Kafka
Kafka
环境搭建
环境搭建篇(顺序->java-Zookeeper -kafka)
基础概念
核心概念
- Broker
- Kafka的服务端程序,可以认为一个mq节点就是一个broker
- broker存储topic的数据
- Producer生产者
- 创建消息Message,然后发布到MQ中
- 该角色将消息发布到Kafka的topic中
- Consumer消费者:
- 消费队列里面的消息
- ConsumerGroup消费者组
- 同个topic, 广播发送给不同的group,一个group中只有一个consumer可以消费此消息
- Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,主题的意思
- Partition分区
- kafka数据存储的基本单元,topic中的数据分割为一个或多个partition,每个topic至少有一个partition,是有序的
- 一个Topic的多个partitions, 被分布在kafka集群中的多个server上
- 消费者数量 <=小于或者等于Partition数量
- Replication 副本(备胎)
- 同个Partition会有多个副本replication ,多个副本的数据是一样的,当其他broker挂掉后,系统可以主动用副本提供服务
- 默认每个topic的副本都是1(默认是没有副本,节省资源),也可以在创建topic的时候指定
- 如果当前kafka集群只有3个broker节点,则replication-factor最大就是3了,如果创建副本为4,则会报错
- ReplicationLeader、ReplicationFollower
- Partition有多个副本,但只有一个replicationLeader负责该Partition和生产者消费者交互
- ReplicationFollower只是做一个备份,从replicationLeader进行同步
- ReplicationManager
- 负责Broker所有分区副本信息,Replication 副本状态切换
- offset
- 每个consumer实例需要为他消费的partition维护一个记录自己消费到哪里的偏移offset
- kafka把offset保存在消费端的消费者组里
- 特点总结
- 多订阅者
- 一个topic可以有一个或者多个订阅者
- 每个订阅者都要有一个partition,所以订阅者数量要少于等于partition数量
- 高吞吐量、低延迟: 每秒可以处理几十万条消息
- 高并发:几千个客户端同时读写
- 容错性:多副本、多分区,允许集群中节点失败,如果副本数据量为n,则可以n-1个节点失败
- 扩展性强:支持热扩展
基础命令
# 创建topic
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic xdclass-topic
# 查看topic
./kafka-topics.sh --list --zookeeper 112.74.55.160:2181
