python——字典
1、字典概述
1.1字典特性
(1)字典是无序的。
(2)字典是是以键值对的方式储存的,也就是以key:value的形式来储存的。
(3)字典的关键字是dict;
(4)字典的数据形式是{}。
1.2字典排序的规则
(1)如果是数字,默认是从小到大排序;
(2)如果是字符串,内部处理的思路是把字符串转为数字后再排序,和1的规则一样;
(3)如果是多个字符串,比如aa,ab,那么这个时候他的规则是:
A、aa和ab先比较第一个字符串,发现第一个相同,就比较第二个;
B、比较第二个,如果相同,依次如A的方法进行处理,当遇到不同的时候,就将字符串转为数字,然后在排序,规则与1相同。
(4)把字符串转为数字,使用的内部函数是sorted();
(5)字典排序使用到的内部函数是sorted();
(6)必须是相同的数据类型才能进行比较。
2、字典的方法
2.1查询字典的方法:dir
#字典example
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#查询字典的方法
print(dir(dict))
#字典的方法:'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'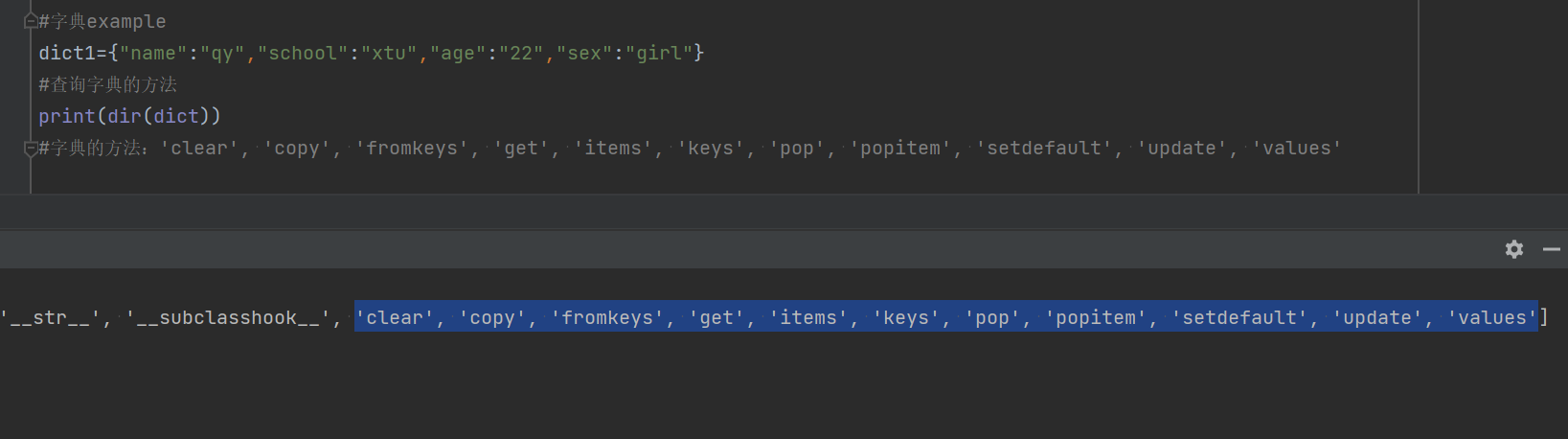
2.2输出字典中所有的key
2.2.1使用循环的方式实现(for)
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#通过循环的方式实现
for a in dict1.keys():
print(a)
2.2.2使用keys方法实现
keys:该方法是用来输出某个字典中的所有key值。
#获取所有字典的key
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#通过方法实现,关键字是keys。
print(dict1.keys())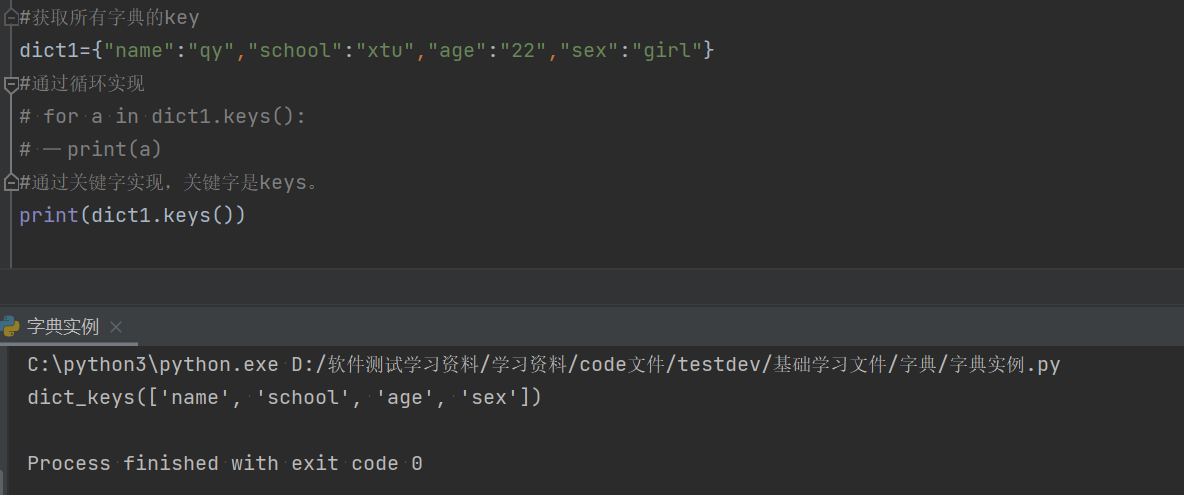
2.3输出字典中所有的value
2.3.1通过循环实现(for)
#获取所有字典的value,通过循环的方法实现
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
for item in dict1.values():
