ES系列(六):search处理过程实现1框架
上一篇文章中,我们看了get在es的实现过程,虽只是一个简单的单条查询,但看起来实现却非常之复杂。纠其原因,是我们围绕了太多外围的东西讲了,而其核心则无外乎三点:1. 定义id对应的机器节点; 2. 查找真正的docId; 3. 查找docId对应的field信息;
本篇,我们再看另一个es的重要功能:search. 可以说,整个es就是立足于search的,所以,单就这事,足够我们啃上许久许久了。但,我们可以分步来,今日只需聊个大概框架,细节留待日后再说。实际上,平时我们聊事物时,又何偿不是在聊框架类的东西呢。只是有时候钻到牛角尖去,反倒能体现一个人的水平问题了。而针对这一点,则往往会牵出一个人的两个能力点:抓取问题核心的能力;深度理解和思考的能力。
闲话休绪,进入正题:search的处理框架。
1. searchAction框架
我们就以如下请求作为研究来源,即如何发起一个普通的search请求:
# 查找 test 索引中字段 name=ali 的记录 curl -X GET -H 'content-type:application/json' -d '{"query":{"match":{"name":"ali"}}}' http://localhost:9200/test/job/_search
如上备注所说,过滤条件其实就一个 name=ali, 我们可以很容易类比到sql中的表达:
select * from test where name='ali';
看起来问题并不复杂,那么es中又是如何处理该事务的呢? es中的包划分得比较清晰,比如http请求,会先交给rest包下实现处理,内部处理交由action模块处理,启动模块由bootstrap处理等等。总之,这是一个优秀应用必备一个特性:代码清晰易懂。
整个http请求的search入口包,其存放位置如下:
client实例负责许多的请求转发入口,负责与远程或者本机的es节点进行通讯,调度等重要工作。它是在es启动时初始化的一个重要实例,其存放位置如下:

action的内部请求定义包,用于在启动时注册处理器,以及在接收到http请求后,将其统一转发到内部节点处理,其存放位置如下:

最后,来看下 search 的语法包含哪些?这可以在每个具体Action的 routes() 方法中找到:
// org.elasticsearch.rest.action.search.RestSearchAction#routes @Override public List<Route> routes() { return unmodifiableList(asList( new Route(GET, "/_search"), new Route(POST, "/_search"), new Route(GET, "/{index}/_search"), new Route(POST, "/{index}/_search"), // Deprecated typed endpoints. new Route(GET, "/{index}/{type}/_search"), new Route(POST, "/{index}/{type}/_search"))); }
即 search支持不带索引、带索引、带索引带type、GET/POST搜索, 可谓是语法宽松得很呐。
2. search的框架实现
本节我们就来看看实现search功能,es都是如何做的呢?
接到外部请求后,会交给nettyHandler, 然后交给RestController, 然后再找到具体的handler, 然后进行prepare, accept. 具体实现细节可以参考前几篇文章。这里只想说明,最终会交到 RestSearchAction 进行处理。 而 RestSearchAction 继承了BaseRestHandler, 会统一走处理流程: prepareAction() -> 参数检查 -> 具体实现调用 ;
2.1. 搜索请求的接入
本部分主要讲解,当接到外部请求后,如果内部的searcher,因是有许多的线程池,以及许多的分布式节点,这前面许多工作并不会执行真正查询。故只会有一些分发起查询工作,参数解析等。我们可以先看个时序图,解其大致:

实现如下:
// org.elasticsearch.rest.BaseRestHandler#handleRequest @Override public final void handleRequest(RestRequest request, RestChannel channel, NodeClient client) throws Exception { // prepare the request for execution; has the side effect of touching the request parameters // 具体的处理实现上下文准备 final RestChannelConsumer action = prepareRequest(request, client); // validate unconsumed params, but we must exclude params used to format the response // use a sorted set so the unconsumed parameters appear in a reliable sorted order final SortedSet<String> unconsumedParams = request.unconsumedParams().stream().filter(p -> !responseParams().contains(p)).collect(Collectors.toCollection(TreeSet::new)); // validate the non-response params if (!unconsumedParams.isEmpty()) { final Set<String> candidateParams = new HashSet<>(); candidateParams.addAll(request.consumedParams()); candidateParams.addAll(responseParams()); throw new IllegalArgumentException(unrecognized(request, unconsumedParams, candidateParams, "parameter")); } if (request.hasContent() && request.isContentConsumed() == false) { throw new IllegalArgumentException("request [" + request.method() + " " + request.path() + "] does not support having a body"); } usageCount.increment(); // execute the action action.accept(channel); } // org.elasticsearch.rest.action.search.RestSearchAction#prepareRequest @Override public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException { SearchRequest searchRequest = new SearchRequest(); /* * We have to pull out the call to `source().size(size)` because * _update_by_query and _delete_by_query uses this same parsing * path but sets a different variable when it sees the `size` * url parameter. * * Note that we can't use `searchRequest.source()::size` because * `searchRequest.source()` is null right now. We don't have to * guard against it being null in the IntConsumer because it can't * be null later. If that is confusing to you then you are in good * company. */ IntConsumer setSize = size -> searchRequest.source().size(size); // 解析参数 request.withContentOrSourceParamParserOrNull(parser -> parseSearchRequest(searchRequest, request, parser, client.getNamedWriteableRegistry(), setSize)); // 具体的search 业务处理入口 return channel -> { RestCancellableNodeClient cancelClient = new RestCancellableNodeClient(client, request.getHttpChannel()); cancelClient.execute(SearchAction.INSTANCE, searchRequest, new RestStatusToXContentListener<>(channel)); }; }
这前置工作,两个重点:1. 解析参数; 2. 构建业务处理的consumer逻辑; 其中,es中大量使用了lamda表达式,大大简化了java编程的繁文缛节,算是为java扳回点颜面。
search作为es中重要且复杂功能,其参数也是超级复杂,要想完全理解各参数,倒真是可以花上几篇的文章好好讲上几讲。不过想稍微多了解点,也可以展开下面的实现,看个大概。


// org.elasticsearch.rest.action.search.RestSearchAction#parseSearchRequest /** * Parses the rest request on top of the SearchRequest, preserving values that are not overridden by the rest request. * * @param requestContentParser body of the request to read. This method does not attempt to read the body from the {@code request} * parameter * @param setSize how the size url parameter is handled. {@code udpate_by_query} and regular search differ here. */ public static void parseSearchRequest(SearchRequest searchRequest, RestRequest request, XContentParser requestContentParser, NamedWriteableRegistry namedWriteableRegistry, IntConsumer setSize) throws IOException { if (searchRequest.source() == null) { searchRequest.source(new SearchSourceBuilder()); } searchRequest.indices(Strings.splitStringByCommaToArray(request.param("index"))); if (requestContentParser != null) { // 将外部请求转换为可读的格式,比如解析出 {"query":{"match":{"xx":"1"}}} // 此处相当于词法语法解析,有些难度呢 searchRequest.source().parseXContent(requestContentParser, true); } final int batchedReduceSize = request.paramAsInt("batched_reduce_size", searchRequest.getBatchedReduceSize()); searchRequest.setBatchedReduceSize(batchedReduceSize); if (request.hasParam("pre_filter_shard_size")) { searchRequest.setPreFilterShardSize(request.paramAsInt("pre_filter_shard_size", SearchRequest.DEFAULT_PRE_FILTER_SHARD_SIZE)); } if (request.hasParam("max_concurrent_shard_requests")) { // only set if we have the parameter since we auto adjust the max concurrency on the coordinator // based on the number of nodes in the cluster final int maxConcurrentShardRequests = request.paramAsInt("max_concurrent_shard_requests", searchRequest.getMaxConcurrentShardRequests()); searchRequest.setMaxConcurrentShardRequests(maxConcurrentShardRequests); } if (request.hasParam("allow_partial_search_results")) { // only set if we have the parameter passed to override the cluster-level default searchRequest.allowPartialSearchResults(request.paramAsBoolean("allow_partial_search_results", null)); } // do not allow 'query_and_fetch' or 'dfs_query_and_fetch' search types // from the REST layer. these modes are an internal optimization and should // not be specified explicitly by the user. String searchType = request.param("search_type"); if ("query_and_fetch".equals(searchType) || "dfs_query_and_fetch".equals(searchType)) { throw new IllegalArgumentException("Unsupported search type [" + searchType + "]"); } else { searchRequest.searchType(searchType); } // 解析顶层参数备用 parseSearchSource(searchRequest.source(), request, setSize); searchRequest.requestCache(request.paramAsBoolean("request_cache", searchRequest.requestCache())); String scroll = request.param("scroll"); if (scroll != null) { // scroll 解析,与时间相关 searchRequest.scroll(new Scroll(parseTimeValue(scroll, null, "scroll"))); } if (request.hasParam("type")) { deprecationLogger.deprecate("search_with_types", TYPES_DEPRECATION_MESSAGE); searchRequest.types(Strings.splitStringByCommaToArray(request.param("type"))); } searchRequest.routing(request.param("routing")); searchRequest.preference(request.param("preference")); searchRequest.indicesOptions(IndicesOptions.fromRequest(request, searchRequest.indicesOptions())); checkRestTotalHits(request, searchRequest); if (searchRequest.pointInTimeBuilder() != null) { preparePointInTime(searchRequest, request, namedWriteableRegistry); } else { searchRequest.setCcsMinimizeRoundtrips( request.paramAsBoolean("ccs_minimize_roundtrips", searchRequest.isCcsMinimizeRoundtrips())); } } // org.elasticsearch.search.builder.SearchSourceBuilder#parseXContent /** * Parse some xContent into this SearchSourceBuilder, overwriting any values specified in the xContent. Use this if you need to set up * different defaults than a regular SearchSourceBuilder would have and use {@link #fromXContent(XContentParser, boolean)} if you have * normal defaults. * * @param parser The xContent parser. * @param checkTrailingTokens If true throws a parsing exception when extra tokens are found after the main object. */ public void parseXContent(XContentParser parser, boolean checkTrailingTokens) throws IOException { XContentParser.Token token = parser.currentToken(); String currentFieldName = null; if (token != XContentParser.Token.START_OBJECT && (token = parser.nextToken()) != XContentParser.Token.START_OBJECT) { throw new ParsingException(parser.getTokenLocation(), "Expected [" + XContentParser.Token.START_OBJECT + "] but found [" + token + "]", parser.getTokenLocation()); } // 循环解析直到结束 while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) { if (token == XContentParser.Token.FIELD_NAME) { currentFieldName = parser.currentName(); } else if (token.isValue()) { if (FROM_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { from = parser.intValue(); } else if (SIZE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { size = parser.intValue(); } else if (TIMEOUT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { timeout = TimeValue.parseTimeValue(parser.text(), null, TIMEOUT_FIELD.getPreferredName()); } else if (TERMINATE_AFTER_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { terminateAfter = parser.intValue(); } else if (MIN_SCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { minScore = parser.floatValue(); } else if (VERSION_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { version = parser.booleanValue(); } else if (SEQ_NO_PRIMARY_TERM_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { seqNoAndPrimaryTerm = parser.booleanValue(); } else if (EXPLAIN_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { explain = parser.booleanValue(); } else if (TRACK_SCORES_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { trackScores = parser.booleanValue(); } else if (TRACK_TOTAL_HITS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { if (token == XContentParser.Token.VALUE_BOOLEAN || (token == XContentParser.Token.VALUE_STRING && Booleans.isBoolean(parser.text()))) { trackTotalHitsUpTo = parser.booleanValue() ? TRACK_TOTAL_HITS_ACCURATE : TRACK_TOTAL_HITS_DISABLED; } else { trackTotalHitsUpTo = parser.intValue(); } } else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { fetchSourceContext = FetchSourceContext.fromXContent(parser); } else if (STORED_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { storedFieldsContext = StoredFieldsContext.fromXContent(SearchSourceBuilder.STORED_FIELDS_FIELD.getPreferredName(), parser); } else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { sort(parser.text()); } else if (PROFILE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { profile = parser.booleanValue(); } else { throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].", parser.getTokenLocation()); } } else if (token == XContentParser.Token.START_OBJECT) { // 解析query 参数 if (QUERY_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { queryBuilder = parseInnerQueryBuilder(parser); } else if (POST_FILTER_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { postQueryBuilder = parseInnerQueryBuilder(parser); } else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { fetchSourceContext = FetchSourceContext.fromXContent(parser); } else if (SCRIPT_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { scriptFields = new ArrayList<>(); while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) { scriptFields.add(new ScriptField(parser)); } } else if (INDICES_BOOST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { deprecationLogger.deprecate("indices_boost_object_format", "Object format in indices_boost is deprecated, please use array format instead"); while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) { if (token == XContentParser.Token.FIELD_NAME) { currentFieldName = parser.currentName(); } else if (token.isValue()) { indexBoosts.add(new IndexBoost(currentFieldName, parser.floatValue())); } else { throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].", parser.getTokenLocation()); } } } else if (AGGREGATIONS_FIELD.match(currentFieldName, parser.getDeprecationHandler()) || AGGS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { aggregations = AggregatorFactories.parseAggregators(parser); } else if (HIGHLIGHT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { highlightBuilder = HighlightBuilder.fromXContent(parser); } else if (SUGGEST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { suggestBuilder = SuggestBuilder.fromXContent(parser); } else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { sorts = new ArrayList<>(SortBuilder.fromXContent(parser)); } else if (RESCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { rescoreBuilders = new ArrayList<>(); rescoreBuilders.add(RescorerBuilder.parseFromXContent(parser)); } else if (EXT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { extBuilders = new ArrayList<>(); String extSectionName = null; while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) { if (token == XContentParser.Token.FIELD_NAME) { extSectionName = parser.currentName(); } else { SearchExtBuilder searchExtBuilder = parser.namedObject(SearchExtBuilder.class, extSectionName, null); if (searchExtBuilder.getWriteableName().equals(extSectionName) == false) { throw new IllegalStateException("The parsed [" + searchExtBuilder.getClass().getName() + "] object has a " + "different writeable name compared to the name of the section that it was parsed from: found [" + searchExtBuilder.getWriteableName() + "] expected [" + extSectionName + "]"); } extBuilders.add(searchExtBuilder); } } } else if (SLICE.match(currentFieldName, parser.getDeprecationHandler())) { sliceBuilder = SliceBuilder.fromXContent(parser); } else if (COLLAPSE.match(currentFieldName, parser.getDeprecationHandler())) { collapse = CollapseBuilder.fromXContent(parser); } else if (POINT_IN_TIME.match(currentFieldName, parser.getDeprecationHandler())) { pointInTimeBuilder = PointInTimeBuilder.fromXContent(parser); } else if (RUNTIME_MAPPINGS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { runtimeMappings = parser.map(); } else { throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].", parser.getTokenLocation()); } } else if (token == XContentParser.Token.START_ARRAY) { if (STORED_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { storedFieldsContext = StoredFieldsContext.fromXContent(STORED_FIELDS_FIELD.getPreferredName(), parser); } else if (DOCVALUE_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { docValueFields = new ArrayList<>(); while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) { docValueFields.add(FieldAndFormat.fromXContent(parser)); } } else if (FETCH_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { fetchFields = new ArrayList<>(); while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) { fetchFields.add(FieldAndFormat.fromXContent(parser)); } } else if (INDICES_BOOST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) { indexBoosts.add(new IndexBoost(parser)); } } else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { sorts = new ArrayList<>(SortBuilder.fromXContent(parser)); } else if (RESCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { rescoreBuilders = new ArrayList<>(); while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) { rescoreBuilders.add(RescorerBuilder.parseFromXContent(parser)); } } else if (STATS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { stats = new ArrayList<>(); while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) { if (token == XContentParser.Token.VALUE_STRING) { stats.add(parser.text()); } else { throw new ParsingException(parser.getTokenLocation(), "Expected [" + XContentParser.Token.VALUE_STRING + "] in [" + currentFieldName + "] but found [" + token + "]", parser.getTokenLocation()); } } } else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) { fetchSourceContext = FetchSourceContext.fromXContent(parser); } else if (SEARCH_AFTER.match(currentFieldName, parser.getDeprecationHandler())) { searchAfterBuilder = SearchAfterBuilder.fromXContent(parser); } else { throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].", parser.getTokenLocation()); } } else { throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].", parser.getTokenLocation()); } } // 解析完成,token被使用完 if (checkTrailingTokens) { token = parser.nextToken(); if (token != null) { throw new ParsingException(parser.getTokenLocation(), "Unexpected token [" + token + "] found after the main object."); } } } // org.elasticsearch.index.query.AbstractQueryBuilder#parseInnerQueryBuilder /** * Parses a query excluding the query element that wraps it */ public static QueryBuilder parseInnerQueryBuilder(XContentParser parser) throws IOException { if (parser.currentToken() != XContentParser.Token.START_OBJECT) { if (parser.nextToken() != XContentParser.Token.START_OBJECT) { throw new ParsingException(parser.getTokenLocation(), "[_na] query malformed, must start with start_object"); } } if (parser.nextToken() == XContentParser.Token.END_OBJECT) { // we encountered '{}' for a query clause, it used to be supported, deprecated in 5.0 and removed in 6.0 throw new IllegalArgumentException("query malformed, empty clause found at [" + parser.getTokenLocation() +"]"); } if (parser.currentToken() != XContentParser.Token.FIELD_NAME) { throw new ParsingException(parser.getTokenLocation(), "[_na] query malformed, no field after start_object"); } String queryName = parser.currentName(); // move to the next START_OBJECT if (parser.nextToken() != XContentParser.Token.START_OBJECT) { throw new ParsingException(parser.getTokenLocation(), "[" + queryName + "] query malformed, no start_object after query name"); } QueryBuilder result; try { result = parser.namedObject(QueryBuilder.class, queryName, null); } catch (NamedObjectNotFoundException e) { String message = String.format(Locale.ROOT, "unknown query [%s]%s", queryName, SuggestingErrorOnUnknown.suggest(queryName, e.getCandidates())); throw new ParsingException(new XContentLocation(e.getLineNumber(), e.getColumnNumber()), message, e); } //end_object of the specific query (e.g. match, multi_match etc.) element if (parser.currentToken() != XContentParser.Token.END_OBJECT) { throw new ParsingException(parser.getTokenLocation(), "[" + queryName + "] malformed query, expected [END_OBJECT] but found [" + parser.currentToken() + "]"); } //end_object of the query object if (parser.nextToken() != XContentParser.Token.END_OBJECT) { throw new ParsingException(parser.getTokenLocation(), "[" + queryName + "] malformed query, expected [END_OBJECT] but found [" + parser.currentToken() + "]"); } return result; } // org.elasticsearch.rest.action.search.RestSearchAction#parseSearchSource /** * Parses the rest request on top of the SearchSourceBuilder, preserving * values that are not overridden by the rest request. */ private static void parseSearchSource(final SearchSourceBuilder searchSourceBuilder, RestRequest request, IntConsumer setSize) { // ?q=xx 格式的搜索 QueryBuilder queryBuilder = RestActions.urlParamsToQueryBuilder(request); if (queryBuilder != null) { searchSourceBuilder.query(queryBuilder); } int from = request.paramAsInt("from", -1); if (from != -1) { searchSourceBuilder.from(from); } int size = request.paramAsInt("size", -1); if (size != -1) { setSize.accept(size); } if (request.hasParam("explain")) { searchSourceBuilder.explain(request.paramAsBoolean("explain", null)); } if (request.hasParam("version")) { searchSourceBuilder.version(request.paramAsBoolean("version", null)); } if (request.hasParam("seq_no_primary_term")) { searchSourceBuilder.seqNoAndPrimaryTerm(request.paramAsBoolean("seq_no_primary_term", null)); } if (request.hasParam("timeout")) { searchSourceBuilder.timeout(request.paramAsTime("timeout", null)); } if (request.hasParam("terminate_after")) { int terminateAfter = request.paramAsInt("terminate_after", SearchContext.DEFAULT_TERMINATE_AFTER); if (terminateAfter < 0) { throw new IllegalArgumentException("terminateAfter must be > 0"); } else if (terminateAfter > 0) { searchSourceBuilder.terminateAfter(terminateAfter); } } StoredFieldsContext storedFieldsContext = StoredFieldsContext.fromRestRequest(SearchSourceBuilder.STORED_FIELDS_FIELD.getPreferredName(), request); if (storedFieldsContext != null) { searchSourceBuilder.storedFields(storedFieldsContext); } String sDocValueFields = request.param("docvalue_fields"); if (sDocValueFields != null) { if (Strings.hasText(sDocValueFields)) { String[] sFields = Strings.splitStringByCommaToArray(sDocValueFields); for (String field : sFields) { searchSourceBuilder.docValueField(field, null); } } } FetchSourceContext fetchSourceContext = FetchSourceContext.parseFromRestRequest(request); if (fetchSourceContext != null) { searchSourceBuilder.fetchSource(fetchSourceContext); } if (request.hasParam("track_scores")) { searchSourceBuilder.trackScores(request.paramAsBoolean("track_scores", false)); } if (request.hasParam("track_total_hits")) { if (Booleans.isBoolean(request.param("track_total_hits"))) { searchSourceBuilder.trackTotalHits( request.paramAsBoolean("track_total_hits", true) ); } else { searchSourceBuilder.trackTotalHitsUpTo( request.paramAsInt("track_total_hits", SearchContext.DEFAULT_TRACK_TOTAL_HITS_UP_TO) ); } } String sSorts = request.param("sort"); if (sSorts != null) { String[] sorts = Strings.splitStringByCommaToArray(sSorts); for (String sort : sorts) { int delimiter = sort.lastIndexOf(":"); if (delimiter != -1) { String sortField = sort.substring(0, delimiter); String reverse = sort.substring(delimiter + 1); if ("asc".equals(reverse)) { searchSourceBuilder.sort(sortField, SortOrder.ASC); } else if ("desc".equals(reverse)) { searchSourceBuilder.sort(sortField, SortOrder.DESC); } } else { searchSourceBuilder.sort(sort); } } } String sStats = request.param("stats"); if (sStats != null) { searchSourceBuilder.stats(Arrays.asList(Strings.splitStringByCommaToArray(sStats))); } String suggestField = request.param("suggest_field"); if (suggestField != null) { String suggestText = request.param("suggest_text", request.param("q")); int suggestSize = request.paramAsInt("suggest_size", 5); String suggestMode = request.param("suggest_mode"); searchSourceBuilder.suggest(new SuggestBuilder().addSuggestion(suggestField, termSuggestion(suggestField) .text(suggestText).size(suggestSize) .suggestMode(SuggestMode.resolve(suggestMode)))); } } // org.elasticsearch.rest.action.RestActions#urlParamsToQueryBuilder public static QueryBuilder urlParamsToQueryBuilder(RestRequest request) { String queryString = request.param("q"); if (queryString == null) { return null; } QueryStringQueryBuilder queryBuilder = QueryBuilders.queryStringQuery(queryString); queryBuilder.defaultField(request.param("df")); queryBuilder.analyzer(request.param("analyzer")); queryBuilder.analyzeWildcard(request.paramAsBoolean("analyze_wildcard", false)); queryBuilder.lenient(request.paramAsBoolean("lenient", null)); String defaultOperator = request.param("default_operator"); if (defaultOperator != null) { queryBuilder.defaultOperator(Operator.fromString(defaultOperator)); } return queryBuilder; }
2.2. search请求的分发
最终执行search时,由 RestCancellableNodeClient 进行execute, 并通过 SearchAction.INSTANCE 查找到处理器 TransportSearchAction . 但此任务,仍是在做前期工作,当前client即会作为协调节点,它知当前语义如何,需要将请求拆解、分发给各节点,或者自行使用异步线程处理。
// org.elasticsearch.action.search.TransportSearchAction#doExecute @Override protected void doExecute(Task task, SearchRequest searchRequest, ActionListener<SearchResponse> listener) { executeRequest(task, searchRequest, this::searchAsyncAction, listener); } private void executeRequest(Task task, SearchRequest searchRequest, SearchAsyncActionProvider searchAsyncActionProvider, ActionListener<SearchResponse> listener) { final long relativeStartNanos = System.nanoTime(); final SearchTimeProvider timeProvider = new SearchTimeProvider(searchRequest.getOrCreateAbsoluteStartMillis(), relativeStartNanos, System::nanoTime); ActionListener<SearchSourceBuilder> rewriteListener = ActionListener.wrap(source -> { if (source != searchRequest.source()) { // only set it if it changed - we don't allow null values to be set but it might be already null. this way we catch // situations when source is rewritten to null due to a bug searchRequest.source(source); } // 重点逻辑 final ClusterState clusterState = clusterService.state(); final SearchContextId searchContext; final Map<String, OriginalIndices> remoteClusterIndices; if (searchRequest.pointInTimeBuilder() != null) { searchContext = SearchContextId.decode(namedWriteableRegistry, searchRequest.pointInTimeBuilder().getId()); remoteClusterIndices = getIndicesFromSearchContexts(searchContext, searchRequest.indicesOptions()); } else { searchContext = null; // 获取远程索引 remoteClusterIndices = remoteClusterService.groupIndices(searchRequest.indicesOptions(), searchRequest.indices(), idx -> indexNameExpressionResolver.hasIndexAbstraction(idx, clusterState)); } OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY); if (remoteClusterIndices.isEmpty()) { // 本地执行 搜索 executeLocalSearch( task, timeProvider, searchRequest, localIndices, clusterState, listener, searchContext, searchAsyncActionProvider); } else { if (shouldMinimizeRoundtrips(searchRequest)) { final TaskId parentTaskId = task.taskInfo(clusterService.localNode().getId(), false).getTaskId(); ccsRemoteReduce(parentTaskId, searchRequest, localIndices, remoteClusterIndices, timeProvider, searchService.aggReduceContextBuilder(searchRequest), remoteClusterService, threadPool, listener, (r, l) -> executeLocalSearch( task, timeProvider, r, localIndices, clusterState, l, searchContext, searchAsyncActionProvider)); } else { AtomicInteger skippedClusters = new AtomicInteger(0); // 更多的是需要收集许多shard数据 collectSearchShards(searchRequest.indicesOptions(), searchRequest.preference(), searchRequest.routing(), skippedClusters, remoteClusterIndices, remoteClusterService, threadPool, ActionListener.wrap( searchShardsResponses -> { final BiFunction<String, String, DiscoveryNode> clusterNodeLookup = getRemoteClusterNodeLookup(searchShardsResponses); final Map<String, AliasFilter> remoteAliasFilters; final List<SearchShardIterator> remoteShardIterators; if (searchContext != null) { remoteAliasFilters = searchContext.aliasFilter(); remoteShardIterators = getRemoteShardsIteratorFromPointInTime(searchShardsResponses, searchContext, searchRequest.pointInTimeBuilder().getKeepAlive(), remoteClusterIndices); } else { remoteAliasFilters = getRemoteAliasFilters(searchShardsResponses); remoteShardIterators = getRemoteShardsIterator(searchShardsResponses, remoteClusterIndices, remoteAliasFilters); } int localClusters = localIndices == null ? 