程序员代码面试指南上(1-3)
目录
第1章 栈和队列
第2章 链表问题
第3章 二叉树问题
附:二叉树的层序遍历
19 Tarjan算法与并查集解决二叉树节点间最近公共祖先的批量查询问题
注:依据在牛客网上是否能通过为标准
第1章 栈和队列
注:在视频中是先讲了一道题目:用固定大小的数组来实现栈和队列
用数组来实现栈:
//用数组来实现栈 public static class ArrayStack{ private Integer[] arr; //数组实际存储的数据容量 private Integer size; public ArrayStack(int initSize){ if (initSize < 0){ //当创建时若初始容量<0抛出异常 throw new IllegalArgumentException("The init size is less than 0"); } arr = new Integer[initSize]; size = 0; } //添加元素 public void push(int num){ if (size == arr.length){ throw new ArrayIndexOutOfBoundsException("The queue is full"); } arr[size++] = num; } //查看栈顶元素 public Integer peek(){ if (size == 0){ return null; } return arr[size-1]; } //弹出栈顶元素 public Integer pop(){ if (size == 0){ throw new ArrayIndexOutOfBoundsException("The queue is empty"); } //size是从1开始的所以要先自减1 return arr[--size]; } }
用数组来实现队列:
这个是面试中常问到的,其元素的插入和删除过程如下图所示:
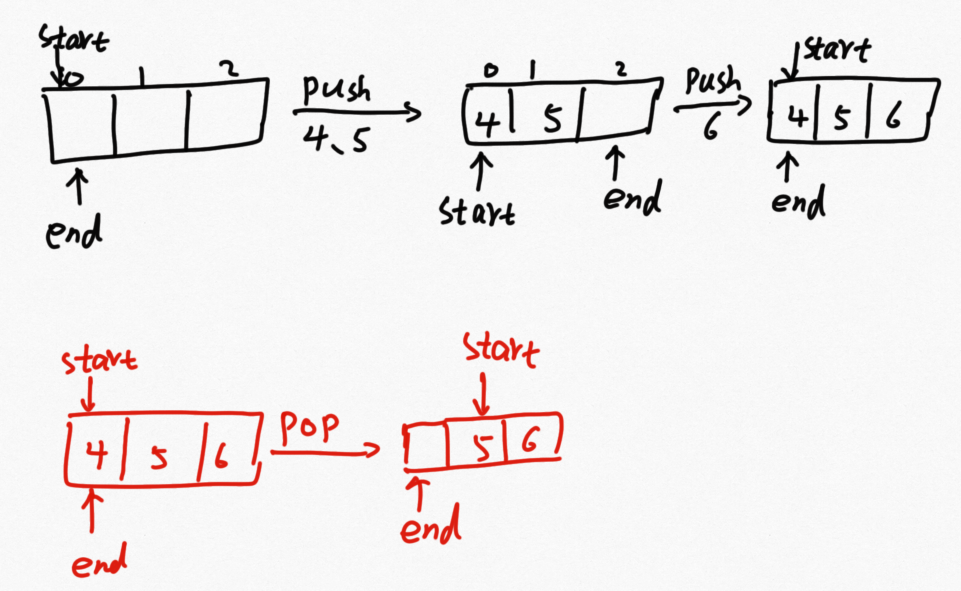
从图中可以看出:
(1)start和end是毫不相关的,end指向的是要插入元素的,start指向的是要弹出元素的位置
(2)end是循环的,start也是循环的,那么限制其是否合理的就是整个数组的容量。为什么是循环?因为在加入的过程中也可以弹出,这样前面的空间可能是有空余的。
//用数组来实习队列 public static class ArrayQueue{ private Integer[] arr; private Integer size; //队首 private Integer first; //队尾 private Integer last; public ArrayQueue(int initSize){ if (initSize < 0){ throw new IllegalArgumentException("The init size is less than 0"); } arr = new Integer[initSize]; size = 0; first = 0; last = 0; } //加入元素 public void push(int num){ if (size == arr.length) { throw new ArrayIndexOutOfBoundsException("The queue is full"); } size++; arr[last] = num; //判断是否到达了尾部然后进行循环 last = last == arr.length-1 ? 0:last+1; } //查看队首元素 public Integer peek(){ if (size == 0){ return null; } return arr[first]; } //弹出队列元素 public Integer poll(){ if (size == 0){ throw new ArrayIndexOutOfBoundsException("The queue is empty"); } size--; int temp = first; //队首也是循环的 first = first == arr.length-1 ? 0:first+1; return arr[temp]; } }
这个算法的核心其实并不难,主要是这种答题格式要注意。
public class Main { public static void main(String[] args) throws Exception{ Stack<Integer> stack = new Stack<>(); Stack<Integer> min = new Stack<>(); //使用BufferedReader速度要快,BufferedReader读取时先把数据存入缓冲区,然后在从缓冲区读取 BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(in.readLine()); for (int i = 0; i < n; i++) { String s = in.readLine(); if (s.startsWith("push")){ int value = Integer.parseInt(s.split(" ")[1]); stack.push(value); if (min.isEmpty() || value < min.peek()){ //当新来的数据小时加入到最小栈中 min.push(value); }else { //当新来的数据大时,为了保持数量的相等最小栈中继续添加元素,只不过添加的最小栈的中最小元素 min.push(min.peek()); } }else if (s.equals("pop")){ stack.pop(); min.pop(); }else if (s.equals("getMin")){ System.out.print(min.peek()+" "); } } } }
在1中是把类融合在一起了,这里把类单独分开写。其注意事项可以参考剑指offer中的记录
public class Main { public static void main(String[] args) throws Exception{ queue que = new queue(); BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(in.readLine()); for (int i = 0; i < n; i++) { String s = in.readLine(); if (s.startsWith("add")){ int value = Integer.parseInt(s.split(" ")[1]); que.add(value); }else if (s.equals("peek")){ System.out.println(que.peek()); }else if (s.equals("poll")){ que.poll(); } } } } //自己定义的队列 class queue{ Stack<Integer> stack1 = new Stack<>(); Stack<Integer> stack2 = new Stack<>(); //压入数据 public void add(int value){ stack1.add(value); } //弹出数据 public void poll(){ if (stack2.isEmpty()){ while (!stack1.isEmpty()){ stack2.push(stack1.pop()); } } stack2.pop(); } //查看数据 public int peek(){ if (stack2.isEmpty()){ while (!stack1.isEmpty()){ stack2.push(stack1.pop()); } } return stack2.peek(); } }
注:与这个相关的还有一个用队列实现栈可以参考LeetCode-225。
这里主要是递归的使用,准备两个递归一个递归不断的获取栈底元素从上向下遍历返回时则从下向上,另一个递归不断调用自身接收并压入栈中。使用下面代码在牛客网上没有通过,这是牛客网其自身问题的
public class Main { public static void main(String[] args) throws Exception { BufferedReader bf = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(bf.readLine()); String[] arr = bf.readLine().split(" "); Stack<Integer> stack = new Stack<Integer>(); for (int i = 0; i < n; i++) { stack.push(Integer.parseInt(arr[i])); } //对栈开始逆序 reverse(stack); //输出结果 while (!stack.isEmpty()){ System.out.print(stack.pop()+" "); } } //需要准备两个方法,一个方法获取栈底元素,一个方法来保存 private static int getLastAndRemove(Stack<Integer> stack){ int result = stack.pop(); if (stack.isEmpty()){ return result; }else{ //获取最后一个元素 int last = getLastAndRemove(stack); //中间过程弹出的元素也要入栈 stack.push(result); //返回最后一个元素 return last; } } //接收元素并压入栈中 private static void reverse(Stack<Integer> stack){ if (stack.isEmpty()){ return; } //获取栈底元素并移除 int i = getLastAndRemove(stack); //递归从底向上遍历 reverse(stack); //遍历到顶部后开始添加 stack.push(i); } }
一开始想的是三个队列,但没有必要,分别用猫、狗队列存储各自的即可,那么如何知道进入的先后顺序?可以记录下其出现的顺序,在存入的时候也把这个顺序存入,弹出的时候进行比较即可。
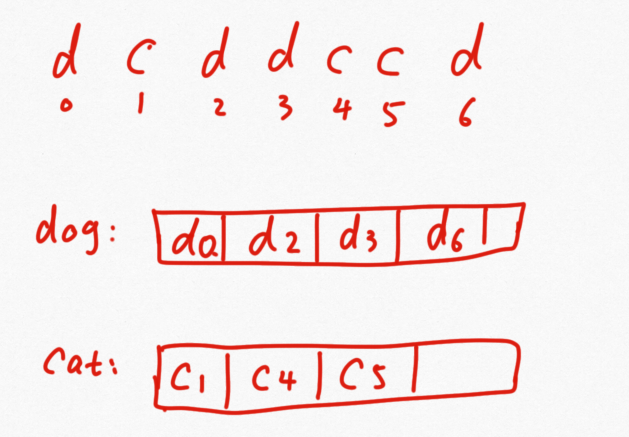
在代码实现时注意类之间的继承关系,不能对给定的代码修改而要自己实现一个新的类。
public class Cat_Dog_Queue { public static class Pet { private String type; public Pet(String type) { this.type = type; } public String getPetType() { return this.type; } } public static class Dog extends Pet { public Dog() { super("dog"); } } public static class Cat extends Pet { public Cat() { super("cat"); } } //这个类中保存了宠物和其先后顺序 //虽然可以直接在Pet Dog Cat类中修改但是这样不符合编程规范 public static class PetEnterQueue{ private Pet pet; private long count; public PetEnterQueue(Pet pet,long count){ this.pet = pet; this.count = count; } public Pet getPet() { return this.pet; } public long getCount() { return this.count; } public String getEnterPetType() { return this.pet.getPetType(); } } public static class DogCatQueue{ //狗队列 private Queue<PetEnterQueue> dogQ; //猫队列 private Queue<PetEnterQueue> catQ; //这里定义一个公共的count来方便计数 private long count; public DogCatQueue(){ //队列的底层用链表来实现 this.dogQ = new LinkedList<>(); this.catQ = new LinkedList<>(); this.count = 0; } //添加宠物 