Jdk1.8 JUC源码解析(1)-atomic-AtomicXXX
目录
一、Unsafe简介
在正式的开讲 juc-atomic框架系列之前,有必要先来了解下Java中的Unsafe类。
Unsafe类,来源于sun.misc包。该类封装了许多类似指针操作,可以直接进行内存管理、操纵对象、阻塞/唤醒线程等操作。Java本身不直接支持指针的操作,所以这也是该类命名为Unsafe的原因之一。
J.U.C中的许多CAS方法,内部其实都是Unsafe类在操作。
比如AtomicBoolean的compareAndSet方法:

unsafe.compareAndSwapInt方法是个native方法。(如果对象中的字段值与期望值相等,则将字段值修改为x,然后返回true;否则返回false):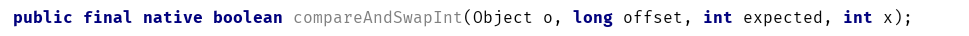
入参的含义如下:
| 参数名称 | 含义 |
|---|---|
| o | 需要修改的对象 |
| offset | 需要修改的字段到对象头的偏移量(通过偏移量,可以快速定位修改的是哪个字段) |
| expected | 期望值 |
| x | 要设置的值 |
Unsafe类中CAS方法都是native方法,需要通过CAS原子指令完成。在讲AQS时,里面有许多涉及CLH队列的操作,其实就是通过Unsafe类完成的指针操作。
二、Unsafe对象的创建
Unsafe是一个final类,不能被继承,也没有公共的构造器,只能通过工厂方法getUnsafe获得Unsafe的单例。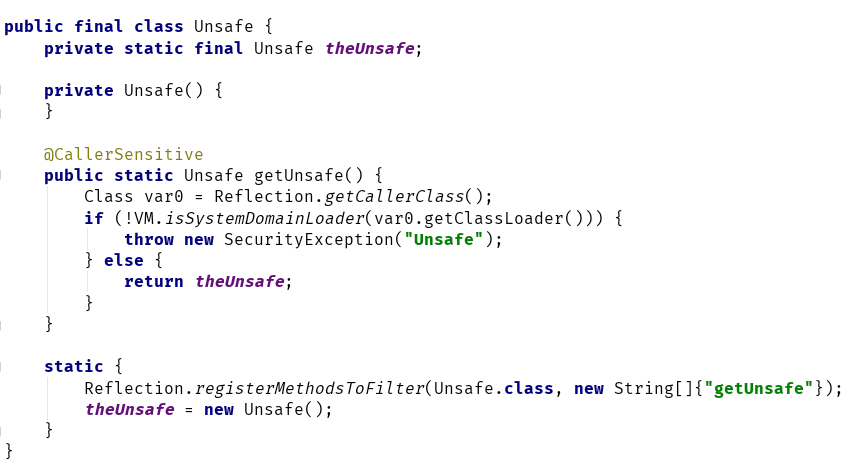
但是getUnsafe方法限制了调用该方法的类的类加载器必须为Bootstrap ClassLoader。
Java中的类加载器可以大致划分为以下三类:
| 类加载器名称 | 作用 |
|---|---|
| Bootstrap类加载器(Bootstrap ClassLoader) | 主要加载的是JVM自身需要的类,这个类加载使用C++语言实现的,是JVM自身的一部分,它负责将 【JDK的安装目录】/lib路径下的核心类库,如rt.jar |
| 扩展类加载器(Extension ClassLoader) | 该加载器负责加载【JDK的安装目录】\jre\lib\ext目录中的类库,开发者可以直接使用该加载器 |
| 系统类加载器(Application ClassLoader) | 负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器,也是默认的类加载器 |
所以在用户代码中直接调用getUnsafe方法,会抛出异常。因为用户自定义的类一般都是由系统类加载器加载的。
但是,是否就真的没有办法获取到Unsafe实例了呢?当然不是,要获取Unsafe对象的方法很多,这里给出一种通过反射的方法:
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
但是,除非对Unsafe的实现非常清楚,否则应尽量避免直接使用Unsafe来进行操作。
三、AtomicXXX
1 功能简介:
原子量和普通变量相比,主要体现在读写的线程安全上。对原子量的是原子的(比如多线程下的共享变量i++就不是原子的),由CAS操作保证原子性。对原子量的读可以读到最新值,由volatile关键字来保证可见性。
原子量多用于数据统计(如接口调用次数)、一些序列生成(多线程环境下)以及一些同步数据结构中。
