Dubbo(五):集群容错的实现
前两篇中,我们看到了dubbo在负载均衡和服务路由方面的实现,它为集群功能提供了必要的功能。
今天我们再来看另一个集群组件的实现:集群容错。
1. dubbo 集群容错简介
为了避免单点故障,现在的应用通常至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多的服务器。对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题,服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。为了处理这些问题,Dubbo 定义了集群接口 Cluster 以及 Cluster Invoker。集群 Cluster 用途是将多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。
dubbo的集群容错功能由多个组件共同完成:包括 Cluster、Cluster Invoker、Directory、Router 和 LoadBalance 等。它们之间的依赖关系如下:
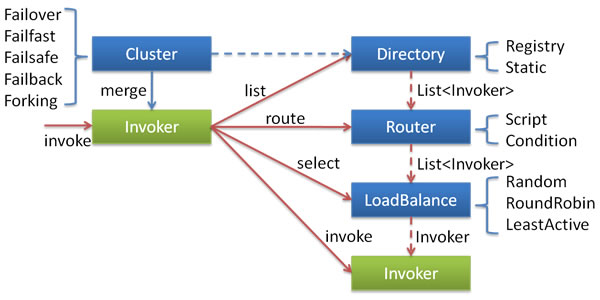
负载均衡、路由服务是在一次调用中进行的,而容错则是当调用发生异常之后,进行处理策略。
dubbo中主要提供了以下几种容错策略实现:
Failover Cluster - 失败自动切换
Failfast Cluster - 快速失败
Failsafe Cluster - 失败安全
Failback Cluster - 失败自动恢复
Forking Cluster - 并行调用多个服务提供者
以上集群容错策略可以通过提供者或者消费者的 service或reference进行配置:
<dubbo:service cluster="failsafe" />
<dubbo:reference cluster="failsafe" />
其优先级同样遵循dubbo设计原则,消费端配置优先,其次是提供端。不配置情况下默认是failover策略,默认重试3次。
2. 集群容错的框架实现
集群接口 Cluster 和 Cluster Invoker,这两者是不同的。Cluster 是接口,而 Cluster Invoker 是一种 Invoker。服务提供者的选择逻辑,以及远程调用失败后的的处理逻辑均是封装在 Cluster Invoker 中。
Cluster 的实现类图如下:

各个Cluster的实现都很简单,也都统一继承了 AbstractCluster, 而该 AbstractCluster 则做了一层统一的拦截器的功能接入,实现如下:
public abstract class AbstractCluster implements Cluster { private <T> Invoker<T> buildClusterInterceptors(AbstractClusterInvoker<T> clusterInvoker, String key) { AbstractClusterInvoker<T> last = clusterInvoker; List<ClusterInterceptor> interceptors = ExtensionLoader.getExtensionLoader(ClusterInterceptor.class).getActivateExtension(clusterInvoker.getUrl(), key); // 根据需要包装ClusterInvoker, 使用切面的方式进行拦截器接入 // 按先后依次强入拦截器 if (!interceptors.isEmpty()) { for (int i = interceptors.size() - 1; i >= 0; i--) { final ClusterInterceptor interceptor = interceptors.get(i); final AbstractClusterInvoker<T> next = last; // 使用内部类进行包装拦截器 // 先后顺序如: beforeC -> beforeB -> beforeA (spring中还有Around) -> afterA -> afterB -> afterC (spring中还有afterReturn) last = new InterceptorInvokerNode<>(clusterInvoker, interceptor, next); } } return last; } @Override public <T> Invoker<T> join(Directory<T> directory) throws RpcException { // ClusterInvoker 调用入口, 让具体策略实现 doJoin(), 并在其基础上进行包装拦截器, 依据来源 reference.interceptor=xxx return buildClusterInterceptors(doJoin(directory), directory.getUrl().getParameter(REFERENCE_INTERCEPTOR_KEY)); } // protected abstract <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException; protected class InterceptorInvokerNode<T> extends AbstractClusterInvoker<T> { private AbstractClusterInvoker<T> clusterInvoker; private ClusterInterceptor interceptor; private AbstractClusterInvoker<T> next; public InterceptorInvokerNode(AbstractClusterInvoker<T> clusterInvoker, ClusterInterceptor interceptor, AbstractClusterInvoker<T> next) { this.clusterInvoker = clusterInvoker; this.interceptor = interceptor; this.next = next; } @Override public Class<T> getInterface() { return clusterInvoker.getInterface(); } @Override public URL getUrl() { return clusterInvoker.getUrl(); } @Override public boolean isAvailable() { return clusterInvoker.isAvailable(); } @Override public Result invoke(Invocation invocation) throws RpcException { Result asyncResult; try { // 拦截器的具体处理逻辑 // 有个 intercept() 的默认方法,其为调用 clusterInvoker.invoke(invocation); 从而实现链式调用 interceptor.before(next, invocation); asyncResult = interceptor.intercept(next, invocation); } catch (Exception e) { // onError callback if (interceptor instanceof ClusterInterceptor.Listener) { ClusterInterceptor.Listener listener = (ClusterInterceptor.Listener) interceptor; listener.onError(e, clusterInvoker, invocation); } throw e; } finally { interceptor.after(next, invocation); } return