


MySQL学习笔记1
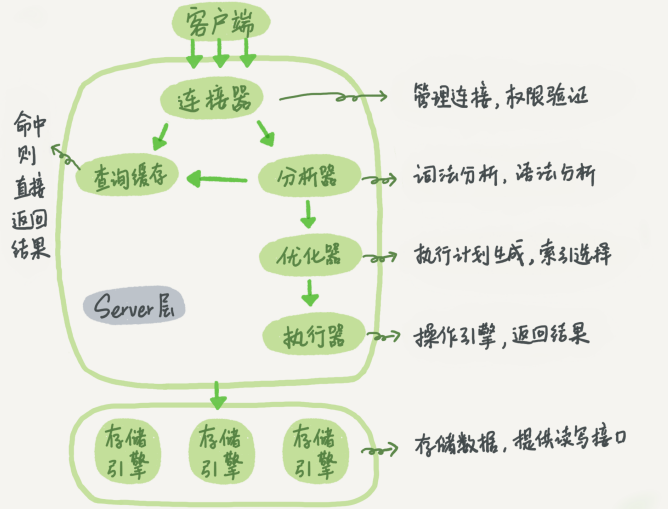
1.MySQL的基本架构
1.1 基本架构
一条MySQL的语句执行过程
1.2 储存引擎
官网5.7版本支持的10种存储引擎:
MyISAM: 拥有较高的插入,查询速度,但不支持事务
InnoDB :5.5.8版本后Mysql的默认数据库引擎,支持ACID事务,支持行级锁定
BDB: 源自Berkeley DB,事务型数据库的另一种选择,支持COMMIT和ROLLBACK等其他事务特性
Memory :所有数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失
Merge :将一定数量的MyISAM表联合而成一个整体,在超大规模数据存储时很有用
Archive :非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive拥有高效的插入速度,但其对查询的支持相对较差
Federated: 将不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用
Cluster/NDB :高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用
CSV: 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个.CSV文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV存储引擎不支持索引。
BlackHole :黑洞引擎,写入的任何数据都会消失,一般用于记录binlog做复制的中继
InnoDB
InnoDB 是一个事务安全的存储引擎,它具备提交、回滚以及崩溃恢复的功能以保护用户数据。InnoDB 的行级别锁定保证数据一致性提升了它的多用户并发数以及性能。InnoDB 将用户数据存储在聚集索引中以减少基于主键的普通查询所带来的 I/O 开销。为了保证数据的完整性,InnoDB 还支持外键约束。默认使用B+TREE数据结构存储索引。
特点:
- 支持事务,支持4个事务隔离(ACID)级别
- 行级锁定(更新时锁定当前行)
- 读写阻塞与事务隔离级别相关
- 既能缓存索引又能缓存数据
- 支持外键
- InnoDB更消耗资源,读取速度没有MyISAM快
- 在InnoDB中存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度;
- 对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。数据和索引放在一块,都位于B+数的叶子节点上;
适用场景:
- 需要支持事务的场景(银行转账之类)
- 适合高并发,行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成的
- 数据修改较频繁的业务
MyISAM
MyISAM既不支持事务、也不支持外键、其优势是访问速度快,但是表级别的锁定限制了它在读写负载方面的性能,因此它经常应用于只读或者以读为主的数据场景。默认使用B+TREE数据结构存储索引。
特点:
- 不支持事务
- 表级锁定(更新时锁定整个表)
- 读写互相阻塞(写入时阻塞读入、读时阻塞写入;但是读不会互相阻塞)
- 只会缓存索引(通过key_buffer_size缓存索引,但是不会缓存数据)
- 不支持外键
- 读取速度快
适用场景:
- 不需要支持事务的场景
- 一般读数据的较多的业务
- 数据修改相对较少的业务
- 数据一致性要求不是很高的业务
Memory
在内存中创建表。每个MEMORY表只实际对应一个磁盘文件(frm 表结构文件)。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引。
特点:
- 支持的数据类型有限制,比如:不支持TEXT和BLOB(二进制大对象)类型(长度不固定),对于字符串类型的数据,只支持固定长度的行,VARCHAR会被自动存储为CHAR类型;
- 支持的锁粒度为表级锁。所以,在访问量比较大时,表级锁会成为MEMORY存储引擎的瓶颈;
- 由于数据是存放在内存中,一旦服务器出现故障,数据都会丢失;