# 生产者发送消息
./kafka-console-producer.sh --broker-list 112.74.55.160:9092 --topic version1-topic
# 消费者消费消息 ( --from-beginning:会把主题中以往所有的数据都读取出来, 重启后会有这个重复消费)
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1
# 删除topic
./kafka-topics.sh --zookeeper 112.74.55.160:2181 --delete --topic t1
# 查看broker节点topic状态信息
./kafka-topics.sh --describe --zookeeper 112.74.55.160:2181 --topic xdclass-topic
模拟消息发送
消息模型
点对点
-
点对点(point to point)
- 消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息
- 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费
-
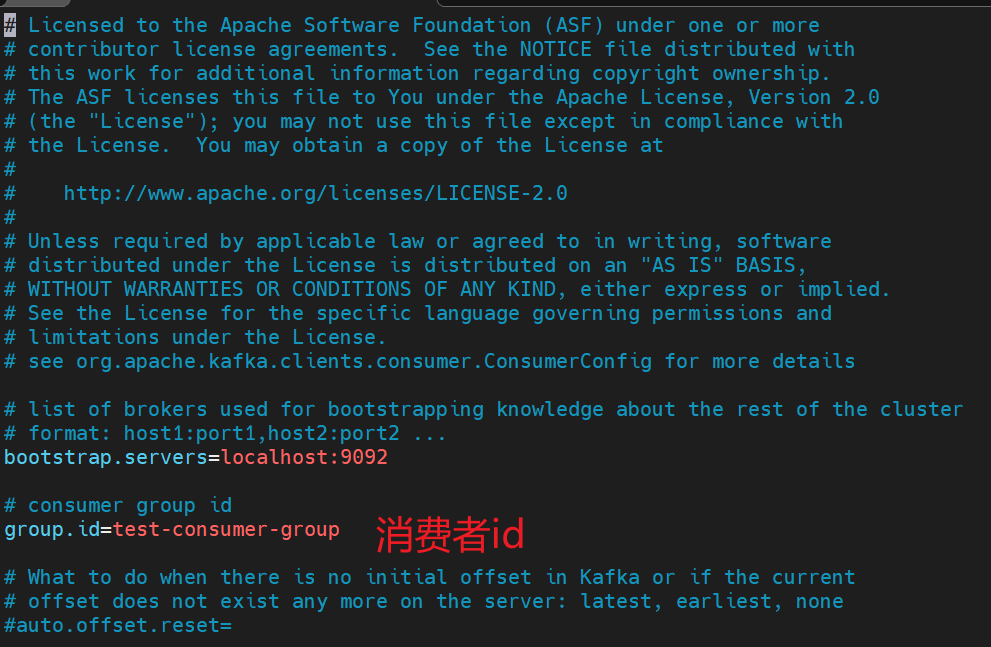
编辑消费者配置(确保同个名称group.id一样)
- 编辑 config/consumer.properties(使用默认即可)
-
创建topic, 1个分区
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t1
- 指定配置文件启动 两个消费者
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer.properties
-
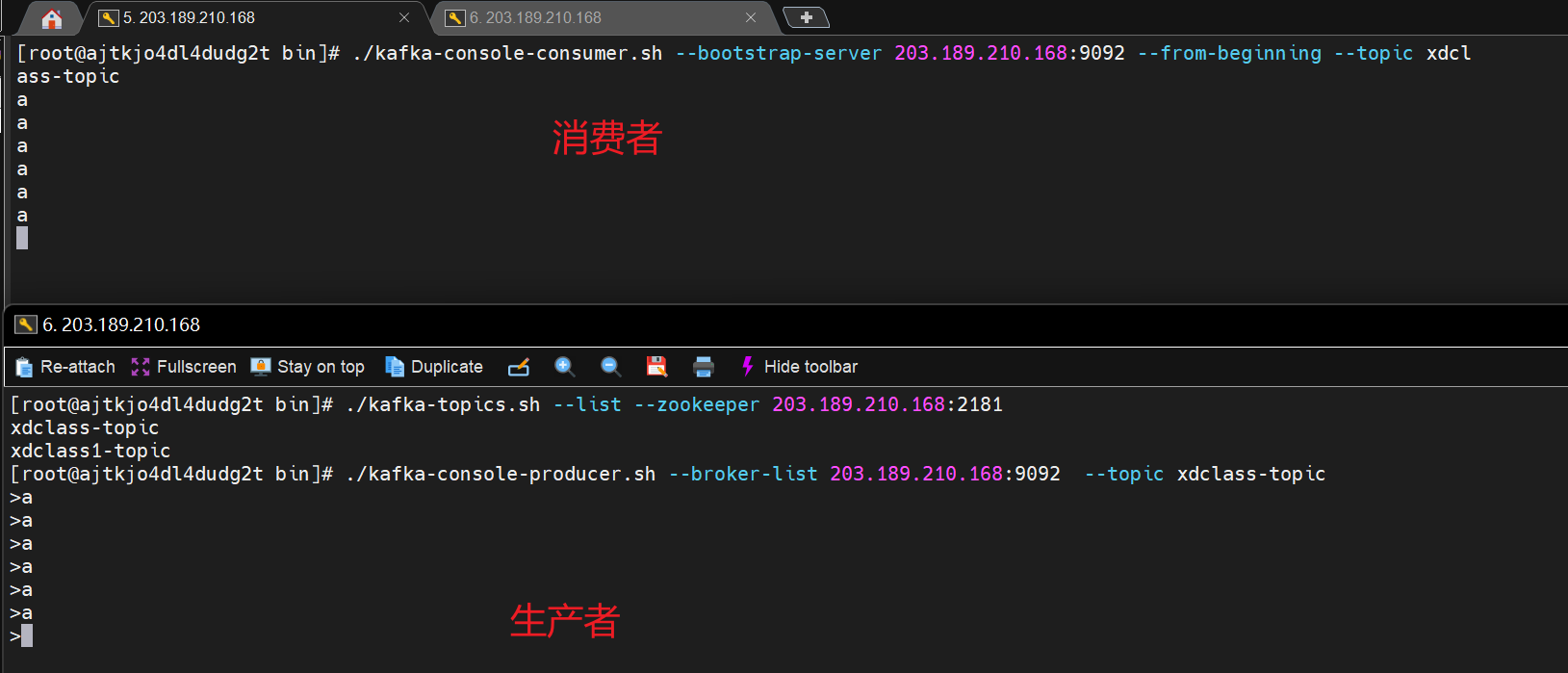
现象
-
只有一个消费者可以消费到数据,一个分区只能被同个消费者组下的某个消费者进行消费
-

-
发布订阅
-
发布/订阅(publish/subscribe)
- 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。
- 和点对点方式不同,发布到topic的消息会被所有订阅者消费。
-
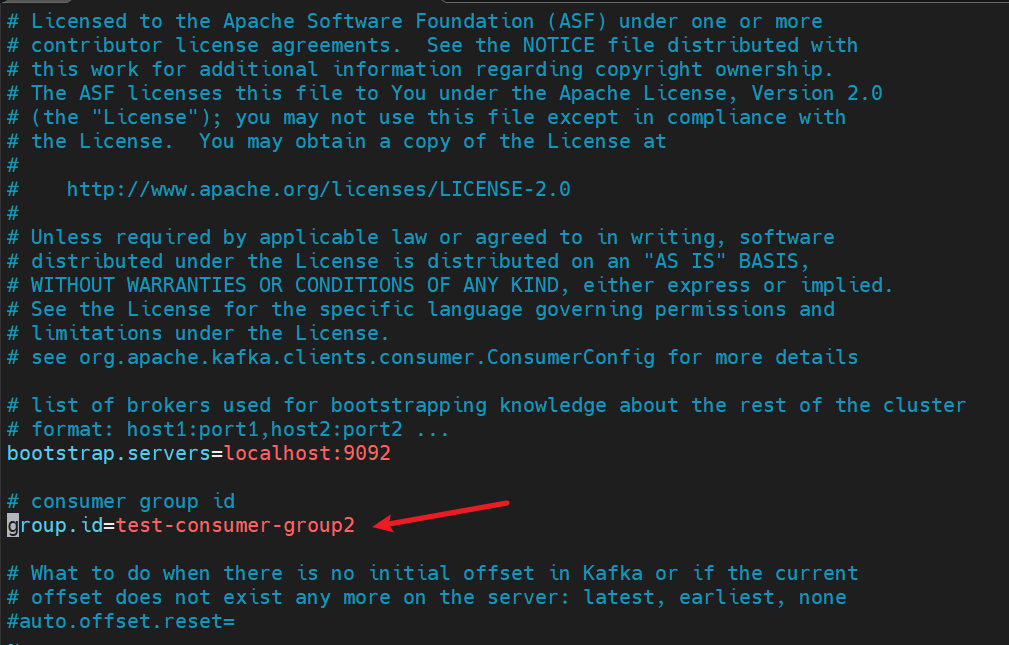
编辑消费者配置(确保group.id 不一样)
- 编辑 config/consumer-1.properties
- 编辑 config/consumer-2.properties
-
创建topic, 2个分区
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t2
- 指定配置文件启动 两个消费者
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-1.properties
