Python下载会员歌曲
Python下载会员歌曲
@(博客)[QQ|会员音乐|下载]
018.8.8
1. 由于本人是法盲,所以是否涉及侵权QQ音乐不知;如若侵权,相告即删
2. 相关代码仅作参考学习,不用于商业目的
前言
本来想先编个故事再进入正文的,这符合我的风格。但由于要下载QQ音乐的VIP歌曲,代码方面不难,而是分析文件的过程有点绕。我已经觉得这个过程我会说不清楚,继而意兴阑珊,故事什么的就了无趣味了
目标
QQ音乐中VIP才能下载的歌曲
使用库
主要使用的库:
- requests 向服务器发起请求
- urllib 构建url地址
- re 提取需要的数据
分析
(1)文件A
首先我们来到QQ音乐的网页端,播放一首歌曲,这里就以【小半】为例
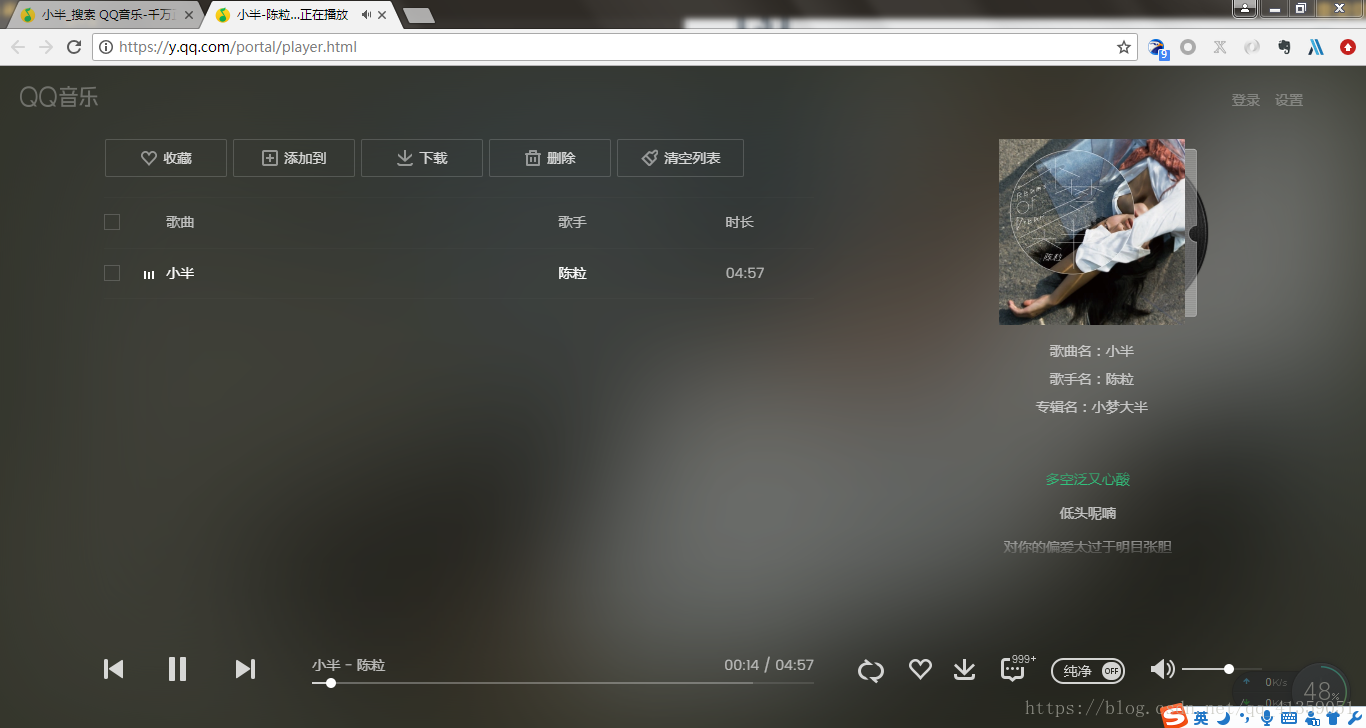
利用chrome的开发者工具,勾选Preserver log,并且选中Media,刷新页面
刷新页面
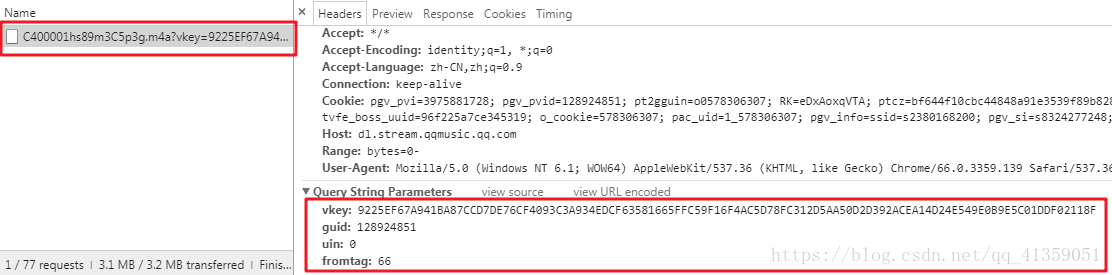
此时会发现有这么一个不知道什么的文件出现,暂且称之为文件A。右下角红色方框内是请求这个数据时带上的query参数
点进来之后会发现其实这就是我们需要的歌曲文件
