核缓冲区到磁盘缓冲区的拷贝工作
-
(写)从内核的soket buffer到网卡设备的拷贝工作
-
但是:内核缓冲区到用户缓冲区之间的拷贝工作仍然由CPU负责
-
DMA技术里面的损耗
-
CPU的用户态和内核态切换
-
CPU的内存拷贝损耗
-
下图应用程序从磁盘读取数据发送到网络上的损耗,程序需要两个命令 先read读取,再write写出
- 四次内核态和用户态的切换
- 四次缓冲区的拷贝
- 读取:磁盘缓冲区到内核缓冲区(DMA)
- 读取:内核缓冲区到用户缓冲区(CPU)
- 写出:用户缓冲区到内核缓冲区Socket Buffer(CPU)
- 写出:内核缓冲区的Socket Buffer到网卡设备(DMA)
- 性能损耗操作
- 2次DMA拷贝、2次CPU拷贝、4次内核态用户态切换
- 计算机大神们怎么会容忍这类浪费呢,所以就诞生了零拷贝
零拷贝ZeroCopy
- 减少不必要的内核缓冲区跟用户缓冲区之间的拷贝工作,
- 从而减少CPU的开销和减少了kernel和user模式的上下文切换,达到性能的提升
- 从磁盘中读取文件通过网络发送出去,只需要拷贝2\3次 和 2\4的内核态和用户态的切换即可
- ZeroCopy技术实现有两种(内核态和用户态切换次数不一样)
- 方式一 mmap + write
- 方式二 sendfile
ZeroCopy实现方式一 mmap + write
-
操作系统都使用虚拟内存, 虚拟地址 通过多级页表 映射物理地址
- 多个虚拟内存可以指向同一个物理地址,虚拟内存的总空间远大于物理内存空间
-
如果把内核空间和用户空间的虚拟地址映射到同一个物理地址,就不需要来回复制数据了
-
mmap系统调⽤函数会直接把内核缓冲区⾥的数据映射到⽤户空间,
-
内核空间和⽤户空间就不需要进⾏数据拷⻉操作,节省了CPU开销
-
函数
- mmap( ) 读取
- write( )写出
-
步骤
- 应用程序先调用mmap()方法,将数据从磁盘拷贝到内核缓冲区,返回结束(DMA负责)
- 再调用write( ), 内核缓冲区的数据直接拷贝到内核socket buffer(CPU负责)
- 然后把内核缓冲区的Socket Buffer给直接拷贝给Socket协议栈 即网卡设备中,返回结束(DMA负责)
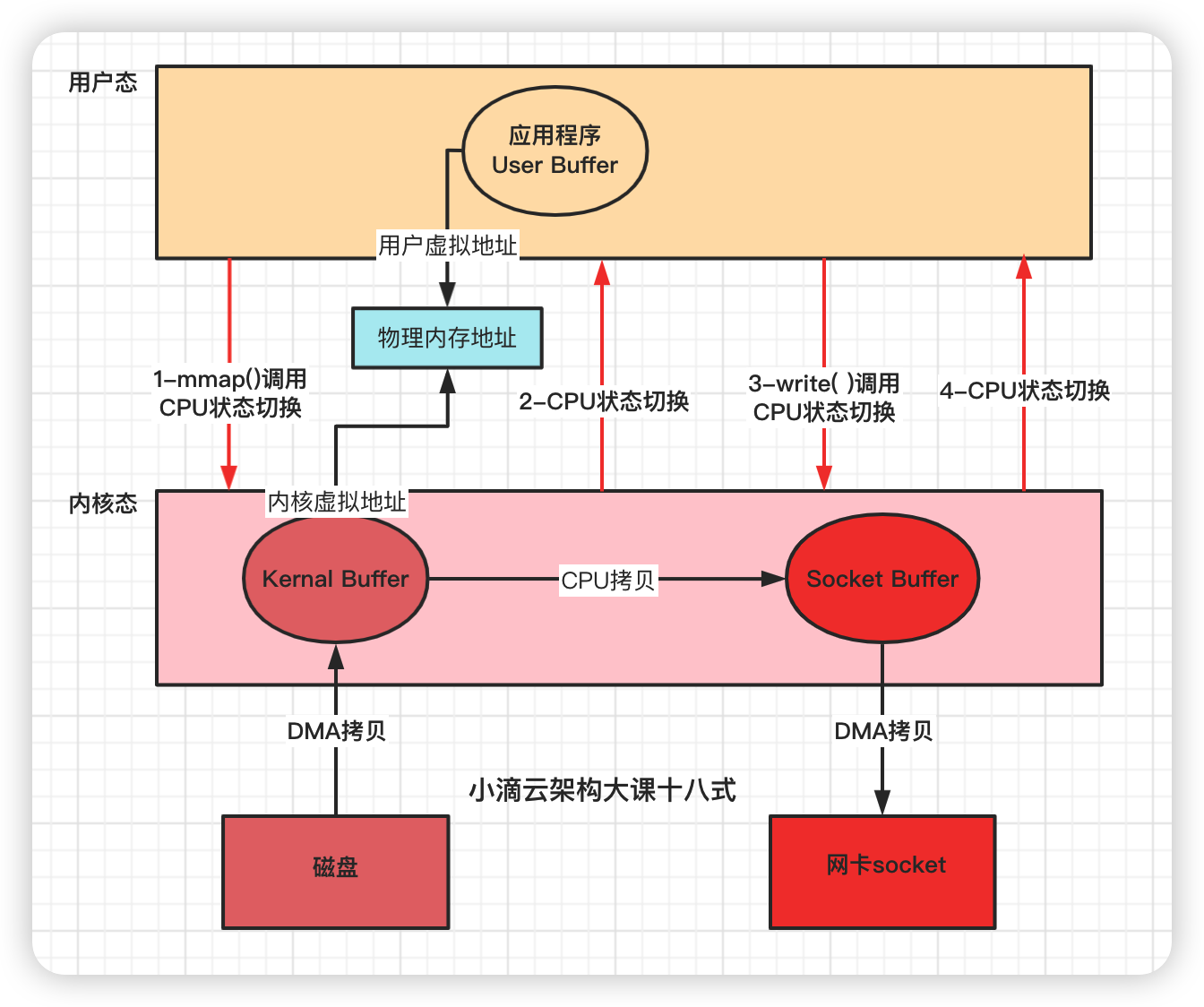
-
损耗
- 没用零拷贝的前,4次CPU上下⽂切换和4次数据拷贝
- 采用mmap后,CPU用户态和内核态上下文切换依旧是4次 和 全程 有 3 次数据拷⻉
- 2次DMA拷贝、1次CPU拷贝、4次内核态用户态切换
- 减少1次CPU拷贝(不是减少两次, 因为内核之间有新增一次拷贝)
ZeroCopy实现方式二 sendfile
-
Linux kernal 2.1新增发送⽂件的**系统调⽤函数 sendfile( ) **
-
替代 read() 和 write() 两个系统调⽤,减少⼀次系统调⽤,即减少 2 次CPU上下⽂切换的开销
-
调用sendfile( ),从磁盘读取到内核缓冲区,然后直接把内核缓冲区的数据拷⻉到 socket buffer缓冲区⾥
-
再把内核缓冲区的Socket Buffer给直接拷贝给Socket协议栈 即网卡设备中)(DMA负责)
-
函数
-
Sendfile( )
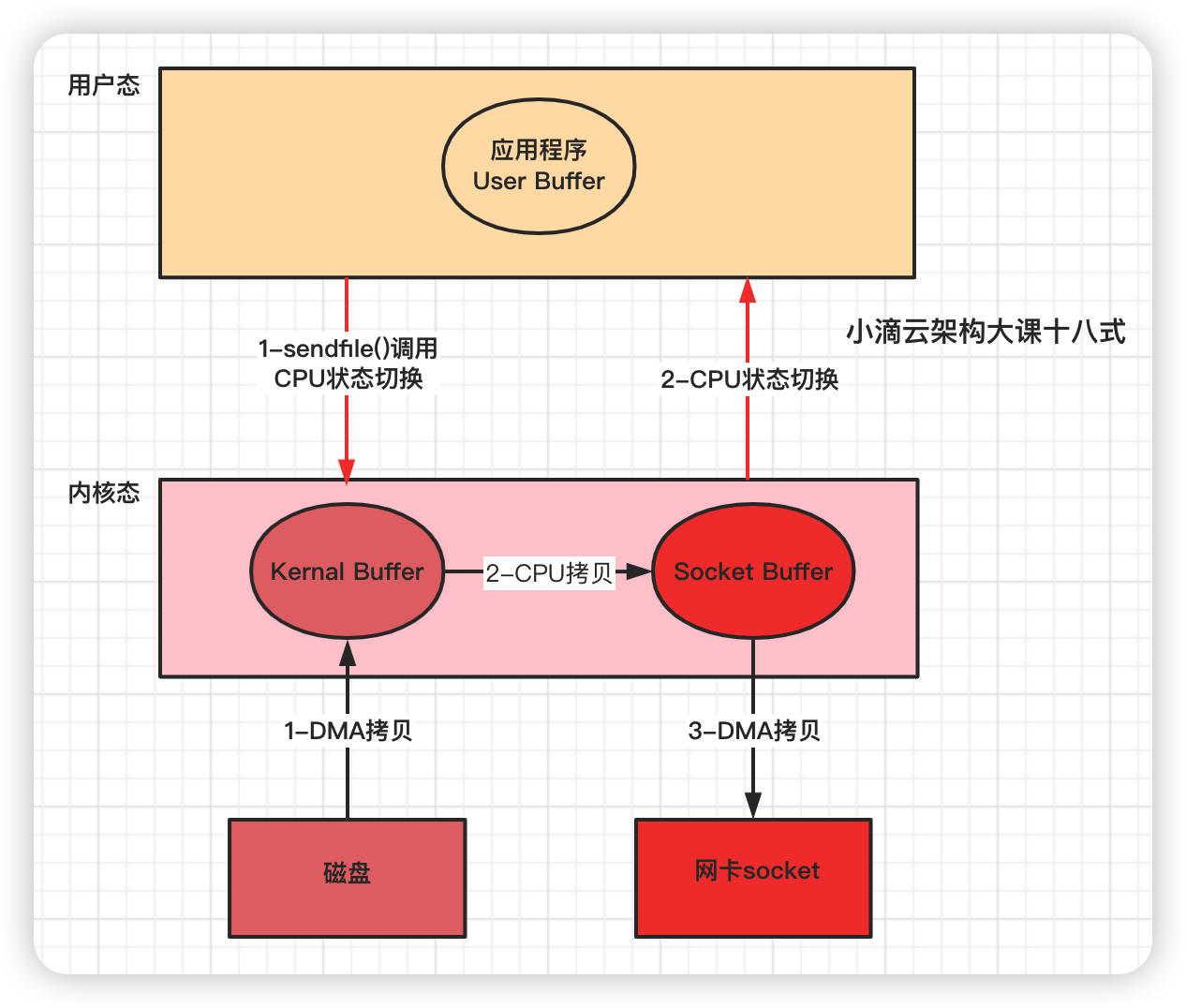
-
-
步骤
- 应用程序先调用sendfile()方法,将数据从磁盘拷贝到内核缓冲区(DMA负责)
- 然后把 内核缓冲区的数据直接拷贝到内核socket buffer(CPU负责)
- 然后把内核缓冲区的Socket Buffer给直接拷贝给Socket协议栈 即网卡设备中,返回结束(DMA负责)
-
损耗
- 没用零拷贝的前,4次CPU上下⽂切换和4次数据拷贝
- 采用sendfile后,CPU用户态和内核态上下文切换是2次 和 全程 有 3 次数据拷⻉
- 2次DMA拷贝、1次cpu拷贝、2次内核态用户态切换
-
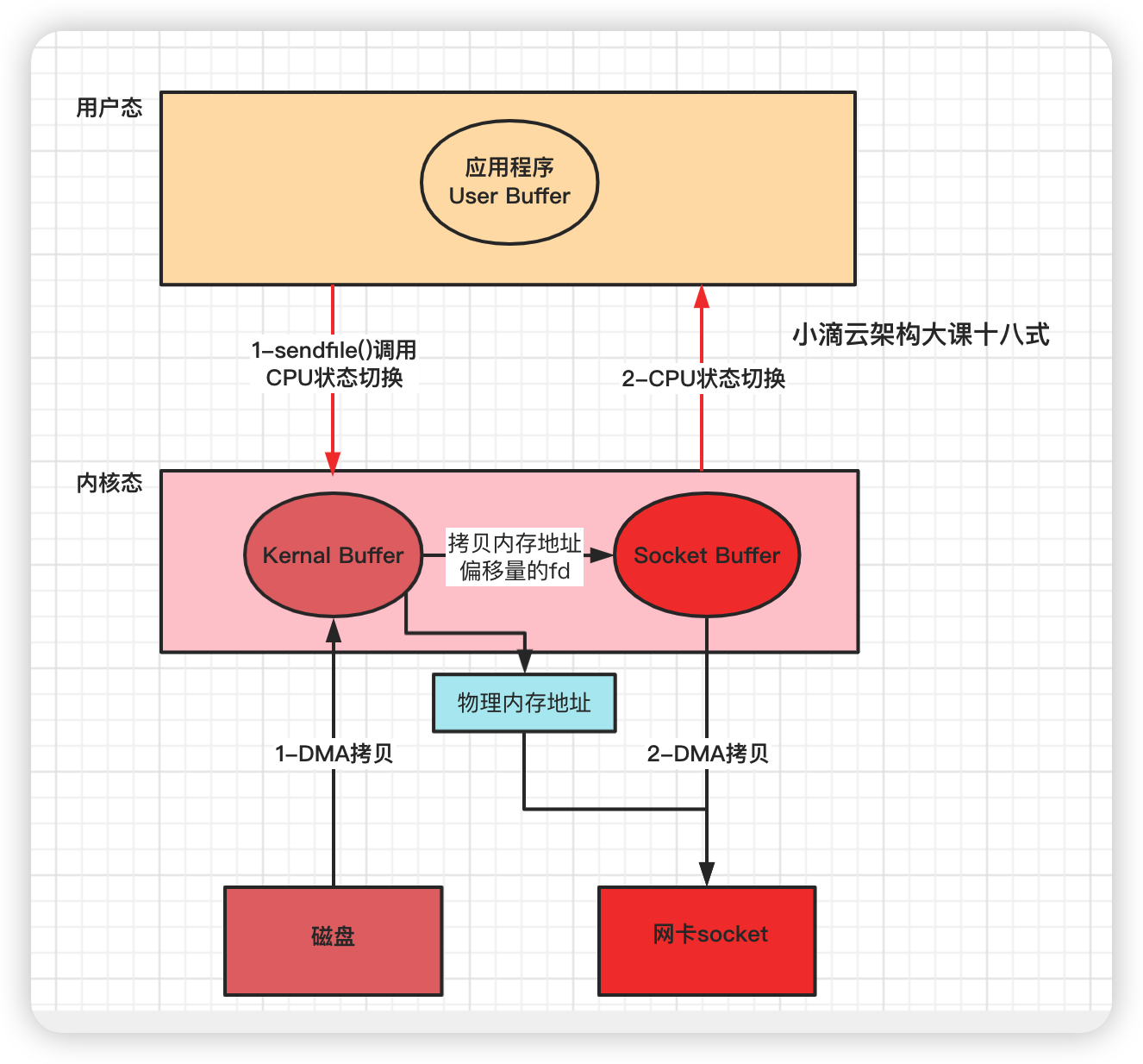
Linux 2.4+ 版本之后改进sendfile, 利用DMA Gather(带有收集功能的DMA),变成了真正的零拷贝(没有CPU Copy)
- 应用程序先调用sendfile()方法,将数据从磁盘拷贝到内核缓冲区(DMA负责)
- 把内存地址、偏移量的缓冲区 fd 描述符 拷贝 到Socket Buffer中去 拷贝很少的数据 可忽略
- 本质和虚拟内存的解决方法思路一样,就是内存地址的记录
- 然后把内核缓冲区的Socket Buffer给直接拷贝给Socket协议栈 即网卡设备中,返回结束(DMA负责)
磁盘IO常见性能指标和分析工具#
iostat#
-
常见磁盘IO性能指标
- 磁盘读写常见指标
-
IOPS(Input/Output Operations per Second)
- 指每秒能处理的I/O个数,表示块存储处理读写(输出/输入)的能力,单位为次,有顺序IOPS和随机IOPS
- 比如100次/秒,那iops就是100次/秒,例如数据库类应用等典型场景重点提升这个指标,下面是阿里云盘性能
-
吞吐量/带宽(Throughput)
- 是指单位时间内可以成功传输的数据数量,单位为MB/s
- 比如 一个硬盘的读写 IO 是 1MB,硬盘的 IOPS 是 100,那么硬盘总的吞吐率就是 100MB/s
- 带宽 = IOPS * IO大小
-
访问时延(Latency)
- 是指IO请求从发出到收到响应的间隔时间,常以毫秒ms或者微妙us为单位
- 硬盘响应时间 = 硬盘访问时间 + IO排队延迟,过高的时延会导致应用性能下降或报错。
- 普通的HDD磁盘,随机IO读写延迟是10毫秒,IO带宽大约100MB/秒,随机IOPS一般在100左右
-
使用率 Utilization
- 指磁盘处理 I/O 的时间百分比,过高的使用率 ,常规字段 Utilization-缩写%util 表示
- 如超过 80%意味着磁盘 I/O 存在性能瓶颈
-
I/O 等待队列长度 Queue Length
- 表示等待处理的 I/O 请求的数目,如果 I/O 请求压力持续超出磁盘处理能力,就会增大队列长度
-
饱和度
- 磁盘处理 I/O 的繁忙程度,过高的饱和度说明磁盘存在严重的性能瓶颈
- 当饱和度为 100% 时,磁盘无法接受新的 I/O 请求
- 注意:使用率和饱和度是完全不同的
- 使用率只考虑有没有IO,不考虑IO的大小;当使用率是100%时,磁盘也可能接收新的IO请求
-
- 磁盘读写常见指标
-
sysstat提供了Linux性能监控的工具集,包括iostat、mpstat、pidstat、sar 等
-
【全局命令】 iostat
- 查看系统综合的磁盘IO情况
- iostat [参数] [时间] [次数]
iostat -p ALL -h - 参数说明
参数 说明 -c 仅显示CPU状态统计信息 -d 仅显示磁盘统计信息 -k 或 -m 以Kb 或 Mb为单位显示,常用 -h 可读性高 -p 指定显示IO的设备,ALL表示显示所有 -x 显示详细信息 - 显示信息,iostat不能直接得到磁盘饱和度

字段 说明 【重要】r/s 每秒发送给磁盘的读请求次数 , r/s+ w/s 是磁盘 IOPS 【重要】w/s 每秒发送给磁盘的写请求次数,r/s+ w/s 是磁盘 IOPS 【重要】rkB/s 每秒从磁盘读取的数据量,rkB/s+wkB/s 是吞吐量 【重要】wkB/s 每秒向磁盘写入的数据量,rkB/s+wkB/s 是吞吐量 【重要】r_await 读请求处理完成等待时间,包括在队列中的等待时间和设备实际处理时间
r_await+w_await ,是RT响应时间【重要】w_await 写请求处理完成等待时间,包括在队列中的等待时间和设备实际处理时间
r_await+w_await ,是RT响应时间【重要】aqu-sz 平均请求队列长度 rareq-sz 平均读请求大小 wareq-sz 平均写请求大小 【重要】%util 磁盘处理I/O的时间百分比,表示的是磁盘的忙碌情况;如果>80% 就是磁盘可能处于忙碌状态
一秒中有百分之多少的时间用于I/O操作,或者说一秒中有多少时间I/O队列是非空的
-
iotop#
-
【局部命令】iotop
- 查看当前系统的各个进程 使用磁盘IO的情况
- 安装
yum install -y iotop iotop -o -d 3每3秒刷新下各个进程磁盘IO情况- 参数
参数 说明 -o 只显示正在读写磁盘的程序 -d 跟一个数值,表示iotop命令刷新的时间 -
显示信息
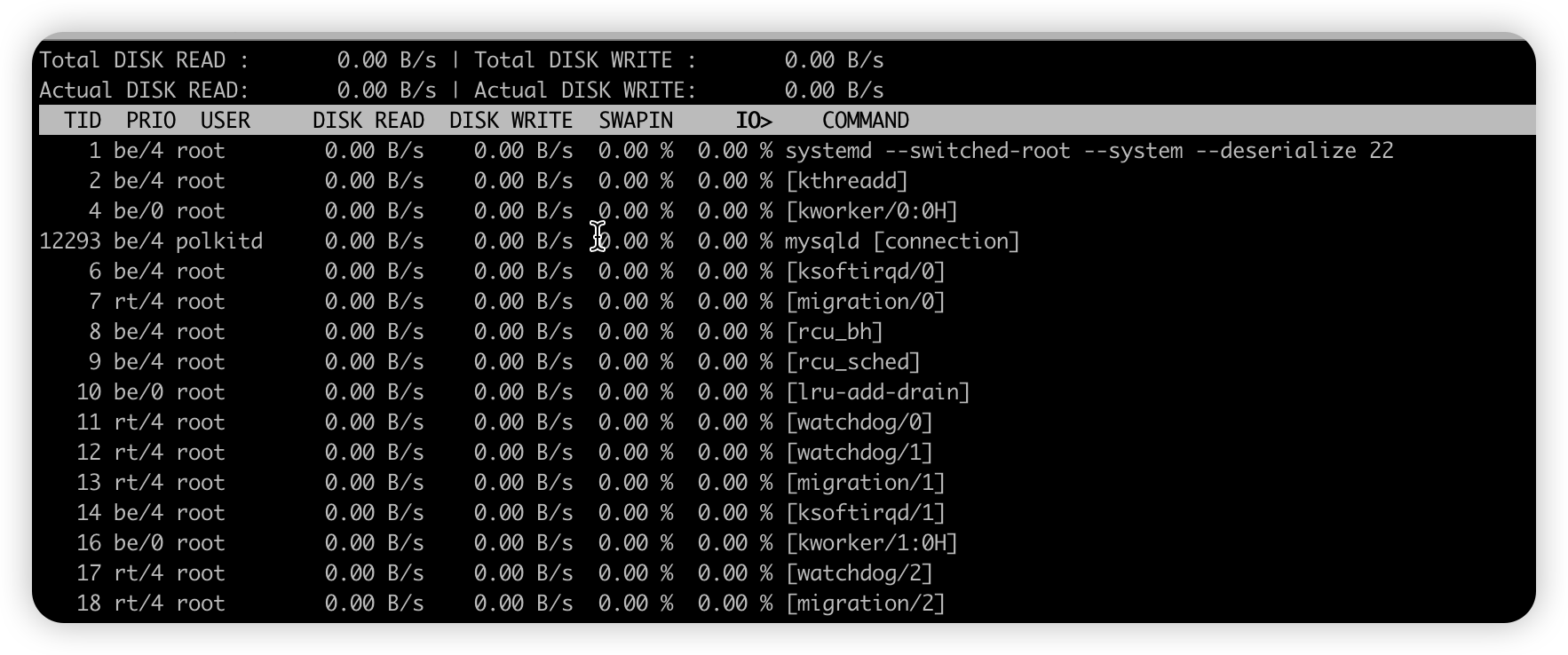
字段 说明 Total DISK READ 从磁盘中读取的总速率 Total DISK WRITE 往磁盘里写入的总速率 Actual DISK READ 从磁盘中读取的实际速率 Actual DISK WRITE 往磁盘里写入的实际速率 TID 线程ID,按 p 可以转换成进程ID PRIO 优先级 USER 线程所有者 DISK READ 进程从磁盘中读取的速率 DISK WRITE 进程往磁盘里写入的速率 SWAPIN 进程swap交换百分比 IO> IO等待所占用的百分比 COMMAND 具体的进程命令 -
总结
-
【全局】iostat是系统级别的IO监控
-
【局部】iotop是进程级别IO监控
-
-
案例测试 :模拟IO密集型应用,系统是4核
- 终端一 模拟2个磁盘IO进程, 持续600s
stress --hdd 2 --hdd-bytes 6G --timeout 600s - 终端二 全局
iostat -d -x 1 - 终端三 全局
top - 终端四 局部
iotop
- 终端一 模拟2个磁盘IO进程, 持续600s
深入理解计算机网络#
19 基础
20洪水入侵案例
21生产问题分析
22网络IO AIO NIO AIO 讲解
23DNS - 智能DNS案例
24 HTTPq浅浅解析
计算机网络分层结构#
分层模型介绍#
-
OSI 七层模型 Open System Interconnection 七层模型
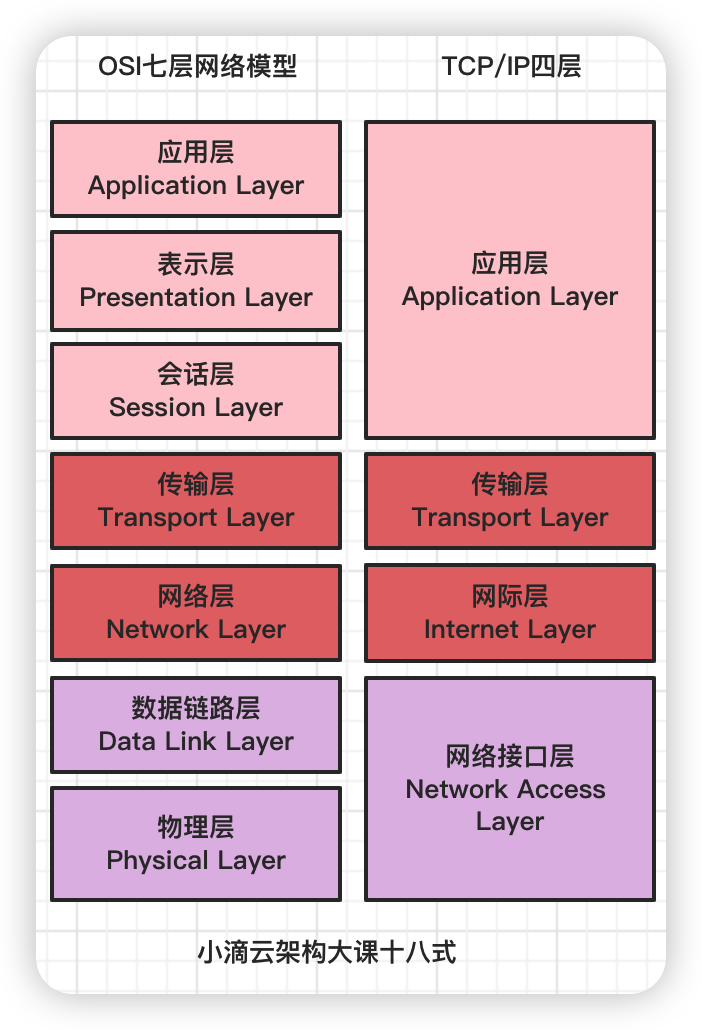
-
TCP/IP 四层模型 Transmission Control Protocol/Internet Protocol)四层模型
- 应用层:负责应用程序之间的沟通,如 HTTP、FTP、DNS 等
- 传输层:负责两台主机之间的数据传输,端到端通信,如 TCP、UDP 等
- 网际层:负责网络包的封装、寻址和路由,如 IP 等
- 网络接口层:负责网络包在物理网络中的传输,如 MAC 寻址转化、通过网卡传输网络数据帧等
-
为什么要分层,如果你说网络设计者会如何设计?