asyncResult.whenCompleteWithContext((r, t) -> { // onResponse callback if (interceptor instanceof ClusterInterceptor.Listener) { ClusterInterceptor.Listener listener = (ClusterInterceptor.Listener) interceptor; if (t == null) { listener.onMessage(r, clusterInvoker, invocation); } else { listener.onError(t, clusterInvoker, invocation); } } }); } @Override public void destroy() { clusterInvoker.destroy(); } @Override public String toString() { return clusterInvoker.toString(); } @Override protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { // The only purpose is to build a interceptor chain, so the cluster related logic doesn't matter. return null; } } }
接下来,我们详细看看,每个集群容错策略都是如何创建的。
// failover 失败自动切换 public class FailoverCluster extends AbstractCluster { public final static String NAME = "failover"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new FailoverClusterInvoker<>(directory); } } // failfast 快速失败 public class FailfastCluster extends AbstractCluster { public final static String NAME = "failfast"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new FailfastClusterInvoker<>(directory); } } // failsafe 失败安全 public class FailsafeCluster extends AbstractCluster { public final static String NAME = "failsafe"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new FailsafeClusterInvoker<>(directory); } } // failback 失败自动恢复 public class FailbackCluster extends AbstractCluster { public final static String NAME = "failback"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new FailbackClusterInvoker<>(directory); } } // forking 并行调用多个服务提供者 public class ForkingCluster extends AbstractCluster { public final static String NAME = "forking"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new ForkingClusterInvoker<>(directory); } } // mergeable 合并结果容错 public class MergeableCluster extends AbstractCluster { public static final String NAME = "mergeable"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new MergeableClusterInvoker<T>(directory); } }
3. 具体集群容错的实现
failover, 失败自动切换。这是dubbo的默认集群容错策略,因为它是一个比较通用的策略,即只需做重试即可,保证高可用。
整个集群容错策略的调用入口在 AbstractClusterInvoker.invoke() 中,经过一些通用过程调用后,再由具体策略实现 doInvoke();
// org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke @Override public Result invoke(final Invocation invocation) throws RpcException { // 有效性检查 checkWhetherDestroyed(); // binding attachments into invocation. Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments(); if (contextAttachments != null && contextAttachments.size() != 0) { ((RpcInvocation) invocation).addObjectAttachments(contextAttachments); } // 路由服务提供所有的 invokers List<Invoker<T>> invokers = list(invocation); // 获取负载均衡器 LoadBalance loadbalance = initLoadBalance(invokers, invocation); RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation); // 各子类实现 具体的容错逻辑 return doInvoke(invocation, invokers, loadbalance); }
各ClusterInvoker的实现类图如下:

3.1. failover 失败自动切换实现
// org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker#doInvoke @Override @SuppressWarnings({"unchecked", "rawtypes"}) public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { List<Invoker<T>> copyInvokers = invokers; checkInvokers(copyInvokers, invocation); String methodName = RpcUtils.getMethodName(invocation); int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1; if (len <= 0) { len = 1; } // retry loop. RpcException le = null; // last exception. List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers. Set<String> providers = new HashSet<String>(len); // 失败自动切换,就是一个重试的过程 for (int i = 0; i < len; i++) { //Reselect before retry to avoid a change of candidate `invokers`. //NOTE: if `invokers` changed, then `invoked` also lose accuracy. if (i > 0) { // 进行重试时,需要刷新invokers checkWhetherDestroyed(); copyInvokers = list(invocation); // check again checkInvokers(copyInvokers, invocation); } // 使用负载均衡选取一个 invoker Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked); // 将选中的invoker添加到 invoked 中,避免反复选择一个失效的invoker invoked.add(invoker); RpcContext.getContext().setInvokers((List) invoked); try { // 调用选中的invoker 远程服务,成功直接返回了,失败则容错能力上 Result result = invoker.invoke(invocation); if (le != null && logger.isWarnEnabled()) { logger.warn("Although retry the method " + methodName + " in the service " + getInterface().getName() + " was successful by the provider " + invoker.getUrl().getAddress() + ", but there have been failed providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le); } // 调用成功直接返回 return result; } catch (RpcException e) { // 业务异常则直接抛出,不再重试 if (e.isBiz()) { // biz exception. throw e; } le = e; } catch (Throwable e) { le = new RpcException(e.getMessage(), e); } finally { providers.add(invoker.getUrl().getAddress()); } } throw new RpcException(le.getCode(), "Failed to invoke the method " + methodName + " in the service " + getInterface().getName() + ". Tried " + len + " times of the providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le.getCause() != null ? le.getCause() : le); }
总结:failover 容错,即是自动重试各可用提供者的过程。
3.2. failback 失败自动恢复的实现
public FailbackClusterInvoker(Directory<T> directory) { super(directory); // retries=3 int retriesConfig = getUrl().getParameter(RETRIES_KEY, DEFAULT_FAILBACK_TIMES); if (retriesConfig <= 0) { retriesConfig = DEFAULT_FAILBACK_TIMES; } // failbacktasks=100 int failbackTasksConfig = getUrl().getParameter(FAIL_BACK_TASKS_KEY, DEFAULT_FAILBACK_TASKS); if (failbackTasksConfig <= 0) { failbackTasksConfig = DEFAULT_FAILBACK_TASKS; } retries = retriesConfig; failbackTasks = failbackTasksConfig; } // 当调用失败后,将其添加到定时队列中,稍后进行重新请求 private void addFailed(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, Invoker<T> lastInvoker) { if (failTimer == null) { synchronized (this) { if (failTimer == null) { // 以1秒为间隔使用 hash环,扫描任务 failTimer = new HashedWheelTimer( new NamedThreadFactory("failback-cluster-timer", true), 1, TimeUnit.SECONDS, 32, failbackTasks); } } } // 使用 RetryTimerTask 来构建调度的任务 RetryTimerTask retryTimerTask = new RetryTimerTask(loadbalance, invocation, invokers, lastInvoker, retries, RETRY_FAILED_PERIOD); try { failTimer.newTimeout(retryTimerTask, RETRY_FAILED_PERIOD, TimeUnit.SECONDS); } catch (Throwable e) { logger.error("Failback background works error,invocation->" + invocation + ", exception: " + e.getMessage()); } } @Override protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { Invoker<T> invoker = null; try { checkInvokers(invokers, invocation); invoker = select(loadbalance, invocation, invokers, null); // 只调用一次,失败即失败 return invoker.invoke(invocation); } catch (Throwable e) { logger.error("Failback to invoke method " + invocation.getMethodName() + ", wait for retry in background. Ignored exception: " + e.getMessage() + ", ", e); // 添加到失败队列中,稍后进行调度 addFailed(loadbalance, invocation, invokers, invoker); return AsyncRpcResult.newDefaultAsyncResult(null, null, invocation); // ignore } }
总结:failback 容错,即是只做一次调用,失败后会开启后续定时任务进行重新调用的过程。
3.3. failfast 快速失败的实现
