Bigdata——Hadoop搭建
准备:
需要三台虚拟机(修改好IP地址并安装JAVA)
修改当前网络时间:
date -s ”2021-10-23 08:47:00“
关闭防火墙并且关闭防火墙自启动
service iptables stop/status/start/resrtart //防火墙的相关命令 chkconfig iptables off //关闭防火墙自启动
设置三台主机ssh免密登陆
现修改/etc/hosts的映射 添加三台机子的IP与name
将映射文件传给其他节点
scp /etc/hosts node1:/etc/hosts scp /etc/hosts node2:/etc/hosts
主节点执行 ssh-keygen -t rsa 并一直回车 生成密钥
将密钥拷贝到其他两个子节点,实现免密码登录到子节点。命令如下:
ssh-copy-id -i node1 ssh-copy-id -i node2
实现主节点master本地免密码登录
cd /root/.ssh cat ./id_rsa.pub >> ./authorized_keys
安装hadoop:
新建文件目录:
mkdir /bigdata
解压hadoop-2.6.0
tar -zxvf hadoop-2.6.0.tar.gz -C /bigdata
修改hadoop的配置环境,目录是在/bigdata/hadoop-2.6.0/etc/hadoop内
-
修改hadoop-env.sh 根据个人环境JAVA的安装目录来
export JAVA_HOME=/bigdata/jdk1.8.0 -
修改slaves
node1 node2 -
修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/bigdata/hadoop-2.6.0/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration> -
修改hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> -
修改yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> </configuration> -
修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
将修改好的hadoop配置发送到其他子机上:
scp -r /bigdata/hadoop-2.6.0 node1:/bigdata scp -r /bigdata/hadoop-2.6.0 node2:/bigdata
环境配置就直接在/etc/profile里面写就行了
然后在主节点终端 先对namenode格式化 然后在启动hadoop即可
hdfs namenode -format start-all.sh
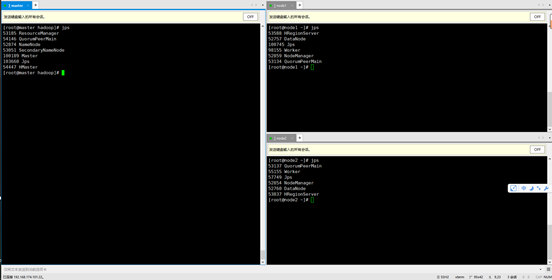
利用jps查看相关进程
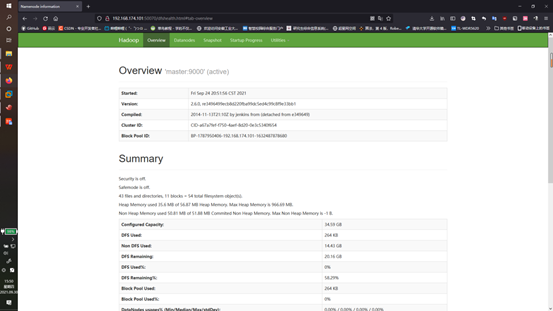
也可以访问主机:50070验证hdfs的状态
这里是网址是 192.168.174.101:50070
测试hadoop
编写一个txt 文本,例如
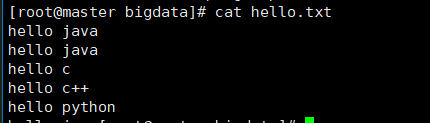
再将其上传到hdfs上:

这里input的路径我已经存在 如果不存在 请使用 hadoop fs -mkdir /input 创建
调用hadoop自带的mapreduce
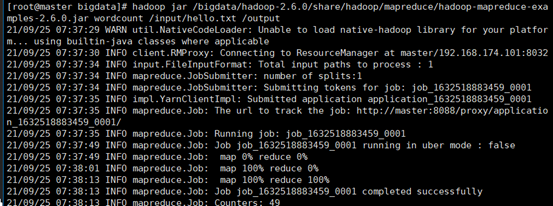
利用hadoop自带的jar包对文本进行计数工作。
hadoop jar /bigdata/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /input/hello.txt /output
该jar包没有指定函数接口 所以要在jar包后输入函数名作为 指出运行接口。
后面两个是输入和输出的路径。
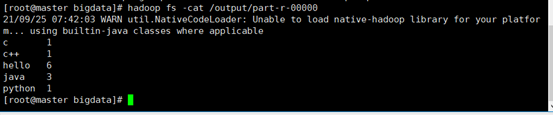
使用 hadoop fs -cat /output/part-r-00000 查看结果
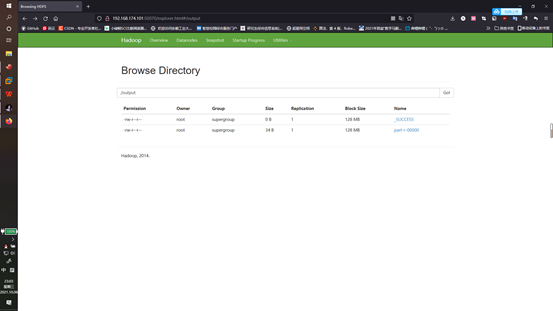
或者在本机的web上查看结构
有时会发现学习是一件很快乐的事情 比一直跑步容易多了 不是嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号