- 查询的时候,如果有用到临时表,而且临时表中有BLOB,TEXT类型的字段,那么这个临时表就会转化为MyISAM类型的表,性能会急剧降低;
- 默认使用hash索引。
- 如果一个内部表很大,会转化为磁盘表。
适用场景:
- 那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地堆中间结果进行分析并得到最终的统计结果。
- 目标数据比较小,而且非常频繁的进行访问,在内存中存放数据,如果太大的数据会造成内存溢出。可以通过参数max_heap_table_size控制Memory表的大小,限制Memory表的最大的大小。
- 数据是临时的,而且必须立即可用得到,那么就可以放在内存中。
- 存储在Memory表中的数据如果突然间丢失的话也没有太大的关系。
1.3 MySQL索引
索引是对数据库表中一列或多列的值进行排序的一种结构。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
1.3.1 索引的优缺点
优点:
- 索引大大减小了服务器需要扫描的数据量,从而大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 索引可以帮助服务器避免排序和创建临时表
- 索引可以将随机IO变成顺序IO
- 索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组,提高了表访问并发性
- 关于InnoDB、索引和锁:InnoDB在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
- 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索引,那么需要占用的空间会更大
- 对表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了整数的维护速度
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效;
1.3.2 索引的数据结构
MySQL中常用的索引结构(索引底层的数据结构)有:B-TREE ,B+TREE ,HASH

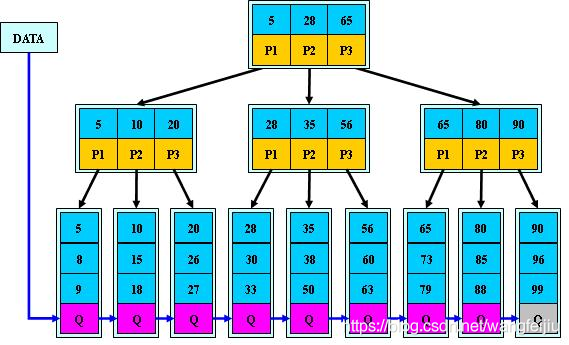
1.3.3 索引的分类
逻辑划分:
- 主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL;
- 唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
- 普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
- 全文索引:它查找的是文本中的关键词,主要用于全文检索。
物理划分:
- 聚簇索引(clustered index)不是单独的一种索引类型,而是一种数据存储方式。这种存储方式是依靠B+树来实现的,根据表的主键构造一棵B+树且B+树叶子节点存放的都是表的行记录数据时,方可称该主键索引为聚簇索引。聚簇索引也可理解为将数据存储与索引放到了一块,找到索引也就找到了数据。
- 非聚簇索引:数据和索引是分开的,B+树叶子节点存放的不是数据表的行记录。
虽然InnoDB和MyISAM存储引擎都默认使用B+树结构存储索引,但是只有InnoDB的主键索引才是聚簇索引,InnoDB中的辅助索引以及MyISAM使用的都是非聚簇索引。每张表最多只能拥有一个聚簇索引。
覆盖索引:搜索的索引键中的字段恰好是查询的字段(或是组合索引键中的其它字段)。覆盖索引的查询效率极高,原因在于不用做回表查询。
一些索引优化的建议:
- InnoDB中主键不宜定义太大,因为辅助索引也会包含主键列,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
- InnoDB中尽量不使用非单调字段作主键(不使用多列),因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
1.4 日志系统