// org.apache.dubbo.rpc.cluster.support.FailfastClusterInvoker#doInvoke @Override public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { checkInvokers(invokers, invocation); // 使用负载均衡选取一个 可用的 invoker, 然后进行调用即可 // selected = null, 即只一次选择即可完成select Invoker<T> invoker = select(loadbalance, invocation, invokers, null); try { return invoker.invoke(invocation); } catch (Throwable e) { if (e instanceof RpcException && ((RpcException) e).isBiz()) { // biz exception. throw (RpcException) e; } throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() : 0, "Failfast invoke providers " + invoker.getUrl() + " " + loadbalance.getClass().getSimpleName() + " select from all providers " + invokers + " for service " + getInterface().getName() + " method " + invocation.getMethodName() + " on consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e.getCause() != null ? e.getCause() : e); } } // org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#select /** * Select a invoker using loadbalance policy.</br> * a) Firstly, select an invoker using loadbalance. If this invoker is in previously selected list, or, * if this invoker is unavailable, then continue step b (reselect), otherwise return the first selected invoker</br> * <p> * b) Reselection, the validation rule for reselection: selected > available. This rule guarantees that * the selected invoker has the minimum chance to be one in the previously selected list, and also * guarantees this invoker is available. * * @param loadbalance load balance policy * @param invocation invocation * @param invokers invoker candidates * @param selected exclude selected invokers or not * @return the invoker which will final to do invoke. * @throws RpcException exception */ protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException { if (CollectionUtils.isEmpty(invokers)) { return null; } String methodName = invocation == null ? StringUtils.EMPTY_STRING : invocation.getMethodName(); boolean sticky = invokers.get(0).getUrl() .getMethodParameter(methodName, CLUSTER_STICKY_KEY, DEFAULT_CLUSTER_STICKY); //ignore overloaded method if (stickyInvoker != null && !invokers.contains(stickyInvoker)) { stickyInvoker = null; } //ignore concurrency problem if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) { if (availablecheck && stickyInvoker.isAvailable()) { return stickyInvoker; } } Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected); if (sticky) { stickyInvoker = invoker; } return invoker; } private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException { if (CollectionUtils.isEmpty(invokers)) { return null; } if (invokers.size() == 1) { return invokers.get(0); } Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation); //If the `invoker` is in the `selected` or invoker is unavailable && availablecheck is true, reselect. if ((selected != null && selected.contains(invoker)) || (!invoker.isAvailable() && getUrl() != null && availablecheck)) { try { Invoker<T> rInvoker = reselect(loadbalance, invocation, invokers, selected, availablecheck); if (rInvoker != null) { invoker = rInvoker; } else { //Check the index of current selected invoker, if it's not the last one, choose the one at index+1. int index = invokers.indexOf(invoker); try { //Avoid collision invoker = invokers.get((index + 1) % invokers.size()); } catch (Exception e) { logger.warn(e.getMessage() + " may because invokers list dynamic change, ignore.", e); } } } catch (Throwable t) { logger.error("cluster reselect fail reason is :" + t.getMessage() + " if can not solve, you can set cluster.availablecheck=false in url", t); } } return invoker; }
总结: failfast 容错,使用负载均衡策略选择一次可用的invoker, 进行调用, 异常则抛出,正常则返回结果。
3.4. failsafe 安全失败容错的实现
@Override public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { try { checkInvokers(invokers, invocation); // 与failfast 一样,只使用一次负载均衡策略,选择一个invoker调用即可 // 差别在于返回值,failsafe 不抛出异常,当发生异常时返回一个默认值 Invoker<T> invoker = select(loadbalance, invocation, invokers, null); return invoker.invoke(invocation); } catch (Throwable e) { logger.error("Failsafe ignore exception: " + e.getMessage(), e); // 将异常信息忽略,返回默认值 return AsyncRpcResult.newDefaultAsyncResult(null, null, invocation); // ignore } }