0 : 1; int totalClusters = remoteClusterIndices.size() + localClusters; int successfulClusters = searchShardsResponses.size() + localClusters; executeSearch((SearchTask) task, timeProvider, searchRequest, localIndices, remoteShardIterators, clusterNodeLookup, clusterState, remoteAliasFilters, listener, new SearchResponse.Clusters(totalClusters, successfulClusters, skippedClusters.get()), searchContext, searchAsyncActionProvider); }, listener::onFailure)); } } }, listener::onFailure); // 调用 rewriteListener, 此处source 代表所有输入的搜索条件参数 (json) if (searchRequest.source() == null) { rewriteListener.onResponse(searchRequest.source()); } else { Rewriteable.rewriteAndFetch(searchRequest.source(), searchService.getRewriteContext(timeProvider::getAbsoluteStartMillis), rewriteListener); } } // org.elasticsearch.index.query.Rewriteable#rewriteAndFetch /** * Rewrites the given rewriteable and fetches pending async tasks for each round before rewriting again. */ static <T extends Rewriteable<T>> void rewriteAndFetch(T original, QueryRewriteContext context, ActionListener<T> rewriteResponse) { rewriteAndFetch(original, context, rewriteResponse, 0); } /** * Rewrites the given rewriteable and fetches pending async tasks for each round before rewriting again. */ static <T extends Rewriteable<T>> void rewriteAndFetch(T original, QueryRewriteContext context, ActionListener<T> rewriteResponse, int iteration) { T builder = original; try { for (T rewrittenBuilder = builder.rewrite(context); rewrittenBuilder != builder; rewrittenBuilder = builder.rewrite(context)) { builder = rewrittenBuilder; if (iteration++ >= MAX_REWRITE_ROUNDS) { // this is some protection against user provided queries if they don't obey the contract of rewrite we allow 16 rounds // and then we fail to prevent infinite loops throw new IllegalStateException("too many rewrite rounds, rewriteable might return new objects even if they are not " + "rewritten"); } if (context.hasAsyncActions()) { T finalBuilder = builder; final int currentIterationNumber = iteration; context.executeAsyncActions(ActionListener.wrap(n -> rewriteAndFetch(finalBuilder, context, rewriteResponse, currentIterationNumber), rewriteResponse::onFailure)); return; } } rewriteResponse.onResponse(builder); } catch (IOException|IllegalArgumentException|ParsingException ex) { rewriteResponse.onFailure(ex); } }
以上就是大致的搜索过程接入,看着着实有点累吧。先来看看单节点搜索实现框架:
// org.elasticsearch.action.search.TransportSearchAction#executeLocalSearch private void executeLocalSearch(Task task, SearchTimeProvider timeProvider, SearchRequest searchRequest, OriginalIndices localIndices, ClusterState clusterState, ActionListener<SearchResponse> listener, SearchContextId searchContext, SearchAsyncActionProvider searchAsyncActionProvider) { executeSearch((SearchTask)task, timeProvider, searchRequest, localIndices, Collections.emptyList(), (clusterName, nodeId) -> null, clusterState, Collections.emptyMap(), listener, SearchResponse.Clusters.EMPTY, searchContext, searchAsyncActionProvider); } // org.elasticsearch.action.search.TransportSearchAction#executeSearch private void executeSearch(SearchTask task, SearchTimeProvider timeProvider, SearchRequest searchRequest, OriginalIndices localIndices, List<SearchShardIterator> remoteShardIterators, BiFunction<String, String, DiscoveryNode> remoteConnections, ClusterState clusterState, Map<String, AliasFilter> remoteAliasMap, ActionListener<SearchResponse> listener, SearchResponse.Clusters clusters, @Nullable SearchContextId searchContext, SearchAsyncActionProvider searchAsyncActionProvider) { clusterState.blocks().globalBlockedRaiseException(ClusterBlockLevel.READ); // TODO: I think startTime() should become part of ActionRequest and that should be used both for index name // date math expressions and $now in scripts. This way all apis will deal with now in the same way instead // of just for the _search api final List<SearchShardIterator> localShardIterators; final Map<String, AliasFilter> aliasFilter; final String[] concreteLocalIndices; if (searchContext != null) { assert searchRequest.pointInTimeBuilder() != null; aliasFilter = searchContext.aliasFilter(); concreteLocalIndices = localIndices == null ? new String[0] : localIndices.indices(); localShardIterators = getLocalLocalShardsIteratorFromPointInTime(clusterState, localIndices, searchRequest.getLocalClusterAlias(), searchContext, searchRequest.pointInTimeBuilder().getKeepAlive()); } else { // 解析索引 final Index[] indices = resolveLocalIndices(localIndices, clusterState, timeProvider); // 解析路由 Map<String, Set<String>> routingMap = indexNameExpressionResolver.resolveSearchRouting(clusterState, searchRequest.routing(), searchRequest.indices()); routingMap = routingMap == null ? Collections.emptyMap() : Collections.unmodifiableMap(routingMap); concreteLocalIndices = new String[indices.length]; for (int i = 0; i < indices.length; i++) { concreteLocalIndices[i] = indices[i].getName(); } Map<String, Long> nodeSearchCounts = searchTransportService.getPendingSearchRequests(); GroupShardsIterator<ShardIterator> localShardRoutings = clusterService.operationRouting().searchShards(clusterState, concreteLocalIndices, routingMap, searchRequest.preference(), searchService.getResponseCollectorService(), nodeSearchCounts); localShardIterators = StreamSupport.stream(localShardRoutings.spliterator(), false) .map(it -> new SearchShardIterator( searchRequest.getLocalClusterAlias(), it.shardId(), it.getShardRoutings(), localIndices)) .collect(Collectors.toList()); // 别名过滤器 aliasFilter = buildPerIndexAliasFilter(searchRequest, clusterState, indices, remoteAliasMap); } // 分片迭代器 final GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardIterators, remoteShardIterators); // 检查shard数量是否超限 failIfOverShardCountLimit(clusterService, shardIterators.size()); Map<String, Float> concreteIndexBoosts = resolveIndexBoosts(searchRequest, clusterState); // optimize search type for cases where there is only one shard group to search on // 搜索优化:一个shard时,查找完成一个立即返回 if (shardIterators.size() == 1) { // if we only have one group, then we always want Q_T_F, no need for DFS, and no need to do THEN since we hit one shard searchRequest.searchType(QUERY_THEN_FETCH); } if (searchRequest.allowPartialSearchResults() == null) { // No user preference defined in search request - apply cluster service default searchRequest.allowPartialSearchResults(searchService.defaultAllowPartialSearchResults()); } if (searchRequest.isSuggestOnly()) { // disable request cache if we have only suggest searchRequest.requestCache(false); switch (searchRequest.searchType()) { case DFS_QUERY_THEN_FETCH: // convert to Q_T_F if we have only suggest searchRequest.searchType(QUERY_THEN_FETCH); break; } } final DiscoveryNodes nodes = clusterState.nodes(); // 索引搜索连接管理 BiFunction<String, String, Transport.Connection> connectionLookup = buildConnectionLookup(searchRequest.getLocalClusterAlias(), nodes::get, remoteConnections, searchTransportService::getConnection); // 获取专门用于搜索的线程池 final Executor asyncSearchExecutor = asyncSearchExecutor(concreteLocalIndices, clusterState); final boolean preFilterSearchShards = shouldPreFilterSearchShards(clusterState, searchRequest, concreteLocalIndices, localShardIterators.size() + remoteShardIterators.size()); // 构造异步请求处理器,开启search searchAsyncActionProvider.asyncSearchAction( task, searchRequest, asyncSearchExecutor, shardIterators, timeProvider, connectionLookup, clusterState, Collections.unmodifiableMap(aliasFilter), concreteIndexBoosts, listener, preFilterSearchShards, threadPool, clusters).start(); }
主要就是检查索引、分片、线程池等,搞好之后提到异步执行去了。而分布式系统高性能的秘诀就是在这里,难点也是在这里,难以排查跟踪。
下面我们简单看看多节点搜索时,需要收集结果,其过程大致如下:
// org.elasticsearch.action.search.TransportSearchAction#collectSearchShards static void collectSearchShards(IndicesOptions indicesOptions, String preference, String routing, AtomicInteger skippedClusters, Map<String, OriginalIndices> remoteIndicesByCluster, RemoteClusterService remoteClusterService, ThreadPool threadPool, ActionListener<Map<String, ClusterSearchShardsResponse>> listener) { final CountDown responsesCountDown = new CountDown(remoteIndicesByCluster.size()); final Map<String, ClusterSearchShardsResponse> searchShardsResponses = new ConcurrentHashMap<>(); final AtomicReference<Exception> exceptions = new AtomicReference<>(); for (Map.Entry<String, OriginalIndices> entry : remoteIndicesByCluster.entrySet()) { final String clusterAlias = entry.getKey(); boolean skipUnavailable = remoteClusterService.isSkipUnavailable(clusterAlias); Client clusterClient = remoteClusterService.getRemoteClusterClient(threadPool, clusterAlias); final String[] indices = entry.getValue().indices(); ClusterSearchShardsRequest searchShardsRequest = new ClusterSearchShardsRequest(indices) .indicesOptions(indicesOptions).local(true).preference(preference).routing(routing); clusterClient.admin().cluster().searchShards(searchShardsRequest, new CCSActionListener<ClusterSearchShardsResponse, Map<String, ClusterSearchShardsResponse>>( clusterAlias, skipUnavailable, responsesCountDown, skippedClusters, exceptions, listener) { @Override void innerOnResponse(ClusterSearchShardsResponse clusterSearchShardsResponse) { searchShardsResponses.put(clusterAlias, clusterSearchShardsResponse); } @Override Map<String, ClusterSearchShardsResponse> createFinalResponse() { return searchShardsResponses; } } ); } }
然后其中有许多处理shard, 索引的细节,感兴趣的自行深入。
// org.elasticsearch.cluster.metadata.IndexNameExpressionResolver#resolveSearchRouting /** * Resolves the search routing if in the expression aliases are used. If expressions point to concrete indices * or aliases with no routing defined the specified routing is used. * * @return routing values grouped by concrete index */ public Map<String, Set<String>> resolveSearchRouting(ClusterState state, @Nullable String routing, String... expressions) { List<String> resolvedExpressions = expressions != null ? Arrays.asList(expressions) : Collections.emptyList(); Context context = new Context(state, IndicesOptions.lenientExpandOpen(), false, false, true, isSystemIndexAccessAllowed()); for (ExpressionResolver expressionResolver : expressionResolvers) { resolvedExpressions = expressionResolver.resolve(context, resolvedExpressions); } // TODO: it appears that this can never be true? if (isAllIndices(resolvedExpressions)) { return resolveSearchRoutingAllIndices(state.metadata(), routing); } Map<String, Set<String>> routings = null; Set<String> paramRouting = null; // List of indices that don't require any routing Set<String> norouting = new HashSet<>(); if (routing != null) { paramRouting = Sets.newHashSet(Strings.splitStringByCommaToArray(routing)); } for (String expression : resolvedExpressions) { IndexAbstraction indexAbstraction = state.metadata().getIndicesLookup().get(expression); if (indexAbstraction != null && indexAbstraction.getType() == IndexAbstraction.Type.ALIAS) { IndexAbstraction.Alias alias = (IndexAbstraction.Alias) indexAbstraction; for (Tuple<String, AliasMetadata> item : alias.getConcreteIndexAndAliasMetadatas()) { String concreteIndex = item.v1(); AliasMetadata aliasMetadata = item.v2(); if (!norouting.contains(concreteIndex)) { if (!aliasMetadata.searchRoutingValues().isEmpty()) { // Routing alias if (routings == null) { routings = new HashMap<>(); } Set<String> r = routings.get(concreteIndex); if (r == null) { r = new HashSet<>(); routings.put(concreteIndex, r); } r.addAll(aliasMetadata.searchRoutingValues()); if (paramRouting != null) { r.retainAll(paramRouting); } if (r.isEmpty()) { routings.remove(concreteIndex); } } else { // Non-routing alias if (!norouting.contains(concreteIndex)) { norouting.add(concreteIndex); if (paramRouting != null) { Set<String> r = new HashSet<>(paramRouting); if (routings == null) { routings = new HashMap<>(); } routings.put(concreteIndex, r); } else { if (routings != null) { routings.remove(concreteIndex); } } } } } } } else { // Index if (!norouting.contains(expression)) { norouting.add(expression); if (paramRouting != null) { Set<String> r = new HashSet<>(paramRouting); if (routings == null) { routings = new HashMap<>(); } routings.put(expression, r); } else { if (routings != null) { routings.remove(expression); } } } } } if (routings == null || routings.isEmpty()) { return null; } return routings; } // org.elasticsearch.cluster.routing.OperationRouting#searchShards public GroupShardsIterator<ShardIterator> searchShards(ClusterState clusterState, String[] concreteIndices, @Nullable Map<String, Set<String>> routing, @Nullable String preference, @Nullable ResponseCollectorService collectorService, @Nullable Map<String, Long> nodeCounts) { final Set<IndexShardRoutingTable> shards = computeTargetedShards(clusterState, concreteIndices, routing); final Set<ShardIterator> set = new HashSet<>(shards.size()); for (IndexShardRoutingTable shard : shards) { ShardIterator iterator = preferenceActiveShardIterator(shard, clusterState.nodes().getLocalNodeId(), clusterState.nodes(), preference, collectorService, nodeCounts); if (iterator != null) { set.add(iterator); } } return GroupShardsIterator.sortAndCreate(new ArrayList<>(set)); } // org.elasticsearch.cluster.routing.OperationRouting#computeTargetedShards private Set<IndexShardRoutingTable> computeTargetedShards(ClusterState clusterState, String[] concreteIndices, @Nullable Map<String, Set<String>> routing) { routing = routing == null ? EMPTY_ROUTING : routing; // just use an empty map final Set<IndexShardRoutingTable> set = new HashSet<>(); // we use set here and not list since we might get duplicates for (String index : concreteIndices) { final IndexRoutingTable indexRouting = indexRoutingTable(clusterState, index); final IndexMetadata indexMetadata = indexMetadata(clusterState, index); final Set<String> effectiveRouting = routing.get(index); if (effectiveRouting != null) { for (String r : effectiveRouting) { final int routingPartitionSize = indexMetadata.getRoutingPartitionSize(); for (int partitionOffset = 0; partitionOffset < routingPartitionSize; partitionOffset++) { set.add(RoutingTable.shardRoutingTable(indexRouting, calculateScaledShardId(indexMetadata, r, partitionOffset))); } } } else { for (IndexShardRoutingTable indexShard : indexRouting) { set.add(indexShard); } } } return set; }