2 源码分析:
首先,原子量的一些较底层的操作都是来自sun.misc.Unsafe类,所以原子量内部有一个Unsafe的静态引用。
private static final Unsafe unsafe = Unsafe.getUnsafe();
2.1 AtomicInteger
2.1.1 属性
在AtomicInteger源码中,由内部的一个int域来保存值:
private volatile int value; //当前值 private static final long valueOffset; //当前值在类中的偏移
AtomicInteger中的CAS操作体现在方法compareAndSet。它的实现在unsafe.cpp里面,这部分代码在上篇博客:Java CAS 原理分析中已经解释过了,这里不再赘述。
其余的大多数方法都是基于compareAndSet方法来实现的,来看其中一个,incrementAndGet方法:
public final int incrementAndGet() { //调用unsafe中的方法,this:当前对象;valueOffset:偏移;因为是自增的所以需要传入1 return unsafe.getAndAddInt(this, valueOffset, 1) + 1; }
unsafe类中的相应方法实现:
public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { //根据当前对象和传入偏移,在底层获取内存中保存的对应的值 var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); //while语句中调用了一个native方法,判断期望值var5与内存中的值是否相等,如果不相等便一直循环下去,如果相等则更新内存中的值为var5+var4 return var5; }
/** * Sets to the given value. * * @param newValue the new value */ public final void set(int newValue) { value = newValue; } /** * Eventually sets to the given value. * * @param newValue the new value * @since 1.6 */ public final void lazySet(int newValue) { unsafe.putOrderedInt(this, valueOffset, newValue); }
lazySet方法是set方法的不可见版本。什么意思呢?
我们知道通过volatile修饰的变量,可以保证在多处理器环境下的“可见性”。也就是说当一个线程修改一个共享变量时,其它线程能立即读到这个修改的值。volatile的实现最终是加了内存屏障:
-
保证写volatile变量会强制把CPU写缓存区的数据刷新到内存
-
读volatile变量时,使缓存失效,强制从内存中读取最新的值
-
由于内存屏障的存在,volatile变量还能阻止重排序
lazySet内部调用了Unsafe类的putOrderedInt方法,通过该方法对共享变量值的改变,不一定能被其他线程立即看到。也就是说以普通变量的操作方式来写变量。
为什么会有这种奇怪方法?什么情况下需要使用lazySet呢?
考虑下面这样一个场景:
private AtomicInteger ai = new AtomicInteger(); lock.lock(); try { // ai.set(1); } finally { lock.unlock(); }
由于锁的存在:
- lock()方法获取锁时,和volatile变量的读操作一样,会强制使CPU缓存失效,强制从内存读取变量。
- unlock()方法释放锁时,和volatile变量的写操作一样,会强制刷新CPU写缓冲区,把缓存数据写到主内存
所以,上述ai.set(1)可以用ai.lazySet(1)方法替换:
由锁来保证共享变量的可见性,以设置普通变量的方式来修改共享变量,减少不必要的内存屏障,从而提高程序执行的效率。
2.2 AtomicBoolean
属性与AtomicInteger类似的,唯一区别在于构造方法上稍有不同,AtomicBoolean内部是用一个int域来表示布尔状态,1表示true;0表示false:
private volatile int value; /** * Creates a new {@code AtomicBoolean} with the given initial value. * * @param initialValue the initial value */ public AtomicBoolean(boolean initialValue) { value = initialValue ? 1 : 0; }
以原子方式更新对象引用。
可以看到,AtomicReference持有一个对象的引用——value,并通过Unsafe类来操作该引用:
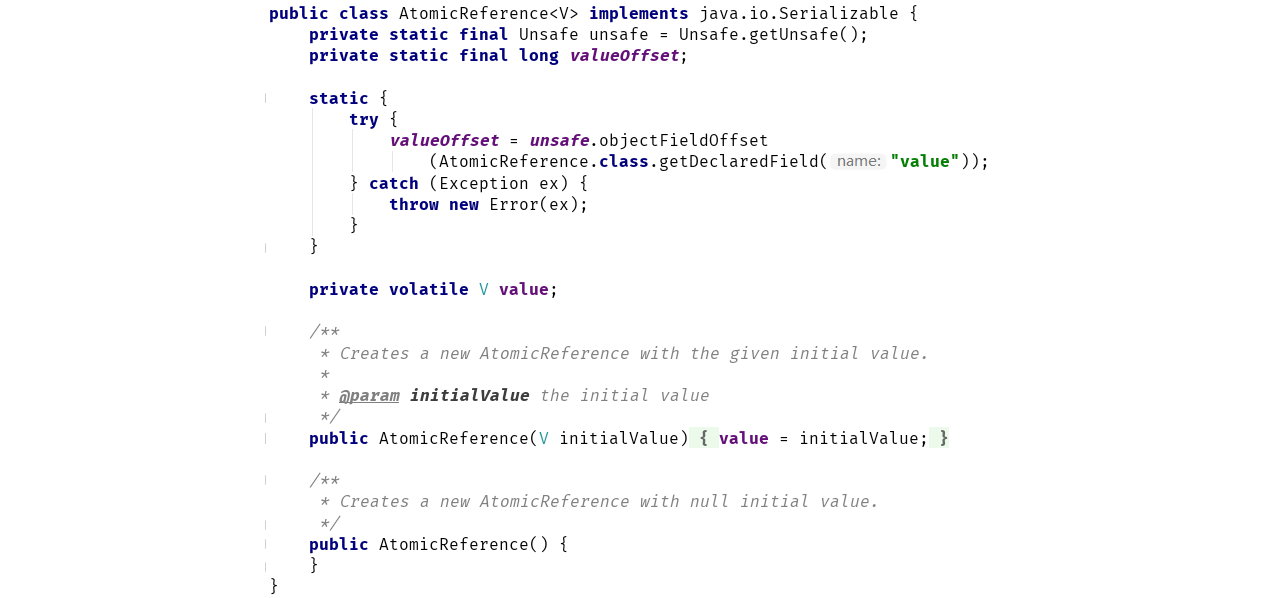
为什么需要AtomicReference?难道多个线程同时对一个引用变量赋值也会出现并发问题?
引用变量的赋值本身没有并发问题,也就是说对于引用变量var ,类似下面的赋值操作本身就是原子操作: Foo var = ... ; AtomicReference的引入是为了可以用一种类似乐观锁的方式操作共享资源,在某些情景下以提升性能。
我们知道,当多个线程同时访问共享资源时,一般需要以加锁的方式控制并发:
volatile Foo sharedValue = value; Lock lock = new ReentrantLock(); lock.lock(); try{ // 操作共享资源sharedValue } finally{ lock.unlock(); }
上述访问方式其实是一种对共享资源加悲观锁的访问方式。
而AtomicReference提供了以无锁方式访问共享资源的能力,看看如何通过AtomicReference保证线程安全,来看个具体的例子:
public class AtomicRefTest { public static void main(String[] args) throws InterruptedException { AtomicReference<Integer> ref = new AtomicReference<>(new Integer(1000)); List<Thread> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { Thread t = new Thread(new Task(ref), "Thread-" + i); list.add(t); t.start(); } for (Thread t : list) { t.join(); } System.out.println(ref.get()); // 打印2000 } } class Task implements Runnable { private AtomicReference<Integer> ref; Task(AtomicReference<Integer> ref) { this.ref = ref; } @Override public void run() { for (; ; ) { //自旋操作 Integer oldV = ref.get(); if (ref.compareAndSet(oldV, oldV + 1)) // CAS操作 break; } } }
上述示例,最终打印“2000”。
该示例并没有使用锁,而是使用自旋+CAS的无锁操作保证共享变量的线程安全。1000个线程,每个线程对金额增加1,最终结果为2000,如果线程不安全,最终结果应该会小于2000。
通过示例,可以总结出AtomicReference的一般使用模式如下:
AtomicReference<Object> ref = new AtomicReference<>(new Object()); Object oldCache = ref.get(); // 对缓存oldCache做一些操作 Object newCache = someFunctionOfOld(oldCache); // 如果期间没有其它线程改变了缓存值,则更新 boolean success = ref.compareAndSet(oldCache , newCache);
上面的代码模板就是AtomicReference的常见使用方式,看下compareAndSet方法:

该方法会将入参的expect变量所指向的对象和AtomicReference中的引用对象进行比较,如果两者指向同一个对象,则将AtomicReference中的引用对象重新置为update,修改成功返回true,失败则返回false。也就是说,AtomicReference其实是比较对象的引用。
AtomicStampedReference
4.1 AtomicStampedReference的引入
CAS操作可能存在ABA的问题,就是说:
假如一个值原来是A,变成了B,又变成了A,那么CAS检查时会发现它的值没有发生变化,但是实际上却变化了。
一般来讲这并不是什么问题,比如数值运算,线程其实根本不关心变量中途如何变化,只要最终的状态和预期值一样即可。
但是,有些操作会依赖于对象的变化过程,此时的解决思路一般就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A - 2B - 3A。
在CAS中会可能出现ABA问题,AtomicStampedReference就是上面所说的加了版本号的AtomicReference。
4.2 AtomicStampedReference原理
先来看下如何构造一个AtomicStampedReference对象,AtomicStampedReference只有一个构造器:
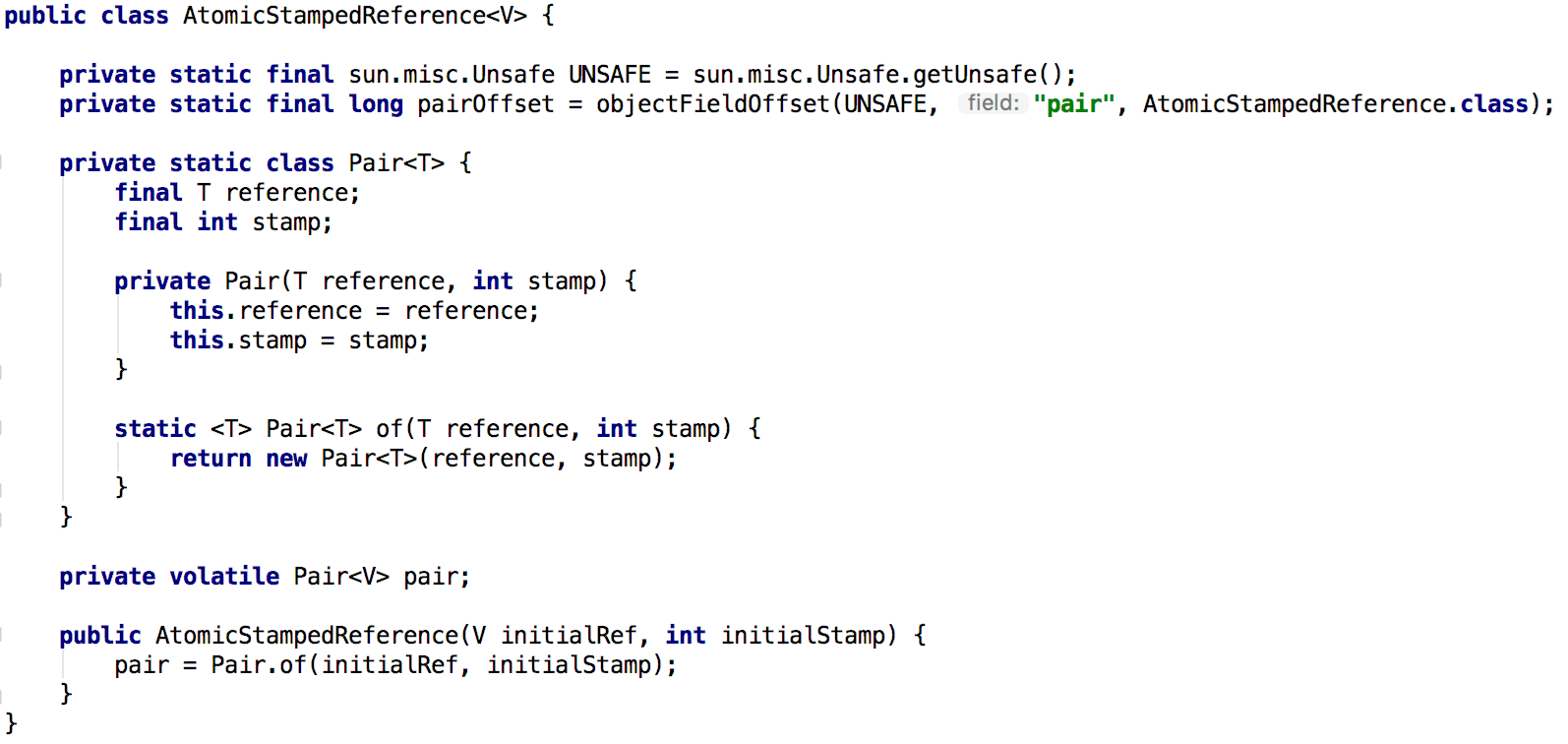
可以看到,除了传入一个初始的引用变量initialRef外,还有一个initialStamp变量,initialStamp其实就是版本号(或者说时间戳),用来唯一标识引用变量。