- 不分层
- 应用程序从把数据转为01二进制,写代码操作网卡发送数据
- 写代码处理建立网络连接、网络寻址、可靠性传输、失败重传巴拉巴拉。。。。
- 分层
- 每层分工明确,利用单一职责模式和责任链模式
- 开发人员 负责 编写应用层 业务代码
- 操作系统 负责 建立网络连接、可靠性传输
- 交换机路由器 负责 物理媒介上传输二进制格式
- 不分层
-
日常编写代码一样( Controller- Service-Dao)
- 高内聚: 类的每个成员方法只完成一件事(最大限度的聚合,模块内部代码之间的联系越强,内聚就越高, 模块的独立性就越好
- 低耦合: 减少类内部,一个成员方法调用另一个成员方法, 不要有牵一发动全身
-
套娃一样的封装数据包,比如TCP协议是封装在IP数据包中
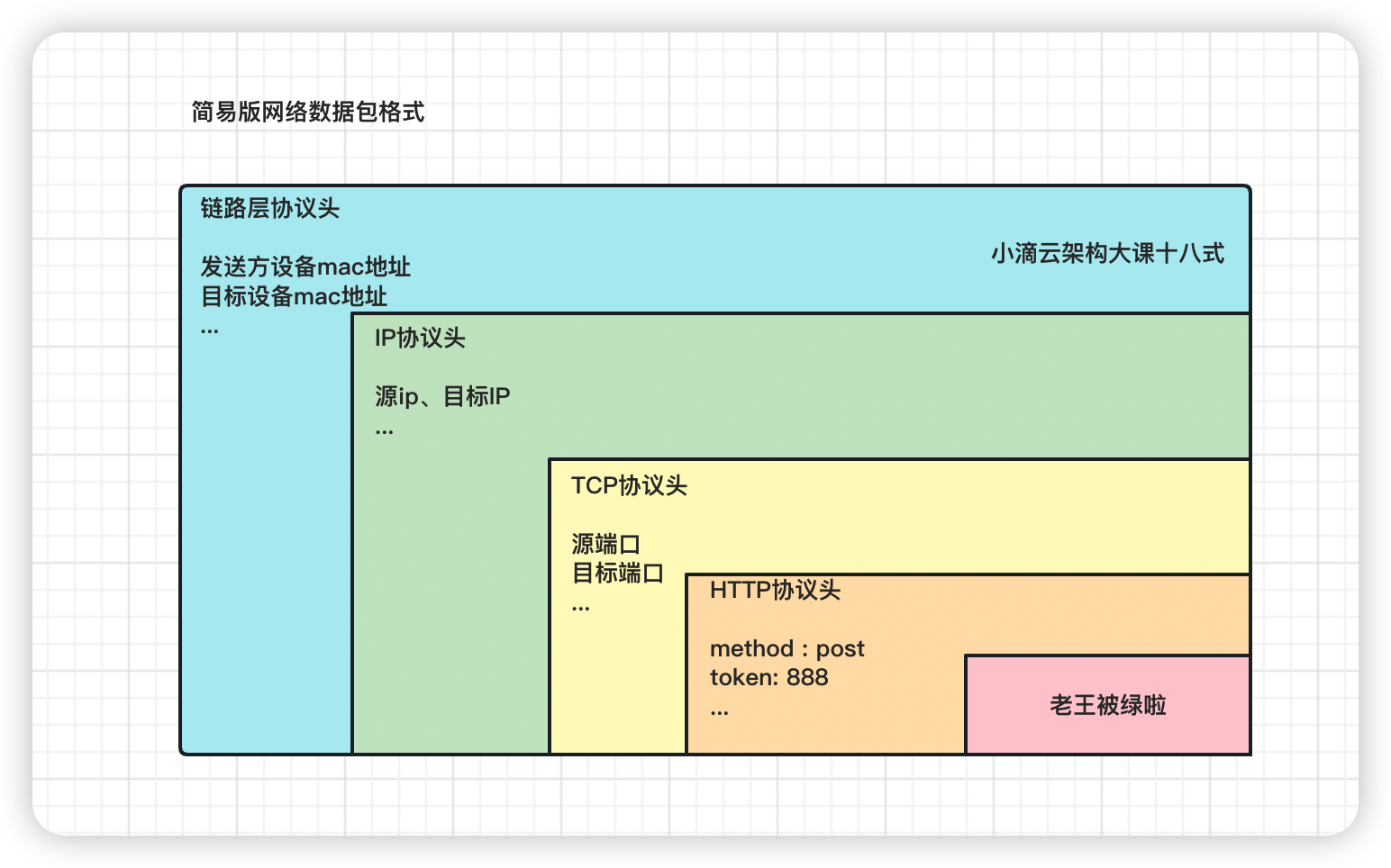
-
总结:网络分层方便 使用、管理、维护,每层支持的协议不一样,应用场景也不一样
-
OSI 七层模型和TCP/IP 四层模型 两个模型哪个更好?
-
两个模型各有各的好,前者更详细,后者容易理解
-
例子
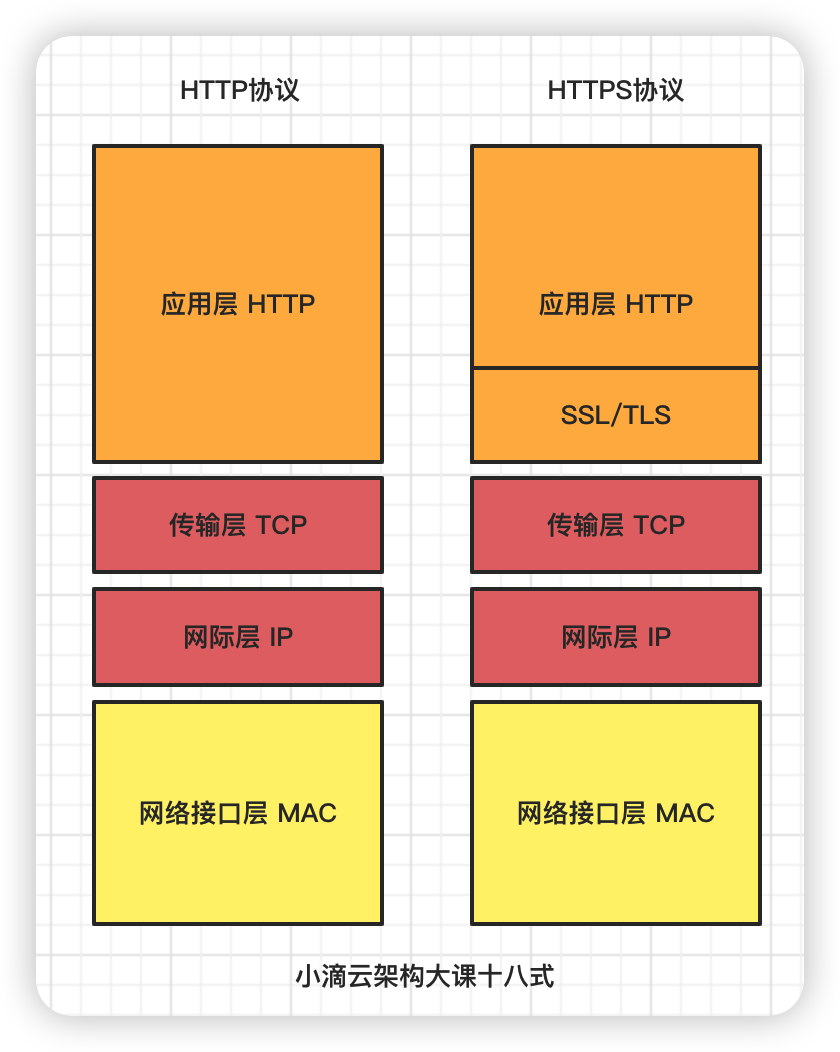
- TCP/IP 四层模型 网络加密传输
- HTTPS 在 HTTP 与 TCP 层之间加⼊了 SSL/TLS 协议
-
OSI 七层模型 高并发下的负载均衡
-
F5、LVS(四层负载均衡 )
- 用虚拟ip+port接收请求,再转发到对应的真实机器(仅做分发作用,没有流量产生)
- 基于IP报文的负载均衡,不解析协议,性能强,对内存和cpu资源消耗比较低
- 根据负载均衡设备,把请求转发到后端对应的IP+端口,比较粗粒度
-
HAproxy、Nginx(七层负载均衡)
- 用虚拟的url或主机名接收请求,再转向相应的处理服务器
- 需要解析协议,根据报头内的信息来执行负载均衡任务,占用的系统资源对内存和cpu资源消耗较高
- 在四层基础上,可以根据应用层的特征(URL/浏览器/Cookie 等)进一步决定如何去转发流量
-
- TCP/IP 四层模型 网络加密传输
-
协议和传输#
简介: 大白话网络分层下的协议和传输
- 网络分层模型和主要协议
- 网络分层模型下,数据在各层之间的传输
- 类似寄快递,中转站一层层分发,省->市->县->区->村->房号->具体联系人
- 发送数据包
- 在网络协议栈中从上到下逐层处理,最终送到网卡发送出去
- 接收数据包
- 需要经过网络协议栈从下到上的逐层处理,最后送到应用程序中使用
- 注意
- 应用层是直接面向用户的一层,为应用程序提供统一协议的接口,但不是应用程序
- 目的是保障不同类型的应用采用的低层通信协议是一致的
-
很多同学疑惑:传输层协议和网际层协议有什么区别?
-
网际层协议负责提供主机间的逻辑通信;
- 互联网上N多台设备,通过IP地址识别通信主机,网络层可以具体定位到哪台设备
- 网络层的只检验IP数据报首部中的校验和字段是否出现差错,而不检查数据部分
-
传输层协议负责提供进程间的逻辑通信
- 一个主机上N多进程,通过端口号识别应用层进程,传输层可以具体定位到哪个进程
- 需要对收到的报文更进一步进行差错检测
-
生活中例子
- 老王住在北京合租,冰冰和Anna住在在广州合租,圣诞节快到了,老王给冰冰买了一箱冰棍
- 快递中转站 把包裹 从北京投递广州,就是网际层,只看大体的地址
- 冰冰家附近的快递小哥,看详细地址和电话号码把包裹给到冰冰,避免给到Anna,就是传输层,再进一步看地址
- 实体
- 主机 = 不同城市的房子
- 进程 = 合租房子里面的Anna和冰冰
- 应用程序消息 = 一箱冰棍
- 传输层协议 = 本地快递小哥
- 网络层协议 = 快递中转站
-
-
问题
- 网络模型的各层协议主要用处?
- 那么多协议是否都要详细掌握?
-
原则(二八原则,掌握工作里面最多用的网络层次和协议)
- 常用网络层次和协议
- 应用层:HTTP、HTTPS
- 传输层:TCP、UDP
- 网络层:IP
- 常用网络层次和协议
网络层核心知识和常见概念#
-
网络层中的最重要的协议,IP协议(Internet Protocol)
- 是一种工作在网际层的网络协议,定义如何将数据包从一台计算机传输到另一台计算机
- 提供一种通用的方法来在网络中传输数据,提供不可靠、无连接的传送服务
- App发送请求,达到运营服务商的交换机,交换机根据IP地址再进行路由转发(多次),最后达到目标服务器
- 网络各层作用不一样,IP协议用途是把数据包投递过去
- IP协议没这个机制,不确保数据一定送达,可以用传输层TCP协议的机制做可靠性传输
- IP协议是其他协议的基础,比如TCP协议和UDP协议
-
用途
-
寻址和路由
- IP数据报中有源IP地址和目的IP地址,表示数据包的源主机和目标主机
- 数据报在传输过程中,每个中间的网络节点比如IP网关/路由器等,都只根据网络地址来进行转发,直到目标主机
-
分片和重组
- 数据报传输过程中会经过不同的网络,不同的网络环境中数据报的最大长度限制是不同的
- 通过给每个IP数据报分配一个标识符和分段组装信息,可以让数据报在不同的网络中能够被传输
- 被分段后的IP数据报可以独立在网络中进行转发,在达到目标主机后由目标主机完成重组工作,恢复成原来的IP数据报
-
-
网络层相关协议
- IP协议(Internet Protocol,因特网互联协议);
- ICMP协议(Internet Control Message Protocol,因特网控制报文协议)
- ARP协议(Address Resolution Protocol,地址解析协议)
- RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)
-
IP 地址有哪些分类
- ip地址由4个小段,每个小段由8个bit,即四个字节组成共32位(便于记忆 采用4个十进制数来表示一个IP地址)
- 例如192.168.0.0 (二进制1100 0000, 1010 0000, 0000 0000, 0000 0000)
- IP 地址 =
- 网络号:属于互联网的哪一个网络
- 主机号:属于该网络中的哪一台主机
类别 描述(商业应用中只用到A、B、C三类) A类 0开头,前8为网络号,后24位的主机号;即0.0.0.0到127.255.255.255 B类 10开头,前16为网络号,后16位的主机号;即128.0.0.0到191.255.255.255 C类 110开头,前24为网络号,后8位的主机号,即192.0.0.0到223.255.255.255 D和E类 留作未来社会的应用,或做一些实验用到 - 全球现有的IPv4地址一共有2的32次方个,估算约为42.9亿个,除去一些特用的IP和一些不能用的IP,剩下可用的不到40亿
- ip地址由4个小段,每个小段由8个bit,即四个字节组成共32位(便于记忆 采用4个十进制数来表示一个IP地址)
-
IPv4不够用怎么办?
- DHCP技术
- 动态主机配置协议,动态分配IP地址,只给接入网络的设备分配IP地址
- 同一个MAC地址的设备,每次接入互联网时,得到的IP地址可能不一样
- NAT
- 网络地址转换协议,不同局域网的主机可以使用相同的IP地址,一定程度上缓解了IP资源枯竭的问题,
- 局域网中使用的IP地址是不能在公网中使用,当局域网主机想要与公网主机进行通信时,将主机IP地址转换为全球IP地址
- 原理
- 从局域网出去的IP数据报,将其IP地址替换为NAT服务器拥有的合法的公共IP地址,并将替换关系记录到NAT映射表;
- 从公共互联网返回IP数据报,根据目的IP地址查找NAT映射表,把内部局域网IP地址替换目的IP地址,转发到内部网络。
- IPV6
- 作为接替IPv4的下一代互联网协议,可以实现2的128次方个地址,
- 即使给地球上每一粒沙子都分配一个IP地址也够用,从根本上解决IPv4地址不够用的问题
- DHCP技术
-
常用概念
-
MAC地址(Media Access Control Address)
- 用来定义网络设备的位置,也叫硬件地址,每一个电脑设备都拥有唯一的MAC地址共48位,使用十六进制表示
- MAC地址在世界是唯一的,通常表示为12个16进制数,如:00-16-EA-AE-3C-40就是一个MAC地址
-
ARP协议
- Address Resolution Protocol,地址解析协议,实现 IP 地址到 MAC 地址的映射,ARP表是自动建立,不需要配置
- 为网卡的IP地址到对应的硬件地址提供动态映射, 把网络层32位地址转化为数据链路层MAC的48位地址。
IP地址 Mac地址 192.168.12.4 00-16-3e-14-c4-4d 192.168.93.12 00-16-EA-AE-3C-40 192.168.43.42 00-16-h6-G2-6A-03 -
RARP协议
- Reverse Address Resolution Protocol 逆地址解析协议,把数据链路层MAC的48位地址 转化为 网络层32位地址
-
-
IP和Mac的区别
-
MAC地址是数据链路层和物理层使用的地址,写在网卡上的物理地址,不可变更。
-
IP地址是网络层使用的地址,是一种逻辑地址,用来区别网络上的计算机
-
只使用MAC地址是否可以??
-
路由器记住每个MAC地址,MAC地址的长度为48位,最多共有2的48次方个MAC地址,每个路由器需要256T来存储
-
当设备连入网络时 还没有IP地址的时,根据MAC地址来区分不同的设备
-
生活例子
-
身份证是每个人一直不变的
-
在哪个城市工作需要办理居住证
-
-
-
传输层核心知识 TCP和UDP#
-
传输层
-
网络层把数据发到对应的节点,传输层则 进一步 将数据可靠地传送到对应的端口
-
使用端口区分不同的进程,信息传送的协议数据单元称为段或报文
-
主要的协议:TCP和UDP
-
-
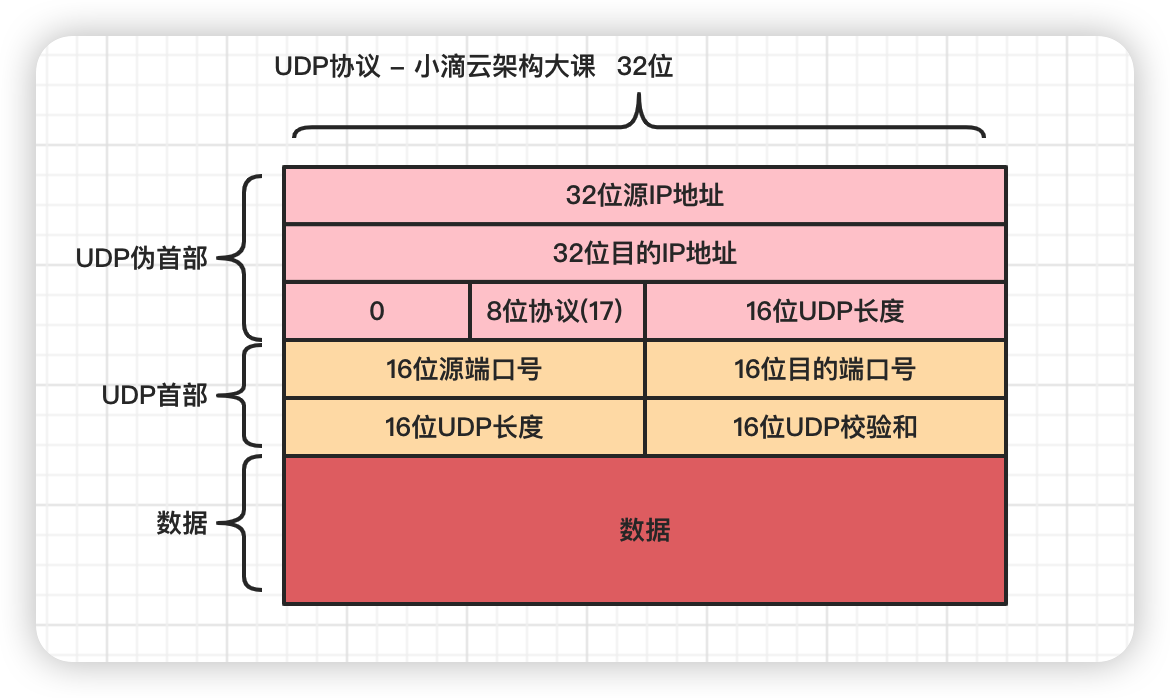
UDP协议 (User Datagram Protocol 用户数据报协议)
- 面向无连接的协议,它不需要建立连接,就可以发送数据
- 协议不需要握手,因此发送数据的速度更快,传输效率更高。
- 不提供可靠性,因为它不会检查发送的数据是否损坏或丢失,所以可能会发生数据丢失或损坏的情况。
- 支持多种应用,如视频会议、在线游戏等,它可以提供实时性和可靠性
-
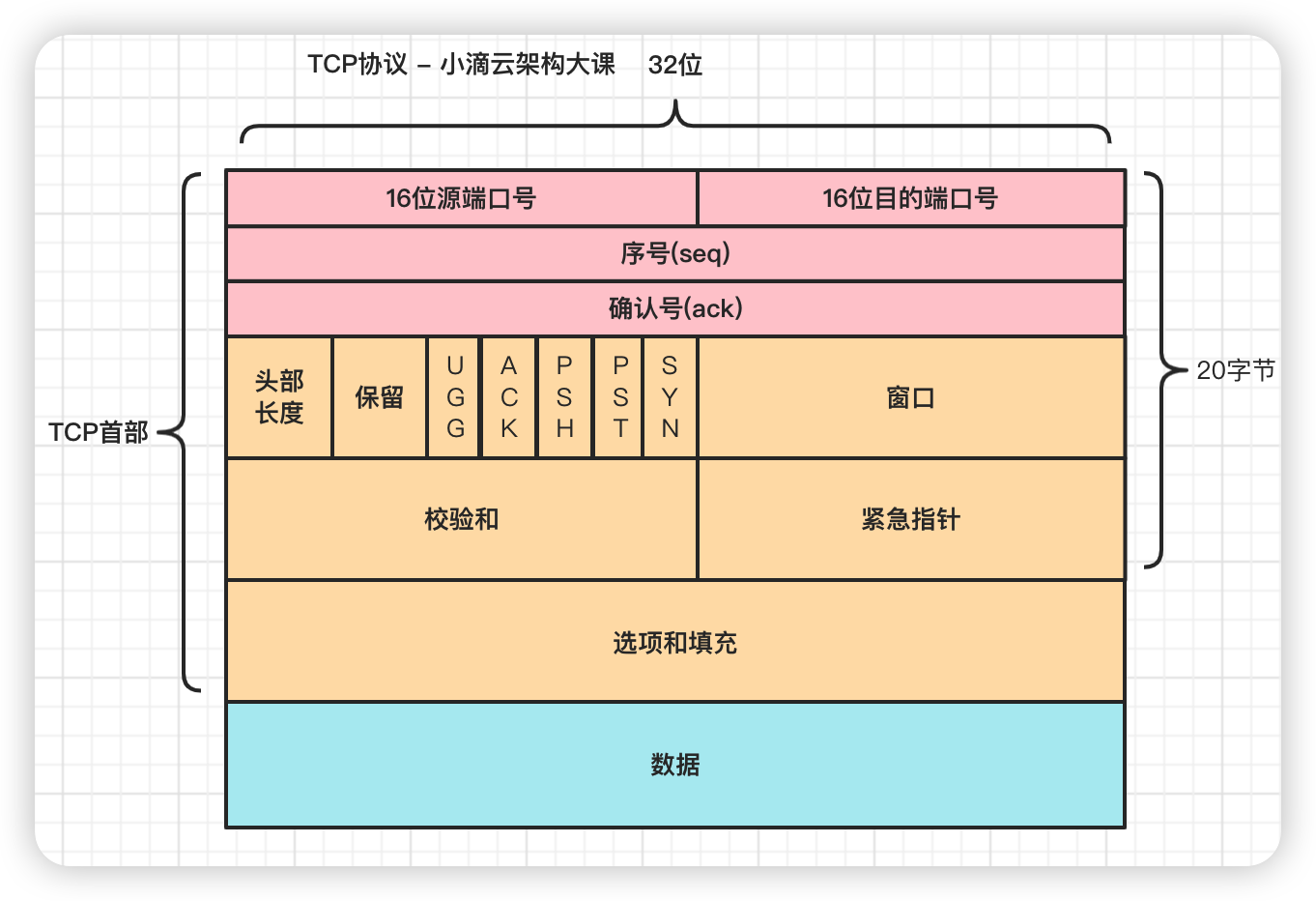
TCP协议 (Transmission Control Protocol 传输控制协议) 重点掌握
-
面向连接:TCP是面向连接的协议,在正式收发数据前,必须建立可靠的连接
-
可靠性:TCP协议提供了丰富的可靠性机制,如检验和、确认和重传等,来保证数据的正确性。
-
流量控制:提供了流量控制机制,可以防止发送方发送数据速度过快,从而使接收方来不及处理,从而确保网络的稳定性。
-
拥塞控制:提供了拥塞控制机制,可以防止网络拥塞,从而提高网络的吞吐量
-
常用于传输文件、电子邮件、FTP等服务,能够校验数据的完整性,以保证数据不被破坏
-
协议部分解析
- 源端口号:报文的发送端口
- 目的端口号:报文的接收端口
- 序号(seq):在TCP传送的数据流都有一个序号
- 在SYN标志是1时,表示初始发送的序列号
- 确认号(ack):期望收到对方下次发送的数据的第一个字节的序号,是上次已成功收到数据字节序号+1
- 例如发送确认号为1001,则表示前1000个字节已经被确认接收
- 标志位(控制位,方便后续了解TCP三次握手)
- URG (urgent紧急,很少用)
- 当URG=1时,此报文应尽快传送
- RST (reset重置)
- 重置复位标志,用于复位对应的TCP连接
- RST一般是在FIN之后才会出现为1的情况,表示的是连接重置
- FIN (finish结束)
- 结束标志,用于结束一个TCP会话,释放连接
- PSH (push传送)
- 指数据包到达接收端以后,不对其进行队列处理,尽快把数据交给应用程序处理
- 常规数据发送流程
- 主机发送数据时,会放在TCP缓冲区中,直到该段达到一定大小,然后发送到接收器
- 当段到达接收端时,被放置在TCP传入缓冲器中,会等待直到其他段到达,完成后数据就被传递到应用层
- 这种设计保证数据传输尽可能高效,将它们组合成一个或多个较大的片段,节省时间和带宽
- 上述流程大多数情况下是没问题的,但是有些则需要尽快处理,所以有这个标识位
- ACK (acknowledgement 确认)
- 确认标志,1表示确认收到请求,0表示未确认
- SYN( 同步序列编号Synchronize Sequence Numbers)
- SYN标志位和ACK标志位搭配使用,用来建立连接
- 当连接请求的时候,SYN=1,ACK=0,代表连接开始但是未获得响应
- 当连接被响应的时候,标志位中ACK会置为1 代表确认收到连接请求,变成了SYN=1,ACK=1
- SYN与FIN不会同时为1的,因为前者 表示的是建立连接,而后者表示的是断开连接
- URG (urgent紧急,很少用)
-
拓展
-
如何确定一个唯一的TCP连接?
- TCP四元组: 源IP地址、源端口、目的ip、目的端口
- 有地方也说五元组: 传输协议类型、源IP地址、源端口、目的ip、目的端口,协议如果是TCP则默认不加
-
-
底层传输数据包大小计算和MTU-MSS介绍#
简介: 底层传输数据包大小计算和MTU-MSS介绍
-
背景
- 前面了解了网络多层模型知识,每层的叫法会有区别
- 问题:TCP和UDP每次能够传输的最大长度是多少?
-
回答上述问题,需要知道什么是MTU和MSS
-
MTU(Maximum Transmission Unit)
- 是指在网络中,单个数据包能够传输的最大字节数,数据链路层提供给上层网络层最大一次传输大小
- 是网络设备(如路由器)在处理数据包时所能支持的最大封装单元大小(不同网卡的MTU也不一样,物理接口限制)
- 以太网数据链路层中约定的数据载荷部分最大长度,数据不超过它时就无需分片
- MTU值越大传输的速率就越快,但也会增加网络的延迟
- 数据包从发送端传输到接收端,要经过多个网络,每条网络的MTU都可能不一样,通信过程中最小的MTU称为路径MTU
- 类似木桶效应,装水容量被最短的决定
-
MSS(Max Segment Size,是TCP最大报文段大小)
- 是一个TCP报文段中包含的最大字节,传输层TCP提交给网络层最大分段大小
- TCP在传送大量数据时以MSS的大小将数据进行分割发送,重发时也是以MSS为单位。
- MSS的值由发送端和接收端在建立连接时在TCP报文中进行协商得到的,它的值受到网络中MTU(最大传输单元)的限制。
- 两端主机在在三次握手发出建立连接的请求时,会在TCP首部中写入MSS选项,告诉对方自己的接口能够适应的MSS的大小,然后在两者之间选择一个较小的值进行使用
- MSS = MTU - IP header头大小 - TCP 头大小
- TCP的MSS最大值是:以太网MSS=1500(MTU)-20(IP首部长度)-20(TCP首部大小)=1460字节
-
总结
-
MTU是指单次数据传输中可以传输的最大字节数,是由网络设备的硬件限制决定的,通常是1500字节。
-
MSS是指TCP传输数据报文中,由TCP首部和数据构成的部分的最大字节数,是由MTU和TCP首部长度决定的
-
一般情况下MSS = MTU - IP header头大小 - TCP 头大小,通常是1460字节。
-
MTU是网络传输最大报文包,MSS是网络传输数据最大值
- 好比快递包裹:100克的快递箱最多装900克商品,总重量1000克就是MTU,900克商品就是MSS
-
-
-
问题:TCP和UDP每次能够传输的最大长度是多少?