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-2.properties


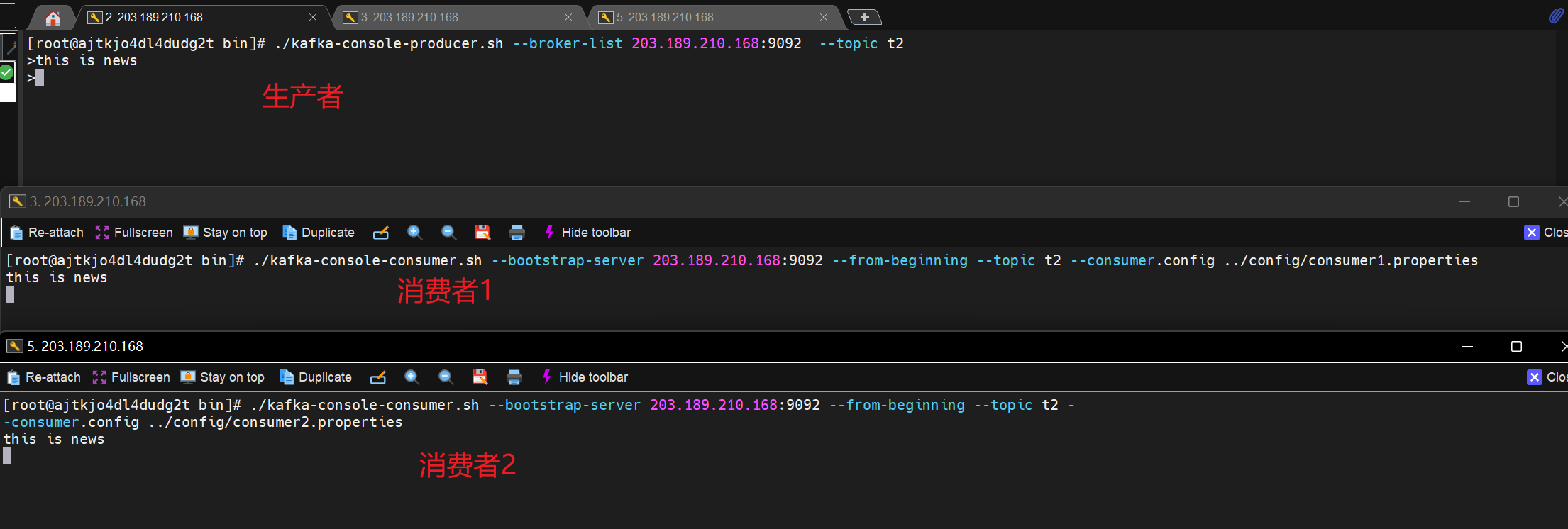
- 现象
- 两个不同消费者组的节点,都可以消费到消息,实现发布订阅模型
代码操作
创建项目
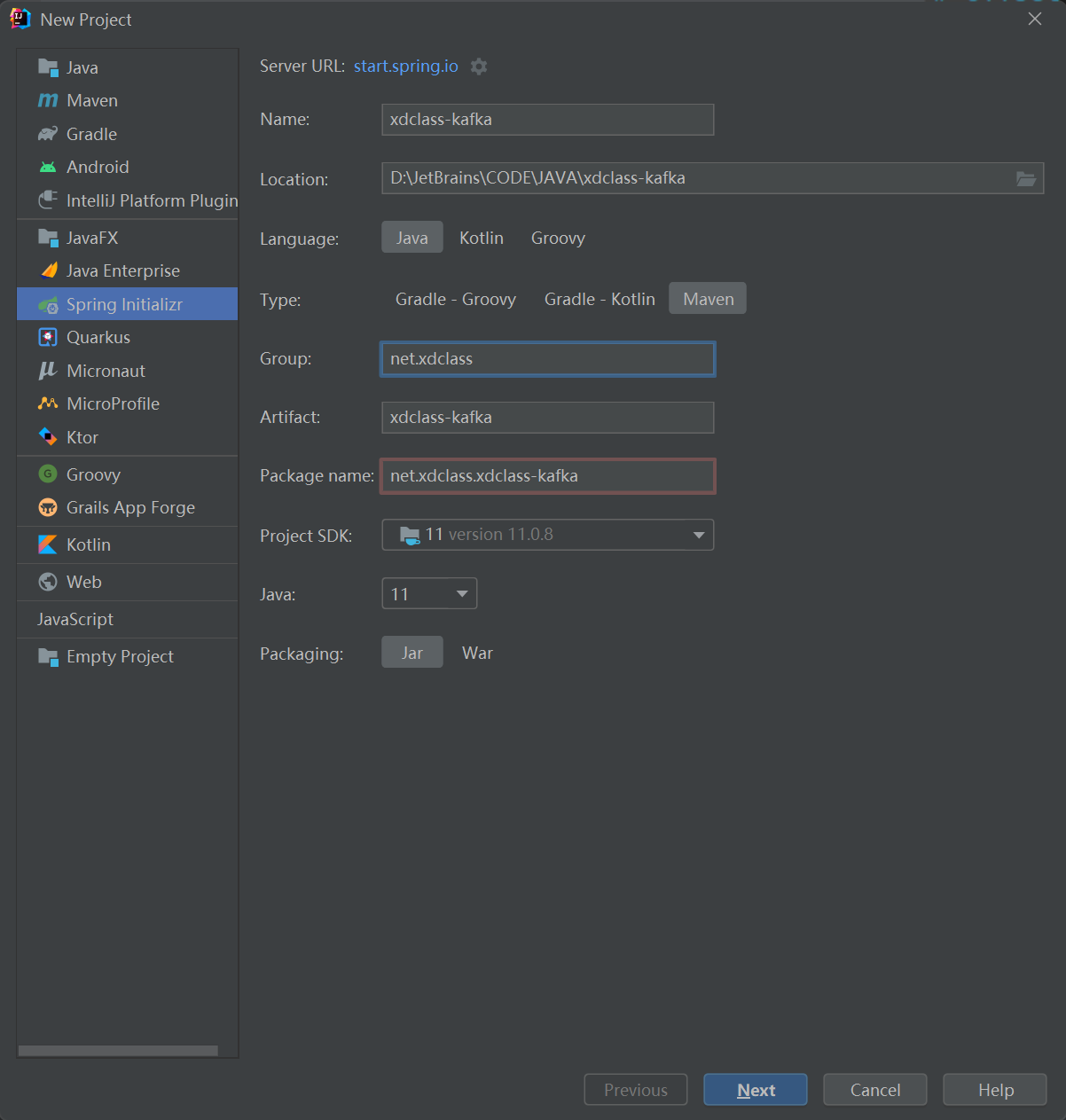
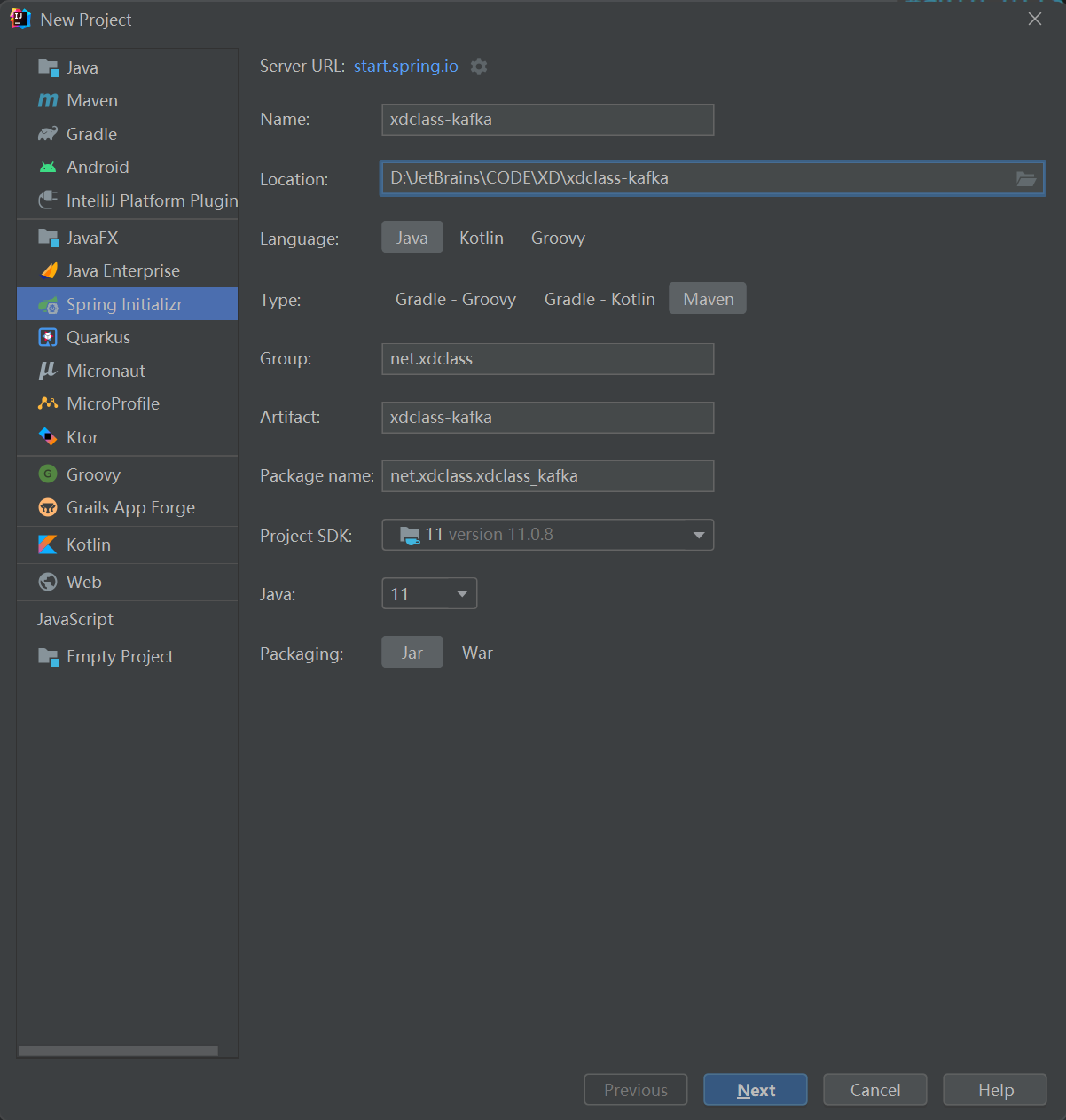
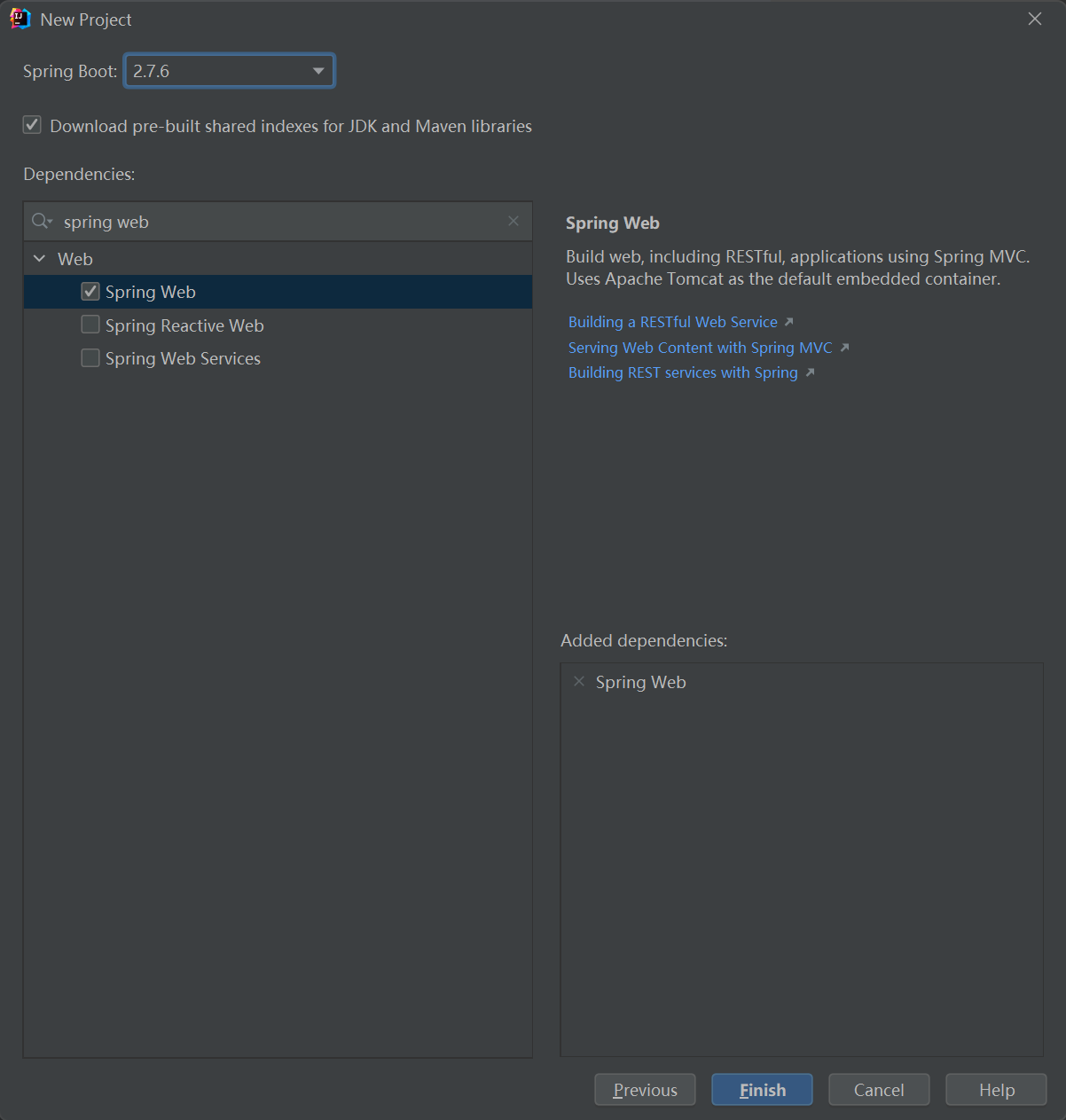
官方依赖: kafka-clients
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
server操作
public class KafkaAdminTest {
private static final String TOPIC_NAME = "xdclass-sp-topic-test";
/**
* 设置admin 客户端
*
* @return
*/
public static AdminClient initAdminClient() {
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9092");
AdminClient adminClient = AdminClient.create(properties);
return adminClient;
}
/**
* 创建topic
*/
@Test
public void createTopicTest() {
AdminClient adminClient = initAdminClient();
NewTopic newTopic = new NewTopic(TOPIC_NAME, 2, (short) 1);
CreateTopicsResult createTopicsResult = adminClient.createTopics(Arrays.asList(newTopic));
try {
createTopicsResult.all().get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
/**
* 列举topic
*
* @throws ExecutionException
* @throws InterruptedException
*/
@Test
public void listTopicTest() throws ExecutionException, InterruptedException {
AdminClient adminClient = initAdminClient();
ListTopicsOptions options = new ListTopicsOptions();
options.listInternal(true);
ListTopicsResult listTopicsResult = adminClient.listTopics(options);