MySQL的日志文件主要有错误日志(error log)、一般查询日志(general log)、慢查询日志(slow query log)、中继日志(relay log)、二进制日志(binlog)、重做日志(redo log)、回滚日志(undo log)。
error log
错误日志是最重要的日志之一,它记录了MySQL服务启动和停止正确和错误的信息,还记录了mysqld实例运行过程中发生的错误事件信息。
可以使用" --log-error=[file_name] "来指定mysqld记录的错误日志文件,如果没有指定file_name,则默认的错误日志文件为datadir目录下的 `hostname`.err ,hostname表示当前的主机名。
也可以在MySQL配置文件中的mysqld配置部分,使用log-error指定错误日志的路径。
如果不知道错误日志的位置,可以查看变量log_error来查看。
SHOW VARIABLES LIKE 'log_error';
general log
查询日志分为一般查询日志和慢查询日志,它们是通过查询是否超出变量 long_query_time 指定时间的值来判定的。在超时时间内完成的查询是一般查询,可以将其记录到一般查询日志中,但是建议关闭这种日志(默认是关闭的),超出时间的查询是慢查询,可以将其记录到慢查询日志中。
使用" --general_log={0|1} "来决定是否启用一般查询日志,使用" --general_log_file=file_name "来指定查询日志的路径。不给定路径时默认的文件名以 `hostname`.log 命名。
由于一般查询日志会记录所有的sql语句,因此默认没有开启一般查询日志,也不建议开启一般查询日志。
slow query log
查询超出变量 long_query_time 指定时间值的为慢查询。但是查询获取锁(包括锁等待)的时间不计入查询时间内。
mysql记录慢查询日志是在查询执行完毕且已经完全释放锁之后才记录的,因此慢查询日志记录的顺序和执行的SQL查询语句顺序可能会不一致(例如语句1先执行,查询速度慢,语句2后执行,但查询速度快,则语句2先记录)。
MySQL 5.1之后就支持微秒级的慢查询超时时长,对于DBA来说,一个查询运行0.5秒和运行0.05秒是非常不同的,前者可能索引使用错误或者走了表扫描,后者可能索引使用正确。
指定的慢查询超时时长表示的是超出这个时间的才算是慢查询,等于这个时间的不会记录。
和慢查询有关的变量:
long_query_time=10 # 指定慢查询超时时长(默认10秒),超出此时长的属于慢查询 log_output={TABLE|FILE|NONE} # 定义一般查询日志和慢查询日志的输出格式,默认为file log_slow_queries={yes|no} # 是否启用慢查询日志,默认不启用 slow_query_log={1|ON|0|OFF} # 也是是否启用慢查询日志,此变量和log_slow_queries修改一个另一个同时变化 slow_query_log_file=/mydata/data/hostname-slow.log #默认路径为库文件目录下主机名加上-slow.log log_queries_not_using_indexes=OFF # 查询没有使用索引的时候是否也记入慢查询日志
如何启用慢查询日志:
mysql> set @@global.slow_query_log=on;
慢查询日志有专门的归类工具mysqldumpslow
binlog
Binary Log (二进制日志),包含描述数据库更改的“ 事件 ”,例如表创建操作或对表数据的更改。Bin log不用于诸如select或 show不修改数据的语句。
binlog产生于mysql中的server层。binlog是以事件形式记录的,不是事务日志(但可能是基于事务来记录binlog),不代表它只记录innodb日志,myisam表也一样有binlog。
对于事务,binlog只在事务提交的时候一次性写入提交前的每个二进制日志记录都先cache,提交时写入。非事务每次执行完语句就直接写入。
binlog的两种写入方式:

binlog文件包含两种类型:
索引文件(文件名后缀为.index)用于记录哪些日志文件正在被使用
日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件