print(item)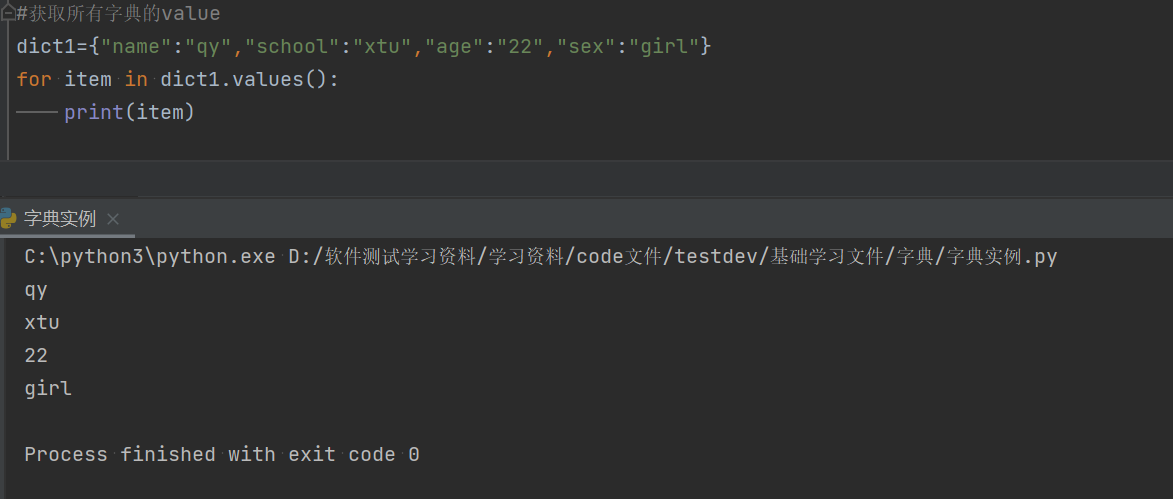
2.3.2通过values方法实现
values:该方法是用来输出某个字典中的所有value值。
#获取所有字典的value
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#通过方法实现,关键字是values。
print(dict1.values())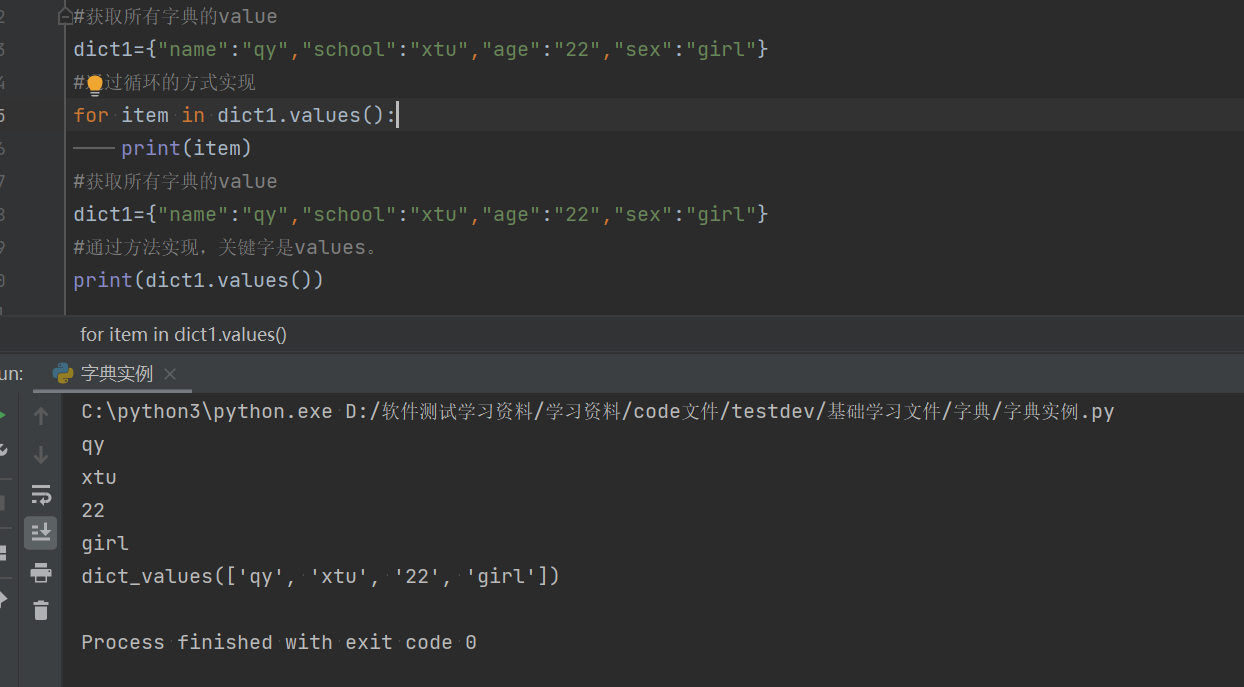
2.4输出字典中所有的键值:items
items:该方法是实现输出字典中的所有键值对,但是无法以k:value的形式输出。
#输出字典中所有的键值
#通过循环的方式实现
for key,value in dict1.items():
print(key,value) #循环输出字典中的key和value
#想要把输出的key和value以key:value的形式输出。
a=(key,value) #循环输出字典中的key和value,输出后的数据类型为元组类型,可以通过type关键字查看。
a_list=list(a) #把元组的数据类型转换为列表
a_list=[str(i) for i in a_list ] #把列表中的元素的数据类型转化为字符串类型
a_list_str=",".join(a_list) #把列表转化为字符串
b=a_list_str.replace(",",":") #通过replace方法把key和value中间的","替换为":"输出。
print(b)
#通过items方法实现。
print(dict1.items())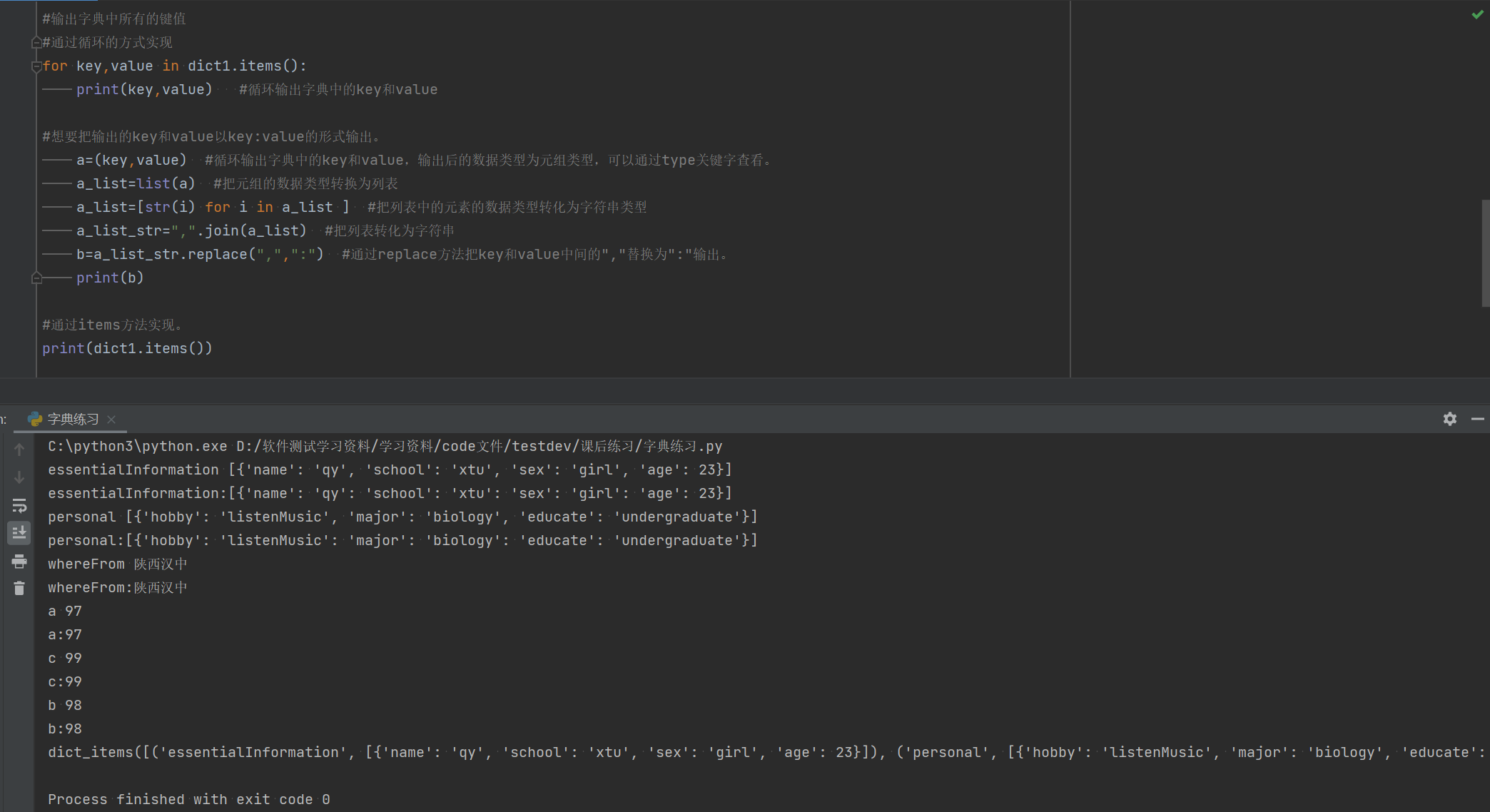
2.5获取字典中某个key的value值:get
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#获取字典中某个key的value值,用的关键字是get:
print(dict1.get("name"))
#或者不使用get,直接获取:
print(dict1["name"])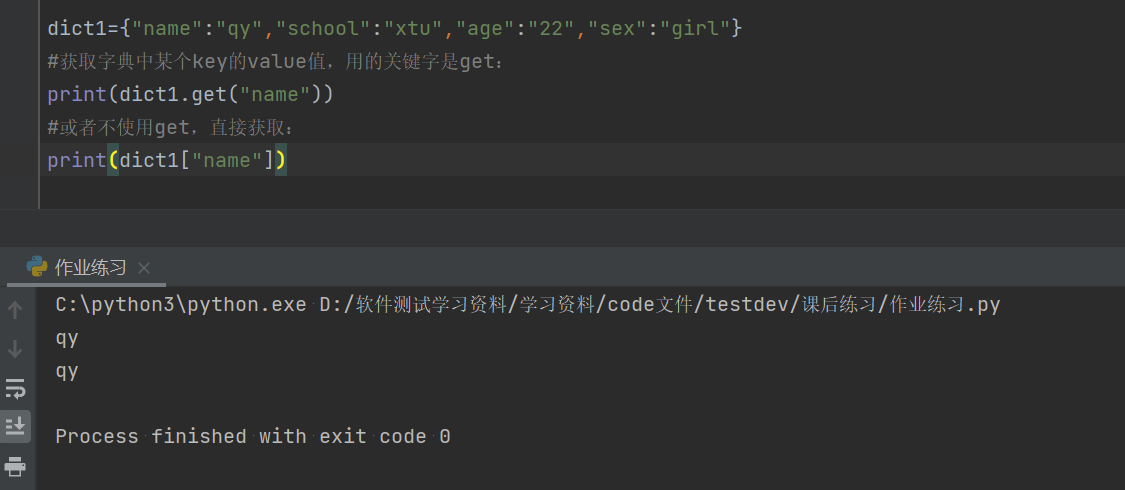
2.6字典的合并(添加):update
#两个字典的合并,就是把dict1的内容合并到dict中,也可以称为添加,关键字是update
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
