Hbase的命令及API操作
下面记录一下Hbase的简单命令,以及相关的API操作,Hbase虽然也是一种数据库,但是基本命令和MySQL不一样。
基本概念
Hbase因为是列存储,因此出现了一些新的概念,分别是行键RowKey、列族Column Family、列Column、单元Cell和命名空间NameSpace。大部分概念可以通过excel表格来理解,以下是它们的示意图。
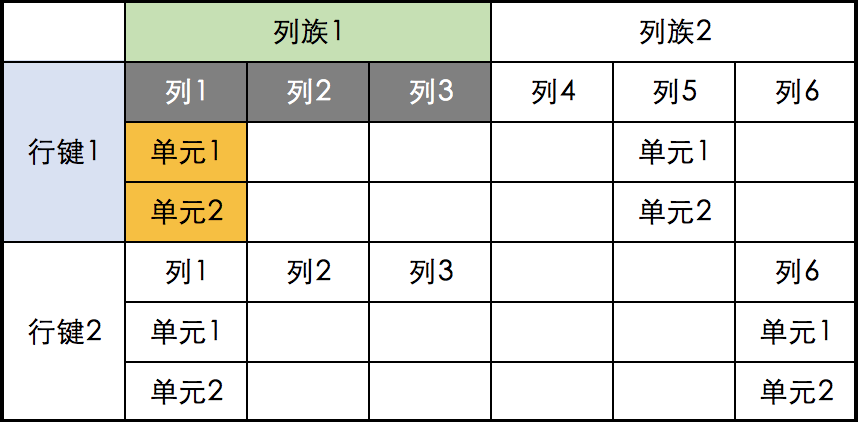
(1)行键
行键类似MySQL中的主键,但hbase中没有主键的概念,它默认按照字典序排列,这个是分布式存储的基础。建表的时候是不需要指定行键的,它是在插入数据的指定。
(2)列族和列
一个表中至少包含一个列族,如图它相当如一个大的类,将包含很多小类,小类就是列。列族下面可以有0到多个列,列在建表的时候无需指定,在添加数据时可以动态增删。从上面示意图可以看出,增删列时最后会形成一个稀疏的数据结构,它不同MySQL那么紧凑密集。
(3)单元
hbase是可以增删改查数据的,实际上它的数据是存储在hdfs上,理论上是不能修改的,为了能做到更新数据,hbase存储的数据将有一个时间戳来标识,不同时间戳的数据就存储在一个个的不同单元中,默认只显示最新时间戳的数据,给人一种可以修改数据的感觉。因此单元里就是保存不同时间戳的数据。
(4)命名空间
命名空间相当如MySQL中的database,在hbase中使用namespace,均是可以区分同名表名的,hbase中如果不指定namespace就默认是default的命名空间。
基本命令
基本命令包含DDL(增删表)和DML(增删改查表数据),其中DDL命令需要经过HMaster,DML只需要经过HRegionServer,下面记录一下。
DDL相关
(1)新建一个表,下面指定了命名空间的操作。
# 新建命名空间,默认是default hbase(main):002:0> create_namespace "hbasedemo" 2020-01-11 11:43:35,074 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/software/hbase-0.98.17-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/software/hadoop-2.7.1/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 0 row(s) in 2.0560 seconds # 查看命名空间 hbase(main):003:0> list_namespace NAMESPACE default hbase hbasedemo 3 row(s) in 0.0620 seconds # 新建表,至少需要指定表名、列族,basic和data就是列族,这是省略写法 hbase(main):004:0> create 'hbasedemo:star','basic','data' 0 row(s) in 1.0880 seconds => Hbase::Table - hbasedemo:star # 查看表是否建立,如果是默认就用list命令查看表 hbase(main):005:0> list_namespace_tables 'hbasedemo' TABLE star 1 row(s) in 0.0640 seconds
(2)新建一个表,如果不指定命令空间,默认就是在default命名空间下,下面使用建表的完整写法。
# 完整写法 hbase(main):015:0> create 'star',{NAME=>'basic'},{NAME=>'data'} 0 row(s) in 0.4320 seconds => Hbase::Table - star # 查看表结构 hbase(main):017:0> desc 'star' Table star is ENABLED star COLUMN FAMILIES DESCRIPTION {NAME => 'basic', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', D ATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true ', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} {NAME => 'data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DA TA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true' , BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} 2 row(s) in 0.0650 seconds
(3)删除一个表,删除刚才命名空间下建立的表。
# 删除表,需要先disable让其不可用,反之使用enable使其可用 hbase(main):007:0> disable 'hbasedemo:star' 0 row(s) in 1.3800 seconds # 查看是否已经禁用 hbase(main):010:0> is_enabled 'hbasedemo:star' false 0 row(s) in 0.0370 seconds # 删除表,指定了命名空间前面 hbase(main):011:0> drop 'hbasedemo:star' 0 row(s) in 0.2540 seconds # 查看是否删除 hbase(main):012:0> list_namespace_tables 'hbasedemo' TABLE 0 row(s) in 0.0130 seconds
(4)删除一个表,如果删除default命名空间下的表。
hbase(main):019:0> disable 'star' 0 row(s) in 1.3080 seconds # 删除表 hbase(main):020:0> drop 'star' 0 row(s) in 0.2010 seconds # exists命令查看表是否存在 hbase(main):021:0> exists 'star' Table star does not exist 0 row(s) in 0.0240 seconds
另外,删除了表后,就可以删除命名空间了,否则会提示命名空间下不为空。
hbase(main):006:0> drop_namespace 'hbasedemo' ERROR: org.apache.hadoop.hbase.constraint.ConstraintException: Only empty namespaces can be removed. Namespace hbasedemo has 1 tables
删除了表后,就可以删除命名空间。
# 删除命名空间 hbase(main):013:0> drop_namespace 'hbasedemo' 0 row(s) in 0.0520 seconds # 已删除 hbase(main):014:0> list_namespace NAMESPACE default hbase
DML相关
以下DML相关操作,在默认命名空间下进行,如果需要指定命名空间,表名前加命名空间即可,即'命名空间:表名'来指定。
(1)插入数据 ,使用命令''put 表名,行键,'列族:列',数据''的格式来添加。
# 插入两条数据 hbase(main):024:0> put 'star','s1','basic:name','messi' 0 row(s) in 0.2160 seconds hbase(main):025:0> put 'star','s1','data:score',51 0 row(s) in 0.0160 seconds
(2)查找数据,主要为get和scan命令,其中scan为全表扫描,get是指定列族和列的查询方式。
get命令
# 查询s1行键的所有数据 hbase(main):026:0> get 'star','s1' COLUMN CELL basic:name timestamp=1578716219238, value=messi data:score timestamp=1578716244483, value=51 2 row(s) in 0.4040 seconds # 查询s1行键的指定列族的数据 hbase(main):027:0> get 'star','s1',{COLUMN=>'basic'} COLUMN CELL basic:name timestamp=1578716219238, value=messi 1 row(s) in 0.0210 seconds # 查询s1行键的指定列族的数据,简写方式 hbase(main):028:0> get 'star','s1','data' COLUMN CELL data:score timestamp=1578716244483, value=51 1 row(s) in 0.0100 seconds # 查询s1行键的指定列族和列的数据 hbase(main):029:0> get 'star','s1',{COLUMN=>'basic:name'} COLUMN CELL basic:name timestamp=1578716219238, value=messi 1 row(s) in 0.0090 seconds # 查询s1行键的指定列族和列的数据,简写方式 hbase(main):028:0> get 'star','s1','data:score' COLUMN CELL data:score timestamp=1578716244483, value=51 1 row(s) in 0.0110 seconds
scan命令
