SQL语句之select
1、数据库导入
场景:开发给测试一个SQL脚本和一个SQL语句命令,SQL脚本中的数据都已经写好,测试只用进行导入操作即可。
测试导入外部数据(SQL脚本)到数据库的步骤:打开控制台,先进入要导入的sql脚本的目录下,然后执行SQL语句命令:mysql -u root -p <employees.sql

2、数据查询
2.1所有字段限量查询
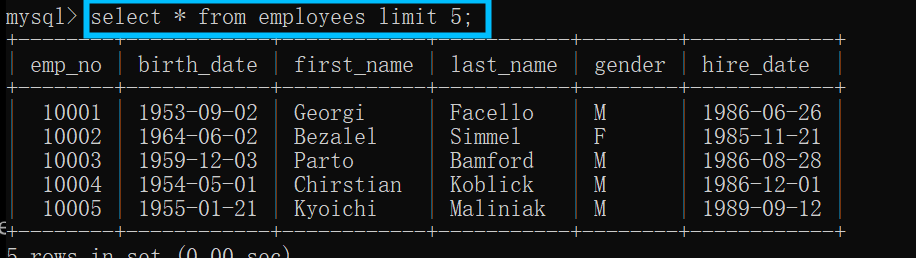
employees:表示查询的表的名称;
limit 5:表示想要查询前5条数据;
2.2部分字段的限量查询
当一个表中有很多条数据,但我们只想查询表中的前n条数据的某些字段的内容,用的命令为:select first_name,gender from employees limit n;

first_name,gender:表示想要查询的字段;
2.3查询表中数据的条数
查询表中的数据的条数用的命令为:select count(*) from employees;或者用命令:select count(1) from employees;
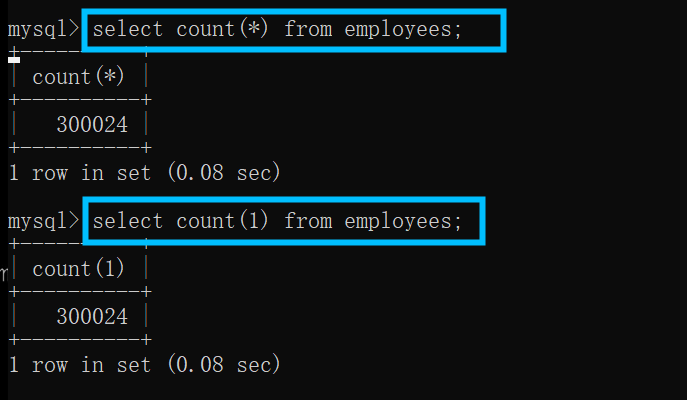
count(*)/count(1):表示总数的意思;
查询表中某个字段的数据的条数使用的命令为:select count(emp_no) from salaries;

ount(emp_no) :表示查看emp_no的数据的总数;
2.4并且查询:and
当我们需要在一个有很多条数据的表中查询到同时满足某些条件的数据时,我们使用的命令为:
select * from employees where first_name="Georgi" and gender="M"and hire_date="1989-01-31";

