192. 统计词频
题目
写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
为了简单起见,你可以假设:
words.txt只包括小写字母和 ' ' 。
每个单词只由小写字母组成。
单词间由一个或多个空格字符分隔。
示例:
假设 words.txt 内容如下:
the day is sunny the the
the sunny is is
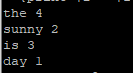
你的脚本应当输出(以词频降序排列):
the 4
is 3
sunny 2
day 1
说明:
不要担心词频相同的单词的排序问题,每个单词出现的频率都是唯一的。
你可以使用一行 Unix pipes 实现吗?
解答
首先,看到输入和输出,我们应该考虑四个点:
- 竖排,使用tr -s命令将空格变成回车。
- 排序,可以使用sort -r倒序排列词汇。
- 去重,使用uniq -c统计各词汇出现次数。
- 排列,可使用awk命令来重新排列输出内容。
于是我们最终给出的命令如下:
cat words.txt |tr -s ' ' '\n'|sort -r|uniq -c|awk '{print $2" "$1}'
而预计的输出如下:
193. 有效电话号码
题目
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个 bash 脚本输出所有有效的电话号码。
你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
你也可以假设每行前后没有多余的空格字符。
示例:
假设 file.txt 内容如下:
987-123-4567
123 456 7890
(123) 456-7890
你的脚本应当输出下列有效的电话号码:
987-123-4567
(123) 456-7890
解答
此题考正则表达式,只要将正确的正则表达式写出即可。
观察两个合规表达式的共同点,可将其分为两部分:
第一部分:
(三位数字)三位数字:(xxx) xxx 或者 三位数字-三位数字:xxx-xxx
第二部分:
横杠+四位数字:-xxxx
所以,此表达式就是第一部分和第二部分加在一起就可以。
我们可以用grep/awk/sed来做匹配。
grep版:
grep -P '^(\d{3}-|\(\d{3}\) )\d{3}-\d{4}$' file.txt
sed版:
sed -n -r '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/p' file.txt
awk版:
awk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-([0-9]{4})$/' file.txt
最后得到的结果是一样的:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号