之后便使用 asyncExecutor执行start() 开启搜索分发。
// org.elasticsearch.action.search.TransportSearchAction#buildConnectionLookup static BiFunction<String, String, Transport.Connection> buildConnectionLookup(String requestClusterAlias, Function<String, DiscoveryNode> localNodes, BiFunction<String, String, DiscoveryNode> remoteNodes, BiFunction<String, DiscoveryNode, Transport.Connection> nodeToConnection) { return (clusterAlias, nodeId) -> { final DiscoveryNode discoveryNode; final boolean remoteCluster; if (clusterAlias == null || requestClusterAlias != null) { assert requestClusterAlias == null || requestClusterAlias.equals(clusterAlias); discoveryNode = localNodes.apply(nodeId); remoteCluster = false; } else { discoveryNode = remoteNodes.apply(clusterAlias, nodeId); remoteCluster = true; } if (discoveryNode == null) { throw new IllegalStateException("no node found for id: " + nodeId); } return nodeToConnection.apply(remoteCluster ? clusterAlias : null, discoveryNode); }; } // org.elasticsearch.action.search.TransportSearchAction#asyncSearchExecutor Executor asyncSearchExecutor(final String[] indices, final ClusterState clusterState) { final boolean onlySystemIndices = Arrays.stream(indices) .allMatch(index -> { final IndexMetadata indexMetadata = clusterState.metadata().index(index); return indexMetadata != null && indexMetadata.isSystem(); }); return onlySystemIndices ? threadPool.executor(ThreadPool.Names.SYSTEM_READ) : threadPool.executor(ThreadPool.Names.SEARCH); } // org.elasticsearch.action.search.AbstractSearchAsyncAction#start /** * This is the main entry point for a search. This method starts the search execution of the initial phase. */ public final void start() { if (getNumShards() == 0) { //no search shards to search on, bail with empty response //(it happens with search across _all with no indices around and consistent with broadcast operations) int trackTotalHitsUpTo = request.source() == null ? SearchContext.DEFAULT_TRACK_TOTAL_HITS_UP_TO : request.source().trackTotalHitsUpTo() == null ? SearchContext.DEFAULT_TRACK_TOTAL_HITS_UP_TO : request.source().trackTotalHitsUpTo(); // total hits is null in the response if the tracking of total hits is disabled boolean withTotalHits = trackTotalHitsUpTo != SearchContext.TRACK_TOTAL_HITS_DISABLED; listener.onResponse(new SearchResponse(InternalSearchResponse.empty(withTotalHits), null, 0, 0, 0, buildTookInMillis(), ShardSearchFailure.EMPTY_ARRAY, clusters, null)); return; } executePhase(this); } // org.elasticsearch.action.search.AbstractSearchAsyncAction#executePhase private void executePhase(SearchPhase phase) { try { phase.run(); } catch (Exception e) { if (logger.isDebugEnabled()) { logger.debug(new ParameterizedMessage("Failed to execute [{}] while moving to [{}] phase", request, phase.getName()), e); } onPhaseFailure(phase, "", e); } }
最终 search 会以异步run的形式到达,并迭代shard运行。
// org.elasticsearch.action.search.AbstractSearchAsyncAction#run @Override public final void run() { for (final SearchShardIterator iterator : toSkipShardsIts) { assert iterator.skip(); skipShard(iterator); } if (shardsIts.size() > 0) { assert request.allowPartialSearchResults() != null : "SearchRequest missing setting for allowPartialSearchResults"; if (request.allowPartialSearchResults() == false) { final StringBuilder missingShards = new StringBuilder(); // Fail-fast verification of all shards being available for (int index = 0; index < shardsIts.size(); index++) { final SearchShardIterator shardRoutings = shardsIts.get(index); if (shardRoutings.size() == 0) { if(missingShards.length() > 0){ missingShards.append(", "); } missingShards.append(shardRoutings.shardId()); } } if (missingShards.length() > 0) { //Status red - shard is missing all copies and would produce partial results for an index search final String msg = "Search rejected due to missing shards ["+ missingShards + "]. Consider using `allow_partial_search_results` setting to bypass this error."; throw new SearchPhaseExecutionException(getName(), msg, null, ShardSearchFailure.EMPTY_ARRAY); } } // 多个shard运行搜索 for (int i = 0; i < shardsIts.size(); i++) { final SearchShardIterator shardRoutings = shardsIts.get(i); assert shardRoutings.skip() == false; assert shardItIndexMap.containsKey(shardRoutings); int shardIndex = shardItIndexMap.get(shardRoutings); performPhaseOnShard(shardIndex, shardRoutings, shardRoutings.nextOrNull()); } } } // org.elasticsearch.action.search.AbstractSearchAsyncAction#performPhaseOnShard protected void performPhaseOnShard(final int shardIndex, final SearchShardIterator shardIt, final SearchShardTarget shard) { /* * We capture the thread that this phase is starting on. When we are called back after executing the phase, we are either on the * same thread (because we never went async, or the same thread was selected from the thread pool) or a different thread. If we * continue on the same thread in the case that we never went async and this happens repeatedly we will end up recursing deeply and * could stack overflow. To prevent this, we fork if we are called back on the same thread that execution started on and otherwise * we can continue (cf. InitialSearchPhase#maybeFork). */ if (shard == null) { SearchShardTarget unassignedShard = new SearchShardTarget(null, shardIt.shardId(), shardIt.getClusterAlias(), shardIt.getOriginalIndices()); fork(() -> onShardFailure(shardIndex, unassignedShard, shardIt, new NoShardAvailableActionException(shardIt.shardId()))); } else { final PendingExecutions pendingExecutions = throttleConcurrentRequests ? pendingExecutionsPerNode.computeIfAbsent(shard.getNodeId(), n -> new PendingExecutions(maxConcurrentRequestsPerNode)) : null; Runnable r = () -> { final Thread thread = Thread.currentThread(); try { // 在单shard上搜索 executePhaseOnShard(shardIt, shard, new SearchActionListener<Result>(shard, shardIndex) { @Override public void innerOnResponse(Result result) { try { onShardResult(result, shardIt); } catch (Exception exc) { onShardFailure(shardIndex, shard, shardIt, exc); } finally { executeNext(pendingExecutions, thread); } } @Override public void onFailure(Exception t) { try { onShardFailure(shardIndex, shard, shardIt, t); } finally { executeNext(pendingExecutions, thread); } } }); } catch (final Exception e) { try { /* * It is possible to run into connection exceptions here because we are getting the connection early and might * run into nodes that are not connected. In this case, on shard failure will move us to the next shard copy. */ fork(() -> onShardFailure(shardIndex, shard, shardIt, e)); } finally { executeNext(pendingExecutions, thread); } } }; // 排队或立即运行 if (throttleConcurrentRequests) { pendingExecutions.tryRun(r); } else { r.run(); } } } // org.elasticsearch.action.search.SearchQueryThenFetchAsyncAction#executePhaseOnShard protected void executePhaseOnShard(final SearchShardIterator shardIt, final SearchShardTarget shard, final SearchActionListener<SearchPhaseResult> listener) { // 构造search请求 ShardSearchRequest request = rewriteShardSearchRequest( super.buildShardSearchRequest(shardIt, listener.requestIndex)); // 发送 search 请求到对应节点,而对于本地节点则mock一个connection, 直接执行本地搜索 getSearchTransport() .sendExecuteQuery( getConnection(shard.getClusterAlias(), shard.getNodeId()), request, getTask(), listener); } // org.elasticsearch.action.search.AbstractSearchAsyncAction#buildShardSearchRequest @Override public final ShardSearchRequest buildShardSearchRequest(SearchShardIterator shardIt, int shardIndex) { AliasFilter filter = aliasFilter.get(shardIt.shardId().getIndex().getUUID()); assert filter != null; float indexBoost = concreteIndexBoosts.getOrDefault(shardIt.shardId().getIndex().getUUID(), DEFAULT_INDEX_BOOST); ShardSearchRequest shardRequest = new ShardSearchRequest(shardIt.getOriginalIndices(), request, shardIt.shardId(), shardIndex, getNumShards(), filter, indexBoost, timeProvider.getAbsoluteStartMillis(), shardIt.getClusterAlias(), shardIt.getSearchContextId(), shardIt.getSearchContextKeepAlive()); // if we already received a search result we can inform the shard that it // can return a null response if the request rewrites to match none rather // than creating an empty response in the search thread pool. // Note that, we have to disable this shortcut for queries that create a context (scroll and search context). shardRequest.canReturnNullResponseIfMatchNoDocs(hasShardResponse.get() && shardRequest.scroll() == null); return shardRequest; }
发送请求过程之前我们细细见识过,此处可忽略。
// org.elasticsearch.action.search.SearchTransportService#sendExecuteQuery public void sendExecuteQuery(Transport.Connection connection, final ShardSearchRequest request, SearchTask task, final SearchActionListener<SearchPhaseResult> listener) { // we optimize this and expect a QueryFetchSearchResult if we only have a single shard in the search request // this used to be the QUERY_AND_FETCH which doesn't exist anymore. final boolean fetchDocuments = request.numberOfShards() == 1; Writeable.Reader<SearchPhaseResult> reader = fetchDocuments ? QueryFetchSearchResult::new : QuerySearchResult::new; final ActionListener handler = responseWrapper.apply(connection, listener); transportService.sendChildRequest(connection, QUERY_ACTION_NAME, request, task, new ConnectionCountingHandler<>(handler, reader, clientConnections, connection.getNode().getId())); } // org.elasticsearch.transport.TransportService#sendChildRequest public <T extends TransportResponse> void sendChildRequest(final Transport.Connection connection, final String action, final TransportRequest request, final Task parentTask, final TransportResponseHandler<T> handler) { sendChildRequest(connection, action, request, parentTask, TransportRequestOptions.EMPTY, handler); } // org.elasticsearch.transport.TransportService#sendChildRequest public <T extends TransportResponse> void sendChildRequest(final Transport.Connection connection, final String action, final TransportRequest request, final Task parentTask, final TransportRequestOptions options, final TransportResponseHandler<T> handler) { request.setParentTask(localNode.getId(), parentTask.getId()); sendRequest(connection, action, request, options, handler); } // org.elasticsearch.transport.TransportService#sendRequest /** * Sends a request on the specified connection. If there is a failure sending the request, the specified handler is invoked. * * @param connection the connection to send the request on * @param action the name of the action * @param request the request * @param options the options for this request * @param handler the response handler * @param <T> the type of the transport response */ public final <T extends TransportResponse> void sendRequest(final Transport.Connection connection, final String action, final TransportRequest request, final TransportRequestOptions options, final TransportResponseHandler<T> handler) { try { final TransportResponseHandler<T> delegate; if (request.getParentTask().isSet()) { // If the connection is a proxy connection, then we will create a cancellable proxy task on the proxy node and an actual // child task on the target node of the remote cluster. // ----> a parent task on the local cluster // | // ----> a proxy task on the proxy node on the remote cluster // | // ----> an actual child task on the target node on the remote cluster // To cancel the child task on the remote cluster, we must send a cancel request to the proxy node instead of the target // node as the parent task of the child task is the proxy task