
hive数据倾斜的情况处理
hive的数据倾斜的原因分析:少量key值对应了大量的数据,所以导致在reduce阶段,少数的几个reduce运行特别慢(数据量太大)xuexi: (http://itindex.net/detail/57899-spark-%E6%95%B0%E6%8D%AE-%E6%96%B9%E6%B3%95)
第一种:使用map join操作,这样就剩去了reduce操作
目前的版本默认支持map join操作
hive.auto.convert.join # 默认值为true,自动开户MAPJOIN优化 hive.mapjoin.smalltable.filesize # 默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中
大佬:https://www.cnblogs.com/MOBIN/p/5702580.html
第二种:count(distinct)换为先group 在count的方法
大佬:https://blog.csdn.net/xyh1re/article/details/81813995
- 采用分而治之的思路,对前3为进行分组,剩余的进行count(distinct)
-- 外层SELECT求和 SELECT SUM(mau_part) mau FROM ( -- 内层SELECT分别进行COUNT(DISTINCT)计算 SELECT substr(uuid, 1, 3) uuid_part, COUNT(DISTINCT substr(uuid, 4)) AS mau_part FROM detail_sdk_session WHERE partition_date >= '2016-01-01' AND partition_date <= now GROUP BY substr(uuid, 1, 3) ) t; [bca][12gc] [bc1][12dg] ... 分别计算出[bca]开头的有100个,[bc1]开头的有1000个,最后sum一下即可
2.给uuid打标记的方法
-- 第三层SELECT SELECT SUM(s.mau_part) mau FROM ( -- 第二层SELECT SELECT tag, COUNT(*) mau_part FROM ( -- 第一层SELECT SELECT uuid, CAST(RAND() * 100 AS BIGINT) tag -- 为去重后的uuid打上标记,标记为:0-100之间的整数。 FROM detail_sdk_session WHERE partition_date >= '2016-01-01' AND partition_date <= now GROUP BY uuid -- 通过GROUP BY,保证去重 ) t GROUP BY tag ) s ; 1.为每个uuid打上一个100以内的整数的标记 2.为每个整数(100以内)进行分组求次数 3.将100个标记数的结果次数进行求和
第三种:参数调优--hive.groupby.skewindata
hive.groupby.skewindata = true 设置此参数为true时,则会为任务起两个job,第一个job会将所有的map的输出结果的key按照随机的方式分发到各个reduce节点,进行数据汇总,第二个job会将第一个job的处理结果,按照key的规则分发到reduce完成最后的结汇总
第四种:left semi join 避免了reduce过程
- join右边的表只能在on中设置条件,在where和select 中都无法使用
- 右边只会把key传给左表,故,不会发生reduce过程
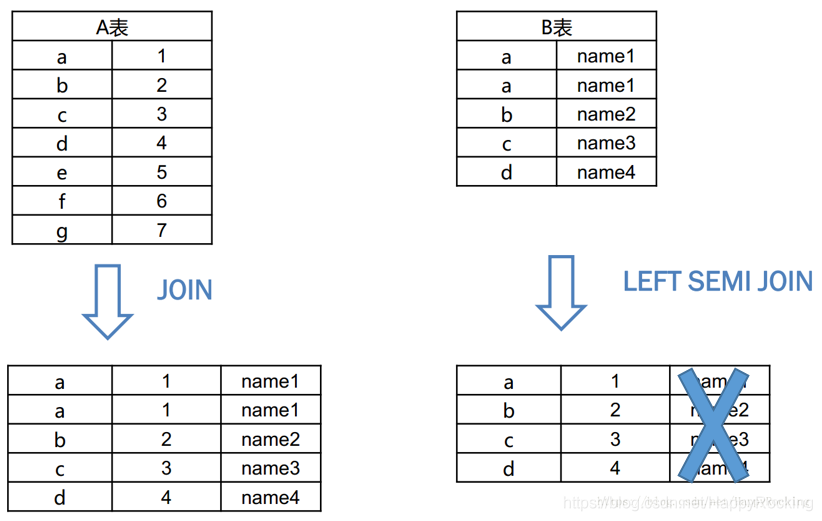
第五种:针对特殊的数据进行特殊处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号