- 以太网数据包(packet)的大小是固定1522字节
- 其中22字节是头信息(head), 1500 字节是负载(payload)
- IP 数据包在以太网数据包的负载里面,它也有自己的头信息20字节,所以 IP 数据包的负载最多为1480字节
- TCP 数据包在 IP 数据包的负载里面,它的头信息最少也需要20字节,所以 TCP 数据包的最大负载是 1480 - 20 = 1460 字节
- 但 IP 和 TCP 协议往往有额外的头信息,所以 TCP 负载实际为1400字节左右
- UDP 数据包每次能够传输的最大长度 MSS = MTU(1500B)- IP头(20B) - UDP头(8B) = 1472(Bytes)
- TCP 数据包每次能够传输的最大长度 MSS = MTU(1500B) - IP头(20B) - TCP头(20B) = 1460 (Bytes)
- 以太网数据包(packet)的大小是固定1522字节
-
发送10MB数据包,最终应用程序是怎样获取数据的?
-
假如发送一个 10MB 的文件,因为一个包最多1400字节,就必须分成多个包,起码需要发送7100多个包
- 注意:数据包大小在不同协议不一样,HTTP/2对比HTTP/1有优化压缩 HTTP协议的头信息
-
服务器的操作系统会把收集的数据包组装完成,根据TCP包的端口转给应用程序,应用程序不用关心数据通信的细节
-
带来了进一步的问题
-
服务器发送数据包 越快越好,但是由于各种因素,比如带宽小、线路不稳定,导致了丢包严重,怎么解决?
-
接下去就是学习TCP的可靠性传输机制!!!面试特别高频
-
-
ifconfig#
-
掌握些常见的网络性能指标,从不同的方面来度量计算机网络的性能
-
前置知识:
- 比特是计算机中的数据量单位,一个比特是一个1或一个0
- 1Byte(字节)=8bit(比特) 字节的简写为B,比特简写为b
- 小写b和大写B分别对应大小单位bit(比特)和byte(字节)
-
速率
- 连接在计算机网络上的主机在数字信道上传送比特的速率,也称为比特率或速率
- 单位:bit/s(b/s,bps) 或 kb/s = 10³ b/s(小写k指10³)
- 案例
- 假如 数据块大小 100MB,网卡发送速率是100Mbps,发送时间大体是 8秒多
- 100MB*8 / 100Mbps 约等于 8秒, 特别注意:1/8(B/s)=b/s,即1B=8bit,平时计算需要单位换算
-
带宽
- 网络通信线路所能传送数据的能力,在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”,单位同速率也是bps
- 案例
- 老王家里带宽为800M,是指800Mbps或800Mb/s,真实速度其实要在带宽的基础上除以8即,800Mbps/8=100M/s
- 用户在网上下载时显示的速率单位往往是Byte(字节)/s(秒),注意是大写字母B,字节和比特之间的关系为1Byte=8Bits;
-
吞吐量
- 单位时间内通过某个网络(或信道、接口)的实际的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)
- 吞吐量受带宽限制,吞吐量 / 带宽,就是该网络的使用率
- 常用的网络吞吐率的单位有
- PPS(即每秒发送多少个分组数据包)Packet Per Second(包 / 秒)表示以网络包为单位的传输速率
- 云服务器实例每秒最多可以处理的网络数据包数量(包括收发包两个方向)
- 网络收发包用于衡量云服务器的网络质量,PPS数值越大网络性能越好
- BPS(Bytes Per Second)即每秒发送多少字节
- bPS (bits Per Second )即每秒发送多少比特
- PPS(即每秒发送多少个分组数据包)Packet Per Second(包 / 秒)表示以网络包为单位的传输速率
-
时延
- 指数据(一个报文或分组,甚至比特)从网络的一端传送到另一端所需的时间
- 源主机和目的主机之间路径会由多个链路和多个路由器组成,网络时延主要由 发送+传播+处理时延组成
-
往返时间RTT
- 从源主机发送信号到目标主机,目标主机接收信号再返回到源主机所需要时间(一个来回)
-
丢包率
- 丢包率即分组丢失率,是指在一定的时间范围内,传输过程中丢失的分组数量与总分组数量的比率。
- 场景 :老王打王者荣耀游戏时丢包造成游戏卡顿
-
-
ifconfig命令(宏观命令)
- 展示网络信息和网卡接口收发数据包的统计信息
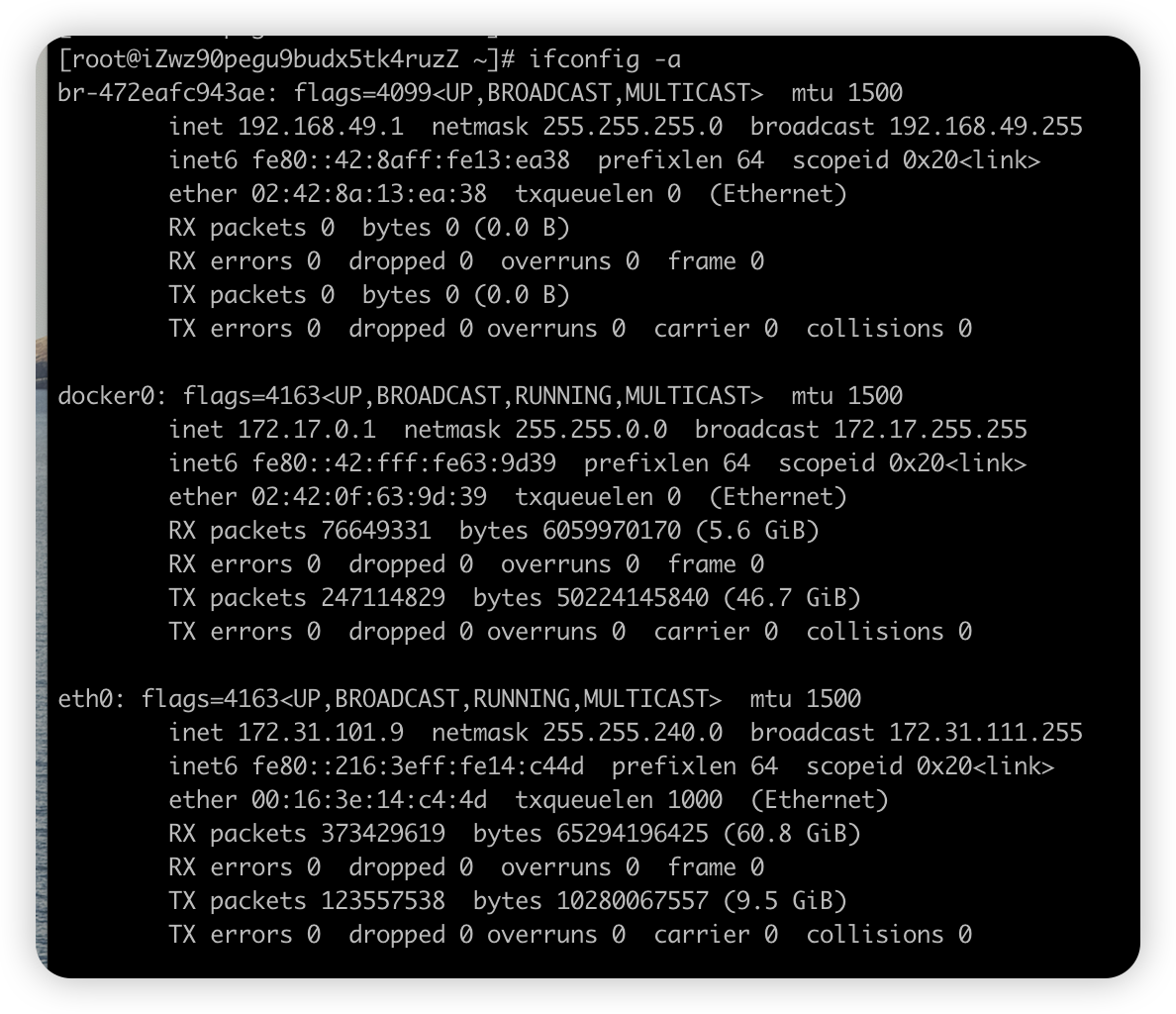
字段 说明 flags=4163<UP,BROADCAST,RUNNING,MULTICAST> RUNNING 表示物理网络是连通的,网卡已连接到交换机或路由器。如果没有,通常表示网线被拔掉 mtu 最大的传输单元,默认大小是 1500 inet ipv4地址,ECS实例绑定弹性公网IP(EIP)后,操作系统中只显示私网IP地址,不显示EIP的公网IP地址
公网IP存在于网关设备,并不在ECS实例的网卡上,所以在操作系统内看不到公网IP,只能看到网卡上的私网IPnetmask 子网的掩码 broadcast 广播地址 ether mac地址 RX,TX 接收和发送的数据包的个数 或 字节数 packets 包数 bytes 字节数 errors 表示发生错误的数据包数,比如校验错误等 dropped 表示丢弃的数据包数 overruns 表示超限数据包数,网络 I/O 速度过快,数据包来不及处理而导致的丢包 carrier 表示发生 carrirer 错误的数据包数,比如物理电缆出现问题等 collisions 表示碰撞数据包数
netstat#
简介: 网络统计分析命令netstat和网络连接状态
-
netstat命令
- 内核中访问网络及相关信息的命令,显示与IP、TCP、UDP和ICMP协议相关的统计数据,检验本机各端口的网络连接情况
参数 说明 -r --route,显示路由表信息 -n -n选项禁用域名解析功能,默认情况下netstat会通过反向域名解析技术查找每个ip地址对应的主机名 -s --statistics,按照每个协议来分类进行统计 -p --programs,与链接相关程序名和进程的PID -l --listening,显示所有监听的端口 -a -all,显示所有链接和监听端口 -u --udp 显示UDP传输协议的连接状况 -t --tcp 显示TCP传输协议的连接状况 -i --interfaces,显示网卡界面信息 -
应用场景
- netstat -anp :显示系统端口使用和进程情况
- netstat -anp |grep 端口 :显示指定系统端口使用和进程情况
- netstat -nupl:UDP类型的端口
- netstat -ntpl:TCP类型的端口
- netstat -na|grep ESTABLISHED|wc -l:统计已连接上的,状态为"established"
- netstat -l:只显示所有监听端口
- netstat -lt:只显示所有监听tcp端口
- netstat -anp :显示系统端口使用和进程情况
-
命令
netstat -atnlp
字段 说明 Proto 协议名 tcp协议 或 udp协议 recv-Q 网络接收队列,表示收到的数据已经在本地接收缓冲,但还有多少没有被进程取走 send-Q 网络发送队列,发送队列不能很快清零,则可能是有应用向外发送数据包过快,或对方接收数据包不够快 Local Address 表示本地IP地址
:::port 表示对外开放的IPv6端口,外网可访问,::: 这三个冒号:中,
前两个"::"是"0:0:0:0:0:0:0:0"的缩写,表示IPv6的"0.0.0.0",第三个冒号:是IP和端口的分隔符
如127.0.0.1:port 表示只能本机访问的端口,外网无法访问;
如0.0.0.0:port 表示对外开放的IPv4端口,外网可访问
如为0.0.0.0:* 则表示没有对外开放;
如是 ::😗 表示对外开放Foreign Address 表示远程IP地址,显示规则与 Local Address 相同, 一般都是0.0.0.0:(IPv4) 和 :::(IPv6)。 State 链路状态 有11种,TCP连接建立的三次握手和TCP连接断开的四次挥手过程来描述
LISTEN(socket进行监听)
SYN_SENT(客户端tcp发送一个SYN以请求建立一个连接.之后状态)
SYN_RECV(服务端发出ACK确认客户端的 SYN 后状态置为SYN_RECV)
ESTABLISHED(打开的连接,双方可以进行或已经在数据交互)
FIN_WAIT1(主动关闭端应用程序调用close,TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态)
CLOSE_WAIT(被动关闭端TCP接到FIN后,发出ACK以回应FIN请求,并进入CLOSE_WAIT)
FIN_WAIT2(主动关闭端接到ACK后,就进入了FIN-WAIT-2)
LAST_ACK(被动关闭端一段时间后程序将调用CLOSE关闭连接,TCP发送一个 FIN,等待对方的ACK.进入LAST-ACK)
TIME_WAIT(在主动关闭端接收到FIN后,TCP 就发送ACK包,并进入TIME-WAIT状态)
CLOSING(少见,等待远程TCP对连接中断的确认)
CLOSED(被动关闭端在接受到ACK包后,就进入了closed的状态。连接结束)
UNKNOWN(未知的Socket状态)PID/Program PID即进程id,Program即使用该socket的应用程序
三次握手#
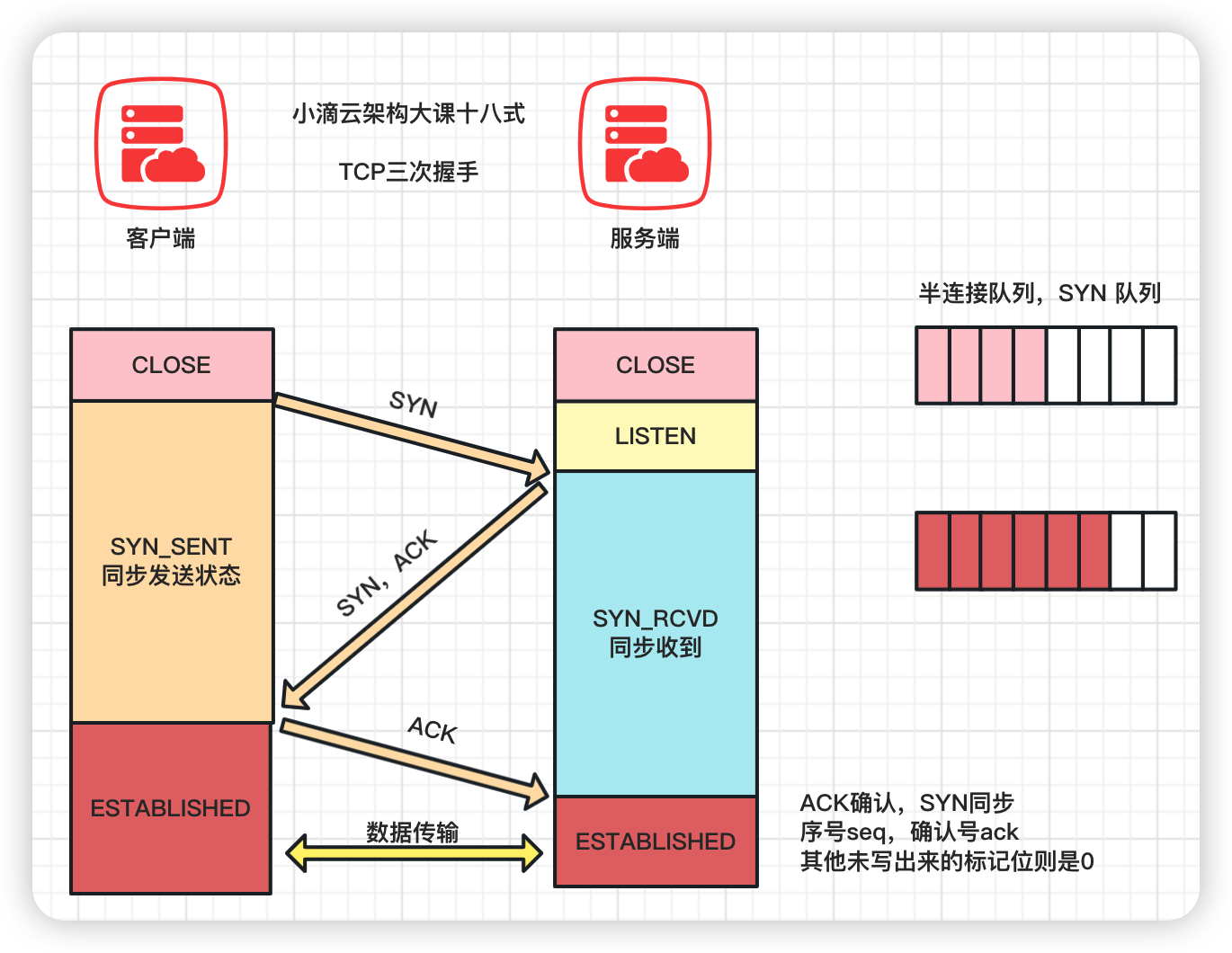
进阶TCP底层三次握手详细流程#
-
TCP的可靠性传输机制:TCP三次握手的流程
-
一次握手:客户端发送一个SYN(Synchronize)数据包到服务器,用来请求建立连接,状态变为SYN_SEND;
- 报文首部中的同部位SYN=1,同时随机生成初始序列号 seq=x
-
二次握手:服务器收到客户端的SYN数据包,并回复一个SYN+ACK 数据包,用来确认连接,状态变为SYN_RECEIVED;
- 确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时随机初始化一个序列号 seq=y
-
三次握手:客户端收到服务器的SYN+ACK数据包,并回复一个ACK 数据包,用来确认连接建立完成,状态变为ESTABLISHED
- 确认报文的ACK=1,ack=y+1,,seq=x+1
- 出于安全的考虑 第1次握手不能携带数据,第3次握手是可以携带数据的。
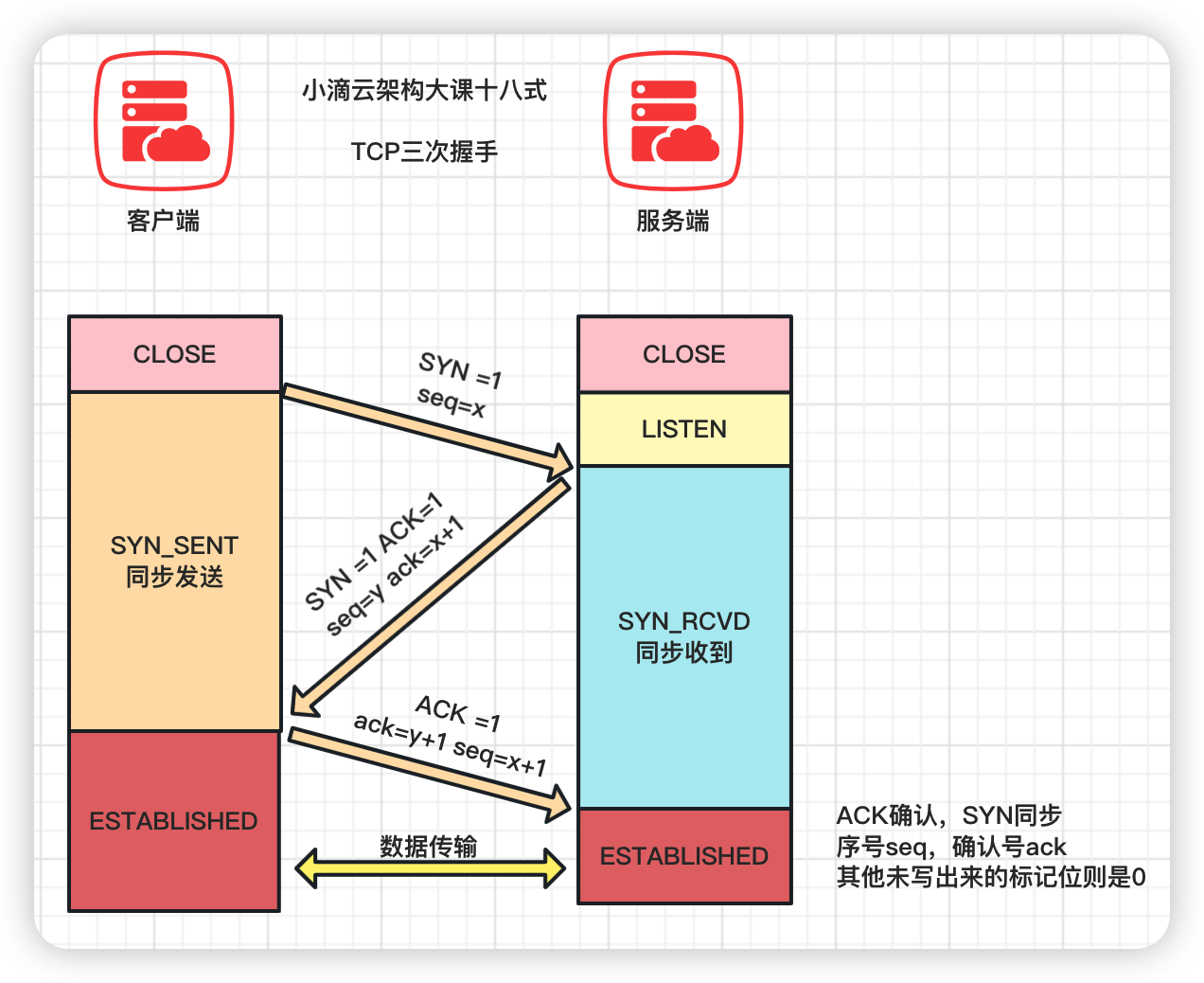
-
-
TCP三次握手的状态变化
- 客户端:CLOSED -> SYN_SENT -> ESTABLISHED
- 服务端:CLOSED ->LISTEN-> SYN_RECEIVED -> ESTABLISHED
-
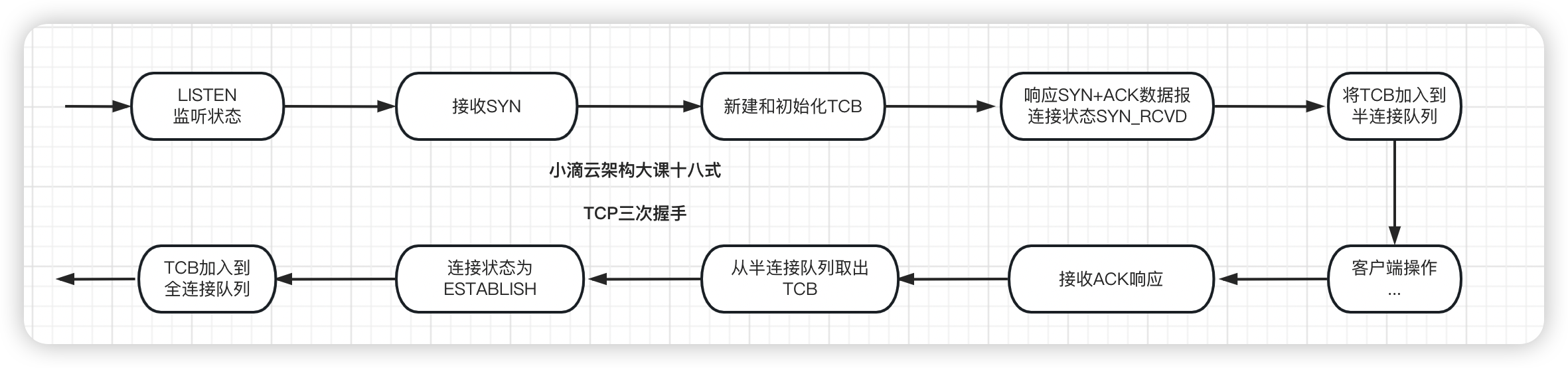
TCP连接的数据结构
-
TCP是有状态的协议,有多个连接存在时通过TCP的控制块 TCB (Transmission Control Block)来记录每一个连接的状态
- 通常一个TCB至少需要280个字节
-
通过 四元组区分不同的TCP数据报属于哪一个连接 源IP地址、源端口、目的ip、目的端口
-
连接对象信息存在一个容器中,每次接收到报文后从容器中取出对应的控制块来处理
struct tcb // tcp 控制块 { _u32 remote_ip; // 远端ip _u32 local_ip; // 本地ip _u16 remote_port; // 远端端口号 _u16 local_port; // 本地端口号 int status; // 连接状态 ... }
-
- 来点形象的记忆深刻
TCP为什么要三次握手而不是二次或四次#
简介:面试题-TCP为什么要三次握手而不是二次或者四次
-
为什么要三次握手呢,不是二次或者四次?