Set<String> topics = listTopicsResult.names().get();
for (String topic : topics) {
System.err.println(topic);
}
}
/**
* 删除topic
*
* @throws ExecutionException
* @throws InterruptedException
*/
@Test
public void delTopicTest() throws ExecutionException, InterruptedException {
AdminClient adminClient = initAdminClient();
DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList("xdclass-v1-sp-topic-test11111"));
deleteTopicsResult.all().get();
}
/**
* 查看某个topic详情
*
* @throws ExecutionException
* @throws InterruptedException
*/
@Test
public void detailTopicTest() throws ExecutionException, InterruptedException {
AdminClient adminClient = initAdminClient();
DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME));
Map<String, TopicDescription> stringTopicDescriptionMap = describeTopicsResult.all().get();
Set<Map.Entry<String, TopicDescription>> entries = stringTopicDescriptionMap.entrySet();
entries.stream().forEach((entry) -> System.out.println("name:" + entry.getKey() + ", desc:" + entry.getValue()));
}
/**
* 增加分区数量
*
* @throws ExecutionException
* @throws InterruptedException
*/
@Test
public void incrPartitionTopicTest() throws ExecutionException, InterruptedException {
Map<String, NewPartitions> infoMap = new HashMap<>(1);
AdminClient adminClient = initAdminClient();
NewPartitions newPartitions = NewPartitions.increaseTo(5);
