UI自动化测试之页面对象设计模式
1、概述
1.1页面对象设计模式的优势
在自动化测试过程中,对于维护的成本而言,需要考虑进一步的优化,那么我们可以使用页面对象设计模式,它的具体优势如下:
(1)创建可以跨多个测试用例共享的代码
(2)减少重复代码的数量
(3)如果用户界面发生了维护,我们只需要维护一个地方,这样修改以及维护的成本相对而言是比较低的。
1.2创建项目
在pycharm中创建项目的步骤如图:
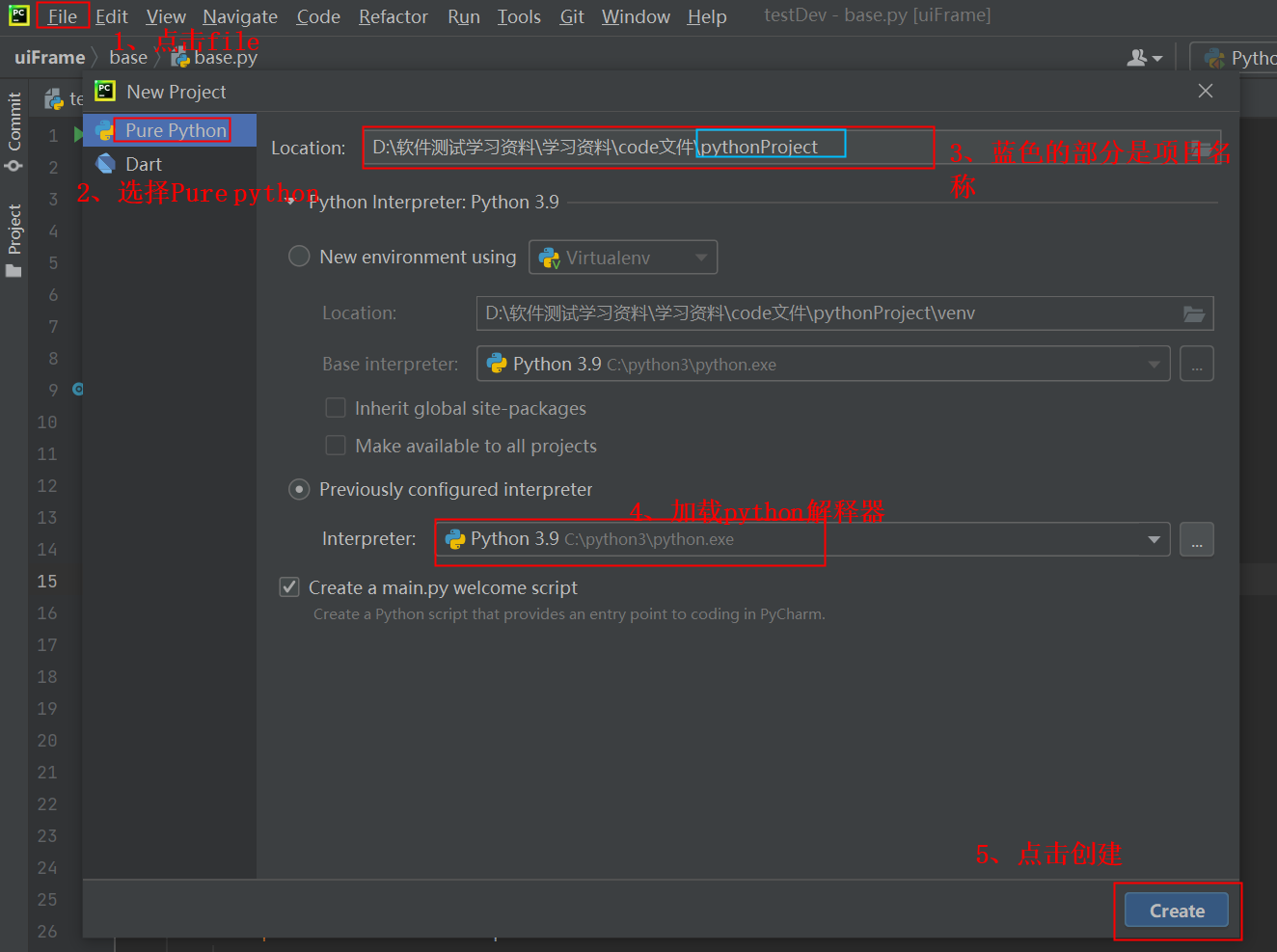
然后点击attch即可在project中看到新创建的项目:
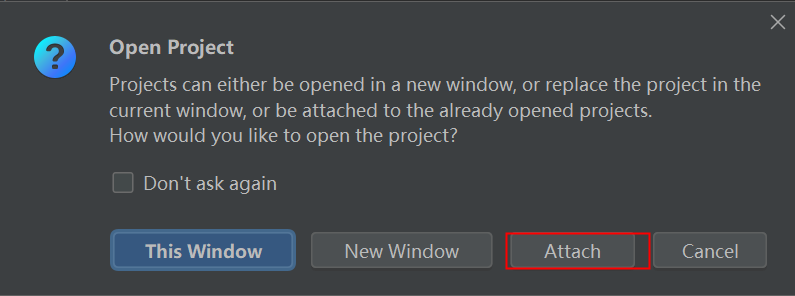
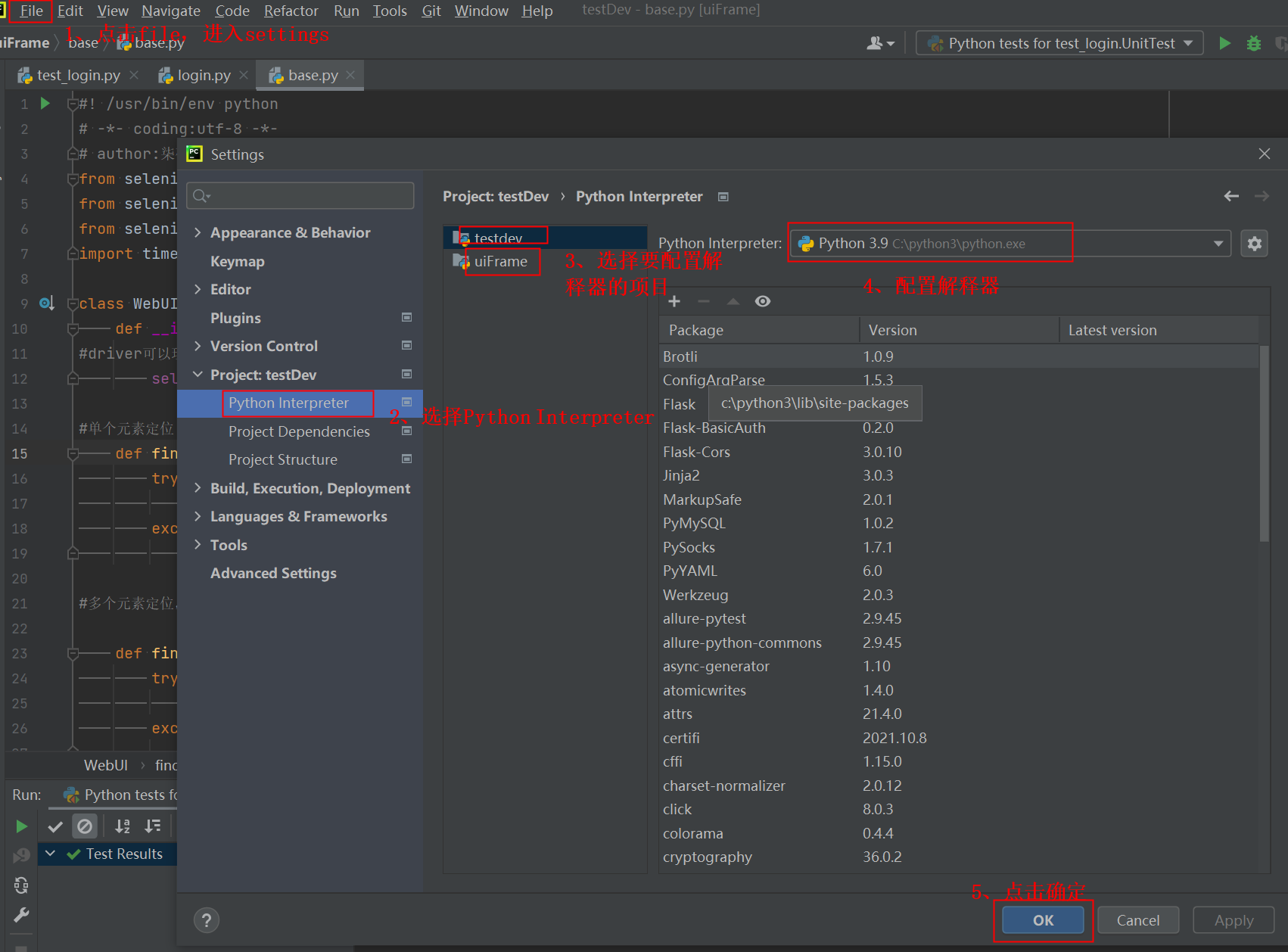
给已经创建好的项目配置python解释器:
2、页面对象设计
2.1目录结构设计
编写的目录顺序可自行调整,如下图:
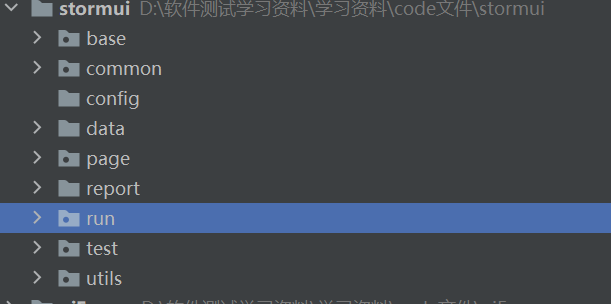
各个目录详解:
(1)base:基础层,主要编写底层定位元素的类,它是一个包。
(2)common:公共类,里面编写公共使用到的方法。
(3)config:配置文件存储目录。
(4)data:存储测试使用到测试数据。
(5)page:对象层,编写具体的业务逻辑,把页面每一个操作行为单独的写一个方法或者是函数。
(6)report:测试报告目录,主要用来存放测试报告。
(7)test:测试层,里面主要是测试模块,也可以说是每个测试的场景的代码。
(8)utils:工具类,存放工具,如文件处理、说明文档等。
(9)run:运行层:整个自动化测试的运行目录。
2.2具体页面设计模式
这里以新浪邮箱为例,来说明整个页面设计的具体目录如何实现的代码。
2.2.1基础层:base
该目录是基础层,主要编写底层定位元素的类,它是一个包;元素定位有两类,单个元素定位和多个元素定位。以及一种特殊的情况,定位iframe框架中的元素,我们之前已经说过,进入iframe框架有三种方式:ID、name和索引,这里简述通过ID进入iframe框架的方式,base层里的东西,适用于所有场景,即无论做什么产品的自动化测试,都可以直接进行调用:
#base:基础层,主要编写底层定位元素的类,它是一个包;元素定位有两类,单个元素定位和多个元素定位,还有一种特殊情况,即需要定位的元素在iframe框架中。
from selenium.webdriver.support.expected_conditions import NoSuchElementException #显示异常信息要导入的类
#定义一个编写底层定位元素的类
class WebUI(object):
def __init__(self,driver):
#=driver里的drive可以理解为webdriver实例化后的对象,这里只是做一个假设,在测试类中进行验证,
self.driver=driver
'''单个元素定位的方式
args:*args:识别元素属性,ctr+鼠标放置到元素+左键:判断定位元素属性的方法是否正确
:return:它是一个元组,需要带上具体什么方式定位元素属性以及元素属性的值'''
#单个元素定位:
# def findElement(self,*args):
# return self.driver.find_element(*args)
# 如果想要获取到运行异常是的详细信息,可以使用函数异常逻辑,except返回具体错误信息。
def findElement(self,*args):
try:
return self.driver.find_element(*args)
except NoSuchElementException as e:
return e.args[0]
'''单个元素定位的方式
