FLink
Flink
⼤数据的计算模式的概念
-
大数据的【计算模式】主要分为两种,适用于不同的大数据应用场景
-
批量计算(batch computing)
- 批处理:对一定规模量的数据进行处理,类似搬砖,10个10个的搬
- 场景:离线数据统计、报表分析等(过去1年 10000亿条日志,分析日、周、月,接口响应延迟 状态码)
- 特点:批量计算非实时、高延迟,计算完成后才可以得到结果
- 框架:Hadoop MapReduce
-
流式计算(stream computing)
- 流处理:对源源不断的数据流进行处理,类似水龙头出水
- 特点:流式计算实时、低延迟,实时取最新的结果
- 场景:实时监控、实时风控等
- 框架:Spark(宏观上)、Flink
-
-
区分( 离线计算和实时计算 +流式计算和批量计算)
- 离线计算和实时计算 :是对数据处理的【延迟】不一样(一个实时和非实时)
- 流式计算和批量计算: 是对数据处理的【方式】不一样(一个流式和一个批量)
- 结论:离线和批量不等价,实时和流式不等价,因为不是同个维度的东西
Flink相关介绍
Flink介绍和重要概念
什么是Flink
- Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算
- Flink官⽹
概念
- 数据流
- 任何类型的数据都可以形成一种事件流,信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
- 什么是有界流
- 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
- 什么是无界流
- 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
Tuple元组
- 元组类型, 多个语言都有的特性, flink的java版 tuple最多支持25个
- 用途
- 函数返回(return)多个值,多个不同类型的对象
- List集合不是也可以吗,集合里面是单个类型
- 列表只能存储相同的数据类型,而元组Tuple可以存储不同的数据类型
Tuple3<Integer, String, Double> t = Tuple3.of(1,"xdclass.net",32.1);
System.out.println(t.f0);
System.out.println(t.f1);
System.out.println(t.f2);
1
xdclass.net
120
Map + FlatMap操作介绍
-
什么是java里面的Map操作
- 一对一 转换对象,比如DO转DTO
-
什么是java里面的FlatMap操作
- 一对多转换对象
List<String> list1 = new ArrayList<>();
list1.add("springboot,springcloud");
list1.add("redis6,docker");
list1.add("kafka,rabbitmq");
//一对一转换
List<String> list2 = list1.stream().map(obj -> {
obj = "小滴课堂" + obj;
return obj;
}).collect(Collectors.toList());
System.out.println(list2);
//一对多转换
List<String> list3 = list1.stream().flatMap(
obj -> {
return Arrays.stream(obj.split(","));
}
).collect(Collectors.toList());
System.out.println(list3);
[小滴课堂springboot,springcloud, 小滴课堂redis6,docker, 小滴课堂kafka,rabbitmq]
[springboot, springcloud, redis6, docker, kafka, rabbitmq]
流处理API
-
Flink的API层级 为流式/批式处理应用程序的开发提供了不同级别的抽象
-
第一层是最底层的抽象为有状态实时流处理,抽象实现是 Process Function,用于底层处理
-
第二层抽象是 Core APIs,许多应用程序不需要使用到上述最底层抽象的 API,而是使用 Core APIs 进行开发
- 例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等,此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
-
第三层抽象是 Table API。 是以表Table为中心的声明式编程API,Table API 使用起来很简洁但是表达能力差
- 类似数据库中关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等
- 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用
-
第四层最顶层抽象是 SQL,这层程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式
- SQL 抽象与 Table API 抽象之间的关联是非常紧密的
-
注意:Table和SQL层变动多,还在持续发展中,大致知道即可,核心是第一和第二层
-
- Flink编程模型
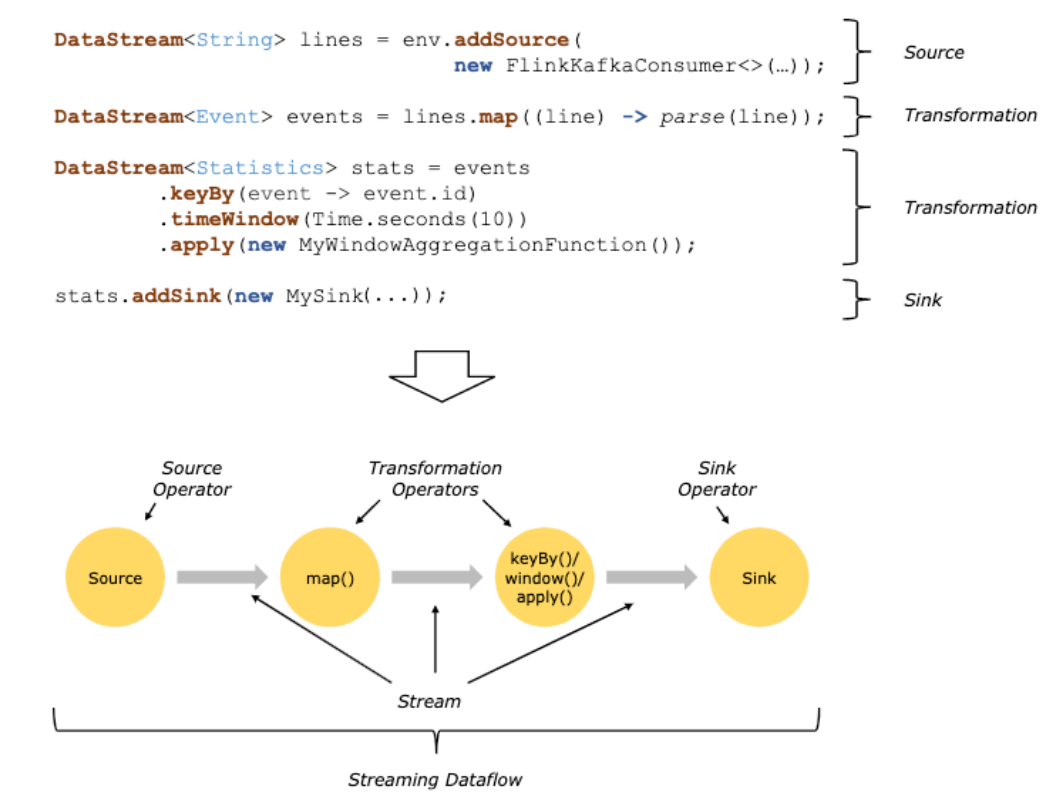
Source
-
Source来源
- 元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
public static void main(String [] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //相同类型元素的数据流 source //DataStream<String> ds1 = env.fromElements("java,SpringBoot", "spring cloud,redis", "kafka,小滴课堂"); //ds1.print("ds1:"); //相同类型元素的数据流 source //DataStream<String> ds2 = env.fromCollection(Arrays.asList("java,SpringBoot", "spring cloud,redis", "kafka,小滴课堂")); //ds2.print("ds2:"); DataStream<Long> ds3 = env.fromSequence(1,10); ds3.print("ds3:"); //DataStream需要调用execute,可以取个名称 env.execute("source job"); }-
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS文件);
-
基于Socket
- env.socketTextStream("ip", 8888)
public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); //DataStream<String> ds = env.readTextFile("C:\\Users\\Zz\\Desktop\\words.txt"); //ds.print("readTextFile"); //DataStream<String> textDS = env.readTextFile("hdfs://xdclass-dcloud-link-img.oss-cn-shenzhen.aliyuncs.com/Flink/words.txt"); //textDS.print("TextNetwork"); DataStream<String> stringDataStream = env.socketTextStream("127.0.0.1", 8888); stringDataStream.print(); //DataStream需要调用execute,可以取个名称 env.execute("source job"); }-
自定义Source,实现接口自定义数据源,rich相关的api更丰富
- 并行度为1
- SourceFunction
- RichSourceFunction
- 并行度大于1
- ParallelSourceFunction
- RichParallelSourceFunction
public static void main(String[] args) throws Exception { //构建执⾏任务环境以及任务的启动的⼊⼝, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<VideoOrder> videoOrderDataStream = env.addSource(new VideoOrderSource()); videoOrderDataStream.print(); //DataStream需要调⽤execute,可以取个名称 env.execute("custom source job"); } // PoJo @Data @AllArgsConstructor @NoArgsConstructor public class VideoOrder { private String tradeNo; private String title; private int money; private int userId; private Date createTime; @Override public String toString() { return "VideoOrder{" + "tradeNo='" + tradeNo + '\'' + ", title='" + title + '\'' + ", money=" + money + ", userId=" + userId + ", createTime=" + TimeUtil.format(createTime) + '}'; } } // 自定义输出数据源 public class VideoOrderSource extends RichParallelSourceFunction<VideoOrder> { private volatile Boolean flag = true; private Random random = new Random(); private static List<String> list = new ArrayList<>(); static { list.add("spring