白话说java gc垃圾回收
gc是java区别于其他好几门语言(c/c++)的一个代表功能(当然也有很多可以自动管理内存的语言,如所有的脚本语言,你根本不知道内存管理这回事)!
当然,之所以要把c/c++和java相比,是因为java出现的初衷即是对标c++的缺点的。不管怎么样,gc让程序员gg们不用痛苦地管理内存,这是好事!
回归正题,gc是什么?网上有大片的讲解,但大多显得高深莫测,云里雾里,我想换个角度来讲讲这事。
小白:Garbage Collect 垃圾回收(内存),是一种自动管理内存的一种机制!
下面,我们分几个问题来讨论gc的实现及原理!
一条主线(如果是你会怎么做?):
1. 什么内存可以回收?(回收对象判定)
2. 什么时候回收?(回收时机)
3. 怎么回收?(回收算法)
基本上,我们主要来回答完这几个问题,gc的事情基本就定了!
我们也可以先用简单的三句话来回答上面的问题:
1. 没有用的内存就可以回收了;
2. 在保证回收准确的前提下,随时可以回收;
3. 用高效算法进行回收,保证最小影响业务代码运行;
所以,其实大体思路还是简单的,但是具体做下来就不那么简单了。gc功能经过几十年的发展依然还在完善中,就是最好的证明!
下面我们来细细解答这几个思路!
各表一支(慢慢道来):
1. 什么样的内存可以回收?什么样的内存是没有用的?可以回收的内存,一般来说肯定是没用的内存(有用内存将其删除是高危动作)!
所以,判定什么样的内存是无用内存,就是问题的关键!
通常的简单的,使用引用计数器法推断:给对象添加引用计数器,当一个地方引用时,将计数加1,当引用失效时,将计数器减1;计数器为0,则表示对象不会再被使用了,即是无用内存。
如上便是大名鼎鼎的引用计数算法。这样单独说它,其实是没有问题的,因为就是有的语言就是这么干的,如AS3.0, python等等!
但是,java却是没有采用这种判断方法,判定对象是否无用的。因为这种算法对java而言,存在一个循环引用问题,解决不了。
java中是使用可达性分析算法来判定一个对象是否有用的。
可达性算法原理为:从 gc roots 作为起始点,所有走过的路径为引用链,当一个对象到gc roots不可达时,则证明对象不可达,即对象无引用,可回收。所以,我们只要找出家些不可达gc roots的对象,将其回收即可。
所以,可达性分析剩下两个关键问题:
1. gc roots 在哪里?
2. 分析的起点是 gc roots吗?还是其他对象?
3. 需要扫描所有路径吗?数量怎么样?效率怎么样?
java中规定以下几种对象可作为gc roots:
1. 虚拟机栈中引用的对象(栈帧中的本地变量表中引用的对象);
2. 方法区中静态属性引用的对象;
3. 方法区中常量引用的对象;
4. 本地方法栈中jni引用的对象;
即以以上几种gc roots作为根开始扫描,没有引用的对象可以清除;
为全路径扫描,找不到对象为需要删除的对象;(请查看c++源码扫描解释)
2. 什么时候回收?任何安全准确的时间点进行回收?
在确定了哪些对象可以清除后,找个时间点就可以清除了。其实,在可达性分析后不可达的对象,也可以继续存在:
1. 对象可以finalize()方法中拯救自己一次!(逃逸)
2. 当然,gc不是实时运行的,它的触发时机为:当新生代空间不够将触发一次minor gc,此时幸存下来的对象的年龄则加1;Eden区minor gc后,进入young s1(From)区,再次minor gc还存活的对象年龄加1且被转移到young s2(To)区,年龄超出一般15岁以后,就进入老年代了;当老年代空间也不够放对象时,将触发一次full gc,一般fg都伴随着一次minor gc。
3. 执行内存清理时,需要暂停所有线程,否则会存在一致性问题。暂停所有的线程方式有两种: 1. 抢占式中断,2. 主动式中断;对于睡眠线程,则将其设置为安全区域。在此安全占或安全区域(safepoint)内才可以进行回收!
3. 怎样回收?
怎样高效回收内存!都有些什么算法?