# 先插入一条数据 hbase(main):034:0> put 'star','s1','data:assists',10 0 row(s) in 0.0650 seconds # 全表查询 hbase(main):035:0> scan 'star' ROW COLUMN+CELL s1 column=basic:name, timestamp=1578716219238, value=messi s1 column=data:assists, timestamp=1578717093292, value=10 s1 column=data:score, timestamp=1578716244483, value=51 1 row(s) in 0.0230 seconds # 指定列族 hbase(main):036:0> scan 'star',{COLUMNS=>['basic','data']} ROW COLUMN+CELL s1 column=basic:name, timestamp=1578716219238, value=messi s1 column=data:assists, timestamp=1578717093292, value=10 s1 column=data:score, timestamp=1578716244483, value=51 1 row(s) in 0.0200 seconds # 指定列 hbase(main):037:0> scan 'star',{COLUMNS=>['basic:name','data:score']} ROW COLUMN+CELL s1 column=basic:name, timestamp=1578716219238, value=messi s1 column=data:score, timestamp=1578716244483, value=51 1 row(s) in 0.0180 seconds
(3)更新数据
更新数据,其实也是插入数据,只是默认只显示最新时间戳的数据。后续再补充可以显示历史版本数据的操作。
# 查看梅西当前进球数 hbase(main):038:0> get 'star','s1','data:score' COLUMN CELL data:score timestamp=1578716244483, value=51 1 row(s) in 0.0210 seconds # 更新梅西进球数 hbase(main):039:0> put 'star','s1','data:score',60 0 row(s) in 0.0260 seconds # 再次查看,显示更新后的数据 hbase(main):040:0> get 'star','s1','data:score' COLUMN CELL data:score timestamp=1578717295077, value=60 1 row(s) in 0.0110 seconds
(4)删除数据
删除数据后还未从HDFS上完全抹掉,需要HFile在major compact后,标记为删除的数据才会被真正丢弃。
# 先查看一下 hbase(main):041:0> scan 'star' ROW COLUMN+CELL s1 column=basic:name, timestamp=1578716219238, value=messi s1 column=data:assists, timestamp=1578717093292, value=10 s1 column=data:score, timestamp=1578717295077, value=60 1 row(s) in 0.0180 seconds # 删除指定行键下的列 hbase(main):042:0> delete 'star','s1','data:assists' 0 row(s) in 0.0390 seconds # 已删除梅西的助攻数 hbase(main):043:0> scan 'star' ROW COLUMN+CELL s1 column=basic:name, timestamp=1578716219238, value=messi s1 column=data:score, timestamp=1578717295077, value=60 1 row(s) in 0.0100 seconds # 删除整个行键数据 hbase(main):044:0> deleteall 'star','s1' 0 row(s) in 0.0230 seconds # 已删除 hbase(main):045:0> scan 'star' ROW COLUMN+CELL 0 row(s) in 0.0070 seconds
如果要能查看历史版本的数据,建表时需要指定能查看的历史版本数。
# 新建表,指定列族能提供的历史版本数 hbase(main):047:0> create 'star1',{NAME=>'basic',VERSIONS=>3},{NAME=>'data',VERSIONS=>2} 0 row(s) in 0.4300 seconds # 插入数据 => Hbase::Table - star1 hbase(main):048:0> put 'star1','s1','basic:name','ronald' 0 row(s) in 0.1110 seconds hbase(main):049:0> put 'star1','s1','basic:age',34 0 row(s) in 0.0380 seconds hbase(main):050:0> put 'star1','s1','data:score',45 0 row(s) in 0.0190 seconds hbase(main):051:0> put 'star1','s1','data:score',46 0 row(s) in 0.0080 seconds hbase(main):052:0> put 'star1','s1','data:score',47 0 row(s) in 0.0250 seconds hbase(main):053:0> put 'star1','s1','data:score',48 0 row(s) in 0.0150 seconds # 默认只显示最新信息 hbase(main):054:0> scan 'star1' ROW COLUMN+CELL s1 column=basic:age, timestamp=1578718726764, value=34 s1 column=basic:name, timestamp=1578718715616, value=ronald s1 column=data:score, timestamp=1578718771868, value=48 1 row(s) in 0.0770 seconds # 指定历史版本数量,然后指定了3条,但是建表只提供2条,因此就显示2条 hbase(main):055:0> scan 'star1',{COLUMNS=>'data:score',VERSIONS=>3} ROW COLUMN+CELL s1 column=data:score, timestamp=1578718771868, value=48 s1 column=data:score, timestamp=1578718769656, value=47 1 row(s) in 0.0340 seconds # 只有1条,虽然能提供3条,但是也只显示1条 hbase(main):056:0> scan 'star1',{COLUMNS=>'basic',VERSIONS=>3} ROW COLUMN+CELL s1 column=basic:age, timestamp=1578718726764, value=34 s1 column=basic:name, timestamp=1578718715616, value=ronald 1 row(s) in 0.0180 seconds # get命令也可以指定版本数 hbase(main):058:0> get 'star1','s1',{COLUMNS=>'basic',VERSIONS=>3} COLUMN CELL basic:age timestamp=1578718726764, value=34 basic:name timestamp=1578718715616, value=ronald 2 row(s) in 0.0350 seconds # 可以指定时间戳 hbase(main):059:0> get 'star1','s1',{COLUMNS=>'data:score',TIMESTAMP=>1578718769656} COLUMN CELL data:score timestamp=1578718769656, value=47 1 row(s) in 0.0090 seconds
基本API操作
下面是相关API基本操作,覆盖上面基础的的DDL和DML操作,执行过程中使用了log4j来打印日志,log4j的配置文件需放在src目录下。
log4j内容


