python——库的管理
1、标准库
import os #借用外部的库,需要先进行调用。
#获取当前工作目录,即当前python脚本工作的目录路径。
print("获取当前路径",os.getcwd()) #获取某个固定的路径,一般来说不是很实用。
#路径拼接
#基础路径,可以通过该方法获取可变的路径。
print(os.path.dirname(__file__))
#获取当前路径的上一级目录
print(os.path.dirname(os.path.dirname(__file__)))
#获取当前路径的上两级目录
print(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))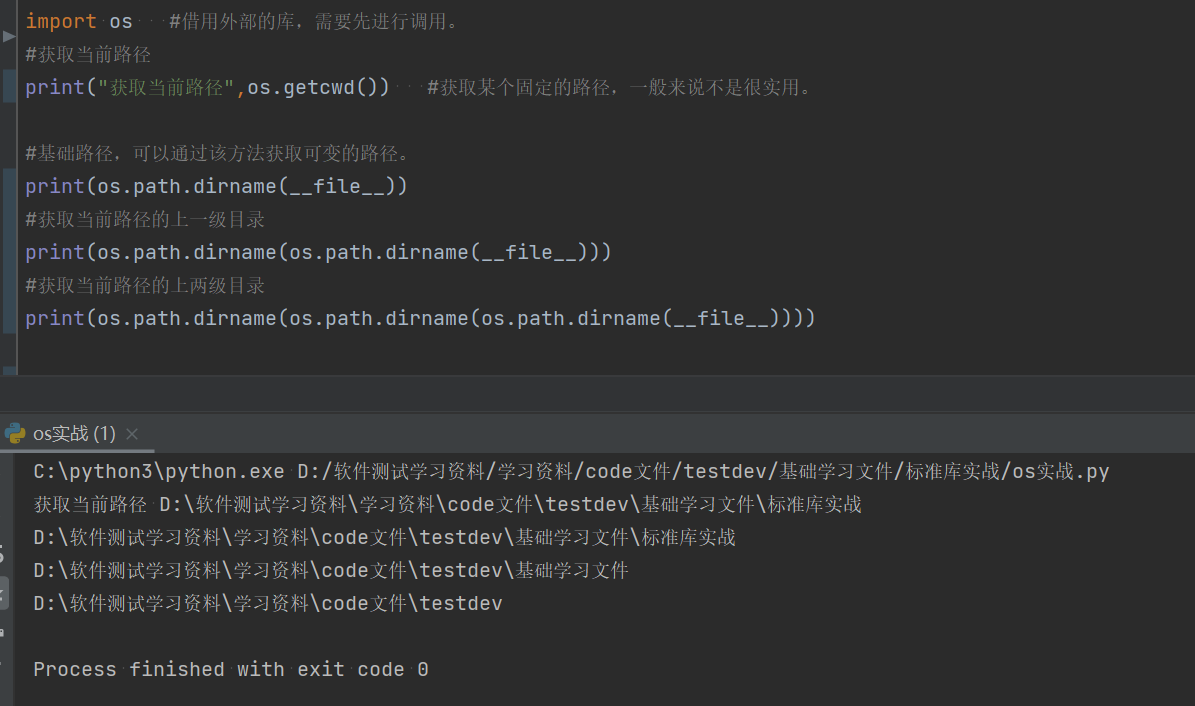
1.1.2通过基础路径的方法读取文件
import os #借用外部的库,需要先进行调用。
#通过基础路径读取文件,如读取标准库实战文件夹下的data文件夹下的login.txt文件。
base_dir=os.path.dirname(__file__) #定义基础路径(base_dir),获取标准库实战文件夹。
print(base_dir)
# 路径拼接,filePath=(os.path.join(base_dir,"存放文件的文件夹","文件名")。
#存放文件的文件夹如果在获得的基础路径的第二级目录下,(base_dir,"存放文件的文件夹","文件名")就可以写为(base_dir,"存放文件的第一级文件夹","存放文件的第二级文件夹","文件名")
filePath=(os.path.join(base_dir,"data","login.txt")) #定义变量为获取文件的路径和文件名(fliePath):路径拼接。
with open(file=filePath,mode="r",encoding="utf-8") as f:
print(f.read())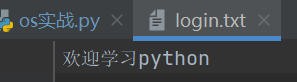