|
|
定义
|
优点
|
缺点
|
|---|---|---|---|
| statement | 记录的是修改SQL语句 | 日志文件小,节约IO,提高性能 |
准确性差,对一些系统函数不能准确复制或不能复制,如now()、uuid()、limit(由于mysql是自选索引,有可能master同salve选择的索引不同,导致更新的内容也不同)等 在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题) |
| row | 记录的是每行实际数据的变更 | 准确性强,能准确复制数据的变更 | 日志文件大,较大的网络IO和磁盘IO |
| mixed | statement和row模式的混合 | 准确性强,文件大小适中 |
statement:

这里的info,从begin到commit,中间是真实执行的语句,实际上只是执行了insert操作,在这之前,还有use ...操作,这个命令不是主动执行的,而是mysql根据当前操作的数据表所在的库,自动添加的
在最后有一个xid event,xid是把binlog和redolog关联起来的关键,binlog和redolog都有一个共同的字段xid,当系统崩溃进行恢复的时候,会按照顺序扫描binlog,若是碰到既有prepare又有commit的redolog,就直接提交;若是碰到只有prepare,而没有commit的redolog,就直接拿xid去binlog查询对应的事务。
row:

可以看到 同格式为statement相比,前后的begin、commit是相同的, 但是row格式中的binlog没有了sql语句的原文,而是替换成了两个event,Table_map和Write_rows ,table_map标识的是操作的表名,另外的ROWS_EVENT分为三种:WRITE_ROWS_EVENT,UPDATE_ROWS_EVENT,DELETE_ROWS_EVENT,分别对应insert,update和delete操作。
这种记录方式下,在这里完全看不出来具体操作内容是什么。需要使用mysqlbinlog工具解析和查看binlog中的内容。
mixed:
mixed 格式的意思是,MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。
mixed 格式可以利用 statment 格式的优点,同时又避免了数据不一致的风险。
binlog的作用:
-
主从复制,对于复制,主库上的binlog提供要发送到从库的数据更改的记录。主库将其binlog中包含的事件发送到其从库,这些服务器执行这些事件以对主库上的数据进行相同的更改。
-
某些数据恢复操作需要使用binlog。还原备份后,将重新执行备份后记录的binlog中的事件。这些事件使数据库从备份点更新。
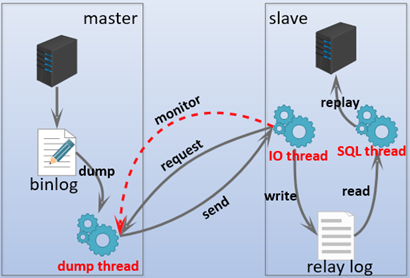
relay log
relay log用于主从复制。
在slave连接到master并设置连接参数后,会开启SQL线程和IO线程。
IO线程用于连接master,监控和接受master的binlog。当启动IO线程成功连接master时,master会同时启动一个dump线程,该线程将slave请求要复制的binlog给dump出来,之后IO线程负责监控并接收master上dump出来的二进制日志,当master上binlog有变化的时候,IO线程就将其复制过来并写入到自己的中继日志(relay log)文件中。
slave上的另一个线程SQL线程用于监控、读取并重放relay log中的日志,将数据写入到自己的数据库中。
2.MySQL的锁
2.1 不同引擎支持的锁级别
1.MyISAM和memory存储引擎只支持表级别的锁。
2.innodb支持行级别的锁和表级别的锁,默认情况下在允许使用行级别锁的时候都会使用行级别的锁。
2.2 锁的类型
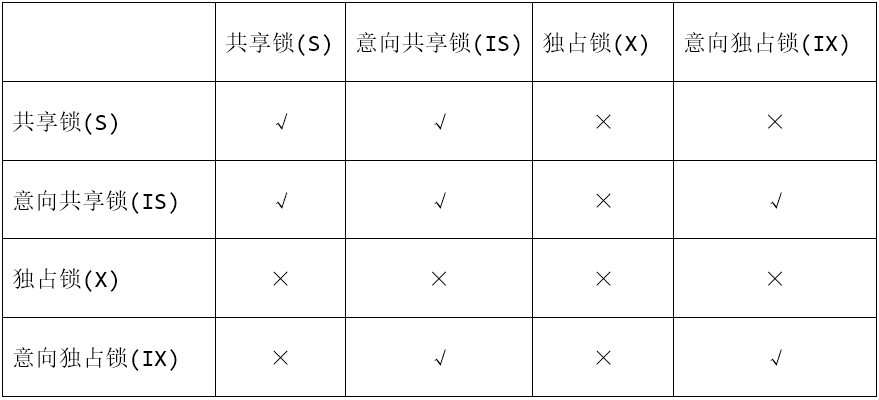
在MySQL中只有简单的几种锁类型:
1.共享锁(S):即读锁,不涉及修改数据,在检索数据时才申请的锁。
2.独占锁(X):增、删、改等涉及修改操作的时候,都会申请独占锁。