在构造器内部,实例化了一个Pair对象,Pair对象记录了对象引用和时间戳信息,采用int作为时间戳,实际使用的时候,要保证时间戳唯一(一般做成自增的),如果时间戳如果重复,还会出现ABA的问题。
AtomicStampedReference的所有方法,其实就是Unsafe类针对这个Pair对象的操作。
和AtomicReference相比,AtomicStampedReference中的每个引用变量都带上了pair.stamp这个版本号,这样就可以解决CAS中的ABA问题了。
4.2 AtomicStampedReference使用示例
来看下AtomicStampedReference的使用:
AtomicStampedReference<Foo> asr = new AtomicStampedReference<>(null,0); // 创建AtomicStampedReference对象,持有Foo对象的引用,初始为null,版本为0 int[] stamp=new int[1]; Foo oldRef = asr.get(stamp); // 调用get方法获取引用对象和对应的版本号 int oldStamp=stamp[0]; // stamp[0]保存版本号 asr.compareAndSet(oldRef, null, oldStamp, oldStamp + 1) //尝试以CAS方式更新引用对象,并将版本号+1
上述模板就是AtomicStampedReference的一般使用方式,注意下compareAndSet方法:

我们知道,AtomicStampedReference内部保存了一个pair对象,该方法的逻辑如下:
- 如果AtomicStampedReference内部pair的引用变量、时间戳 与 入参expectedReference、expectedStamp都一样,说明期间没有其它线程修改过AtomicStampedReference,可以进行修改。此时,会创建一个新的Pair对象(casPair方法,因为Pair是Immutable类)。
但这里有段优化逻辑,就是如果 newReference == current.reference && newStamp == current.stamp,说明用户修改的新值和AtomicStampedReference中目前持有的值完全一致,那么其实不需要修改,直接返回true即可。
AtomicMarkableReference
我们在讲ABA问题的时候,引入了AtomicStampedReference。
AtomicStampedReference可以给引用加上版本号,追踪引用的整个变化过程,如:
A -> B -> C -> D - > A,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了3次。
但是,有时候,我们并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference:

可以看到,AtomicMarkableReference的唯一区别就是不再用int标识引用,而是使用boolean变量——表示引用变量是否被更改过。
从语义上讲,AtomicMarkableReference对于那些不关心引用变化过程,只关心引用变量是否变化过的应用会更加友好。
0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号