1.1.3获取当前目录下的所有文件和文件夹
import os #借用外部的库,需要先进行调用。
#获取当前目录下所有文件和文件夹
for a in os.listdir(path=os.getcwd()):
print(a)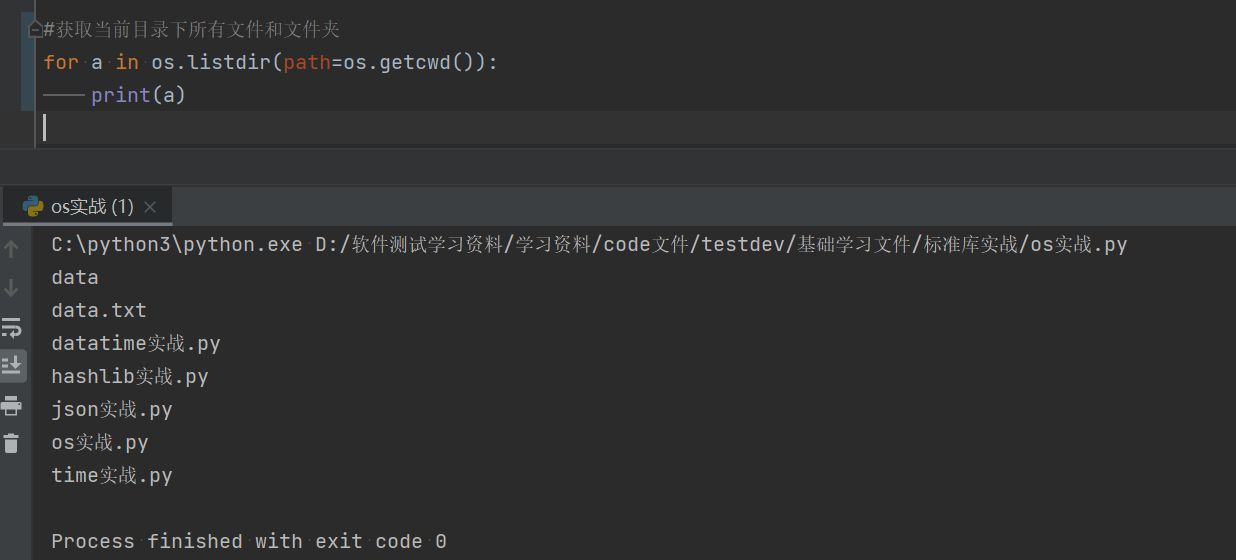
1.1.4获取文件/目录信息
import os #借用外部的库,需要先进行调用。
#获取某个文件或目录信息:os.stat("某个目录\某个文件")
print(os.stat("D:"))
1.1.5 查看操作系统名称
import os #借用外部的库,需要先进行调用。
#获取操作系统名称,windows平台下返回‘nt’,Linux则返回‘posix’。
print(os.name)
1.1.6查看系统环境变量
import os #借用外部的库,需要先进行调用。
#获取系统环境变量
print(os.environ)
1.1.7判断文件是否存在
import os #借用外部的库,需要先进行调用。
#判断文件是否存在。输出的是True或者Flase
print(os.path.exists(filePath))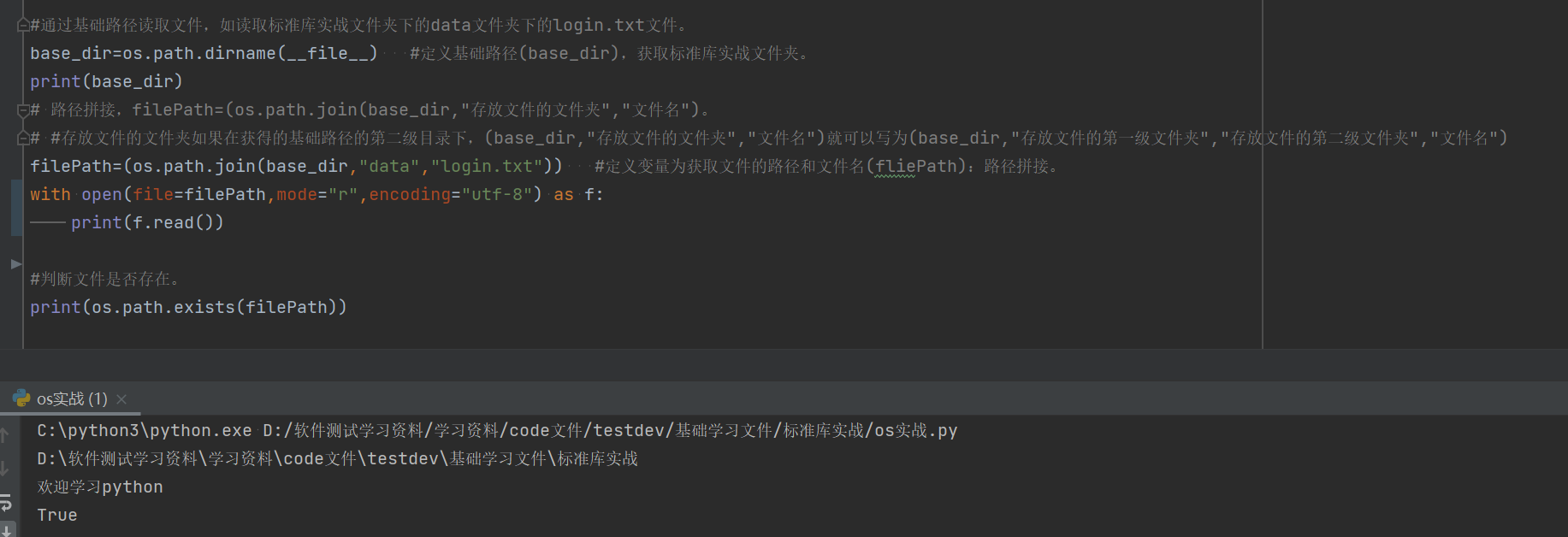
1.2time库:该模块提供各种与时间有关系的库
1.2.1获取时间戳
# #time:该模块提供各种与时间有关系的库。
import time #借用外部的库,需要先进行调用。
#获取时间戳
print(time.time())
1.2.2以字符串格式获取当前时间
# #time:该模块提供各种与时间有关系的库。
import time #借用外部的库,需要先进行调用。
#获取当前时间字符串格式,获取的是北京时间。
print(time.ctime())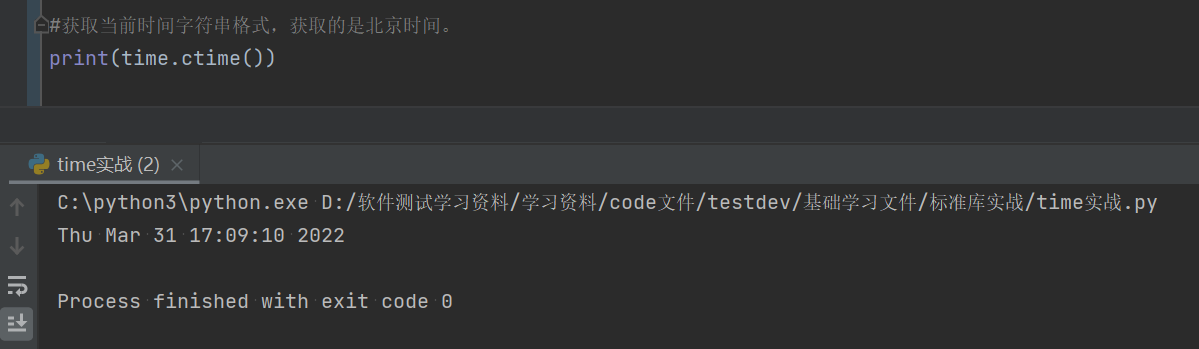
1.2.3程序休眠(秒)
# #time:该模块提供各种与时间有关系的库。
import time #借用外部的库,需要先进行调用。