args:*args:识别元素属性,ctr+鼠标放置到元素+左键:判断定位元素属性的方法是否正确
index:识别元素的索引
:return:它是一个元组,需要带上具体什么方式定位元素属性以及元素属性的值'''
# #多个元素定位,由于需要使用到他的索引,所以需要加一个index参数。
# def findElements(self, *args, index):
# return self.driver.find_elements(*args)[index]
# 如果想要获取到运行异常是的详细信息,可以使用函数异常逻辑,except返回具体错误信息。
def findElements(self,*args,index):
try:
return self.driver.find_elements(*args)[index]
except NoSuchElementException as e:
return e.args[0]
#iframe框架中的元素定位,这里简述通过ID的方式进入iframe框架:
def findFrame(self,frameID):
return self.driver.switch_to.frame(frameID)2.2.2对象层:page
该目录是对象层,编写具体的业务逻辑,把页面每一个操作行为单独的写一个方法或者是函数,他是一个包。
#page:对象层,编写具体的业务逻辑,把页面每一个操作行为单独的写一个方法或者是函数。如下:
from selenium.webdriver.common.by import By #By:具体元素定位需要用到的类
from base.base import WebUI #导入base层,也就是基础层,WebUI元素定位的类。
import time #关于时间的库
#定义一个登录的类:username、password、loginEnter、errorPrompt是登录的类中的数据属性,可以在整个类中调用,调用的方式为:self.数据属性。
class Login(WebUI): #要定位元素,所以需要继承WebUl类。
username=(By.ID,"freename")
password=(By.ID,"freepassword")
loginEnter=(By.CLASS_NAME,"loginBtn")
errorPrompt=(By.XPATH,"/html/body/div[3]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[1]/span[1]")
#用户名:输入用户名这个操作的函数
def InputUsername(self,username):
time.sleep(3)
self.findElement(*self.username).send_keys(username)
#密码:输入密码这个操作的函数
def InputPassword(self,password):
time.sleep(3)
self.findElement(*self.password).send_keys(password)
#点击登陆这个操作的函数
def loginClick(self):
self.findElement(*self.loginEnter).click()
#获取提示框文本信息的函数
def textInformation(self):
return self.findElement(*self.errorPrompt).text
#封装:把新浪输入用户名和密码后点击登录的操作封装为一个函数。
def sinaLogin(self,username,password):
self.InputUsername(username=username)
self.InputPassword(password=password)