boot2.x课程"); list.add("微服务SpringCloud课程"); list.add("RabbitMQ消息队列"); list.add("Kafka课程"); list.add("小滴课堂面试专题第一季"); list.add("Flink流式技术课程"); list.add("工业级微服务项目大课训练营"); list.add("Linux课程"); } /** * run 方法调用前 用于初始化连接 * @param parameters * @throws Exception */ @Override public void open(Configuration parameters) throws Exception { System.out.println("-----open-----"); } /** * 用于清理之前 * @throws Exception */ @Override public void close() throws Exception { System.out.println("-----close-----"); } /** * 产生数据的逻辑 * @param ctx * @throws Exception */ @Override public void run(SourceContext<VideoOrder> ctx) throws Exception { while (flag){ Thread.sleep(1000); String id = UUID.randomUUID().toString(); int userId = random.nextInt(10); int money = random.nextInt(100); int videoNum = random.nextInt(list.size()); String title = list.get(videoNum); VideoOrder videoOrder = new VideoOrder(id,title,money,userId,new Date()); ctx.collect(videoOrder); } } /** * 控制任务取消 */ @Override public void cancel() { flag = false; } } - 并行度为1
- 元素集合
-
Connectors与第三方系统进行对接(用于source或者sink都可以)
- Flink本身提供Connector例如kafka、RabbitMQ、ES等
- 注意:Flink程序打包一定要将相应的connetor相关类打包进去,不然就会失败
-
Apache Bahir连接器
- 里面也有kafka、RabbitMQ、ES的连接器更多
-
总结 和外部系统进行读取写入的
- 第一种 Flink 里面预定义的 source 和 sink。
- 第二种 Flink 内部也提供部分 Boundled connectors。
- 第三种是第三方 Apache Bahir 项目中的连接器。
- 第四种是通过异步 IO 方式
- 异步I/O是Flink提供的非常底层的与外部系统交互
Sink读取Kafka案例
Sink
- Sink 输出源
- 预定义
- writeAsText (过期)
- 自定义
- SinkFunction
- RichSinkFunction
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
- flink官方提供 Bundle Connector
- kafka、ES 等
- Apache Bahir
- kafka、ES、Redis等
- 预定义
自定义Sink保存到Mysql案例
- 建表
CREATE TABLE `video_order` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`money` int(11) DEFAULT NULL,
`title` varchar(32) DEFAULT NULL,
`trade_no` varchar(64) DEFAULT NULL,
`create_time` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 添加jdbc依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
- 编码
public class Flink06CustomMysqlSinkApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream<VideoOrder> DS = env.addSource(new VideoOrderSource());
DataStream<VideoOrder> filterDS = DS.filter(new FilterFunction<VideoOrder>() {
@Override
public boolean filter(VideoOrder value) throws Exception {
return value.getMoney() > 30;
}
});
filterDS.printToErr();
filterDS.addSink(new MysqlSink());
env.execute("Mysql");
}
}
// 自定义Sink
public class MysqlSink extends RichSinkFunction<VideoOrder> {
private Connection conn;
private PreparedStatement ps;
/**
* 初始化连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("open=======");
conn = DriverManager.getConnection("jdbc:mysql://ip:port/xd_order?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai", "user", "pwd");
String sql = "INSERT INTO `video_order` (`user_id`, `money`, `title`, `trade_no`, `create_time`) VALUES(?,?,?,?,?);";
ps = conn.prepareStatement(sql);
}
/**
* 关闭链接
*
* @throws Exception
*/
@Override
public void close() throws Exception {
System.out.println("close=======");
if (conn != null) {
conn.close();
}
if (ps != null) {
ps.close();
;
}
}
/**
* 执行对应的sql
*
* @param value
* @param context
* @throws Exception
*/
@Override
public void invoke(VideoOrder value, Context context) throws Exception {
ps.setInt(1, value.getUserId());
ps.setInt(2, value.getMoney());
ps.setString(3, value.getTitle());
ps.setString(4, value.getTradeNo());
ps.setDate(5, new Date(value.getCreateTime().getTime()));
ps.executeUpdate();
}
}
自定义Sink保存到Redis案例
- Flink怎么操作redis?
- 方式一:自定义sink
- 方式二:使用connector
- Redis Sink 核心是RedisMapper 是一个接口,使用时要编写自己的redis操作类实现这个接口中的三个方法
- getCommandDescription 选择对应的数据结构和key名称配置
- getKeyFromData 获取key
- getValueFromData 获取value
- 使用
- 添加依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
- 编码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStream<VideoOrder> ds = env.fromElements(
new VideoOrder("21312", "java", 32, 5, new Date()),
new VideoOrder("314", "java", 32, 5, new Date()),
new VideoOrder("542", "springboot", 32, 5, new Date()),
new VideoOrder("42", "redis", 32, 5, new Date()),
new VideoOrder("4252", "java", 32, 5, new Date()),
new VideoOrder("42", "springboot", 32, 5, new Date()),
new VideoOrder("554232", "flink", 32, 5, new Date()),
new VideoOrder("23323", "java", 32, 5, new Date())
);
DataStream<Tuple2<String, Integer>> sumDS = ds.flatMap(new FlatMapFunction<VideoOrder, Tuple2<String, Integer>>() {
@Override
public void flatMap(VideoOrder value, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(new Tuple2<>(value.getTitle(), 1));
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1);
sumDS.print();
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("203.189.210.168").setPort(8000).setPassword("123456").build();
sumDS.addSink(new RedisSink<>(conf,new VideoOrderCounterSink1()));
env.execute("redis");
}
// 自定义redisSink
public class MyRedisSink implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "VIDEO_ORDER_COUNTER");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> value) {