#程序休眠,以秒为单位。
time.sleep(5)
print("休息好了么?")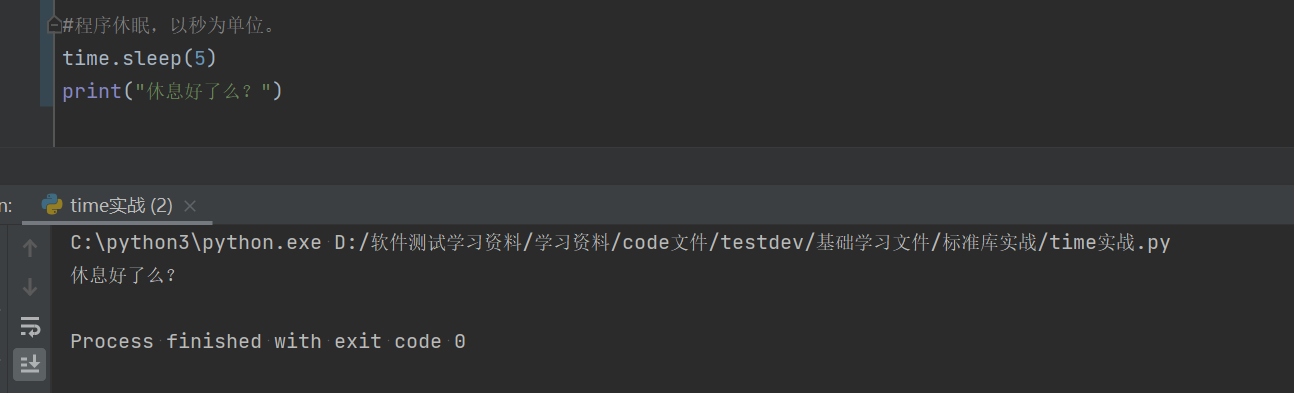
1.2.4时间戳转换为本地时间
# #time:该模块提供各种与时间有关系的库。
import time #借用外部的库,需要先进行调用。
#时间戳转换为本地时间
localTime=time.localtime(time.time())
print(localTime)
#时间戳转换为本地时间,然后通过字符串的格式化输出
print("年:{0},月:{1},日:{2}".format(localTime.tm_year,localTime.tm_mon,localTime.tm_yday))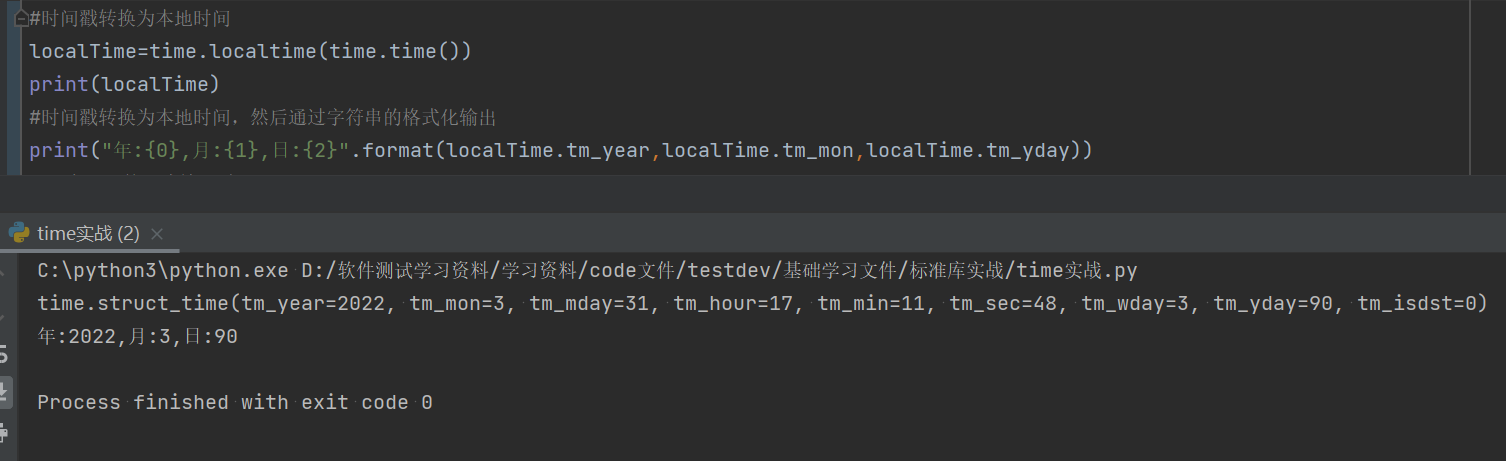
| 序号 | 属性 | 字段 | 值 |
| 0 | tm_year | 4位数年 | 如2022 |
| 1 | tm_mon | 月 | 1到12 |
| 2 | tm_mday | 日 | 1到31 |
| 3 | tm_hour | 小时 | 0到23 |
| 4 | tm_min | 分钟 | 0到59 |
| 5 | tm_sec | 秒 | 0到61 (60或61 是闰秒) |
| 6 | tm_wday | 一周的第几日 | 0到6(0是星期一) |
| 7 | tm_yday | 一年的第几日 | 0到366 |
1.2.5中国式输出时间
# #time:该模块提供各种与时间有关系的库。
import time #借用外部的库,需要先进行调用。
#中国人的方式输出时间
print(time.strftime("%y-%m-%d %H:%M:%S" ,time.localtime()))
print(time.strftime("%T %x",time.localtime()))
#strftime方法格式化输出时间的控制符。
