机器学习基础——范数
范数本质是向量或者矩阵映射到实数域的单值函数。
假设\(N(x)=\Vert x \Vert\)是定义在\(R^n\)上的函数,她需要满足以下三个条件:
- 非负性: \(\Vert x \Vert \ge 0\),当且仅当\(x=0\)时,\(\Vert x \Vert = 0\)
- 齐次性:\(\Vert kx \Vert = \Vert x \Vert *\Vert k \Vert, \quad k \in R\)
- 三角不等性:对于\(\forall x,y \in R^n, \quad \Vert x+y \Vert \le \Vert x \Vert+\Vert y \Vert\)
则称\(N(x)=\Vert x \Vert\)在\(R^n\)上向量\(x\)的范数
那么,向量范数和矩阵范数输出都是一个值,实数值。只不过输入空间不同罢了。他们都是为了能够更显性的体现出一个向量和矩阵的大小。
下面是一些范数的图示:
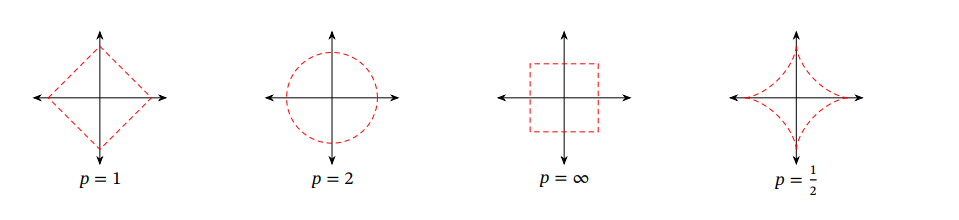
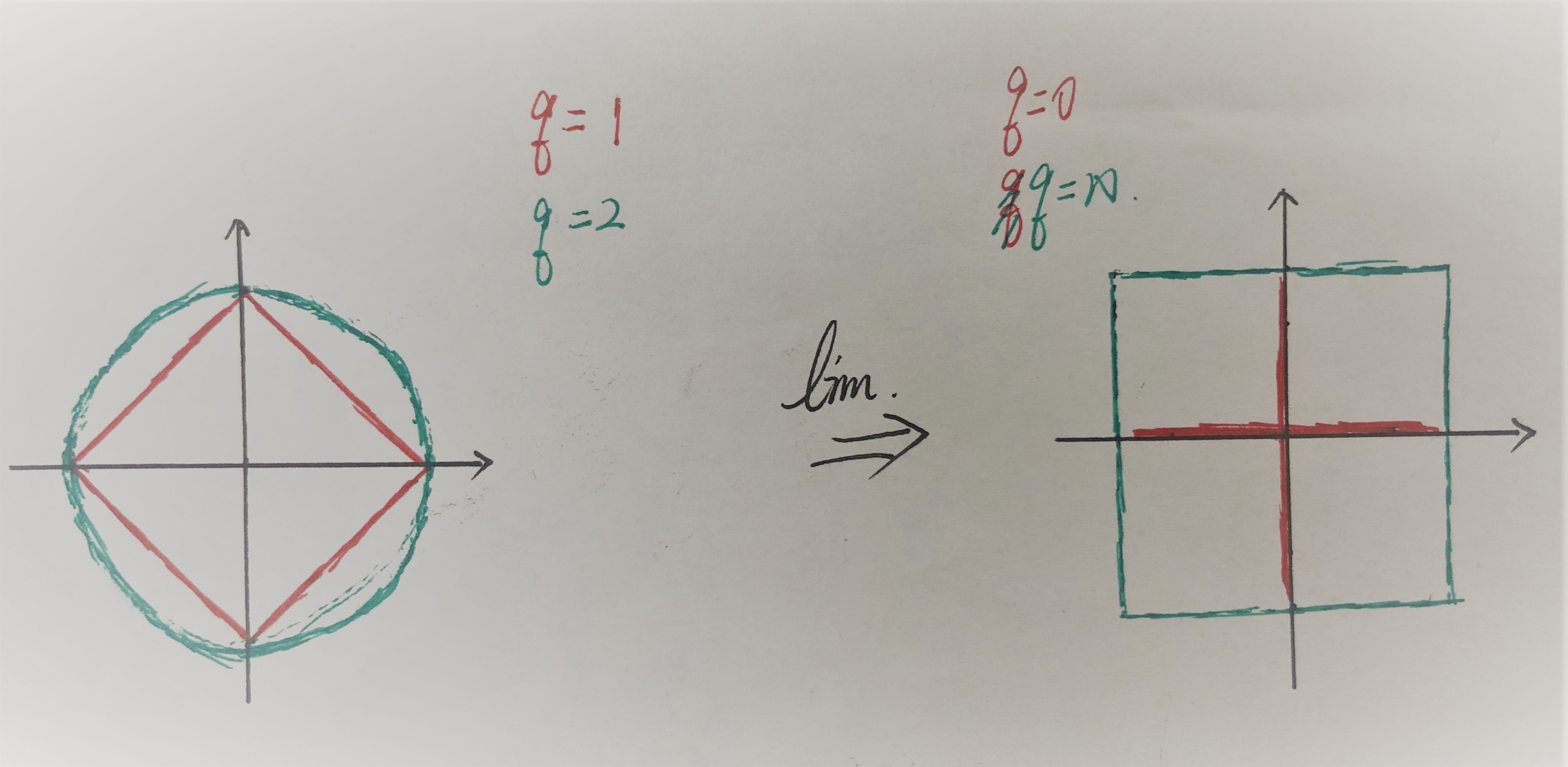
同样,范数也可以有相对应的变化趋势,从下图中不难发现一些东西:
Vector 范数计算公式:
\[\Vert x\Vert_1= \sum_{i=1}^N |x_i| \\\Vert x\Vert_2= \sqrt {\sum_{i=1}^N x_i^2} \\\Vert x\Vert_p= ({\sum_{i=1}^N x_i^p})^{\frac{1}{p}} \\\Vert x\Vert _\infty= \max|x_i|
\]
Matrix 范数计算公式:
\[A_{m\times n}\\ \Vert A\Vert_1= \max_j \sum_{i=1}^m |a_{ij}| \\\Vert A\Vert_2= \sqrt {\lambda_{max}(A^TA)} \\\Vert A\Vert_F= ({\sum_{i=1}^m \sum_{j=1}^n |a_{ij}|^2})^{\frac{1}{2}} \\\Vert A\Vert_\infty= \max_i \sum_{j=1}^n|a_{ij}|
\]
范数的应用:在机器学习中,范数最常见的作用是来对目标函数进行惩罚,达到正则化的效果,以免目标函数过拟合。当然面对模型过拟合的方法不止正则化这一种,还有增加数据,特征提取等方式。
\(L_1\)范数(Lasso)和\(L_0\)范数通过正则化得到稀疏解
\(L_2\)范数(Ridge)通过正则化得到稠密解,这种方法有个专有的名字:权值衰减
有时会发现学习是一件很快乐的事情 比一直跑步容易多了 不是嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号