以上是支持表锁的存储引擎都会有的锁类型。以下两种是支持行锁或页锁才会有的锁类型,也就是说myisam没有下面的锁,而innodb有。
3.意向共享锁(IS):事务在请求S锁前,要先获得IS锁,这种特殊的共享锁是意向共享锁。
4.意向独占锁(IX):事务在请求X锁前,要先获得IX锁,这种特殊的独占锁是意向独占锁。
锁的兼容性:
2.2.1 表级锁
MySQL里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)
表锁的语法是lock tables … read/write。可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。lock tables语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象
如果在某个线程A中执行lock tables t1 read,t2 wirte;这个语句,则其他线程写t1、读写t2的语句都会被阻塞。同时,线程A在执行unlock tables之前,也只能执行读t1、读写t2的操作。连写t1都不允许
在MySQL5.5版本引入了MDL,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁
读锁之间不互斥,因此可以有多个线程同时对一张表增删改查
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行
2.2.2 行级锁
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议
如果事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放
2.2.3 死锁
在并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁

这时候,事务A在等待事务B释放id=2的行锁,而事务B在等待事务A释放id=1的行锁。 事务A和事务B在互相等待对方的资源释放,就是进入了死锁状态。当出现死锁以后,有两种策略:
一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数innodb_lock_wait_timeout来设置
另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数innodb_deadlock_detect设置为on,表示开启这个逻辑
一种头痛医头的方法,就是如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。但是这种操作本身带有一定的风险,因为业务设计的时候一般不会把死锁当做一个严重错误,毕竟出现死锁了,就回滚,然后通过业务重试一般就没问题了,这是业务无损的。而关掉死锁检测意味着可能会出现大量的超时,这是业务有损的。
另一个思路是控制并发度。
或者将一行改成逻辑上的多行来减少锁冲突。
3.MySQL事务
3.1 什么是事务
事务是用户一系列的数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。
事务具有 4 个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这 4 个特性简称为 ACID 特性。
1. 原子性
事务必须是原子工作单元,事务中的操作要么全部执行,要么全都不执行,不能只完成部分操作。原子性在数据库系统中,由恢复机制来实现。
2. 一致性
事务开始之前,数据库处于一致性的状态;事务结束后,数据库必须仍处于一致性状态。数据库一致性的定义是由用户负责的。例如,在银行转账中,用户可以定义转账前后两个账户金额之和保持不变。
3. 隔离性
系统必须保证事务不受其他并发执行事务的影响,即当多个事务同时运行时,各事务之间相互隔离,不可互相干扰。事务查看数据时所处的状态,要么是另一个并发事务修改它之前的状态,要么是另一个并发事务修改它之后的状态,事务不会查看中间状态的数据。隔离性通过系统的并发控制机制实现。
4. 持久性
一个已完成的事务对数据所做的任何变动在系统中是永久有效的,即使该事务产生的修改不正确,错误也将一直保持。持久性通过恢复机制实现,发生故障时,可以通过日志等手段恢复数据库信息。