- 两次握手案例一: 两端同步确认序列号
- 第一步:客户端发送一个起始序列号seq = x的 报文段给服务器。
- 第二步:服务器端返回向客户端发送确认号 ack = x+1,表示对客户端的起始序列号x 表示确认,并告诉客户端,他的起始序列号是 seq = y,但不一定成功发给客户端,导致服务端序列号可能丢失
- 两次握手,只有服务器对客户端的起始序列号做了确认,但客户端却没有对服务器的起始序列号做确认,不能保证可靠性
- 两次握手案例二:防止失效的连接请求报文段被服务端接收
- 若客户端向服务端发送的连接请求阻塞,客户端等待应答超时,就会再次发送连接请求,此时上一个连接请求就是"失效的"
- 如果建立连接只需两次握手,此时如果网络拥塞,客户端发送的连接请求迟迟到不了服务端,客户端便超时重发请求,如果服务端正确接收并确认应答,双方便开始通信,通信结束后释放连接
- 这时如果那个阻塞的连接请求抵达了服务端,由于只有两次握手,服务端收到请求就会进入ESTABLISHED状态,等待发送数据或主动发送数据,但客户端早已进入CLOSED状态,服务端将会一直等待下去,浪费服务端连接资源
- 如果 TCP 是三次握手,那么客户端在接收到服务器端 seq+1 的消息之后,可以判断当前的连接是否为历史连接
- 如果判断为历史连接的话就会发送终止报文(RST)给服务器端终止连接
- 如果判断当前连接不是历史连接的话就会发送指令给服务器端来建立连接。
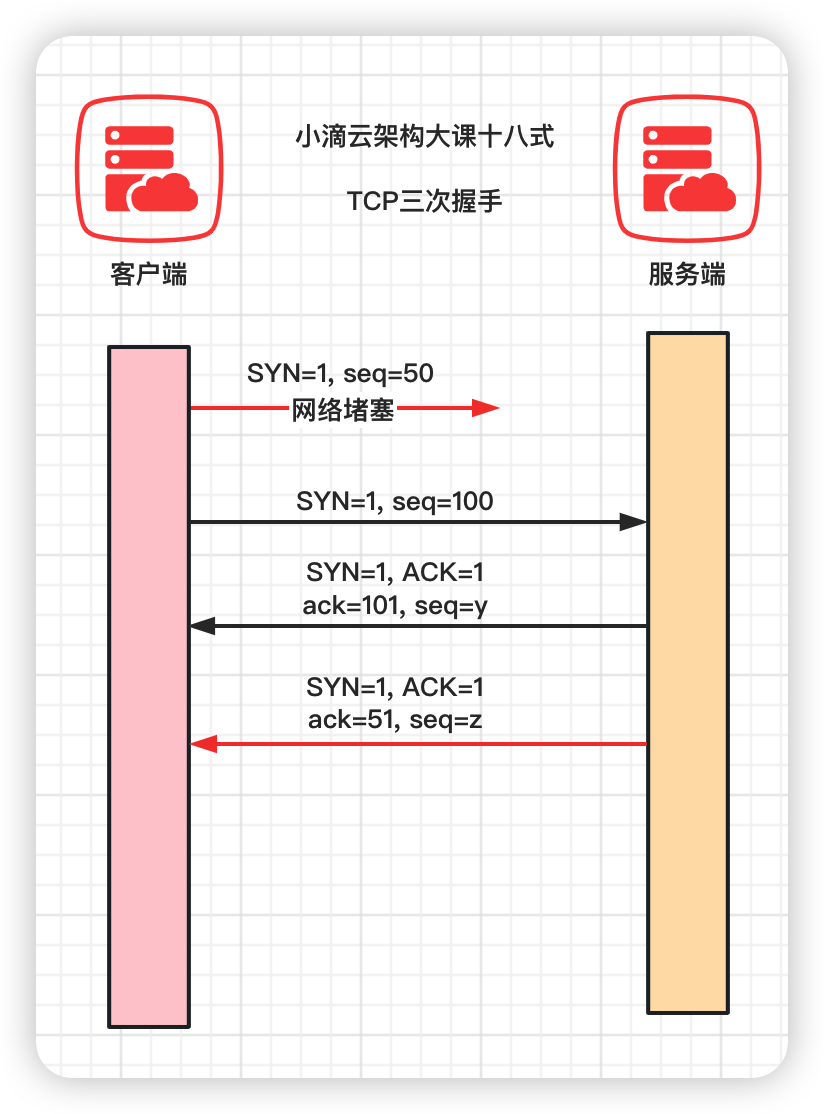
- TCP 连接可以四次握手,甚至是五次握手能实现 TCP 连接的稳定性,但三次握手是最节省资源的连接方式
- 两次握手案例一: 两端同步确认序列号
-
结论
-
三次握手的主要目的是保证连接是 双工+可用的,保证双方都具有接受和发送数据的能力
-
防止重复历史连接的初始化 ,避免资源的浪费
-
同步双方初始序列号
- 序列号seq:用来解决网络包乱序问题
- 确认号ack :用来解决丢包的问题
-
记住:可靠性传输主要是通过重传机制来保证
-
TCP洪水攻击介绍和ss命令浅析#
简介: TCP洪水攻击介绍和ss命令浅析
-
ss命令-
Socket Statistics 是Linux中的一条网络工具命令,用于显示当前系统的各种网络连接状态,包括TCP、UDP以及Unix套接字等
-
显示的内容和 netstat 类似, 但ss能够显示更多更详细的有关 TCP 和连接状态的信息
-
使用格式:ss [OPTIONS] ,常用选项如下
参数 说明 -s 显示概要信息 -a 显示所有网络连接状态; -l 显示正在监听的网络连接; -n 显示IP地址和端口号 -t 显示TCP状态 -u 显示UDP状态
-
-
洪水攻击SYN Flood
-
是一种网络攻击,它使用伪造的TCP连接请求来淹没服务器的资源,从而使服务器无法响应正常的用户请求
-
这种攻击通过不断地发送同步(SYN)连接请求到服务器,而服务器会尝试建立连接,
-
当服务器回复 SYN+ACK 报文后,攻击者不会发送确认(ACK)
-
那SYN队列里的连接则不会出对队,逐步就会占满服务端的 SYN半连接队列
-
服务器会一直等待,耗尽服务器的资源,最终就是服务器不能为正常⽤户提供服务
-
攻击的背景来源
- TCP 进入三次握手前,服务端会从内部创建了两个队列
- 半连接队列(SYN 队列)
- 全连接队列(ACCEPT 队列)
- TCP 进入三次握手前,服务端会从内部创建了两个队列
-
半连接队列(SYN 队列)
-
存放的是三次握手未完成的连接,客户端发送 SYN 到服务端,服务端收到回复 ACK 和 SYN
-
状态由 LISTEN 变为 SYN_RCVD,此时这个连接就被放进 SYN 半连接队列
-
半连接队列的个数一般是有限的,在SYN攻击时服务器会打开大量的半连接,分配TCB耗尽服务器的资源,使得正常的连接请求无法得到响应
- 服务器会给每个待完成的半连接设一个定时器,如果超过时间还没有收到客户端的ACK消息
- 则重新发送一次SYN-ACK消息给客户端,直到重试超过一定次数时才会放弃
- 这个操作服务器需要分配内核资源维护半连接状态
-
系统最大半队列大小 (半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的,Linux 内核版本实现不一样)
# sysctl -a|grep max_syn net.ipv4.tcp_max_syn_backlog = 1024 # cat /proc/sys/net/ipv4/tcp_max_syn_backlog 1024 -
查看系统当前半队列大小
方式一: ss -s 结果的 synrecv 0 就是 方式二: netstat -natp | grep SYN_RECV | wc -l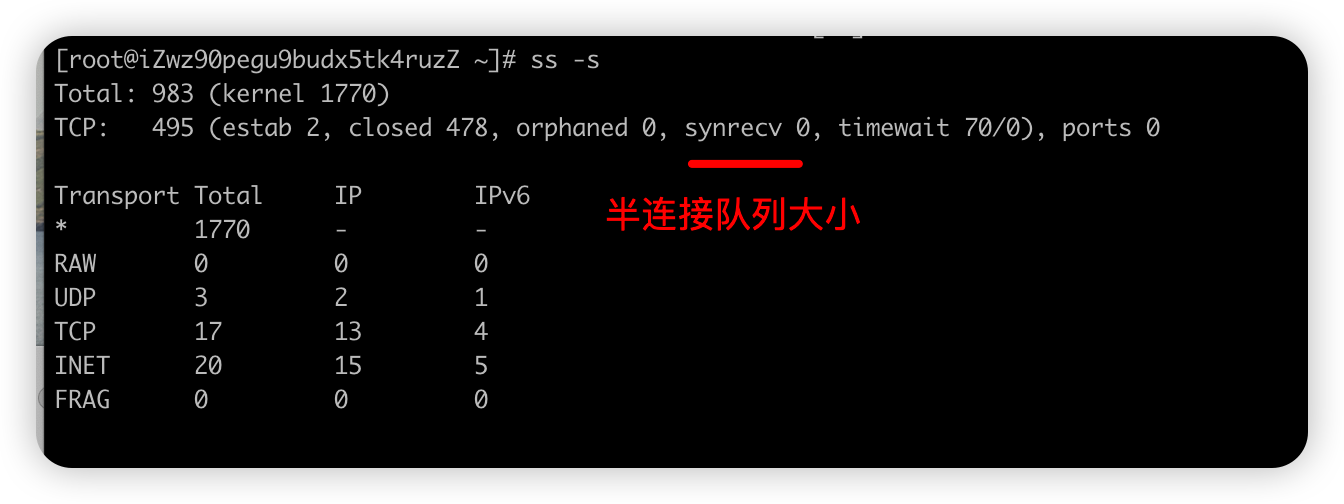
-
查看 SYN队列是否有溢出
间隔执行下面命令,如果有持续大量递增则是溢出 netstat -s|grep LISTEN 显示:6891 SYNs to LISTEN sockets dropped
-
-
全连接队列(ACCEPT 队列)
-
存放的是完成三次握手的连接,客户端回复 ACK, 并且服务端接收后,三次握手就完成了
-
连接会等待被的应用取走,在被取走之前,它被放进 ACCEPT全连接队列
-
系统最大全连接队列大小
# cat /proc/sys/net/core/somaxconn 长度由 net.core.somaxconn 和 应用程序使用 listen 函数时传入的参数,二者取最小值 默认为 128,表示最多有 129 的 ESTABLISHED 的连接等待accept -
查看系统当前全连接队列大小
ss -lnt 如果是指定端口 可以用 ss -lnt |grep 80 # -l 显示正在Listener的socket # -n 不解析服务名称 # -t 只显示tcp 常规可以通过port端口看是哪类应用, 80端口这一行 state 在LISTEN 状态下 Send-Q表示listen端口上的全连接队列最大为128 Recv-Q为全连接队列当前使用了多少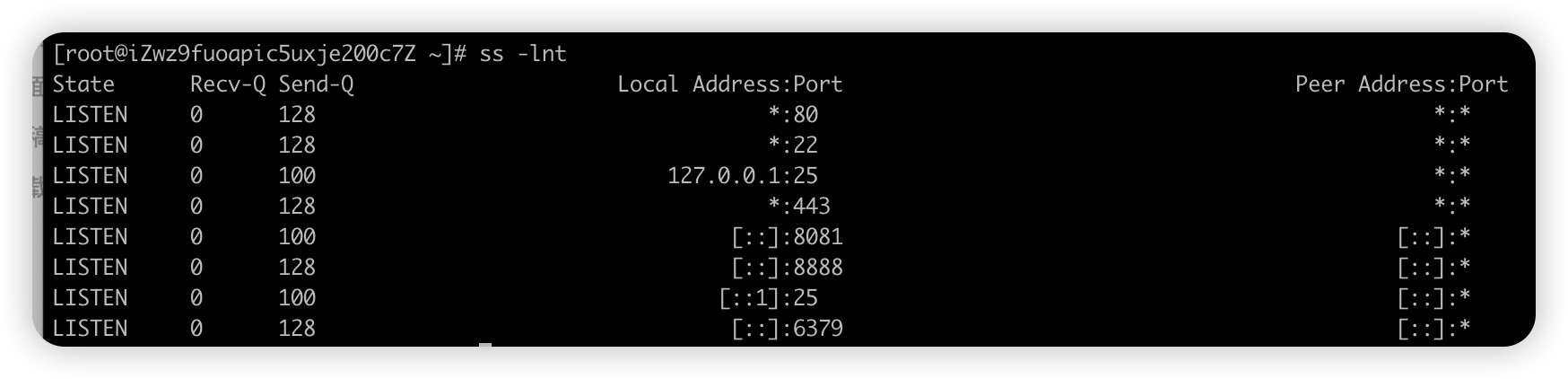
-
查看 Accept 队列 是否有溢出
间隔执行下面命令,如果有持续大量递增则是溢出 netstat -s | grep TCPBacklogDrop 显示:TCPBacklogDrop: 36 -
全连接队列满后发生什么
cat /proc/sys/net/ipv4/tcp_abort_on_overflow-
系统会根据 net.ipv4.tcp_abort_on_overflow 参数决定返回,有两个值分别是 0 和 1(常规推荐是0)
- 0 如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 如果全连接队列满了,server 发送一个
reset包给 client,表示废掉这个握手过程和这个连接- 客户端连接不上服务器,判断是否是服务端 TCP 全连接队列满的原因,可以把 tcp_abort_on_overflow 设为 1
- client异常中会报
connection reset by peer,大概率是由于服务端 TCP 全连接队列溢出导致的问题
-
-
-
总结
- 不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时内核会直接丢弃或返回 RST 包
- 全连接队列、半连接队列溢出很关键,对于一些短连接应用(比如Nginx、PHP)更容易爆发
- 一旦溢出,从cpu、线程状态看起来都比较正常,但是压力上不去
-
-
TCP洪水攻击 基础缓解方案:TCP SYN Cookies (延缓TCB分配)
- 使用连接信息(源地址、源端口、目的地址、目的端口等)和一个随机数,计算出一个哈希值(SHA1)
- SYN-Cookie避免内存空间被耗尽,但是加密会消耗CPU
- 攻击者发送大量的ACK包过来,被攻击机器将会花费大量的CPU时间在计算Cookie上,造成正常的逻辑无法被执行
- 哈希值 被用作序列号 应答 SYN+ACK 包,客户端发送完三次握手的最后一次 ACK ,
- 服务器就会重新计算这个哈希值,确认是之前的 SYN+ACK 的返回包,则进入 TCP 的连接状态。
- 当开启了 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,不需要维护半连接数的限制
- 如果是DDOS则难解决,需要花钱购买流量设备
# 开启syncookies 阿里云ECS默认开启 # vim /etc/sysctl.conf net.ipv4.tcp_syncookies = 1 0 值,表示关闭该功能; 1 值,表示仅当 SYN 半连接队列放不下时,再启用它; 2 值,表示无条件开启功能-
其他解决方案
- 增大半连接队列和全连接队列;
- 减少 SYN+ACK 重传次数(减小tcp_synack_retries的值)
- 收到syn攻击时,服务端会重传syn+ack报文到最大次数,才会断开连接,所以可以减少重传次数
- 使用连接信息(源地址、源端口、目的地址、目的端口等)和一个随机数,计算出一个哈希值(SHA1)
Linux服务器TCP洪水攻击入侵案例实战《上》#
简介: Linux服务器TCP洪水攻击入侵案例实战《上》
-
TCP洪水攻击环境准备
-
准备hping3工具:hping3是一款开源的网络扫描和测试工具,可用于模拟tcp洪水攻击
-
hping3 命令安装
# 依赖库 yum -y install libpcap yum -y install libpcap-devel yum -y install tcl-devel #安装 yum -y install hping3 -
参数说明
参数 说明 -S 表示发送SYN数据包 -U 发送UDP包 -A 发送ACK包 -p 表示攻击的端口 -i u100 表示每隔100微秒发送一个网络帧 --flood 和洪水一样不停的攻击 --rand-source 随机构造发送方的IP地址 -
-
使用hping3模拟tcp洪水攻击:通过hping3指令,向攻击目标发送大量tcp数据包,从而模拟tcp洪水攻击。
-
机器准备
-
机器A 部署Nginx 作为常规服务
- 阿里云服务需要关闭 syn_cookie ,即
net.ipv4.tcp_syncookies = 0
vim /etc/sysctl.conf 修改完之后,需要执行 sysctl -p 配置才能生效。- docker部署nginx. (自行安装docker)
docker run --name nginx-xd -p 80:80 -d nginx:1.23.3 - 阿里云服务需要关闭 syn_cookie ,即
-
机器B安装hping3 ,模拟 SYN 攻击
hping3 -S -p 80 --flood 172.31.101.9 #-S是发送SYN数据包,-p是目标端口,172.31.101.9是目标机器ip
-
-
现象
- 攻击前 访问A机器的nginx成功
- 攻击时 机器A服务访问超时失败(使用谷歌浏览器开启隐身模式,或者 curl -v 地址)
- 查看内存占用率不高、CPU平均负载和使用率等比较低,CPU耗在
si 软中断消耗时间比例升高

-
Linux服务器TCP洪水攻击入侵案例实战《下》#
简介: Linux服务器TCP洪水攻击入侵案例实战《下》
-
入侵攻防分析实战
-
查看内存占用率不高、CPU平均负载和使用率等比较低,CPU耗在
si 软中断消耗时间比例升高-
流程浅析
- 网卡接收到数据包后,通过硬件中断的方式,通知内核有新的数据,内核调用中断处理程序,把网卡的数据读到内存中
- 更新一下硬件寄存器的状态,再发送一个软中断信号,通知从内存中找到网络数据
- 按照网络协议栈对数据进行逐层解析和处理,然后把数据交给应用程序进行处理
- 前面部分处理硬件请求,属于硬中断,特点是快速执行;
- 后面部发处理是内核触发,属于软中断,特点是延迟执行。
-
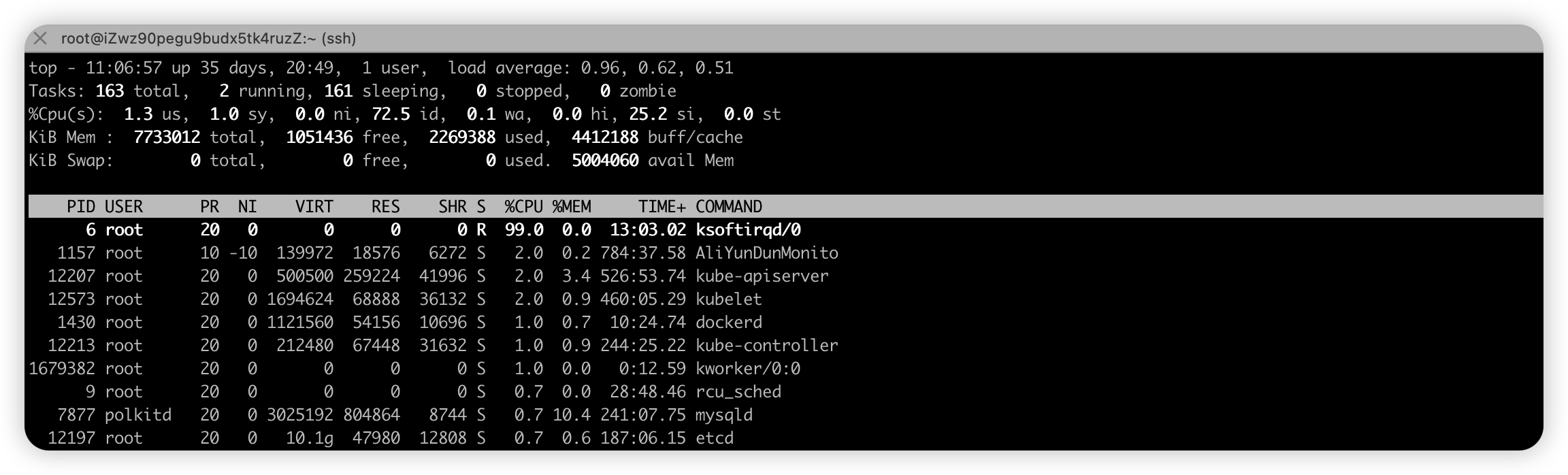
CPU主要用在软中断上,从进程列表上看到CPU 使用率最高的也是软中断进程 ksoftirqd
- ksoftirqd是运行在Linux的进程,专门处理系统的软中断的,格式是 “ksoftirqd/CPU 编号
- 在多核服务器上每核都有一个ksoftirqd进程,经常看到ksoftirqd/0表示这是CPU0的软中断处理程序
-
所以软中断过多比较大可能导致问题,通过文件系统 /proc/softirqs 看是哪类下软中断导致
- /proc/softirqs 提供了软中断的运行情况
- /proc/interrupts 提供了硬中断的运行情况
-
-
命令
watch -d cat /proc/softirqsEvery 2.0s: cat /proc/softirqs Sat Jan 7 12:15:45 2023 CPU0 CPU1 CPU2 CPU3 HI: 0 0 0 1 TIMER: 346771437 154363606 304924440 150269528 NET_TX: 148 7395 91 53 NET_RX: 203887543 25629878 37152669 27395828 BLOCK: 11007513 0 0 0 BLOCK_IOPOLL: 0 0 0 0 TASKLET: 9798 38 15 7 SCHED: 165941548 77615785 144222611 74794157 HRTIMER: 0 0 0 0 RCU: 184530769 93465836 167240016 91974099 说明 HI 高优先级软中断 TIMER表示定时器软中断,用于定时触发某些操作 NET_TX表示网络发送软中断,用于处理网络发送的数据包 NET_RX表示网络接收软中断,用于处理网络接收的数据包 BLOCK表示块设备软中断,用于处理磁盘读写请求。 TASKLET:任务中断,用于处理任务的中断任务。 SCHED 表示内核调度软中断 HRTIMER:高精度定时器中断,用于处理高精度定时任务。 RCU:Read-Copy Update中断,用于处理读写锁的内核操作。- 现象:
- 几个指标都在变化中,但是NET_RX 是变化最多的
- 推断是网络接收软中断,用于处理网络接收的数据包 导致出现问题
- 现象:
-
查看网络流量命令 sar
sar -n DEV 1 -h #-n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据 -h人类可读方式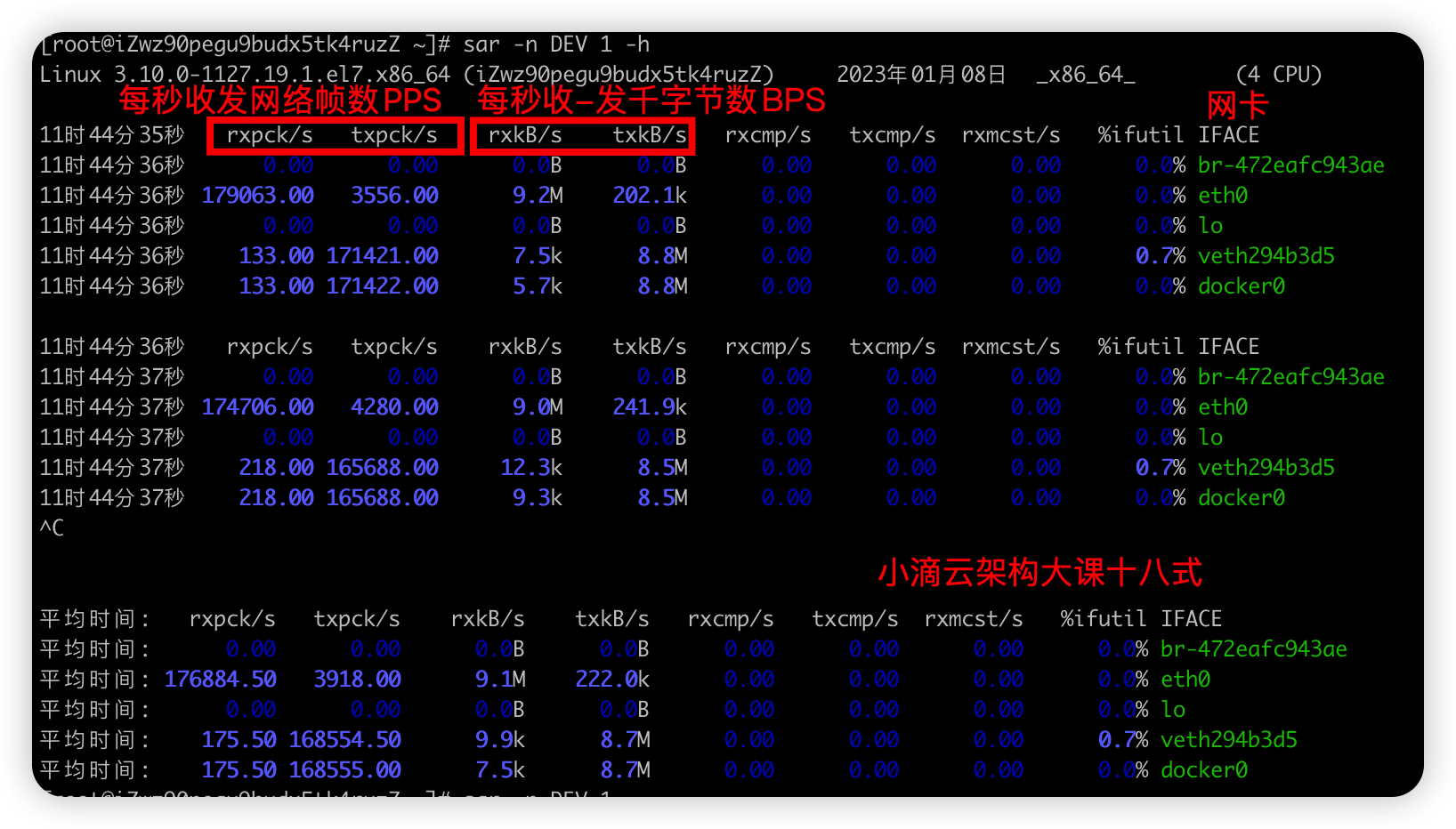
-
分析网卡数据包
- eth0:接收的网络帧(包) PPS较大为179063, 而每秒收到的数据包大小BPS为9.2M(转为字节)
- 计算为:9.2 * 1024 * 1024 /179063 = 54字节,平均每个网络帧只有54字节,很小的网络帧是小包问题
- 其他网卡是Linux内部网桥转发导致的,不必关注
-
进一步抓包分析
tcpdump -i eth0 -n tcp port 80参数 说明 -i 指定抓哪个网卡接口的数据包。 -n 不解析协议名和主机名, 避免DNS解析 tcp port 80 只抓取tcp协议并且端口号为80的网络帧 -vv 显示更加详细的信息。 -e 显示mac地址。 -w write 写入保存到文件中。导入的文件可以使用wireshark打开。 -r read 读取文件中的数据。 -c 在收到指定包数目之后,tcpdump就会停止。 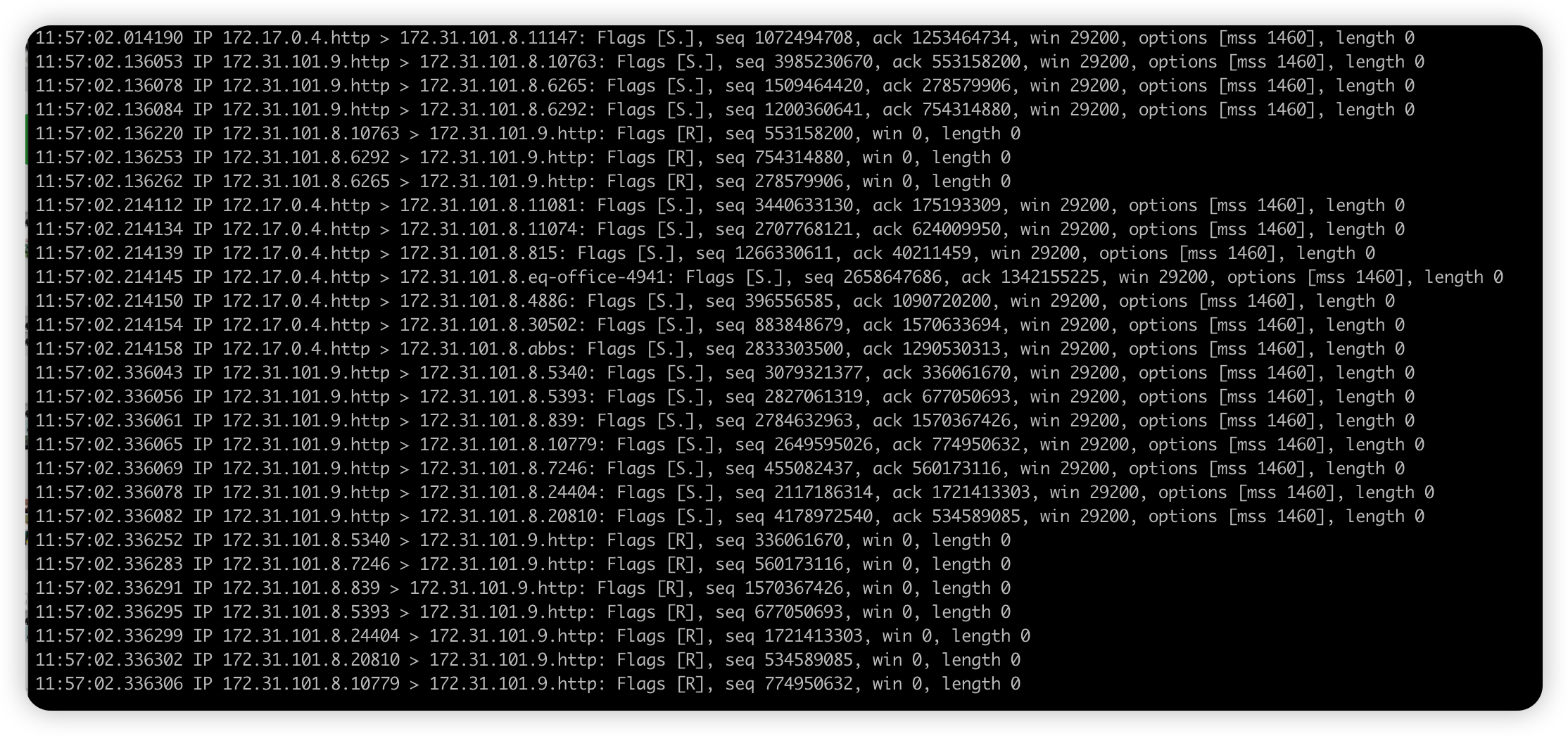
对输出结果进行分析: 第一列:时分秒毫秒 第二列:网络协议 IP 第三列:发送方的ip地址 第四列:箭头 > 表示数据流向 第五列:接收方的ip地址 第六列:冒号 第七列:数据包内容,包括Flags 标识符,seq 号,ack 号,win 窗口,数据长度 length 更多标识符:使用 tcpdump 抓包后,会遇到的 TCP 报文 Flags,有以下几种: [S] : SYN(开始连接) [P] : PSH(推送数据) [F] : FIN (结束连接) [R] : RST(重置连接) [.] : 没有 Flag (意思是除上面四种类型外的其他情况,有可能是 ACK 也有可能是 URG)- 分析
- 大部分数据都是从 172.31.101.8.43231 > 172.31.101.9.http: Flags [S] ,数据包是SYN
- 确认是 SYN FLOOD 洪水攻击
- 分析
-
TCP洪水攻击结果分析和解决方案实战#
简介: TCP洪水攻击结果分析和解决方案实战
-
分析洪水攻击结果现象
-
查看系统最大半连接队列大小
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog 1024 -
查看SYN半连接队列大小
方式一: ss -s 结果的 synrecv 0 就是 方式二: netstat -natp | grep SYN_RECV | wc -l -
查看 SYN半连接队列是否有溢出
间隔执行下面命令,如果有持续大量递增则是溢出 netstat -s|grep LISTEN 显示:6891 SYNs to LISTEN sockets dropped -
攻击时也可以查看 SYN_RECV 状态的连接数
- 查看连接
netstat -n -p | grep SYN_RECV - 统计数量
netstat -n -p | grep SYN_RECV | wc -l
- 查看连接
-
-
缓解TCP洪水攻击方案
- 开启tcp_cookie
vim /etc/sysctl.conf net.ipv4.tcp_syncookies = 1 修改完之后,需要执行 sysctl -p 配置才能生效。- 增大半连接队列和全连接队列
- 半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的
- 测试发现服务端最多只有 256 个半连接队列而不是 1024,Linux 内核版本实现不一样,和somaxconn全连接队列也有关系