return value.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> value) {
return value.f1.toString();
}
}
Source读取Kafka -- Sink输出到Kafka案例
- 之前自定义SourceFunction,Flink官方也有提供对接外部系统的,比如读取Kafka
- flink官方提供的连接器
- 添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
- 进入docker查看消息
# 启动消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic xdclass-order --from-beginning
# 启动生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic xdclass-topic
- 编写代码
- FlinkKafkaConsumer-》FlinkKafkaConsumerBase-》RichParallelSourceFunction(富函数-并行读取kafka多分区)
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//kafka地址
props.setProperty("bootstrap.servers", "localhost:9092");
//组名
props.setProperty("group.id", "video-order-group");
//字符串序列化和反序列化规则
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//offset重置规则
props.setProperty("auto.offset.reset", "latest");
//自动提交
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "2000");
//有后台线程每隔10s检测一下Kafka的分区变化情况
props.setProperty("flink.partition-discovery.interval-millis","10000");
// 监听生产者
FlinkKafkaConsumer<String> consumer =new FlinkKafkaConsumer<>("xdclass-topic", new SimpleStringSchema(), props);
//设置从记录的消费者组内的offset开始消费, 如果没有记录从 auto.offset.reset 配置开始消费
consumer.setStartFromGroupOffsets();
DataStream<String> ds = env.addSource(consumer);
ds.print();
//处理,拼接字符串
DataStream<String> mapDS = ds.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return "小滴课堂:"+value;
}
});
//输出到消费者
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("xdclass-order", new SimpleStringSchema(), props);
mapDS.addSink(kafkaSink);
//DataStream需要调用execute,可以取个名称
env.execute("custom source job");
}
Transformation
Flink 里面的Map和FlatMap
- 需求:多数算子,我们会用订单 转换-过滤-分组-统计 来实现
- 这样大家更加明白应用场景,比如应用到多个方面等
- 结果类型 idea自动提示
- 算子后 .var 回车 java类型
- 算子后 .val 回车 scala类型
- 什么是java里面的Map操作
- 一对一 转换对象
DataStream<VideoOrder> ds = env.fromElements(
new VideoOrder("253","java",30,15,new Date()),
new VideoOrder("323","java",30,5,new Date()),
new VideoOrder("42","java",30,5,new Date()),
new VideoOrder("543","springboot",21,5,new Date()),
new VideoOrder("423","redis",40,5,new Date()),
new VideoOrder("15","redis",40,5,new Date()),
new VideoOrder("312","springcloud",521,5,new Date()),
new VideoOrder("125","kafka",1,55,new Date())
);
// map转换,来一个记录一个,方便后续统计
DataStream<Tuple2<String,Integer>> mapDS = ds.map(new MapFunction<VideoOrder, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(VideoOrder value) throws Exception {
return new Tuple2<>(value.getTitle(),1);
}
});
mapDS.print();
- 什么是java里面的FlatMap操作
- 一对多转换对象
//只是一对一记录而已,没必要使用flatMap
// FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型
DataStream<Tuple2<String,Integer>> mapDS = ds.flatMap(new FlatMapFunction<VideoOrder, Tuple2<String,Integer>>() {
@Override
public void flatMap(VideoOrder value, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(new Tuple2<>(value.getTitle(),1));
}
});
Flink 里面的RichMap和RichFlatMap 算子实战
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
- RichXXX相关Open、Close、setRuntimeContext等 API方法会根据并行度进行操作的
- 比如并行度是4,那就有4次触发对应的open/close方法等,是4个不同subtask
- 比如 RichMapFunction、RichFlatMapFunction、RichSourceFunction等
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(2);
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
DataStream<VideoOrder> ds = env.fromElements(
new VideoOrder("21312","java",32,5,new Date()),
new VideoOrder("314","java",32,5,new Date()),
new VideoOrder("542","springboot",32,5,new Date()),
new VideoOrder("42","redis",32,5,new Date()),
new VideoOrder("4252","java",32,5,new Date()),
new VideoOrder("42","springboot",32,5,new Date()),
new VideoOrder("554232","flink",32,5,new Date()),
new VideoOrder("23323","java",32,5,new Date())
);
//transformation
DataStream<Tuple2<String,Integer>> mapDS = ds.map(new RichMapFunction<VideoOrder, Tuple2<String,Integer>>() {
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("========open");
}
@Override
public void close() throws Exception {
System.out.println("========close");
}
@Override
public Tuple2<String, Integer> map(VideoOrder value) throws Exception {
return new Tuple2<>(value.getTitle(),1);
}
});
mapDS.print();
//DataStream需要调用execute,可以取个名称
env.execute("map job");
}
DataStreamSource<String> ds = env.fromElements("spring,java", "springcloud,flink", "java,kafka");
SingleOutputStreamOperator<String> flatMapDS = ds.flatMap(new RichFlatMapFunction<String, String>() {
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("========open");
}
@Override
public void close() throws Exception {
System.out.println("========close");
}
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
System.out.println(1);
String [] arr = value.split(",");
for(String str:arr){
out.collect(str);
}
}
});
flatMapDS.print();
//DataStream需要调用execute,可以取个名称
env.execute("flat map job");