事务的 ACID 原则保证了一个事务或者成功提交,或者失败回滚,二者必居其一。因此,它对事务的修改具有可恢复性。即当事务失败时,它对数据的修改都会恢复到该事务执行前的状态。
3.2 事务的四大特性及实现方式
3.2.1 原子性
事务的原子性是通过undo log日志进行实现的。当事务需要回滚时,InnoDB引擎就会调用undo log进行SQL语句的撤销,实现数据的回滚。
undo log(回滚日志)
undo log是InnoDB引擎提供的日志。undo log有两个作用,一是提供回滚,二是实现MVCC功能。
3.2.2 持久性
事务的持久性是通过InnoDB存储引擎中的redo log日志来实现的。
redo log(重做日志)
重做日志(redo log)是InnoDB引擎层的日志,用来记录事务操作引起数据的变化。
内容:
redo log 是物理日志,记载着每次在某个页上做了什么修改。写redo log也是需要写磁盘的,但它的好处就是顺序IO。写入的速度很快。
redo log 包括两部分:
一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;
二是磁盘上的重做日志文件(redo log file),该部分日志是持久的,redo log 存储的是物理格式的日志,记录的是物理数据页面的修改信息,它是顺序写入 redo log file 中的。
产生时间:
事务开始之后就产生redo log,redo log的落盘不一定是随着事务的提交才写入的,在事务的执行过程中,就会写入redo log buffer中,然后根据配置的方式来选择落盘策略,当对应事务的写入到磁盘之后,redo log的使命也就完成了,重做日志占用的空间就可以重用(被覆盖)。
redo log日志的大小是固定的,为了能够持续不断的对更新记录进行写入,在redo log日志中设置了两个标志位置,checkpoint和write_pos,分别表示记录擦除的位置和记录写入的位置。这种结构很像一个循环队列:

落盘方式:
在默认的配置方式下,每个事务提交前会将redo log刷新到redo log file
写redo log的时候,先写buffer,再真正落到磁盘中的。buffer由另一个线程控制,根据配置方式来决定落盘策略。
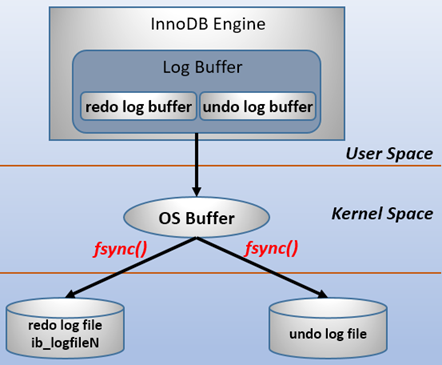


MySQL支持用户自定义在commit时如何将log buffer中的日志刷log file中。这种控制通过变量 innodb_flush_log_at_trx_commit 的值来决定。该变量有3种值:0、1、2,默认为1。但注意,这个变量只是控制commit动作是否刷新log buffer到磁盘。 当设置为1的时候,事务每次提交都会将log buffer中的日志写入os buffer并调用fsync()刷到log file on disk中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。 当设置为0的时候,事务提交时不会将log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 当设置为2的时候,每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到log file on disk。
事务的持久性就是靠redo log来实现的(如果写入内存成功,但数据还没真正刷到磁盘,如果此时的数据库挂了,我们可以靠redo log来恢复内存的数据,这就实现了持久性)。
redo log和bin log的区别:
- bin log是在存储引擎的上层产生的,不管是什么存储引擎,对数据库进行了修改都会产生bin log。而redo log是innodb层产生的,只记录该存储引擎中表的修改。并且bin log先于redo log被记录。
- bin log记录操作的方法是逻辑性的语句。即便它是基于行格式的记录方式,其本质也还是逻辑的SQL设置,如该行记录的每列的值是多少。而redo log是在物理格式上的日志,它记录的是数据库中每个页的修改。
