
Java使用Jsoup之爬取博客数据应用实例
导入Maven依赖

<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency>
选择你要爬取网站(这里我以爬取自己的博客文章为例)
通过浏览器进入这个网址
如我的博客
使用浏览器调试工具(后面会说到这个目的)
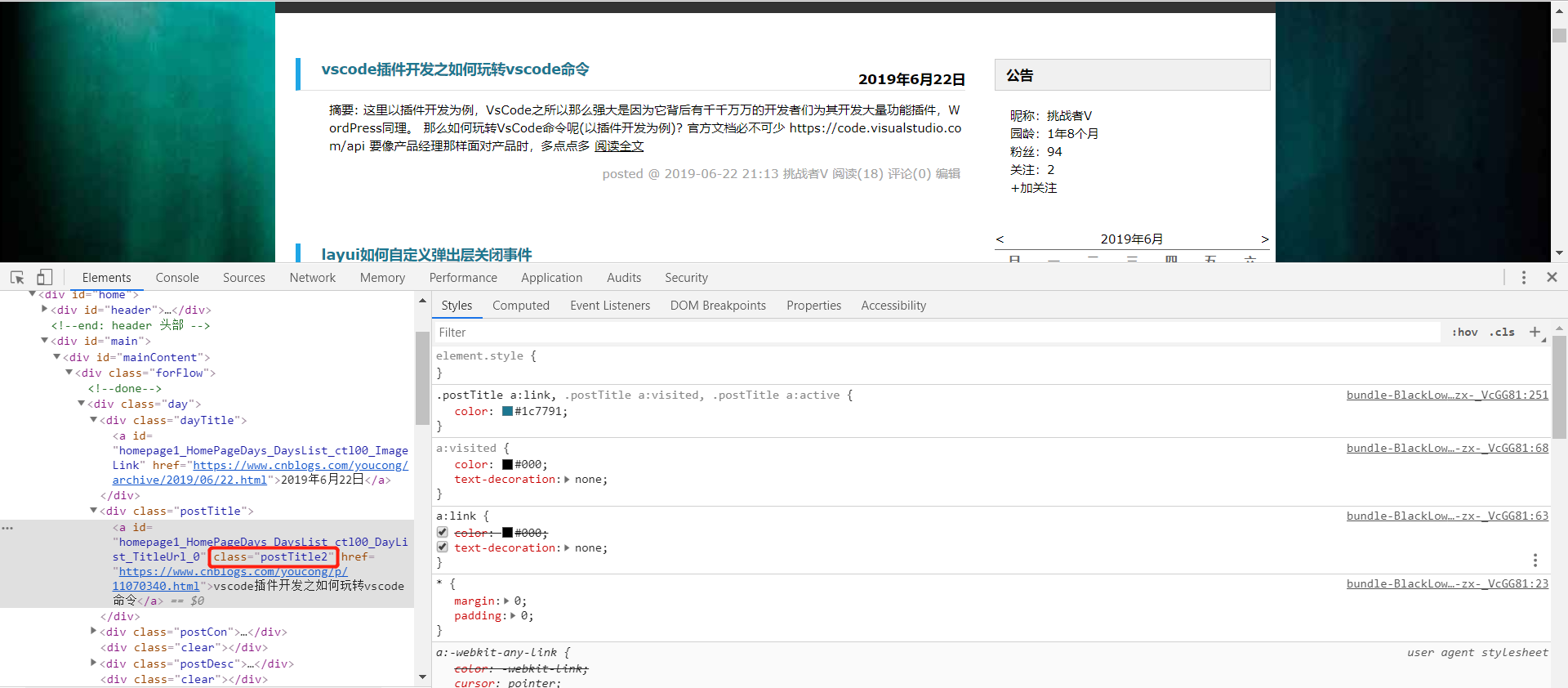
编写对应的Java的代码
package cn.test; import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * A simple example, used on the jsoup website. */ public class BlogJsoup { /** * 获取博客最近十篇文章 * @param args * @throws IOException */ public static void main(String[] args) throws IOException { Connection connection = Jsoup.connect("https://www.cnblogs.com/youcong/"); connection.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"); try { Document document = connection.timeout(100000).get(); //包含所有列表的文章 Elements elements = document.getElementsByClass("postTitle2"); for (Element element : elements) { String path = element.attr("href"); String text = element.text(); String msg = text+" "+path; System.out.println(msg); } } catch (IOException e) { e.printStackTrace(); } } }
上面的代码,用流程可以梳理为如下:
连接爬取的网站->设置浏览器请求头(防止因浏览器的限制导致爬取数据失败)->获取整个HTML(实际就是一个html)->选择HTML中的某一个元素(如类选择器postTitle2,如果不指定对应的元素选择器,那么直接爬取的就是整个HTML)->爬取数据并输出
输出结果如图:

分类:
Java



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述
2018-06-30 wordpress之插件安装和主题安装(包含常见问题)