
<数据结构与算法分析>读书笔记--要分析的问题
通常,要分析的最重要的资源就是运行时间。有几个因素影响着程序的运行时间。有些因素(如使用编译器和计算机)显然超出了任何理论模型的范畴,因此,虽然它们是重要的,但是我们在这里还是不能考虑它们。剩下的主要因素是所使用的算法以及对该算法的输入。
典型的情形是,输入的大小是主要的考虑方面。我们定义两个函数Tavg(N)和Tworst(N),分别为算法对于输入量N所花费的平均运行时间和最坏情况的运行时间。显然,Tavg(N)<=Tworst(N)。
如果存在多于一个的输入,那么这些函数可用有多于一个的变量。
偶尔也分析一个算法的最好情形的性能。不过,通常这没有什么重要意义,因为它不代表典型的行为。平均情形性能常常反映典型的行为,而最坏的性能则代表对任何可能输入的性能一种保证。还要注意,虽然在这一章我们分析的是Java程序,但所得到的界实际上是算法的界而不是程序的界。程序是算法以一种特殊编程语言的实现,程序设计语言的细节几乎总是不影响大于O的答案。如果一个程序比算法分析提出的速度慢得多,那么可能存在低效率的实现。这在类似C++的语言中很普遍,比如,数组可能当作整体而被漫不经心的拷贝,而不是由引用来传递。不管怎么说,这在Java中也可能出现。
一般来说,如果没有相反的指定,则所需要的量是最坏情况的运行时间。其原因之一是它对所有的输入提供了一个界限,包括特别坏的输入,而平均情况分析不提供这样的界。另一个原因是平均情况的界计算起来通常要困难得多。在某些情况下,“平均”的定义可能影响分析的结果。(例如,什么是下属问题的平均输入?)
作为一个例子,我们将在下一节考虑下述问题:
最大子序列和问题:
例如:对于输入-2,11,-4,13,-5,-2,答案为20(从A2到A4) 。
这个问题之所以有吸引力,主要是因为存在求解它的很多算法,而这些算法的性能又差异很大。我们将讨论求解该问题的四种算法。这四种算法在某台计算机上(究竟是哪一台具体的计算机并不重要)的运行时间。如图:
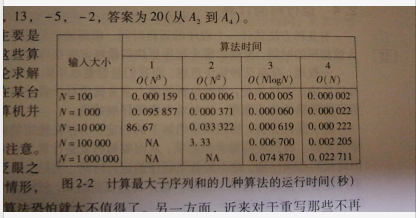
在表中有几个重要的情况值得注意。对于小量的输入,这些算法都在眨眼之间完成,因此如果只是小量输入的情形,那么花费大量的努力去设计聪明的算法恐怕就太不值得了。
另一方面,近来对于重写那些不再合理的基于小输入量假设而在五年以前编写的程序确实存在巨大的市场。现在看来,这些程序太慢了,因为它们用的是一些低劣的算法。对于大量的输入,算法4显然是最好的选择(虽然算法3也可以用)。
其次,表中所给的时间不包括读入数据所需要的时间。对于算法4,仅仅从磁盘读入数据所用的时间很可能在数量级上比求解上述问题所需要的时间还要大。这是许多有效算法的典型特点。数据的读入一般是个瓶颈;一旦数据读入,问题就会迅速解决。但是,对于低效率的算法情况就不同了,它必然要占用大量的计算机资源。因此只要可能,使得算法足够有效而不至成为问题的瓶颈是非常重要的。
注意到具有线性复杂度的算法4表现很好,当问题的规模增长了十倍的时候,其运行的时间也增长十倍。而具有平方复杂度的算法2就不行了,十倍的规模增长导致运行时间大于有百倍(10的2次方)的增长。而立方级复杂度的算法1的运行时间则由千倍(10的3次方)的增长。对于N=100000,我们可以预期算法1将花费近乎90000秒或一天的时间。类似地,我们可预期算法2用大约333秒来完成N=1000000。然而,算法2也可能花费更多的时间,因为在现代计算机中,内存存取N=1000000可能比处理N=100000要慢,这取决于内存缓存的大小。
再看图:
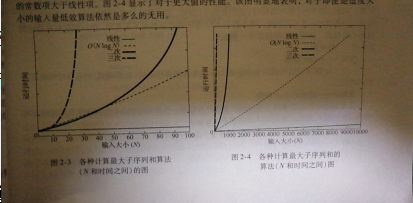
左图指出了四种算法运行时间的增长率。尽管该图只包含N从10到100的值,但是相对增长率还是很明显的。虽然O(NlogN)算法的图看起来是线性的,但是用直尺的边(或是一张纸)容易验证它并不是直线。虽然O(N)算法的图看似直线,但这只是因为对于小的N值其中的常数项大于线性项。右图中更显示对于更大值的性能。该图明显地表明,对于即使是适度大小的输入量低效算法依然是多么的无用。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述