log4j.rootLogger = info,stdout log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
(1)新建表
package com.boe; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.CompareFilter; import org.apache.hadoop.hbase.filter.Filter; import org.apache.hadoop.hbase.filter.RegexStringComparator; import org.apache.hadoop.hbase.filter.RowFilter; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** * HBase DDL和DML相关API操作 */ public class HBaseDemo { Configuration conf=null; @Before public void before(){ conf= HBaseConfiguration.create(); //通过连接zookeeper,获取hbase的连接地址 //可以多写几个zookeeper节点,一个节点可能会有宕机的可能,导致连接不上 conf.set("hbase.zookeeper.quorum","hadoop01:2181,hadoop02:2181,hadoop03:2181"); } //1 创建表 @Test public void createTable() throws IOException { //连接HBase //Configuration conf=HBaseConfiguration.create(); //通过连接zookeeper获取HBase的连接地址 //conf.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");//担心一个节点挂掉不保险,可以全写上 //连接HBase HBaseAdmin admin=new HBaseAdmin(conf); //创建表 //准备HTableDescriptor HTableDescriptor table=new HTableDescriptor(TableName.valueOf("employer"));//指定表名 //准备列族 HColumnDescriptor basic=new HColumnDescriptor("basic"); HColumnDescriptor other=new HColumnDescriptor("info"); //表添加列族 table.addFamily(basic);table.addFamily(other); //创建表 admin.createTable(table); //关闭管理权 admin.close(); } }
执行后新建表employer成功。

