Loki简介,部署,使用
1|0前言
在对公司容器云的日志方案进行设计的时候,发现主流的 ELK (Elasticsearch, Logstash, Kibana) 或者 EFK (Elasticsearch, Filebeat or Fluentd, Kibana) 比较重,再加上现阶段对于 ES 复杂的搜索功能很多都用不上,最终选择了 Grafana 开源的 Loki 日志系统。下面我们来介绍下 Loki 的一些基本概念和架构,当然 EFK 作为业界成熟的日志聚合解决方案也是大家应该需要熟悉和掌握的;
2|0简介
Loki 是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签,专门为 Prometheus 和 Kubernetes 用户做了相关优化。该项目受 Prometheus 启发,官方的介绍就是: Like Prometheus,But For Logs.,类似于 Prometheus 的日志系统;
项目地址:https://github.com/grafana/loki/
与其他日志聚合系统相比, Loki 具有下面的一些特性:
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高,能对接alertmanager;
- 特别适合储存 Kubernetes Pod 日志; 诸如 Pod 标签之类的元数据会被自动删除和编入索引;
- 受 Grafana 原生支持,避免kibana和grafana来回切换;
3|0架构说明
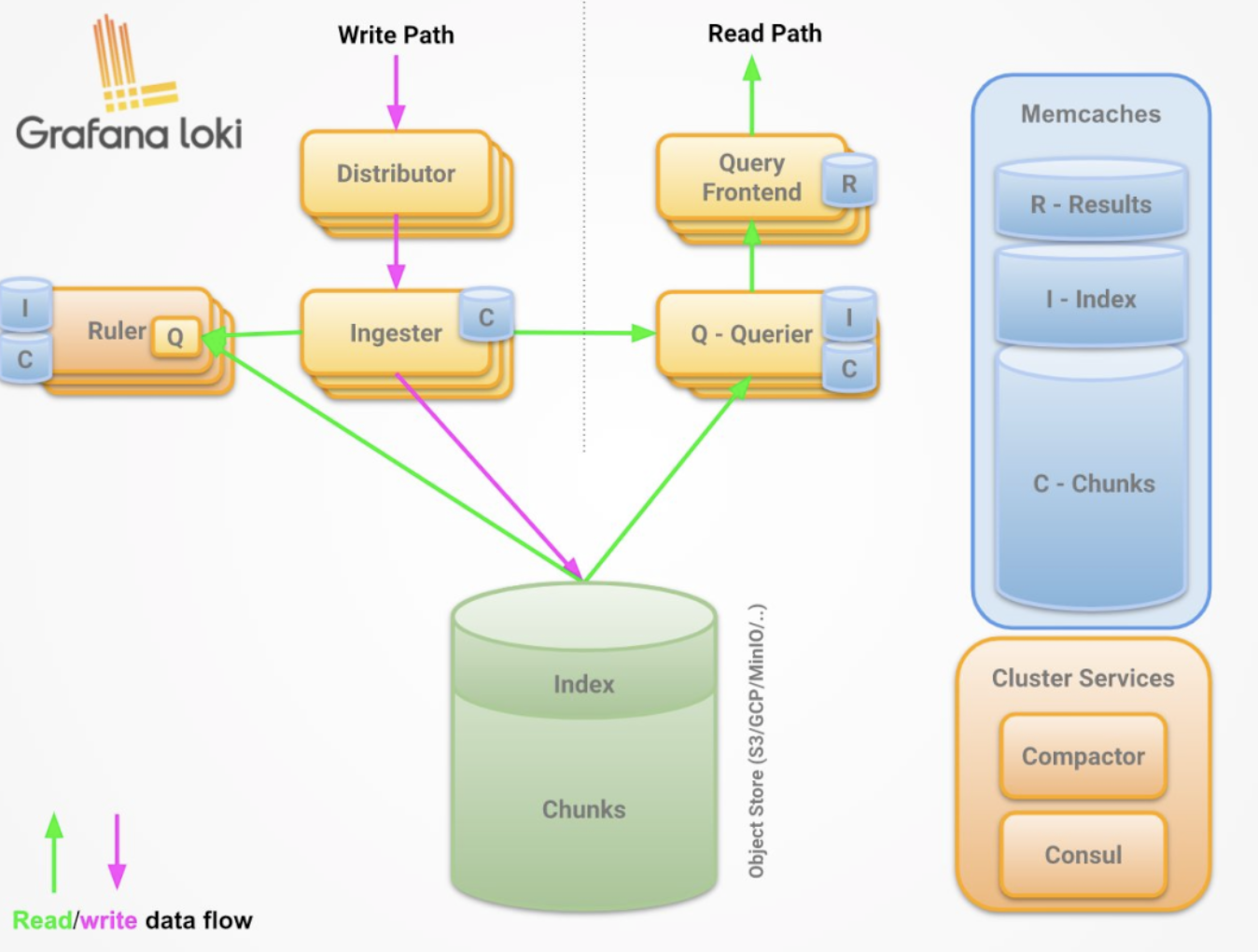
3|1组件说明
Promtail 作为采集器,类比filebeat
loki相当于服务端,类比es
loki进程包含四种角色
querier 查询器
inester 日志存储器
query-frontend 前置查询器
distributor 写入分发器
可以通过loki二进制的 -target 参数指定运行角色
3|2read path
查询器接受HTTP/1 数据请求
查询器将查询传递给所有ingesters请求内存中的数据
接收器接受读取的请求,并返回与查询匹配的数据(如果有)
如果没有接受者返回数据, 则查询器会从后备存储中延迟加载数据并对其执行查询;
查询器将迭代所有接收到的数据并进行重复数据删除, 从而通过HTTP/1连接返回最终数据集;
3|3write path

分发服务器收到一个HTTP/1请求,以存储流数据;
每个流都使用散列环散列;
分发程序将每个流发送到适当的inester和其副本(基于配置的复制因子);
每个实例将为流的数据创建一个块或将其追加到现有块中, 每个租户和每个标签集的块都是唯一的;
分发服务器通过HTTP/1链接以成功代码作为响应;
4|0部署
4|1本地化模式安装
下载promtail和loki二进制
安装promtail
安装loki
5|0使用
5|1grafana上配置loki数据源
grafana-loki-dashsource
在数据源列表中选择 Loki,配置 Loki 源地址:
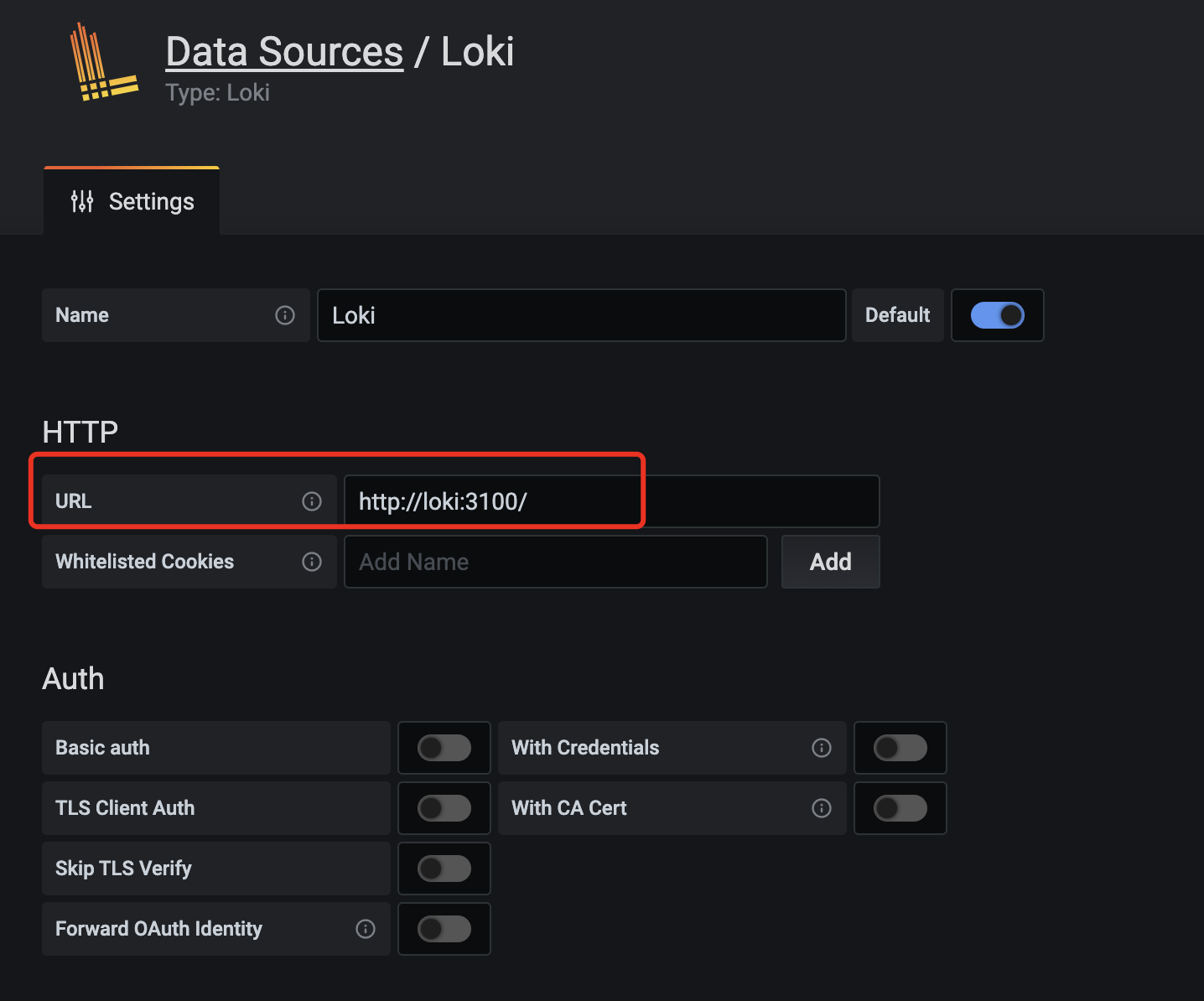
grafana-loki-dashsource-config
源地址配置 http://loki:3100 即可,保存。
保存完成后,切换到 grafana 左侧区域的 Explore,即可进入到 Loki 的页面

grafana-loki
然后我们点击 Log labels 就可以把当前系统采集的日志标签给显示出来,可以根据这些标签进行日志的过滤查询:
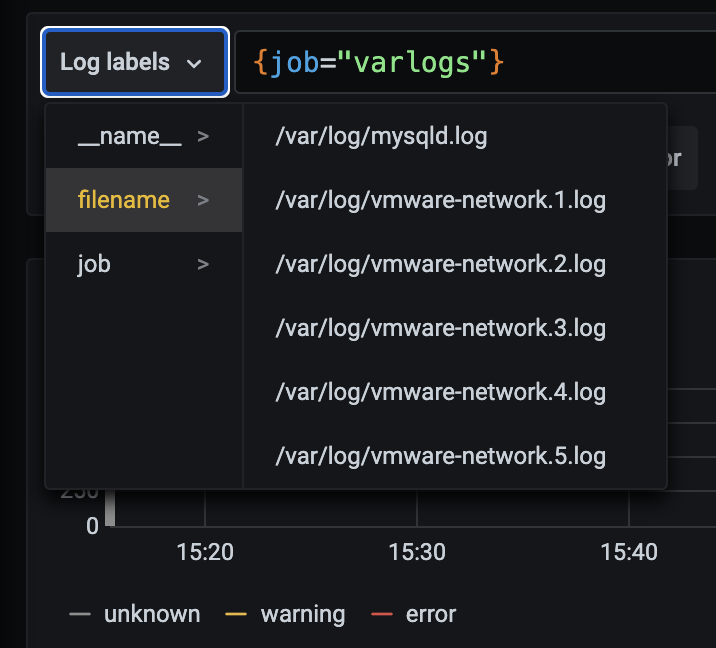
grafana-loki-log-labels
比如我们这里选择 /var/log/messages,就会把该文件下面的日志过滤展示出来,不过由于时区的问题,可能还需要设置下时间才可以看到数据:
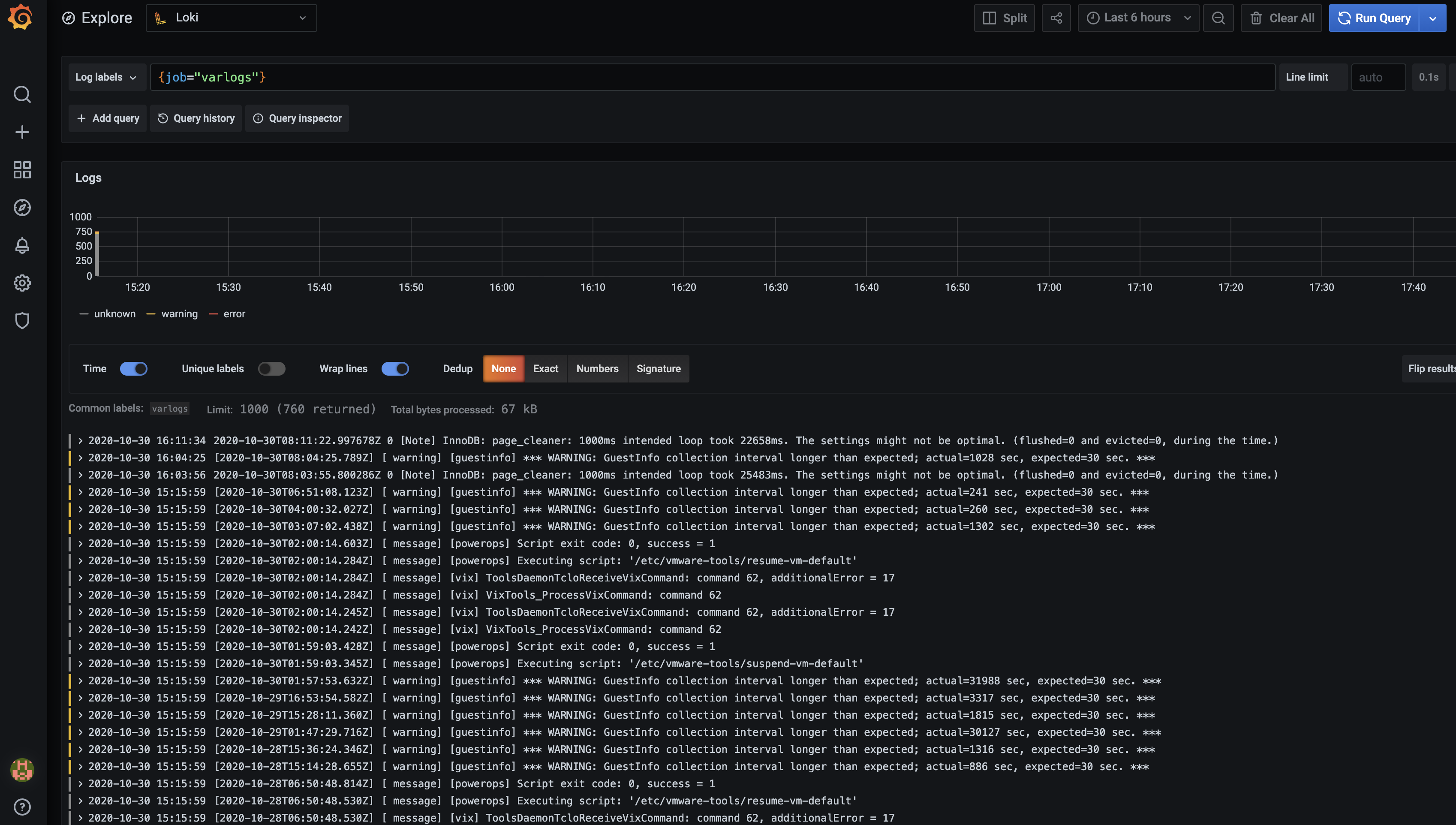
s
grafana-loki-logs
这里展示的是 promtail 容器里面 / var/log 目录中的日志
promtail 容器 / etc/promtail/config.yml
这里的 job 就是 varlog,文件路径就是 / var/log/*log
5|2在grafana explore上配置查看日志
算 qps rate({job="message"} |="kubelet" [1m])
5|3只索引标签
之前多次提到 loki 和 es 最大的不同是 loki 只对标签进行索引而不对内容索引 下面我们举例来看下
静态标签匹配模式