# %y:两位数的年份表示(00 - 99)
# %Y:四位数的年份表示(000 - 9999)
# %m:月份(01 - 12)
# %d:月内中的一天(0 - 31)
# %H:24小时制小时数(0 - 23)
# %I:12小时制小时数(01 - 12)
# %M:分钟数(00 - 59)
# %S:秒(00 - 59)
# %a:本地简化星期名称
# %A:本地完整星期名称
# %b:本地简化的月份名称
# %B:本地完整的月份名称
# %c:本地相应的日期表示和时间表示
# %j:年内的一天(001 - 366)
# %p:本地A.M.或P.M.的等价符
# %U:一年中的星期数(00 - 53)星期天为星期的开始
# %w:星期(0 - 6),0为星期天,为星期的开始
# %W:一年中的星期数(00 - 53)星期一为星期的开始
# %x:本地相应的日期表示
# %X:本地相应的时间表示
# %T:本地相应时间的表示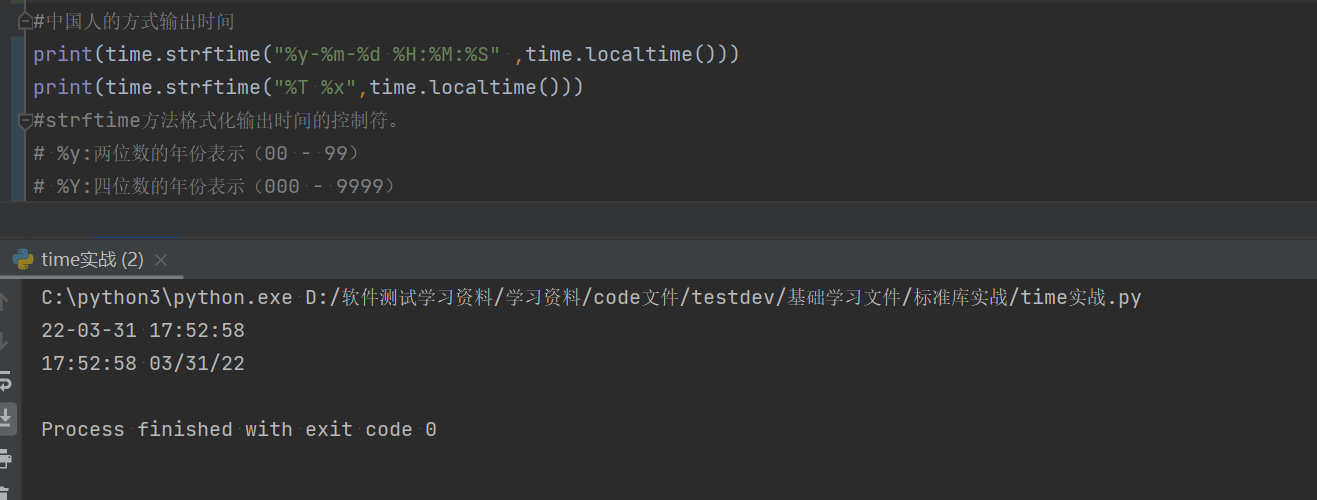
1.3datetime库: 该模块也是表达时间的,但是比time更加直观
1.3.1查询当前时间
import datetime #借用外部的库,需要先进行调用。
#查询当前时间
print(datetime.datetime.now()) #第一个datetime表示的是库,第二个datetime是类,now是方法。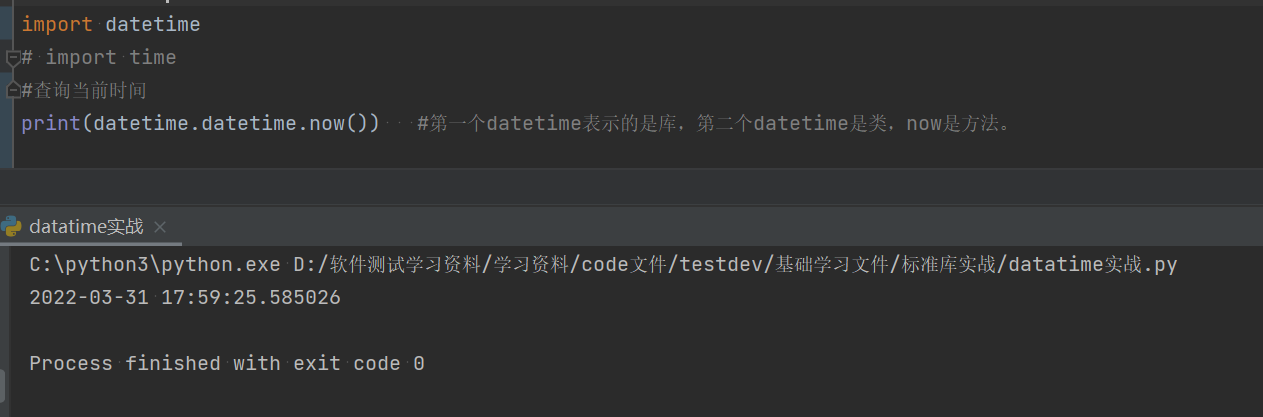
1.3.2在当前时间基础上增加或减少时间
import datetime #借用外部的库,需要先进行调用。
#在当前时间的基础上增加/减少天数、小时、分、秒,无法增加或减少年份。
#在当前时间的基础上增加5天
print(datetime.datetime.now()+datetime.timedelta(days=5))
#在当前时间的基础上增加3小时
print(datetime.datetime.now()+datetime.timedelta(hours=3))
#在当前时间的基础上增加10分钟