dict2={"city":"xian"}
dict1.update(dict2)
print(dict1)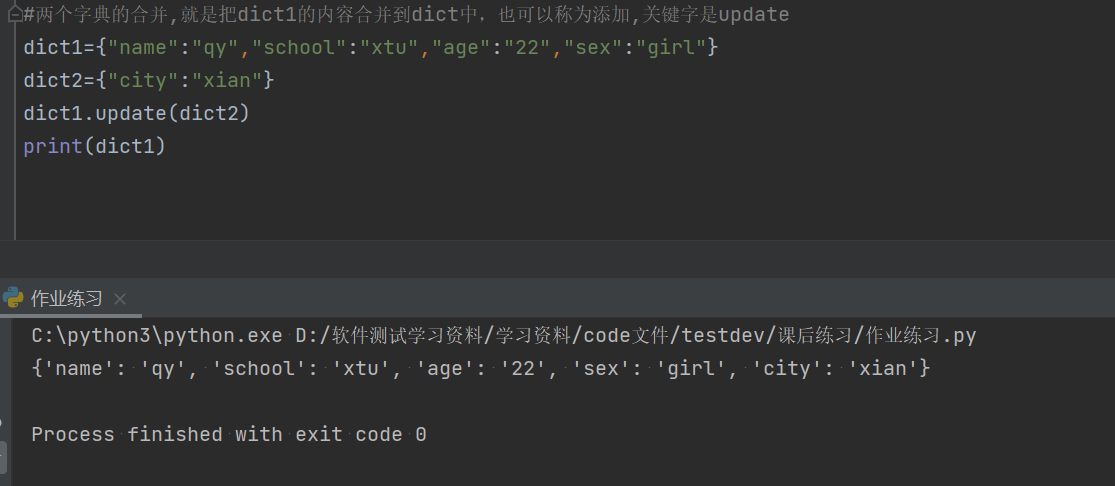
2.7字典的排序
2.7.1sorted方法
字典的排序规则如1.2所述。其排序可以以key进行排序,也可以value进行排序。
#字典的排序,可以以key进行排序,也可以value进行排序,排序的关键字是sorted。
dict1={"name":"qy","school":"xtu","age":"22","sex":"girl"}
#以key进行排序:首先需要输出字典中的所有键值,这是通过items实现的,然后进行排序。
print(dict(sorted(dict1.items(),key=lambda a:a[0])))
#dict()是将输出的数据类型强制转换为字典类型;
#dict1.items()是输出dict1的所有键值;
#key=lambda固定格式;
#item:item[0]是以key进行排序,其中的item是可以自定义的变量,0表示列表中key的索引,那么value的索引就是1。那么以value进行排序:
print(dict(sorted(dict1.items(),key=lambda b:b[1])))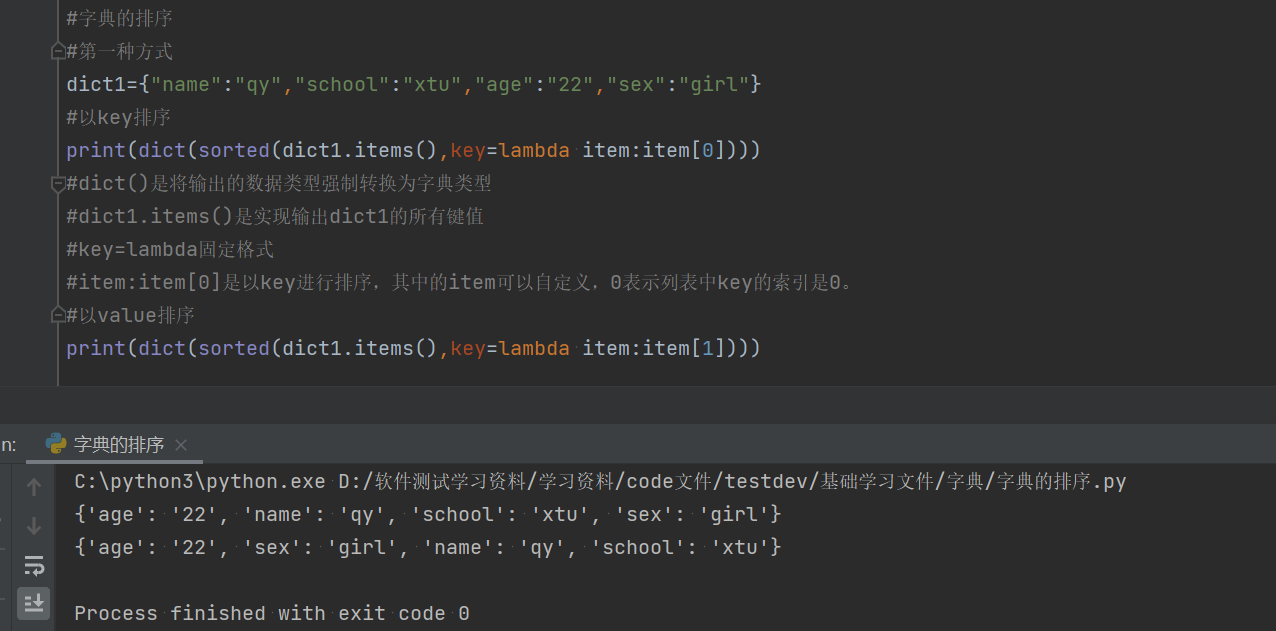
2.7.2OrderedDict()方法
这种方式,只能在新添加字典时使其有序,但无法对已存在的字典进行排序。
#第二种方式,只能在新添加字典时使其有序,但是无法对已存在的字典进行排序,使用的关键字是OrderedDict()
from collections import OrderedDict
dict1=OrderedDict()
dict1["name"]="qy"
dict1["sex"]="girl"
dict1["school"]="xtu"
dict1["age"]="22"
print(dict(dict1))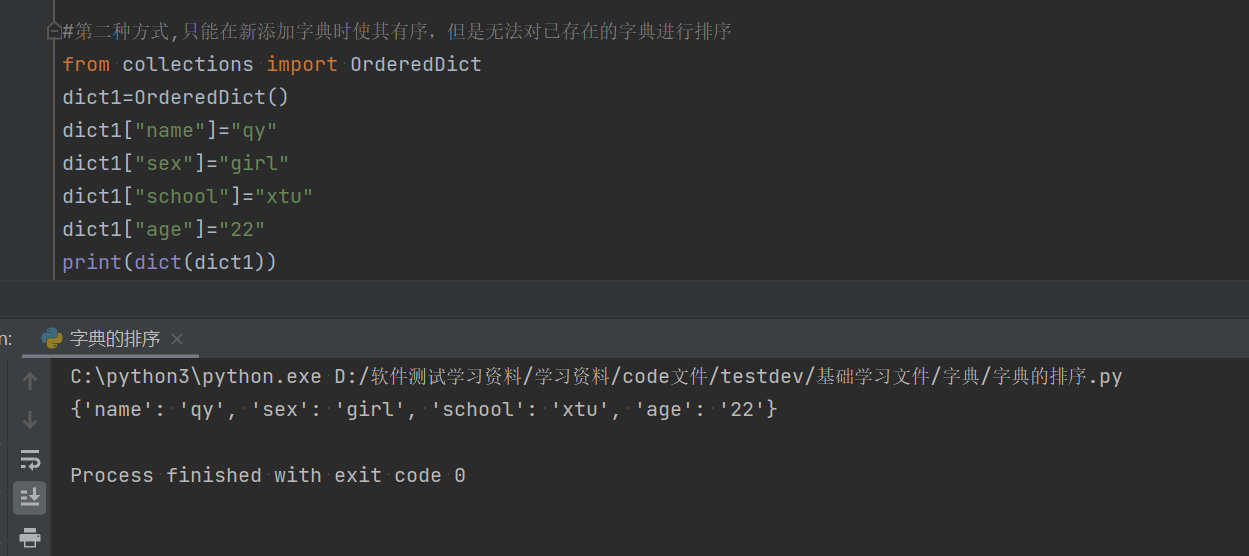
2.8复杂字典结构的输出
2.8.1多数据的输出实例1
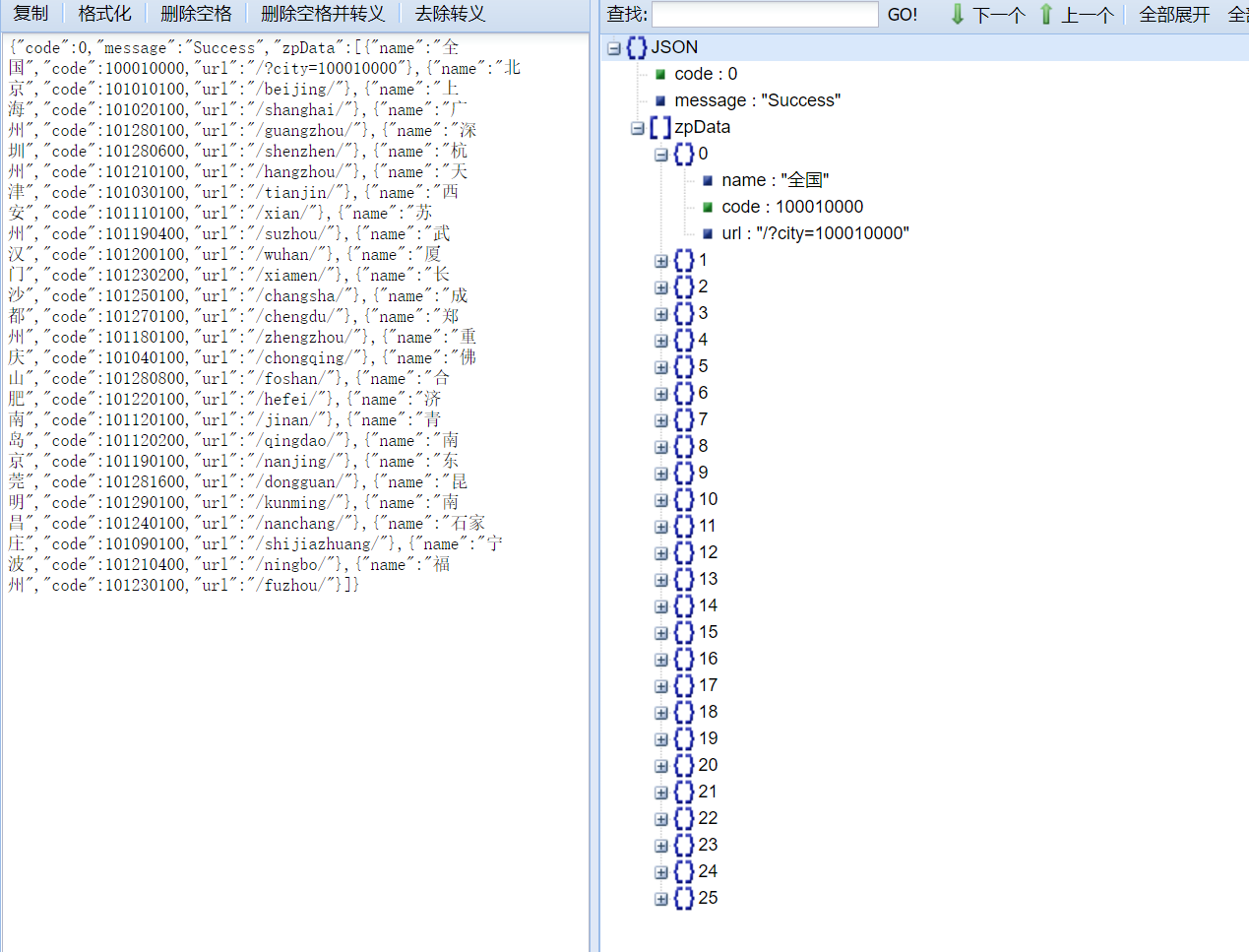
数据如下:
#输出地区的信息,输出的方式为列表:
yl={"code":0,"message":"Success","zpData":[{"name":"全国","code":100010000,"url":"/?city=100010000"},{"name":"北京","code":101010100,"url":"/beijing/"},{"name":"上海","code":101020100,"url":"/shanghai/"},{"name":"广州","code":101280100,"url":"/guangzhou/"},{"name":"深圳","code":101280600,"url":"/shenzhen/"},{"name":"杭州","code":101210100,"url":"/hangzhou/"},{"name":"天津","code":101030100,"url":"/tianjin/"},{"name":"西安","code":101110100,"url":"/xian/"},{"name":"苏州","code":101190400,"url":"/suzhou/"},{"name":"武汉","code":101200100,"url":"/wuhan/"},{"name":"厦门","code":101230200,"url":"/xiamen/"},{"name":"长沙","code":101250100,"url":"/changsha/"},{"name":"成都","code":101270100,"url":"/chengdu/"},{"name":"郑州","code":101180100,"url":"/zhengzhou/"},{"name":"重庆","code":101040100,"url":"/chongqing/"},{"name":"佛山","code":101280800,"url":"/foshan/"},{"name":"合肥","code":101220100,"url":"/hefei/"},{"name":"济南","code":101120100,"url":"/jinan/"},{"name":"青岛","code":101120200,"url":"/qingdao/"},{"name":"南京","code":101190100,"url":"/nanjing/"},{"name":"东莞","code":101281600,"url":"/dongguan/"},{"name":"昆明","code