


ES中文分词器安装以及自定义配置
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.8.10的ES,所以就下载ik-6.8.10.zip的文件。
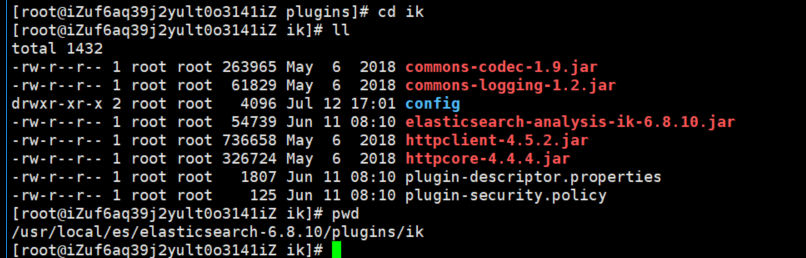
解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
重启ElasticSearch
测试效果
未使用ik分词器的效果
### 原生分词 GET /_analyze { "analyzer": "standard", "text": "中华人民共和国" }
效果:
{ "tokens" : [ { "token" : "中", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "华", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "人", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "民", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "共", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "和", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 }, { "token" : "国", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 6 } ] }
ik_smart分词效果:
# ik_smart:会做最粗粒度的拆分 GET /_analyze { "analyzer": "ik_smart", "text": "中华人民共和国" }
效果:
{ "tokens" : [ { "token" : "中华人民共和国", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 } ] }
ik_max_word会将文本做最细粒度的拆分
## ik_max_word会将文本做最细粒度的拆分 GET /_analyze { "analyzer": "ik_max_word", "text": "中华人民共和国" }
效果:
{ "tokens" : [ { "token" : "中华人民共和国", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 }, { "token" : "中华人民", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "中华", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 2 }, { "token" : "华人", "start_offset" : 1, "end_offset" : 3, "type" : "CN_WORD", "position" : 3 }, { "token" : "人民共和国", "start_offset" : 2, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "人民", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 5 }, { "token" : "共和国", "start_offset" : 4, "end_offset" : 7, "type" : "CN_WORD", "position" : 6 }, { "token" : "共和", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 7 }, { "token" : "国", "start_offset" : 6, "end_offset" : 7, "type" : "CN_CHAR", "position" : 8 } ] }
对于上面两个分词效果的解释:
- 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
- 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
自定义扩展词
一些热词,自定义的词,ik是不会收录的,这时候我们需要自定义扩展。
比如:王者荣耀。
分词的效果如下,显然是不满足我们需求的,这时候就需要自定义.
GET /_analyze { "analyzer": "ik_smart", "text": "王者荣耀" }
效果:
{ "tokens" : [ { "token" : "王者", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "荣耀", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 } ] }
在config目录下新建ext.dic文件
王者荣耀
进入 es安装目录/plugins/ik/config
编辑IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es,测试效果
{ "tokens" : [ { "token" : "王者荣耀", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 } ] }
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.8.10的ES,所以就下载ik-6.8.10.zip的文件。
解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
重启ElasticSearch
测试效果
未使用ik分词器的效果
### 原生分词
GET /_analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "华",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
ik_smart分词效果:
# ik_smart:会做最粗粒度的拆分
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
ik_max_word会将文本做最细粒度的拆分
## ik_max_word会将文本做最细粒度的拆分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
对于上面两个分词效果的解释:
- 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
- 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
自定义扩展词
一些热词,自定义的词,ik是不会收录的,这时候我们需要自定义扩展。
比如:王者荣耀。
分词的效果如下,显然是不满足我们需求的,这时候就需要自定义.
GET /_analyze
{
"analyzer": "ik_smart",
"text": "王者荣耀"
}
效果:
{
"tokens" : [
{
"token" : "王者",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "荣耀",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
在config目录下新建ext.dic文件
王者荣耀
进入 es安装目录/plugins/ik/config
编辑IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es,测试效果
{
"tokens" : [
{
"token" : "王者荣耀",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
}
]
}
