Promethues 之 Thanos

Promethues简介和原理
请看我之前写的 Prometheus简介,原理和安装
https://www.cnblogs.com/you-men/p/12839535.html
官方架构问题
官方架构存在一个最大的问题数据量一上去需要尽快拆分,例如在使用中发现Es的Export会拉取大量metrics直接导致单机Prom不堪重负「io巨高」当然指标太多也不是好事这个会在最后讨论下如果避免,所以需要拆分集群「此处不讨论官方的联邦策略,这个扩展性并没有那么好,依然需要拆分多套联邦集群」
顺着正常思路我们一定是先拆分集群,我也没有逃出这个方法开始着手拆分,拆了历史数据还在老集群还要搬数据大量的Ops工作啊「哪怕写了自动化脚本,回车还是要人敲的吧」,拆完了看着不错哦,但是另外的问题来了,要通知Dev我们拆了地址变了,随之而来的是大量的通知「心很累」。metrics还是很多总不能没事就拆吧,而且历史保留时间我们是7天慢慢发现用户要查7天前的就再见了「无法支持」。
当然我们也有联邦集群,在联合部署中,全局Prometheus服务器可以在其他Prometheus服务器上聚合数据,这些服务区可能分布在多个数据中心。每台服务器只能看到一部分度量指标。为了处理每个数据中心的负载,可以在一个数据中心内运行多台Prometheus服务器,并进行水平分片。在分片设置中,从服务器获取数据的子集,并由主服务器对其进行聚合。在查询特定的服务器时,需要查询拼凑数据的特定从服务器。默认情况下,Prometheus存储15天的时间序列数据。为了无限期存储数据,Prometheus提供了一个远程端点,用于将数据写入另一个数据存储区。不过,在使用这种方法时,数据去重是个问题。其他解决方案(如Cortex)提供了一个远程写入端点和兼容的查询API,实现可伸缩的长期存储。
综上问题主要是:拆分之痛、全局查询、数据去重、历史数据查询、AlertManager无高可用
**
业务发展快不是Ops推脱的理由,某天躺在床上刷刷微信发现神器尽然已经有了「虽然还只是一个测试版本」Thanos,果断开始调研发现可以啊基本解决了上面提及的多个痛点。「团队中也来两个了新的小伙伴 Go专职研发、监控系统小达人、感谢两位的帮助」心中无比激动,开始动手了。
Thanos是啥
Improbable团队开源了Thanos,一组通过跨集群联合、跨集群无限存储和全局查询为Prometheus增加高可用性的组件。Improbable部署了一个大型的Prometheus来监控他们的几十个Kubernetes集群。默认的Prometheus设置在查询历史数据、通过单个API调用进行跨分布式Prometheus服务器查询以及合并多个Prometheus数据方面存在困难。
Thanos通过使用后端的对象存储来解决数据保留问题。Prometheus在将数据写入磁盘时,边车的StoreAPI组件会检测到,并将数据上传到对象存储器中。Store组件还可以作为一个基于gossip协议的检索代理,让Querier组件与它进行通信以获取数据。
Thanos还提供了时间序列数据的压缩和降采样(downsample)存储。Prometheus提供了一个内置的压缩模型,现有较小的数据块被重写为较大的数据块,并进行结构重组以提高查询性能。Thanos在Compactor组件(作为批次作业运行)中使用了相同的机制,并压缩对象存储数据。Płotka说,Compactor也对数据进行降采样,“目前降采样时间间隔不可配置,不过我们选择了一些合理的时间间隔——5分钟和1小时”。压缩也是其他时间序列数据库(如InfluxDB和OpenTSDB)的常见功能。
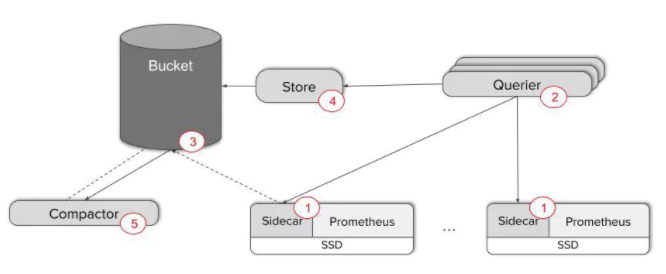
Thanos通过一种简单的可无缝接入当前系统的方案解决这些问题。其主要功能点通过Sidecar、Querier、Store和Compactor来实现,这里做一个简单介绍。
+
Tenant's Premise | Provider Premise
|
| +------------------------+
| | |
| +-------->+ Object Storage |
| | | |
| | +-----------+------------+
| | ^
| | S3 API | S3 API
| | |
| | +-----------+------------+
| | | | Store API
| | | Thanos Store Gateway +<-----------------------+
| | | | |
| | +------------------------+ |
| | |
| +---------------------+ |
| | |
+--------------+ | +-----------+------------+ +---------+--------+
| | | Remote | | Store API | |
| Prometheus +------------->+ Thanos Receiver +<-------------+ Thanos Querier |