public void add(Pet pet){ if (pet.getPetType().equals("dog")){ dogQ.add(new PetEnterQueue(pet,this.count++)); }else if (pet.getPetType().equals("cat")){ catQ.add(new PetEnterQueue(pet,this.count++)); }else { throw new RuntimeException("err, not dog or cat"); } } //弹出宠物 public Pet pollAll(){ if (!dogQ.isEmpty() && !catQ.isEmpty()){ //当猫狗队列都不为空时,比较顺序弹出 if (dogQ.peek().getCount() < catQ.peek().getCount()){ return dogQ.poll().getPet(); }else { return catQ.poll().getPet(); } }else if (!dogQ.isEmpty()){ //当只有狗队列不为空时弹出狗队列 return dogQ.poll().getPet(); }else if (!catQ.isEmpty()){ return catQ.poll().getPet(); }else { throw new RuntimeException("err, queue is empty!"); } } //弹出狗队列 public Dog pollDog(){ if (isDogEmpty()){ throw new RuntimeException("Dog queue is empty!"); } return (Dog) dogQ.poll().getPet(); } //弹出猫队列 public Cat pollCat(){ if (isCatEmpty()){ throw new RuntimeException("Cat queue is empty!"); } return (Cat) catQ.poll().getPet(); } //判断是否为空 public boolean isEmpty(){ return dogQ.isEmpty() && catQ.isEmpty(); } public boolean isDogEmpty(){ return dogQ.isEmpty(); } public boolean isCatEmpty(){ return catQ.isEmpty(); } } }
两个栈之间的交换操作单理解起来比较麻烦,画出交换过程就可以方便的看出其中步骤了。
public class Main { public static void main(String[] args) throws Exception{ //接收输入的数据 BufferedReader bf = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(bf.readLine()); String[] str = bf.readLine().split(" "); Stack<Integer> stack = new Stack<>(); for (int i = 0; i < n; i++) { int value = Integer.parseInt(str[i]); stack.push(value); } //调用排序方法 sort(stack); } //排序方法,可以画图方便理解 public static void sort(Stack<Integer> stack){ Stack<Integer> help = new Stack<>(); while (!stack.isEmpty()){ int value = stack.pop(); while (!help.isEmpty() && value < help.peek()){ stack.push(help.pop()); } help.push(value); } while (!help.isEmpty()){ System.out.print(help.pop()+" "); } } }
public class Main { public static void main(String[] args) throws Exception{ //接收输入的数据 BufferedReader bf = new BufferedReader(new InputStreamReader(System.in)); String[] arr = bf.readLine().split(" "); int n = Integer.parseInt(arr[1]); String[] str = bf.readLine().split(" "); int[] value = new int[str.length]; int[] res = new int[str.length-n+1]; for (int i = 0; i < str.length; i++) { value[i] = Integer.parseInt(str[i]); } //接收结果并输出 res = getMaxWindows(value,n); for (int i = 0; i < res.length; i++) { System.out.print(res[i]+" "); } } public static int[] getMaxWindows(int[] arr, int w){ //先判断是否合法 if (arr == null || w < 1 || arr.length < w){ return null; } //双向队列用链表来实现,可以队首出也可以队尾出 LinkedList<Integer> qMax = new LinkedList<>(); int index =0; //保留结果的数组 int[] result = new int[arr.length - w + 1]; for (int i = 0; i < arr.length; i++) { while (!qMax.isEmpty() && arr[i] >= arr[qMax.peekLast()]){ //因为arr[i]大于队列中的队尾元素,那么就相当于队尾元素没用了,不断循环下去 qMax.pollLast(); } //当经历了上面循环后,队列中要么为空,要么当前数组小。队列中保存的是索引 qMax.add(i); //判断队列的队首元素是否过期 //依据就是中间是否间隔了是三个数,因为队列中存储的是索引,所以可用下面的判断方法 if (i - w == qMax.peekFirst()){ qMax.pollFirst(); } //判断是否累计好了窗口 //这个其实就是最初要保证有三个数 if (i - w >= -1){ result[index++] = arr[qMax.peekFirst()]; } } return result; } }
这道题目升级后便是下面的第十题
单调栈结构:
这道题目便可以借用上面第8题的结构,单调栈,在这里可以先给出一个引子问题参考LeetCode84:柱状图中最大的矩形
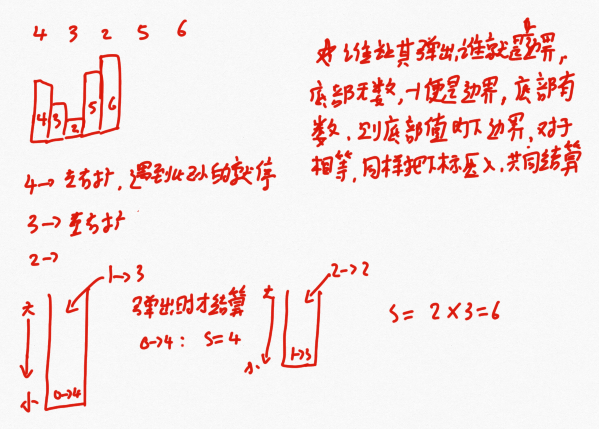
代码实现
public static int maxRecFromBottom(int[] height) { if (height == null || height.length == 0) { return 0; } int maxArea = 0; //准备单调栈 Stack<Integer> stack = new Stack<Integer>(); //for循环遍历数组中的每一个数 for (int i = 0; i < height.length; i++) { //当栈不为空且当前数<=栈顶元素时进入循环 while (!stack.isEmpty() && height[i] <= height[stack.peek()]) { //弹出栈顶 int j = stack.pop(); //定义左边界 int k = stack.isEmpty() ? -1 : stack.peek(); //根据边界和高度计算出面积 int curArea = (i - k - 1) * height[j]; maxArea = Math.max(maxArea, curArea); } //否则直接入栈 stack.push(i); } //遍历完成后,结算栈中剩余的元素 while (!stack.isEmpty()) { int j = stack.pop(); int k = stack.isEmpty() ? -1 : stack.peek(); int curArea = (height.length - k - 1) * height[j]; maxArea = Math.max(maxArea, curArea); } return maxArea; }
与上面题目类似的还有LeetCode11-盛水最多的容器,但LeetCode11相对来说要简单,用不到这么复杂的结构,两者可以对比分析。
这个问题要在引子的基础上生成自己需要的数组,剩下的只需要调用上面的代码即可
public static int maxRecSize(int[][] map) { if (map == null || map.length == 0 || map[0].length == 0) { return 0; } int maxArea = 0; //生成辅助数组 int[] height = new int[map[0].length]; for (int i = 0; i < map.length; i++) { for (int j = 0; j < map[0].length; j++) { //若当前位置为0则直接变成0,不为0则把前面的进行累加,表示的就是前面有几个连续的1 height[j] = map[i][j] == 0 ? 0 : height[j] + 1; } //每一列依次增长,计算最大面积 maxArea = Math.max(maxRecFromBottom(height), maxArea); } return maxArea; }
对于这道题目还有一个升级版本,题目如下:
一个数组中的数字组成环形山,数值为山高:1 2 4 5 3
规则,烽火传递:相邻之间的两座山必能看到烽火,非相邻的山之间有一边的山高都 <= 这两个非相邻山的山高,则这两座山能相互看到烽火。比如,1和4就不能看到,因为顺时针边,2比1大,挡住了,逆时针边,3和5都比1大,挡住了。而3与4就能看到,虽然逆时针边5挡住了,但顺时针边1和2没挡住3。
问哪两座山能相互看到烽火;要求时间复杂为O(1)。此题答案为(1, 2)(1, 3)(2, 4)(4, 5)(5, 3)(2, 3)(4, 3)
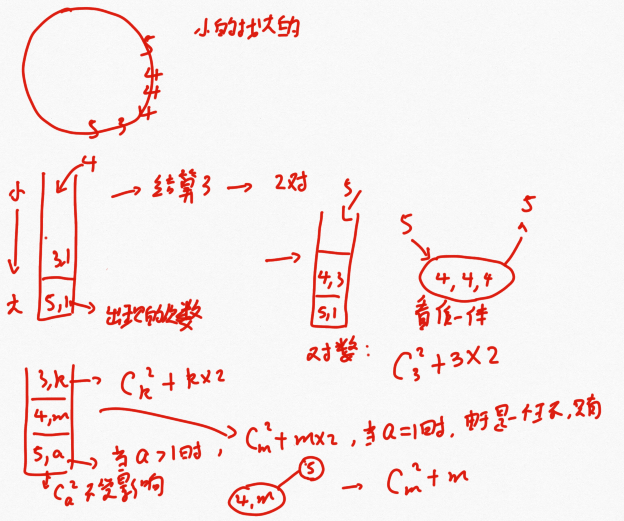
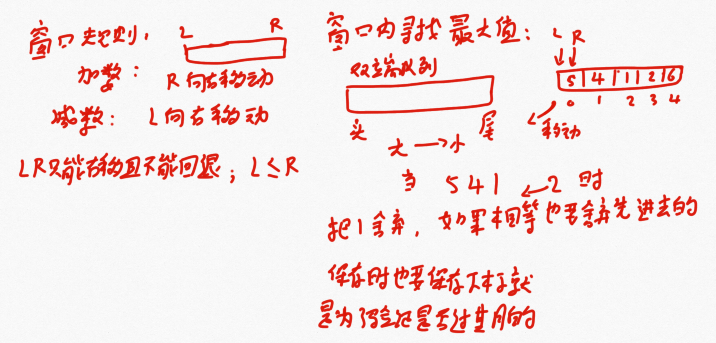
这道题目就是在上面的第7解题思路上进行改造的,考虑:若L到R之间已经达标了,那么窗内的子数组必然也达标了,若没有达标,窗内的子数组则也没有达标
public static int getNum(int[] arr, int num) { if (arr == null || arr.length == 0) { return 0; } //最小队列 LinkedList<Integer> qmin = new LinkedList<Integer>(); //最大队列 LinkedList<Integer> qmax = new LinkedList<Integer>(); int L = 0; int R = 0; int res = 0; while (L < arr.length) { //当L确定时,R向右移动,直至不满足要求 while (R < arr.length) { //最小值更新 while (!qmin.isEmpty() && arr[qmin.peekLast()] >= arr[R]) { qmin.pollLast(); } qmin.addLast(R); //最大值更新 while (!qmax.isEmpty() && arr[qmax.peekLast()] <= arr[R]) { qmax.pollLast(); } qmax.addLast(R); //当不满足时直接跳出 if (arr[qmax.getFirst()] - arr[qmin.getFirst()] > num) { break; } R++; } //最小值是否过期 if (qmin.peekFirst() == L) { qmin.pollFirst(); } //最大值是否过期 if (qmax.peekFirst() == L) { qmax.pollFirst(); } //一次性获得所有以L开头的符合要求的子数组数量 res += R - L; //L右移 L++; } return res; }