not the parent task on the local cluster. Hence, here we // unwrap the connection and keep track of the connection to the proxy node instead of the proxy connection. final Transport.Connection unwrappedConn = unwrapConnection(connection); final Releasable unregisterChildNode = taskManager.registerChildConnection(request.getParentTask().getId(), unwrappedConn); delegate = new TransportResponseHandler<T>() { @Override public void handleResponse(T response) { unregisterChildNode.close(); handler.handleResponse(response); } @Override public void handleException(TransportException exp) { unregisterChildNode.close(); handler.handleException(exp); } @Override public String executor() { return handler.executor(); } @Override public T read(StreamInput in) throws IOException { return handler.read(in); } @Override public String toString() { return getClass().getName() + "/[" + action + "]:" + handler.toString(); } }; } else { delegate = handler; } asyncSender.sendRequest(connection, action, request, options, delegate); } catch (final Exception ex) { // the caller might not handle this so we invoke the handler final TransportException te; if (ex instanceof TransportException) { te = (TransportException) ex; } else { te = new TransportException("failure to send", ex); } handler.handleException(te); } } // org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor#interceptSender @Override public AsyncSender interceptSender(AsyncSender sender) { return new AsyncSender() { @Override public <T extends TransportResponse> void sendRequest(Transport.Connection connection, String action, TransportRequest request, TransportRequestOptions options, TransportResponseHandler<T> handler) { final boolean requireAuth = shouldRequireExistingAuthentication(); // the transport in core normally does this check, BUT since we are serializing to a string header we need to do it // ourselves otherwise we wind up using a version newer than what we can actually send final Version minVersion = Version.min(connection.getVersion(), Version.CURRENT); // Sometimes a system action gets executed like a internal create index request or update mappings request // which means that the user is copied over to system actions so we need to change the user if (AuthorizationUtils.shouldReplaceUserWithSystem(threadPool.getThreadContext(), action)) { securityContext.executeAsUser(SystemUser.INSTANCE, (original) -> sendWithUser(connection, action, request, options, new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original) , handler), sender, requireAuth), minVersion); } else if (AuthorizationUtils.shouldSetUserBasedOnActionOrigin(threadPool.getThreadContext())) { AuthorizationUtils.switchUserBasedOnActionOriginAndExecute(threadPool.getThreadContext(), securityContext, (original) -> sendWithUser(connection, action, request, options, new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original) , handler), sender, requireAuth)); } else if (securityContext.getAuthentication() != null && securityContext.getAuthentication().getVersion().equals(minVersion) == false) { // re-write the authentication since we want the authentication version to match the version of the connection securityContext.executeAfterRewritingAuthentication(original -> sendWithUser(connection, action, request, options, new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original), handler), sender, requireAuth), minVersion); } else { sendWithUser(connection, action, request, options, handler, sender, requireAuth); } } }; } // org.elasticsearch.transport.TransportService#sendRequestInternal private <T extends TransportResponse> void sendRequestInternal(final Transport.Connection connection, final String action, final TransportRequest request, final TransportRequestOptions options, TransportResponseHandler<T> handler) { if (connection == null) { throw new IllegalStateException("can't send request to a null connection"); } DiscoveryNode node = connection.getNode(); Supplier<ThreadContext.StoredContext> storedContextSupplier = threadPool.getThreadContext().newRestorableContext(true); ContextRestoreResponseHandler<T> responseHandler = new ContextRestoreResponseHandler<>(storedContextSupplier, handler); // TODO we can probably fold this entire request ID dance into connection.sendReqeust but it will be a bigger refactoring final long requestId = responseHandlers.add(new Transport.ResponseContext<>(responseHandler, connection, action)); final TimeoutHandler timeoutHandler; if (options.timeout() != null) { timeoutHandler = new TimeoutHandler(requestId, connection.getNode(), action); responseHandler.setTimeoutHandler(timeoutHandler); } else { timeoutHandler = null; } try { if (lifecycle.stoppedOrClosed()) { /* * If we are not started the exception handling will remove the request holder again and calls the handler to notify the * caller. It will only notify if toStop hasn't done the work yet. */ throw new NodeClosedException(localNode); } if (timeoutHandler != null) { assert options.timeout() != null; timeoutHandler.scheduleTimeout(options.timeout()); } connection.sendRequest(requestId, action, request, options); // local node optimization happens upstream } catch (final Exception e) { // usually happen either because we failed to connect to the node // or because we failed serializing the message final Transport.ResponseContext<? extends TransportResponse> contextToNotify = responseHandlers.remove(requestId); // If holderToNotify == null then handler has already been taken care of. if (contextToNotify != null) { if (timeoutHandler != null) { timeoutHandler.cancel(); } // callback that an exception happened, but on a different thread since we don't // want handlers to worry about stack overflows. In the special case of running into a closing node we run on the current // thread on a best effort basis though. final SendRequestTransportException sendRequestException = new SendRequestTransportException(node, action, e); final String executor = lifecycle.stoppedOrClosed() ? ThreadPool.Names.SAME : ThreadPool.Names.GENERIC; threadPool.executor(executor).execute(new AbstractRunnable() { @Override public void onRejection(Exception e) { // if we get rejected during node shutdown we don't wanna bubble it up logger.debug( () -> new ParameterizedMessage( "failed to notify response handler on rejection, action: {}", contextToNotify.action()), e); } @Override public void onFailure(Exception e) { logger.warn( () -> new ParameterizedMessage( "failed to notify response handler on exception, action: {}", contextToNotify.action()), e); } @Override protected void doRun() throws Exception { contextToNotify.handler().handleException(sendRequestException); } }); } else { logger.debug("Exception while sending request, handler likely already notified due to timeout", e); } } } // org.elasticsearch.transport.Transport.Connection#sendRequest @Override public void sendRequest(long requestId, String action, TransportRequest request, TransportRequestOptions options) throws TransportException { sendLocalRequest(requestId, action, request, options); } // org.elasticsearch.transport.TransportService#sendLocalRequest private void sendLocalRequest(long requestId, final String action, final TransportRequest request, TransportRequestOptions options) { final DirectResponseChannel channel = new DirectResponseChannel(localNode, action, requestId, this, threadPool); try { onRequestSent(localNode, requestId, action, request, options); onRequestReceived(requestId, action); final RequestHandlerRegistry reg = getRequestHandler(action); if (reg == null) { throw new ActionNotFoundTransportException("Action [" + action + "] not found"); } final String executor = reg.getExecutor(); if (ThreadPool.Names.SAME.equals(executor)) { //noinspection unchecked // ... reg.processMessageReceived(request, channel); } else { threadPool.executor(executor).execute(new AbstractRunnable() { @Override protected void doRun() throws Exception { //noinspection unchecked reg.processMessageReceived(request, channel); } @Override public boolean isForceExecution() { return reg.isForceExecution(); } @Override public void onFailure(Exception e) { try { channel.sendResponse(e); } catch (Exception inner) { inner.addSuppressed(e); logger.warn(() -> new ParameterizedMessage( "failed to notify channel of error message for action [{}]", action), inner); } } @Override public String toString() { return "processing of [" + requestId + "][" + action + "]: " + request; } }); } } catch (Exception e) { try { channel.sendResponse(e); } catch (Exception inner) { inner.addSuppressed(e); logger.warn( () -> new ParameterizedMessage( "failed to notify channel of error message for action [{}]", action), inner); } } }
3. 单节点的搜索实现
前面许多动作,都是在prepare. 但最终,始终要落到lucene上搜索才行。 它将由 SearchService 执行搜索动作。
总体时时序图如下:
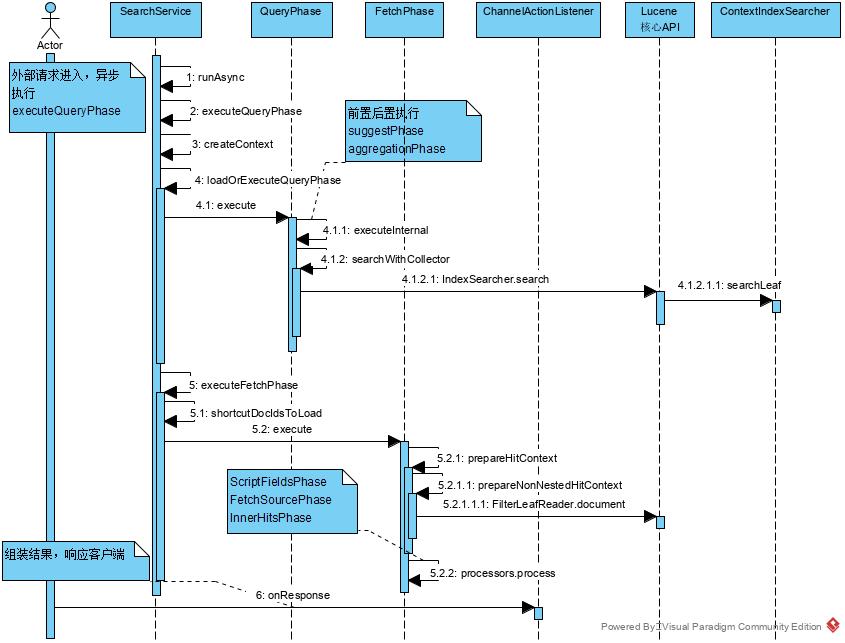
具体代码实现:
// org.elasticsearch.search.SearchService#executeQueryPhase public void executeQueryPhase(ShardSearchRequest request, boolean keepStatesInContext, SearchShardTask task, ActionListener<SearchPhaseResult> listener) { assert request.canReturnNullResponseIfMatchNoDocs() == false || request.numberOfShards() > 1 : "empty responses require more than one shard"; final IndexShard shard = getShard(request); rewriteAndFetchShardRequest(shard, request, new ActionListener<ShardSearchRequest>() { @Override public void onResponse(ShardSearchRequest orig) { // check if we can shortcut the query phase entirely. if (orig.canReturnNullResponseIfMatchNoDocs()) { assert orig.scroll() == null; final CanMatchResponse canMatchResp; try { ShardSearchRequest clone = new ShardSearchRequest(orig); canMatchResp = canMatch(clone, false); } catch (Exception exc) { listener.onFailure(exc); return; } if (canMatchResp.canMatch == false) { listener.onResponse(QuerySearchResult.nullInstance()); return; } } // fork the execution in the search thread pool // 异步运行 executor.execute() runAsync(getExecutor(shard), () -> executeQueryPhase(orig, task, keepStatesInContext), listener); } @Override public void onFailure(Exception exc) { listener.onFailure(exc); } }); } // org.elasticsearch.search.SearchService#executeQueryPhase private SearchPhaseResult executeQueryPhase(ShardSearchRequest request, SearchShardTask task, boolean keepStatesInContext) throws Exception { final ReaderContext readerContext = createOrGetReaderContext(request, keepStatesInContext); try (Releasable ignored = readerContext.markAsUsed(getKeepAlive(request)); // 创建上下文,参数信息,此处将重新解析请求参数 SearchContext context = createContext(readerContext, request, task, true)) { final long afterQueryTime; try (SearchOperationListenerExecutor executor = new SearchOperationListenerExecutor(context)) { // 执行 search, 得到 DocId 信息,放入context中 loadOrExecuteQueryPhase(request, context); if (context.queryResult().hasSearchContext() == false && readerContext.singleSession()) { freeReaderContext(readerContext.id()); } afterQueryTime = executor.success(); } if (request.numberOfShards() == 1) { // 结果集中只存在一个shard, 则可立即查询文档详情 return executeFetchPhase(readerContext, context, afterQueryTime); } else { // 否则,需要再做排序操作后再查询文档详情 // Pass the rescoreDocIds to the queryResult to send them the coordinating node and receive them back in the fetch phase. // We also pass the rescoreDocIds to the LegacyReaderContext in case the search state needs to stay in the data node. final RescoreDocIds rescoreDocIds = context.rescoreDocIds(); context.queryResult().setRescoreDocIds(rescoreDocIds); readerContext.setRescoreDocIds(rescoreDocIds); return context.queryResult(); } } catch (Exception e) { // execution exception can happen while loading the cache, strip it if (e instanceof ExecutionException) { e = (e.getCause() == null || e.getCause() instanceof Exception) ? (Exception) e.getCause() : new ElasticsearchException(e.getCause()); } logger.trace("Query phase failed", e); processFailure(readerContext, e); throw e; } } // org.elasticsearch.search.SearchService#loadOrExecuteQueryPhase /** * Try to load the query results from the cache or execute the query phase directly if the cache cannot be used. */ private void loadOrExecuteQueryPhase(final ShardSearchRequest request, final SearchContext context) throws Exception { final boolean canCache = indicesService.canCache(request, context); context.getQueryShardContext().freezeContext(); if (canCache) { indicesService.loadIntoContext(request, context, queryPhase); } else { queryPhase.execute(context); } }
以上即是单节点搜索框架,查询DocId, 然后视情况查询doc详情。说来倒也简单,只是许多细节,需要知晓。
首先,创建上下文的过程,主要是解析现有参数,备后续使用,以及后续结果也将存入上下文中。按需展开。