infoMap.put(TOPIC_NAME, newPartitions);
CreatePartitionsResult createPartitionsResult = adminClient.createPartitions(infoMap);
createPartitionsResult.all().get();
}
}
producer操作
public class KafkaProducerTest {
public static final String TOPIC_NAME = "xdclass-sp-topic-test";
public static Properties getProperties() {
Properties props = new Properties();
// broker地址
props.put("bootstrap.servers", "ip:9092,ip:9093,ip:9094");
// 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
props.put("acks", "all");
//props.put(ProducerConfig.ACKS_CONFIG, "all");
// 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
props.put("retries", 0);
//props.put(ProducerConfig.RETRIES_CONFIG, 0);
// 生产者缓存每个分区未发送的消息,缓存的大小是通过 batch.size 配置指定的,默认值是16KB
props.put("batch.size", 16384);
/**
* 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满
* 如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端
* 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送减少请求
* 如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
*/
props.put("linger.ms", 5);
/**
* buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
* 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器
* 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
* buffer.memory要大于batch.size,否则会报申请内存不#足的错误,不要超过物理内存,根据实际情况调整
* 需要结合实际业务情况压测进行配置
*/
props.put("buffer.memory", 33554432);
/**
* key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被设置,
* 即使消息中没有指定key,序列化器必须是一个实
org.apache.kafka.common.serialization.Serializer接口的类,
* 将key序列化成字节数组。
*/
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
/**
* send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
* 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
* <p>
* 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
* 发送消息后返回的一个 Future 对象,调用get即可
* <p>
* 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
* 1)main线程发送消息到RecordAccumulator即返回
* 2)sender线程从RecordAccumulator拉取信息发送到broker
* 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
*/
@Test
public void testSend() {
Properties properties = getProperties();
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 9; i++) {
Future<RecordMetadata> future = producer.send(new ProducerRecord<>(TOPIC_NAME, "xdclass-key-test" + i, "xdclass-value" + i));
try {
RecordMetadata recordMetadata = future.get();
System.out.println("发送状态:" + recordMetadata.toString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
}
/**
* 发送消息携带回调函数
*/
@Test
public void testSendWithCallback() {
Properties properties = getProperties();
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 3; i++) {
producer.send(new ProducerRecord<>(TOPIC_NAME, "xdclass-key" + i, "xdclass-value" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.err.println("发送状态:" + metadata.toString());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
/**
* 发送给消息携带回调函数,指定某个分区
* <p>
* 实现顺序消息
*/
@Test
public void testSendWithCallbackAndPartition() {
Properties properties = getProperties();
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("xdclass-v1-sp-topic-test", 5, "xdclass-key" + i, "xdclass-value" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.err.println("发送状态:" + metadata.toString());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
/**
* 自定义分区策略
*/
@Test
public void testSendWithPartitionStrategy() {
Properties properties = getProperties();
properties.put("partitioner.class", "net.xdclass.xdclass_kafka.config.XdclassPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("xdclass-v1-sp-topic-test", "xdclass-key" + i, "xdclass-value" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.err.println("发送状态:" + metadata.toString());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
}
consumer操作
- 消费者配置
#消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
group.id
#为true则自动提交偏移量
enable.auto.commit
#自动提交offset周期
auto.commit.interval.ms
#重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理,
#默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
auto.offset.reset
#序列化器
key.deserializer
-
如果需要从头消费partition消息,怎操作?