- 增加半连接队列大小不能只增大 tcp_max_syn_backlog 的值,还要一同增大 somaxconn 即增大全连接队列
#增大 tcp_max_syn_backlog(半连接队列) echo 2048 > /proc/sys/net/ipv4/tcp_max syn backlog #增大 somaxconn(全连接队列) echo 2048 > /proc/sys/net/core/somaxconn- 减少 SYN+ACK 重传次数(减小tcp_synack_retries的值)
# 减少SYN+ACK 的重传次数为1,加快处于SYN_REVC 状态的 TCP 连接断开 echo 1 > /proc/sys/net/ipv4/tcp_synack_retries -
效果验证:开启tcp_cookie
-
重新进行, 机器B安装hping3 ,模拟 SYN 攻击
hping3 -S -p 80 --flood 172.31.101.9 #-S是发送SYN数据包,-p是目标端口,172.31.101.9是目标机器ip -
现象
- 攻击前 访问A机器的nginx成功
- 攻击时 机器A服务可以访问成功,但是会有卡顿,如果是多节点DDOS攻击,仍然会造成服务不可用
- 查看内存、CPU负载等比较低
-
-
现象和思路总结
- 当发现服务器或业务卡顿的时候,通过top命令来查看服务器负载和cpu使用率,然后排查cpu占用较高的进程
- 如果发现cpu使用率并不高,但是si软中断很高,且ksoftirqd进程cpu占用率高,则说明服务器持续发生软中断
- 通过cat /proc/softirqs 来分析是哪类型的软中断次数最多,watch命令来查看变化最快的值
- 多数情况下网络发生中断的情况会比较多,通过sar命令来查看收发包速率和收发包数据量
- 验证是否是网络收发包过多导致,计算每个包的大小,判断服务器是否收到了flood攻击
- 通过tcpdump来抓包,分析数据包来源ip和抓包数据中的Flags来分析数据包类型
- 如果是Flood洪水攻击,可以通过调整tcp链接参数策略和防火墙封禁异常ip
- 如果是大规模DDOS攻击,则花钱找运营商购买流量包封堵
四次挥手#
四次挥手详细流程和记忆#
简介: 进阶TCP底层-四次挥手详细流程和记忆
- TCP通过三次握手建立连接,而断开连接则是通过四次挥手,详细流程如下
- 第一次
- 客户端发送FIN(Finish)报文段,用于关闭客户端到服务端的数据传输,表示客户端的数据发送完毕;
- 客户端进入 FIN_WAIT_1 状态
- 第二次
- 服务端收到客户端的FIN报文段后,发送ACK报文段,确认收到了客户端的FIN报文段
- 服务端进入CLOSE_WAIT状态,客户端接收到这个确认包后进入 FIN_WAIT_2 状态
- 第三次
- 服务端发送FIN报文段,用于关闭服务端到客户端的数据传输,表示服务端的数据发送完毕
- 服务器端进入 LAST_ACK 状态,等待客户端的最后一个 ACK
- 第四次:
- 客户端收到服务端的FIN报文段后,发送ACK报文段,确认收到了服务端的FIN报文段
- 客户端接收后进入TIME_WAIT状态,在此阶段下等待2MSL时间(两个最大段生命周期,2 Maximum Segment Lifetime)
- 如果这个时间间隔内没有收到服务端的请求,进入CLOSED状态;服务器端接收到ACK确认包之后,也进入 CLOSED 状态。
- 从而完成TCP四次挥手
- 第一次
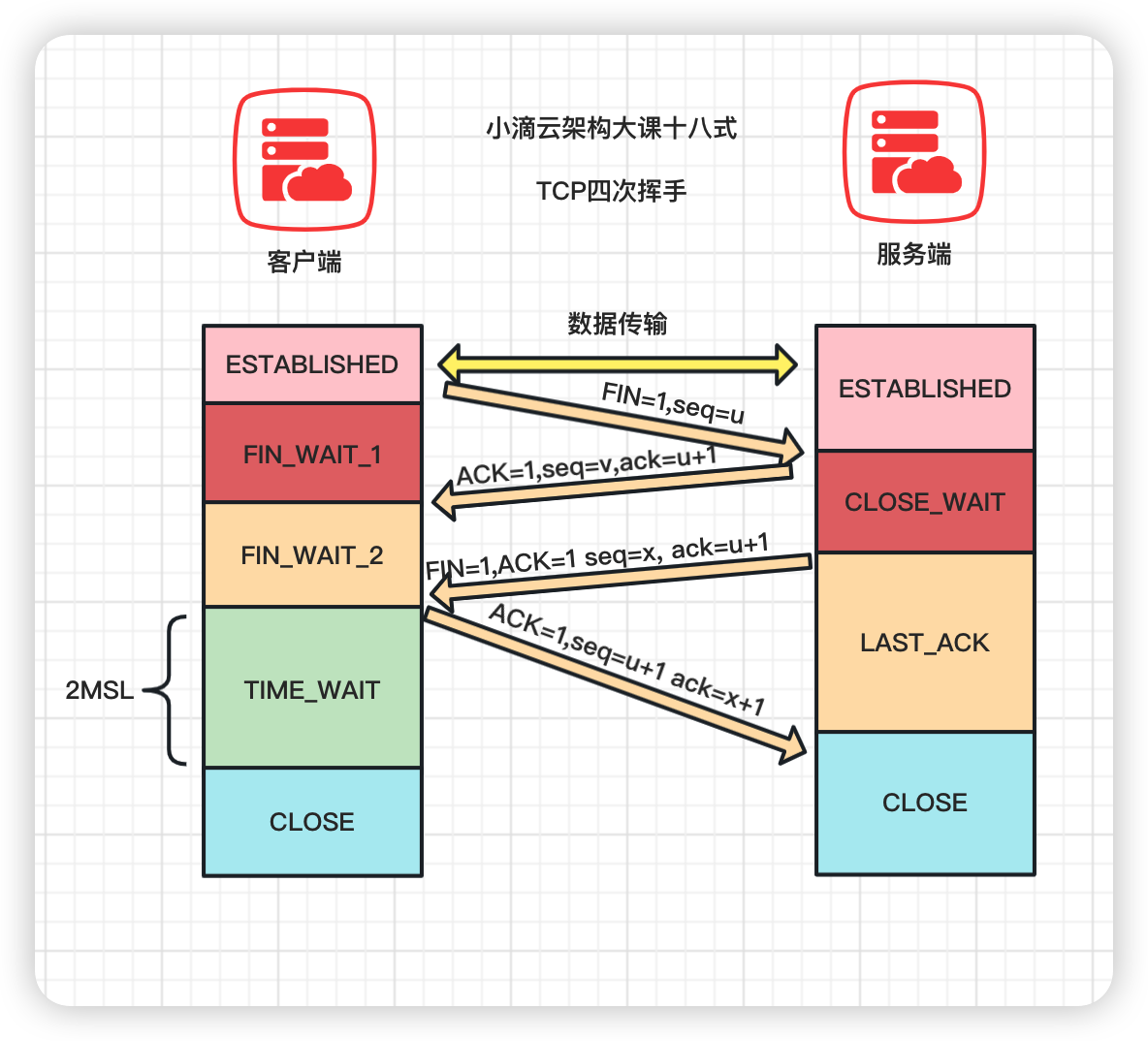
-
如何形象记忆?
- 程序员老王和 清纯可爱的冰冰 在 广东的爱情故事
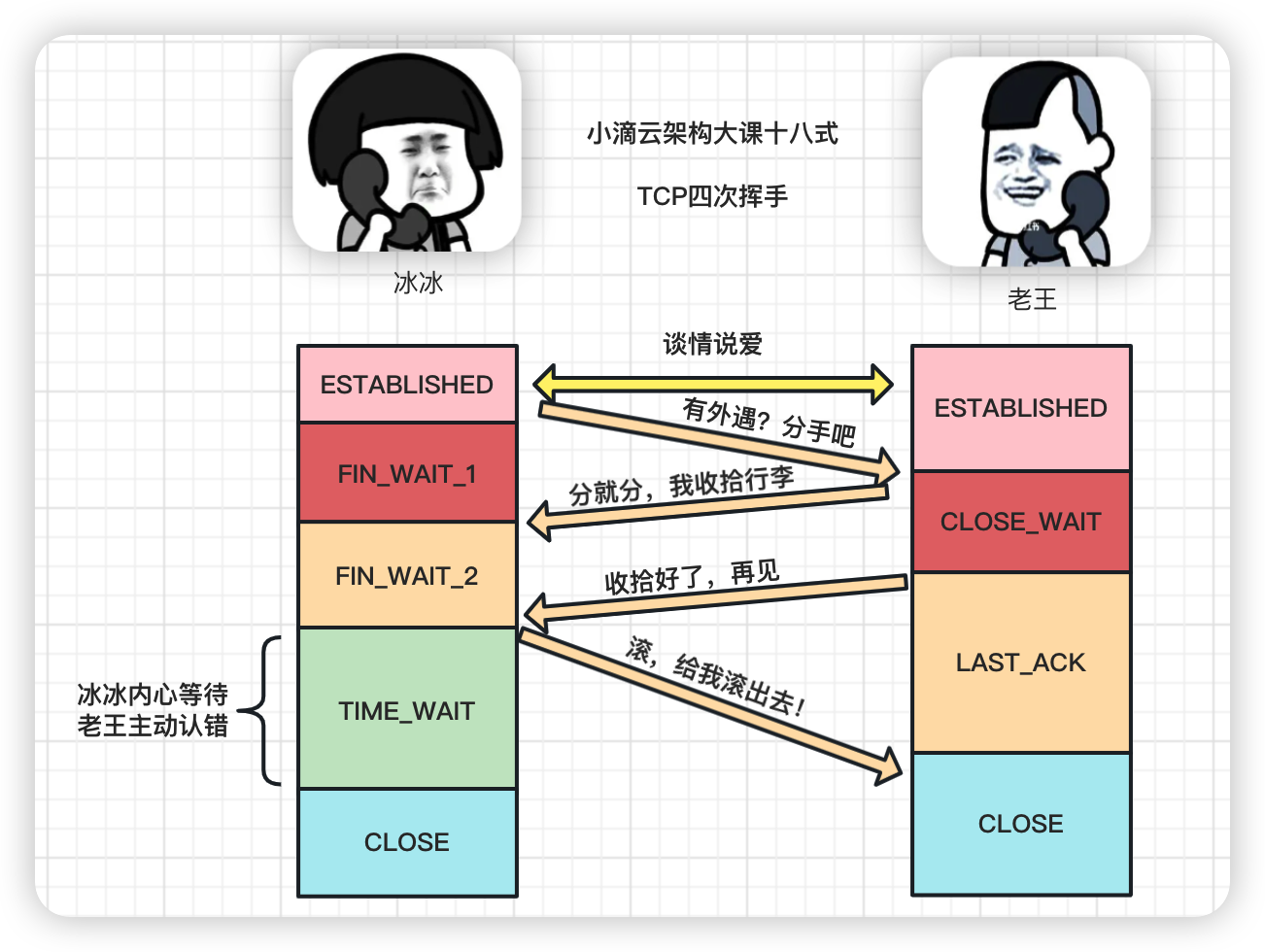
关于TCP四次挥手的疑惑点你能回答几个#
简介: 面试官-关于TCP四次挥手的疑惑点你能回答几个
-
为啥要等待2MSL时间
- 2MSL是报⽂最⼤⽣存时间,是任何报⽂在⽹络上存在的最⻓时间,超过这个时间报⽂将被丢弃
- 假如最后一次客户端发送ACK给服务端没收到,超时后 服务端重发FIN,客户端响应ACK,来回就是2个MSL
- 等待2MSL,可以让本次连接持续的时间内所产生的所有报文段都从网络中消失,避免旧的报文段
- RFC 793中规定一个MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟
-
CLOSE-WAIT 和 TIME-WAIT 的区别
- CLOSE-WAIT是等待关闭
- 服务端收到客户端关闭连接的请求并确认之后,进入CLOSE-WAIT状态。
- 但服务端可能还有一些数据没有传输完成,不能立即关闭连接
- 所以CLOSE-WAIT状态是为了保证服务端在关闭连接之前将待发送的数据处理完
- TIME-WAIT是在第四次挥手
- 当客户端向服务端发送ACK确认报文后进入TIME-WAIT状态,主动关闭连接的,才有time_wait状态
- 在HTTP请求中,如果connection头部的取值设置为close,那么多数都由服务端主动关闭连接
- 服务端处理完请求后主动关闭连接,所以服务端出现大量time_wait状态
- 防⽌旧连接的数据包
- 如果客户端收到服务端的FIN报文之后立即关闭连接,但服务端对应的端口并没有关闭
- 客户端在相同端口建立新的连接,可能导致新连接收到旧连接的数据包,从而产生问题
- 保证连接正确关闭
- 假如客户端最后一次发送的ACK包在传输的时候丢失,由于TCP协议的超时重传机制,服务端将重发FIN报文
- 如果客户端不是TIME-WAIT状态而直接关闭的话,当收到服务端重送的FIN包时,客户端会用RST包来响应服务端
- 导致服务端以为有错误发生,但实际是关闭连接是没问题的
- 当客户端向服务端发送ACK确认报文后进入TIME-WAIT状态,主动关闭连接的,才有time_wait状态
- CLOSE-WAIT是等待关闭
-
TIME-WAIT状态有啥坏处?
-
过多TIME-WAIT状态 会占用文件描述符/内存资源/CPU 和端口,占满所有端口,则会导致无法创建新连接
-
高并发短连接的TCP服务器上
-
当服务器处理完请求后立刻主动正常关闭连接,会出现大量socket处于TIME_WAIT状态
-
端口有个0~65535的范围,排除系统和其他服务要用的,剩下的很少
-
查看time_wait状态连接数
netstat -an |grep TIME_WAIT|wc -l
-
-
解决方案
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
- 目前版本的http协议基本上都是支持长连接
- 配置
SO_REUSEADDR,在 端口不够用时,TCP连接位于TIME_WAIT状态时可以重用端口- 对应linux系统配置
net.ipv4.tcp_tw_reuse=1
- 对应linux系统配置
- 缩减 time_wait 时间,设置为 1 MSL
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
-
-
-
为什么建立连接是三次握手,关闭连接却是四次挥手呢?
-
为了确保数据能够完成传输,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了
-
但未必所有的数据都全部发送给对方了,所以不能马上会关闭SOCKET
-
可能还需要发送一些数据给对方之后,再发送FIN报文告诉对方来表示同意现在可以关闭SOCKET连接
-
对比
- 三次握手中第二次握手SYN和ACK是一起发送
- TCP断开连接的FIN 和 ACK需要分开 表示服务端仍可以接受数据,因此需要四次挥手
-
TCP的可靠性传输ACK-流量控制-拥塞控制-重传机制#
简介: TCP的可靠性传输 ACK-流量控制-拥塞控制-重传机制
-
问题:服务器发送数据包 越快越好,但是由于各种因素,比如带宽小、线路不稳定,导致了丢包严重,怎么解决?
-
TCP的可靠性传输机制
-
ACK机制
- 接收方收到TCP 数据包,要响应一个确认消息 acknowledgement,简称 ACK
- ACK有两个信息:期待要收到下一个数据包的编号和 当前接收方的接收窗口的剩余容量
-
流量控制(通过接收方来控制流量的一种方式,属于 端 对 端的控制,好比 从A仓库运输到B仓库)
- TCP 连接的双方都有固定大小的buffer缓冲空间,接收端只允许发送端发送接收端缓冲区能接纳的数据
- 当接收方来处理不过来发送方的数据,会提示发送方降低发送的速率,防止包丢失
- 流量控制是让发送方的发送速率不要太快,让接收方来得及接收
- 利用的是可变大小的滑动窗口机制, 在TCP连接上实现对发送方的流量控制
- TCP 协议有个叫 win,即 16 位的窗口大小,
- 接受方每次收到数据包 ,在发送确认报文的时候也告诉发送方,自己的缓存区还有多少空余空间
- 缓冲区的空余空间,称为接受窗口大小
-
-
拥塞控制(通过发送方来控制流量的一种方式,对整个网络 全局性考虑,好比从 A仓库到B仓库路上最运输最多的重量)
- 是一种自适应算法,利用多种机制,根据网络的状况自动调整发送端的发送速率,以避免网络拥塞
- 慢启动
- 发送端会以一个较小的窗口值开始发送,每收到一个ACK消息后,窗口值就会翻倍增加,直到窗口值达到最大值
- 如果不丢包,就加快发送速度;如果丢包,则降低发送速度
- 这样就可以慢慢地增加发送端的发送速率,避免突然发送大量数据造成网络拥塞。
- 快速重传
- 当发送端发送的数据报文没有在规定时间内收到ACK确认消息时,发送端就会认为该数据报文丢失
- 它会立即重发该数据报文,从而提高数据传输的效率。
- 拥塞避免
- 当收到三个重复的ACK消息时,发送端会认为网络出现拥塞,它会减少发送速率
- 降低发送端的数据量,从而减少网络的拥塞情况
-
重传机制
-
超时重传 Retransmission Timeout(时间驱动)
- 发送一个数据包后就开启计时器,在一定时间内如果没有得到发送的数据报的 ACK 报文,就重发数据,直到发送成功
- 配置超时重传时间就是 RTO,一般大于RTT(Round-Trip Time,往返时间)就行
- 缺点
- 报文丢失会等待一定的超时时候才重传,增加端到端的时延
-
快速重传 Fast Retransmit (数据驱动)
- TCP 协议给每个包编号seq(sequence number),第1个包的编号是一个随机数
- 接收方收到多个包后,方便组装还原,如果发生丢包,可以知道丢失的是哪一个包
- 例子
- 接收方收到了6号包,没有收到14号包,ACK 就会记录,期待收到14号包
- 过了一段时间14号包还是没收到,但是收到24号包,ACK 里面的编号不会变化,总是响应期待14号包
- 如果发送方收到三个连续的重复 ACK 或者 超时还没有收到任何 ACK,会确认14号包丢包,再次重发这个包。
- 重传成功后,接收方会返回正常最新的ACK
- 缺点
- 快速重传 解决了超时时间的问题,但存在重传的时候,是重传之前的⼀个,还是重传所有的问题
- 根据不同的实现,两种重传都可能,也有更多机制SACK和D-SACK
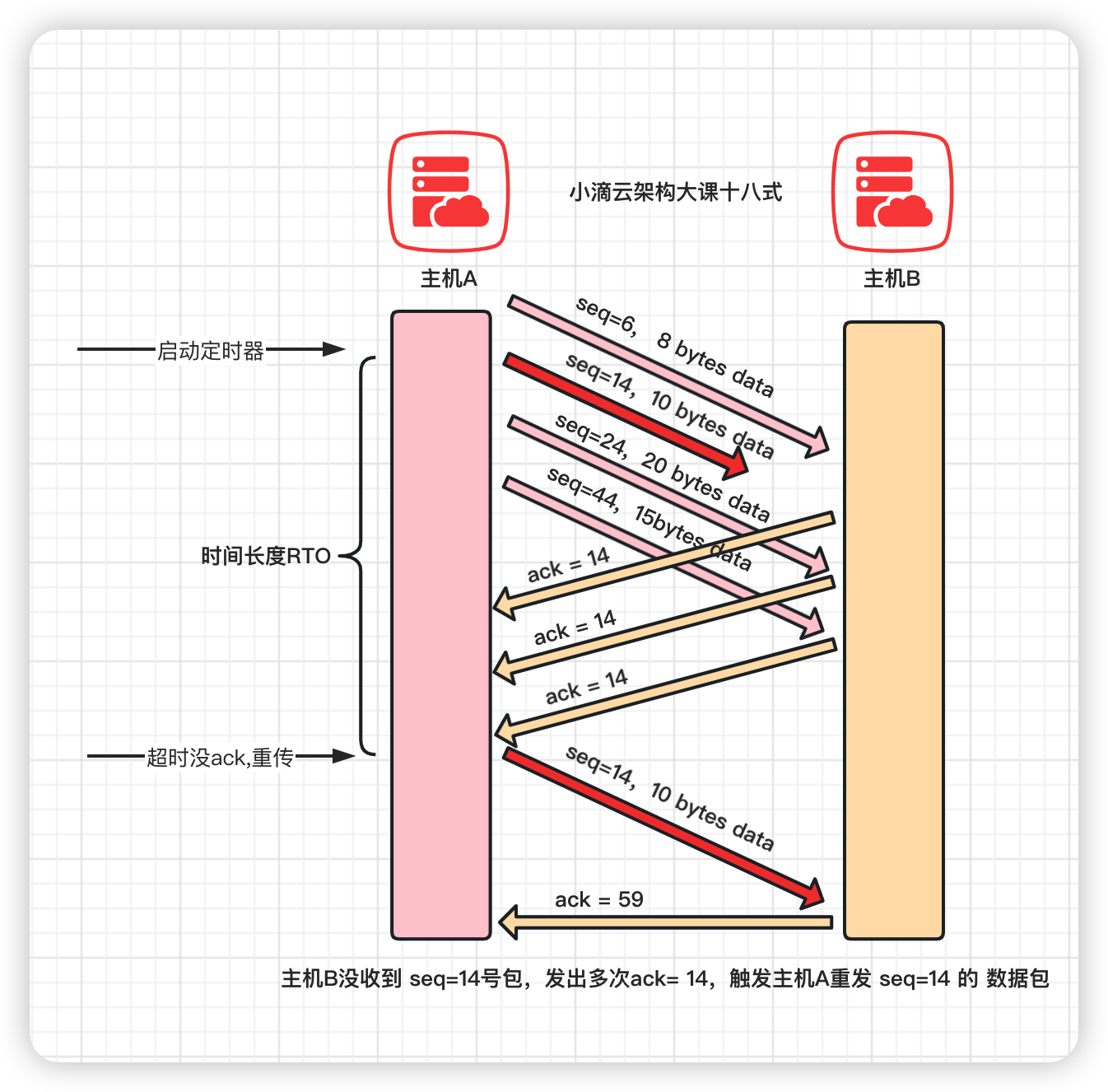
-
-
TCP的传输优化机制 Nagle算法和延迟确认#
简介: TCP的传输优化机制 Nagle算法和延迟确认
- 背景
- TCP的报文发送数据少,假如只有几个字节,那网络传输效率特别低
- 每个报⽂中都会有 20 个字节的 TCP 头部, 20 个字节的 IP 头部,⽽数据只有⼏个字节或者没数据的时候特别浪费
- 好比 老王 开着 大货车,去送一斤水果 给冰冰
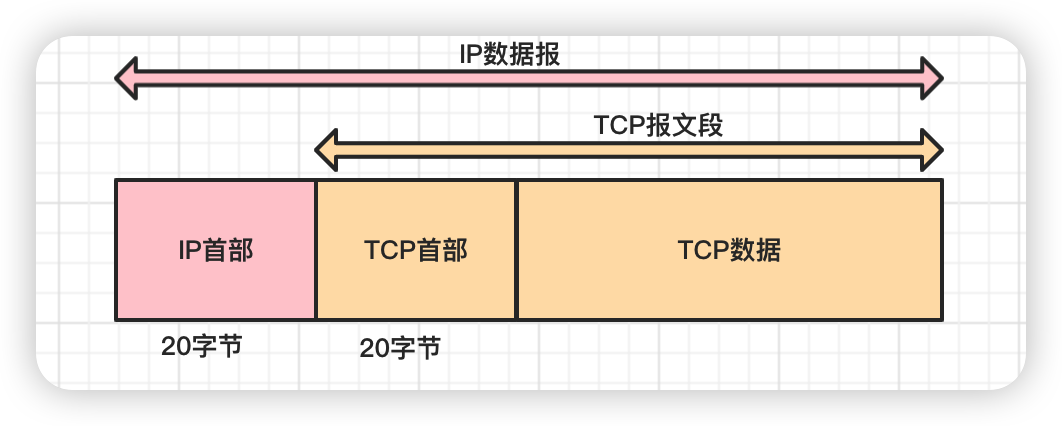
-
解决方案
-
Nagle 算法
-
是TCP协议的一种流量控制算法,它的目的是为了减少网络中的小数据包的数量,提高网络的效率
-
TCP/IP协议中,无论发送多少数据都要在数据前面加上协议头,对方接收到数据也需要发送ACK表示确认
-
为了提高利用网络带宽,TCP希望尽可能的发送足够大的数据,诞生了Nagle算法
- 任意时刻,最多只能有一个未被确认的小段。
- “小段” 指的是小于MSS尺寸的数据块
- “未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认。
-
TCP协议默认开启了Nagle算法,默认TCP_NODELAY选项为false
-
做法
- 一个 TCP 连接上最多只能有一个未被ACK确认的数据包,在收到确认信息之前,不再发送后续数据包
- 在上一个数据包未到达目的地前,即未收到 ack 前,将多个数据包组合成一个数据包发送
- 当上一个小分组的 ack 收到后,TCP 就将收集的小分组合并成一个大分组发送出去,以减少小包的发送数量
- 上面条件都没满足,发生了超时(一般为200ms),也会立即发送
-
简单来说 满足下面任一条件才发送数据,不然就等待
- TCP连接中, 没有已发送未确认报⽂时,则⽴刻发送数据
- TCP连接中 存在未确认报⽂时,会等到 **没有已发送未确认报⽂ ** 或 数据⻓度达到 MSS ⼤⼩时,再发送数据。
- 再或者超时,也会发送数据
-
案例
- 客户端每次发送一个字节,发送
hello给服务端,虽然是一个个字节发送 - 但测试发现hello 被分成两个包发送,一个是h,一个是ello,提高了传输效率
- 分成的2个数据包,并没有连续被发出,等待第一个包收到ACK之后,才发第二个包
- 客户端每次发送一个字节,发送
-
禁用Nagle算法
- 默认开启的,比较适用于发送方发送大批量的小数据,并且接收方作出及时回应的场合,降低包的传输个数
- 如果业务是实时的发送数据并需要及时获取响应,则不适合开启Nagle算法
- 延迟要求比较严格的地方,网络比较通畅 或 内部网的情况下,应该关闭nagle算法
- 游戏类服务器开发也会禁用Nagle
- linux提供了TCP_NODELAY的选项来禁用Nagle算法
- 禁止Nagle算法,每一次send 都会组一个包进行发送,hello被分成5个小包分别发送
- 不用等待ACK,可以连续发送数据包
- netty框架里面
.childOption(ChannelOption.TCP_NODELAY, true)禁用
-
生活中例子
- Nagle算法相当于大家尽量做公交车,这样路上的小车少,交通会通顺一些,但缺点是要等公交车
- 禁止Nagle算法,相当于大家都开车,对交通的负载会加大

-
-
延迟确认
- TCP报文中假如没携带数据,只是发ACK, 但有 40 个字节的 IP 头 和 TCP 头,⽹络效率也是很低的,就产⽣出 TCP 延迟确认
- 做法
- 当 TCP 收到一个数据包时,它不会立即发出确认,而是等待一段时间 ,Linux默认延时时间为 40ms
- 如果在这段时间内有响应数据要发送时,ACK会随着响应数据⼀起发送给对⽅;如果期间没数据发送则40ms后才ACK
- TCP 就将这两个数据包一起确认,从而减少了确认报文的数量
- 这种策略可以有效地减少网络中的报文交换,从而提高网络效率
-
注意
- Nagle 算法和延迟确认不能一起使用
- Nagle 算法 是用于延迟发送数据包,延迟确认 是用于 延迟接收数据包
- 两个凑在一起就会造成更大的延迟,会产生性能问题
-
中间件框架里面的应用
- Kafka 的 producer生产者发送到Broker 机制优化
#当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。 acks #请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性 retries #每个分区未发送消息总字节大小,单位:字节,超过设置的值就会提交数据到服务端,默认值是16KB batch.size # 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满,如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端 # 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求 #如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送 linger.ms
-
Linux服务器常见网络内核参数配置和修改讲解#
简介: Linux服务器常见内核参数配置和修改讲解
-
Linux性能优化特别广,只讲最常见最高频需要知道的
-
备注
- 本章部分内容整理来自阿里云ESC官方和社区文档
- 这里感谢声明下 阿里云 运营和技术的同学
- 方便大家更好学习相关技术,并结合阿里云生产环境进行练习
-
-
在修改内核参数前,需要注意以下几点:
-
从实际需求出发,尽量有相关数据的支撑,不建议随意调整内核参数。
-
了解参数的具体作用,需注意同类型或版本的环境中,内核参数可能有所不同
-
如果是使用云服务器,厂商那边多数的配置是满足很多业务的需求了
-
除非自己对业务特性和相关参数特别了解,否则不建议修改
-
-
查看内核参数
- 执行
sysctl -a命令,查看当前系统中生效的所有参数 - sysctl -a 显示参数特别多,常规加 grep 过滤下
- 执行
-
两种修改Linux实例内核参数
- 方法一:通过/proc/sys/目录查看和修改内核参数
- /proc/sys/目录是Linux内核在启动后生成的伪目录,
- 目录下的net文件夹中存放了当前系统中开启的所有内核参数,目录树结构与参数的完整名称相关
- 比如
net.ipv4.tcp_tw_recycle,它对应的文件是/proc/sys/net/ipv4/tcp_tw_recycle文件,文件的内容就是参数值- 查看内核参数
net.ipv4.tcp_tw_recycle的值,命令cat /proc/sys/net/ipv4/tcp_tw_recycle - 修改内核参数
net.ipv4.tcp_tw_recycle的值,命令echo "0" > /proc/sys/net/ipv4/tcp_tw_recycle
- 查看内核参数
- 方法二:通过sysctl.conf文件查看和修改内核参数
- 修改
/etc/sysctl.conf文件中的参数:vim /etc/sysctl.conf - 执行命令使配置生效.