总结: failsafe 容错,即忽略掉所有异常,只返回正式结果。当发生异常时,返回 AsyncRpcResult.newDefaultAsyncResult 作为结果,好像没有发生异常一样。
3.5. forking 并发请求容错实现
// org.apache.dubbo.rpc.cluster.support.ForkingClusterInvoker#doInvoke @Override @SuppressWarnings({"unchecked", "rawtypes"}) public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { try { checkInvokers(invokers, invocation); final List<Invoker<T>> selected; // forks=2 final int forks = getUrl().getParameter(FORKS_KEY, DEFAULT_FORKS); // timeout=1000 final int timeout = getUrl().getParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT); if (forks <= 0 || forks >= invokers.size()) { selected = invokers; } else { selected = new ArrayList<>(forks); while (selected.size() < forks) { Invoker<T> invoker = select(loadbalance, invocation, invokers, selected); if (!selected.contains(invoker)) { //Avoid add the same invoker several times. selected.add(invoker); } } } RpcContext.getContext().setInvokers((List) selected); final AtomicInteger count = new AtomicInteger(); final BlockingQueue<Object> ref = new LinkedBlockingQueue<>(); for (final Invoker<T> invoker : selected) { // 使用线程池进行并发调用 invoker // 线程池为无界队列式: executor = Executors.newCachedThreadPool(new NamedInternalThreadFactory("forking-cluster-timer", true)); executor.execute(() -> { try { Result result = invoker.invoke(invocation); // 只要结果响应,则入队到 ref 中 ref.offer(result); } catch (Throwable e) { int value = count.incrementAndGet(); if (value >= selected.size()) { // 当超过forks 数量的异常发生后,将异常信息写入ref中,即外部可以获取结果了 ref.offer(e); } } }); } try { // 阻塞获取结果,最长等待 timeout // 获取第一个结果作为响应依据 Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS); // 因可以全部异常,获取到的结果可能是个 Throwable 信息,须先判定 if (ret instanceof Throwable) { Throwable e = (Throwable) ret; throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() : 0, "Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e.getCause() != null ? e.getCause() : e); } return (Result) ret; } catch (InterruptedException e) { throw new RpcException("Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e); } } finally { // clear attachments which is binding to current thread. RpcContext.getContext().clearAttachments(); } }
总结: forking 容错,即是同时发起n个并发请求调用提供者,谁最先响应则返回谁的结果。其他结果则全部忽略。可以说是非常耗资源的一种方式了,不过总是有相应的应用场景,所以存在。
3.6. broadcast 广播容错的实现
// org.apache.dubbo.rpc.cluster.support.BroadcastClusterInvoker#doInvoke @Override @SuppressWarnings({"unchecked", "rawtypes"}) public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { checkInvokers(invokers, invocation); RpcContext.getContext().setInvokers((List) invokers); RpcException exception = null; Result result = null; // 向所有invoker发起调用,只要有一个异常,则抛出异常 for (Invoker<T> invoker : invokers) { try { result = invoker.invoke(invocation); } catch (RpcException e) { exception = e; logger.warn(e.getMessage(), e); } catch (Throwable e) { exception = new RpcException(e.getMessage(), e); logger.warn(e.getMessage(), e); } } if (exception != null) { throw exception; } return result; }
总结: broadcast 容错,即向所有invoker发起调用(即广播),全部成功才算成功。
3.7. mergeable 归并容错的实现