":101290100,"url":"/kunming/"},{"name":"南昌","code":101240100,"url":"/nanchang/"},{"name":"石家庄","code":101090100,"url":"/shijiazhuang/"},{"name":"宁波","code":101210400,"url":"/ningbo/"},{"name":"福州","code":101230100,"url":"/fuzhou/"}]}
#新定义一个列表
list1=[]
#利用循环获取yl中zpData的所有数据赋给a
for a in yl["zpData"]:
#通过循环将a中的“name”的值不断增加到列表list1中,增加的关键字是append
list1.append(a["name"])
print(list1)
#输出除全国以外的所有地区的拼音,以列表的方式输出:
#输出地区的信息,输出的方式为列表:
yl={"code":0,"message":"Success","zpData":[{"name":"全国","code":100010000,"url":"/?city=100010000"},{"name":"北京","code":101010100,"url":"/beijing/"},{"name":"上海","code":101020100,"url":"/shanghai/"},{"name":"广州","code":101280100,"url":"/guangzhou/"},{"name":"深圳","code":101280600,"url":"/shenzhen/"},{"name":"杭州","code":101210100,"url":"/hangzhou/"},{"name":"天津","code":101030100,"url":"/tianjin/"},{"name":"西安","code":101110100,"url":"/xian/"},{"name":"苏州","code":101190400,"url":"/suzhou/"},{"name":"武汉","code":101200100,"url":"/wuhan/"},{"name":"厦门","code":101230200,"url":"/xiamen/"},{"name":"长沙","code":101250100,"url":"/changsha/"},