/sbin/sysctl -p
- 修改
- 方法一:通过/proc/sys/目录查看和修改内核参数
-
Linux文件句柄数限制优化
- 啥是Linux文件句柄
* 在linux系统设计里面遵循一切都是文件的原则,即磁盘文件、目录、网络套接字、磁盘、管道等 * 所有这些都是文件,进行打开的时候会返回一个fd,即是文件句柄 * 如果频繁的打开文件,或者打开网络套接字而忘记释放就会有句柄泄露的现象 * 在linux系统中对进程可以调用的文件句柄数进行了限制,在默认情况下每个进程可以调用的最大句柄数是1024个 * 如果超过了这个限制进程将无法获取新的句柄,而从导致不能打开新的文件或者网络套接字,对于线上服务器即会出现服务被拒绝的情况。 * 遇到文件句柄达到上限时,会碰到`Too many open files`或者 `Socket/File: Can’t open so many files`等错误-
修改方式
-
局部文件句柄数(单个进程最大打开文件数)
ulimit -n一个进程最大打开的文件数 fd, 不同系统有不同的默认值- 编辑
vim /etc/security/limits.conf文件末尾增加
* hard nofile 100000 * soft nofile 100000- 其中
*代表所有用户,100000代表修改的值,修改以后需要重新登录才能生效
-
全局文件句柄数(所有进程所能够创建的文件句柄数)
- 查看全局文件句柄数:cat /proc/sys/fs/file-max
- 编辑
/etc/sysctl.conf,在文件末尾加上:fs.file-max=10000000000 - 使配置文件生效:sysctl -p
-
-
注意
- 一般修改进程级的最大打开文件句柄数即可(很多系统默认1024,有点小)
- 一般不需要调整系统级的最大数,局部文件句柄数一定不要超过全局文件句柄数
-
Linux常见的网络内核参数说明(backlog的中文意思理解为存储)
描述 net.core.rmem_default 默认的TCP数据接收窗口大小(字节)。 net.core.rmem_max 最大的TCP数据接收窗口(字节)。 net.core.wmem_default 默认的TCP数据发送窗口大小(字节)。 net.core.wmem_max 最大的TCP数据发送窗口(字节)。 net.core.netdev_max_backlog 当内核处理速度比网卡接收速度慢时,这部分多出来的包就会被保存在网卡的接收队列上,而该参数说明了这个队列的数量上限。
在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。net.core.somaxconn 该参数定义了系统中每一个端口最大的监听队列的长度,是个全局参数。
该参数和net.ipv4.tcp_max_syn_backlog有关联,后者指的是还在三次握手的半连接的上限,该参数指的是处于ESTABLISHED的数量上限。当backlog大于net.core.somaxconn时,以net.core.somaxconn参数为准。net.ipv4.tcp_keepalive_time TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。 net.ipv4.tcp_syncookies 默认值0表示关闭。
当该参数被设置为1,且SYN_RECV队列满了之后,内核会对SYN包的回复做一定的修改,即在响应的SYN+ACK包中,初始的序列号是由源IP+Port、目的IP+Port及时间这五个参数共同计算出一个值组成精心组装的TCP包。由于ACK包中确认的序列号并不是之前计算出的值,恶意攻击者无法响应或误判,而请求者会根据收到的SYN+ACK包做正确的响应。
启用net.ipv4.tcp_syncookies后,会忽略net.ipv4.tcp_max_syn_backlog。net.ipv4.tcp_tw_reuse 表示是否允许将处于TIME-WAIT状态的Socket(TIME-WAIT的端口)用于新的TCP连接。 net.ipv4.tcp_tw_recycle 能够更快地回收TIME-WAIT套接字。 net.ipv4.tcp_fin_timeout 对于本端断开的Socket连接,TCP保持在FIN-WAIT-2状态的时间(秒)。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。 net.ipv4.ip_local_port_range 表示TCP/UDP协议允许使用的本地端口号。 net.ipv4.tcp_max_syn_backlog 该参数决定了系统中处于 SYN_RECV状态的TCP连接数量。SYN_RECV状态指的是当系统收到SYN后,作为SYN+ACK响应后等待对方回复三次握手阶段中的最后一个ACK的阶段。对于还未获得对方确认的连接请求,可保存在队列中的最大数目。如果服务器经常出现过载,可以尝试增加这个数字。默认值大小会受实例内存的影响,默认值最大为2048。net.ipv4.tcp_max_tw_buckets 该参数设置系统的TIME_WAIT的数量,如果超过默认值则会被立即清除
tcp_max_tw_buckets默认值大小会受实例内存的影响,最大值为262144。net.ipv4.tcp_synack_retries 指明了处于SYN_RECV状态时重传SYN+ACK包的次数。 net.ipv4.tcp_abort_on_overflow 设置该参数为1时,当系统在短时间内收到了大量的请求,而相关的应用程序未能处理时,就会发送Reset包直接终止这些链接。建议通过优化应用程序的效率来提高处理能力,而不是简单地Reset。默认值为0。
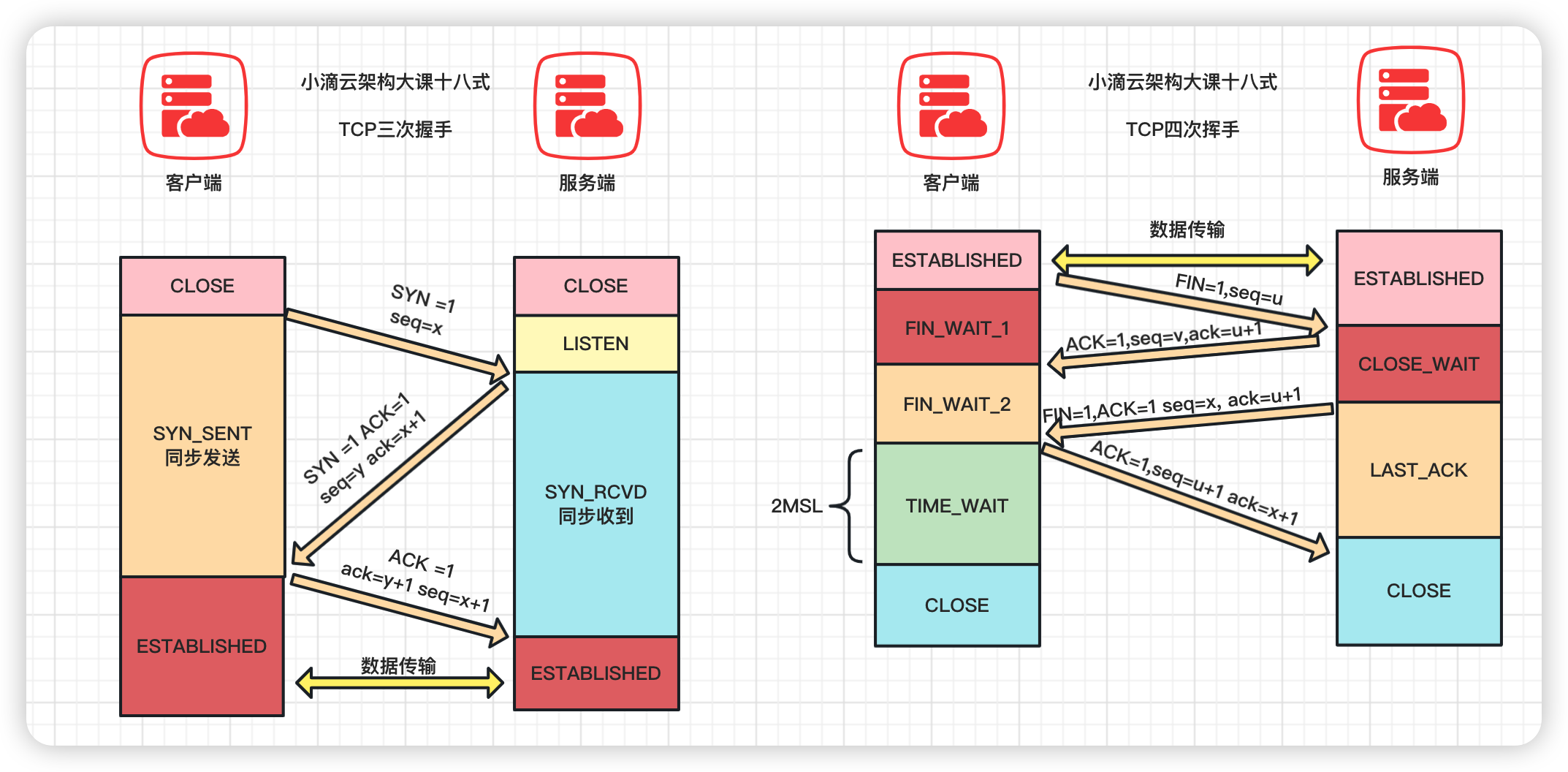
Linux服务器生产环境常见问题案例分析《上》#
简介: Linux服务器生产环境常见问题案例分析
- 背景
- 基于TCP三次握手和四次挥手的内容,进行案例分析找出相关影响参数
- 注意
- 这些是生产环境里面高频的问题点,即线上故障
- 也是面试里面高频的 生产环境网络方向问题诊断-场景案例面试题
-
生产环境Linux服务问题一
-
现象
- 业务突然访问不了,诊断出是网络方向的问题
- Linux实例的
/var/log/messages日志信息全是类似“kernel: TCP: time wait bucket table overflow”的报错信息 - 提示“
time wait bucket table”溢出
-
原因分析
- 参数
net.ipv4.tcp_max_tw_buckets可以调整内核中管理TIME_WAIT状态的数量 - 当实例中处于TIME_WAIT状态,需要转换为TIME_WAIT状态的连接数之和超过
net.ipv4.tcp_max_tw_buckets参数值 - messages日志中将报“
time wait bucket table” 错误,同时内核关闭超出参数值的部分TCP连接 - 根据实际情况适当调高
net.ipv4.tcp_max_tw_buckets参数,同时从业务层面去改进TCP连接。
- 参数
-
解决方案
- 统计TCP连接数
netstat -atnp |grep tcp |wc -l,如果确认连接使用很高,容易超出限制 vim /etc/sysctl.conf, 增加net.ipv4.tcp_max_tw_buckets参数值的大小- 执行
sysctl -p命令,使配置立刻生效
- 统计TCP连接数
-
-
生产环境Linux服务问题二
- 现象
- 业务突然访问不了,诊断出是网络方向的问题
- Linux实例中FIN_WAIT2状态的TCP链接过多
- 原因分析
- 在HTTP服务中,Server由于某种原因会主动关闭连接,作为主动关闭连接的Server就会进入FIN_WAIT2状态。
- 如果Client不关闭,FIN_WAIT2状态将保持到系统重启,越来越多的FIN_WAIT2状态会致使内核Crash。
- 建议调小
net.ipv4.tcp_fin_timeout参数的值,加快系统关闭处于FIN_WAIT2状态的TCP连接 - TCP连接处于
FIN_WAIT2状态,下一步会进入TIME_WAIT状态
- 解决方案
- 统计 TCP处于连接的数量
netstat -atn|grep FIN_WAIT2|wc -l - 执行
vim /etc/sysctl.conf命令,调整net.ipv4.tcp_fin_timeout = 30- 阿里云ECS默认是60秒,查看
sysctl -a | grep net.ipv4.tcp_fin_timeout
- 阿里云ECS默认是60秒,查看
- 执行
sysctl -p命令,使配置立刻生效
- 统计 TCP处于连接的数量
- 现象
Linux服务器生产环境常见问题案例分析《下》#
简介: Linux服务器生产环境常见问题案例分析
-
生产环境Linux服务问题三
- 现象
- 业务突然访问不了,诊断出是网络方向的问题
- Linux实例中出现大量CLOSE_WAIT状态的TCP连接
- 原因分析
- 根据机器的业务量判断CLOSE_WAIT数量是否超出了正常的范围
- TCP连接断开时需要进行四次挥手,TCP连接的两端都可以发起关闭连接的请求
- 如果对端发起了关闭连接,但本地没有关闭连接,那么该连接就会处于CLOSE_WAIT状态
- 虽然该连接已经处于半开状态,但是已经无法和对端通信,需要及时的释放该连接
- 建议从业务层面及时判断某个连接是否已经被对端关闭,即在程序逻辑中对连接及时关闭,并进行检查
- 解决方案
- 编程语言中对应的读、写函数一般包含了检测CLOSE_WAIT状态的TCP连接功能,
- 查看处于CLOSE_WAIT状态的连接数
netstat -atnp|grep CLOSE_WAIT|wc -l - 比如是java业务,检查相关IO操作是否有正常关闭
- 通过
read方法来判断I/O ,当read方法返回-1时,则表示已经到达末尾 - 通过
close方法关闭该连接
- 通过
- 现象
-
生产环境Linux服务器问题四
-
现象
- 业务突然访问不了,诊断出是网络方向的问题
- 存在大量处于TIME_WAIT状态的连接
-
原因分析
- 主动发起关闭的一端,在发送最后一个ACK之后会进入time_wait的状态
- 该发送方会保持2MSL时间之后才会回到初始状态,MSL值是数据包在网络中的最大生存时间
- 处于这个状态的TCP连接在2MSL等待期间,定义这个连接的四元组 客户端IP和端口,服务端IP和端口号 不能被使用
-
解决方案
- 查看处于TIME_WAIT状态的连接数
netstat -atnp|grep TIME_WAIT|wc -l - 执行
vim /etc/sysctl.conf命令,调整参数
#开启SYN的cookies,当出现SYN等待队列溢出时,启用cookies进行处理 net.ipv4.tcp_syncookies = 1 #允许将TIME-WAIT的socket重新用于新的TCP连接 net.ipv4.tcp_tw_reuse = 1 #开启TCP连接中TIME-WAIT的sockets快速回收功能 net.ipv4.tcp_tw_recycle = 1 #如果socket由服务端要求关闭,则该参数决定了保持在FIN-WAIT-2状态的时间。 net.ipv4.tcp_fin_timeout = 30- 执行
sysctl -p命令,使配置立刻生效 - 除了的减少TIME_WAIT状态的连接,也可以通过扩大端口范围和对TIME_WAIT的bucket进行扩容等手段优化系统性能
- 查看处于TIME_WAIT状态的连接数
-
Linux网络IO模型#
常见的网络IO模型和BIO-NIO介绍#
-
网络IO
-
网络IO模型的话题就从未间断,无论是平时还是面试
-
IO有磁盘IO、网络IO,侧重点是网络IO,用户程序从网络中获取数据
-
IO操作分两步
- 发起IO请求等待数据准备
- 实际IO操作
-
基于前面讲的知识点,应用程序从网络Socket获取数据的步骤
- 客户端和服务器通过TCP三次握手成功
- 用户程序通过系统调用 转变为 内核态
- 操作系统等待发送端发送相关数据
- 发送端发送数据后,接受端的操作系统从网卡设备获取数据
- DMA把网卡Socket Buffer中读取客户端发送的数据到内核缓冲区
- CPU把内核缓冲区的数据拷贝到用户缓冲区
- 用户程序获取到数据进行相关处理
-
-
常见的IO的模型
-
BIO (Blocking I/O) 同步阻塞I/O
-
NIO (Non-blocking IO)同步非阻塞IO
-
IO 多路复用(IO multiplexing )同步非阻塞
-
AIO ( Asynchronous I/O)异步非阻塞I/O
-
-
什么是 BIO (Blocking I/O) 同步阻塞I/O
-
应用程序在执行系统调用后,一直处于阻塞状态,直到内核数据拷贝到用户空间
-
同一时刻只能处理一个操作效率低,使用多进程/多线程的方式使得服务端能够和多个客户端连接通信
-
每个请求都会开启一个线程处理,高并发时 服务端会用大量的线程来处理多个Socket
-
优点
- 技术实现简单,来一个请求开启一个线程处理
-
缺点
- 产生大量线程处于阻塞状态,大量线程进行上下文切换,严重浪费CPU
-
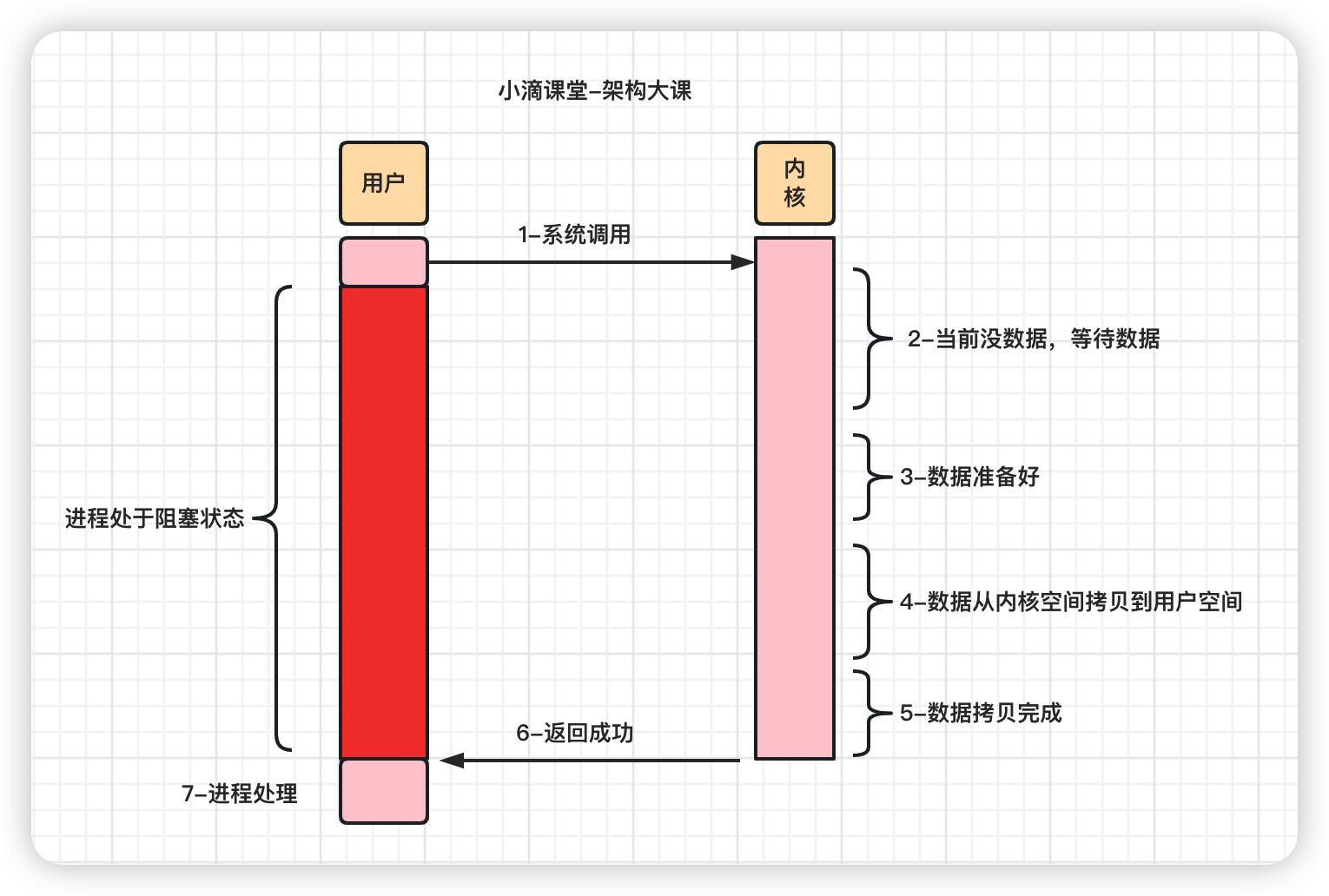
-
什么是 NIO (Non-blocking IO)非阻塞IO
- 应用程序通过 recvfrom系统调用,如果当前数据还没有准备好会立即返回,然后再次进行系统调用,反复询问数据是否准备好
- 应用程序发送一个读取 IO 的请求,如果数据还没有从网卡写入内核空间,直接返回未就绪
- 如果数据准备好,当前进程进入阻塞转态,把数据从内核空间拷贝到用户空间,进程阻塞结束进行处理数据
- 优点
- 做到不需要程序死等到结果,在数据没有准备好的的时候,进程没有阻塞
- 缺点
- 使用轮询的方式,通过 系统调用判断数据是否准备好,会发生多次用户态到内核态的切换
- 如果数据没准备好,会重复多次发出同样请求,浪费CPU资源
最高频使用的网络IO模型-IO多路复用#
-
背景
-
BIO为每个请求创建一个线程,且线程会阻塞等待数据的完成,大量的线程导致CPU上下文切换浪费资源
-
NIO 在数据未准备好的时候,会反复通过系统调用确认数据,也会让CPU上下文切换浪费资源
-
解决方案
- 使用一个线程处理 N 个 IO 请求,没有上下文切换和线程的创建和销毁,程序会更快,这就是 IO 多路复用的思路
-
-
IO 多路复用(实际开发中最多)
- I/O是指网络I/O, 多路指多个TCP连接(即socket或者channel),复用指复用一个或几个线程
- 简单来说
- 就是使用一个或者几个线程处理多个TCP连接,最大优势是减少系统开销小
- 不必创建过多的进程/线程,也不必维护这些进程/线程,大大减少资源占用
- 类似于非阻塞 IO ,但轮询不是由用户线程去执行,而是由内核去轮询
- 内核监听到数据准备好后,通知内核程序复制数据到用户态
