
自增ID算法snowflake - C#版
2018-05-09 14:56 会飞的雪鹿 阅读(1462) 评论(0) 编辑 收藏 举报急景流年,铜壶滴漏,时光缱绻如画,岁月如诗如歌。转载一篇博客来慰藉,易逝的韶华。
使用UUID或者GUID产生的ID没有规则
Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现的
概述
分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
该项目地址为:https://github.com/twitter/snowflake是用Scala实现的。
python版详见开源项目https://github.com/erans/pysnowflake。
结构
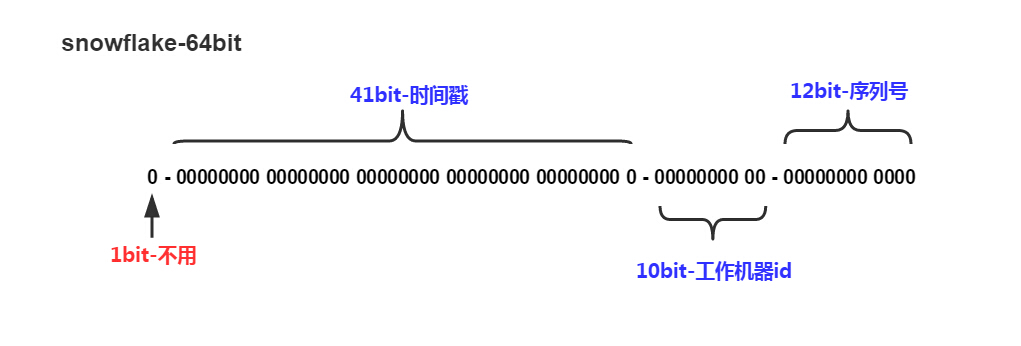
snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。据说:snowflake每秒能够产生26万个ID。
从图上看除了第一位不可用之外其它三组均可浮动站位,据说前41位就可以支撑到2082年,10位的可支持1023台机器,最后12位序列号可以在1毫秒内产生4095个自增的ID。
在多线程中使用要加锁。
看懂代码前 先来点计算机常识:<<左移 假如1<<2 :1左移2位=1*2^2=4(这里^是多少次方的意思,和下面的不同,哈别混淆。)
^异或 :true^true=false false^false=false true^false=true false^true=true 例子: 1001^0001=1000
负数的二进制:
第二步:各位取反,0变1,1变0
第三步:最后面加1
好了废话不多说 直接代码:
public class IdWorker { //机器ID private static long workerId; private static long twepoch = 687888001020L; //唯一时间,这是一个避免重复的随机量,自行设定不要大于当前时间戳 private static long sequence = 0L; private static int workerIdBits = 4; //机器码字节数。4个字节用来保存机器码(定义为Long类型会出现,最大偏移64位,所以左移64位没有意义) public static long maxWorkerId = -1L ^ -1L << workerIdBits; //最大机器ID private static int sequenceBits = 10; //计数器字节数,10个字节用来保存计数码 private static int workerIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数 private static int timestampLeftShift = sequenceBits + workerIdBits; //时间戳左移动位数就是机器码和计数器总字节数 public static long sequenceMask = -1L ^ -1L << sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微秒在进行生成 private long lastTimestamp = -1L; /// <summary> /// 机器码 /// </summary> /// <param name="workerId"></param> public IdWorker(long workerId) { if (workerId > maxWorkerId || workerId < 0) throw new Exception(string.Format("worker Id can't be greater than {0} or less than 0 ", workerId)); IdWorker.workerId = workerId; } public long nextId() { lock (this) { long timestamp = timeGen(); if (this.lastTimestamp == timestamp) { //同一微秒中生成ID IdWorker.sequence = (IdWorker.sequence + 1) & IdWorker.sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限 if (IdWorker.sequence == 0) { //一微秒内产生的ID计数已达上限,等待下一微秒 timestamp = tillNextMillis(this.lastTimestamp); } } else { //不同微秒生成ID IdWorker.sequence = 0; //计数清0 } if (timestamp < lastTimestamp) { //如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过 throw new Exception(string.Format("Clock moved backwards. Refusing to generate id for {0} milliseconds", this.lastTimestamp - timestamp)); } this.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳 long nextId = (timestamp - twepoch << timestampLeftShift) | IdWorker.workerId << IdWorker.workerIdShift | IdWorker.sequence; return nextId; } } /// <summary> /// 获取下一微秒时间戳 /// </summary> /// <param name="lastTimestamp"></param> /// <returns></returns> private long tillNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /// <summary> /// 生成当前时间戳 /// </summary> /// <returns></returns> private long timeGen() { return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; } }
调用:
IdWorker idworker = new IdWorker(1); for (int i = 0; i < 1000; i++) { Console.WriteLine(idworker.nextId()); }
其他算法:
方法一:UUID
UUID是通用唯一识别码 (Universally Unique Identifier),在其他语言中也叫GUID,可以生成一个长度32位的全局唯一识别码。
String uuid = UUID.randomUUID().toString()
结果示例:
046b6c7f-0b8a-43b9-b35d-6489e6daee91
为什么无序的UUID会导致入库性能变差呢?