第2章 链表问题
这道题目很简单,核心代码部分也遇到过好几次。只是这里要自己写出所有的相关部分,不再是单独写一个小块所以可能有点麻烦。
public class Main { //定义链表节点 private static class Node{ int val; Node next; Node(int val){ this.val = val; } } //创建一个链表 private static Node createLinkedList(String[] strings,int n){ Node head = new Node(Integer.parseInt(strings[0])); Node node = head; for (int i=1;i<n;i++){ Node newNode = new Node(Integer.parseInt(strings[i])); node.next = newNode; node = newNode; } return head; } public static void main(String[] args) throws Exception{ //根据读入的数据创建两个链表 BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(reader.readLine()); String[] strings1 = reader.readLine().split(" "); Node list1 = createLinkedList(strings1,n); int m = Integer.parseInt(reader.readLine()); String[] strings2 = reader.readLine().split(" "); Node list2 = createLinkedList(strings2,m); //调用算法 printCommonNode(list1,list2); } //核心代码部分 private static void printCommonNode(Node list1, Node list2) { while (list1 != null && list2 != null){ if (list1.val == list2.val){ System.out.print(list1.val+" "); list1 = list1.next; list2 = list2.next; }else if (list1.val < list2.val){ list1 = list1.next; }else { list2 = list2.next; } } System.out.println(); } }
这里一开始报超时错误,发现不是代码自身的问题,是没有采用输出流。
public class Main{ //定义链表节点 private static class Node{ int val; Node next; Node(int val){ this.val = val; } } //创建一个链表 private static Node createNode(String[] strings,int n){ Node head = new Node(Integer.parseInt(strings[0])); Node node = head; for (int i=1;i<n;i++){ Node newNode = new Node(Integer.parseInt(strings[i])); node.next = newNode; node = newNode; } return head; } public static void main(String[] args) throws Exception{ //根据读入的数据创建两个链表 BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); String[] str = reader.readLine().split(" "); int n = Integer.parseInt(str[0]); int k = Integer.parseInt(str[1]); String[] strings = reader.readLine().split(" "); Node head = createNode(strings,n); //调用算法 head = removaLastKthNode(head,k); //把结果输出 StringBuilder builder = new StringBuilder(); while(head!=null){ builder.append(head.val).append(" "); head = head.next; } System.out.print(builder.toString()); } //核心代码部分 private static Node removaLastKthNode(Node node, int k) { if (node == null || k < 1){ return node; } Node cur = node; /* 这是自己写的代码但就是没通过,但提交发现报错的用例测试输出与正确的是一样的,不知道哪里出问题了 while (cur != null){ cur = cur.next; //此处用k--其实是快了一步的,因为在链表删除的时候其实要指向的是待删除节点的前一个节点 k--; //当看减为0时此时已到达指定位置 if (k == 0){ break; } } //循环结束后如果k大于0说明k过大了 if (k > 0){ return node; } if (cur == null){ return head.next; } //遍历到指定为位置即待删除节点的前一个节点 while (cur != null){ head = head.next; cur = cur.next; } head.next = head.next.next; return node; */ while (cur != null){ k--; cur = cur.next; } if(k > 0){ return node; }else if(k == 0){ return node.next; }else { cur = node; while (++k != 0){ cur = cur.next; } cur.next = cur.next.next; } return node; } }
上面的代码巧妙的用k来实现了对头结点和中间节点的同一处理,对于更一般的头节点和中间节点的处理应该采用的是虚拟头结点的方法
这道题目和博客中算法面试3-链表-2设立虚拟头结点基本上是一样的,只不过此处寻找的是位置而那里则是值,相对来说此处还要简单一些
//不设立虚拟头节点的方法 private static Node removaKthNode(Node node, int k) { if (node == null || k < 1){ return node; } if (k == 1){ return node.next; } Node curr = node; k = k-2; while (k != 0){ curr = curr.next; if (curr == null){ return node; } k--; } curr.next = curr.next.next; return node; } //设立虚拟头节点的方法 private static Node removaKthNode(Node node, int k) { if (node == null || k < 1){ return node; } Node dummyHead = new Node(0); dummyHead.next = node; Node cur = dummyHead; while(cur.next != null){ k--; if(k == 0){ cur.next = cur.next.next; break; } cur = cur.next; } return dummyHead.next; }
反转单向链表在博客https://www.cnblogs.com/youngao/p/11525932.html 链表反转中已经给出了两种方法,这里关注的重点在于双向链表。对于双向链表其表示如下图所示
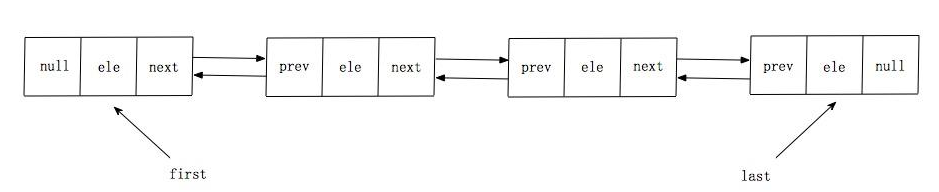
在牛客网刷题时取巧,因为单向双向输出都一样因此全部都按照双向的处理了
public class Main{ public static void main(String[] args) throws Exception { //接收输入 BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); int n = Integer.parseInt(reader.readLine()); String[] strings = reader.readLine().split(" "); //创建链表,这里其实是钻了题目的空子了,因为单向的双向的在输出的时候并没有区别,所以整体安装双向链表来操作了 Node list = createDoubleList(strings,n); //调用反转方法 list = reverseDoubleList(list); //输出链表 printList(list); //第二个链表的处理流程同第一个是一样的 int m = Integer.parseInt(reader.readLine()); String[] str = reader.readLine().split(" "); Node doubleList = createDoubleList(str,m); doubleList = reverseDoubleList(doubleList); printList(doubleList); } //输出节点的方法 private static void printList(Node node){ StringBuilder builder = new StringBuilder(); while (node != null){ builder.append(node.val).append(" "); node = node.next; } System.out.println(builder.toString()); } //反转链表-双向链表 private static Node reverseDoubleList(Node head){ Node pre = null; Node next = null; while (head != null) { next = head.next; head.next = pre; head.last = next; pre = head; head = next; } return pre; } //创建链表 private static Node createDoubleList(String[] strings,int n){ Node head = new Node(Integer.parseInt(strings[0])); Node node = head; for (int i=1;i<n;i++){ Node newNode = new Node(Integer.parseInt(strings[i])); node.next = newNode; newNode.last = node; node = newNode; } return head; } //定义出节点 private static class Node{ private int val; private Node last; private Node next; public Node(int val){ this.val = val; } } }
这题目就是LeetCode-92可以参考LeetCode中的笔记。
先给出最基础的解法