// org.elasticsearch.search.SearchService#createContext final SearchContext createContext(ReaderContext readerContext, ShardSearchRequest request, SearchShardTask task, boolean includeAggregations) throws IOException { final DefaultSearchContext context = createSearchContext(readerContext, request, defaultSearchTimeout); try { if (request.scroll() != null) { context.scrollContext().scroll = request.scroll(); } // 解析参数 parseSource(context, request.source(), includeAggregations); // if the from and size are still not set, default them // DEFAULT_FROM=0 if (context.from() == -1) { context.from(DEFAULT_FROM); } // DEFAULT_SIZE=10 if (context.size() == -1) { context.size(DEFAULT_SIZE); } context.setTask(task); // pre process queryPhase.preProcess(context); } catch (Exception e) { context.close(); throw e; } return context; } // org.elasticsearch.search.SearchService#parseSource private void parseSource(DefaultSearchContext context, SearchSourceBuilder source, boolean includeAggregations) { // nothing to parse... if (source == null) { return; } SearchShardTarget shardTarget = context.shardTarget(); QueryShardContext queryShardContext = context.getQueryShardContext(); context.from(source.from()); context.size(source.size()); Map<String, InnerHitContextBuilder> innerHitBuilders = new HashMap<>(); // 解析query if (source.query() != null) { InnerHitContextBuilder.extractInnerHits(source.query(), innerHitBuilders); context.parsedQuery(queryShardContext.toQuery(source.query())); } // 解析 post_filter if (source.postFilter() != null) { InnerHitContextBuilder.extractInnerHits(source.postFilter(), innerHitBuilders); context.parsedPostFilter(queryShardContext.toQuery(source.postFilter())); } if (innerHitBuilders.size() > 0) { for (Map.Entry<String, InnerHitContextBuilder> entry : innerHitBuilders.entrySet()) { try { entry.getValue().build(context, context.innerHits()); } catch (IOException e) { throw new SearchException(shardTarget, "failed to build inner_hits", e); } } } if (source.sorts() != null) { try { Optional<SortAndFormats> optionalSort = SortBuilder.buildSort(source.sorts(), context.getQueryShardContext()); if (optionalSort.isPresent()) { context.sort(optionalSort.get()); } } catch (IOException e) { throw new SearchException(shardTarget, "failed to create sort elements", e); } } context.trackScores(source.trackScores()); if (source.trackTotalHitsUpTo() != null && source.trackTotalHitsUpTo() != SearchContext.TRACK_TOTAL_HITS_ACCURATE && context.scrollContext() != null) { throw new SearchException(shardTarget, "disabling [track_total_hits] is not allowed in a scroll context"); } if (source.trackTotalHitsUpTo() != null) { context.trackTotalHitsUpTo(source.trackTotalHitsUpTo()); } if (source.minScore() != null) { context.minimumScore(source.minScore()); } if (source.profile()) { context.setProfilers(new Profilers(context.searcher())); } if (source.timeout() != null) { context.timeout(source.timeout()); } context.terminateAfter(source.terminateAfter()); // 聚合解析 if (source.aggregations() != null && includeAggregations) { AggregationContext aggContext = new ProductionAggregationContext( context.getQueryShardContext(), /* * The query on the search context right now doesn't include * the filter for nested documents or slicing so we have to * delay reading it until the aggs ask for it. */ () -> context.query() == null ? new MatchAllDocsQuery() : context.query(), context.getProfilers() == null ? null : context.getProfilers().getAggregationProfiler(), multiBucketConsumerService.create(), () -> new SubSearchContext(context).parsedQuery(context.parsedQuery()).fetchFieldsContext(context.fetchFieldsContext()), context::addReleasable, context.bitsetFilterCache(), context.indexShard().shardId().hashCode(), context::getRelativeTimeInMillis, context::isCancelled ); try { AggregatorFactories factories = source.aggregations().build(aggContext, null); context.aggregations(new SearchContextAggregations(factories)); } catch (IOException e) { throw new AggregationInitializationException("Failed to create aggregators", e); } } if (source.suggest() != null) { try { context.suggest(source.suggest().build(queryShardContext)); } catch (IOException e) { throw new SearchException(shardTarget, "failed to create SuggestionSearchContext", e); } } if (source.rescores() != null) { try { for (RescorerBuilder<?> rescore : source.rescores()) { context.addRescore(rescore.buildContext(queryShardContext)); } } catch (IOException e) { throw new SearchException(shardTarget, "failed to create RescoreSearchContext", e); } } if (source.explain() != null) { context.explain(source.explain()); } if (source.fetchSource() != null) { context.fetchSourceContext(source.fetchSource()); } if (source.docValueFields() != null) { FetchDocValuesContext docValuesContext = new FetchDocValuesContext(context.getQueryShardContext(), source.docValueFields()); context.docValuesContext(docValuesContext); } if (source.fetchFields() != null) { FetchFieldsContext fetchFieldsContext = new FetchFieldsContext(source.fetchFields()); context.fetchFieldsContext(fetchFieldsContext); } if (source.highlighter() != null) { HighlightBuilder highlightBuilder = source.highlighter(); try { context.highlight(highlightBuilder.build(queryShardContext)); } catch (IOException e) { throw new SearchException(shardTarget, "failed to create SearchContextHighlighter", e); } } if (source.scriptFields() != null && source.size() != 0) { int maxAllowedScriptFields = queryShardContext.getIndexSettings().getMaxScriptFields(); if (source.scriptFields().size() > maxAllowedScriptFields) { throw new IllegalArgumentException( "Trying to retrieve too many script_fields. Must be less than or equal to: [" + maxAllowedScriptFields + "] but was [" + source.scriptFields().size() + "]. This limit can be set by changing the [" + IndexSettings.MAX_SCRIPT_FIELDS_SETTING.getKey() + "] index level setting."); } for (org.elasticsearch.search.builder.SearchSourceBuilder.ScriptField field : source.scriptFields()) { FieldScript.Factory factory = scriptService.compile(field.script(), FieldScript.CONTEXT); SearchLookup lookup = context.getQueryShardContext().lookup(); FieldScript.LeafFactory searchScript = factory.newFactory(field.script().getParams(), lookup); context.scriptFields().add(new ScriptField(field.fieldName(), searchScript, field.ignoreFailure())); } } if (source.ext() != null) { for (SearchExtBuilder searchExtBuilder : source.ext()) { context.addSearchExt(searchExtBuilder); } } if (source.version() != null) { context.version(source.version()); } if (source.seqNoAndPrimaryTerm() != null) { context.seqNoAndPrimaryTerm(source.seqNoAndPrimaryTerm()); } if (source.stats() != null) { context.groupStats(source.stats()); } if (CollectionUtils.isEmpty(source.searchAfter()) == false) { if (context.scrollContext() != null) { throw new SearchException(shardTarget, "`search_after` cannot be used in a scroll context."); } if (context.from() > 0) { throw new SearchException(shardTarget, "`from` parameter must be set to 0 when `search_after` is used."); } FieldDoc fieldDoc = SearchAfterBuilder.buildFieldDoc(context.sort(), source.searchAfter()); context.searchAfter(fieldDoc); } if (source.slice() != null) { if (context.scrollContext() == null) { throw new SearchException(shardTarget, "`slice` cannot be used outside of a scroll context"); } context.sliceBuilder(source.slice()); } if (source.storedFields() != null) { if (source.storedFields().fetchFields() == false) { if (context.sourceRequested()) { throw new SearchException(shardTarget, "[stored_fields] cannot be disabled if [_source] is requested"); } if (context.fetchFieldsContext() != null) { throw new SearchException(shardTarget, "[stored_fields] cannot be disabled when using the [fields] option"); } } context.storedFieldsContext(source.storedFields()); } if (source.collapse() != null) { if (context.scrollContext() != null) { throw new SearchException(shardTarget, "cannot use `collapse` in a scroll context"); } if (context.searchAfter() != null) { throw new SearchException(shardTarget, "cannot use `collapse` in conjunction with `search_after`"); } if (context.rescore() != null && context.rescore().isEmpty() == false) { throw new SearchException(shardTarget, "cannot use `collapse` in conjunction with `rescore`"); } final CollapseContext collapseContext = source.collapse().build(queryShardContext); context.collapse(collapseContext); } }
第二、具体查找docId是由 QueryPhase 实现:
// org.elasticsearch.search.query.QueryPhase#execute public void execute(SearchContext searchContext) throws QueryPhaseExecutionException { if (searchContext.hasOnlySuggest()) { suggestPhase.execute(searchContext); searchContext.queryResult().topDocs(new TopDocsAndMaxScore( new TopDocs(new TotalHits(0, TotalHits.Relation.EQUAL_TO), Lucene.EMPTY_SCORE_DOCS), Float.NaN), new DocValueFormat[0]); return; } if (LOGGER.isTraceEnabled()) { LOGGER.trace("{}", new SearchContextSourcePrinter(searchContext)); } // Pre-process aggregations as late as possible. In the case of a DFS_Q_T_F // request, preProcess is called on the DFS phase phase, this is why we pre-process them // here to make sure it happens during the QUERY phase // 几个前置后置处理点,使整体功能齐全 aggregationPhase.preProcess(searchContext); // 执行真正的查询 boolean rescore = executeInternal(searchContext); if (rescore) { // only if we do a regular search rescorePhase.execute(searchContext); } suggestPhase.execute(searchContext); aggregationPhase.execute(searchContext); if (searchContext.getProfilers() != null) { ProfileShardResult shardResults = SearchProfileShardResults .buildShardResults(searchContext.getProfilers()); searchContext.queryResult().profileResults(shardResults); } } // org.elasticsearch.search.query.QueryPhase#executeInternal /** * In a package-private method so that it can be tested without having to * wire everything (mapperService, etc.) * @return whether the rescoring phase should be executed */ static boolean executeInternal(SearchContext searchContext) throws QueryPhaseExecutionException { final ContextIndexSearcher searcher = searchContext.searcher(); SortAndFormats sortAndFormatsForRewrittenNumericSort = null; final IndexReader reader = searcher.getIndexReader(); QuerySearchResult queryResult = searchContext.queryResult(); queryResult.searchTimedOut(false); try { queryResult.from(searchContext.from()); queryResult.size(searchContext.size()); Query query = searchContext.query(); assert query == searcher.rewrite(query); // already rewritten final ScrollContext scrollContext = searchContext.scrollContext(); if (scrollContext != null) { if (scrollContext.totalHits == null) { // first round assert scrollContext.lastEmittedDoc == null; // there is not much that we can optimize here since we want to collect all // documents in order to get the total number of hits } else { final ScoreDoc after = scrollContext.lastEmittedDoc; if (returnsDocsInOrder(query, searchContext.sort())) { // now this gets interesting: since we sort in index-order, we can directly // skip to the desired doc if (after != null) { query = new BooleanQuery.Builder() .add(query, BooleanClause.Occur.MUST) .add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER) .build(); } // ... and stop collecting after ${size} matches searchContext.terminateAfter(searchContext.size()); } else if (canEarlyTerminate(reader, searchContext.sort())) { // now this gets interesting: since the search sort is a prefix of the index sort, we can directly // skip to the desired doc if (after != null) { query = new BooleanQuery.Builder() .add(query, BooleanClause.Occur.MUST) .add(new SearchAfterSortedDocQuery(searchContext.sort().sort, (FieldDoc) after), BooleanClause.Occur.FILTER) .build(); } } } } final LinkedList<QueryCollectorContext> collectors = new LinkedList<>(); // whether the chain contains a collector that filters documents boolean hasFilterCollector = false; if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER) { // add terminate_after before the filter collectors // it will only be applied on documents accepted by these filter collectors collectors.add(createEarlyTerminationCollectorContext(searchContext.terminateAfter())); // this collector can filter documents during the collection hasFilterCollector = true; } if (searchContext.parsedPostFilter() != null) { // add post filters before aggregations // it will only be applied to top hits collectors.add(createFilteredCollectorContext(searcher, searchContext.parsedPostFilter().query())); // this collector can filter documents during the collection hasFilterCollector = true; } if (searchContext.queryCollectors().isEmpty() == false) { // plug in additional collectors, like aggregations collectors.add(createMultiCollectorContext(searchContext.queryCollectors().values())); } if (searchContext.minimumScore() != null) { // apply the minimum score after multi collector so we filter aggs as well collectors.add(createMinScoreCollectorContext(searchContext.minimumScore())); // this collector can filter documents during the collection hasFilterCollector = true; } CheckedConsumer<List<LeafReaderContext>, IOException> leafSorter = l -> {}; // try to rewrite numeric or date sort to the optimized distanceFeatureQuery if ((searchContext.sort() != null) && SYS_PROP_REWRITE_SORT) { Query rewrittenQuery = tryRewriteLongSort(searchContext, searcher.getIndexReader(), query, hasFilterCollector); if (rewrittenQuery != null) { query = rewrittenQuery; // modify sorts: add sort on _score as 1st sort, and move the sort on the original field as the 2nd sort SortField[] oldSortFields = searchContext.sort().sort.getSort(); DocValueFormat[] oldFormats = searchContext.sort().formats; SortField[] newSortFields = new SortField[oldSortFields.length + 1]; DocValueFormat[] newFormats = new DocValueFormat[oldSortFields.length + 1]; newSortFields[0] = SortField.FIELD_SCORE; newFormats[0] = DocValueFormat.RAW; System.arraycopy(oldSortFields, 0, newSortFields, 1, oldSortFields.length); System.arraycopy(oldFormats, 0, newFormats, 1, oldFormats.length); sortAndFormatsForRewrittenNumericSort = searchContext.sort(); // stash SortAndFormats to restore it later searchContext.sort(new SortAndFormats(new Sort(newSortFields), newFormats)); leafSorter = createLeafSorter(oldSortFields[0]); } } boolean timeoutSet = scrollContext == null && searchContext.timeout() != null && searchContext.timeout().equals(SearchService.NO_TIMEOUT) == false; final Runnable timeoutRunnable; if (timeoutSet) { final long startTime = searchContext.getRelativeTimeInMillis(); final long timeout = searchContext.timeout().millis(); final long maxTime = startTime + timeout; timeoutRunnable = searcher.addQueryCancellation(() -> { final long time = searchContext.getRelativeTimeInMillis(); if (time > maxTime) { throw new TimeExceededException(); } }); } else { timeoutRunnable = null; } if (searchContext.lowLevelCancellation()) { searcher.addQueryCancellation(() -> { SearchShardTask task = searchContext.getTask(); if (task != null && task.isCancelled()) { throw new TaskCancelledException("cancelled"); } }); } try { boolean shouldRescore; // if we are optimizing sort and there are no other collectors if (sortAndFormatsForRewrittenNumericSort!