where:定位词,表示查询的数据定位到哪里;
first_name="Georgi" and gender="M"and hire_date="1989-01-31":查询的条件语句,表示查询同时满足这三个条件的结果;
a and b:表示需要同时满足a和b;
2.5或者查询:or
当我们需要在一个有很多条数据的表中查询到满足其中部分条件的数据时,我们使用的命令为:
select * from employees where first_name="Georgi" and last_name="Ariola"or hire_date="1989-01-31"limit 10;
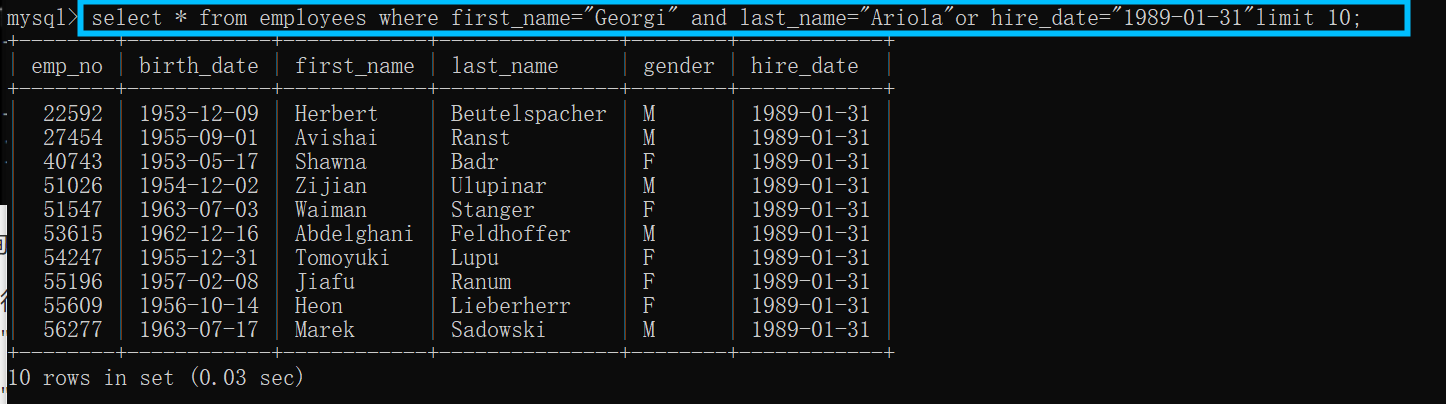
first_name="Georgi" and last_name="Ariola"or hire_date="1989-01-31":查询的条件语句,表示需要满足first_name="Georgi" 并且 last_name="Ariola"或者hire_date="1989-01-31";
a or b:表示需要满足a或者b任意一个;
2.6包含查询:in
当我们需要在一个有很多条数据的表中查询到包含某个或某些条件的数据时,我们使用的命令为: select * from employees where first_name in("herbert") limit 10;

first_name in("herbert"):表示查询first_name中包含herbert的数据;
in(x):表示包含x内容;
2.7范围查询:between and
当我们需要在一个有很多条数据的表中筛选某个字段的范围,这个范围包含头与尾,使用的命令为:
select * from employees where hire_date between "1989-07-22" and "1990-12-28";

hire_date between "1989-07-22" and "1990-12-28":表示查询hire_date的范围在1989-07-22(包括)到1990-12-28(包括)的数据;
between a and b:表示范围在a和b之间,包括a和b;
2.8否定查询:not
当我们需要在一个有很多条数据的表中查询某些字段不包含某个条件(范围)的数据时,用的命令为:
select * from employees where first_name not in("herbert") limit 10;
select * from employees where hire_date not between "1989-07-22" and "1990-12-28"limit 5;

first_name not in("herbert"):表示查询first_name中不包含herbert的数据;
hire_date not between "1989-07-22" and "1990-12-28":表示查询hire_date的范围不在1989-07-22(包括)到1990-12-28(包括)的数据;
not in(a):表示不包含a/not between a and b:表示范围不在a(包括)和b(包括)之间;
2.9模糊查询:%匹配任意字符
当一个表中有很多条数据,我们想要查询包含某些关键词的数据,但是关键词我们又记忆不清时,使用的命令为:
select * from employees where first_name like "h%" limit 10; 在h后面匹配任意字符
select * from employees where first_name like "%s%" limit 10; 在s前后匹配任意字符

如当匹配的关键字后/前为er时,使用的命令为:
select * from employees where first_name like "%er" limit 10; 关键字后面为er
select * from employees where first_name like "er%" limit 10; 关键字前面为er

2.10模糊查询:_代表一个字符串
当一个表中有很多条数据,我们想要查询包含某些关键词的数据,但是关键词中有几个字符我们又记忆不清,使用的命令为:
select * from employees where first_name like "_ _ _ka%" limit 10;

first_name like "_ _ _ka%":表示查询first_name中第四、五个字符为ka的内容;
like %a%:表示包含a;
2.11模糊查询:^代表以什么开头
当我们需要从一个有很多数据的表中,查询到以某个(些)字符开头的数据时,我们用的命令为:
select * from employees where first_name rlike "^ch" limit 10;

first_name rlike "^ch":表示查询first_name中以ch开头的内容;
rlike ^a:表示以a开头;
2.12模糊查询:$代表以什么结尾
当我们需要从一个有很多数据的表中,查询到以某个(些)字符结尾的数据时,我们用的命令为: select * from employees where first_name rlike "ra$" limit 10;

first_name rlike "ra$" :表示查询first_name中以ra结尾的内容;
rlike a$:表示以a结尾;
2.13别名:as表示设置别名
当我们需要更直观的看到某个数据时,我们可以给其设置别名,命令为:select count(*) as total from empliyees;

count(*) as total:表示把count(*)的别名设置为total;
a as b:表示把a的别名设置为b;
2.14排序:order by表示对查询结果进行排序
当我们需要对查询的结果进行排序时,我们使用的命令为:
select * from salaries order by salary desc limit 10;
select * from salaries order by salary asc limit 10;
其中desc表示正序,而asc表示倒序,如果不使用关键字,默认为倒序排列。

order by salary desc/asc:表示把salary从高到低/从低到高排列;
order by a :表示给a排序;
2.15group by:表示对相同结果进行聚合
聚合函数:

当我们查询某一个表中某个字段的数据的条数,并把相同结果进行聚合后作为结果显示出来,使用的命令为:
select gender,count(1) from employees group by gender;

gender,count(1):表示查询gender字段的数据条数;
a,count(1/*):表示查询a的所有数据总数;
group by gender:表示把gender中相同的数据聚合起来;
group by a:表示把a中相同的数据聚合起来;
比如:把salary字段的所有数据,相同的进行数据聚合在一起,然后根据数据的多少按照从高到低的顺序进行排列,并把count(1)的别名设置为count,使用的命令为:
select salary,count(1) as count from salaries group by salary order by count desc limit 5;

salary,count(1):表示查询salary数据的总数;
count(1) as count:表示把count(1)的别名设置为count;
group by salary:表示把salary中相同的数据聚合起来;
order by count desc:表示根据数据聚合后的多少按照从高到低的顺序进行排列;
2.16最大:max表示查询最大值
当我们需要查询某个表中某个字段的最大值时,使用的命令为:select max(salary) from salaries;

max(salary):表示查询salary中的最大值;
2.17最小:min表示查询最小值
当我们需要查询某个表中某个字段的最小值时,使用的命令为:select min(salary) from salaries;

min(salary):表示查询salary中的最小值;
2.18平均:avg表示查询平均值
当我们需要查询某个表中某个字段的最小值时,使用的命令为:select avg(salary) from salaries;

avg(salary) :表示查询salary的平均值;
2.19总和:sum表示和值
当我们需要查询某个表中某个字段的和值时,使用的命令为:select sum(salary) from salaries;

sum(salary):表示查询salary的和值;
2.20年份:year表示显示年份
当我们需要仅显示表中的日期的年份时,用的命令为:select year(from_date) from salaries limit 10;
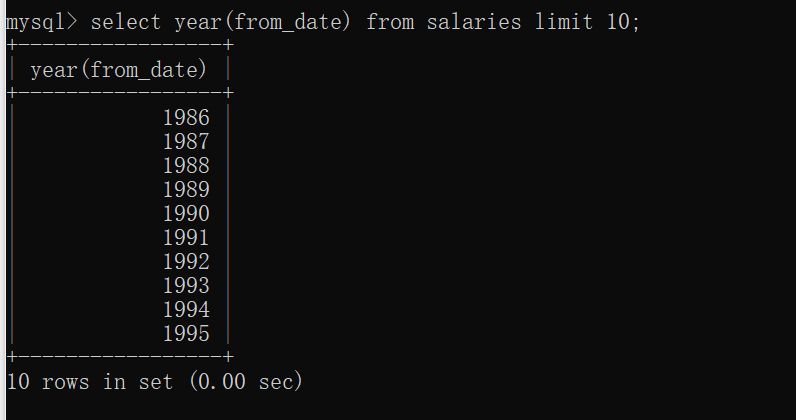
year(from_date):表示仅显示from_date的年份;
如:按照年份,对员工的薪资进行从⾼到低的进行排序的命令:
select year(from_date) as dateYear,sum(salary) as sumSalary from salaries group by dateYear order by sumSalary desc;

year(from_date):表示仅显示from_date的年份;
year(from_date) as dateYear:表示把year(from_date) 的别名设置为dateYear;
sum(salary):表示查询salary的和值;
sum(salary) as sumSalary:表示把sum(salary)的别名设置为sumsalary;
group by dateYear:表示把dateYear中相同的聚合到一起;
order by sumSalary desc:表示将sumSalary从高到低进行排列;
2.21去重:distinct表示去掉重复
当我们在查询某项数据,需要去掉里面重复的内容时,使用的命令为:select distinct title from titles;