{"name":"成都","code":101270100,"url":"/chengdu/"},{"name":"郑州","code":101180100,"url":"/zhengzhou/"},{"name":"重庆","code":101040100,"url":"/chongqing/"},{"name":"佛山","code":101280800,"url":"/foshan/"},{"name":"合肥","code":101220100,"url":"/hefei/"},{"name":"济南","code":101120100,"url":"/jinan/"},{"name":"青岛","code":101120200,"url":"/qingdao/"},{"name":"南京","code":101190100,"url":"/nanjing/"},{"name":"东莞","code":101281600,"url":"/dongguan/"},{"name":"昆明","code":101290100,"url":"/kunming/"},{"name":"南昌","code":101240100,"url":"/nanchang/"},{"name":"石家庄","code":101090100,"url":"/shijiazhuang/"},{"name":"宁波","code":101210400,"url":"/ningbo/"},{"name":"福州","code":101230100,"url":"/fuzhou/"}]}
#新定义一个列表
list1=[]
for a in yl["zpData"]:
#判断name不是全国
if a["name"]!="全国":
#通过循环将a中的“name”的值不断增加到列表list1中,增加的关键字是append,并将拼音的"/"用”“替换,用的关键字为replace。
list1.append(a["url"].replace("/",""))
print(list1)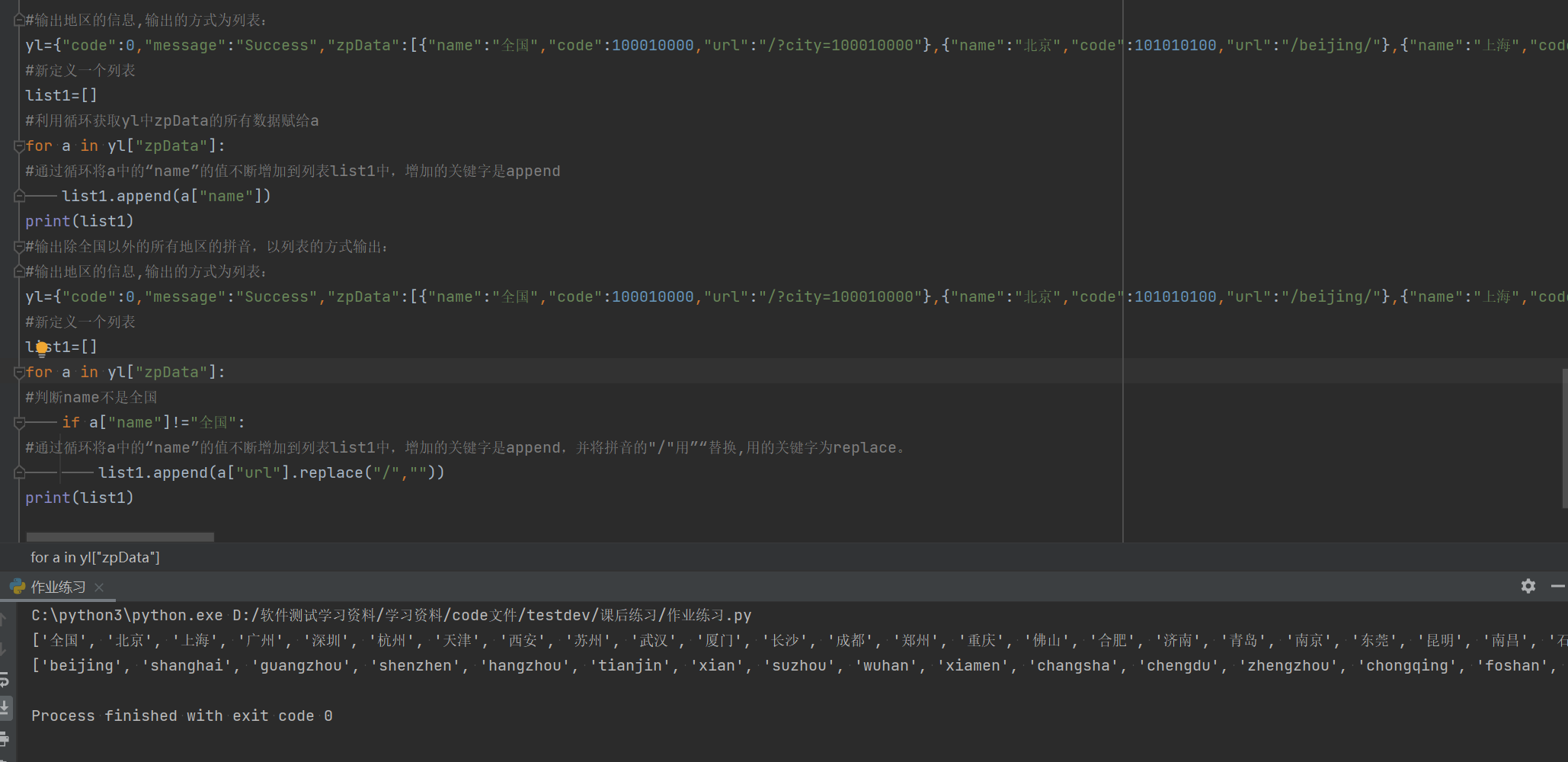
2.8.2实例2
dict1={"status":0,"msg":"ok","datas":
[
{"company":"华为","职位":"测试开发工程师"},
{"company":"腾讯云","职位":"Go开发工程师"},