=null && collectors.size()==0 && searchContext.getProfilers()==null) { shouldRescore = searchWithCollectorManager(searchContext, searcher, query, leafSorter, timeoutSet); } else { // search... shouldRescore = searchWithCollector(searchContext, searcher, query, collectors, hasFilterCollector, timeoutSet); } // if we rewrote numeric long or date sort, restore fieldDocs based on the original sort if (sortAndFormatsForRewrittenNumericSort!=null) { searchContext.sort(sortAndFormatsForRewrittenNumericSort); // restore SortAndFormats restoreTopFieldDocs(queryResult, sortAndFormatsForRewrittenNumericSort); } ExecutorService executor = searchContext.indexShard().getThreadPool().executor(ThreadPool.Names.SEARCH); if (executor instanceof QueueResizingEsThreadPoolExecutor) { QueueResizingEsThreadPoolExecutor rExecutor = (QueueResizingEsThreadPoolExecutor) executor; queryResult.nodeQueueSize(rExecutor.getCurrentQueueSize()); queryResult.serviceTimeEWMA((long) rExecutor.getTaskExecutionEWMA()); } return shouldRescore; } finally { // Search phase has finished, no longer need to check for timeout // otherwise aggregation phase might get cancelled. if (timeoutRunnable!=null) { searcher.removeQueryCancellation(timeoutRunnable); } } } catch (Exception e) { throw new QueryPhaseExecutionException(searchContext.shardTarget(), "Failed to execute main query", e); } } // org.elasticsearch.search.query.QueryPhase#searchWithCollector private static boolean searchWithCollector(SearchContext searchContext, ContextIndexSearcher searcher, Query query, LinkedList<QueryCollectorContext> collectors, boolean hasFilterCollector, boolean timeoutSet) throws IOException { // create the top docs collector last when the other collectors are known // 创建docs上下文 final TopDocsCollectorContext topDocsFactory = createTopDocsCollectorContext(searchContext, hasFilterCollector); // add the top docs collector, the first collector context in the chain collectors.addFirst(topDocsFactory); final Collector queryCollector; if (searchContext.getProfilers() != null) { InternalProfileCollector profileCollector = QueryCollectorContext.createQueryCollectorWithProfiler(collectors); searchContext.getProfilers().getCurrentQueryProfiler().setCollector(profileCollector); queryCollector = profileCollector; } else { queryCollector = QueryCollectorContext.createQueryCollector(collectors); } QuerySearchResult queryResult = searchContext.queryResult(); try { // 调用lucene接口,执行真正的查询 searcher.search(query, queryCollector); } catch (EarlyTerminatingCollector.EarlyTerminationException e) { queryResult.terminatedEarly(true); } catch (TimeExceededException e) { assert timeoutSet : "TimeExceededException thrown even though timeout wasn't set"; if (searchContext.request().allowPartialSearchResults() == false) { // Can't rethrow TimeExceededException because not serializable throw new QueryPhaseExecutionException(searchContext.shardTarget(), "Time exceeded"); } queryResult.searchTimedOut(true); } if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER && queryResult.terminatedEarly() == null) { queryResult.terminatedEarly(false); } for (QueryCollectorContext ctx : collectors) { ctx.postProcess(queryResult); } return topDocsFactory.shouldRescore(); }
更多。。。
// org.elasticsearch.search.query.TopDocsCollectorContext#createTopDocsCollectorContext /** * Creates a {@link TopDocsCollectorContext} from the provided <code>searchContext</code>. * @param hasFilterCollector True if the collector chain contains at least one collector that can filters document. */ static TopDocsCollectorContext createTopDocsCollectorContext(SearchContext searchContext, boolean hasFilterCollector) throws IOException { final IndexReader reader = searchContext.searcher().getIndexReader(); final Query query = searchContext.query(); // top collectors don't like a size of 0 final int totalNumDocs = Math.max(1, reader.numDocs()); if (searchContext.size() == 0) { // no matter what the value of from is return new EmptyTopDocsCollectorContext(reader, query, searchContext.sort(), searchContext.trackTotalHitsUpTo(), hasFilterCollector); } else if (searchContext.scrollContext() != null) { // we can disable the tracking of total hits after the initial scroll query // since the total hits is preserved in the scroll context. int trackTotalHitsUpTo = searchContext.scrollContext().totalHits != null ? SearchContext.TRACK_TOTAL_HITS_DISABLED : SearchContext.TRACK_TOTAL_HITS_ACCURATE; // no matter what the value of from is int numDocs = Math.min(searchContext.size(), totalNumDocs); return new ScrollingTopDocsCollectorContext(reader, query, searchContext.scrollContext(), searchContext.sort(), numDocs, searchContext.trackScores(), searchContext.numberOfShards(), trackTotalHitsUpTo, hasFilterCollector); } else if (searchContext.collapse() != null) { boolean trackScores = searchContext.sort() == null ? true : searchContext.trackScores(); int numDocs = Math.min(searchContext.from() + searchContext.size(), totalNumDocs); return new CollapsingTopDocsCollectorContext(searchContext.collapse(), searchContext.sort(), numDocs, trackScores); } else { int numDocs = Math.min(searchContext.from() + searchContext.size(), totalNumDocs); final boolean rescore = searchContext.rescore().isEmpty() == false; if (rescore) { assert searchContext.sort() == null; for (RescoreContext rescoreContext : searchContext.rescore()) { numDocs = Math.max(numDocs, rescoreContext.getWindowSize()); } } return new SimpleTopDocsCollectorContext(reader, query, searchContext.sort(), searchContext.searchAfter(), numDocs, searchContext.trackScores(), searchContext.trackTotalHitsUpTo(), hasFilterCollector) { @Override boolean shouldRescore() { return rescore; } }; } } // org.apache.lucene.search.IndexSearcher#search /** Lower-level search API. * * <p>{@link LeafCollector#collect(int)} is called for every matching document. * * @throws BooleanQuery.TooManyClauses If a query would exceed * {@link BooleanQuery#getMaxClauseCount()} clauses. */ public void search(Query query, Collector results) throws IOException { query = rewrite(query); search(leafContexts, createWeight(query, results.scoreMode(), 1), results); } // org.elasticsearch.search.internal.ContextIndexSearcher#search @Override protected void search(List<LeafReaderContext> leaves, Weight weight, Collector collector) throws IOException { for (LeafReaderContext ctx : leaves) { // search each subreader searchLeaf(ctx, weight, collector); } } // org.elasticsearch.search.internal.ContextIndexSearcher#searchLeaf /** * Lower-level search API. * * {@link LeafCollector#collect(int)} is called for every matching document in * the provided <code>ctx</code>. */ private void searchLeaf(LeafReaderContext ctx, Weight weight, Collector collector) throws IOException { cancellable.checkCancelled(); weight = wrapWeight(weight); final LeafCollector leafCollector; try { leafCollector = collector.getLeafCollector(ctx); } catch (CollectionTerminatedException e) { // there is no doc of interest in this reader context // continue with the following leaf return; } Bits liveDocs = ctx.reader().getLiveDocs(); BitSet liveDocsBitSet = getSparseBitSetOrNull(liveDocs); if (liveDocsBitSet == null) { BulkScorer bulkScorer = weight.bulkScorer(ctx); if (bulkScorer != null) { try { bulkScorer.score(leafCollector, liveDocs); } catch (CollectionTerminatedException e) { // collection was terminated prematurely // continue with the following leaf } } } else { // if the role query result set is sparse then we should use the SparseFixedBitSet for advancing: Scorer scorer = weight.scorer(ctx); if (scorer != null) { try { intersectScorerAndBitSet(scorer, liveDocsBitSet, leafCollector, this.cancellable.isEnabled() ? cancellable::checkCancelled: () -> {}); } catch (CollectionTerminatedException e) { // collection was terminated prematurely // continue with the following leaf } } } } // org.apache.lucene.search.BulkScorer#score /** Scores and collects all matching documents. * @param collector The collector to which all matching documents are passed. * @param acceptDocs {@link Bits} that represents the allowed documents to match, or * {@code null} if they are all allowed to match. */ public void score(LeafCollector collector, Bits acceptDocs) throws IOException { final int next = score(collector, acceptDocs, 0, DocIdSetIterator.NO_MORE_DOCS); assert next == DocIdSetIterator.NO_MORE_DOCS; } // org.elasticsearch.search.query.TopDocsCollectorContext.SimpleTopDocsCollectorContext#postProcess @Override void postProcess(QuerySearchResult result) throws IOException { final TopDocsAndMaxScore topDocs = newTopDocs(); result.topDocs(topDocs, sortAndFormats == null ? null : sortAndFormats.formats); } // org.elasticsearch.search.query.TopDocsCollectorContext.SimpleTopDocsCollectorContext#newTopDocs TopDocsAndMaxScore newTopDocs() { TopDocs in = topDocsSupplier.get(); float maxScore = maxScoreSupplier.get(); final TopDocs newTopDocs; if (in instanceof TopFieldDocs) { TopFieldDocs fieldDocs = (TopFieldDocs) in; newTopDocs = new TopFieldDocs(totalHitsSupplier.get(), fieldDocs.scoreDocs, fieldDocs.fields); } else { newTopDocs = new TopDocs(totalHitsSupplier.get(), in.scoreDocs); } return new TopDocsAndMaxScore(newTopDocs, maxScore); }
最后,我们来看下查询到docId后,查询字段信息过程。(一般地,该过程会在所有节点的docId都查找完成之后,由协调节点处理后再进行该阶段操作。但此处,我们相当于走了 QUERY_AND_FETCH 流程,即立即查询结果。)
// org.elasticsearch.search.SearchService#executeFetchPhase private QueryFetchSearchResult executeFetchPhase(ReaderContext reader, SearchContext context, long afterQueryTime) { try (SearchOperationListenerExecutor executor = new SearchOperationListenerExecutor(context, true, afterQueryTime)){ shortcutDocIdsToLoad(context); // 执行查询,将结果写入 context fetchPhase.execute(context); if (reader.singleSession()) { freeReaderContext(reader.id()); } executor.success(); } return new QueryFetchSearchResult(context.queryResult(), context.fetchResult()); } // org.elasticsearch.search.SearchService#shortcutDocIdsToLoad /** * Shortcut ids to load, we load only "from" and up to "size". The phase controller * handles this as well since the result is always size * shards for Q_T_F */ private void shortcutDocIdsToLoad(SearchContext context) { final int[] docIdsToLoad; int docsOffset = 0; final Suggest suggest = context.queryResult().suggest(); int numSuggestDocs = 0; final List<CompletionSuggestion> completionSuggestions; if (suggest != null && suggest.hasScoreDocs()) { completionSuggestions = suggest.filter(CompletionSuggestion.class); for (CompletionSuggestion completionSuggestion : completionSuggestions) { numSuggestDocs += completionSuggestion.getOptions().size(); } } else { completionSuggestions = Collections.emptyList(); } if (context.request().scroll() != null) { TopDocs topDocs = context.queryResult().topDocs().topDocs; docIdsToLoad = new int[topDocs.scoreDocs.length + numSuggestDocs]; for (int i = 0; i < topDocs.scoreDocs.length; i++) { docIdsToLoad[docsOffset++] = topDocs.scoreDocs[i].doc; } } else { TopDocs topDocs = context.queryResult().topDocs().topDocs; if (topDocs.scoreDocs.length < context.from()) { // no more docs... docIdsToLoad = new int[numSuggestDocs]; } else { int totalSize = context.from() + context.size(); docIdsToLoad = new int[Math.min(topDocs.scoreDocs.length - context.from(), context.size()) + numSuggestDocs]; for (int i = context.from(); i < Math.min(totalSize, topDocs.scoreDocs.length); i++) { docIdsToLoad[docsOffset++] = topDocs.scoreDocs[i].doc; } } } for (CompletionSuggestion completionSuggestion : completionSuggestions) { for (CompletionSuggestion.Entry.Option option : completionSuggestion.getOptions()) { docIdsToLoad[docsOffset++] = option.getDoc().doc; } } context.docIdsToLoad(docIdsToLoad, docIdsToLoad.length); } // org.elasticsearch.search.fetch.FetchPhase#execute public void execute(SearchContext context) { if (LOGGER.isTraceEnabled()) { LOGGER.trace("{}", new SearchContextSourcePrinter(context)); } if (context.isCancelled()) { throw new TaskCancelledException("cancelled"); } if (context.docIdsToLoadSize() == 0) { // no individual hits to process, so we shortcut context.fetchResult().hits(new SearchHits(new SearchHit[0], context.queryResult().getTotalHits(), context.queryResult().getMaxScore())); return; } DocIdToIndex[] docs = new DocIdToIndex[context.docIdsToLoadSize()]; for (int index = 0; index < context.docIdsToLoadSize(); index++) { docs[index] = new DocIdToIndex(context.docIdsToLoad()[index], index); } // make sure that we iterate in doc id order Arrays.sort(docs); Map<String, Set<String>> storedToRequestedFields = new HashMap<>(); FieldsVisitor fieldsVisitor = createStoredFieldsVisitor(context, storedToRequestedFields); FetchContext fetchContext = new FetchContext(context); SearchHit[] hits = new SearchHit[context.docIdsToLoadSize()]; List<FetchSubPhaseProcessor> processors = getProcessors(context.shardTarget(), fetchContext); NestedDocuments nestedDocuments = context.getNestedDocuments(); int currentReaderIndex = -1; LeafReaderContext currentReaderContext = null; LeafNestedDocuments leafNestedDocuments = null; CheckedBiConsumer<Integer, FieldsVisitor, IOException> fieldReader = null; boolean hasSequentialDocs = hasSequentialDocs(docs); for (int index = 0; index < context.docIdsToLoadSize(); index++) { if (context.isCancelled()) { throw new TaskCancelledException("cancelled"); } int docId = docs[index].docId; try { int readerIndex = ReaderUtil.subIndex(docId, context.searcher().getIndexReader().leaves()); if (currentReaderIndex != readerIndex) { currentReaderContext = context.searcher().getIndexReader().leaves().get(readerIndex); currentReaderIndex = readerIndex; if (currentReaderContext.reader() instanceof SequentialStoredFieldsLeafReader && hasSequentialDocs && docs.length >= 10) { // All the docs to fetch are adjacent but Lucene stored fields are optimized // for random access and don't optimize for sequential access - except for merging. // So we do a little hack here and pretend we're going to do merges in order to // get better sequential access. SequentialStoredFieldsLeafReader lf = (SequentialStoredFieldsLeafReader) currentReaderContext.reader(); fieldReader = lf.getSequentialStoredFieldsReader()::visitDocument; } else { // reader.documet() 查询文档 fieldReader = currentReaderContext.reader()::document; } for (FetchSubPhaseProcessor processor : processors) { processor.setNextReader(currentReaderContext); } leafNestedDocuments = nestedDocuments.getLeafNestedDocuments(currentReaderContext); } assert currentReaderContext != null; HitContext hit = prepareHitContext( context, leafNestedDocuments, nestedDocuments::hasNonNestedParent, fieldsVisitor, docId, storedToRequestedFields, currentReaderContext, fieldReader); for (FetchSubPhaseProcessor processor : processors) { processor.process(hit); } hits[docs[index].index] = hit.hit(); } catch (Exception e) { throw new FetchPhaseExecutionException(context.shardTarget(), "Error running fetch phase for doc [" + docId + "]", e); } } if (context.isCancelled()) { throw new TaskCancelledException("cancelled"); } TotalHits totalHits = context.queryResult().getTotalHits(); context.fetchResult().hits(new SearchHits(hits, totalHits, context.queryResult().getMaxScore())); } // org.elasticsearch.search.fetch.FetchPhase#prepareHitContext private HitContext prepareHitContext(SearchContext context, LeafNestedDocuments nestedDocuments, Predicate<String> hasNonNestedParent, FieldsVisitor fieldsVisitor, int docId, Map<String, Set<String>> storedToRequestedFields, LeafReaderContext subReaderContext, CheckedBiConsumer<Integer, FieldsVisitor, IOException> storedFieldReader) throws IOException { if (nestedDocuments.advance(docId - subReaderContext.docBase) == null) { return prepareNonNestedHitContext( context, fieldsVisitor, docId, storedToRequestedFields, subReaderContext, storedFieldReader); } else { return prepareNestedHitContext(context, docId, nestedDocuments, hasNonNestedParent, storedToRequestedFields, subReaderContext, storedFieldReader); } } // org.elasticsearch.search.fetch.FetchPhase#prepareNonNestedHitContext /** * Resets the provided {@link HitContext} with information on the current * document. This includes the following: * - Adding an initial {@link SearchHit} instance. * - Loading the document source and setting it on {@link HitContext#sourceLookup()}. This * allows fetch subphases that use the hit context to access the preloaded source. */ private HitContext prepareNonNestedHitContext(SearchContext context, FieldsVisitor fieldsVisitor, int docId, Map<String, Set<String>> storedToRequestedFields, LeafReaderContext subReaderContext, CheckedBiConsumer<Integer, FieldsVisitor, IOException> fieldReader) throws IOException { int subDocId = docId - subReaderContext.docBase; QueryShardContext queryShardContext = context.getQueryShardContext(); if (fieldsVisitor == null) { SearchHit hit = new SearchHit(docId, null, new Text(queryShardContext.getType()), null, null); return new HitContext(hit, subReaderContext, subDocId); } else { SearchHit hit; // 字段填充 loadStoredFields(context.getQueryShardContext()::getFieldType, queryShardContext.getType(), fieldReader, fieldsVisitor, subDocId); Uid uid = fieldsVisitor.uid(); if (fieldsVisitor.fields().isEmpty() == false) { Map<String, DocumentField> docFields = new HashMap<>(); Map<String, DocumentField> metaFields = new HashMap<>(); fillDocAndMetaFields(context, fieldsVisitor, storedToRequestedFields, docFields, metaFields); hit = new SearchHit(docId, uid.id(), new Text(queryShardContext.getType()), docFields, metaFields); } else { // hit 信息返回 hit = new SearchHit(docId, uid.id(), new Text(queryShardContext.getType()), emptyMap(), emptyMap()); } HitContext hitContext = new HitContext(hit, subReaderContext, subDocId); if (fieldsVisitor.source() != null) { // Store the loaded source on the hit context so that fetch subphases can access it. // Also make it available to scripts by storing it on the shared SearchLookup instance. hitContext.sourceLookup().setSource(fieldsVisitor.source()); SourceLookup scriptSourceLookup = context.getQueryShardContext().lookup().source(); scriptSourceLookup.setSegmentAndDocument(subReaderContext, subDocId); scriptSourceLookup.setSource(fieldsVisitor.source()); } return hitContext; } } // org.elasticsearch.search.fetch.FetchPhase#loadStoredFields private void loadStoredFields(Function<String, MappedFieldType> fieldTypeLookup, @Nullable String type, CheckedBiConsumer<Integer, FieldsVisitor, IOException> fieldReader, FieldsVisitor fieldVisitor, int docId) throws IOException { fieldVisitor.reset(); // org.apache.lucene.index.FilterLeafReader#document fieldReader.accept(docId, fieldVisitor); fieldVisitor.postProcess(fieldTypeLookup, type); }
经过如上过程,es已经搜索得到结果,最后就是将结果响应给客户端了。此过程虽不复杂,却也值得一看。
// org.elasticsearch.rest.action.RestStatusToXContentListener#buildResponse @Override public RestResponse buildResponse(Response response, XContentBuilder builder) throws Exception { assert response.isFragment() == false; //would be nice if we could make default methods final response.toXContent(builder, channel.request()); RestResponse restResponse = new BytesRestResponse(response.status(), builder); if (RestStatus.CREATED == restResponse.status()) { final String location = extractLocation.apply(response); if (location != null) { restResponse.addHeader("Location", location); } } return restResponse; }
// org.elasticsearch.action.search.SearchResponse#toXContent @Override public XContentBuilder toXContent(XContentBuilder builder, Params params) throws IOException { builder.startObject(); innerToXContent(builder, params); builder.endObject(); return builder; } // org.elasticsearch.action.search.SearchResponse#innerToXContent public XContentBuilder innerToXContent(XContentBuilder builder, Params params) throws IOException { if (scrollId != null) { builder.field(SCROLL_ID.getPreferredName(), scrollId); } if (pointInTimeId != null) { builder.field(POINT_IN_TIME_ID.getPreferredName(), pointInTimeId); } builder.field(TOOK.getPreferredName(), tookInMillis); builder.field(TIMED_OUT.getPreferredName(), isTimedOut()); if (isTerminatedEarly() != null) { builder.field(TERMINATED_EARLY.getPreferredName(), isTerminatedEarly()); } if (getNumReducePhases() != 1) { builder.field(NUM_REDUCE_PHASES.getPreferredName(), getNumReducePhases()); } RestActions.buildBroadcastShardsHeader(builder, params, getTotalShards(), getSuccessfulShards(), getSkippedShards(), getFailedShards(), getShardFailures()); clusters.toXContent(builder, params); internalResponse.toXContent(builder, params); return builder; } // org.elasticsearch.action.search.SearchResponseSections#toXContent @Override public final XContentBuilder toXContent(XContentBuilder builder, Params params) throws IOException { hits.toXContent(builder, params); if (aggregations != null) { aggregations.toXContent(builder, params); } if (suggest != null) { suggest.toXContent(builder, params); } if (profileResults != null) { profileResults.toXContent(builder, params); } return builder; } @Override public XContentBuilder toXContent(XContentBuilder builder, Params params) throws IOException { builder.startObject(Fields.HITS); boolean totalHitAsInt = params.paramAsBoolean(RestSearchAction.TOTAL_HITS_AS_INT_PARAM, false); if (totalHitAsInt) { long total = totalHits == null ? -1 : totalHits.value; builder.field(Fields.TOTAL, total); } else if (totalHits != null) { builder.startObject(Fields.TOTAL); builder.field("value", totalHits.value); builder.field("relation", totalHits.relation == Relation.EQUAL_TO ? "eq" : "gte"); builder.endObject(); } if (Float.isNaN(maxScore)) { builder.nullField(Fields.MAX_SCORE); } else { builder.field(Fields.MAX_SCORE, maxScore); } builder.field(Fields.HITS); builder.startArray(); for (SearchHit hit : hits) { hit.toXContent(builder, params); } builder.endArray(); builder.endObject(); return builder; } // org.elasticsearch.search.SearchHit#toXContent @Override public XContentBuilder toXContent(XContentBuilder builder, Params params) throws IOException { builder.startObject(); toInnerXContent(builder, params); builder.endObject(); return builder; } // org.elasticsearch.search.SearchHit#toInnerXContent // public because we render hit as part of completion suggestion option public XContentBuilder toInnerXContent(XContentBuilder builder, Params params) throws IOException { // For inner_hit hits shard is null and that is ok, because the parent search hit has all this information. // Even if this was included in the inner_hit hits this would be the same, so better leave it out. if (getExplanation() != null && shard != null) { builder.field(Fields._SHARD, shard.getShardId()); builder.field(Fields._NODE, shard.getNodeIdText()); } if (index != null) { builder.field(Fields._INDEX, RemoteClusterAware.buildRemoteIndexName(clusterAlias, index)); } if (type != null) { builder.field(Fields._TYPE, type); } if (id != null) { builder.field(Fields._ID, id); } if (nestedIdentity != null) { nestedIdentity.toXContent(builder, params); } if (version != -1) { builder.field(Fields._VERSION, version); } if (seqNo != SequenceNumbers.UNASSIGNED_SEQ_NO) { builder.field(Fields._SEQ_NO, seqNo); builder.field(Fields._PRIMARY_TERM, primaryTerm); } if (Float.isNaN(score)) { builder.nullField(Fields._SCORE); } else { builder.field(Fields._SCORE, score); } for (DocumentField field : metaFields.values()) { // ignore empty metadata fields if (field.getValues().size() == 0) { continue; } // _ignored is the only multi-valued meta field // TODO: can we avoid having an exception here? if (field.getName().equals(IgnoredFieldMapper.NAME)) { builder.field(field.getName(), field.getValues()); } else { builder.field(field.getName(), field.<Object>getValue()); } } if (source != null) { XContentHelper.writeRawField(SourceFieldMapper.NAME, source, builder, params); } if (documentFields.isEmpty() == false && // ignore fields all together if they are all empty documentFields.values().stream() .anyMatch(df -> df.getValues().size() > 0)) { builder.startObject(Fields.FIELDS); for (DocumentField field : documentFields.values()) { if (field.getValues().size() > 0) { field.toXContent(builder, params); } } builder.endObject(); } if (highlightFields != null && !highlightFields.isEmpty()) { builder.startObject(Fields.HIGHLIGHT); for (HighlightField field : highlightFields.values()) { field.toXContent(builder, params); } builder.endObject(); } sortValues.toXContent(builder, params); if (matchedQueries.length > 0) { builder.startArray(Fields.MATCHED_QUERIES); for (String matchedFilter : matchedQueries) { builder.value(matchedFilter); } builder.endArray(); } if (getExplanation() != null) { builder.field(Fields._EXPLANATION); buildExplanation(builder, getExplanation()); } if (innerHits != null) { builder.startObject(Fields.INNER_HITS); for (Map.Entry<String, SearchHits> entry : innerHits.entrySet()) { builder.startObject(entry.getKey()); entry.getValue().toXContent(builder, params); builder.endObject(); } builder.endObject(); } return builder; }
本文讲了es search的简要框架过程,并就单个节点的搜索细节给了答案。原没有什么,只供各位看官了解了解罢了。若要知大概,只需两个时序图即可,无须废神。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号