}
KeyBy + filter + Sum
KeyBy分组概念介绍
- keyBy是把数据流按照某个字段分区
- keyBy后是相同的数据放到同个组里面,再进行组内统计
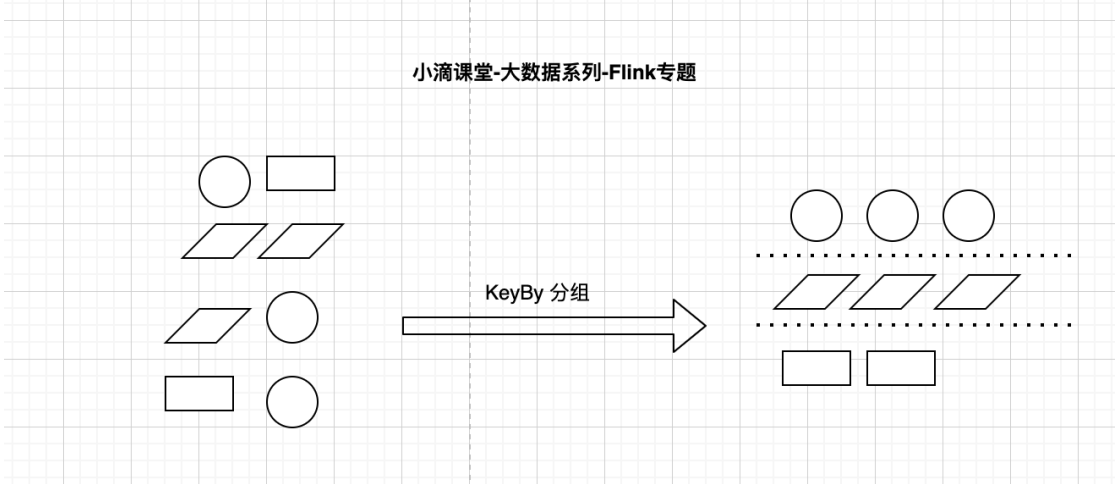
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream<VideoOrder> DS = env.addSource(new VideoOrderSourceV2());
DataStream<VideoOrder> sum = DS.filter(new FilterFunction<VideoOrder>() {
@Override
public boolean filter(VideoOrder value) throws Exception {
return value.getMoney() > 15;
}
}).keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
}).sum("money");
sum.print();
env.execute("money");
}
reduce函数
-
keyBy分组后聚合统计sum和reduce实现一样的效果
-
sum区别
- sum("xxx")使用的时候,如果是tuple元组则用序号,POJO则用属性名称
- keyBy分组后聚合统计sum和reduce实现一样的效果
- sum是简单聚合,reduce是可以自定义聚合,aggregate支持复杂的自定义聚合
-
例子
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream<VideoOrder> DS = env.addSource(new VideoOrderSourceV2());
DataStream<VideoOrder> keyByDS DS.filter(new FilterFunction<VideoOrder>() {
@Override
public boolean filter(VideoOrder value) throws Exception {
return value.getMoney() > 15;
}
}).keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
})
// 对比-------------------------------------------------------------------------------------------------------------------
// sum 算
SingleOutputStreamOperator<VideoOrder> money = keyByDS.sum("money");
money.print();
// reduce 计算
// value1是历史对象,value2是加入统计的对象,所以value1.f1是历史值,value2.f1是新值,不断累加
SingleOutputStreamOperator<VideoOrder> reduce = keyByDS.reduce(new ReduceFunction<VideoOrder>() {
@Override
public VideoOrder reduce(VideoOrder value1, VideoOrder value2) throws Exception {
VideoOrder videoOrder = new VideoOrder();
videoOrder.setTitle(value1.getTitle());
videoOrder.setMoney(value1.getMoney() + value2.getMoney());
return videoOrder;
}
});
reduce.print();
// 对比-------------------------------------------------------------------------------------------------------------------
env.execute("sum----reduce");
}
maxBy-max-minBy-min 区别和应用
- 如果是用了keyby,在后续算子要用maxby,minby类型,才可以再分组里面找对应的数据
- 如果是用max、min等,就不确定是哪个key中选了
- 如果是keyBy的是对象的某个属性,则分组用max/min聚合统计,只有聚合的字段会更新,其他字段还是旧的,导致对象不准确
- 需要用maxby/minBy才对让整个对象的属性都是最新的
- 例子
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
DataStream<VideoOrder> ds = env.fromElements(
new VideoOrder("5", "redis", 41, 52, new Date()),
new VideoOrder("6", "redis", 40, 15, new Date()),
new VideoOrder("6", "redis", 35, 10, new Date()),
new VideoOrder("6", "redis", 45, 19, new Date())
);
KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
});
SingleOutputStreamOperator<VideoOrder> max = keyByDS.max("money");
SingleOutputStreamOperator<VideoOrder> maxBy = keyByDS.maxBy("money");
DataStream<VideoOrder> min = keyByDS.min("money");
DataStream<VideoOrder> minBy = keyByDS.minBy("money");
max.print("max----->");
maxBy.print("maxBy----->");
min.print("min----->");
minBy.print("minBy----->");
//DataStream需要调用execute,可以取个名称
env.execute("job");
}
maxBy----->> VideoOrder{tradeNo='6', title='redis', money=45, userId=19, createTime=2023-03-19 10:14:13}
max----->> VideoOrder{tradeNo='5', title='redis', money=45, userId=52, createTime=2023-03-19 10:14:13}
min----->> VideoOrder{tradeNo='5', title='redis', money=35, userId=52, createTime=2023-03-19 10:14:13}
minBy----->> VideoOrder{tradeNo='6', title='redis', money=35, userId=10, createTime=2023-03-19 10:14:13}
- KeyBy后可以用KeyedProcessFunction,更底层的API,有processElement和onTimer函数
窗口
介绍
Window窗口介绍和应用场景
-
文档地址
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/datastream/operators/windows
- Windows are at the heart of processing infinite streams(Window是处理无限数据量的核心)
-
背景
- 数据流是一直源源不断产生,业务需要聚合统计使用,比如每10秒统计过去5分钟的点击量、成交额等
- Windows 就可以将无限的数据流拆分为有限大小的“桶 buckets”,然后程序可以对其窗口内的数据进行计算
- 窗口认为是Bucket桶,一个窗口段就是一个桶,比如8到9点是一个桶,9到10点是一个桶
-
分类
- time Window 时间窗口,即按照一定的时间规则作为窗口统计
- time-tumbling-window 时间滚动窗口 (用的多)
- time-sliding-window 时间滑动窗口 (用的多)
- session WIndow 会话窗口,即一个会话内的数据进行统计,相对少用
- count Window 数量窗口,即按照一定的数据量作为窗口统计,相对少用
- time Window 时间窗口,即按照一定的时间规则作为窗口统计
-
窗口属性
- 滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
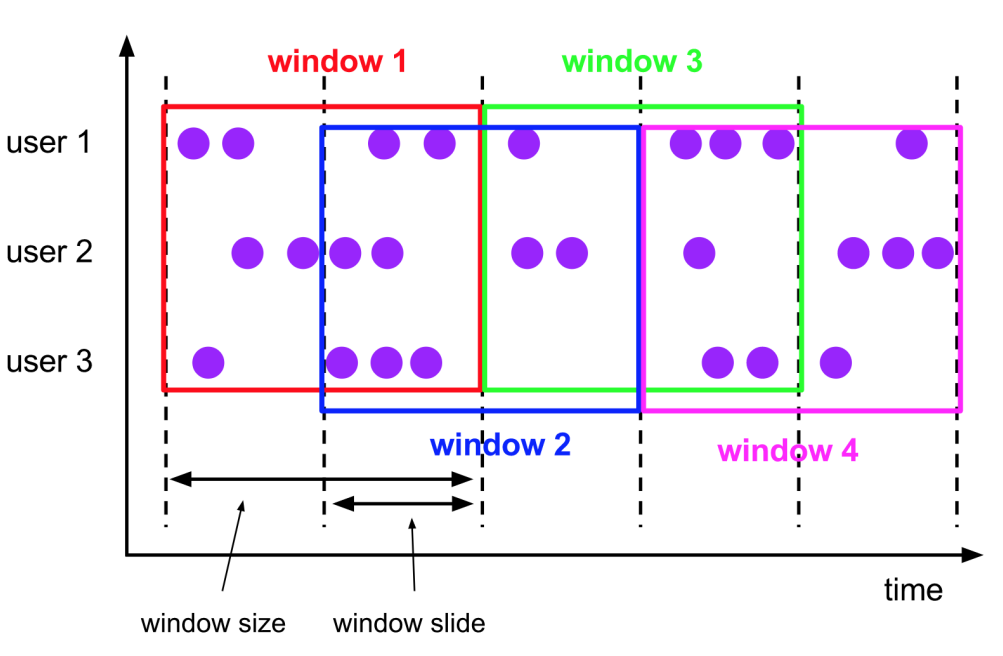
- 滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
- 例子:每10s统计一次最近10s内的订单数量
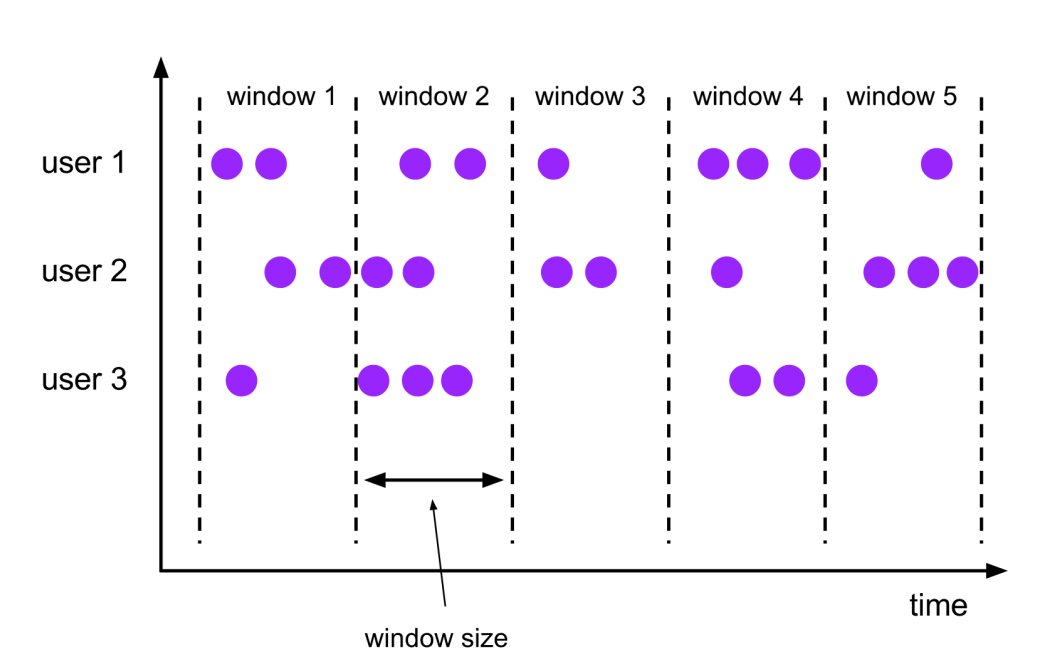
- 窗口大小size 和 滑动间隔 slide
- tumbling-window:滚动窗口: size=slide,如:每隔10s统计最近10s的数据
- sliding-window:滑动窗口: size>slide,如:每隔5s统计最近10s的数据
- size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所以开发中不用
- 滑动窗口 Sliding Windows
Window 窗口API和使用流程介绍
- 什么情况下才可以使用WindowAPI
- 有keyBy 用 window() api
- 没keyBy 用 windowAll() api ,并行度低
- 方括号 ([…]) 中的命令是可选的,允许用多种不同的方式自定义窗口逻辑

-
注意
- 一个窗口内是左闭右开
- countWindow没过期,但timeWindow在1.12过期,统一使用window;
-
窗口分配器 Window Assigners
- 定义了如何将元素分配给窗口,负责将每条数据分发到正确的 window窗口上
- window() 的参数是一个 WindowAssigner,flink本身提供了Tumbling、Sliding 等Assigner
-
窗口触发器 trigger
- 用来控制一个窗口是否需要被触发
- 每个 窗口分配器WindowAssigner 都有一个默认触发器,也支持自定义触发器
-
窗口 window function ,对窗口内的数据做啥?