这就涉及到 B+树索引的分裂:
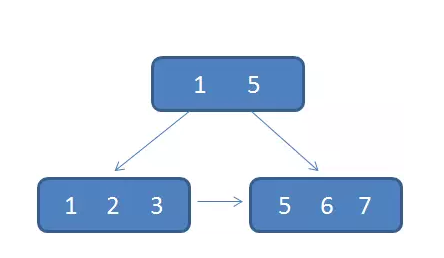
众所周知,关系型数据库的索引大都是B+树的结构,拿ID字段来举例,索引树的每一个节点都存储着若干个ID。
如果我们的ID按递增的顺序来插入,比如陆续插入8,9,10,新的ID都只会插入到最后一个节点当中。当最后一个节点满了,会裂变出新的节点。这样的插入是性能比较高的插入,因为这样节点的分裂次数最少,而且充分利用了每一个节点的空间。
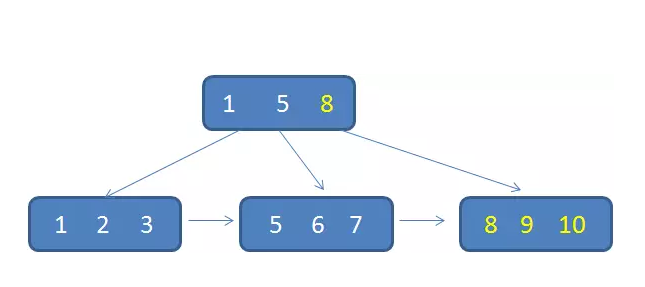
但是,如果我们的插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
方法二:数据库自增主键
假设名为table的表有如下结构:
id feild
35 a
每一次生成ID的时候,访问数据库,执行下面的语句:
begin;
REPLACE INTO table ( feild ) VALUES ( 'a' );
SELECT LAST_INSERT_ID();
commit;
REPLACE INTO 的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。
这样一来,每次都可以得到一个递增的ID。
为了提高性能,在分布式系统中可以用DB proxy请求不同的分库,每个分库设置不同的初始值,步长和分库数量相等:
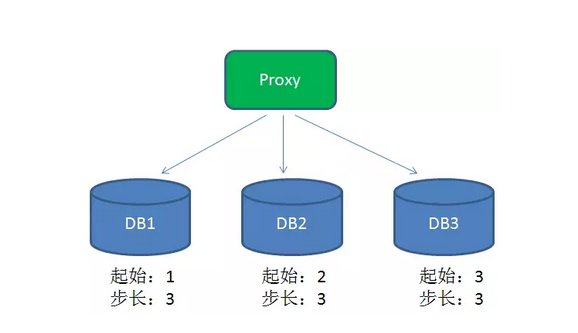
这样一来,DB1生成的ID是1,4,7,10,13....,DB2生成的ID是2,5,8,11,14.....