public class Main { //定义节点 private static class Node { public int value; public Node next; public Node(int data) { this.value = data; } } public static Node josephusKill1(Node head, int m) { //只有一个元素或者环为空或者m不合法时直接返回 if (head == null || head.next == head || m < 1) { return head; } Node last = head; //要删除节点时需要走到要删除节点的前一个位置 while (last.next != head) { last = last.next; } //因为要从1开始报数 int count = 1; while (head != last) { if (count++ == m) { last.next = head.next; //开启新一轮 count = 1; } else { last = last.next; } head = last.next; } return head; } }
上面这种解法每删除一个节点需要遍历m次,一共需要删除的节点数为n-1,所以普通解法的时间复杂度为O(n*m),那么是否可以考虑优化代码使其时间复杂度为O(n)。这里先暂且搁置,在第二轮的时候可以再看看。在算法进阶第四期第8节有讲,但觉得偏向数学方面了因此没有记录,后面有时间可以再看看。
方法一:可以考虑使用栈结构,遍历链表把数值存入栈中然后弹出。因为栈是先进后出的,相当于对链表进行了逆序弹出,如果是回文结构那么二者是相同的。
public static boolean isPalindrome1(Node head) { Stack<Node> stack = new Stack<Node>(); Node cur = head; while (cur != null) { stack.push(cur); cur = cur.next; } while (head != null) { if (head.value != stack.pop().value) { return false; } head = head.next; } return true; }
上面的这种操作需要额外的空间复杂度O(N),那么是否可以对其进行优化那——方法二
注:上面使用栈的方法是无法通过测试的,因为所给的数据量太大已经超出了栈的最大深度,下面给出测试栈最大深度的代码:
private int count = 0; public void testStack(){ count++; testStack(); } public void test(){ try { testStack(); } catch (Throwable e) { System.out.println(e); System.out.println("stack height:"+count); } } public static void main(String[] args) { new Main5().test(); }
上面的代码测试出的栈只不过是一个直观的感受,在每次测试时所得到的结果可能不同,比较严谨的应该是在JVM中查看设置。这个问题可以很有研究的价值,可以在面试题目中加上这个问题。
方法二:利用快慢指针,快指针每次走两步,那么当快指针走到null处慢指针刚好在中间位置,这样只需要把右半部分压入即可,压入完成后检查栈底值出现的顺序是否和链表的左半部分的值相对应。这样所需要的额外空间复杂度变为O(N/2)
public static boolean isPalindrome2(Node head) { if (head == null || head.next == null) { return true; } //为了保证慢指针刚好到一半处需要控制好初始位置 Node slow = head.next; Node fast = head; while (fast.next != null && fast.next.next != null) { slow = slow.next; fast = fast.next.next; } //把后半部分压入栈中 Stack<Node> stack = new Stack<Node>(); while (slow != null) { stack.push(slow); slow = slow.next; } //从头结点处开始遍历,与栈中数据比较 while (!stack.isEmpty()) { if (head.value != stack.pop().value) { return false; } head = head.next; } return true; }
方法三:可以在方法二的基础上继续优化,在找到中间位置的后不存数据,把后半部分的链表结构修改了,然后再遍历比较具体过程如下:
1.首先改变链表右半区的结构,使整个右半区反转,最后指向中间节点。
例如:链表1->2>3->2>1,通过这一步将其调整之后的结构下图所示(奇偶情况不同)
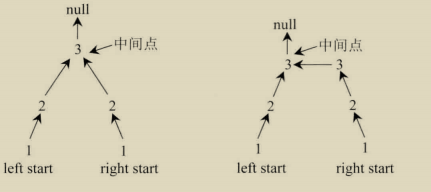
我们将左半区的第一个节点(也就是原链表的头节点)记为 leftstart,右半区反转之后最右边的节点(也就是原链表的最后一个节点)记为 right Start
2. leftstart和 rightstart同时向中间点移动,移动每一步都比较 leftstart和 rightstart节点的值,看是否一样。如果都一样,说明链表为回文结构,否则不是回文结构。
3.不管最后返回的是tue还是 false,在返回前都应该把链表恢复成原来的样子
4.链表恢复成原来的结构之后,返回检査结果。粗看起来,虽然方法三的整个过程也没有多少难度,但要想用有限几个变量完成以上所有的操作,在实现上还是比较考查代码实现能力的。方法三的全部过程请参看如下代码中的 palindrome3方法,该方法只申请了三个Node类型的变量。
// need O(1) extra space public static boolean isPalindrome3(Node head) { if (head == null || head.next == null) { return true; } Node n1 = head; Node n2 = head; while (n2.next != null && n2.next.next != null) { // find mid node n1 = n1.next; // n1 -> mid n2 = n2.next.next; // n2 -> end } n2 = n1.next; // n2 -> right part first node n1.next = null; // mid.next -> null Node n3 = null; while (n2 != null) { // right part convert n3 = n2.next; // n3 -> save next node n2.next = n1; // next of right node convert n1 = n2; // n1 move n2 = n3; // n2 move } n3 = n1; // n3 -> save last node n2 = head;// n2 -> left first node boolean res = true; while (n1 != null && n2 != null) { // check palindrome if (n1.value != n2.value) { res = false; break; } n1 = n1.next; // left to mid n2 = n2.next; // right to mid } n1 = n3.next; n3.next = null; while (n1 != null) { // recover list n2 = n1.next; n1.next = n3; n3 = n1; n1 = n2; } return res; }
注:在笔试解决问题的时候应该采用的是最简单粗暴的方法,只要能解决问题时间复杂度可以先放一放,在面试的时候则是需要给出一个比较优秀的解决方法,来展示自己,这两者解决问题的思路是不同的。
这种划分方式就是快排中partion的思路,一个简单的思路就是把链表的数值保存到数组中,然后在数组中执行partion操作,然后再把这些数存成链表的形式
public static Node listPartition1(Node head, int pivot) { if (head == null) { return head; } Node cur = head; int i = 0; //获取链表的长度 while (cur != null) { i++; cur = cur.next; } Node[] nodeArr = new Node[i]; i = 0; cur = head; //把链表存成数组的形式 for (i = 0; i != nodeArr.length; i++) { nodeArr[i] = cur; cur = cur.next; } //调用数组的partition操作 arrPartition(nodeArr, pivot); //把数组调整为链表的形式 for (i = 1; i != nodeArr.length; i++) { nodeArr[i - 1].next = nodeArr[i]; } nodeArr[i - 1].next = null; return nodeArr[0]; } private static void arrPartition(Node[] nodeArr, int pivot) { int small = -1; int big = nodeArr.length; int index = 0; while (index != big) { if (nodeArr[index].value < pivot) { swap(nodeArr, ++small, index++); } else if (nodeArr[index].value == pivot) { index++; } else { swap(nodeArr, --big, index); } } }
另一种思路如下图所示:

之所以遍历两遍就是为了避免每个分块的头节点重复,在第二次遍历完成后,不需要第三次遍历直接进行连接即可。
本题的代码需要修改一下,还没添加上
本题对应与剑指offer4.3.1:复杂链表的复制,其思路直接在剑指offer的博客笔记中做了补充。
这道题目与LeetCode-02两数相加类似,这里还要复杂一点
public static Node add(Node head1, Node head2){ head1 = reverse(head1); //先进行反转 head2 = reverse(head2); int ca = 0; //进位信息 int n1 = 0;//链表1的数值 int n2 = 0;//链表2的数值 int n = 0;//和 Node c1 = head1; Node c2 = head2; Node node = null; Node pre = null; while (c1 != null || c2 != null){ n1 = c1 != null ? c1.val:0; n2 = c2 != null ? c2.val:0; n = n1+n2+ca; pre = node; node = new Node(n%10); //创建计算结果的链表 node.next = pre; ca = n/10; //提取进位信息 c1 = c1 != null ? c1.next :null; c2 = c2 != null ? c2.next :null; } if (ca == 1){ //当最高位有进位时延长链表长度 pre = node; node = new Node(1); node.next = pre; } //复原 reverse(head1); reverse(head2); return node; }
这道题目基本上就是LeetCode160 相交链表 141环形链表 142 环形链表|| 这三道题目的综合,每一个单独来看都是比较简单的,这里揉在一起需要对各种情况进行判断。
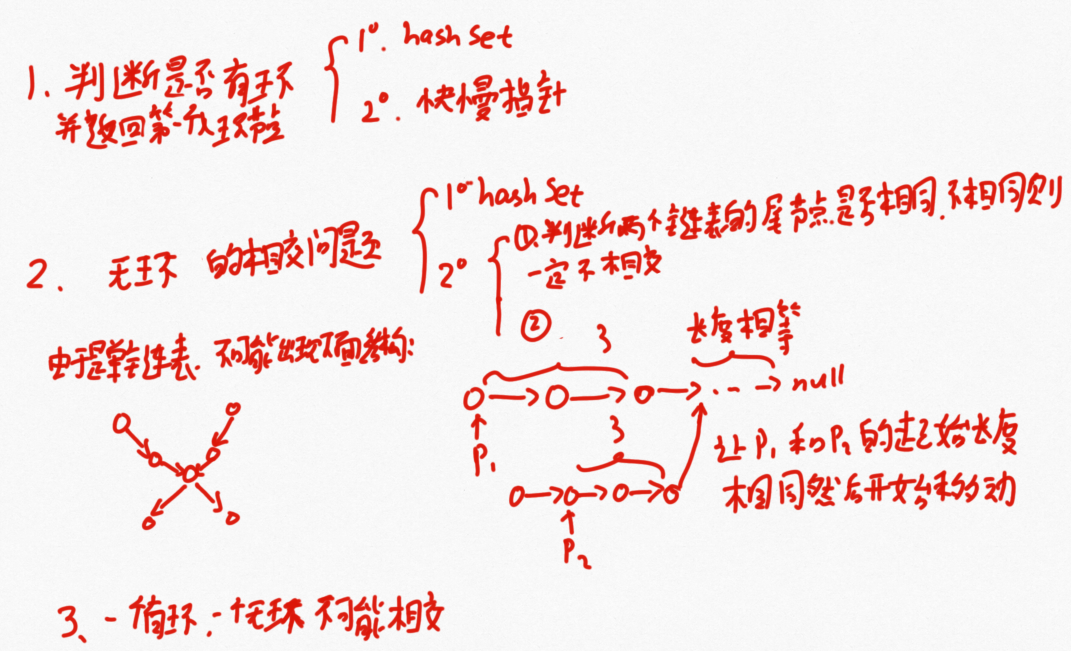