-
定义了要对窗口中收集的数据做的计算操作
-
增量聚合函数
aggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 reduceFunction、aggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
AggregateFunction<IN, ACC, OUT> IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据 -
全窗口函数
apply(new processWindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息)
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗 WindowFunction<IN, OUT, KEY, W extends Window -
如果想处理每个元素更底层的API的时候用
//对数据进行解析 ,process对每个元素进行处理,相当于 map+flatMap+filter process(new KeyedProcessFunction(){processElement、onTimer}) -
时间窗类型
Tumbling-Window滚动时间窗
-
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
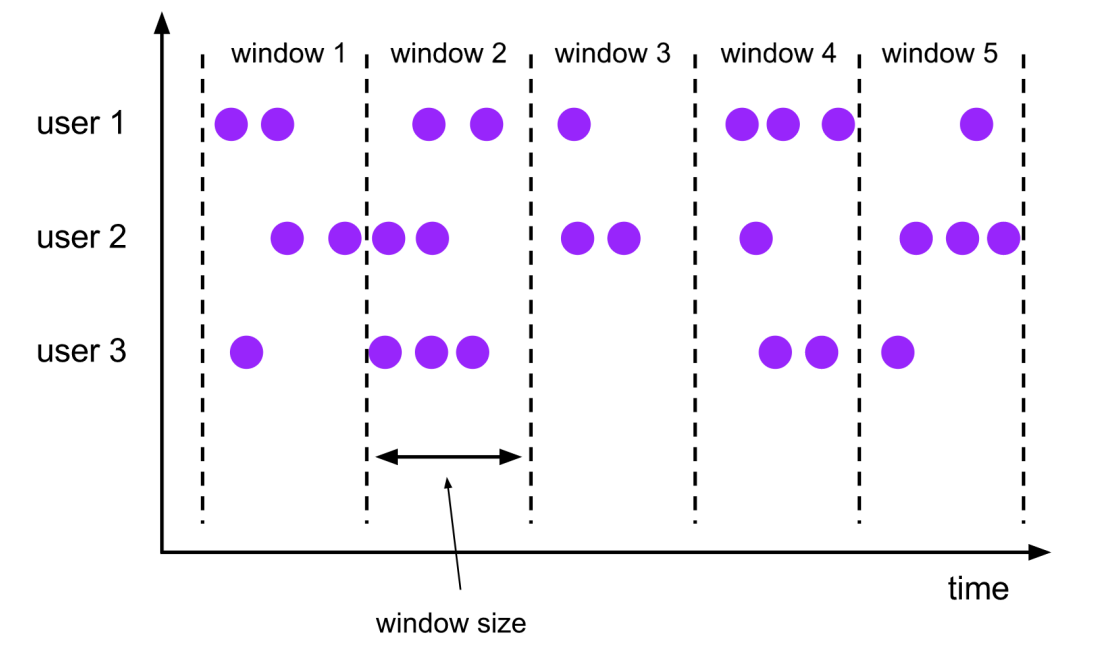
-
比如指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分为[0:00, 0:05)、[0:05, 0:10)、[0:10, 0:15)等窗口
-
案例(可以单一个数据测试,后续再讲时间语义)
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
DataStream<VideoOrder> ds = env.addSource(new VideoOrderSourceV2());
KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
});
DataStream<VideoOrder> sumDS = keyByDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum("money");
sumDS.printToErr();
//DataStream需要调用execute,可以取个名称
env.execute("tumbling window job");
}
-----open-----
产生:spring boot,价格:15, 时间:2023-03-19 10:41:12
产生:java,价格:10, 时间:2023-03-19 10:41:13
产生:spring boot,价格:15, 时间:2023-03-19 10:41:14
VideoOrder{tradeNo='9b26ef', title='spring boot', money=15, userId=5, createTime=2023-03-19 10:41:12}
VideoOrder{tradeNo='a72c38', title='java', money=10, userId=1, createTime=2023-03-19 10:41:13}
产生:spring boot,价格:15, 时间:2023-03-19 10:41:15
产生:java,价格:10, 时间:2023-03-19 10:41:16
产生:spring boot,价格:15, 时间:2023-03-19 10:41:17
产生:spring boot,价格:15, 时间:2023-03-19 10:41:18
产生:java,价格:10, 时间:2023-03-19 10:41:19
VideoOrder{tradeNo='0f5edf', title='spring boot', money=60, userId=1, createTime=2023-03-19 10:41:14}
VideoOrder{tradeNo='eab714', title='java', money=10, userId=1, createTime=2023-03-19 10:41:16}
产生:java,价格:10, 时间:2023-03-19 10:41:20
产生:java,价格:10, 时间:2023-03-19 10:41:22
产生:spring boot,价格:15, 时间:2023-03-19 10:41:23
产生:java,价格:10, 时间:2023-03-19 10:41:24
VideoOrder{tradeNo='42d638', title='java', money=40, userId=2, createTime=2023-03-19 10:41:19}
VideoOrder{tradeNo='0660b4', title='spring boot', money=15, userId=7, createTime=2023-03-19 10:41:23}
Sliding -Window滑动时间窗介绍
- 滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
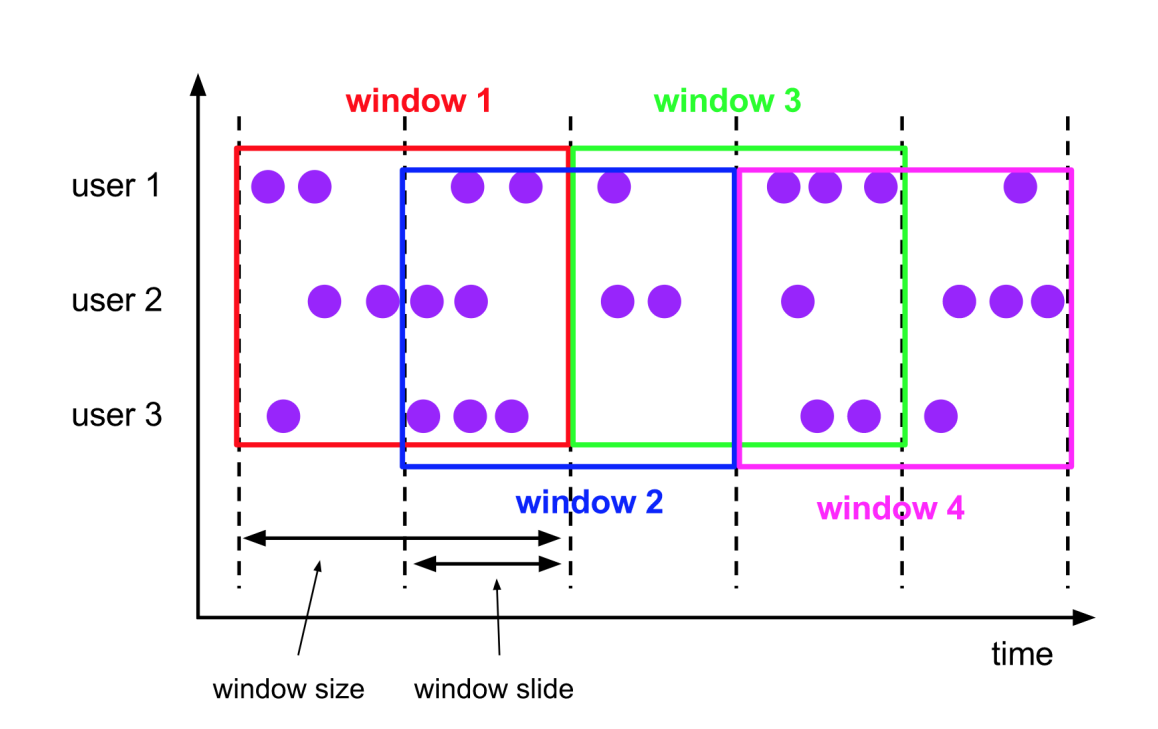
- 案例实战
- 每5秒统计过去15秒的不同视频的订单总价
DataStream<VideoOrder> sumDS = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(20),Time.seconds(5))).sum("money");
-----open-----
产生:spring boot,价格:15, 时间:2023-03-19 10:52:32
VideoOrder{tradeNo='28c36a', title='spring boot', money=15, userId=6, createTime=2023-03-19 10:52:32}
产生:java,价格:10, 时间:2023-03-19 10:52:36
VideoOrder{tradeNo='28c36a', title='spring boot', money=15, userId=6, createTime=2023-03-19 10:52:32}
VideoOrder{tradeNo='3b097b', title='java', money=10, userId=1, createTime=2023-03-19 10:52:36}
产生:java,价格:10, 时间:2023-03-19 10:52:40
产生:java,价格:10, 时间:2023-03-19 10:52:44
VideoOrder{tradeNo='3b097b', title='java', money=30, userId=1, createTime=2023-03-19 10:52:36}
VideoOrder{tradeNo='28c36a', title='spring boot', money=15, userId=6, createTime=2023-03-19 10:52:32}
产生:java,价格:10, 时间:2023-03-19 10:52:48
VideoOrder{tradeNo='3b097b', title='java', money=40, userId=1, createTime=2023-03-19 10:52:36}
产生:java,价格:10, 时间:2023-03-19 10:52:52
VideoOrder{tradeNo='fb2851', title='java', money=40, userId=4, createTime=2023-03-19 10:52:40}
产生:java,价格:10, 时间:2023-03-19 10:52:56
VideoOrder{tradeNo='b71437', title='java', money=30, userId=9, createTime=2023-03-19 10:52:48}
Count Window窗⼝介绍
- 基于数量的滚动窗口, 滑动计数窗口
- 案例:
- 统计分组后同个key内的数据超过5次则进行统计 countWindow(5)
- 只要有2个数据到达后就可以往后统计5个数据的值, countWindow(5, 2)
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
KeyedStream<VideoOrder,String> keyByDS = env.addSource(new VideoOrderSourceV2()).keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
});
//分组后的组内数据超过5个则触发
//DataStream<VideoOrder> sumDS = keyByDS.countWindow(5).sum("money");
//分组后的组内数据超过3个则触发统计过去的5个数据
DataStream<VideoOrder> sumDS = keyByDS.countWindow(5,3).sum("money");