distinct title:表示去掉title中重复的内容;
2.22过滤:having
当我们在查询某项数据,需要过滤里面部分的内容时,使用的命令为:
select salary from salaries having salary>70000 limit 10;
select salary from salaries having salary<70000 limit 10;
select salary from salaries having salary=70000 limit 10;

select salary from salaries:从salaries中获取salary的数据;
having salary>/</=70000:取salary大于/小于/等于70000的数据;
如:找到平均薪资超过140000的员工,使用的命令为: select emp_no,avg(salary) as avg from salaries group by emp_no having avg>140000 order by avg desc;

emp_no,avg(salary) as avg:查询员工的编号和平均薪资;
avg(salary) as avg:表示把avg(salary)的别名设置为avg;
group by emp_no:表示把emp_no中相同的聚合在一起;
having avg>140000:表示选取avg大于140000;
3、关联
把多个表通过一个唯一值进行关联起来的过程。
3.1关联:表格的创建
如我们通过一个人的身份证信息(code)把一个人的个人信息(person)、工作经历(work)、教育经历(educate)三个表关联起来:

3.2关联:数据的插入
插入一条数据,以身份证信息1001进行关联:

3.3关联:数据的查询
所用到的表的字段:

所用到的表中的数据:

3.3.1内连接(inner join)

当我们要查询关联的表中的某些字段的内容时,我们需要通过内关联将有关联的表中的字段关联起来,使用的命令为:
select person.name,person.age,work.copany,educate.schoolname from person inner join work on person.code=work.code inner join educate on work.code=educate.code where person.code=1001;

person.name,person.age,work.copany,educate.schoolname:想要获得的内容的字段;
inner json:表示内关联,即所有表中共有的数据;
work on person.code=work.code:表示person和work两个表通过code关联;
on:表示通过什么进行关联;
where person.code=1001:表示提取code为1001的这条数据中的内容。
3.3.2外连接
3.2.2.1左连接(left join)
获取左表所有记录,获取左边数据表所有符合要求的字段数据信息。

当我们想要查询左表的所有信息,但是又想要查询右表某些字段的信息,我们就可以用左连接。用左连接,我们查询到的是左表的所有信息,右表的部分字段的能与左表匹配的信息,无法匹配的
显示为空,如果有多个表,左连接取最左边的表。如我们在表person、work、workinfo中查询person表中所有的人的姓名、年龄、公司、薪资、工作类型和工作是否安全,我们所用的命令为:
select p.name,p.age,w.copany,w.salary,i.taple,i.issafe from person as p left join work as w on p.code=w.code left join workinfo as i on w.w_id=i.w_id;

p.name,p.age,w.copany,w.salary,i.taple,i.issafe:表示想要查询的字段;
person as p:把person的别名设置为p;
left join:左连接;
person as p left join work as w:person与work左连接;
work as w:把work的别名设置为w;
on p.code=w.code:person和work通过code连接;
left join workinfo as i on w.w_id=i.w_id:work和workinfo通过w_id左连接;
3.2.2.2右链接
获取右表所有记录的信息,获取右边数据表所有的数据信息。