以简单的 promtail 配置举例
配置解读
- 上面这段配置代表启动一个日志采集任务
- 这个任务有 1 个固定标签job="syslog"
- 采集日志路径为 /var/log/messages , 会以一个名为 filename 的固定标签
- 在 promtail 的 web 页面上可以看到类似 prometheus 的 target 信息页面
可以和使用prometheus一样的标签匹配语句进行查询
{job="syslog"}
- 如果我们配置了两个 job,则可以使用{job=~”apache|syslog”} 进行多 job 匹配
- 同时也支持正则和正则非匹配
5|4标签匹配模式的特点
原理
- 和 prometheus 一致,相同标签对应的是一个流 prometheus 处理 series 的模式
- prometheus 中标签一致对应的同一个 hash 值和 refid(正整数递增的 id),也就是同一个 series
- 时序数据不断的 append 追加到这个 memseries 中
- 当有任意标签发生变化时会产生新的 hash 值和 refid,对应新的 series
loki 处理日志的模式 - 和 prometheus 一致,loki 一组标签值会生成一个 stream - 日志随着时间的递增会追加到这个 stream 中,最后压缩为 chunk - 当有任意标签发生变化时会产生新的 hash 值,对应新的 stream
查询过程
- 所以 loki 先根据标签算出 hash 值在倒排索引中找到对应的 chunk?