| | | Write | | | |
+--------------+ | +------------------------+ +---------+--------+
| ^
| |
+--------------+ | |
| | | PromQL |
| User +----------------------------------------------------------------+
| | |
+--------------+ |
+
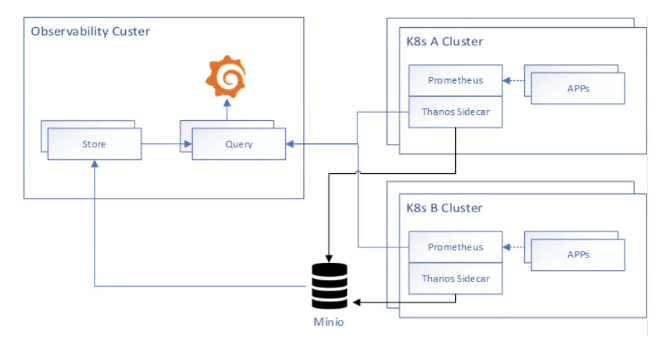
把Prometheus的数据弄一份存到Min io, Prometheus里面默认保存24小时
Sidecar
Sidecar作为一个单独的进程和已有的Prometheus实例运行在一个server上,互不影响。Sidecar可以视为一个Proxy组件,所有对Prometheus的访问都通过Sidecar来代理进行。通过Sidecar还可以将采集到的数据直接备份到云端对象存储服务器。「会消耗原有实例所在集群的资源,上线前可以先把原有server机器升配下」
Querier
所有的Sidecar与Querier直连,同时Querier实现了一套Prometheus官方的HTTP API从而保证对外提供与Prometheus一致的数据源接口,Grafana可以通过同一个查询接口请求不同集群的数据,Querier负责找到对应的集群并通过Sidecar获取数据。Querier本身也是水平可扩展的,因而可以实现高可部署,而且Querier可以实现对高可部署的Prometheus的数据进行合并从而保证多次查询结果的一致性,从而解决全局视图和高可用的问题。「配合云的AutoScaling」
Store
Store实现了一套和Sidecar完全一致的API提供给Querier用于查询Sidecar备份到云端对象存储的数据。因为Sidecar在完成数据备份后,Prometheus会清理掉本地数据保证本地空间可用。所以当监控人员需要调取历史数据时只能去对象存储空间获取,而Store就提供了这样一个接口。Store Gateway只会缓存对象存储的基本信息,例如存储块的索引,从而保证实现快速查询的同时占用较少本地空间。
Comactor
Compactor主要用于对采集到的数据进行压缩,实现将数据存储至对象存储时节省空间。
Ruler
Ruler主要是管理多个AlertManager告警规则配置统一管理的问题「推荐使用集群版本的AlertManager,多个AlertManager之前放一个SLB即可」
Thanos优点
优点
对比官方的解决方案,这个东西可以支持跨集群查询、数据去重、历史数据查询、告警规则统一管理,当然还有别的大家自己脑补。
Thanos问题
store开始只能查询8次还不记得多少次就不行了,还有查询实例时间长了也不行了,需要注意「让研发哥哥解决了,如何解决的回头再放出来,最近官方新发布,貌似修改的这个问题,需要测试下。」使用的是Ceph「其实s3和oss也是可以的,只要支持s3协议即可」,ceph也有坑「这个我不懂了,有专人盯着的这边不讨论」,sidecar组件如果启动在原有就很忙的Prometheus边上之前需要谨慎「把原有OOM过一次」,建议还是先拆了再搞。此组件已经引起官方关注,预祝早日合并到官方去。
容器外&容器内
大概率的很多同学肯定存在容器外面与容器内部两套环境、或者多容器环境。这边写下不成熟的小建议系统给到各位帮助,实现方法有两种「应该还有更多」,Thanos使用的是Gossip进行自动发现其实在容器内外发现上面还是有点麻烦的。
**前提: **Thanos在容器里面MacVlan模式,Pod分配固定IP,漂移时保持IP不变。「容器网络不懂的,大家自己Google下」
SLB
通过k8s api定时判断thanos所在pod情况,如果发生变化调用云的api进行slb更新。「笨办法」
Cousul
万物揭注册原则,全部注册到cousul上面去「其实还是要自己写一个小东西去完成注册」
指标过多
这个问题其实很纠结,Export吐那么多真的都能看的过来吗,目测不可能,需要在Pull那边做相应的控制,只看自己需要的其实对于Dev要求变高了。自己吐的么更是要精准,我是一个DBA吧很多时候面试都会问我你看那些指标啊,CPU、内存、IO、连接数还不够你看吗,指标不是越多越好谁没事都看一遍「闲得慌吗,存着不是浪费计算资源吗,DevOps的大环境下是不是Dev还是需要一些基本看监控能力呢,不要变成只会打字的研发,不淘汰你淘汰谁呢……」
规范
依然要老生常谈规范这个事情,不要一上来就喊着要秒级监控「真的没必要 谁看啊」,定义到各个指标的命名规范其实比这套东西更为重要 ,让研发去理解其实很难的,大家都被业务压的喘不过气来,还有谁会去接受Ops的东西。
运维平台竟可能融合这套东西中最麻烦的几项比如,添加监控、添加告警尽可能傻瓜式。定义到接口是Pull还是Push,规范最重要,生产线能流畅的运转不是代码写的有多好「当然这个也很重要」,是各个接口之间的规范、文档、代码中的注释、要不换了人撸你代码、搞你系统的时候咋弄。意识习惯才是重要的,技术好坏是个人意识,习惯才是个人修养。