- bin log只在每次事务提交的时候一次性写入缓存中的日志"文件"(对于非事务表的操作,则是每次执行语句成功后就直接写入)。而redo log在数据准备修改前写入缓存中的redo log中,然后才对缓存中的数据执行修改操作;而且保证在发出事务提交指令时,先向缓存中的redo log写入日志,写入完成后才执行提交动作。
- 因为bin log只在提交的时候一次性写入,所以bin log中的记录方式和提交顺序有关,且一次提交对应一次记录。而redo log中是记录的物理页的修改,redo log文件中同一个事务可能多次记录,最后一个提交的事务记录会覆盖所有未提交的事务记录。例如事务T1,可能在redo log中记录了 T1-1,T1-2,T1-3,T1* 共4个操作,其中 T1* 表示最后提交时的日志记录,所以对应的数据页最终状态是 T1* 对应的操作结果。而且redo log是并发写入的,不同事务之间的不同版本的记录会穿插写入到redo log文件中,例如可能redo log的记录方式如下: T1-1,T1-2,T2-1,T2-2,T2*,T1-3,T1* 。
- 事务日志记录的是物理页的情况,它具有幂等性,因此记录日志的方式极其简练。幂等性的意思是多次操作前后状态是一样的,例如新插入一行后又删除该行,前后状态没有变化。而bin log记录的是所有影响数据的操作,记录的内容较多。例如插入一行记录一次,删除该行又记录一次。
3.2.3 隔离性
事务之间的隔离,是通过锁机制实现的。当一个事务需要对数据库中的某行数据进行修改时,需要先给数据加锁。加了锁的数据,其它事务是不运行操作的,只能等待当前事务提交或回滚将锁释放。在许多场景中都会利用到不同实现的锁对数据进行保护和同步。
MVCC
MVCC,全称 Multi-Version Concurrency Control ,即多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
MVCC 带来的好处:
在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能
同时还可以解决脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失问题
简而言之,MVCC 就是为了不让数据库采用悲观锁这样性能不佳的形式去解决读-写冲突问题,而提出的解决方案。
MVCC的实现
MVCC 的目的就是多版本并发控制,在数据库中的实现,就是为了解决读写冲突,它的实现原理主要是依赖记录中的 3个隐式字段,undo日志 ,Read View 来实现的。
隐式字段
每行记录除了我们自定义的字段外,还有数据库隐式定义的 DB_TRX_ID, DB_ROLL_PTR, DB_ROW_ID 等字段
DB_TRX_ID:6 byte,最近修改(修改/插入)事务 ID:记录创建这条记录/最后一次修改该记录的事务 ID
DB_ROLL_PTR:7 byte,回滚指针,指向这条记录的上一个版本(存储于 rollback segment 里)
DB_ROW_ID:6 byte,隐含的自增 ID(隐藏主键),如果数据表没有主键,InnoDB 会自动以DB_ROW_ID产生一个聚簇索引
实际还有一个删除 flag 隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除 flag 变了
如上图,DB_ROW_ID 是数据库默认为该行记录生成的唯一隐式主键,DB_TRX_ID 是当前操作该记录的事务 ID ,而 DB_ROLL_PTR 是一个回滚指针,用于配合 undo日志,指向上一个旧版本
undo log
undo log是逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。undo log是采用段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。
事务开始之前,将当前的版本生成undo log,如果事务执行失败或调用了rollback,导致事务需要回滚,就可以利用undo log中的信息将数据回滚到修改之前的样子。undo log也会产生 redo log来保证undo log的可靠性。
当事务提交之后,undo log并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