public static Node getIntersectNode(Node head1, Node head2) { if (head1 == null || head2 == null) { return null; } Node loop1 = getLoopNode(head1); Node loop2 = getLoopNode(head2); //两个无环链表相交 if (loop1 == null && loop2 == null) { return noLoop(head1, head2); } //两个有环链表相交 if (loop1 != null && loop2 != null) { return bothLoop(head1, loop1, head2, loop2); } //一个有环一个无环必然不相交 return null; } //判断是否有环并返回入环的第一个节点,采用快慢指针的方式 public static Node getLoopNode(Node head) { if (head == null || head.next == null || head.next.next == null) { return null; } Node slow = head.next; Node fast = head.next.next; //第一次遍历判断是否有环 while (slow != fast) { if (fast.next == null || fast.next.next == null) { return null; } fast = fast.next.next; slow = slow.next; } //第二次遍历,找到入环节点 fast = head; while (slow != fast) { slow = slow.next; fast = fast.next; } return slow; } public static Node noLoop(Node head1, Node head2) { if (head1 == null || head2 == null) { return null; } Node cur1 = head1; Node cur2 = head2; int n = 0; //先遍历,并记录长度 while (cur1.next != null) { n++; cur1 = cur1.next; } while (cur2.next != null) { n--; cur2 = cur2.next; } //如果两个链表的尾节点不相同必然不相交 if (cur1 != cur2) { return null; } //根据长度,然两个指针初始位置距离终点位置相同 cur1 = n > 0 ? head1 : head2; cur2 = cur1 == head1 ? head2 : head1; n = Math.abs(n); while (n != 0) { n--; cur1 = cur1.next; } //从相同长度位置处开始遍历 while (cur1 != cur2) { cur1 = cur1.next; cur2 = cur2.next; } return cur1; } public static Node bothLoop(Node head1, Node loop1, Node head2, Node loop2) { Node cur1 = null; Node cur2 = null; //当两个入口节点相同时便可退化成两个单链表相交的问题和上面的noLoop方法是一样的,这里有重复代码 if (loop1 == loop2) { cur1 = head1; cur2 = head2; int n = 0; while (cur1 != loop1) { n++; cur1 = cur1.next; } while (cur2 != loop2) { n--; cur2 = cur2.next; } cur1 = n > 0 ? head1 : head2; cur2 = cur1 == head1 ? head2 : head1; n = Math.abs(n); while (n != 0) { n--; cur1 = cur1.next; } while (cur1 != cur2) { cur1 = cur1.next; cur2 = cur2.next; } return cur1; } else { //当不相同时开始移动一个节点,如果该节点走过一圈没有遇到loop2则证明不相交 cur1 = loop1.next; while (cur1 != loop1) { if (cur1 == loop2) { return loop1; } cur1 = cur1.next; } return null; } }
public static Node reverseKNode(Node head,int K){ if (K < 2){ return head; } Node cur = head; Node start = null; Node pre = null; Node next = null; int count = 1; while (cur != null){ next = cur.next; if (count == K){ start = pre == null ? head :pre.next; head = pre == null ? cur : head; //只改变一次 //反转从start到cur节点的值,pre是上一个节点,next是下一个节点 resign(pre,start,cur,next); pre = start; count = 0; } //来到k个节点一组的尾部 count++; cur = next; } return head; //返回整个链表的头节点 } //反转 private static void resign(Node left, Node start, Node end, Node right) { Node pre = start; Node cur = start.next; Node next = null; while (cur != right){ next = cur.next; cur.next = pre; pre = cur; cur = next; } if (left != null){ left.next = end; } start.next = right; }
public static void removeRep(Node head){ if (head == null){ return ; } HashSet<Integer> set = new HashSet<Integer>(); Node pre = head; Node cur = pre.next; set.add(head.val); while (cur != null){ if (set.contains(cur.val)){ pre.next = cur.next; }else{ set.add(cur.val); pre = cur; } cur = cur.next; } }
public static void removeValue(Node head, int num){ while (head != null){ //找到第一个不为num的节点 if (head.val != num){ break; } head = head.next; } Node pre = head; Node cur = head; while (cur != null){ if (cur.val == num){ pre.next = cur.next; }else { pre = cur; } cur = cur.next; } }
本题与剑指offer4.3.2二叉搜索树与双向链表题目一致
public static Node selectionSort(Node head){ Node tail = null; Node cur = head; Node smallPre = null; Node small = null; while (cur != null){ small = cur; smallPre = getSmallestPreNode(cur); //最小节点的前一个节点 if (smallPre != null){ //隔离出最小的节点 small = smallPre.next; smallPre.next = small.next; } cur = cur == small ? cur.next : cur; //以最小的节点为头节点进行延伸链表,if只执行一次,保证了头节点的正确 if (tail == null){ head = small; }else { tail.next = small; } tail = small; } return head; } //找到最小节点的前一个节点 private static Node getSmallestPreNode(Node head) { Node smallPre = null; Node small = head; Node pre = head; Node cur = head.next; while (cur != null){ if (cur.val < small.val){ smallPre = pre; small = cur; } pre = cur ; cur = cur.next; } return smallPre; }
LeetCode147 对链表的插入排序
public ListNode insertionSortList(ListNode head) { if (head == null || head.next == null){ return head; } ListNode pre = null; ListNode dummyHead = new ListNode(0); dummyHead.next = head; while (head != null && head.next != null){ //head指向已排序数组的最后一个位置,若满足递增则已排序的长度增加 if (head.val <= head.next.val){ head = head.next; continue; } //如果不满足递增条件,则需要进行调整 pre = dummyHead; //pre每次从表头循环 //从表头遍历,直至遍历到待插入的位置 while (pre.next.val < head.next.val){ pre = pre.next; } //调整链表节点间的顺序 ListNode cur = head.next; head.next = cur.next; cur.next= pre.next; pre.next = cur; } return dummyHead.next; }
LeetCode148 排序链表 根据题目要求这道题目本质上要使用的就是归并排
归并排序法:在动手之前一直觉得空间复杂度为常量不太可能,因为原来使用归并时,都是 O(N)的,需要复制出相等的空间来进行赋值归并。对于链表,实际上是可以实现常数空间占用的(链表的归并排序不需要额外的空间)。利用归并的思想,递归地将当前链表分为两段,然后merge,分两段的方法是使用 fast-slow 法,用两个指针,一个每次走两步,一个走一步,知道快的走到了末尾,然后慢的所在位置就是中间位置,这样就分成了两段。merge时,把两段头部节点值比较,用一个 p 指向较小的,且记录第一个节点,然后 两段的头一步一步向后走,p也一直向后走,总是指向较小节点,直至其中一个头为NULL,处理剩下的元素。最后返回记录的头即可。
主要考察3个知识点:
知识点1:归并排序的整体思想
知识点2:找到一个链表的中间节点的方法
知识点3:合并两个已排好序的链表为一个新的有序链表
public ListNode sortList(ListNode head) { return head == null ? null : mergeSort(head); } private ListNode mergeSort(ListNode head) { if (head.next == null){ return head; } ListNode fast = head,slow = head; ListNode pre = null; //找到中间节点位置 while (fast != null && fast.next != null){ pre = slow; slow = slow.next; fast = fast.next.next; } //把链表断开 pre.next = null; //不断进行递归拆分 ListNode left = mergeSort(head); ListNode right = mergeSort(slow); return merge(left,right);//把两部分合并起来 } private ListNode merge(ListNode left, ListNode right) { ListNode dummyHead = new ListNode(0); ListNode cur = dummyHead; while (left != null && right != null){ if (left.val <= right.val){ cur.next = left; cur = cur.next; left = left.next; }else { cur.next = right; cur = cur.next; right = right.next; } } cur.next = left == null ? right : left; return dummyHead.next; }
为什么空间复杂度为常量?