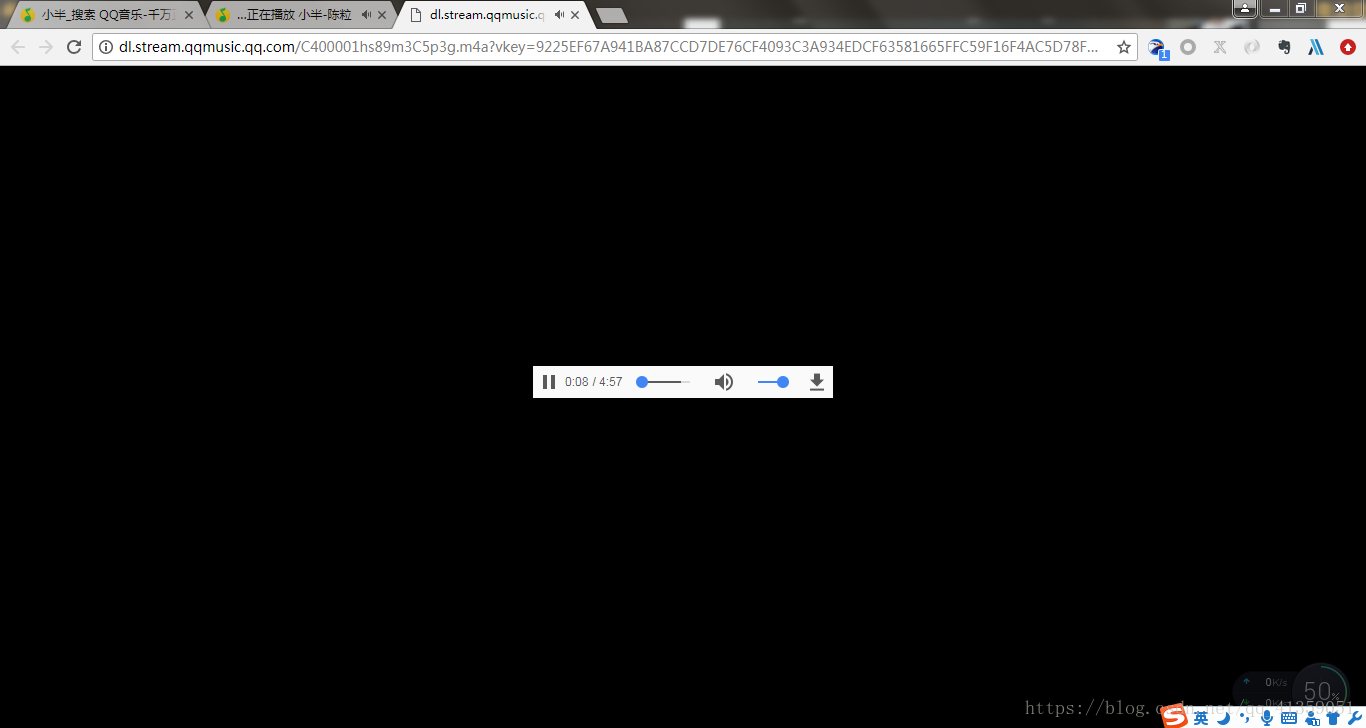
所以现在的问题成了如何请求文件A。我们已经有了请求参数,也可以找到服务器的接口
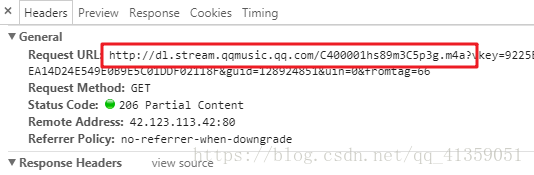
根据反复测试,发现只有关键字vkey的值在发生变化,所以只要我们获取了动态变化的vkey值,拿到文件A就易如反掌了
(2)文件B
通过开发者工具,我找到了一个JS文件,暂且称之为文件B,它在歌曲文件之前被请求,并且其返还数据里面有vkey值
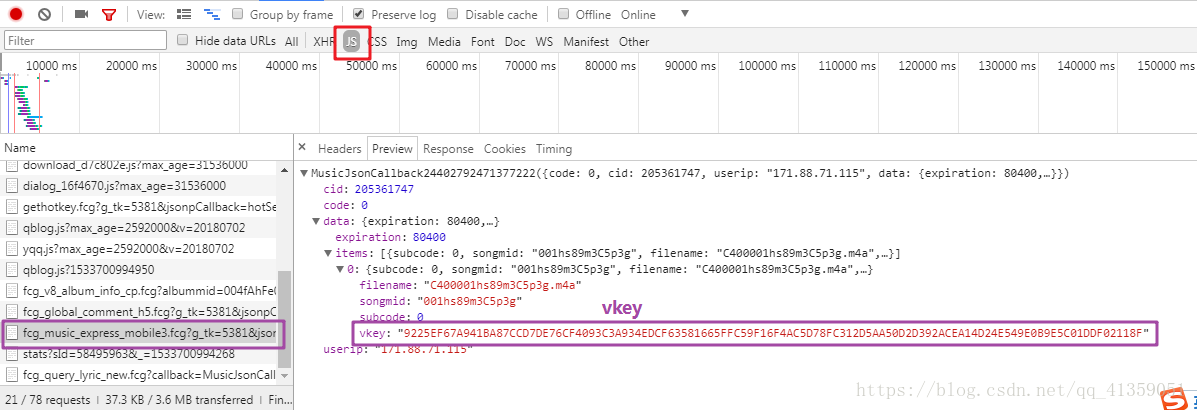
我们也发现,需要请求这个文件,需要的query参数不可谓少
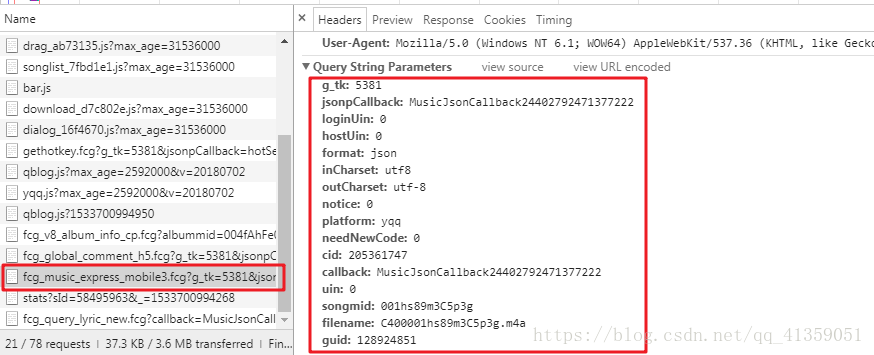
同样,在反复测试以后会发现,songmid的值会根据歌曲的不同而发生改变;filename的值是在songmid值的左边加上C400,右边加上.m4a
于是问题变成了如何获取songmid的值
(3)文件C
继续顺藤摸瓜前边的文件,在一个JS文件,暂且称之为文件C中找到了
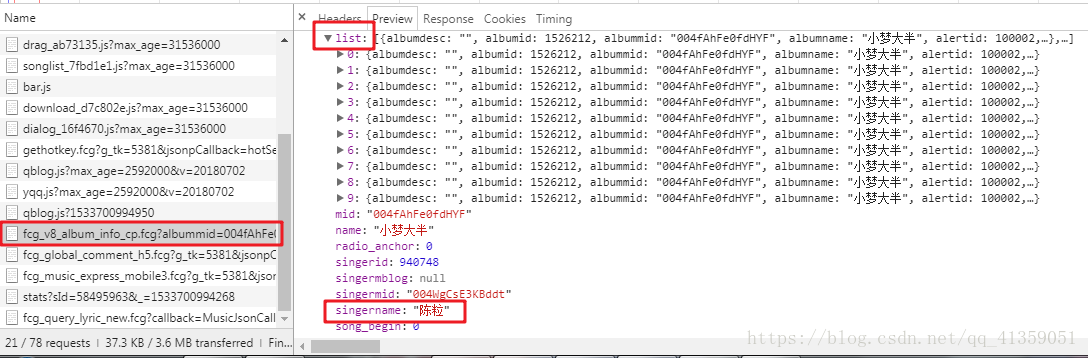
仔细分析会发现,关键字list是包含了【小半】所在专辑《小梦大半》里面的全部歌曲,而还有个关键字singername是歌手名字,为了确保我们下载的歌曲是我们想要的歌手唱的,所以我用正则提取出来。针对list,我的方法是将整个专辑中所有歌曲的songmid以及歌曲的名字全部提取出来,然后再从中确认我们需要的songmid
# 提取歌手名字
SINGER = re.search(r'"singername":"(.+?)"', data).group(1)# 提取专辑中所有的songmid,以及对应的歌曲名字
results = re.findall(r'"songmid":"(\w+?)","songname":"(.+?)"', data)
# 我们知道,通过findall()方法得到的结果是由元组组成的列表(如:[(songmid1, songname1), (songmid2, songname2),...]),所以对其遍历,当歌曲名字SONGNAME在这个元组里边时,返回对应的songmid
if results:
for result in results:
if SONGNAME in result:
return result[0]
else:
return None
else:
return None而如何获得这个文件呢?