当我们想要查询右表的所有信息,但是又想要查询左表某些字段的信息,我们就可以用右连接。用右连接,我们查询到的是右表的所有信息,左表的部分字段的能与右表匹配的信息,无法匹配的
显示为空,如果有多个表,右连接取最右边的表。如我们在表work、workinfo中查询workinfo表中所有的人的公司、薪资、工作类型和工作是否安全,我们所用的命令为:
select w.company,w.salary,i.type,i.issafe from work as w right join workinfo as i on w.w_id=i.w_id;
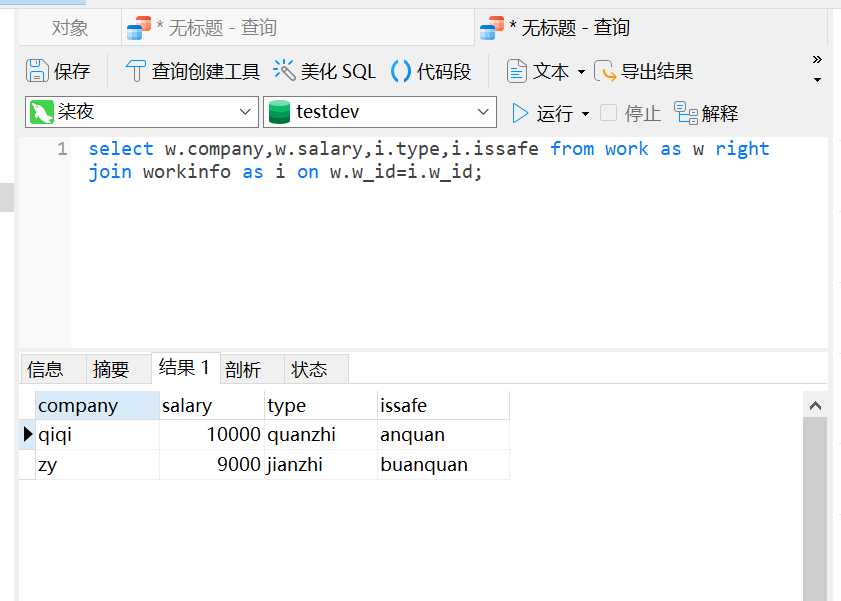
w.company,w.salary,i.type,i.issafe:表示要查询的字段;
work as w:把work的别名设置为w;
right join:右链接;
work as w right join workinfo as i:把work与workinfo右链接;
on w.w_id=i.w_id:work和workinfo通过w_id连接;
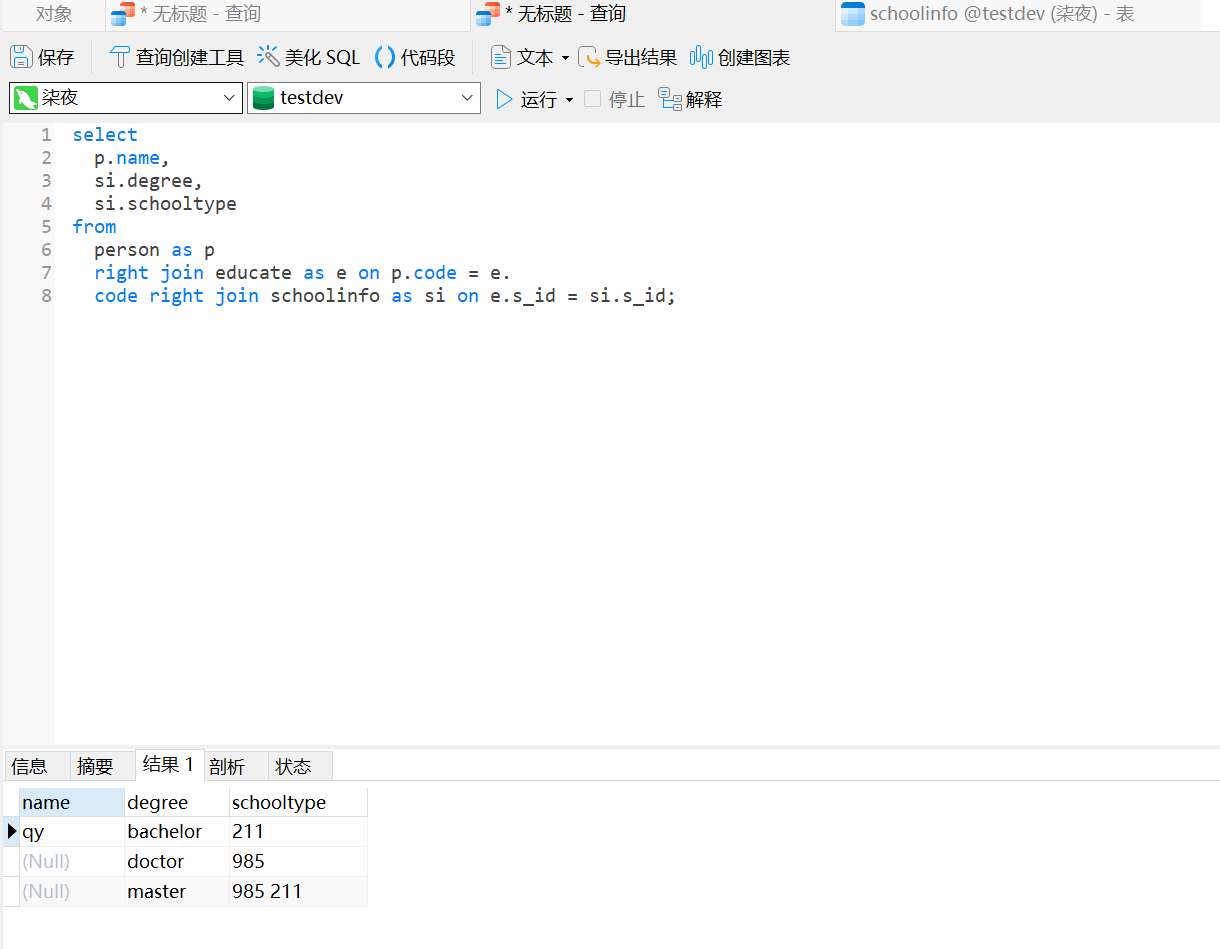
(1)又如:在表person、work、workinfo、educate、schoolinfo表中用右链接查询名字、年龄、公司、薪资、工作类型、公作是否安全、学校名称、学位、学校类型,用的命令为:
select p.name,p.age,w.company,w.salary,wi.type,wi.issafe,e.schoolname,si.degree,si.schooltype from person as p right join work as w on p.code=w.code right join workinfo as wi on w.w_id=wi.w_id right join educate as e on w.code=e.code right join schoolinfo as si on e.s_id=si.s_id;
查询结果如下:

p.name,p.age,w.company,w.salary,wi.type,wi.issafe,e.schoolname,si.degree,si.schooltype:查询的字段;
person as p right join work as w on p.code=w.code:person和work通过code右链接;
right join workinfo as wi on w.w_id=wi.w_id:work和workinfo通过w_id右链接;
right join educate as e on w.code=e.code:work和educate通过code右连接;
right join schoolinfo as si on e.s_id=si.s_id:schoolinfo和educate通过s_id右链接;
3.3.3子查询
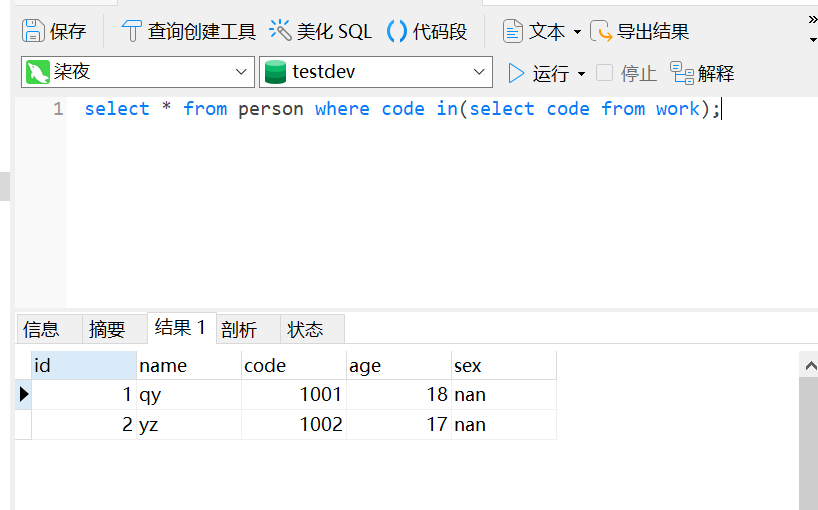
子查询就是以in中的查询结果为条件查询in语句前面的,如命令:select * from person where code in(select code from work);就是指以select code from work的查询结果为条件,然后在
person中进行查询。

那么就是在person中查询code为1001和1002这两条数据。
4、索引
在MySQL中,创建MySQL的索引主要是为了提⾼MySQL查询的效率。但是添加太多的索引也是会降低更新表的速度的。一般情况下,当数据超过百万条时会添加索引。
4.1添加索引
(1)创建表的时候添加索引,如创建info表时给name添加索引:其中index是添加索引的命令,FN是name的索引字符,name是需要添加索引的字段。

查看表的SQL脚本:

(2)更新表的时添加索引,如给info表的id添加索引: alter table info add index FI(id);

查看SQL脚本:

4.2查看索引
查看某个表格中添加的索引:show index from info(表的名称);

4.3删除索引
如删除name的索引: drop index FN(name的索引字符) on info;
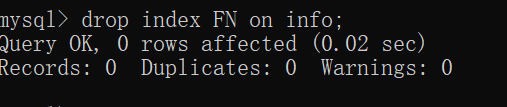
查看SQL脚本:

4.4什么情况下设置了索引但无法使用
(1)以“%”开头的LIKE语句,模糊匹配
(2)OR语句前后没有同时使用索引
(3)数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!