// org.apache.dubbo.rpc.cluster.support.MergeableClusterInvoker#doInvoke @Override protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { checkInvokers(invokers, invocation); // merger=xxx String merger = getUrl().getMethodParameter(invocation.getMethodName(), MERGER_KEY); // 没有指定merger, 直接调用一个可用 invoker 即可 if (ConfigUtils.isEmpty(merger)) { // If a method doesn't have a merger, only invoke one Group for (final Invoker<T> invoker : invokers) { if (invoker.isAvailable()) { try { return invoker.invoke(invocation); } catch (RpcException e) { if (e.isNoInvokerAvailableAfterFilter()) { log.debug("No available provider for service" + getUrl().getServiceKey() + " on group " + invoker.getUrl().getParameter(GROUP_KEY) + ", will continue to try another group."); } else { throw e; } } } } // 最后尝试使用第一个 invoker.invoke() return invokers.iterator().next().invoke(invocation); } Class<?> returnType; try { returnType = getInterface().getMethod( invocation.getMethodName(), invocation.getParameterTypes()).getReturnType(); } catch (NoSuchMethodException e) { returnType = null; } Map<String, Result> results = new HashMap<>(); for (final Invoker<T> invoker : invokers) { RpcInvocation subInvocation = new RpcInvocation(invocation, invoker); subInvocation.setAttachment(ASYNC_KEY, "true"); // 异步调用所有 invoker results.put(invoker.getUrl().getServiceKey(), invoker.invoke(subInvocation)); } Object result = null; List<Result> resultList = new ArrayList<Result>(results.size()); for (Map.Entry<String, Result> entry : results.entrySet()) { Result asyncResult = entry.getValue(); try { // 等待所有 invoker 的结果响应 Result r = asyncResult.get(); if (r.hasException()) { log.error("Invoke " + getGroupDescFromServiceKey(entry.getKey()) + " failed: " + r.getException().getMessage(), r.getException()); } else { // 将所有结果放到 resultList 中 resultList.add(r); } } catch (Exception e) { throw new RpcException("Failed to invoke service " + entry.getKey() + ": " + e.getMessage(), e); } } if (resultList.isEmpty()) { return AsyncRpcResult.newDefaultAsyncResult(invocation); } else if (resultList.size() == 1) { // 只有一个结果,则返回一个 Result return resultList.iterator().next(); } if (returnType == void.class) { return AsyncRpcResult.newDefaultAsyncResult(invocation); } if (merger.startsWith(".")) { merger = merger.substring(1); Method method; try { method = returnType.getMethod(merger, returnType); } catch (NoSuchMethodException e) { throw new RpcException("Can not merge result because missing method [ " + merger + " ] in class [ " + returnType.getName() + " ]"); } if (!Modifier.isPublic(method.getModifiers())) { method.setAccessible(true); } result = resultList.remove(0).getValue(); try { if (method.getReturnType() != void.class && method.getReturnType().isAssignableFrom(result.getClass())) { for (Result r : resultList) { result = method.invoke(result, r.getValue()); } } else { for (Result r : resultList) { method.invoke(result, r.getValue()); } } } catch (Exception e) { throw new RpcException("Can not merge result: " + e.getMessage(), e); } } else { Merger resultMerger; // 解析出 merger, 调用 其 merge 方法,返回结果 if (ConfigUtils.isDefault(merger)) { resultMerger = MergerFactory.getMerger(returnType); } else { resultMerger = ExtensionLoader.getExtensionLoader(Merger.class).getExtension(merger); } if (resultMerger != null) { List<Object> rets = new ArrayList<Object>(resultList.size()); for (Result r : resultList) { rets.add(r.getValue()); } // 有很多merger, 都在 org.apache.dubbo.rpc.cluster.merger中, // 如: MapMerger/Array/Boolean/Int/List/Set/ByteArray... result = resultMerger.merge( rets.toArray((Object[]) Array.newInstance(returnType, 0))); } else { throw new RpcException("There is no merger to merge result."); } } return AsyncRpcResult.newDefaultAsyncResult(result, invocation); }
总结: mergeable 容错,依次调用所有invokers, 并通过使用一个merger进行结果合并处理以返回结果。虽然不知道有啥用,但是感觉很厉害的样子。
dubbo的集群容错实现中,使用了 模板方式模式,责任链模式,工厂模式,代理模式,使得各个容错的实现显得相当简洁明了和简单容易。这就是优秀框架的特性吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号