self.loginClick()2.2.3测试层:test
该目录是测试层,里面主要是测试模块,也可以说是每个测试的场景的代码。
#test:测试层,里面主要是测试模块,也可以说是每个测试的场景的代码。
from selenium import webdriver #自动化测试必须导入的类。
import unittest #测试固件所用到的方法所在的库。
from page.login import Login #导入登陆的类Login
import time #关于时间的库
#定义一个测试类:
class UnitTest(unittest.TestCase,Login):
#初始化
def setUp(self) -> None:
self.driver=webdriver.Chrome() #这里是对webdriver进行实例化,也是对基础层中driver假设的证明。
self.driver.maximize_window()
self.driver.get("https://mail.sina.com.cn/")
self.driver.implicitly_wait(30)
#清理
def tearDown(self) -> None:
self.driver.quit()
#测试模块:登陆的用户名和密码为空
def test_login_Empty(self): #测试用例的名称一定要以test开头,推荐test_。
self.InputUsername(username="") #调用page中的输入用户名的函数
self.InputPassword(password="") #调用page中的输入密码的函数
self.loginClick() #调用page中点击登录的函数
# self.sinaLogin(username="",password="") #调用在page中封装的函数sinaLogin()。
time.sleep(5)
self.assertEqual(self.textInformation(),"请输入邮箱名") #断言,验证登录提示的文本信息,调用page中的获取提示框文本信息的函数
time.sleep(5)
#测试场景:新浪邮箱的登陆
def test_login_format(self): #测试用例的名称一定要以test开头,推荐test_。
'''验证登陆的用户名和密码格式不对''' #测试用例的注释,测试用例一定要有注释。
self.InputUsername(username="asd123") #调用page中的输入用户名的函数
self.InputPassword(password="asd123") #调用page中的输入密码的函数
self.loginClick() #调用page中点击登录的函数
# self.sinaLogin(username="asd123",password="asd123") #调用在page中封装的函数sinaLogin()。
time.sleep(5)
self.assertEqual(self.textInformation(),"您输入的邮箱名格式不正确") ##断言,验证登录提示的文本信息,调用page中的获取提示框文本信息的函数
time.sleep(5)
def test_login_error(self): #测试用例的名称一定要以test开头,推荐test_。 #调用在page中封装的函数sinaLogin()。
'''验证登陆的用户名和密码错误''' #测试用例地注释。
self.InputUsername(username="asd123@sina.com") #调用page中的输入用户名的函数
self.InputPassword(password="asd123") #调用page中的输入密码的函数
self.loginClick() #调用page中点击登录的函数