(2)添加数据
//2 向表中添加数据 @Test public void putData() throws IOException { HTable table=new HTable(conf,TableName.valueOf("employer")); //添加数据 //将每一条数据封装为put对象 Put put=new Put("e1".getBytes());//给定rowKey put.add("basic".getBytes(),"name".getBytes(),"clyang".getBytes()); put.add("basic".getBytes(),"age".getBytes(),"28".getBytes()); //添加数据 table.put(put); //关流 table.close(); }
查看表中数据,插入成功。

可以测试插入100万条数据的时间,本次是在mac下完成,内存8G。
//2.1 添加100万条数据,计算时长,本机32秒插入完成 //hbase shell查看结果发现,rowKey默认是按照字典序排列 @Test public void testMillion() throws IOException { HTable table=new HTable(conf,TableName.valueOf("employer")); //添加100万条数据 List<Put> list=new ArrayList<>(); long start = System.currentTimeMillis(); for (int i = 0; i <1000000 ; i++) { Put put=new Put(("e"+i).getBytes());//给定rowKey put.add("basic".getBytes(),"number".getBytes(),(i+"").getBytes()); list.add(put); if(list.size()==1000){ //添加数据 table.put(list); //关流 list.clear(); } } long end = System.currentTimeMillis(); System.err.println("运行时间为"+(end-start)); //关流 table.close(); }
查看控制台,运行时间为32秒左右,插入100万条数据已经算快了,可能本机配置不行,好一点的机器估计只要几秒。