undo log 主要分为两种:
insert undo log:代表事务在 insert 新记录时产生的 undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃
update undo log:事务在进行 update 或 delete 时产生的 undo log ; 不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被 purge 线程统一清除
purge线程:从前面的分析可以看出,为了实现 InnoDB 的 MVCC 机制,更新或者删除操作都只是设置一下老记录的 deleted_bit ,并不真正将过时的记录删除。
为了节省磁盘空间,InnoDB 有专门的 purge 线程来清理 deleted_bit 为 true 的记录。为了不影响 MVCC 的正常工作,purge 线程自己也维护了一个read view(这个 read view 相当于系统中最老活跃事务的 read view );如果某个记录的 deleted_bit 为 true ,并且 DB_TRX_ID 相对于 purge 线程的 read view 可见,那么这条记录一定是可以被安全清除的。
对 MVCC 有帮助的实质是 update undo log ,undo log 实际上就是存在 rollback segment 中的旧记录链。
undo log的生成过程:
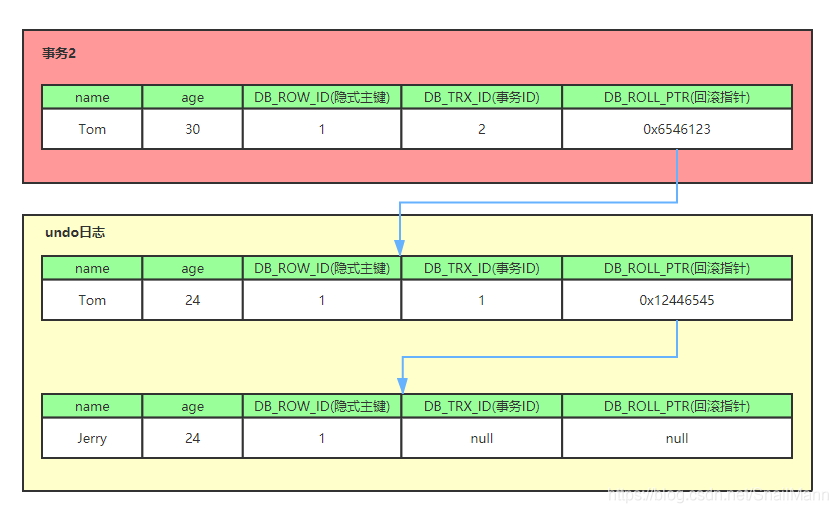
不同事务或者相同事务的对同一记录的修改,会导致该记录的undo log成为一条记录版本链表,undo log 的链首就是最新的旧记录,链尾就是最早的旧记录
Read View
Read View 就是事务进行快照读操作的时候生产的读视图 (Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的 ID (当每个事务开启时,都会被分配一个 ID , 这个 ID 是递增的,所以最新的事务,ID 值越大)
所以我们知道 Read View 主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
判断方式:
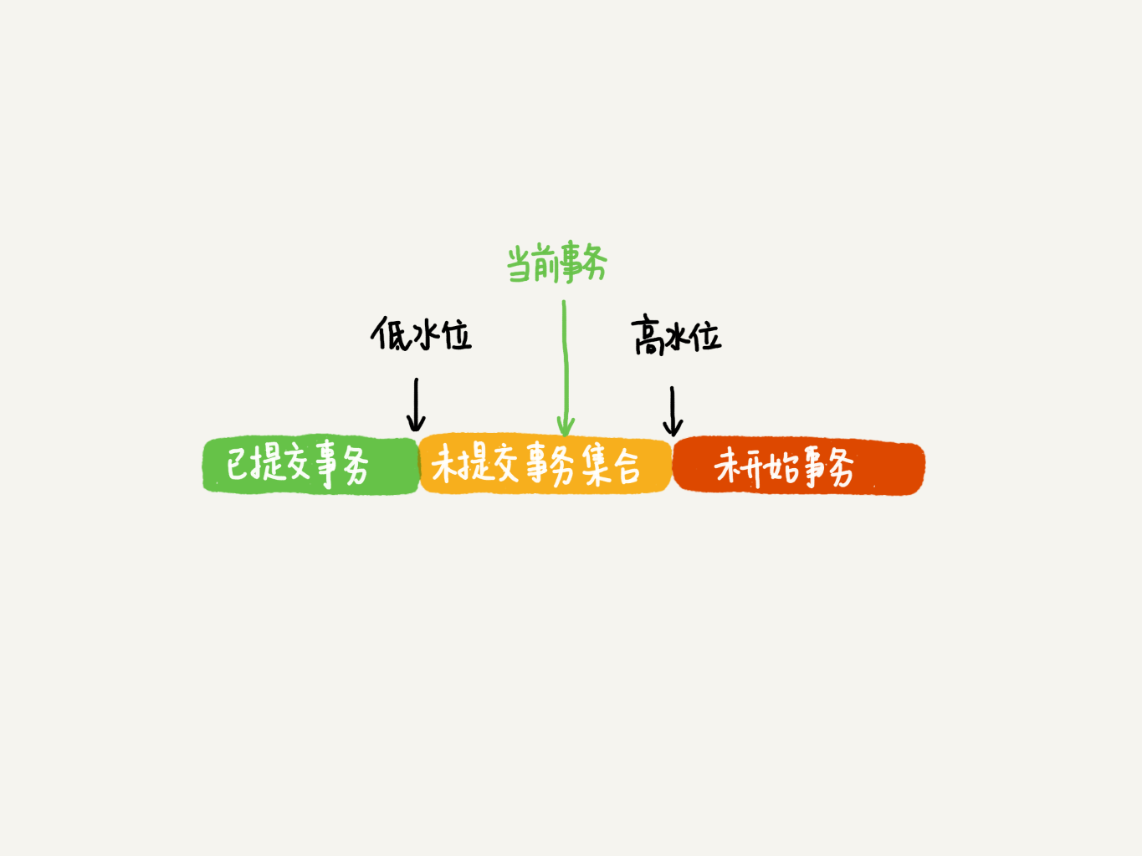
对于当前事务的启动瞬间来说,一个数据版本的DB_TRX_ID,有以下几种可能:
如果落在绿色部分,表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的;
如果落在红色部分,表示这个版本是由将来启动的事务生成的,是肯定不可见的;
如果落在黄色部分,那就包括两种情况
a. 若DB_TRX_ID在数组中,表示这个版本是由还没提交的事务生成的,不可见;
b. 若DB_TRX_ID不在数组中,表示这个版本是已经提交了的事务生成的,可见。
MVCC整体流程
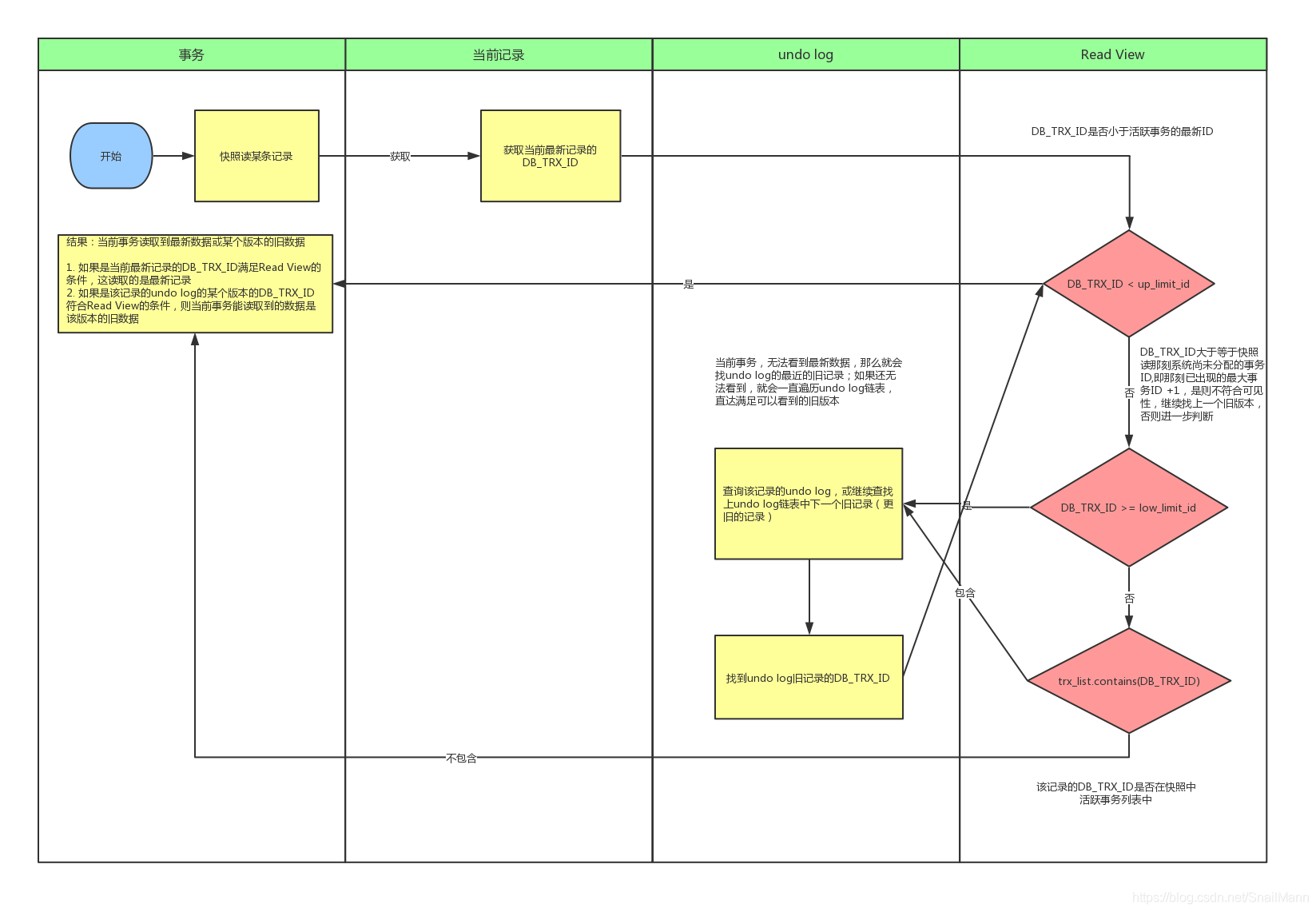
3.2.4 一致性
一致性是指事务执行结束后,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。一致性是事务追求的最终目标,原子性、持久性和隔离性,实际上都是为了保证数据库状态的一致性而存在的。实际上ACID里C的特性是说通过事务的AID来保证一致性。
3.3 事务的执行过程
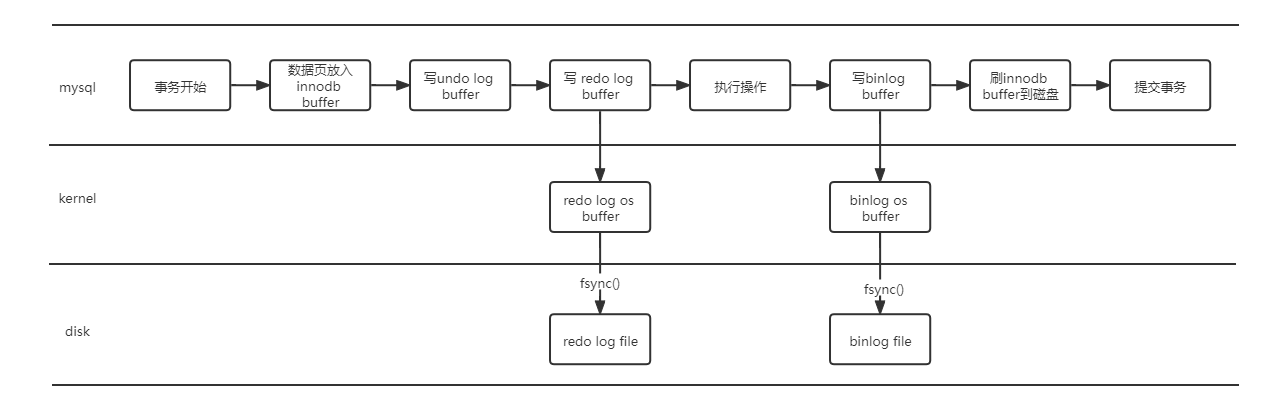
事务开始
申请锁
将需要修改的数据页放入innodb_buffer中
写undo log buffer
写redo log buffer
执行操作
写binlog buffer
刷新innodb_buffer_cache到磁盘(位置也许会在binlog刷新前)
提交事务(提交前把日志的buffer都刷入磁盘)
释放锁
参考资料:
https://www.jianshu.com/p/e6804308b156
https://www.cnblogs.com/f-ck-need-u/p/9010872.html#auto_id_11
https://www.pianshen.com/article/30041949693/