- auto.offset.reset 配置策略即可
- 默认是latest,需要改为 earliest 且消费者组名变更 ,即可实现从头消费
//默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效 props.put("auto.offset.reset","earliest"); -
自动提交offset问题
- 没法控制消息是否正常被消费
- 适合非严谨的场景,比如日志收集发送
-
手工提交offset配置和测试
- 初次启动消费者会请求broker获取当前消费的offset值
-
手工提交offset
- 同步 commitSync 阻塞当前线程 (自动失败重试)
- 异步 commitAsync 不会阻塞当前线程 (没有失败重试,回调callback函数获取提交信息,记录日志)
public class KafkaConsumerTest {
public static Properties getProperties() {
Properties props = new Properties();
//broker地址
props.put("bootstrap.servers", "ip:9092,ip:9093,ip:9094");
//消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
props.put("group.id", "xdclass-g1");
//默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效
props.put("auto.offset.reset", "earliest");
//自动提交offset
props.put("enable.auto.commit", "false");
//自动提交offset延迟时间
// props.put("auto.commit.interval.ms", "1000");
//反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
@Test
public void simpleConsumerTest() {
Properties props = getProperties();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅topic主题
consumer.subscribe(Arrays.asList(KafkaProducerTest.TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.err.printf("topid = %s ,offset = %d ,key = %s ,value = %s%n", record.topic(), record.offset(), record.key(), record.value());
}
//
// consumer.commitSync();
if (!records.isEmpty()) {
consumer.commitAsync((offsets, exception) -> {
if (exception == null) {
System.err.println("手动提交offset成功:" + offsets.toString());
} else {
System.err.println("手动提交offset失败:" + offsets.toString());
}
});
}
}
}
}
Spring依赖: spring-kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
spring:
kafka:
bootstrap-servers: ip:9092,ip:9093,ip:9094
producer:
# 消息重发的次数。
retries: 0
#一个批次可以使用的内存大小
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: all
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
#手工ack,调用ack后立刻提交offset
ack-mode: manual_immediate
#容器运行的线程数
concurrency: 4
发送普通消息+事务
@RestController
public class UserController {
private static final String TOPIC_NAME = "user.register.topic";
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/api/v1/{num}")
private void sendMessage1(@PathVariable("num") String num) {
kafkaTemplate.send(TOPIC_NAME, "这是一个此消息,num=" + num).addCallback(success -> {
String topic = success.getRecordMetadata().toString();
int partition = success.getRecordMetadata().partition();
long offset = success.getRecordMetadata().offset();
System.err.println("发送成功:topic=" + topic + ", partition=" + partition + ", offset = " + offset);
}, failure -> {
System.err.println("发送消息失败:" + failure.getMessage());
});
}
/**
* 注解方式的事务
* @param num
*/
@GetMapping("/api/v1/tran1")
@Transactional(rollbackFor = RuntimeException.class)
public void sendMessage2(int num){
kafkaTemplate.send(TOPIC_NAME,"这个是事务消息 1 i="+num);
if(num == 0){
System.out.println("发送失败");
throw new RuntimeException();
}
kafkaTemplate.send(TOPIC_NAME,"这个是事务消息 2 i="+num);
}
/**
* 声明式事务
* @param num
*/
@GetMapping("/api/v1/tran2")
public void sendMessage3(int num){
kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback<String, Object, Object>() {
@Override
public Object doInOperations(KafkaOperations<String, Object> kafkaOperations) {
kafkaOperations.send(TOPIC_NAME,"这个是事务消息 1 i="+num);
if(num == 0){
System.out.println("发送失败");
throw new RuntimeException();
}
kafkaOperations.send(TOPIC_NAME,"这个是事务消息 2 i="+num);
return true;
}
});
}
}
监听
@Component
public class MQListener {
@KafkaListener(topics = {"user.register.topic"},groupId = "xdclass-gp2")
public void onMessage(ConsumerRecord<?,?> record, Acknowledgment ack,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
System.err.println("消费消息:" + record.topic() + "--------- " + record.partition() + "----------- " +record.value());
ack.acknowledge();;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号