(3)删除数据
//3 从表中删除数据 @Test public void deleteData() throws IOException { HTable table=new HTable(conf,TableName.valueOf("employer")); Delete del=new Delete("e999999".getBytes()); //删除整行 table.delete(del); //关流 table.close(); }
删除成功。

(4)查询数据
查询数据get和scan也要对应的API。
//4 查询数据 //a 字段来查 @Test public void getData() throws IOException { HTable table=new HTable(conf,TableName.valueOf("employer")); //获取数据 Get get=new Get("e1".getBytes()); Result result = table.get(get); //指定列族family和列名qualifier byte[] name = result.getValue("basic".getBytes(), "name".getBytes()); byte[] age = result.getValue("basic".getBytes(), "age".getBytes()); //打印 System.err.println(new String(name)+":"+new String(age)); //关流 table.close(); } //b 全表来查 @Test public void scanData() throws IOException { HTable table=new HTable(conf,TableName.valueOf("employer")); //获取扫描器 //Scan scan=new Scan();//全表扫描 Scan scan=new Scan("e8848".getBytes(),"e8849".getBytes());//指定起始和结束rowKey,部分扫描 ResultScanner scanner = table.getScanner(scan); //将扫描器转换为迭代器后才能遍历 Iterator<Result> iterator = scanner.iterator(); while(iterator.hasNext()){ Result result = iterator.next(); //从result中拿值 byte[] value = result.getValue("basic".getBytes(), "number".getBytes()); System.err.println(new String(value)); } table.close(); }
按字段查控制台

按全表查控制台,全表查还可以指定起始和结束行键,发现默认是按照字典序排列。

查询时,还可以根据行键来过滤,需要使用filter,API中提供了多种选择,这里使用行过滤器,过滤出含有8848行键的数据。
//c 查询数据,使用filter过滤 @Test public void filterData() throws IOException{ HTable table=new HTable(conf,TableName.valueOf("employer")); //获取扫描器 Scan scan=new Scan(); //获取过滤器 Filter filter=new RowFilter(CompareFilter.CompareOp.EQUAL,new RegexStringComparator(".*8848.*")); //设置过滤器 scan.setFilter(filter); //扫描数据 ResultScanner scanner = table.getScanner(scan); Iterator<Result> iterator = scanner.iterator(); while(iterator.hasNext()){ Result result = iterator.next(); //打印result中的值 System.err.println(new String(result.getValue("basic".getBytes(),"number".getBytes()))); } }
查看控制台,过滤成功。

(5)删除表
//5 删除表 @Test public void dropTable() throws IOException { HBaseAdmin admin=new HBaseAdmin(conf); //禁用 admin.disableTable("employer".getBytes()); //删除表 admin.deleteTable("employer".getBytes()); //关流 admin.close(); }
查看删除成功。

以上就是对HBase基础命令和API的记录,后续补充HBase原理相关的内容。
参考博文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号