- 然后再根据查询语句中的关键词等进行过滤,这样能大大的提速
- 因为这种根据标签算哈希在倒排中查找 id,对应找到存储的块在 prometheus 中已经被验证过了
- 属于开销低
- 速度快
5|5动态标签和高基数
所以有了上述知识,那么就得谈谈动态标签的问题了
两个概念
何为动态标签:说白了就是标签的 value 不固定
何为高基数标签:说白了就是标签的 value 可能性太多了,达到 10 万,100 万甚至更多
比如 apache 的 access 日志
在promtail中使用regex想要匹配action和status_code两个标签
- 那么对应 action=get/post 和 status_code=200/400 则对应 4 个流
- 那四个日志行将变成四个单独的流,并开始填充四个单独的块。
- 如果出现另一个独特的标签组合(例如 status_code =“500”),则会创建另一个新流
高基数问题
- 就像上面,如果给 ip 设置一个标签,现在想象一下,如果您为设置了标签 ip,来自用户的每个不同的 ip 请求不仅成为唯一的流
- 可以快速生成成千上万的流,这是高基数,这可以杀死 Loki
如果字段没有被当做标签被索引,会不会查询很慢
Loki 的超级能力是将查询分解为小块并并行分发,以便您可以在短时间内查询大量日志数据
5|6全文索引问题
- 大索引既复杂又昂贵。通常,日志数据的全文索引的大小等于或大于日志数据本身的大小
- 要查询日志数据,需要加载此索引,并且为了提高性能,它可能应该在内存中。这很难扩展,并且随着您摄入更多日志,索引会迅速变大。
- Loki 的索引通常比摄取的日志量小一个数量级,索引的增长非常缓慢
加速查询没标签字段
以上边提到的 ip 字段为例 - 使用过滤器表达式查询
loki查询时的分片(按时间范围分段grep)
- Loki 将把查询分解成较小的分片,并为与标签匹配的流打开每个区块,并开始寻找该 IP 地址。
- 这些分片的大小和并行化的数量是可配置的,并取决于您提供的资源
- 如果需要,您可以将分片间隔配置为 5m,部署 20 个查询器,并在几秒钟内处理千兆字节的日志
- 或者,您可以发疯并设置 200 个查询器并处理 TB 的日志!
两种索引模式对比
- es 的大索引,不管你查不查询,他都必须时刻存在。比如长时间占用过多的内存
- loki 的逻辑是查询时再启动多个分段并行查询
日志量少时少加标签
- 因为每多加载一个 chunk 就有额外的开销
- 举例 如果该查询是
- 在没加 level 标签的情况下只需加载一个 chunk 即 app="loki" 的标签
- 如果加了 level 的情况,则需要把 level=info,warn,error,critical 5 个 chunk 都加载再查询
需要标签时再去添加
- 当 chunk_target_size=1MB 时代表 以 1MB 的压缩大小来切割块
- 对应的原始日志大小在 5MB-10MB,如果日志在 max_chunk_age 时间内能达到 10MB,考虑添加标签
日志应当按时间递增
- 这个问题和 tsdb 中处理旧数据是一样的道理
- 目前 loki 为了性能考虑直接拒绝掉旧数据
__EOF__

本文链接:https://www.cnblogs.com/you-men/p/14900249.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!