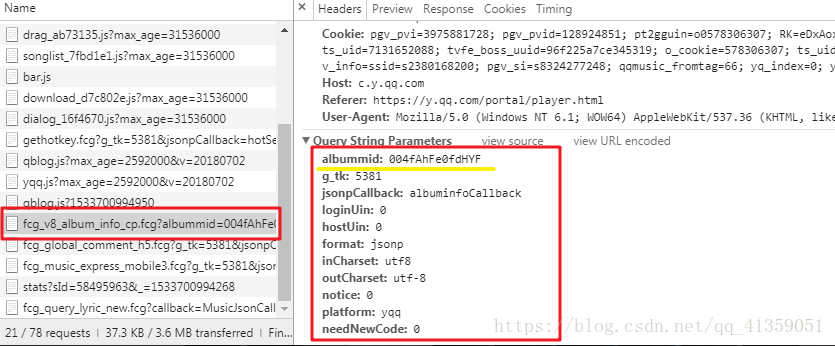
可以看到,获取这个文件的关键点是albummid的值
(4)文件D
来到QQ音乐的搜索界面

当我们在搜索框中键入文字以后点击右边的搜索按钮,会发现浏览器接收到一个文件,我称之为文件D
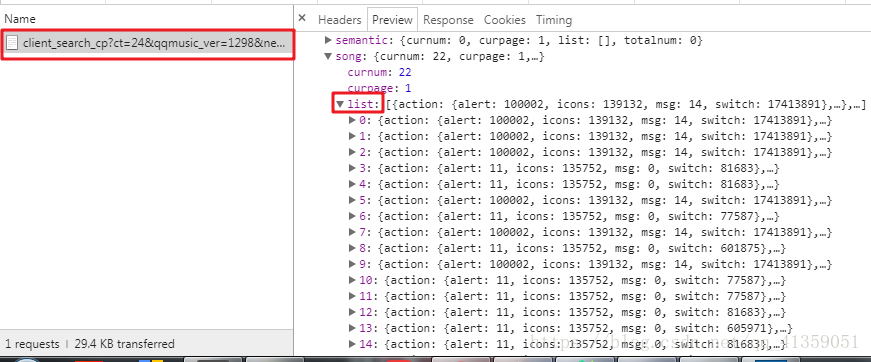
文件D中的list里边就包含了我们搜索出来的结果,因为存在歌曲同名啊,翻唱之类的,所以一般list里边都包含多个值,而一般情况下,比较火的歌,且在QQ音乐中有版权的,都会存放在第一个(如果有其他目的,可自行在list的数据中进行取舍),这里我就只取出第一个
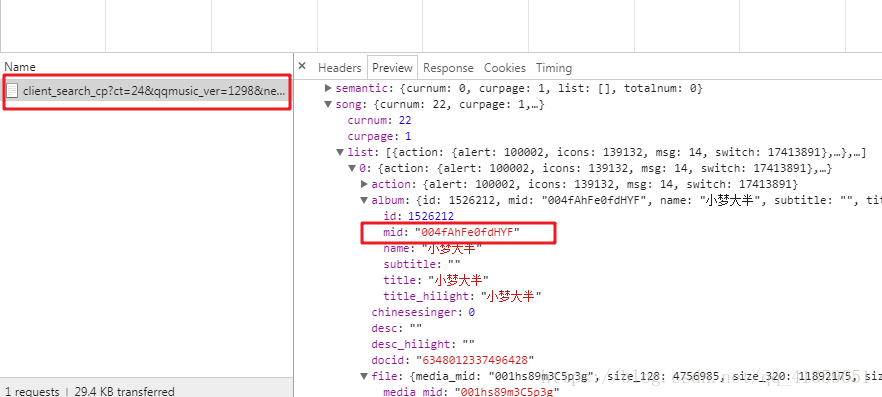
# 提取albummid的值
result = re.search(r'"mid":"(\w+?)"', data)
if result:
return result.group(1)
else:
return None文件D的请求方式就比较简单了
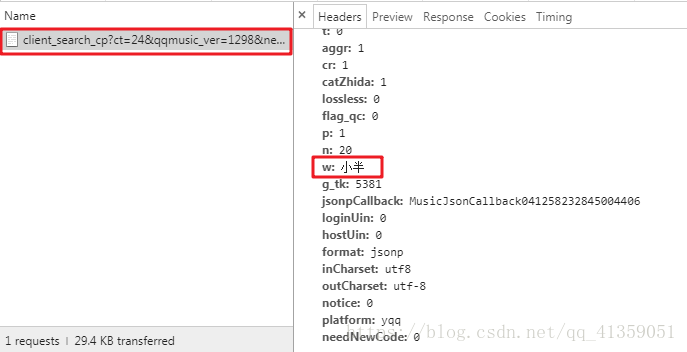
