
网站运维技术与实践之服务器监测常用命令
一、监测的意义
不论是网站运维还是系统管理,服务器本身的运行状况都是我们需要掌控的基础资料。在《打造FaceBook》一书中,王淮介绍FaceBook的工程师文化中有一句“Move Fast and Monitor Closely”。这个"Closely"有两层意义,其一是“即时”的,要从系统开发初期,就有意识地设计好配套的监测,并逐步改善;其二是“深入”,监控不能仅仅停留在监测主机负载、网卡流量的表面层次,而要尽可能地细化,以贴近系统的业务特性。
在系统运行和发展的过程中,监测的重要性得到更进一步的提高。运维人员总是倾向于为了保证稳定性而不轻易对系统做任何改动,所以,运维人员对稳定运行中的系统一举一动都必须要有监测数据的支持。所有的大规模集群运作,包括近年来流行的自动化管理、弹性控制等理念,都要求我们首先对自己的系统的细节有足够的了解。
1.通过命令了解系统的性能概况
1.1 ifconfig命令

结果包含服务器的网卡数目、IP地址、MAC地址、MTU的大小、网卡收发包的情况(丢包和错误包),这些一般是服务器排除故障时需要检查的数据。
1.2 w命令

结果中包含服务器的运行时间、当前用户及其运行程序,以及1分钟、5分钟、10分钟的平均负载。
或许有人会很疑惑,什么是平均负载?
平均负载是反映服务器当前运行状态最直观和简洁的数据。
单核时代,平均负载有如下的经验准则:
(1)如果平均负载大于0.70,趁着事情没有向糟糕的方向发展,赶紧开始找原因(关注原则);
(2)如果负载高于1.00,立刻扔掉其他非重要紧急的事项,先把这个问题修复(针对运维人员,毕竟维护服务器24x7x365稳定运行是运维人员的职责,没有什么是比这个更重要的,因为一旦服务器出问题,公司的业务也会受到很大的影响)(立刻修复原则);
(3)如果负载超过5.00,机器随时可能挂掉,尽可能别出现这种情况,如果出现了,要想尽一切办法解决,不过更好的解决方案是,前期做了充足的监控准备,防止此类事件出现,用一句成语来形容,防微杜渐。
多核时代,新增两条准则:
(1)多核系统上,负载不要高过设备的核心数;
(2)核心如何在CPU分布,这并不重要。两个四核心,四个双核心,八个单核心,效果是一样的。对于计算平均负载来说,它们都是八核心。
当然了,以上的准则,只是在一定条件的情况下总结出的,每个运维人员所面对的服务器情况不一样,需要从实际出发。
比如当核心数多到好几十时,Linux轮询各核心来统计单核负载的耗时长到足以让某些任务状态变化,这时候平均负载会普遍比实际情况低。针对这种情况,Linux内核社区以及有些补丁尽量调整算法。
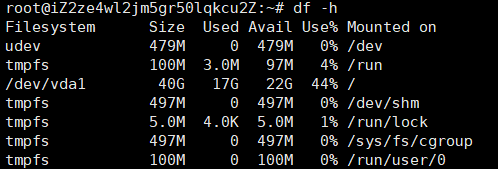
1.3 df
df -h
df -Ti
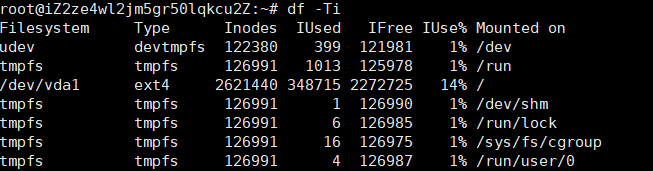
分别查找挂载盘的目录、总容量和使用量、Inode的总量和使用量,以及磁盘文件系统的类型。
1.4 ps
ps的用法太多了
比如我经常用的 ps -ef|grep tomcat 查看tomcat的进程
或者是ps -A查看所有进程等等
1.5 vmstat
通常会使用free命令查看机器的内存使用情况,如

或者free -m(以"兆"的形式显示内存的容量)

vmstat 1 可以用来观察swap的I/O情况,如图:

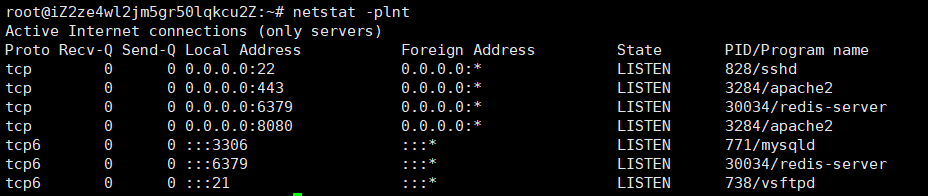
1.6 netstat
netstat 是查看网络相关数据的常用命令,可以用来查看服务器所有的网络层连接状况。
netstat -plnt 命令
1.7 iostat
iostat -x 命令

其中磁盘设备的数据含义如下:
rrqm/s:合并后每秒发送到设备的读入请求数。
wrqm/s:合并后每秒发送到设备的写入请求数。
r/s:每秒发送到设备的读入请求数。
w/s:每秒发送到设备的写入请求数。
rsec/s:每秒从设备读入的扇区数。
wsec/s:每秒从设备写入的扇区数。
rkB/s:每秒从设备读入的数据量,单位为KB。
wkB/s:每秒向设备写入的数据量,单位为KB。
avgrq-sz:发送到设备的请求的平均大小,单位是扇区。
avgqu-sz:发送到设备的请求的平均队列长度。
await:I/O请求平均执行时间,包括发送请求和执行时间,单位是毫秒。
svctm:发送到设备的I/O请求的平均执行时间。单位是毫秒。
$util:在I/O请求发送到设备期间,占用CPU时间的百分比。
一般来说,我们关心每秒的读入请求数、队列长度、请求执行时间和I/O时间占CPU的百分比。
对于磁盘I/O,我们必须要明确一件事情,那就是:
I/O性能的优化是不可能无限提高的。所有机械磁盘的IOPS都在最根本上受限于其机械转动的原理。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述