sumDS.printToErr();
//DataStream需要调用execute,可以取个名称
env.execute("sliding window job");
}
-----组内数据超过5个则触发-----
产生:spring boot,价格:15, 时间:2023-03-19 10:58:28
产生:java,价格:10, 时间:2023-03-19 10:58:28
产生:spring boot,价格:15, 时间:2023-03-19 10:58:29
产生:spring boot,价格:15, 时间:2023-03-19 10:58:29
产生:java,价格:10, 时间:2023-03-19 10:58:30
产生:spring boot,价格:15, 时间:2023-03-19 10:58:31
产生:java,价格:10, 时间:2023-03-19 10:58:31
产生:spring boot,价格:15, 时间:2023-03-19 10:58:32
VideoOrder{tradeNo='46f39a', title='spring boot', money=75, userId=3, createTime=2023-03-19 10:58:28}
产生:java,价格:10, 时间:2023-03-19 10:58:32
产生:java,价格:10, 时间:2023-03-19 10:58:33
VideoOrder{tradeNo='f00ef2', title='java', money=50, userId=1, createTime=2023-03-19 10:58:28}
-----超过3个则触发统计过去的5个数据-----
产生:java,价格:10, 时间:2023-03-19 10:57:01
产生:java,价格:10, 时间:2023-03-19 10:57:02
产生:java,价格:10, 时间:2023-03-19 10:57:02
VideoOrder{tradeNo='d8a177', title='java', money=30, userId=0, createTime=2023-03-19 10:57:01}
产生:spring boot,价格:15, 时间:2023-03-19 10:57:03
产生:spring boot,价格:15, 时间:2023-03-19 10:57:03
产生:spring boot,价格:15, 时间:2023-03-19 10:57:04
VideoOrder{tradeNo='ad8b95', title='spring boot', money=45, userId=5, createTime=2023-03-19 10:57:03}
产生:spring boot,价格:15, 时间:2023-03-19 10:57:04
产生:java,价格:10, 时间:2023-03-19 10:57:05
产生:java,价格:10, 时间:2023-03-19 10:57:05
产生:java,价格:10, 时间:2023-03-19 10:57:06
VideoOrder{tradeNo='0c5133', title='java', money=50, userId=5, createTime=2023-03-19 10:57:02}
窗口函数
AggregateFunction增量聚合函数
-
窗口 window function ,对窗口内的数据做啥?
-
定义了要对窗口中收集的数据做的计算操作
-
增量聚合函数
aggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 reduceFunction、aggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
AggregateFunction<IN, ACC, OUT> IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据
-
-
案例-滚动时间窗
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStream<VideoOrder> aggregate = env.addSource(new VideoOrderSourceV2())
.keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
}).window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new AggregateFunction<VideoOrder, VideoOrder, VideoOrder>() {
@Override
public VideoOrder createAccumulator() {
VideoOrder videoOrder = new VideoOrder();
return videoOrder;
}
@Override
public VideoOrder add(VideoOrder value, VideoOrder accumulator) {
accumulator.setMoney(value.getMoney() + accumulator.getMoney());
if (accumulator.getTitle() == null) {
accumulator.setTitle(value.getTitle());
}
if (accumulator.getCreateTime() == null) {
accumulator.setCreateTime(value.getCreateTime());
}
return accumulator;
}
@Override
public VideoOrder getResult(VideoOrder accumulator) {
return accumulator;
}
@Override
public VideoOrder merge(VideoOrder a, VideoOrder b) {
VideoOrder videoOrder = new VideoOrder();
videoOrder.setMoney(a.getMoney() + b.getMoney());
videoOrder.setTitle(a.getTitle());
return videoOrder;
}
});
aggregate.printToErr();
//DataStream需要调用execute,可以取个名称
env.execute("sliding window job");
}
-----open-----
产生:spring boot,价格:15, 时间:2023-03-19 11:12:01
产生:spring boot,价格:15, 时间:2023-03-19 11:12:02
产生:spring boot,价格:15, 时间:2023-03-19 11:12:03
产生:java,价格:10, 时间:2023-03-19 11:12:04
VideoOrder{tradeNo='null', title='spring boot', money=45, userId=0, createTime=2023-03-19 11:12:01}
VideoOrder{tradeNo='null', title='java', money=10, userId=0, createTime=2023-03-19 11:12:04}
产生:spring boot,价格:15, 时间:2023-03-19 11:12:05
产生:java,价格:10, 时间:2023-03-19 11:12:06
产生:spring boot,价格:15, 时间:2023-03-19 11:12:07
产生:java,价格:10, 时间:2023-03-19 11:12:08
产生:spring boot,价格:15, 时间:2023-03-19 11:12:09
VideoOrder{tradeNo='null', title='spring boot', money=45, userId=0, createTime=2023-03-19 11:12:05}
VideoOrder{tradeNo='null', title='java', money=20, userId=0, createTime=2023-03-19 11:12:06}
产生:java,价格:10, 时间:2023-03-19 11:12:10
产生:spring boot,价格:15, 时间:2023-03-19 11:12:11
产生:spring boot,价格:15, 时间:2023-03-19 11:12:12
产生:java,价格:10, 时间:2023-03-19 11:12:13
产生:spring boot,价格:15, 时间:2023-03-19 11:12:14
VideoOrder{tradeNo='null', title='java', money=20, userId=0, createTime=2023-03-19 11:12:10}
VideoOrder{tradeNo='null', title='spring boot', money=45, userId=0, createTime=2023-03-19 11:12:11}
WindowFunction全窗口函数
-
全窗口函数