{"company":"易点天下","职位":"Java开发工程师"}
]}
#输出测试开发工程师和易点天下:
print(dict1["datas"][0]["职位"])
print(dict1["datas"][2]["company"])
print(dict1["datas"][0]["职位"],dict1["datas"][2]["company"])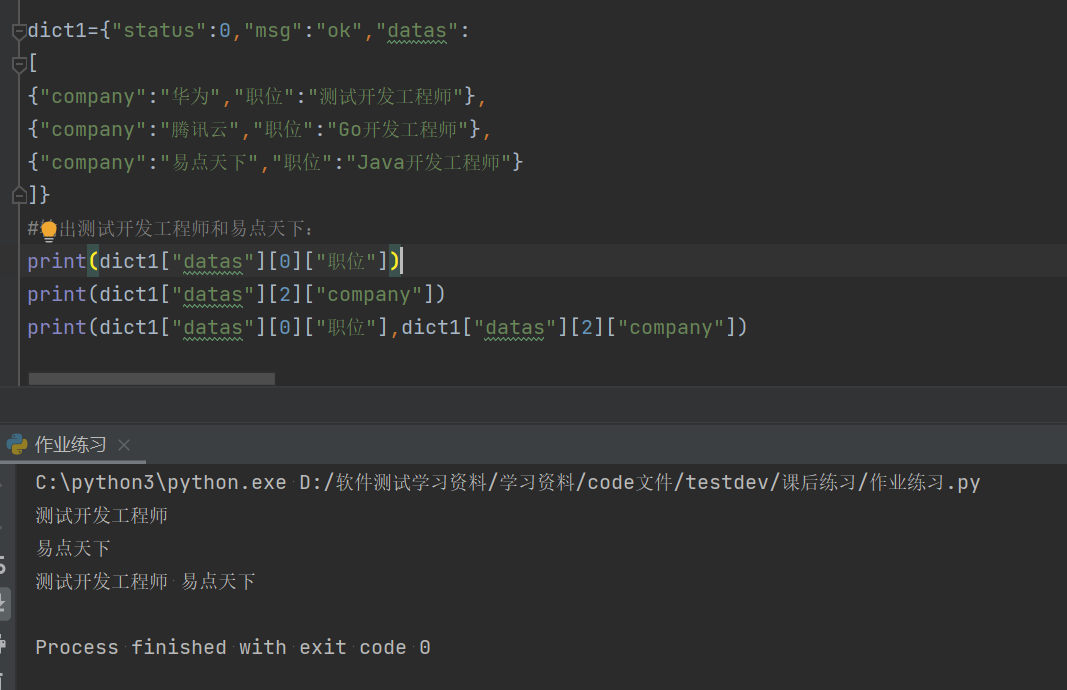
3、数据类型的转换
3.1字符串与列表的转换
3.1.1字符串转列表:split
#字符串与列表的转化
yl="qy,go,java,python"
#字符串转列表,用到的关键字是split,(",")是为了保证列表的格式为["a","b"]的形式,”“中的内容根据定义的字符串对象间的符号定义,一般都是逗号
a=yl.split(",")
print(a)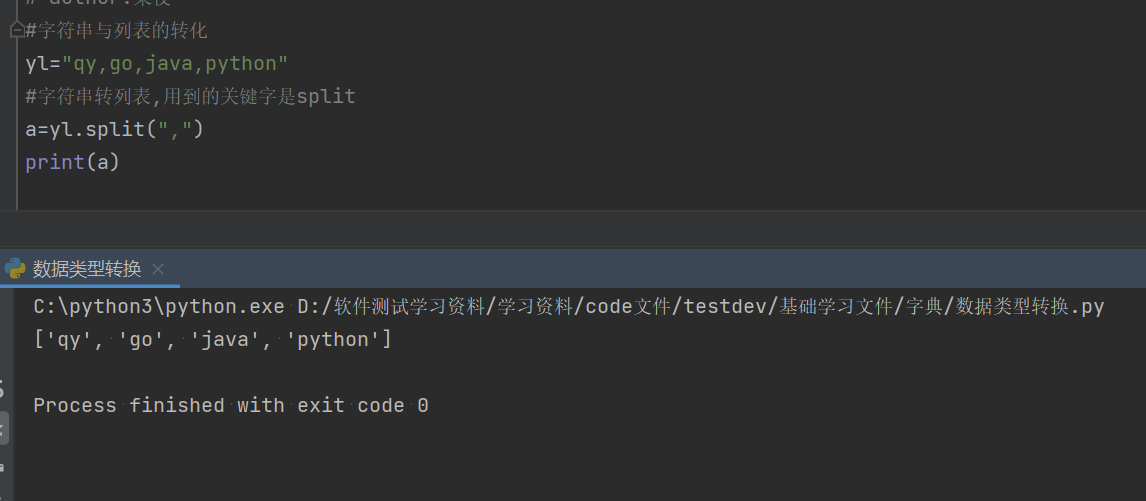
3.1.2列表转化为字符串:join
3.1.2.1当列表中的元素的数据类型为字符串
#列表转字符串,用的关键字是join,","是必须要有的,”“中的内容根据定义的字符串对象间的符号定义,一般都是逗号。
#当列表中的元素类型为字符串时,列表转字符串
a=['qy', 'go', 'java', 'python']
# zl=",".join(a)
# print(zl)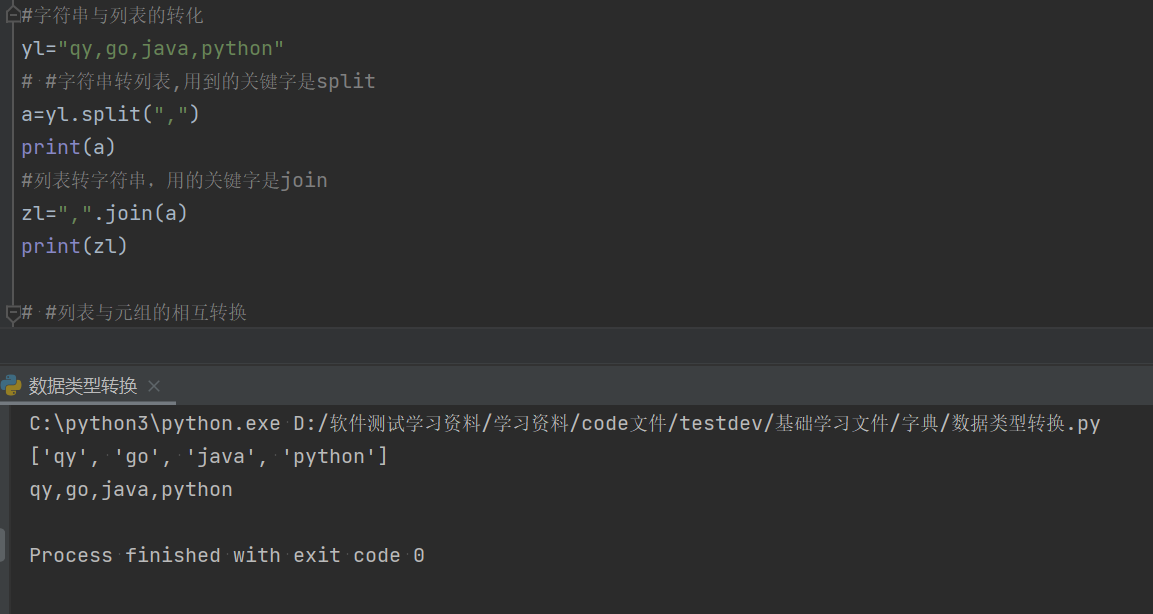
3.1.2.2当列表中的元素的数据类型不为字符串
#第一种方法:通过循环解决
a=[1,2,3,4,5,6]
list1=[]
for b in a:
c=str(b)
list1.append(c)
str1=",".join(list1)
print(str1)
#第二种方法,通过列表推导式解决
list1=[str(b) for b in a] #把列表中元素的类型转换为字符串类型
str1=",".join(list1)
print(str1)
#第三种方法,通过内部函数map解决,map我们在函数中会讲到,这里就不再赘述。
list1=map(str,a) ##把列表中元素的类型转换为字符串类型
str1=",".join(list1)
print(str1)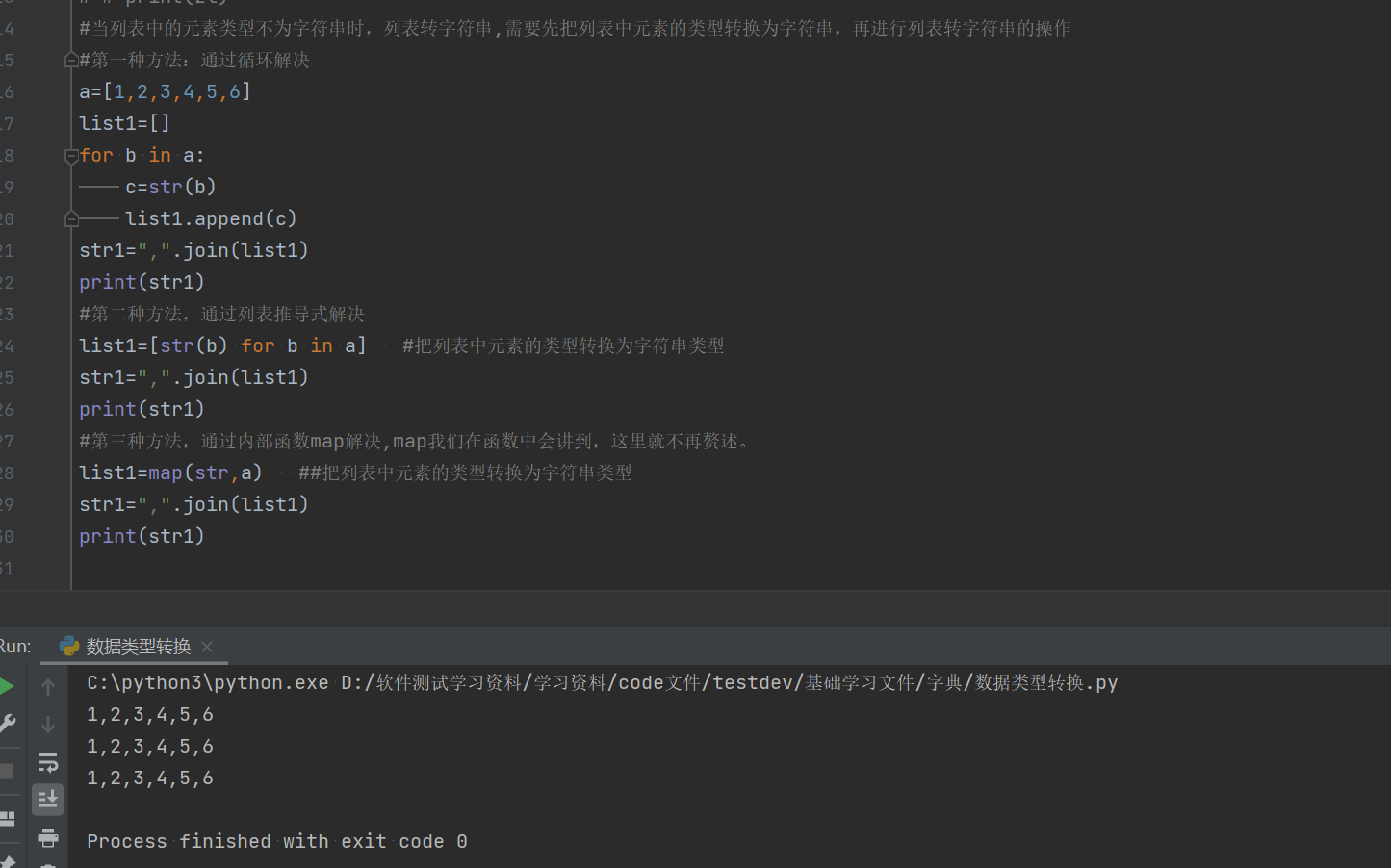
3.2列表与元组的转换
3.2.1元组转列表:list