print(datetime.datetime.now()+datetime.timedelta(minutes=10))
#在当前时间的基础上增加59秒
print(datetime.datetime.now()+datetime.timedelta(seconds=59))
#在当前时间的基础上减少3天
print(datetime.datetime.now()+datetime.timedelta(days=-3))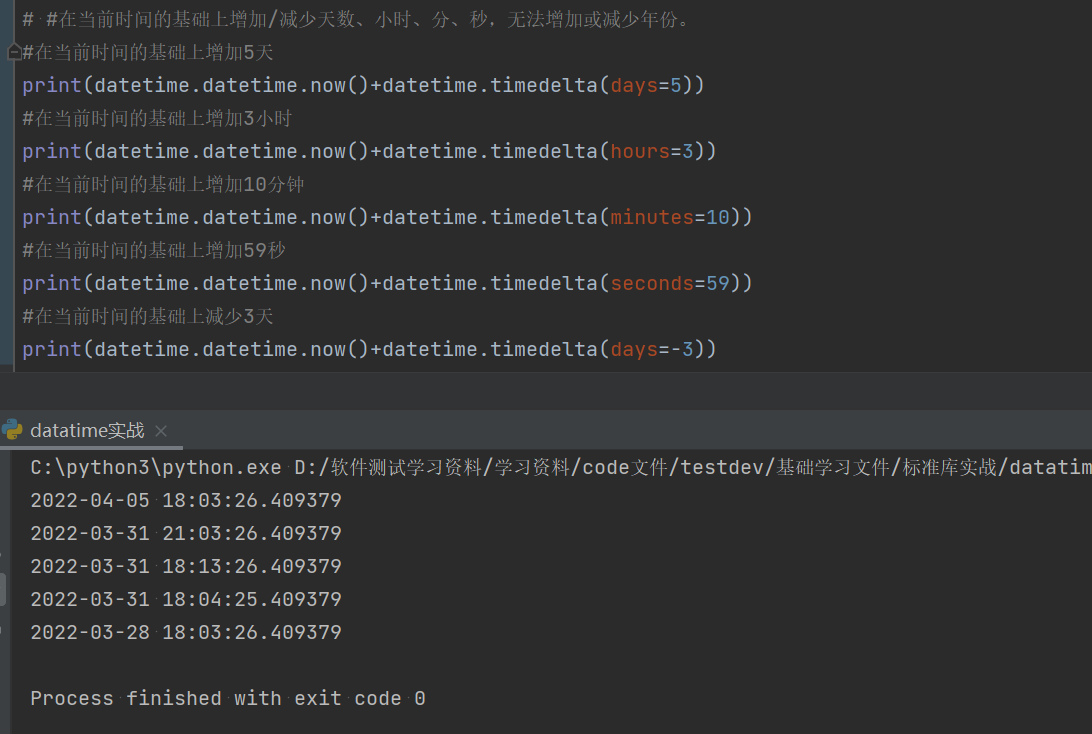
1.3.3时间戳转换为当前时间
import datetime #借用外部的库,需要先进行调用。
import time #借用外部的库,需要先进行调用。
#把时间戳转换为当前时间
print(datetime.datetime.fromtimestamp(time.time()))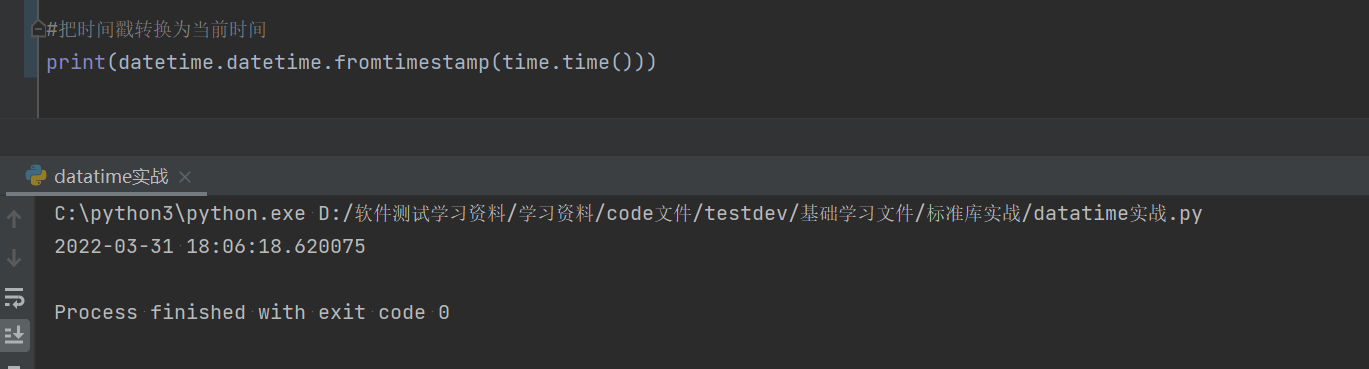 1.4hashlib:该模块是专门处理处理加密的
1.4hashlib:该模块是专门处理处理加密的
开放平台接口加密的步骤:
(1)对请求参数进行排序;
(2)排序之后处理成k=value&k=value的形式;
(3)进行md5的加密,生成密钥。
#开放平台接口加密的步骤:
import hashlib
from urllib import parse #urrlib是一个专门做网络爬虫的库,现在已经很少使用。
# parse方法可以用来将字典形式的请求参数处理成k=value&k=value的形式。
import time
#对内容进行md5的加密。
def sign():
dict1={"name":"qy","age":18,"sex":"girl","school":"xtu","time":time.time()}
#第一步:对请求参数根据key进行排序
dict2=dict(sorted(dict1.items(),key=lambda a:a[0]))
print(dict2)