1. 标记-清除算法;白话说就是遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。然后再将堆中所有没被标记的对象全部清除掉,然后再让程序恢复运行。优点是简单;缺点:1. 两个算法效率都不高;2. 回收后会产生内存碎片;
2. 改进1,标记-复制算法;实现方法方式为:将内存分为两块,将其中一块用于存储,当其中一块好的复制到另一块上后,直接清除原来的内存;优点:实现简单,运行高效;缺点是需要使用一半的内存来做备用,浪费空间了。这里还涉及到担保问题。
3. 改进2,标记-整理算法;其实现方式为:找出可清除的区块,让其沿头移动,从而得到归整的内存区域;优点是:不需要额外的空间即可完成gc;缺点则不一定,主要看这个移动算法是否高效了;
4. 分代收集算法;这里是组合多个基础算法的优点而来的算法,也是当下的调用虚拟机的算法。比如年轻代使用复制算法,老年代使用标记整理算法,物尽其用!
把三个问题解答完后,我们把gc外围的东西搞定了,现在让我们看看具体的收集器吧。
毕竟,原理只是原理,只有具体的收集器对我们才更实用呢!
4. 都有些什么垃圾收集器呢?
Serial 是历史悠久的串行收集器;
Serial old 是serial的老年代收集器,采用标记整理算法收集;
ParNew 是serial的多线程版本收集器;
Parallel Scavenge 是专注于吞吐量的并行收集器;
Parallel old 是Parallel Scavenge的老年代版本,使用多线程和标记整理算法进行收集;
CMS Concurrent Mark Sweep, 是一款以获取最短停顿时间为目标的收集器;
G1 Garbage First, 是一款最新的性能最好的垃圾收集器;
如上面几种垃圾收集器,一般都是以组合的形式进行工作的,而不是单个收集器做完所有事情。(当然越往后就越融合为一个收集器做完了)总之,其目标都是一致的,即以不同的方式收集不同类型的内存, 从而达到最佳收集效果!
其中,serial, serial old, parnew, ps, ps old 基本上就如同前面的一句话描述,虽然其实现可能很复杂,但是呈现出来的还是比较简单的。
我们主要看下 CMS 和 G1 两个收集器!
CMS, 是第一款真正的并发收集器。
G1, 筹备了10年才推出第一个正式版本,可见其难度一斑!
CMS收集器是一款追求获得尽量短的停顿时间为目标的收集器,它是基于标记清除算法操作的;
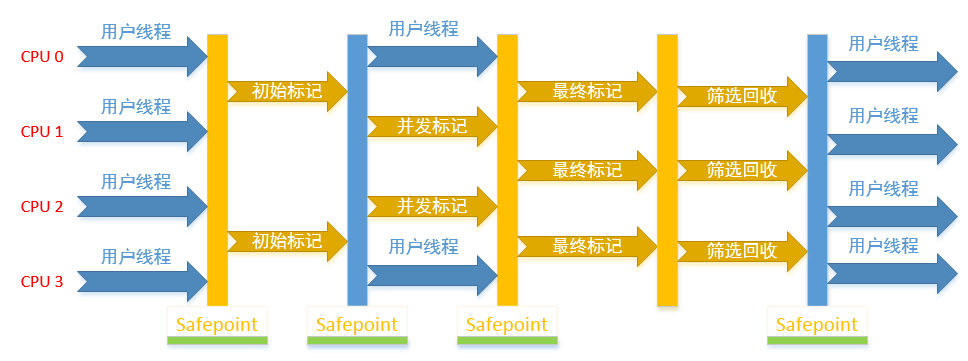
它的运作主要分为4个步骤:
1. 初始标记;(标记gc roots能直接关联到的对象)
2. 并发标记;(对gc roots进行tracing,耗时长)
3. 重新标记;(修正并发标记期间因用户程序运作而改变的对象的标记)
4. 并发清除;(清除标记好的对象空间,耗时长)
这些步骤对于前面几种收集器来说,往往就两个步骤,它是复杂化了的。
它的整体动作过程图示如下:

可以看出,初始标记过程是单线程的,而后续几个动作都是多线程的。其中并发标记和并发清除是和都是可以和用户线程一起工作的,而且这两个过程又是比较耗时的,因此虽然gc一直在工作,但是并没有导致用户长时间的停顿。
有个疑问:并发标记的tracing是什么意思?其实这是个可达性分析的过程,第一步的初始标记仅标记路径,却仍不知道哪些内存是可回收的,所以需要在并发标记过程中,推算出哪些空间是可回收的!(所以,并发标记往往会涉及大量运算?)