# self.sinaLogin(username="asd123@sina.com",password="asd123")
time.sleep(5)
self.assertEqual(self.textInformation(),"登录名或密码错误") ##断言,验证登录提示的文本信息,调用page中的获取提示框文本信息的函数
time.sleep(5)2.2.4公共类:common
这个目录里面编写公共使用到的方法,如路径处理,即获取当前文件目录,该目录也通用于所有测试场景,但前提是po设计模式的目录结构如上图所示。
import os #路径处理的库
def base_dir(): #获取当前文件的目录的上一级目录,也就是获取整个自动化测试的Po设计模式是在哪个目录下。
return os.path.dirname(os.path.dirname(__file__))
print(base_dir())2.2.5配置文件存储目录:config
该目录主要用来储存测试中的配置文件。
2.2.6工具类:utils
这个目录主要用来存放我们测试中用到的一些工具,比如数据驱动时关于json文件的处理、整个测试的说明文档等。该目录也适用于所有的测试场景,但是需要修改对应的文件名,如上所述,适用的前提是po设计模式的目录结构如上图所示。
import json #处理json文件必须要导入的库
from common.public import base_dir #导入获取自动化测试po设计模式的路径的类
import os #路径处理的库
def readJson(): #定义一个返回读取的自动化测试po设计模式data目录下sina.json文件的内容
return json.load(open(file=os.path.join(base_dir(),"data","sina.json"),encoding="utf-8")) #json文件反序列化的过程。2.2.7数据层:data
该目录下主要存放测试使用到的数据,一般是数据驱动时分离出来的数据,储存在json文件中,该层需要注意的就是json文件中的内容始终是一个字典的形式。
{
"addressEmpty":"请输入邮箱名",
"passwordEmpty":"请输入密码",
"confirm":"请再次输入密码"
}2.2.8报告层:report
该目录主要时用来存放测试报告的。
2.2.9运行层:run
该目录是运行测试用例的目录,我们可以根据测试模块来运行,也可以运行所有模块。该层的内容也适用于所有场景,如上所述,适用的前提是po设计模式的目录结构如上图所示。
import HTMLTestRunner #生成测试报告必须要用到的库。
import os #处理路径的库。
import unittest #加载测试模块要用到的库。
import time #时间处理的库。
#按模块来执行:
if __name__=="__main__":
#start_dir=加载所有的测试模块来执行,pattern通过正则的方式获取到要执行的模块。
pathTest = os.path.dirname(os.path.dirname(__file__)) #获取当前路径的上一级目录,也就是自动化测试po设计模式所在的目录,这里简称位主目录。
#(os.path.join(pathTest, "test"))路径拼接,加载的是主目录下的test层中的模块。
suite = unittest.TestLoader().discover(start_dir=(os.path.join(pathTest, "test")),pattern="test_sina.py")
unittest.TextTestRunner().run(suite)
#加载所有的测试模块来执行:执行用到的是unittest库里的TextTestRunner类中的run方法。
#第一种方式:
if __name__=="__main__":
#start_dir=加载所有的测试模块:用到的是unittest库下的TestLoader类中的discover方法,pattern通过正则的方式获取到要执行的模块,*表示所有。
suite =unittest.TestLoader().discover(start_dir=(os.path.join(pathTest, "test")), pattern="test_*.py") #加载要执行的测试模块。
unittest.TextTestRunner().run(suite) #执行加载到的测试模块。
#第二种方式:
def getSuite():
suite = unittest.TestLoader().discover(start_dir=os.path.dirname(__file__), pattern="test_*.py")
return suite
if __name__ == '__main__':
unittest.TextTestRunner().run(getSuite())
#生成自动化测试报告:
#加载所有的测试模块并返回:unittest库下的TextTestRunner()类中的run方法。
def getSuite():
#start_dir=加载所有的测试模块来执行,pattern通过正则的方式获取到要执行的模块
pathTest = os.path.dirname(os.path.dirname(__file__)) #获取主目录。
#获取所有的测试模块:unittest库下的TestLoader()类中的discover的方法。
#(os.path.join(pathTest, "test"))路径拼接,加载的是主目录下的test层中的模块。
suite = unittest.TestLoader().discover(start_dir=(os.path.join(pathTest, "test")), pattern="test_*.py")
return suite
#获取当前时间,由于python格式的限制,当前时间最好采用下面的方式:
def getNowTime():
return time.strftime("%y-%m-%d %H_%M_%S",time.localtime(time.time()))
#执行获取的测试模块,并获取测试报告
def sinaReport():
#获取当前路径的上一级目录,即主目录。
reportPath=os.path.dirname(os.path.dirname(__file__))
#定义文件名和文件储存的路径,文件的储存路径为:reportPath,"report",定义文件名为当前时间+report.html,主要是为为了区分不同时间段生成的测试报告。
filename=os.path.join(reportPath,"report",getNowTime()+"report.html")
time.sleep(3)
#把测试报告写入文件中,b是以二进制的方式写入
fp=open(filename,"wb")
time.sleep(3)
#HTMLTestRunner实例化的过程,stream是流式写入,title是测试报告的标题,description是对测试报告的描述
runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title="新浪邮箱",description="新浪邮箱自动化测试")
time.sleep(3)
#运行所有测试套件:HTMLTestRunner里的run方法。
runner.run(getSuite())
time.sleep(3)
#主函数:执行的入口
if __name__ == '__main__':
sinaReport()