#列表与元组的相互转换
x={1,2,3}
#元组转列表,他的关键字是list
list1=list(x)
print(list1)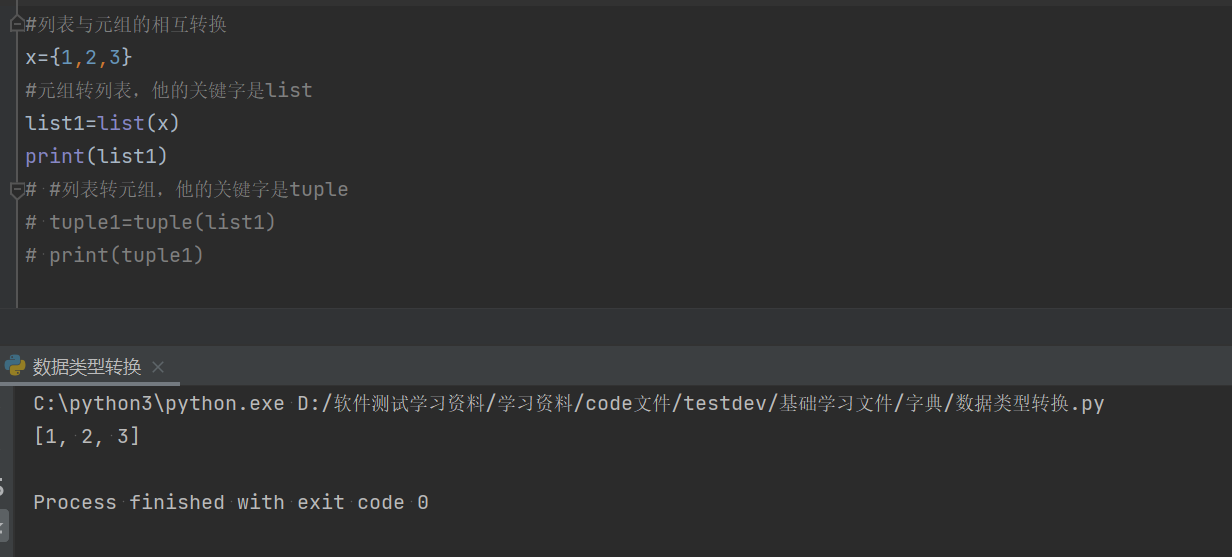
3.2.2列表转元组:tuple
#列表与元组的相互转换
x={1,2,3}
#元组转列表,他的关键字是list
list1=list(x)
print(list1)
#列表转元组,他的关键字是tuple
tuple1=tuple(list1)
print(tuple1)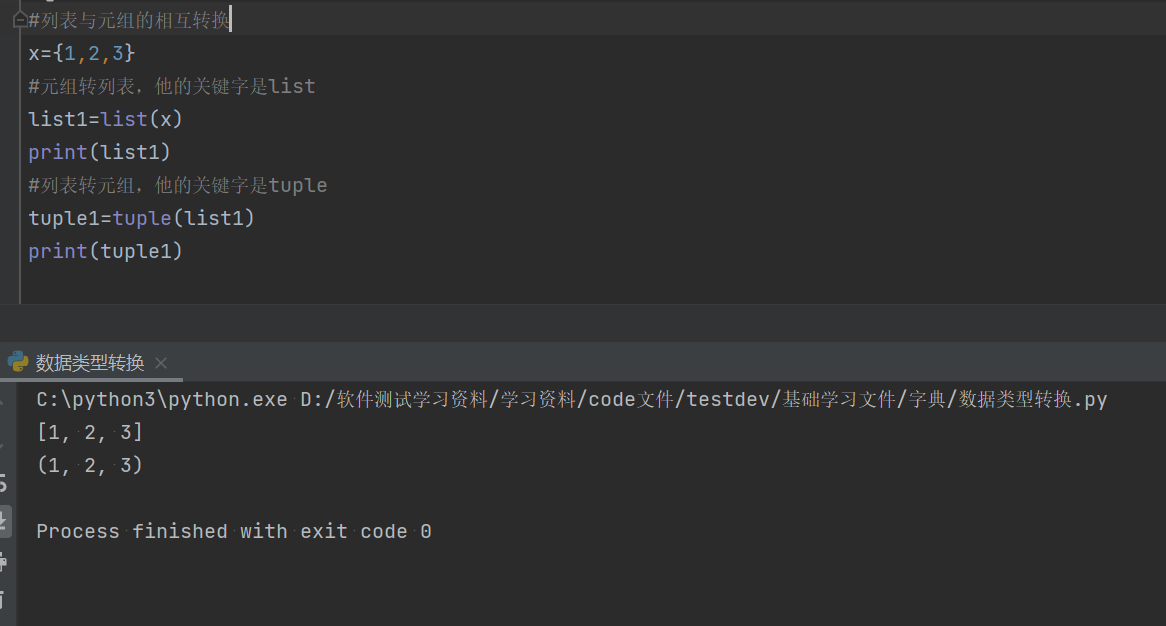
3.3整形与字符串的转换
3.3.1整形转字符串:str
#整型与字符串的转换
age=18
#整型转为字符串,他用的关键字是str
str1=str(age)
print(str1)
print(type(str1))3.3.2字符串转整形:int
#整型与字符串的转换
age=18
#整型转为字符串,他用的关键字是str
str1=str(age)
print(str1)
print(type(str1))
#字符串转为整形,他用的关键字是int
int1=int(str1)
print(int1)
print(type(int1))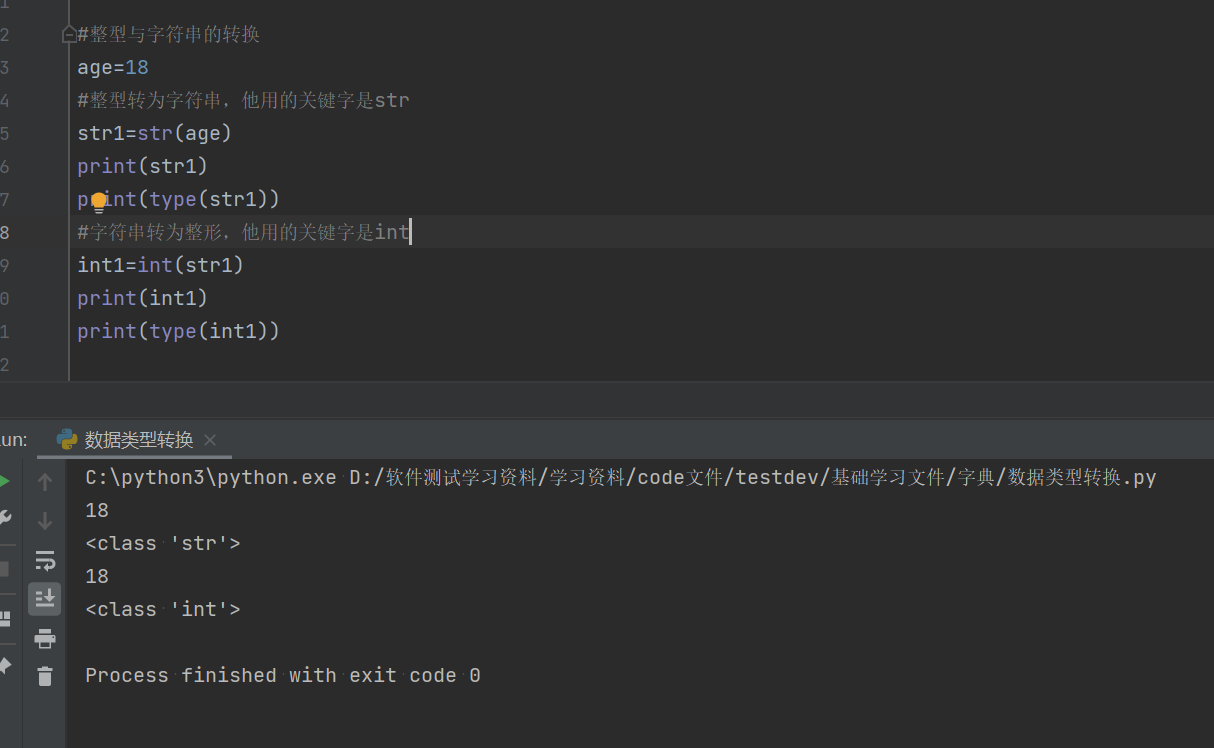
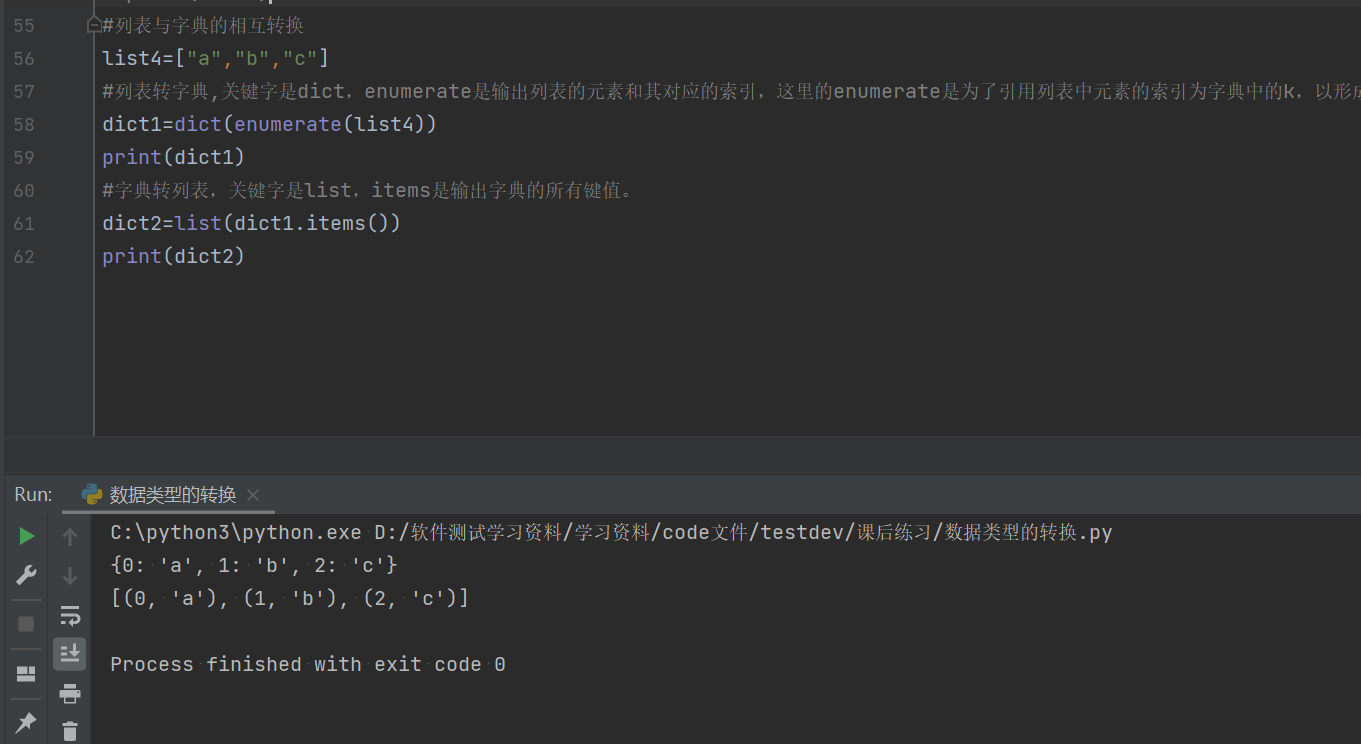
3.4列表与字典的转换
3.4.1列表转为字典:dict
#列表与字典的相互转换
list4=["a","b","c"]
#列表转字典,关键字是dict,enumerate是输出列表的元素和其对应的索引,这里的enumerate是为了引用列表中元素的索引为字典中的k,以形成字典的键值形式。
dict1=dict(enumerate(list4))
print(dict1)3.4.2字典转为列表:list
#列表与字典的相互转换
list4=["a","b","c"]
#列表转字典,关键字是dict,enumerate是输出列表的元素和其对应的索引,这里的enumerate是为了引用列表中元素的索引为字典中的k,以形成字典的键值形式。
dict1=dict(enumerate(list4))
print(dict1)
#字典转列表,关键字是list,items是输出字典的所有键值。
dict2=list(dict1.items())
print(dict2)