cms虽然看起来很好,但是它也有它的缺点,主要体现在:
1. 因为是与用户线程并发,虽不会导致用户线程停顿,但是会抢占cpu资源。所以在cpu资源紧缺的场景则肯定不适合cms了;
2. cms收集器无法处理浮动垃圾,可能会因此导致另一次full gc。因为cms在清理期间用户线程一直在产生垃圾,所以肯定会留下些cms没有收集到的内存,这必须等到下一次gc时才可能回收;而且,由于cms是与用户线程一起工作的,所以,在做清理的同时必须要预留下空间给用户线程使用,所以会收集得更频繁些,比如超过68%的占用时就触发gc;如果在收集期间用户线程的内存不够用了,就会出现“Concurrent Mode Failure”,虚拟机会启用后备预案来进行gc以获得足够空间(serial old),从而导致停顿时间很长问题出现;
3. 并发清除算法会导致内存碎片产生,这在遇到大对象分配时,将无法满足从而会提前触发(可能总体空间还很充足)full gc;当然cms有个开关来解决这问题,-XX:+UseCMSCompactAtFullCollection, 它会在要进行full gc时开户碎片整理过程,当然它的代价是导致停顿时间变长;
综上,我们可以看出cms是个好的收集器,但是它也有自己的短板,如果不顾使用场合地随便应用cms,则可能带来相反的效果;
最后,我们再来看看G1收集器;
G1收集器是个最新的收集器,其研发n的周期也预示了它的难度;粗略地说它是从jdk1.7(7u4)开始面向用户的。
它有如下优势:
1. 并行与并发;与用户线程共存;
2. 分代收集;
3. 空间整合;使用 标记整理算法和复制算法,避免了空间碎片问题;
4. 可预测的停顿;用户可以指定时间,g1会使停顿时间小于设定值;
G1的堆内存总局与其他收集器不同,它是将整个堆分为n个大小相等的region的布局!在回收垃圾时,g1会跟踪各个region里的价值大小,在后台维护一个优先级列表,每次根据允许的收集时间,优先回收价值最大的region。
g1运作大致分为以下几个步骤:
1. 初始标记;(仅标记gc roots能关联到的对象)
2. 并发标记;(可达性分析)
3. 最终标记;(修正并发标记期间的变化,变化被记录在log中)
4. 筛选回收;(将region回收价值排序,根据用户期望进行选择回收计划)
g1的内存分区示意图如下:(n个region)
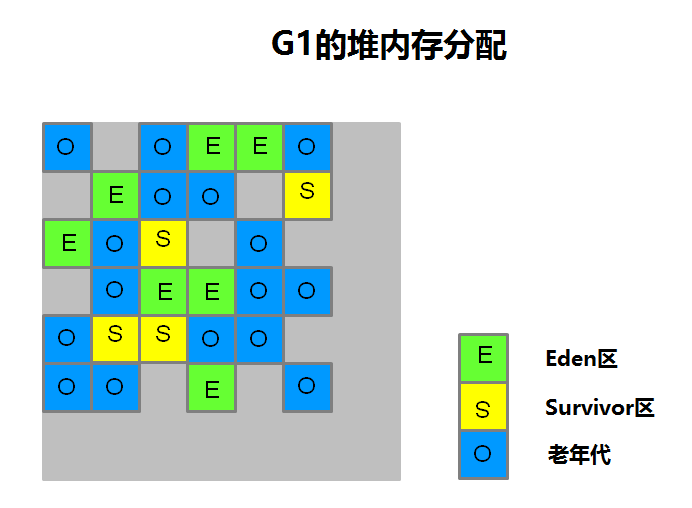
其运行过程与cms大致相似:
G1收集器在jdk1.7中正式亮像,在jdk1.8中做了很多的完善,相信会是越来越多同学的选择的!
本文只是为了讲讲gc的思路,并非从入门到精通!
除了知道收集器名字和原则,还应该要知道怎样控制它。如果你想调优gc配置,请另查资料!
参考: 《深入理解java虚拟机》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号