#第二步:把请求参数处理成k=value&k=value的形式
dict2=parse.urlencode(dict2)
print(dict2)
#第三步:对请求参数进行md5的加密
m=hashlib.md5()
#第四步:把字符串的数据类型处理成bytes的数据类型,字符串转bytes数据类型通过编码和解码进行处理。
m.update(dict2.encode("utf-8"))
#第五步:返回加密后生成的密钥。
return m.hexdigest()
print(sign())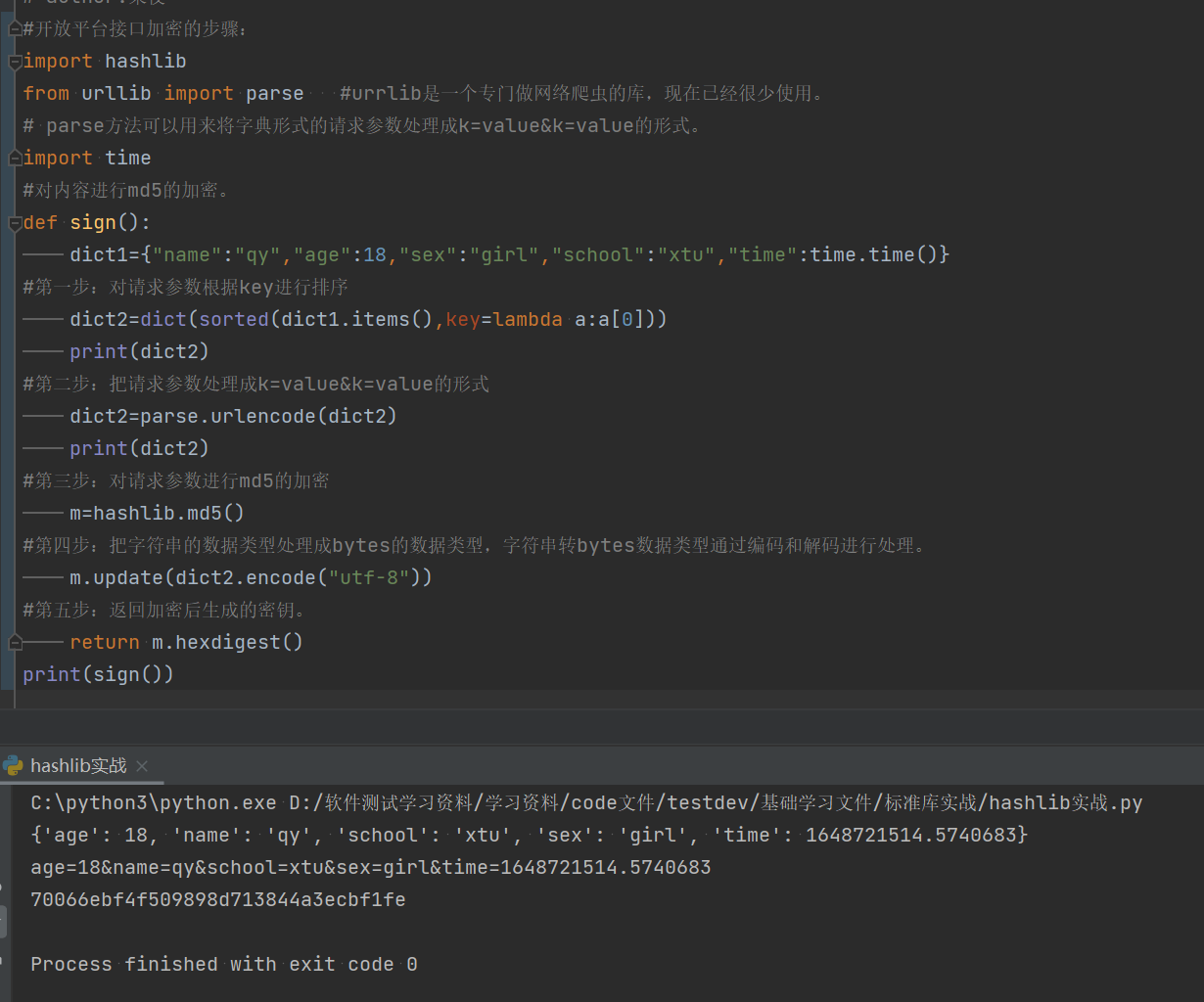
1.5json:该模块可以实现序列化与反序列化
(1)序列化:把内存里的数据类型转为字符串的数据类型,使能够存储到硬盘或通过网络传输到远程,因为硬盘或者网络传输时只接受bytes的数据类型。简单的说就是把Python的数据类型(字典,元组,列表)转为str的数据类型过程。
(2)反序列化,就是str的数据类型转为Python对象的过程。
1.5.1列表的序列化与反序列化
import json #借用外部的库,需要先进行调用。
#列表的序列化和反序列化,列表经过序列化和反序列化其数据类型不变。
#列表的序列化,用的关键字是dumps。
list1=["python","go","java"]
list_str=json.dumps(list1)
print(list_str)
print(type(list_str))
#列表的反序列化,用的关键字是loads。
str_list=json.loads(list_str)
print(str_list)
print(type(str_list))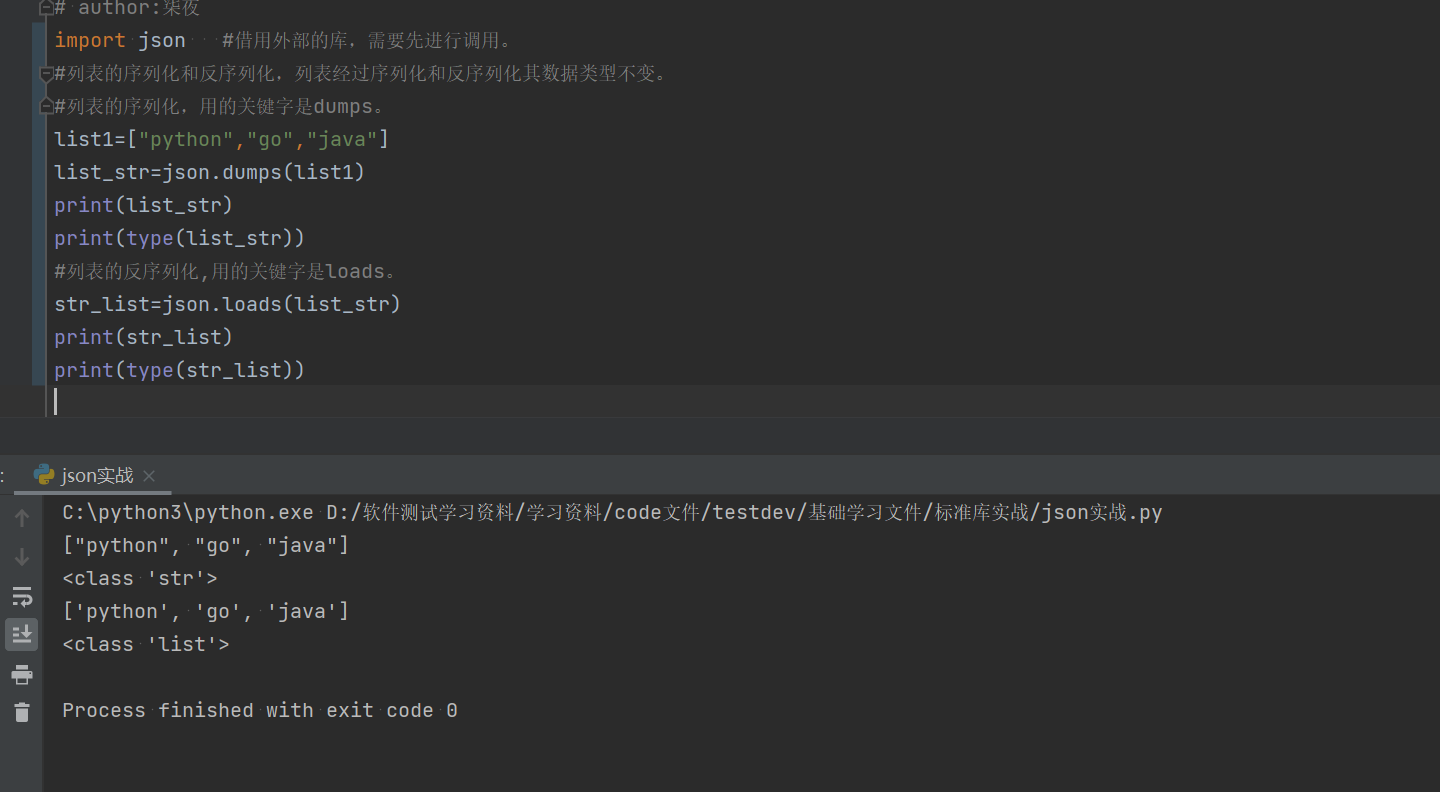
1.5.2元组的序列化与反序列化
import json #借用外部的库,需要先进行调用。
#元组的序列化与反序列化,元组经过序列化和反序列化后,其数据类型变为列表的类型了。
#元组的序列化,用的关键字是dumps。