尽管需要的参数很多,但最重要的就是w了,它对应的是歌曲名字
(5)注意事项
此时再回去看看请求文件A的接口,其实有一部分就是文件B中的关键字filename所对应的值,所以我们对这个接口要动态改变
# 构建下载歌曲的query参数
PARAMS_FOR_VIPSONG["vkey"] = vkey
url = parse.urljoin(URL_FOR_VIPSONG, "C400"+songmid+".m4a?")最后
分析是从里到外,找到的文件是A->B->C->D;而代码的执行顺序应该是从外到里,请求文件的顺序是D->C->B->A
以下是我代码的主要结构
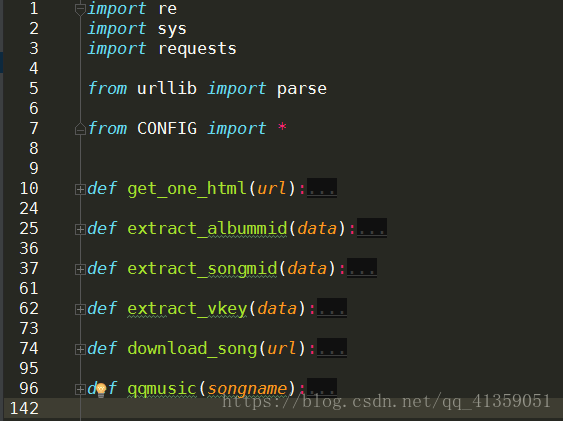
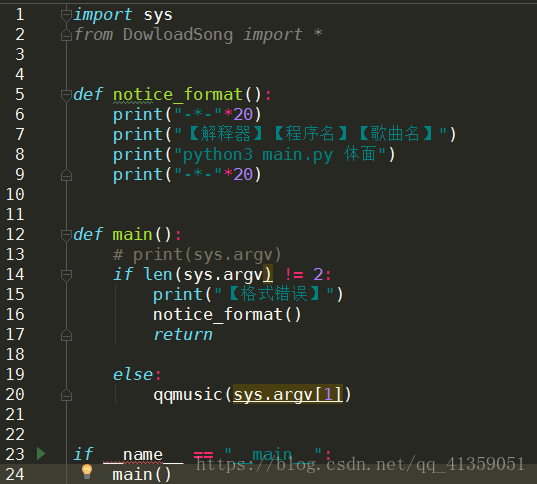
为了更加友好,我另写了一个main.py的文件,来提示程序的用法
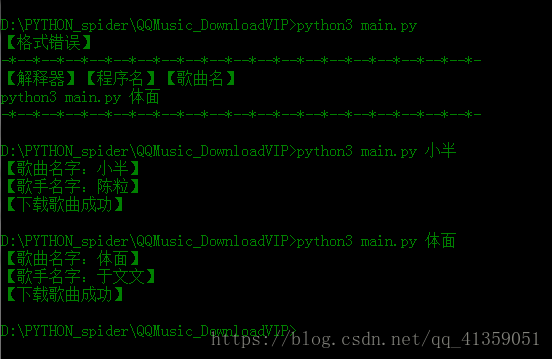
代码运行效果如下
完整代码已上传Github(有详细注释)