apply(new WindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗 WindowFunction<IN, OUT, KEY, W extends Window> -
案例实战
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
SingleOutputStreamOperator<VideoOrder> apply = env.addSource(new VideoOrderSourceV2())
.keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
})
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<VideoOrder> input, Collector<VideoOrder> out) throws Exception {
List<VideoOrder> list = IteratorUtils.toList(input.iterator());
int total = list.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();
VideoOrder videoOrder = new VideoOrder();
videoOrder.setMoney(total);
videoOrder.setTitle(list.get(0).getTitle());
videoOrder.setCreateTime(list.get(0).getCreateTime());
out.collect(videoOrder);
}
});
apply.printToErr();
//DataStream需要调用execute,可以取个名称
env.execute("sliding window job");
}
-----open-----
产生:java,价格:10, 时间:2023-03-19 11:17:50
产生:java,价格:10, 时间:2023-03-19 11:17:51
产生:java,价格:10, 时间:2023-03-19 11:17:52
产生:spring boot,价格:15, 时间:2023-03-19 11:17:53
产生:spring boot,价格:15, 时间:2023-03-19 11:17:54
VideoOrder{tradeNo='null', title='java', money=30, userId=0, createTime=2023-03-19 11:17:50}
VideoOrder{tradeNo='null', title='spring boot', money=30, userId=0, createTime=2023-03-19 11:17:53}
产生:java,价格:10, 时间:2023-03-19 11:17:55
产生:spring boot,价格:15, 时间:2023-03-19 11:17:56
产生:java,价格:10, 时间:2023-03-19 11:17:57
产生:java,价格:10, 时间:2023-03-19 11:17:58
产生:java,价格:10, 时间:2023-03-19 11:17:59
VideoOrder{tradeNo='null', title='java', money=40, userId=0, createTime=2023-03-19 11:17:55}
VideoOrder{tradeNo='null', title='spring boot', money=15, userId=0, createTime=2023-03-19 11:17:56}
processWindowFunction全窗口函数
-
全窗口函数
process(new ProcessWindowFunction(){})- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗 ProcessWindowFunction<IN, OUT, KEY, W extends Window> -
案例实战
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//数据源 source
SingleOutputStreamOperator<VideoOrder> process = env.addSource(new VideoOrderSourceV2())
.keyBy(new KeySelector<VideoOrder, String>() {
@Override
public String getKey(VideoOrder value) throws Exception {
return value.getTitle();
}
}).window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<VideoOrder, VideoOrder, String, TimeWindow>.Context context, Iterable<VideoOrder> elements, Collector<VideoOrder> out) throws Exception {
List<VideoOrder> list = IteratorUtils.toList(elements.iterator());
int total = list.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();
VideoOrder videoOrder = new VideoOrder();
videoOrder.setMoney(total);
videoOrder.setTitle(list.get(0).getTitle());
videoOrder.setCreateTime(list.get(0).getCreateTime());
out.collect(videoOrder);
}
});
process.printToErr();
//DataStream需要调用execute,可以取个名称
env.execute("sliding window job");
}
-----open-----
产生:spring boot,价格:15, 时间:2023-03-19 11:24:30
产生:java,价格:10, 时间:2023-03-19 11:24:31
产生:java,价格:10, 时间:2023-03-19 11:24:32
产生:spring boot,价格:15, 时间:2023-03-19 11:24:33
产生:java,价格:10, 时间:2023-03-19 11:24:34
VideoOrder{tradeNo='null', title='spring boot', money=30, userId=0, createTime=2023-03-19 11:24:30}
VideoOrder{tradeNo='null', title='java', money=30, userId=0, createTime=2023-03-19 11:24:31}
产生:spring boot,价格:15, 时间:2023-03-19 11:24:35
产生:spring boot,价格:15, 时间:2023-03-19 11:24:36
产生:java,价格:10, 时间:2023-03-19 11:24:37
产生:java,价格:10, 时间:2023-03-19 11:24:38
产生:java,价格:10, 时间:2023-03-19 11:24:39
VideoOrder{tradeNo='null', title='spring boot', money=30, userId=0, createTime=2023-03-19 11:24:35}
VideoOrder{tradeNo='null', title='java', money=30, userId=0, createTime=2023-03-19 11:24:37}
无序数据处理机制
Flink的多种时间概念介绍和应用场景
简介: Flink的多种时间概念介绍和应用场景
-
背景
-
前面我们使用了Window窗口函数,flink怎么知道哪个是字段是对应的时间呢?
-
由于网络问题,数据先产生,但是乱序延迟了,那属于哪个时间窗呢?
-
Flink里面定义窗口,可以引用不同的时间概念
-
-
Flink里面时间分类
- 事件时间EventTime(重点关注)
- 事件发生的时间
- 事件时间是每个单独事件在其产生进程上发生的时间,这个时间通常在记录进入 Flink 之前记录在对象中
- 在事件时间中,时间值 取决于数据产生记录的时间,而不是任何Flink机器上的
- 进入时间 IngestionTime
- 事件到进入Flink
- 处理时间ProcessingTime
- 事件被flink处理的时间
- 指正在执行相应操作的机器的系统时间
- 是最简单的时间概念,不需要流和机器之间的协调,它提供最佳性能和最低延迟
- 但是在分布式和异步环境中,处理时间有不确定性,存在延迟或乱序问题
- 事件时间EventTime(重点关注)
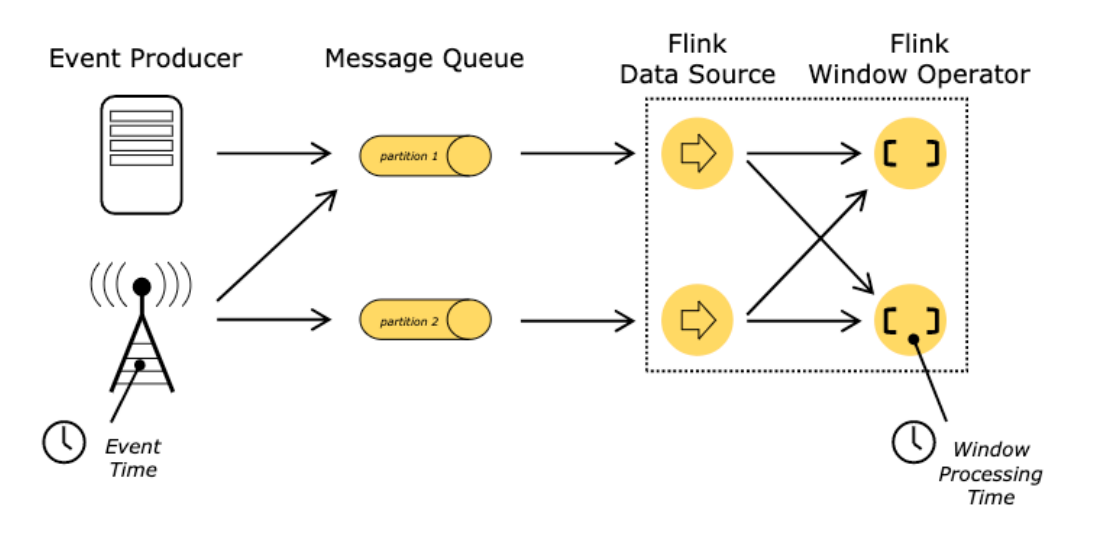
Watermark
-
背景