tuple1=("python","go","java")
tuple_str=json.dumps(tuple1)
print(type(tuple_str))
print(tuple_str)
#元组的反序列化,用的关键字是loads。
str_tuple=json.loads(tuple_str)
print(type(str_tuple))
print(str_tuple)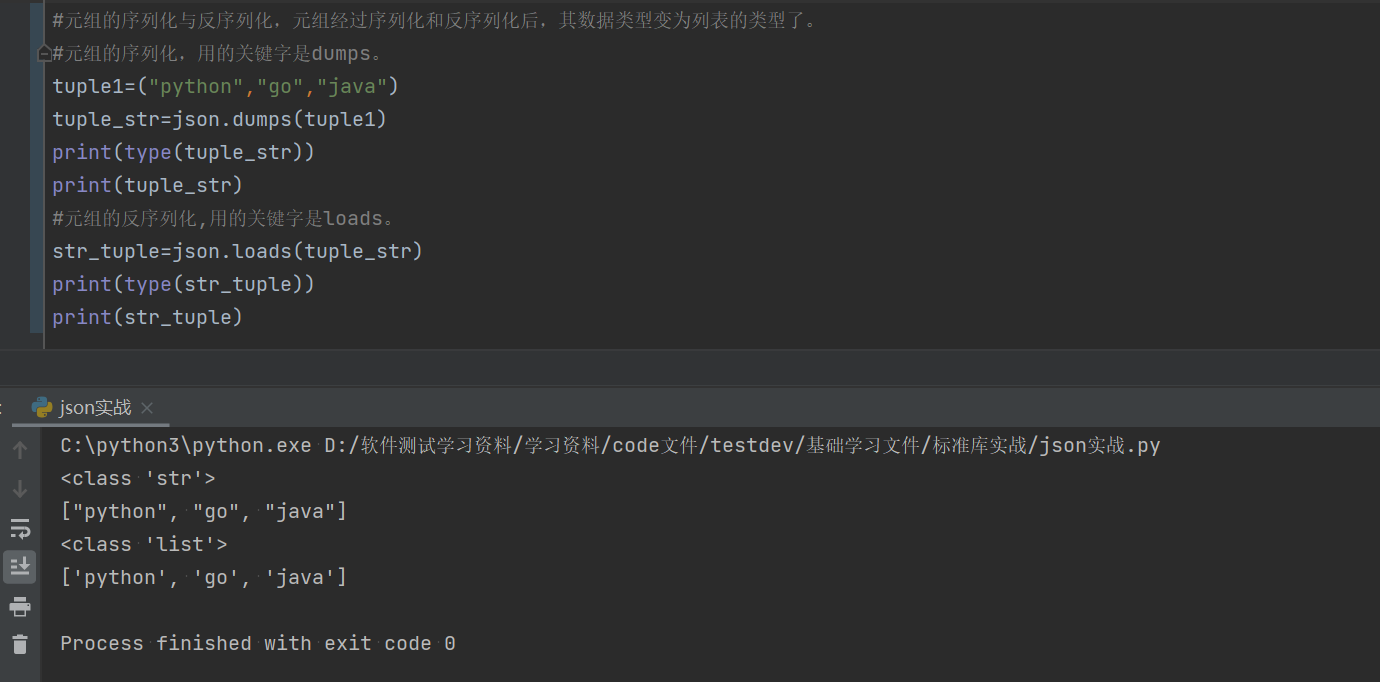 1.5.3字典的序列化与反序列化
1.5.3字典的序列化与反序列化
import json #借用外部的库,需要先进行调用。
#字典的序列化与反序列化,字典经过序列化和反序列化其数据类型不变。
#字典的序列化,用的关键字是dumps。
dict1={"python":1,"go":2,"java":3,}
dict_str=json.dumps(dict1)
print(type(dict_str))
print(dict_str)
#字典的反序列化,用的关键字是loads。
str_dict=json.loads(dict_str)
print(type(str_dict))
print(str_dict)
#字典的序列化,且使其结构化输出,并且处理中文
dict2={"python":"学习","go":2,"java":3,"dataS":[{"math":99,"chinese":95,"English":100},{"wl":80,"sw":97,"zz":86}]}
#indent=True:字符串结构化输出
#ensure_ascii=False:处理中文
print(json.dumps(dict2,indent=True,ensure_ascii=False)) 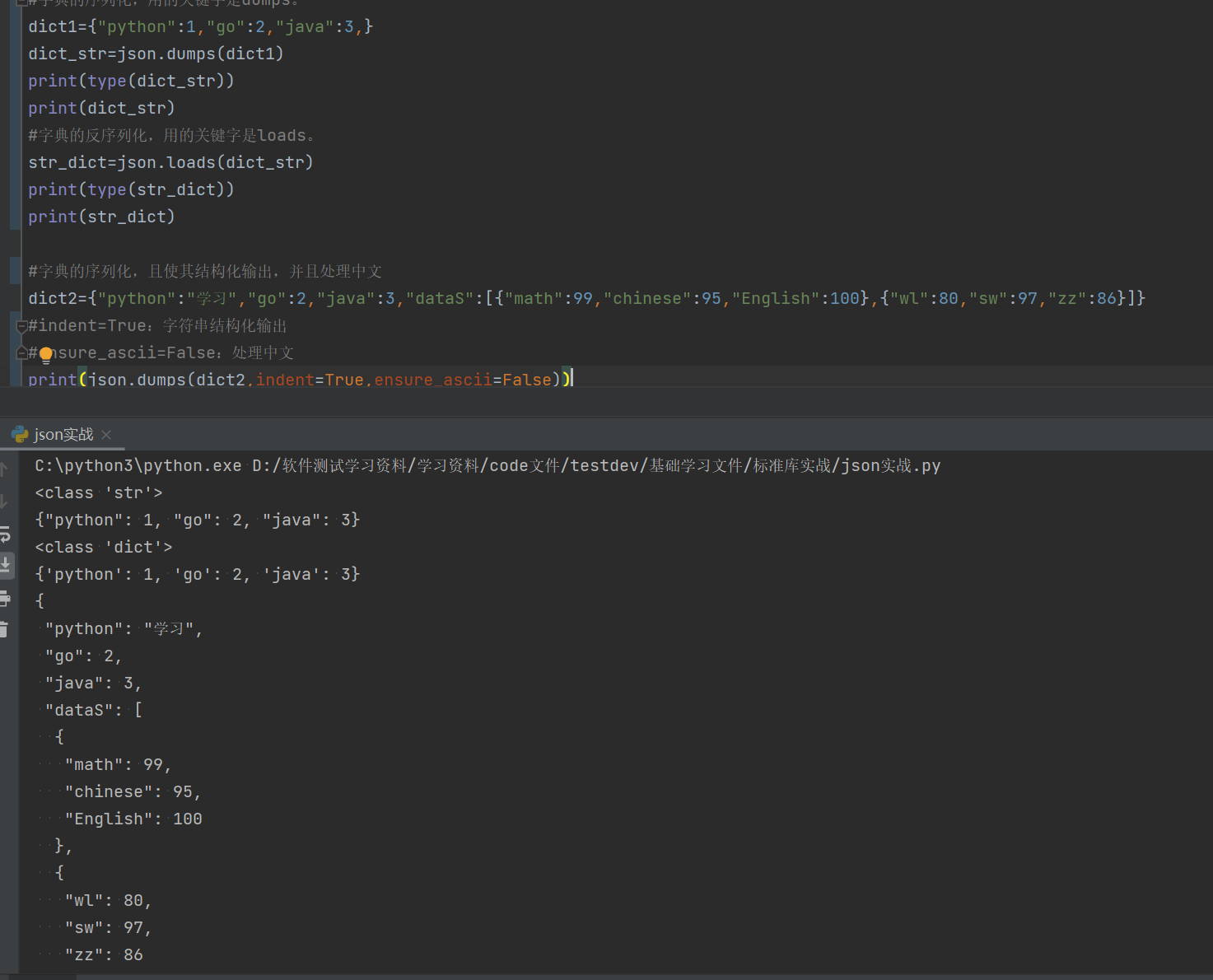
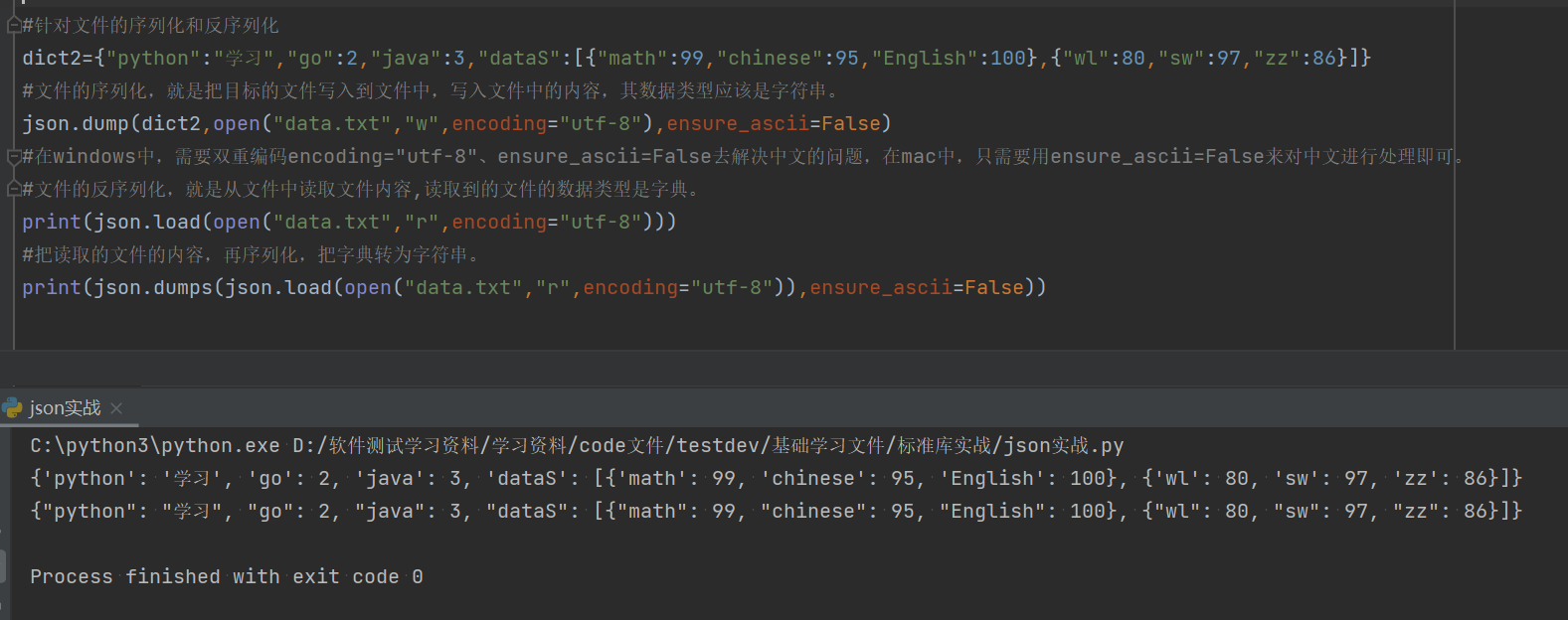
1.5.4文件的序列化与反序列化
import json #借用外部的库,需要先进行调用。
