Python——sklearn.preprocessing.StandardScaler()
# StandardScaler类是一个用来对数据进行归一化和标准化的类。
import numpy as np
from sklearn.preprocessing import StandardScaler
'''
scale_: 缩放比例,同时也是标准差
mean_: 每个特征的平均值
var_:每个特征的方差
n_sample_seen_:样本数量,可以通过patial_fit 增加
'''
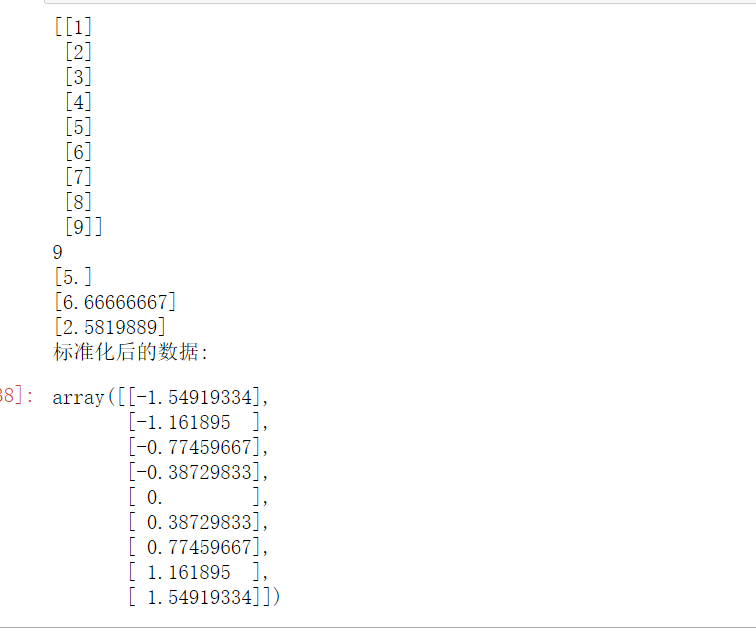
x = np.array(range(1, 10)).reshape(-1, 1)
ss = StandardScaler()
ss.fit(X=x)
print(x)
print(ss.n_samples_seen_)
print(ss.mean_)
print(ss.var_)
print(ss.scale_)
print('标准化后的数据:')
y = ss.fit_transform(x)
y
结果:
关于StandardScaler()的api函数
| api | describe |
|---|---|
fit(X[, y, sample_weight]) |
Compute the mean and std to be used for later scaling. |
fit_transform(X[, y]) |
Fit to data, then transform it. |
get_feature_names_out([input_features]) |
Get output feature names for transformation. |
get_params([deep]) |
Get parameters for this estimator. |
inverse_transform(X[, copy]) |
Scale back the data to the original representation. |
partial_fit(X[, y, sample_weight]) |
Online computation of mean and std on X for later scaling. |
set_params(**params) |
Set the parameters of this estimator. |
transform(X[, copy]) |
Perform standardization by centering and scaling. |
常用api方法:
1、fit
用于计算训练数据的均值和方差, 后面就会用均值和方差来转换训练数据
2、fit_transform
不仅计算训练数据的均值和方差,还会基于计算出来的均值和方差来转换训练数据,从而把数据转换成标准的正太分布
3、transform
很显然,它只是进行转换,只是把训练数据转换成标准的正态分布
对于上述方法的使用:
a) 先用fit
scaler = preprocessing.StandardScaler().fit(X)
这一步可以得到scaler,scaler里面存的有计算出来的均值和方差
b) 再用transform
scaler.transform(X)
这一步再用scaler中的均值和方差来转换X,使X标准化
c) 那么在预测的时候, 也要对数据做同样的标准化处理,即也要用上面的scaler中的均值和方差来对预测时候的特征进行标准化
注意:测试数据和预测数据的标准化的方式要和训练数据标准化的方式一样, 必须用同一个scaler来进行transform
有时会发现学习是一件很快乐的事情 比一直跑步容易多了 不是嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号