- 在多路复用IO模型中,有一个内核线程不断地去轮询多个 socket连接的状态,当真正读写事件发生时,才调用实际的IO读写操作
- 关键点:
- 轮询多个Socket数据是否准备好,放在内核空间执行,内核负责轮询所有socket是否可用 避免用户态和系统态的切换
- 通过一种机制,可以监视多个描述符,一旦某个描述符就绪,就通知程序进行相应的读写操作
- 多路复用的模式有
select、poll、epoll三种,每种模式特点不一样 - 案例
- 当用户进程调用了 select,那么整个进程会被 block,同时kernel 会“监视”所有 select 负责的 socket
- 当任何一个socket的数据准备好 select 就会返回,这时用户进程再调用 read 操作,将数据从内核空间拷贝到用户空间
- 多路复用的模式有
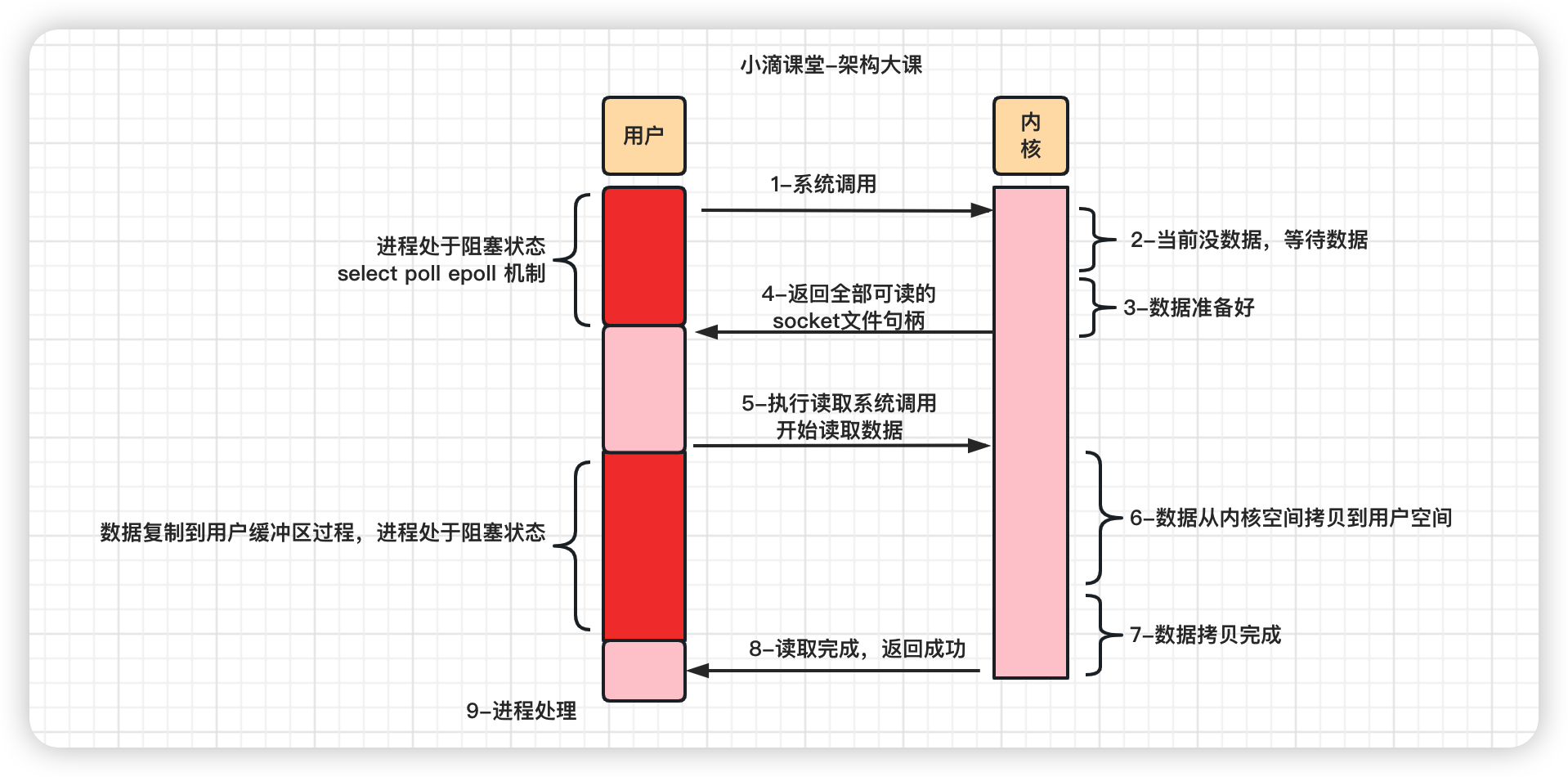
IO多路复用的select-poll-epoll机制#
- 多路复用的模式有
select、poll、epoll三种,每种模式特点不一样
| select | poll | epoll | |
|---|---|---|---|
| 查找模式 | 遍历 | 遍历 | 回调 |
| 底层结构 | bitmap | 链表 | 红黑树 |
| 最大值 | x86架构32位系统最大1024 x64架构64位系统最大2048 |
无限制 | 无限制,1G内存大概支持10万个句柄fd |
| IO效率 | 每次调用,线性遍历,时间复杂度O(n) | 每次调用,线性遍历,时间复杂度O(n) | 当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到列表里,时间复杂度O(1) |
| 备注 | 每次调用,需要把全部的fd从用户空间拷贝到内核空间。 几乎在所有的平台上支持,跨平台支持性好 |
每次调用,需要把全部的fd从用户空间拷贝到内核空间 | 在Linux2.6版本内核新增,用户态拷贝到内核态只需要一次,使用事件通知,通过epoll_ctl( ) 函数注册fd,一旦该fd就绪,内核就会采用callback的回调机制来激活对应的fd |
- 案例
- 100万个连接,里面有1万个连接是活跃,在 select、poll、epoll分别是怎样的表现
- select:不修改宏定义,则需要 1000个进程才可以支持 100万连接
- poll:100万个链接,遍历都响应不过来了,还有空间的拷贝消耗大量的资源
- epoll: 通过 epoll_create、epoll_ctl、epoll_wait 完成操作,大量连接里面少数活跃则性能最高
- 100万个连接,里面有1万个连接是活跃,在 select、poll、epoll分别是怎样的表现
- 总结
- poll的实现和select非常相似,只是文件描述符容量不同, 也都是主动轮训查找
- poll和select共同存在缺点,大量文件描述符需要整体复制,在用户态和内核的空间拷贝,资源开销随fd数量的增加而线性增大
- epoll同poll一样 没有文件句柄的数量限制,是select和poll的增强版本
- 熟悉的nginx在Linux2.6以后的内核中用的IO模型是epoll
AIO 异步非阻塞I/O介绍和网络IO模型总结#
- AIO ( Asynchronous I/O)异步非阻塞I/O
- 用户进程进行 aio_read 系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程
- 用户态进程可以去做别的事情,等到 socket 数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知
- IO 两个阶段,进程都是非阻塞的,异步 IO 才是真正的非阻塞
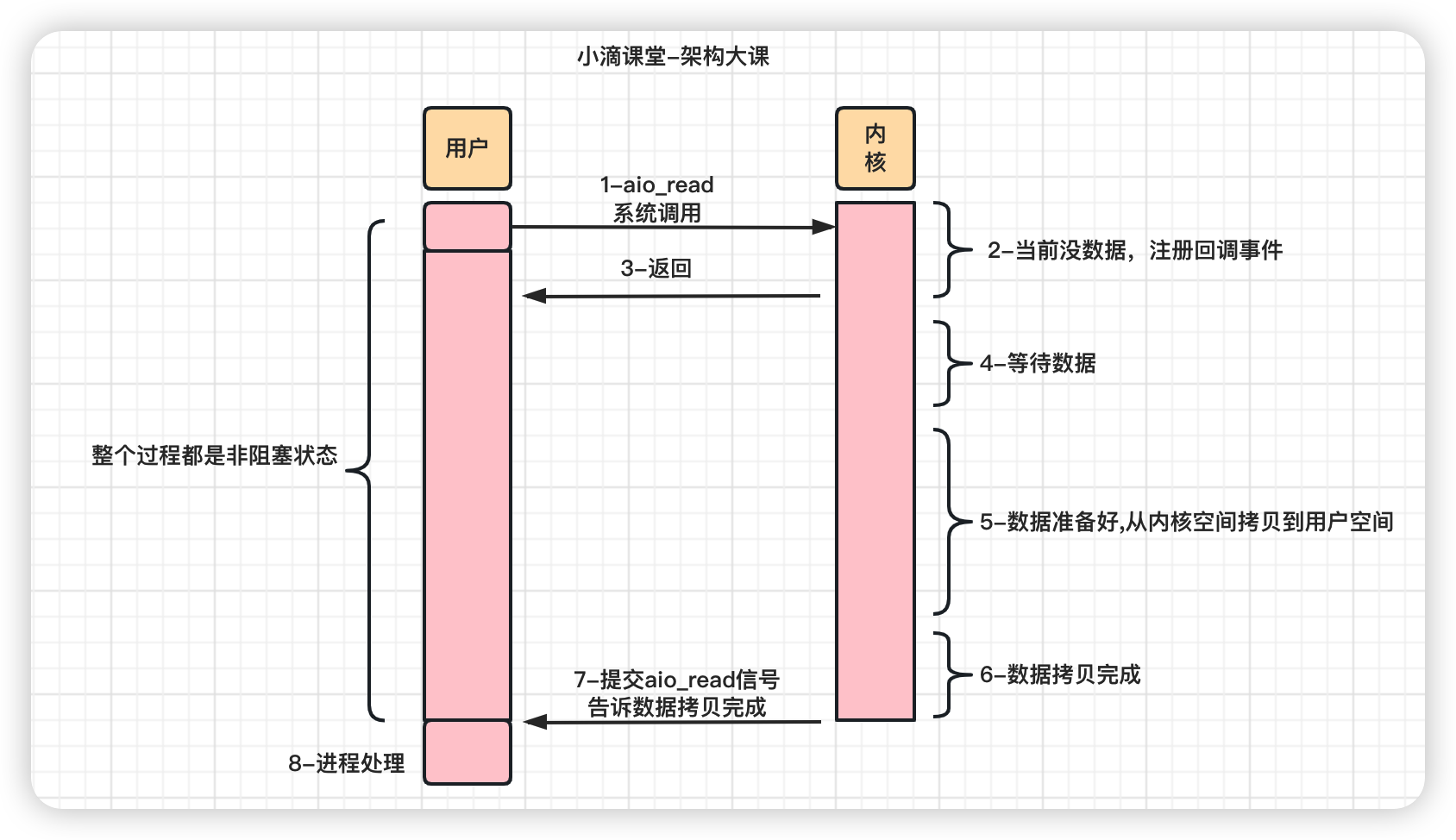
-
常见的IO的模型
-
BIO 、NIO 、IO 多路复用、AIO,也有其他模型
-
IO可以分为两个阶段
- 阶段一 :判断数据有没有准备好,即Socket是否就绪
- 阶段二 :在数据准备好以后,执行真正的读写操作,将数据从内核空间拷贝到用户空间
-
虽然有多种IO模型,但是需要系统内核支持,RPC框架一般都是IO多路复用
-
多数系统支持阻塞IO、多路复用IO,后者是目前开发采用最多的方案
-
AIO虽然强,但常规Window不支持,高版本Linux系统内核才支持
-
应用层协议DNS和智能DNS最佳实践#
走进DNS-网络世界的高德地图#
-
背景
-
Internet上当一台主机要访问另外一台主机时,必须首先获知其地址,IP中是由四段以“.”分开的数字组成
-
IPv4的地址和IPv6的地址同理,记起来总是不如名字那么方便,所以就采用了域名系统来管理名字和IP的对应关系
-
案例
-
要记住 小滴课堂、淘宝、京东 等网站
-
可以使用 ip直接访问,也可以通过域名直接访问,后者更容易记忆和维护
-
-
就比如地图上有10个位置
- 记忆方式一:记住10个位置的经纬度
- 记忆方式二:记住10个位置的中文地区地址
-
-
什么是DNS
- 域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。
- 将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网
- DNS使用域名服务器一般监听在端口 53 上
- 对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
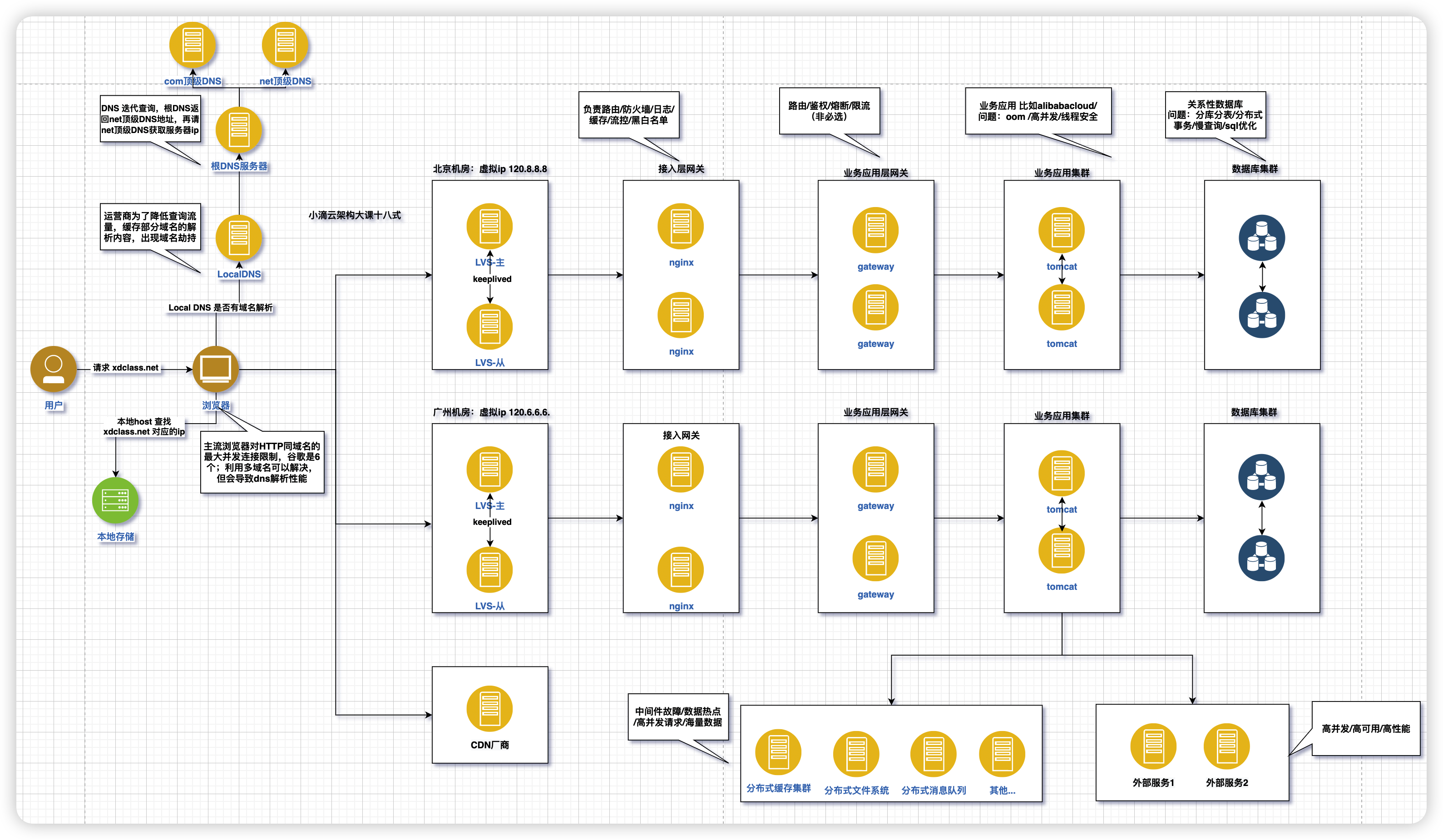
- DNS的作用
- 用途一:记录IP和域名的关系,方便查找
- 用途二:负载均衡,分摊节点压力,业务更加稳定
DNS的高级应用-负载均衡和智能调度#
-
DNS实现负载均衡
- 其实大家做过的了,微服务里面通过服务名称调用对应的服务
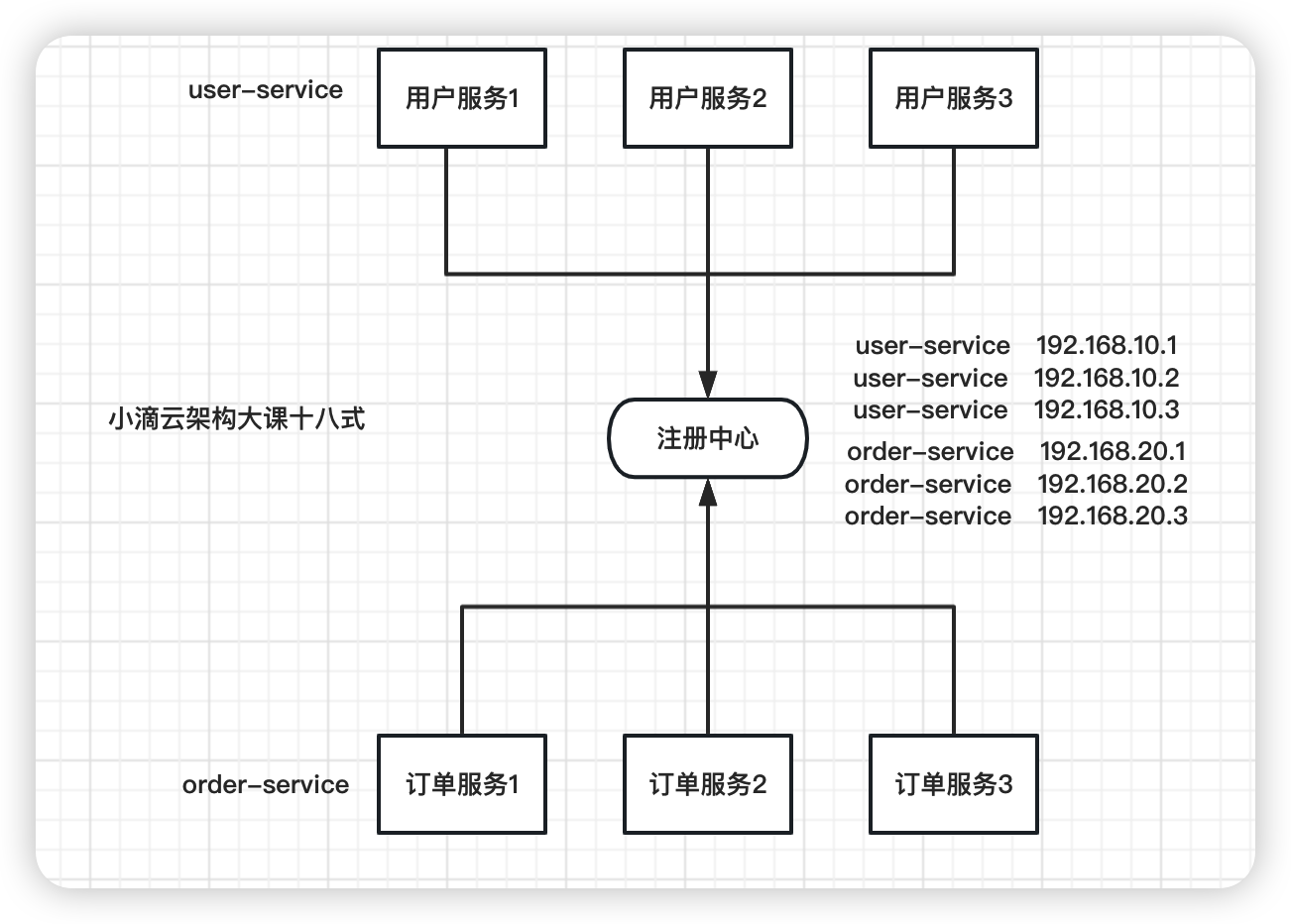
- DNS给用户返回不同的ip,可以轮训获取,可以随机获取,这个就是负载均衡
- 用途
- 数据库
- 业务链接数据库,通过ip直连接,假如数据库宕机切换到其他机器,ip发生改变,则业务需要修改数据库ip
- 如果采用内部DNS,给数据库ip配置域名解析,应用程序通过域名访问数据库,则避免数据库切换要重启应用程序
- 缺点:DNS域名解析需要时间,但是本地DNS解析耗时基本可以忽略
- 应用程序互相访问
- 通过IP或者通过域名,即上述微服务的案例
- 通过名称服务访问,避免了直连ip,维护起来更加方便,且可让业务扩容更多节点提高并发处理能力
- 故障切换
- 根据健康检查结果自动或者手工进行failover主备切换,把异常的地址剔除下线
- 数据库
-
智能DNS
-
就近原则,基于用户地理位置、运营商实现就近接入的智能解析
-
传统DNS解析,不判断访问者来源,会随机选择其中一个IP地址返回给访问者。
-
智能DNS解析,会判断访问者的来源,为不同的访问者智能返回不同的IP地址
-
可使访问者在访问网站时可获取用户指定的IP地址,能够减少解析时延,并提升网站访问速度的功效
-
案例
-
传统DNS解析示例
- 例如域名 xdclass.net,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下
- 将域名指向联通IP地址 (192.0.2.0)
- 将域名指向移动IP地址 (192.0.2.1)
- 将域名指向电信IP地址 (192.0.2.2)
- 可实现的解析效果
- 传统DNS解析不判断访问者的来源,会将192.0.2.0、192.0.2.1、192.0.2.2三个地址全部返回给访问者的LocalDNS
- 访问者的LocalDNS通过随机方式将其中一个IP地址返回给访问者,传统DNS解析有可能会造成访问者跨网访问
- 例如域名 xdclass.net,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下
-
智能DNS解析示例
- 例如域名 xdclass.net,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下:
- 解析线路配置 默认线路 指向 联通IP地址 (192.0.2.0)
- 解析线路配置 移动线路 指向 移动IP地址 (192.0.2.1)
- 解析线路配置 电信线路 指向 电信IP地址 (192.0.2.2)
- 可实现的解析效果
- 云解析会判断访问者的来源,为来源于移动运营商的访问者云解析返回 192.0.2.1 的解析地址
- 为来源于电信运营商的访问者云解析返回 192.0.2.2 的解析地址,其他来源访问者云解析返回192.0.2.0 解析地址
- 例如域名 xdclass.net,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下:
-
-
目标业界的多数云厂商都支持了智能DNS
-
高级实战智能DNS的最佳实践-环境准备#
简介: 高级实战智能DNS的最佳实践-环境准备
-
智能DNS实战环境准备
-
基于阿里云智能DNS,文档地址 https://help.aliyun.com/document_detail/29730.html
- 其他云厂商类似操作,腾讯云,华为云,亚马逊云等,会一个操作另外的都容易
-
备案域名准备
-
自己购买域名并且备案成功,才可以正确访问和使用
-
阿里云ECS服务器
- 使用按量付费方式购买2台不同区域的服务器
- 购买时长 1~3小时即可,验证完成这个功能即可释放服务器,不用再付费用
- 配置:1核1g,centos7.x 即可
- 注意:要不同区域的服务器,通过解析才可以验证 就近原则解析的最终效果
-
购买阿里云智能DNS,企业标准版(可以选购1个月,10来块钱)
-
-
实现效果
高级实战智能DNS的配置案例实战#
简介: 高级实战智能DNS的配置案例实战
-
步骤
- 进入阿里云域名控制台,配置解析
- 注意:DNS解析是有缓存,如果配置后验证未生效,则可以等待一会再进行测试
-
服务器
- 39.108.214.149 深圳机房
- 106.14.139.101 上海机房
-
效果验证
-
测试域名解析生效的方法有以下四类:
- ping 域名解析生效测试。
- 本地域名解析生效测试。
- 测试命令dig或nslookup。
- 全国各地运营商解析生效测试。
-
因为没法在多个城市进行访问,所以直接登录ECS所在的机器,进行ping 对应的域名,即可验证效果
- 常用的在线测试工具: https://boce.aliyun.com/detect/http
-
- 进入阿里云域名控制台,配置解析
-
总结
-
智能DNS可以解决不同地域的客户端智能返回不同的加速IP,降低解析时延
-
配置多节点解析,达到负载均衡,分摊节点压力,业务更加稳定
-
拓展
-
在一些多国家的全球业务里面,让全球用户都能获得较好的访问质量
-
企业会在中国大陆和海外分别部署多套以上的接 入服务点,但是后端数据服务仍然使用一套
-
利用通过DNS服务,对于不同地区的用户请求流量做智能调度,将用户访请求流量路由至不同的接入服务点
-
当然也有企业会根据业务所在国家的政策进行单独部署业务和机房,也包括使用的子域名进行处理,比如
- 印尼等多个国家,不允许其他非本国业务把数据存储在外地
- 大家知道的Apple公司的 云上贵州数据中心 等
- 阿里跨境业务 lazada不同国家的站点
- 越南 lazada.vn
- 新加坡 lazada.sg
- 马来西亚 lazada.com.my
- 泰国 lazada.co.th
- 菲律宾. lazada.com.ph
- 印度尼西亚. lazada.co.id
-
-
应用层协议HTTP核心知识#
应用协议HTTP的从0到1核心内容#
简介: 应用协议HTTP的从0到1核心内容
-
前言
- 经过前面的内容,看到这里大家可以松一口气啦
- 相对前面内容,这几集大家就轻松些了,毕竟HTTP大家是用最多的
-
什么是http协议
- 超⽂本传送协议(Hypertext Transfer Protocol ),是Web联⽹的基础,也是⼿机PC联⽹常⽤的协议之⼀
- 建⽴在TCP协议之上的⼀种应⽤,HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应
- 从建⽴连接到关闭连接的过程称为“⼀次连接”
- HTTP经过 20 多年的演进出现过 0.9、1.0、1.1、2.0、3.0 五个主要版本

-
快速掌握基础知识点
-
Http请求消息结构
- 请求行
- 请求方法
- URL地址
- 协议名
- 请求头
- 报文头包含若干个属性 格式为“属性名:属性值”,
- 服务端据此获取客户端的基本信息
- 请求体
- 请求的参数,可以是json对象,也可以是前端表单生成的key=value&key=value的字符串
- Http响应消息结构
- 响应行
- 报文协议及版本、状态码
- 响应头
- 报文头包含若干个属性 格式为“属性名:属性值”
- 响应正文
- 响应报文体,我们需要的内容,多种形式比如html、json、图片、视频文件等
- 响应行
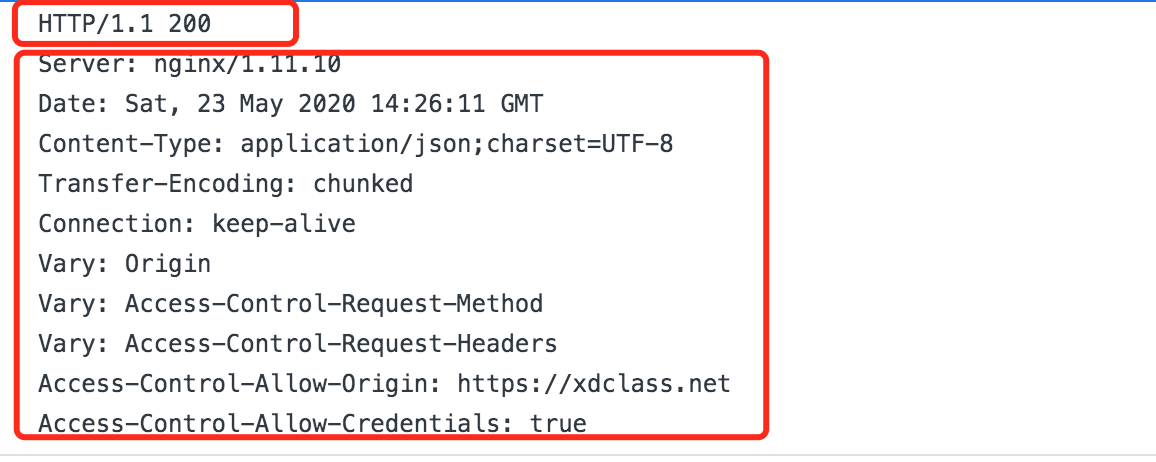
- 请求行
-
响应码
- 1XX: 收到请求,需要请求者继续执行操作,比较少用
- 2XX: 请求成功,常用的 200
- 3XX: 重定向,浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取;
- 好处:网站改版、域名迁移等,多个域名指向同个主站导流
- 必须记住
- 301:永久性跳转,比如域名过期,换个域名
- 302:临时性跳转
- 4XX: 客户端出错,请求包含语法错误或者无法完成请求
- 必须记住
- 400: 请求出错,比如语法协议
- 403: 没权限访问
- 404: 找不到这个路径对应的接口或者文件
- 405: 不允许此方法进行提交,Method not allowed,比如接口一定要POST方式,而你是用了GET
- 必须记住
- 5XX: 服务端出错,服务器在处理请求的过程中发生了错误
- 必须记住
- 500: 服务器内部报错了,完成不了这次请求
- 503: 服务器宕机
- 必须记住
-
缝缝补补几十年-HTTP的艰苦创业史#
简介: 缝缝补补几十年-HTTP的艰苦创业史
-
背景
- 为啥要掌握这个?更充分的掌握HTTP的特性
- 虽然版本到了HTTP3.0,但多数企业项目都是HTTP1.1和HTTP2.0之间
- 未来肯定会普及更多项目,和方便后续进阶学习
-
HTTP经过 20 多年的演进出现过 0.9、1.0、1.1、2.0、3.0 五个主要版本
-
迭代历史
- HTTP/0.9
- 只支持 GET 请求方式,不支持其它
- 不支持请求头 Header,只支持HTML字符串
- TCP连接特性
- 服务端相响应完成,立刻关闭 TCP 连接