#针对文件的序列化和反序列化
dict2={"python":"学习","go":2,"java":3,"dataS":[{"math":99,"chinese":95,"English":100},{"wl":80,"sw":97,"zz":86}]}
#文件的序列化,就是把目标的文件写入到文件中,写入文件中的内容,其数据类型应该是字符串。
json.dump(dict2,open("data.txt","w",encoding="utf-8"),ensure_ascii=False)
#在windows中,需要双重编码encoding="utf-8"、ensure_ascii=False去解决中文的问题,在mac中,只需要用ensure_ascii=False来对中文进行处理即可。
#文件的反序列化,就是从文件中读取文件内容,读取到的文件的数据类型是字典。
print(json.load(open("data.txt","r",encoding="utf-8")))
#把读取的文件的内容,再序列化,把字典转为字符串。
print(json.dumps(json.load(open("data.txt","r",encoding="utf-8")),ensure_ascii=False))
2、第三方的库
安装方式如下:
(1)在线安装
pip3 install 库的名称:库的安装
pip3 uninstall 库的名称:库的卸载
pip3 install -u 库的名称:库的更新
(2)离线安装
安装的网站:https://pypi.org/project/
2.1常用的第三方的库
(1)selenium:UI测试框架
(2)Appium:移动UI测试框架
(3)requests:接口测试框架
(4)pymysql:操作mysql
(5)xlrd:操作excel文件
(6)Django:全栈WEB框架
(7)flask:轻量级WEB框架
(8)fast:异步WEB框架
(9)Pytest:单元测试框架
3、自定义的库
自己编写的python文件。