- 一般我们都是用EventTime事件时间进行处理统计数据
- 但数据由于网络问题延迟、乱序到达会导致窗口计算数据不准确
- 需求:比如时间窗是 [12:01:01,12:01:10 ) ,但是有数据延迟到达
- 当 12:01:10 秒数据到达的时候,不立刻触发窗口计算
- 而是等一定的时间,等迟到的数据来后再关闭窗口进行计算
-
Watermark 水位线介绍
- 由flink的某个operator操作生成后,就在整个程序中随event数据流转
- With Periodic Watermarks(周期生成,可以定义一个最大允许乱序的时间,用的很多)
- With Punctuated Watermarks(标点水位线,根据数据流中某些特殊标记事件来生成,相对少)
- 衡量数据是否乱序的时间,什么时候不用等早之前的数据
- 是一个全局时间戳,不是某一个key下的值
- 是一个特殊字段,单调递增的方式,主要是和数据本身的时间戳做比较
- 用来确定什么时候不再等待更早的数据了,可以触发窗口进行计算,忍耐是有限度的,给迟到的数据一些机会
- 注意
- Watermark 设置太小会影响数据准确性,设置太大会影响数据的实时性,更加会加重Flink作业的负担
- 需要经过测试,和业务相关联,得出一个较合适的值即可
- 由flink的某个operator操作生成后,就在整个程序中随event数据流转
-
窗口触发计算的时机
- watermark之前是按照窗口的关闭时间点计算的 [12:01:01,12:01:10 )
- watermark之后,触发计算的时机
- 窗口内有数据
- Watermaker >= Window EndTime窗口结束时间
- 触发计算后,其他窗口内数据再到达也被丢弃
- Watermaker = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
-
数据流中的事件是有序
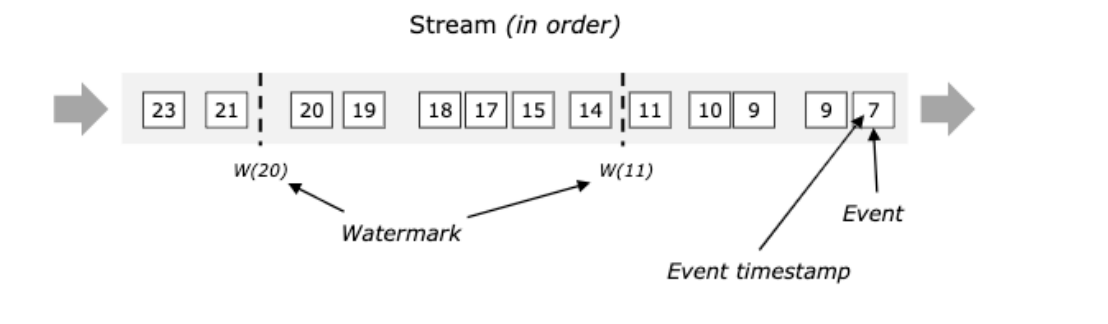
- 数据流中的事件是无序
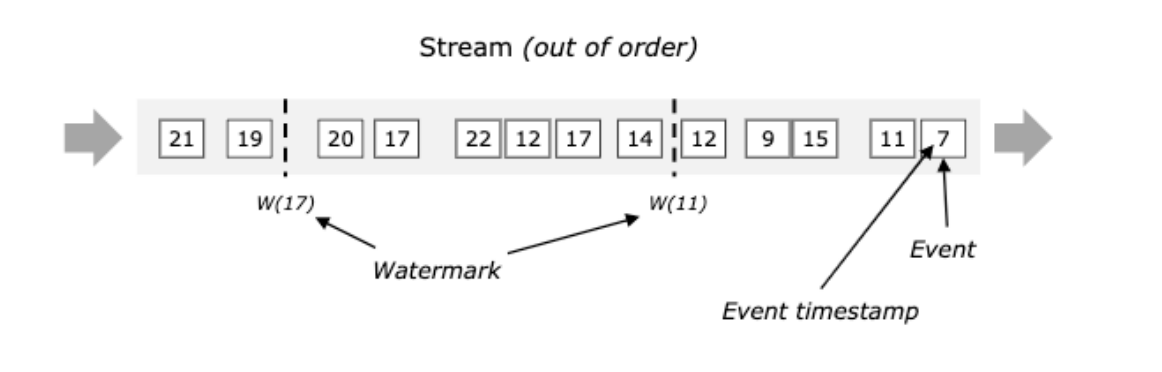
Watermark+allowedLateness+SideOutput兜底延迟数据处理案例-分类统计电商订单成交额
- 需求
- 分组统计不同视频的成交总价
- 数据有乱序延迟,允许3秒的时间
- 背景
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
- 数据超过了allowedLateness 后,就丢失了吗?用侧输出流 SideOutput
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//java,2022-11-11 09-10-10,15
DataStream<String> ds = env.socketTextStream("127.0.0.1", 8888);
//最后的兜底数据
OutputTag<Tuple3<String, String, Integer>> lateData = new OutputTag<Tuple3<String, String, Integer>>("lateDataOrder") {
};
SingleOutputStreamOperator<String> sumDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {
String[] arr = value.split(",");
out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2])));
}
}).assignTimestampsAndWatermarks(WatermarkStrategy
//指定允许乱序延迟的最大时间 3 秒
.<Tuple3<String, String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3))
//指定POJO事件时间列,毫秒
.withTimestampAssigner((event, timestamp) -> TimeUtil.strToDate(event.f1).getTime()))
.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {
@Override
public String getKey(Tuple3<String, String, Integer> value) throws Exception {
return value.f0;
}
})
//开窗
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
//允许1分钟延迟
.allowedLateness(Time.minutes(1))
.sideOutputLateData(lateData)
//聚合, 方便调试拿到窗口全部数据,全窗口函数
.apply(new WindowFunction<Tuple3<String, String, Integer>, String, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<Tuple3<String, String, Integer>> input, Collector<String> out) throws Exception {
//准备list,存储窗口的事件时间
List<String> timeList = new ArrayList<>();
int total = 0;
for (Tuple3<String, String, Integer> order : input) {
timeList.add(order.f1);
total = total + order.f2;
}
String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key, total, TimeUtil.format(window.getStart()), TimeUtil.format(window.getEnd()), timeList);
out.collect(outStr);
}
});
sumDS.printToErr();
//最后兜底处理,更新之前的数据
sumDS.getSideOutput(lateData).printToErr("late data order");
env.execute("watermark job");
}
分组key:java,聚合值:20,窗口开始结束:[2022-11-11 23:12:00~2022-11-11 23:12:10),窗口所有事件时间:[2022-11-11 23:12:07, 2022-11-11 23:12:08]
分组key:java,聚合值:20,窗口开始结束:[2022-11-11 23:12:10~2022-11-11 23:12:20),窗口所有事件时间:[2022-11-11 23:12:11, 2022-11-11 23:12:13]
分组key:java,聚合值:30,窗口开始结束:[2022-11-11 23:12:00~2022-11-11 23:12:10),窗口所有事件时间:[2022-11-11 23:12:07, 2022-11-11 23:12:08, 2022-11-11 23:12:09]
分组key:java,聚合值:40,窗口开始结束:[2022-11-11 23:12:00~2022-11-11 23:12:10),窗口所有事件时间:[2022-11-11 23:12:07, 2022-11-11 23:12:08, 2022-11-11 23:12:09, 2022-11-11 23:12:02]
分组key:java,聚合值:10,窗口开始结束:[2022-11-11 23:12:20~2022-11-11 23:12:30),窗口所有事件时间:[2022-11-11 23:12:23]
late data order> (java,2022-11-11 23:12:03,10)
late data order> (java,2022-11-11 23:12:04,10)
- 测试数据
- 窗口 [23:12:00 ~ 23:12:10) | [23:12:10 ~ 23: 12:20)
- 触发窗口计算条件
- 窗口内有数据
- watermark >= 窗口endtime
- 即 当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
java,2022-11-11 23:12:07,10
java,2022-11-11 23:12:11,10
java,2022-11-11 23:12:08,10
java,2022-11-11 23:12:13,10
java,2022-11-11 23:12:23,10
#延迟1分钟内,所以会输出
java,2022-11-11 23:12:09,10
java,2022-11-11 23:12:02,10
java,2022-11-11 23:14:30,10
#延迟超过1分钟,不会输出,配置了sideOutPut,会在兜底输出
java,2022-11-11 23:12:03,10
java,2022-11-11 23:12:04,10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号