

mapreduce的过程分析
map的shuffle过程分为6个步骤
split --> map --> partition --> kvbuffer(--> sort --> spill) -->merge (--> segment列表 )-->file(文件)
第一步split(切分数据)
- 通过API接口,接入准备的数据,按照128M进行数据切分,每个128M对应一个map
第二步map(操作数据)
- 将数据读取出来,设置好key和value的值
第三步partition(分区)
- 根据key的值进行hash(默认是hash,也可以自己修改采用别的方式)处理,对reduce task数量进行取模获得的partition值。
第四步kvbuffer(数据写入到内存缓冲区-环形数据结构)
kvbuffer分为两部分,一部分是key-value值,一部分是索引值
- bufindex(数据值)
- kvmeta(索引四元组)value起始位置、key起始位置、partition的值、value的长度
缓冲区默认为100M,在写入到80%的时候,会触发spill操作,sortAndspill先把kvbuffer中的数据按照partition的值和key关键字排序,同一partition内按照key有序,将排序好的文件写到本地磁盘。剩余的20%可以继续使用,不会导致map停止。一个溢出文件中,可能由多个partition分区
第五步merge
经过kvbuffer的好几次spill,会出现好多文件(spill1.out文件和spill1.index),merge会读取所有的index文件,维护一个segment列表,将索引文件依次加载到segment列表中,根据列表中的信息,将spill溢出文件合并成一个大文件(file.out、file.index)至此,map端的shuffle操作就做完了。
合并Combiner(具体在哪里,我也不太确定)
如果指定了Combiner,可能在两个地方被调用:
1.当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
2.缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用
合并(Combine)和归并(Merge)的区别: 两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
reduce的shuffle过程分为2个步骤
从map 节点拉取map(已经运行完)的结果数据 --> reduce端merge合并文件
第一步http的方式去map端拉取数据
- map任务结束后,会通知TaskTracker,TaskTracker会通知JobTracker,JobTracker中记录着map与TaskTracker的对应关系,reduce会定期向JobTracker通信,一旦得到map数据输出结果地址,会去对应的数据文件复制到本地,并不会等待所有的map全跑完才做这件事情。map端最终会生成一个文件(file.out、file.index),如果这个文件中有多个partition,那么就会被多个reduce端来拉取数据
![]()
(偷来的图,主要是为了体现,一个map端生成一个file.out和file.index,然后被多个reduce端来拉取数据)
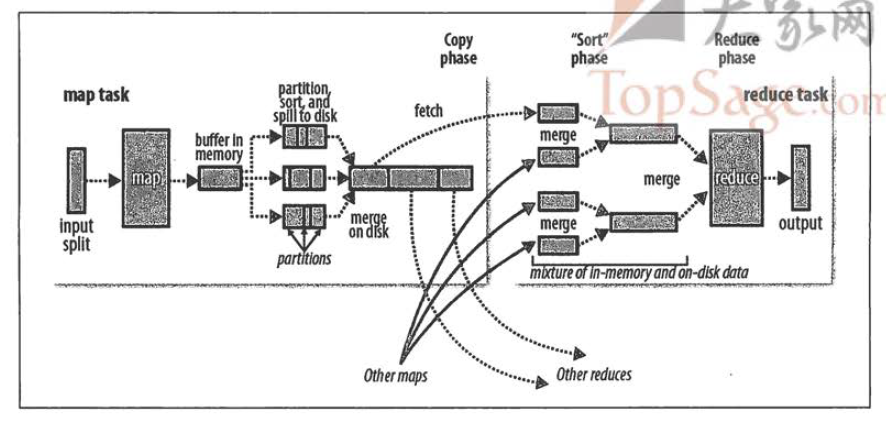
第二步将复制到本地的文件进行reduce-merge
- copy过来的数据会先放到内存中,如果内存缓冲区(mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%)可以容得下数据,可以在内存直接merge,即:内存到内存merge。(这种方式一般不会启用)
- 如果reduce中map数据占到内存一定的空间比例(内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%),会触发内存merge,并将merge结果输出到磁盘上,即:内存到磁盘merge。
- 在reduce端的数据全部拷贝完成时,在reduce端会出现多个文件,会触发合并排序操作,即:磁盘到磁盘merge。故reduce的输出文件是一个整体有序的数据块。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号