在合并的时候是只申请了一个局部的节点,然后比较,把小的从原链表上拆下,组装到新的链表上,因此空间复杂度为O(1)。
与LeetCode-237-删除链表中的节点是一样的,采用赋值修改。但在这里主要考虑的是这种方法的可能带来的问题。例如:1->2->3->null,只知道要删除节点2,而不知道头节点。那么只需要把节点2的值变成节点3的值,然后在链表中删除节点3即可。
问题一:这样的删除方式无法删除最后一个节点。还是以原示例来说明,如果知道要删除节点3,而不知道头节点。但它是最后的节点,根本没有下一个节点来代替节点3被删除,那么只有让节点2的next指向mul这一种办法,而我们又根本找不到节点2,所以根本没法正确删除节点3。读者可能会问,我们能不能把节点3在内存上的区域变成null呢?这样不就相当于让节点2的next指针指向了nul,起到节点3被删除的效果了吗?不可以。null在系统中是一个特定的区域,如果想让节点2的next指针指向mull,必须找到节点2。
问题二:这种删除方式在本质上根本就不是删除除了node节点,而是把node节点的值改变,然后删除node的下ー个节点,在实际的工程中可能会带来很大问题。比如,工程上的一个节点可能代表很复杂的结构,节点值的复制会相当复杂,或者可能改变节点值这个操作都是被禁止的。再如,工程上的一个节点代表提供服务的一个服务器,外界对每个节点都有很多依赖,比如,示例中删除节点2时,其实影响了节点3对外提供的服务。
public static void removeNodeWired(Node node) { if (node == null) { return; } Node next = node.next; if (next == null) { throw new RuntimeException("can not remove last node."); } node.value = next.value; node.next = next.next; }
public static Node insertNum(Node head,int num){ Node node = new Node(num); if (head == null){ //让新节点自己组成环形 node.next = node; return node; } Node pre = head; Node cur = head.next; while (cur != head){ //找到待插入位置 if (pre.val <= num && cur.val >= num){ break; } pre = cur; cur = cur.next; } //插入节点 pre.next = node; node.next = cur; //插入的新节点也可能为头 return head.val < num ? head : node; }
与LeetCode-21-合并两个有序链表是一样的,可以参考博客算法知识点3-链表-2 设立链表的虚拟的头结点。假设两个链表的长度分别为M和N,那么时间复杂度为O(M+N),额外空间复杂度为O(1)。
和LeetCode328 奇偶链表很类似,但不一样的,可以对比来学习
public static void relocate(Node head){ if (head == null || head.next == null){ return; } Node mid = head; Node right = head.next; while (right.next != null && right.next.next != null){ mid = mid.next; //快慢指针跑到链表中间位置 right = right.next.next; } right = mid.next; mid.next = null; //合并 mergerLR(head,right); } private static void mergerLR(Node left, Node right) { Node next = null; while (left.next != null){ next = right.next; right.next = left.next; left.next = right; left = right.next; right = next; } left.next = right; }
21 扁平化多级链表
这道题目不在书上是LeetCode430上的题目,但很有创意,参考LeetCode上写的笔记。
第3章 二叉树问题
对于这个知识点是必须要重点掌握的,对于递归版在博客https://www.cnblogs.com/youngao/p/11179427.html中4小节已经做了解释,这里主要研究非递归版本如何实现。
对于先序遍历,准备一个栈,放入节点,若不为空时弹出,并先放入该节点的右孩子再放入左孩子,依次重复下去
public static void preOrderUnRecur(Node head) { System.out.print("pre-order: "); if (head != null) { Stack<Node> stack = new Stack<Node>(); stack.add(head); while (!stack.isEmpty()) { head = stack.pop(); System.out.print(head.value + " "); if (head.right != null) { stack.push(head.right); } if (head.left != null) { stack.push(head.left); } } } System.out.println(); }
中序遍历:先把左边界全部压入栈中,然后弹出一个节点再压入其右边界,整体上遍历顺序就是左中右
public static void inOrderUnRecur(Node head) { System.out.print("in-order: "); if (head != null) { Stack<Node> stack = new Stack<Node>(); while (!stack.isEmpty() || head != null) { if (head != null) { stack.push(head); head = head.left; } else { head = stack.pop(); System.out.print(head.value + " "); head = head.right; } } } System.out.println(); }
后序遍历:先序遍历的顺序是中左右,那么压入顺序时先压入左孩子再压入右孩子便实现了中右左的遍历顺序,那么把打印处换位存到另一个help栈中,在help栈中弹出的顺序便成了左右中即后序遍历的顺序了
public static void posOrderUnRecur1(Node head) { System.out.print("pos-order: "); if (head != null) { Stack<Node> s1 = new Stack<Node>(); Stack<Node> s2 = new Stack<Node>(); s1.push(head); while (!s1.isEmpty()) { head = s1.pop(); //把打印替换成了存储操作 s2.push(head); if (head.left != null) { s1.push(head.left); } if (head.right != null) { s1.push(head.right); } } while (!s2.isEmpty()) { System.out.print(s2.pop().value + " "); } } System.out.println(); }
符:对于二叉树的层序遍历套路是类似的,但是在LeetCode102-二叉树的层次遍历中,对于结果的输出方式使得套路要修改了,对每层节点的遍历复杂了,要记得看下。
第一种打印方法:
public static void printEdge1(TreeNode head){ if(head == null){ return; } int height = getHeight(head,0); //获得二叉树的最大长度 TreeNode[][] edgeMap = new TreeNode[height][2];//定义一个二维数组用来保存左右边界节点 setEdgeMap(head,0,edgeMap); //把左右边界节点保存到二叉树中 //打印左边界 for (int i = 0; i != edgeMap.length; i++) { System.out.print(edgeMap[i][0].val+" "); } //打印既不是左边又不是右边界的叶子节点 printLeafNotInMap(head,0,edgeMap); //打印右边界但不是左边界的节点 for (int i = edgeMap.length-1; i != -1 ; i--) { if (edgeMap[i][0] != edgeMap[i][1]){ System.out.print(edgeMap[i][1].val+" "); } } System.out.println(); } private static int getHeight(TreeNode head, int height) { if (head == null){ return height; } return Math.max(getHeight(head.left,height+1),getHeight(head.right,height+1)); } private static void setEdgeMap(TreeNode head, int height, TreeNode[][] edgeMap) { if (head == null){ return; } //当为空时是头节点,头节点也是边界节点 edgeMap[height][0] = edgeMap[height][0] == null ? head : edgeMap[height][0]; edgeMap[height][1] = head; //对于头节点而言右边界也是头节点 setEdgeMap(head.left,height+1,edgeMap);//递归遍历二叉树 setEdgeMap(head.right,height+1,edgeMap); } private static void printLeafNotInMap(TreeNode head, int height, TreeNode[][] edgeMap) { if (head == null){ return; } if (head.left == null && head.right == null && head != edgeMap[height][0] && head != edgeMap[height][1]){ System.out.print(head.val +" "); } printLeafNotInMap(head.left,height+1,edgeMap); printLeafNotInMap(head.right,height+1,edgeMap); }
第二种打印方法:
public static void printEdge2(TreeNode head){ if (head == null){ return; } System.out.print(head.val+" ");//打印遍历左右边界路径上的点 if (head.left != null && head.right != null){ printLeftEdge(head.left,true);//打印左边界的延伸路径 printRightEdge(head.right,true);//打印右边界的延伸路径 }else{ printEdge2(head.left != null ? head.left : head.right); } System.out.println(); } private static void printLeftEdge(TreeNode node, boolean print) { if (node == null){ return; } //打印叶子节点和延伸路径上的点,因为print没有赋值操作因此这段代码中当为true便是打印遍历下的所有点 if (print || (node.left == null && node.right == null)){ System.out.print(node.val+" "); } printLeftEdge(node.left,print); //对于左子树的右节点 printLeftEdge(node.right,print && node.left == null ? true:false); } private static void printRightEdge(TreeNode node, boolean print) { if (node == null){ return; } printRightEdge(node.left,print && node.right == null ? true : false); printRightEdge(node.right,print); if (print || (node.left == null && node.right == null)){ System.out.print(node.val+" "); } }
在辅助代码中,这个代码主要是为了测试时方便直观看到结果。
序列化:一个结构可以用什么文件存储下来,存储的过程就是序列化。反序列化:将内存中内容进行还原

以先序遍历的方式序列化过程如上图所示。
为什么要有_表示结束:因为是以字符串的形式保存的,没有值的结束符不能够区分原来数值的大小
为什么要空位也要表示:如果不占据空位当先序后序遍历可能无法区分的,如下图所示,虽然树的结构不同但是其遍历的结果是相同的。
采用什么样的方式序列化,反序列化时也采用这样的方式即可,代码实现如下:
//序列化过程 public static String serialByPre(Node head) { if (head == null) { return "#!"; } //这里用!来表示值的结束 String res = head.value + "!"; res += serialByPre(head.left); res += serialByPre(head.right); return res; } //反序列化过程 public static Node reconByPreString(String preStr) { //先以!进行分割字符串 String[] values = preStr.split("!"); //分割后存入队列中 Queue<String> queue = new LinkedList<String>(); for (int i = 0; i != values.length; i++) { queue.offer(values[i]); } return reconPreOrder(queue); } public static Node reconPreOrder(Queue<String> queue) { String value = queue.poll(); if (value.equals("#")) { return null; } Node head = new Node(Integer.valueOf(value)); head.left = reconPreOrder(queue); head.right = reconPreOrder(queue); return head; }
后序、中序遍历也是类似的,序列化还可以按层序列化,这里直接给出代码
//序列化过程 public static String serialByLevel(Node head) { if (head == null) { return "#!"; } String res = head.value + "!"; Queue<Node> queue = new LinkedList<Node>(); queue.offer(head); while (!queue.isEmpty()) { head = queue.poll(); if (head.left != null) { res += head.left.value + "!"; queue.offer(head.left); } else { res += "#!"; } if (head.right != null) { res += head.right.value + "!"; queue.offer(head.right); } else { res += "#!"; } } return res; } //反序列化过程 public static Node reconByLevelString(String levelStr) { String[] values = levelStr.split("!"); int index = 0; Node head = generateNodeByString(values[index++]); Queue<Node> queue = new LinkedList<Node>(); if (head != null) { queue.offer(head); } Node node = null; while (!queue.isEmpty()) { node = queue.poll(); node.left = generateNodeByString(values[index++]); node.right = generateNodeByString(values[index++]); if (node.left != null) { queue.offer(node.left); } if (node.right != null) { queue.offer(node.right); } } return head; } //根据字符串产生值 public static Node generateNodeByString(String val) { if (val.equals("#")) { return null; } return new Node(Integer.valueOf(val)); }
这个方法就是morris算法

在此理解一下中序先序后序的区别,其实遍历的数字的次数是一样的,但是打印的时机不同,因此有不同的表现形式。
//中序遍历 public static void morrisIn(Node head) { if (head == null) { return; } Node cur = head; //当前节点 Node mostRight = null; while (cur != null) { mostRight = cur.left; if (mostRight != null) { //不断的找当前节点的左子树的最右节点,因为在遍历的时候会修改当前节点的指向,因此while中需要有两个判断 while (mostRight.right != null && mostRight.right != cur) { mostRight = mostRight.right; } if (mostRight.right == null) { mostRight.right = cur; cur = cur.left; continue; } else { mostRight.right = null; } } //打印行为 //System.out.print(cur.value + " "); //当没有左孩子时当前节点向右移动 cur = cur.right; } System.out.println(); } //前序遍历 public static void morrisPre(Node head) { if (head == null) { return; } Node cur = head; Node mostRight = null; while (cur != null) { mostRight = cur.left; if (mostRight != null) { while (mostRight.right != null && mostRight.right != cur) { mostRight = mostRight.right; } if (mostRight.right == null) { mostRight.right = cur; //当节点有右子树时,第一次来到节点的时刻 System.out.print(cur.value + " "); cur = cur.left; continue; } else { mostRight.right = null; } } else { //当节点没有左子树时可以认为第一次来到节点和第二次来到是同一时刻 System.out.print(cur.value + " "); } cur = cur.right; } System.out.println(); }
对于后序遍历,其思路如下:

代码实现:
//后序遍历,在递归的时候是把后序放在第三次遍历的时机进行打印,但morris遍历只有两次 public static void morrisPos(Node head) { if (head == null) { return; } Node cur1 = head; Node cur2 = null; while (cur1 != null) { cur2 = cur1.left; if (cur2 != null) { while (cur2.right != null && cur2.right != cur1) { cur2 = cur2.right; } if (cur2.right == null) { cur2.right = cur1; cur1 = cur1.left; continue; } else { cur2.right = null; //打印时机:第二次来到自己的时候 printEdge(cur1.left); } } cur1 = cur1.right; } //在返回前单独打印右边界 printEdge(head); System.out.println(); } public static void printEdge(Node head) { Node tail = reverseEdge(head); Node cur = tail; while (cur != null) { System.out.print(cur.value + " "); cur = cur.right; } reverseEdge(tail); } public static Node reverseEdge(Node from) { Node pre = null; Node next = null; while (from != null) { next = from.right; from.right = pre; pre = from; from = next; } return pre; }
public static int getMaxLength(TreeNode head,int sum){ //记录从head开始的一条路径上的累加和出现情况(含head值) HashMap<Integer,Integer> sumMap = new HashMap<Integer, Integer>(); sumMap.put(0,0); //不含任何节点,累加和为0 return preOrder(head,sum,0,1,0,sumMap); } private static int preOrder(TreeNode head, int sum, int preSum, int level, int maxLen, HashMap<Integer, Integer> sumMap) { if (head == null){ return maxLen; } int curSum = preSum+head.val; //当前和等于前面和加上现在的节点 //如果当前和已经没出现过则更新,如果已经出现过则不更新 if (!sumMap.containsKey(curSum)){ sumMap.put(curSum,level); //把当前累加和及当前层数存入map中 } if (sumMap.containsKey(curSum - sum)){ maxLen = Math.max(level - sumMap.get(curSum - sum),maxLen); } maxLen = preOrder(head.left,sum,curSum,level+1,maxLen,sumMap); maxLen = preOrder(head.right,sum,curSum,level+1,maxLen,sumMap); if (level == sumMap.get(curSum)){ sumMap.remove(curSum); } //返回最长路径的长度 return maxLen; }
这类问题属于属性DP问题,难点在于分析可能性,当把可能性分析后按照固定的套路,先考虑小部分再考虑大部分这样的顺序来即可。
这道题目中大流程为:求出每一个节点的搜索二叉树;小流程为:如何搜索具体节点的二叉子树
(1)可能性:最大搜索二叉子树可能在当前节点的左子树、右子树、含当前节点三部分中。根据可能性定义出信息体。
(2)根据上的可能性分析出可能需要的信息:左子树的搜索二叉树大小、右子树的搜索二叉树大小、左子树最大搜索二叉树的头部、右子树最大搜索二叉树的头部、左子树的最大值、右子树的最小值。
//需要返回的信息消息体,可以把信息压缩成4部分 public static class ReturnType{ //最大二叉搜索子树的大小 public int size; //最大二叉搜索子树的头 public Node head; //子树的最小值 public int min; //子树的最大值 public int max; public ReturnType(int a, Node b,int c,int d) { this.size =a; this.head = b; this.min = c; this.max = d; } } public static ReturnType process(Node head) { if(head == null) { return new ReturnType(0,null,Integer.MAX_VALUE, Integer.MIN_VALUE); } //左树的信息 Node left = head.left; ReturnType leftSubTressInfo = process(left); //右树的信息 Node right = head.right; ReturnType rightSubTressInfo = process(right); //可能性3包含该节点 int includeItSelf = 0; //左右子树最大二叉搜索树的头结点就是该头节点的左右子孩子,并且左右子树的最大最小值符合要求 if(leftSubTressInfo.head == left &&rightSubTressInfo.head == right && head.value > leftSubTressInfo.max && head.value < rightSubTressInfo.min ) { includeItSelf = leftSubTressInfo.size + 1 + rightSubTressInfo.size; } //可能性1是左子树 int p1 = leftSubTressInfo.size; //可能性2是右子树 int p2 = rightSubTressInfo.size; int maxSize = Math.max(Math.max(p1, p2), includeItSelf); //判断当前的最大二叉搜索子树是来自于哪种情况,是哪种情况相应的头部就变成谁 Node maxHead = p1 > p2 ? leftSubTressInfo.head : rightSubTressInfo.head; if(maxSize == includeItSelf) { maxHead = head; } //返回信息 return new ReturnType(maxSize, maxHead, Math.min(Math.min(leftSubTressInfo.min,rightSubTressInfo.min),head.value), Math.max(Math.max(leftSubTressInfo.max,rightSubTressInfo.max),head.value)); }
类似题目还有本章节的13、20。
利用递归模板的套路:
(1)判断该节点的左右子树是否是平衡二叉树
(2)若左右子树中有一个不平衡,直接返回false;若左右子树均是平衡二叉树则返回左右子树的高度
(3)根据左右子树的高度判断该节点是否是平衡二叉树
根据上面描述可以知道需要返回的信息:是否是平衡二叉树和该节点的高度
代码实现:
//定义返回类型 public static class ReturnData{ boolean isB; int h; public ReturnData(boolean isB,int h){ this.isB = isB; this.h = h; } } //主函数过程 public static boolean isB(Node head){ return process(head).isB; } //递归过程 public static ReturnData process(Node head){ if(head == null){ return new ReturnData(true,0); } //左子树的返回值 ReturnData leftData = process(head.left); //当左子树不是平衡二叉树时返回false,此时高度信息没有用了这里就直接返回0 if (!leftData.isB){ return new ReturnData(false,0); } //右子树的返回值,右子树的过程和左子树的过程是类似的 ReturnData rightData = process(head.right); if (!rightData.isB){ return new ReturnData(false,0); } //当左右子树高度差超过1时便说明该节点不是平衡节点 if (Math.abs(leftData.h - rightData.h) > 1){ return new ReturnData(false,0); } //经历了以上判断还在这里说明是平衡的,这时要返回该节点的真正高度信息:左右子树中高度相对大的一个自增1 return new ReturnData(true,Math.max(leftData.h,rightData.h)+1); }
注:上面代码中即没有用到先序遍历或其它常见的遍历方法,只是简单的使用递归。这里问题的难点在于如何列出返回信息,当列出返回信息时,只需要按照递归方法使用即可。对于优化一般可以优化返回信息。牛客网给出的测试有问题,忽略不管即可。
判断二分搜索树:中序遍历是一个递增序列;
代码实现:
判断完全二叉树:层序遍历节点,(1)如果一个节点有右孩子但没有左孩子返回false(2)若该节点在(1)判读后其左右孩子不全(只有左孩子或者没有左右孩子)则该节点遍历后面的每个节点必须是叶节点
public static boolean isCBT(Node head) { if (head == null) { return true; } //使用一个双端链表来实现队列 Queue<Node> queue = new LinkedList<Node>(); //是否开启叶节点阶段 boolean leaf = false; //定义左右节点 Node left = null; Node r = null; queue.offer(head); while (!queue.isEmpty()) { head = queue.poll(); left = head.left; r = head.right; //(left == null && r != null) 左节点为空有右节点,分析中的情况1 //(leaf && (left != null || r != null))开启了叶节点的阶段,左右两个孩子必须为空否则返回false if ((leaf && (left != null || r != null)) || (left == null && r != null)) { return false; } //广度遍历先加左再加右 if (left != null) { queue.offer(left); } //在第一个if中已经出现排除了左孩子为空右孩子不为空的情况,因此这里只需要判读右孩子为不为空即可,然后分情况分析 if (r != null) { queue.offer(r); } else { leaf = true; } } return true; }
后继节点的定义: 二叉树中序遍历中,node节点的下一个节点叫做node节点的后继节点
如果直接按照定义的那就是先中序遍历存进数组,然后在数组中找该节点的下一个节点即可,这样的时间复杂度为O(N)。但题目中定义了一个parent指针那么有没有可能使的找到后继节点遍历的数目就是根节点到其的路径。
考虑:如果一个节点有右子树,那么根据中序遍历的顺序:左中右,那么该右子树的最左节点就是该节点的后继节点;
若该节点没有右子树,那么向上找寻其父节点,直至找到其父节点的左子树是该节点,如下图所示:
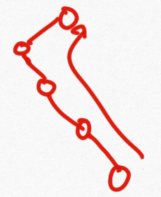
public static Node getNextNode(Node node) { if (node == null) { return node; } if (node.right != null) { //如果该节点有右子树找到其子树的最左节点 return getLeftMost(node.right); } else { Node parent = node.parent; //其父节点的左子树应该是该节点 while (parent != null && parent.left != node) { //利用parent节点向上寻找 node = parent; parent = node.parent; } return parent; } } //找到最左节点 public static Node getLeftMost(Node node) { if (node == null) { return node; } while (node.left != null) { node = node.left; } return node; }
与LeetCode236二叉树的最近公共祖先题目是一样的
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if (root == null || root == p || root == q){ return root; } TreeNode left = lowestCommonAncestor(root.left,p,q); TreeNode right = lowestCommonAncestor(root.right,p,q); if (left != null && right != null){ return root;//若左右子树均不为空,说明当前节点便是最近的公共节点 } //若有一个不为空则哪个不为空返回哪个,因为在递归的时候返回的是最近的,所以这个就是最近的公共祖先 return left != null ? left:right; }
与此类似的还有LeetCode235——二叉搜索树的最近公共祖先
19 Tarjan算法与并查集解决二叉树节点间最近公共祖先的批量查询问题
借用模板:大流程为遍历整个树,求出每一个节点的最大距离
可能性:左子树的最大距离、右子树的最大距离、含该节点的最大距离
这个在牛客网上提交答案显示不通过,要在看看下
public static class ReturnType{ public int maxDistance; //最大距离 public int h; //深度 public ReturnType(int m, int h) { this.maxDistance = m;; this.h = h; } } public static ReturnType process(Node head) { if(head == null) { return new ReturnType(0,0); } //获得左右两边的信息 ReturnType leftReturnType = process(head.left); ReturnType rightReturnType = process(head.right); //可能性3含自己 int includeHeadDistance = leftReturnType.h + 1 + rightReturnType.h; //可能性1,左边的最大距离 int p1 = leftReturnType.maxDistance; //可能性2,右边的最大距离 int p2 = rightReturnType.maxDistance; //当前节点的最大距离 int resultDistance = Math.max(Math.max(p1, p2), includeHeadDistance); //当前节点的深度 int hitself = Math.max(leftReturnType.h, leftReturnType.h) + 1; return new ReturnType(resultDistance, hitself); }
这里还可以不用上面的模板,借用动态规划解决
相关题目:
一个公司的上下节关系是一棵多叉树, 这个公司要举办晚会, 你作为组织者已经摸清了大家的心理: 一个员工的直接上级如果到场, 这个员工肯定不会来。 每个员工都有一个活跃度的值, 决定谁来你会给这个员工发邀请函, 怎么让舞会的气氛最活跃? 返回最大的活跃值。给定一个矩阵来表述这种关系
matrix ={ 1,6
1,5
1,4}
这个矩阵的含义是:matrix[0] = {1 , 6}, 表示0这个员工的直接上级为1, 0这个员工自己的活跃度为6;matrix[1] = {1 , 5}, 表示1这个员工的直接上级为1(他自己是这个公司的最大boss) ,1这个员工自己的活跃度为5;matrix[2] = {1 , 4}, 表示2这个员工的直接上级为1,2这个员工自己的活跃度为4;为了让晚会活跃度最大, 应该让1不来, 0和2来。 最后返回活跃度为10
public class Node{ public int huo;//活跃度 public List<Node> nexts; public Node(int huo){ this.huo = huo; nexts = new ArrayList<Node>(); } } //定义信息体 public class ReturnData{ public int lai_huo; public int bu_lai_huo; public ReturnData(int lai_huo,int bu_lai_huo){ this.lai_huo = lai_huo; this.bu_lai_huo = bu_lai_huo; } } //获得最大活跃度 public int getMaxHuo(){ ReturnData data = process(head); //在不来的活跃度和来的活跃度中选出最大的 return Math.max(data.bu_lai_huo,data.lai_huo); } //递归的过程 public ReturnData process(Node head){ int lai_huo = head.huo; int bu_lai_huo = 0; for (int i = 0; i < head.nexts.size(); i++) { Node next = head.nexts.get(i); ReturnData nextData = process(next); lai_huo += nextData.bu_lai_huo; bu_lai_huo += Math.max(nextData.lai_huo,nextData.bu_lai_huo); } return new ReturnData(lai_huo,bu_lai_huo); }
这部分囊括了常见的组合形式,在LeetCode-105从前序与中序遍历序列构造二叉树,106-从中序与后序序列遍历构造二叉树都有涉及的。详细的解析可以参考剑指offer读书笔记中2.3.4部分-重建二叉树
这里给出中序后序构造二叉树代码不同之处在于:先序和中序的过程是用先序数组最左的值来对中序数组进行划分,因为这是头节点的值。后序数组中头节点的值是后序数组最右的值,所以用后序最右的值来划分中序数组即可。
public TreeNode buildTree(int[] in, int[] pos) { TreeNode root = build(in,0,in.length-1,pos,0,pos.length-1); return root; } private TreeNode build(int[] in, int startIn, int endIn,int[] pos, int startPos, int endPos) { if (startPos >endPos || startIn > endIn){ return null; } TreeNode root = new TreeNode(pos[endPos]); for (int i = startIn; i <=endIn ; i++) { if (in[i] == pos[endPos]){ root.left = build(in,startIn,i-1,pos,startPos,startPos+i-startIn-1); root.right = build(in,i+1,endIn,pos,startPos+i-startIn,endPos-1); break; } } return root; }
有结论:满二叉树若高度为h,则节点数为2^h - 1

public static int nodeNum(Node head) { if (head == null) { return 0; } //1表示头节点在第一层 return bs(head, 1, mostLeftLevel(head, 1)); } //这里的h是不变的,表示整体树的左边界深度 public static int bs(Node node, int level, int h) { //当相等时表明来到了最后一层即叶节点,那么叶节点的个数为1 if (level == h) { return 1; } //判断以该节点的右子树的深度,是否与整体的深度相同 if (mostLeftLevel(node.right, level + 1) == h) { //通过移位运算来表示指数运算,因为加一减一抵消了只需要算指数运算即可 return (1 << (h - level)) + bs(node.right, level + 1, h); } else { return (1 << (h - level - 1)) + bs(node.left, level + 1, h); } } //获取以该节点为头节点的整个树的左边界在哪一层 public static int mostLeftLevel(Node node, int level) { while (node != null) { level++; node = node.left; } return level - 1; }
时间复杂度分析:因为每层只遍历一个节点,那么需要遍历的节点数是logN,每个节点需要遍历左边界又是logN,因此总的时间复杂度为O((logN)^2)
0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号