
简单说说utf-8编码格式
提到utf-8,脑海里立马出现了Unicode。那什么是utf-8, 什么是Unicode呢?简要说一下。
Unicode(Universal Multiple-Octet Coded Character Set,UCS) 是由国际组织设计,可以容纳全世界所有语言文字的编码方案。
utf (UCS Transformation Format ) 是实现Unicode的方法,utf-8 就是其中一个(以8位作为一个编码单元)版本。另外还有utf-16(16位为一个编码单元),utf-32(32位为一个编码单元)
OK,现在先不说这些太专业的东西。用数的表示来说,
想想,如果我们的前辈们规定,0要写成0000,3要写成0003,50要写成0050……
你是不是觉得很蛋疼?很费事?直接表示成0,3,50……方便省事
utf-8就是做了这么一件事。把8位以内能表示的Unicode编码用一个字节表示,16位以内能表示的Unicode编码用两个字节表示,同理,24位3字节,32位4字节
但是,计算机存储数据是连续的二进制数0,1表示的,比如:10111011001001100000111010111100001110……
天晓得你哪里是8位一个字符,哪里是16位一个字符……
utf-8就提供了一种用连续的0,1表示,还能区分1字节、2字节,3字节、4字节的处理方案。
看图(截图来自:https://www.ietf.org/rfc/rfc3629.txt):
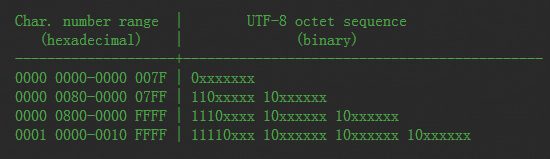
上图表示了字符编码对应的utf-8二进制表示,可见规则如下:
单字节字符(比如ASCII对应字符):最高位用0表示
多字节字符(比如中文字符):第一个字节用n个1 表示,后面字节前两位为10 n表示该字符的字节数
这么一来就可以以字节为单位处理数据了(自己想象的,只为理解处理过程,实际未必真是这样):
1、取出一个字节
2、如果该字节的最高位是0,按单字节字符处理,找到对应Unicode编码。转1;否则,转3
3、识别该字节前面有几位1,记为n,向后再取n-1个字节,找到以这n个字节表示的数对应的编码。转1
(注意:上图中的二进制数中,只有xx表示的部分才是Unicode码,其它都是标志)
总结:Unicode是一个能表示世界上所有语言的编码集合;utf-8是一种Unicode实现方式。
想要了解更多详情,请参考:
UTF-8编码规则

 浙公网安备 33010602011771号
浙公网安备 33010602011771号