- HTTP/1.0
- 请求方式新增了 POST、HEAD 等多种方法
- 增加请求头和响应头,支持更丰富的内容,定制化更强(大部分目前使用)
- 拓展数据传输内容格式,支图片,音频,视频,二进制流等(大部分目前使用)
- TCP连接特性
- 建立 TCP 连接不能复用,每个 TCP 连接只能发送一个请求,数据发送完毕连接就关闭
- 还要请求其他资源,须重新建立连接, 由于建立连接成本很高,性能不理想
- HTTP/1.1 (目前使用最广泛)
- 支持更多请求方法,增加了PUT、PATCH、OPTIONS、DELETE 等请求方式;(大部分目前使用)
- TCP连接特性
- 请求头新增 Connection 字段,设置 Keep-Alive 值保持连接不断开,即响应头加入这行代码:Connection:keep-alive
- Keep-Alive 不会永久保持连接,有一个保持时间,实现长连接需要客户端和服务端都支持长连接
- HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
- TCP 连接默认不关闭,可以被多个请求复用,是此版本最重要的优化
- 同一个 TCP 连接中,客户端可以同时发送多个请求,提升了 HTTP 协议的传输效率
- 请求头新增 Connection 字段,设置 Keep-Alive 值保持连接不断开,即响应头加入这行代码:Connection:keep-alive
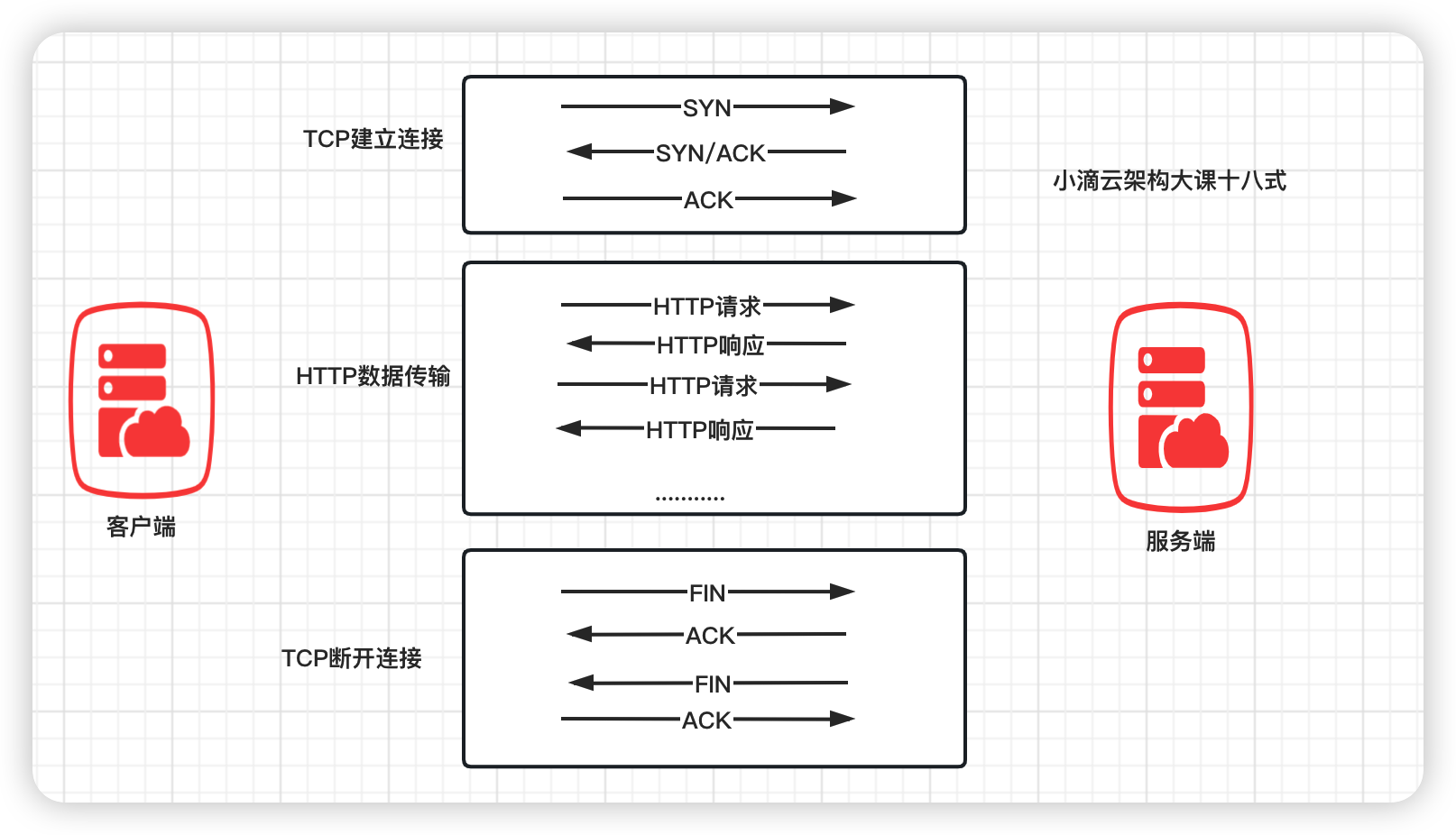
-
HTTP/2.0
-
二进制分帧,1.x 是文本协议,2.0 是以二进制帧为基本单位,使用二进制编码来代替传统的文本编码,可以更有效地传输数据
-
多路复用,可以在单一的TCP连接上同时传输多个请求/响应消息,从而节省连接时间。
-
服务器推送,允许服务器主动推送资源给客户端,从而提高网页加载速度
-
Header压缩,使用HPACK压缩格式对头部进行压缩,从而减少请求/响应消息的体积。
- 之前每次发送都要带相同的 Header,冗余比较多,新版对头部信息进行增量更新,有效减少了头部数据的传输
- 每个网页平均包含 100 多个 HTTP 请求,每个请求头平均有 300-500 字节,数据量达到几十 KB 以上
- 上述说的多个请求头之间通常几乎没有变化,但是过多重复的头导致性能下降
- 在 2版本的 HPACK 算法出现前,旧版使用HTTP的gzip 去压缩请求
- HPACK算法简单说明
- 客户端和服务端共同维护一个 key-value 的数据存储结构
- 如果两端有发生变化时则更新传输,否则就不用重复传输
- 在首次全量传输,后续交互就是增量更新传输,更省空间
- 日常项目开发里面也很多采用的方案
- 比如浏览器缓存等,计算相关数据hash值是否变动,未变动则不用重新请求
-
更好的请求优先级,允许客户端为请求设定优先级,从而更好地控制请求的执行顺序。
-
性能测试
-
- HTTP/0.9
-
HTTP/3.0
- 采用QUIC协议,Quick UDP Internet Connections 的缩写【快速 UDP 互联网连接,】可以更快的建立连接,提高传输效率;
- 谷歌不满足HTTP2,想继续提升 HTTP 的性能,基于 UDP 来开发新一代 HTTP 协议
- 采用 TCP和UDP的优点,在 UDP 基础上改造一个具备 TCP 协议优点的新协议
- QUIC 直接把以往的 TCP的3次 和 TLS的 3握手,总共6 次交互合并成了 3 次,减少了交互次数
- 支持更多的头部字段,如X-Forwarded-For,X-Real-IP等;
- 支持更多的加密技术,如TLS 1.3,DTLS 1.2等;
- 支持更多的数据传输形式,如文件传输,流式传输,管道传输等;
- 建议:新技术都需要时间推移逐步推广
- HTTP/2.0 和 HTTPS 协议的普及度都没有预想高
- IPv4不够用,早就出现IPv6 ,但是现在依旧很少
- 采用QUIC协议,Quick UDP Internet Connections 的缩写【快速 UDP 互联网连接,】可以更快的建立连接,提高传输效率;
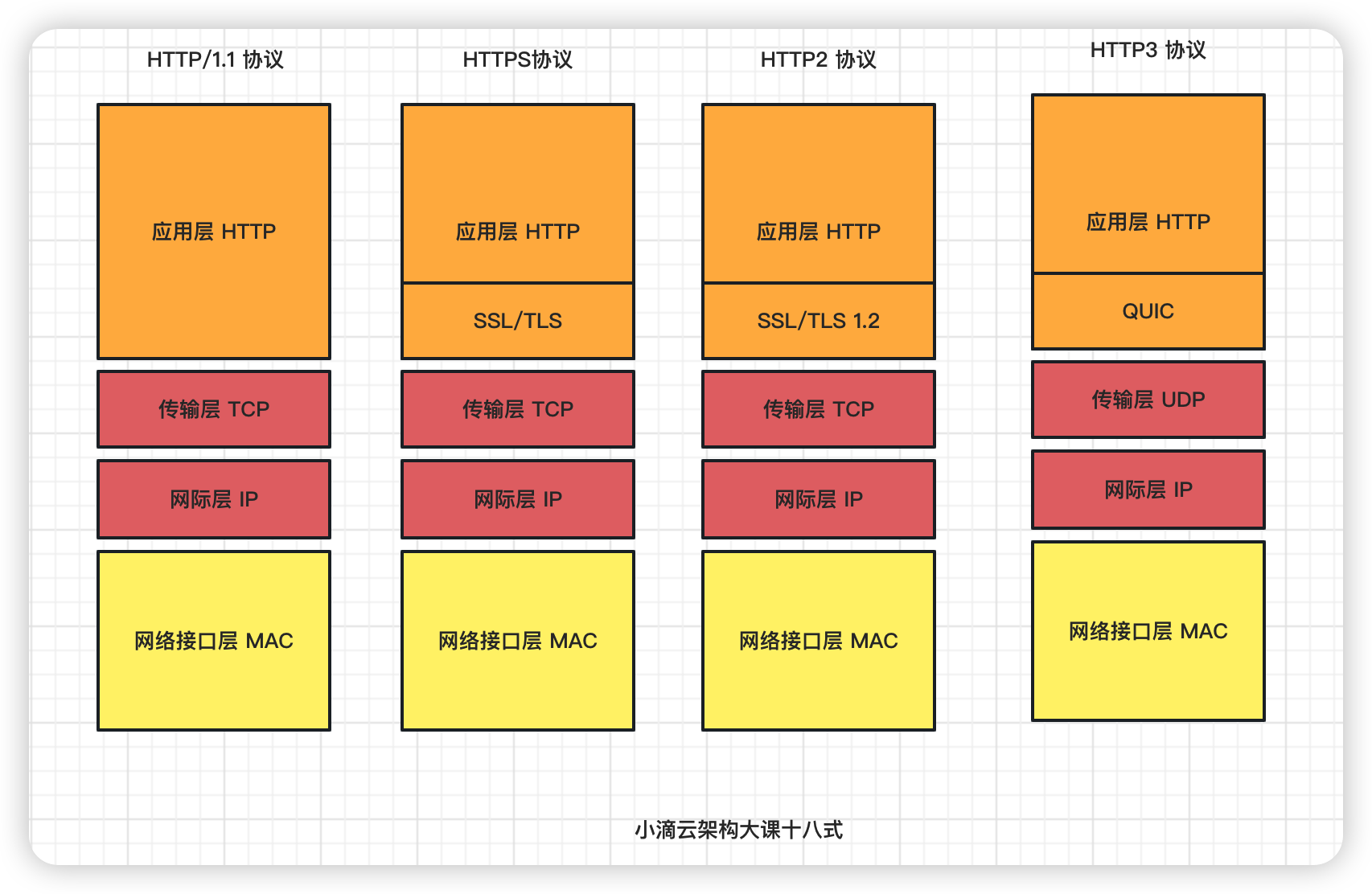
应用层协议常见的对称和非对称加密讲解#
-
背景
- 数据传输过程,要保密(防止被窃取)、完整(防止被篡改)、可用(保证授权方可以正常使用)
-
对称加密
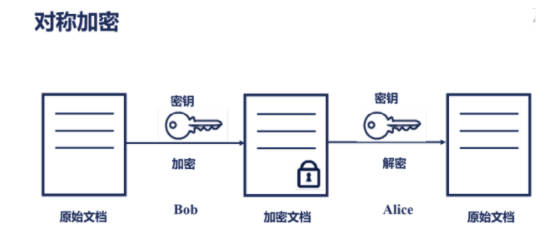
- 场景:消息发送方需要加密大量数据时使用
- 优点:操作比较简单,加密速度快, 秘钥简单
- 缺点:秘钥一旦被窃取,信息会暴露,安全性不高
- 常见的算法
- DES: 全称:Data Encryption Standard,现已被破解
- 3DES:全称: Triple Data Encryption Algorithm, 暂时未被破解
- 解释: 3DES 是在 DES 基础算法上的改良,该算法可向下兼容 DES 加密算法,但计算性能不高,暂时还未被破解
- AES: 全称:Advanced Encryption Standard,暂未被破解
-
非对称加密
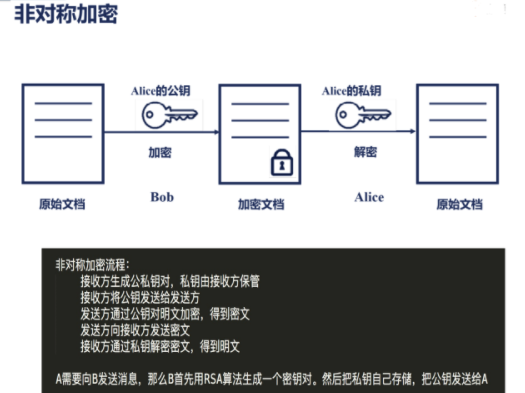
-
加密与解密的过程不是对称的,不是用的同一个秘钥,一把是公钥,一把是私钥,在加密的时候,用公钥去加密,接收方再用对应的私钥去解密
- 注意:非对称加密具有双向性,即公钥和私钥中的任一个均可用作加密,此时另一个则用作解密
-
优点:安全性更高,公钥是公开的,秘钥是自己保存的,不需要将私钥给别人
-
缺点:加密和解密花费时间长、速度慢,只适合对少量数据进行加密
-
场景: 数字签名与验证
常见的算法:RSA,DSA,ECC等,ECC也是比特币底层用的比较多的算法
-
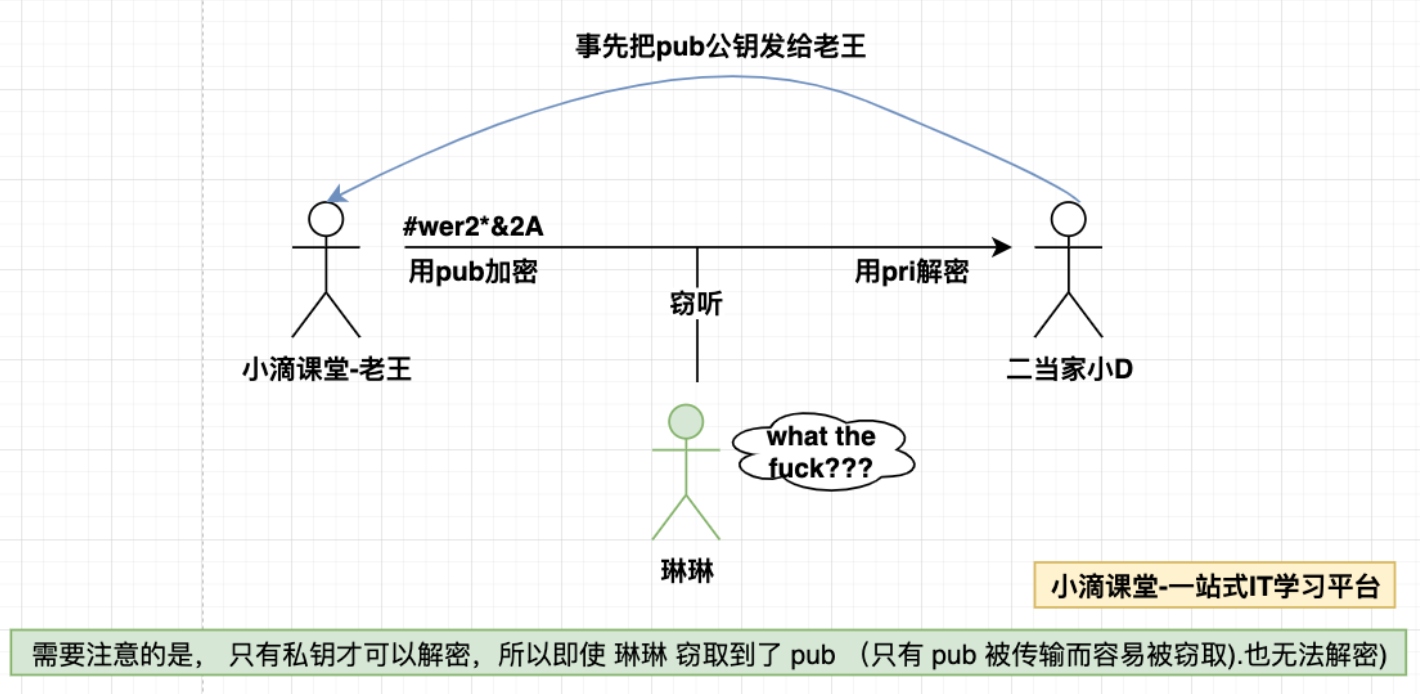
-
总结
- 对称加密:操作比较简单, 加密速度快, 秘钥简单如果泄露就危险
- 非对称加密:安全性更高,加解密复杂,但是加解密速度慢
-
业界比较多的是是对称加密和非对称加密结合使用
- 例子:小滴课堂老王和冰冰的约会那些事情
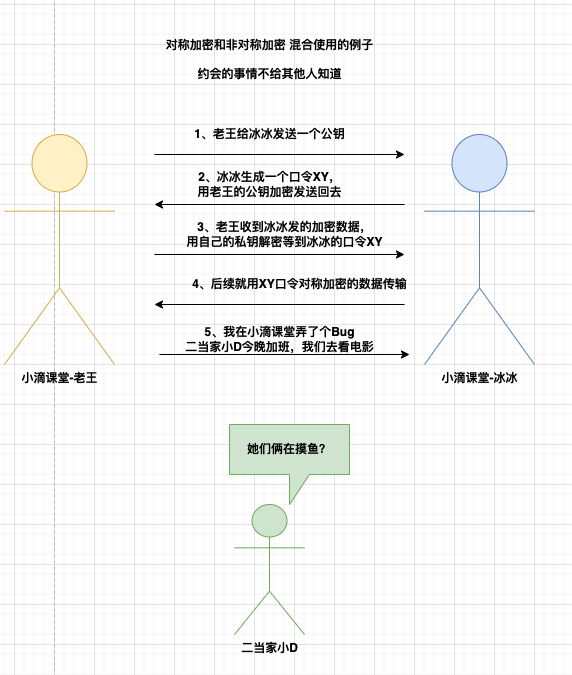
如何让数据传输更安全HTTPS的工作原理#
-
什么是HTTPS
- HTTPS (Hyper Text Transfer Protocol over SecureSocket Layer安全超文本传输协议,是身披SSL外壳的HTTP
- 主要由两部分组成:HTTP + SSL / TLS
- HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。
- 比 HTTP 协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性,增加破解成本
- 缺点:
- 同网络环境下,HTTPS 协议会使页面的加载时间延长近 50%,增加额外的计算资源消耗,增加 10%到 20%的耗电等
- 不过利大于弊,所以Https是趋势,相关资源损耗也在持续下降
- 注意:在进行通信前,会进行 TCP 的三次握手,握手完成后,再进行 TLS 的握手过程
-
为什么要用呢
- HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议
- 要比 HTTP 协议安全,可防止数据在传输过程中被窃取、改变,确保数据的完整性
-
流程
- Server端有一套权威机构颁布的数字证书(证书内容有公钥、证书颁发机构、失效日期等)
- Client端发起 HTTPS 请求,连接到服务端的 443 端口。
- Server端把自己的数字证书发送给Client端,公钥在证书里面,私钥由服务器自己存储
- Client端收到数字证书验证证书的合法性。如果证书验证通过,生成一个随机的对称密钥,用证书的公钥加密并发送给Server端
- Server端接收到Client端发来的密文后,用自己的私钥进行非对称解密,解密之后就得到Client端的对称加密的密钥
- 然后用Client端的对称加密的密钥对数据进行对称加密
- Server端将加密后的密文返回到Client端
- Client端收到后,用自己的对称密钥进行对称解密,得到服务器返回的数据
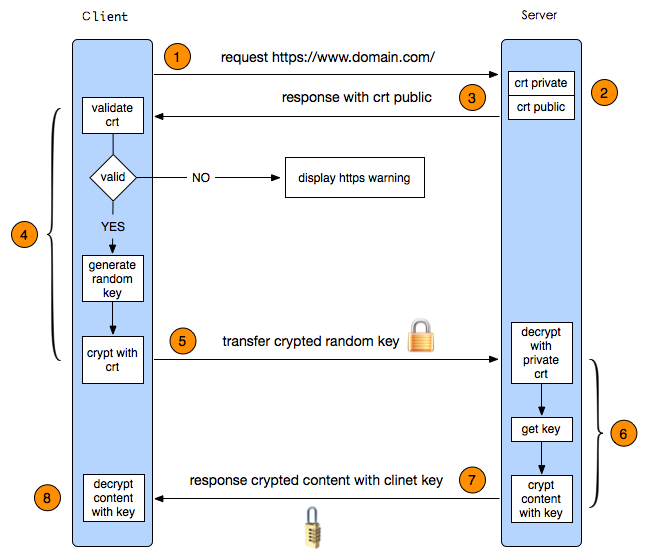
-
说明
- 服务端的证书是由 CA (Certificate Authority,证书认证机构)颁布的,CA机构类似⽹络世界⾥的公安部门
- 客户端内置 CA 对应的证书称为根证书,颁发者和使用者相同,自己为自己签名
- 客户端首先在本地电脑寻找是否有这个服务器证书上的ca机构的根证书
- 如果有继续下一步,如果没有弹出警告认为证书是非法的
- 客户端会内置信任CA的证书信息,包括CA的公钥,证书颁布验证过程也是使用非对称加密进行
- HTTPS非对称加密只作用在证书验证阶段
- 内容传输的加密上使用的是对称加密
- 既保证了秘钥的安全性,又保证了后继数据传输的数据加解密的性能
- 简单说:秘钥交换使用非对称加密,内容传输使用对称加密的方式
- 服务端的证书是由 CA (Certificate Authority,证书认证机构)颁布的,CA机构类似⽹络世界⾥的公安部门
其他#
操作系统的进程调度算法#
-
什么是进程调度
- Linux 是一个多任务操作系统,支持的任务同时运行的数量远远大于 CPU 的数量
- 进程调度 就是指【怎样安排】某一个时刻CPU运行【哪个进程】
-
进程调度类型
-
非抢占式调度 Nonpreemptive
- 一旦把处理机分配给某进程后,进程就会一直运行,直到该进程【完成】】或【阻塞】时才会把 CPU 让给其他进程
- 主要用于【批处理系统】 和 某些对【实时性要求不严】的实时系统
-
抢占式调度 Preemptive
- 暂停某个正在执行的进程,将已分配给该进程的处理机重新分配给另一个进程
- 系统同样是把处理机分配给优先权最高的进程,在其执行期间出现了另一个其优先权更高的进程
- 进程调度程序就停止当前进程的执行,重新将处理机分配给新到的优先级最高的进程
- 主要用于比较严格的【实时系统】中
-
-
算法分类
-
先来先服务调度算法(FCFS,first come first served,非抢占式)
- 按照作业/进程到达的先后顺序进行调度 ,即:优先考虑在系统中等待时间最长的作业
- 重点:排在长进程后的短进程的等待时间长,不利于短作业/进程,长进程得到CPU就执行完成了,不利于短进程
- 比如 进程一响应慢,进程二/三/四响应快,那进程一先到,其他本来很快搞定的但是没被调度到导致效率慢
-
短作业优先调度算法(SJF, Shortest Job First,非抢占式)
- 预计执行时间短的进程优先分派处理机,短进程/作业(要求服务时间最短)
- 在实际情况中占有很大比例,为了使得它们优先执行,对长作业不友好
- 重点:缩短进程的等待时间,提高系统的吞吐量
- 比如 进程一响应慢,进程二/三/四响应快,那同等时间下,更多短进程任务完成了,吞吐量也上去了
-
高响应比优先调度算法(HRRN,Highest Response Ratio Next,非抢占式)
- 在每次调度时,先计算各个作业的优先权:优先权=响应比=(等待时间+要求服务时间)/要求服务时间
- 因为等待时间与服务时间之和就是系统对该作业的响应时间,所以 优先权=响应比=响应时间/要求服务时间
- 选择优先权高的进行服务需要【计算优先权信息,增加了系统的开销】是介于FCFS和SJF之间的一种折中算法
-
时间片轮转调度算法(RR,Round-Robin,抢占式)
- FCFS 的方式按时间片轮流使用CPU 的调度方式,让每个进程在一定时间间隔内都可以得到响应
- 由于高频率的进程切换,会增加了开销,且不区分任务的紧急程度
-
优先级调度算法(**Priority cheduling ** ,有抢占式和非抢占式)
-
根据任务的紧急程度进行调度,高优先级的先处理,低优先级的慢处理
-
通常使用【动态优先级】,如果高优先级任务很多且持续产生,那低优先级的就可能很慢才被处理
- 优先级因素:进程的等待时间、已使用的处理机时间或其他资源的使用情况
-
分类
- 非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
-
-
多级反馈队列调度算法(Multilevel Feedback Queue,抢占式)
- 多级:表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短
- 高优先级队列中已没有调度的进程,则调度次优先级队列中的进程
- 对同个队列中的各个进程,按照时间片轮转法调度
- 比如
- Q1,Q2,Q3三个队列,在Q1中没有进程等待时才去调度Q2,只有Q1,Q2都为空时才会去调度Q3
- 队列的时间片为N,假如Q1中的作业经过N个时间片后还没有完成,则进入到Q2队列,以此类推
- 反馈:表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列
- 多级:表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短
-
总结
- 一个好的调度算法考虑以下几个方面
- 公平-保证每个进程得到合理的CPU时间
- 高效- 使CPU保持忙碌状态,总是有进程在CPU上运行
- 响应时间 -使交互用户的响应时间尽可能短
- 周转时间:使批处理用户等待输出的时间尽可能短
- 吞吐量-使单位时间内处理的进程数量尽可能多
- 不同系统和版本支持的调度算法不一样
- UNIX采用动态优先队列调度
- BSD采用多级反馈队列调度
- Windows采用抢先多任务调度
- 一个好的调度算法考虑以下几个方面
-
解决方案应用
- 内容爬取解析平台,区分大站点和小站点
- 负载均衡算法:nginx / feign / dubbo...
如何使用管道符连接命令?#
在Linux或Unix系统中,管道符(|)被用来将一个命令的输出作为另一个命令的输入,从而实现命令之间的连接,形成一个管道。
下面是一个简单的例子:
ls -l | grep ".txt"
在这个例子中,ls -l命令被用来列出当前目录下的所有文件和目录,其结果被传递到grep ".txt"命令,后者会从中筛选出包含".txt"的行。
这样,你就可以将多个命令连接起来,形成一个复杂的命令。例如:
ps aux | grep "python" | wc -l
在这个例子中:
ps aux命令被用来列出所有的进程;grep "python"命令从中筛选出包含"python"的行;wc -l命令计算这些行的数量。
因此,整个命令的结果就是正在运行的包含"python"的进程的数量。
总的来说,管道符(|)是一个非常强大的工具,可以帮助你连接各种命令,实现复杂的功能。使用时,你只需要将一个命令的输出通过管道符传递给另一个命令即可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