前后端不分离到分离演变,优势,前后端接口联调,排错及优化

1|0前后端分离,不分离简介
1|1前言
前后端分离已成为互联网项目开发的业界标准使用方式,通过nginx+tomcat的方式(也可以中间加一个nodejs)有效的进行解耦,并且前后端分离会为以后的大型分布式架构、弹性计算架构、微服务架构、多端化服务(多种客户端,例如:浏览器,车载终端,安卓,IOS等等)打下坚实的基础。这个步骤是系统架构从猿进化成人的必经之路。
核心思想是前端html页面通过ajax调用后端的restuful api接口并使用json数据进行交互。
名词解释
Web服务器
应用服务器
1|2未分离时代(各种耦合)
早期主要使用MVC框架,Jsp+Servlet的结构图如下
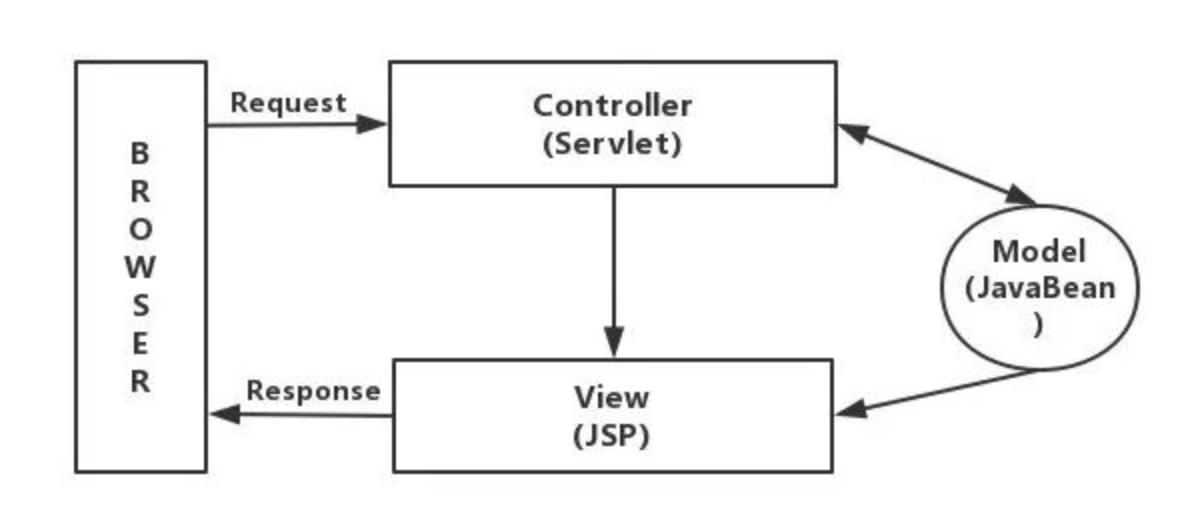
大致就是所有的请求都被发送给作为控制器的Servlet,它接受请求,并根据请求信息将它们分发给适当的JSP来响应。同时,Servlet还根据JSP的需求生成JavaBeans的实例并输出给JSP环境。JSP可以通过直接调用方法或使用UseBean的自定义标签得到JavaBeans中的数据。需要说明的是,这个View还可以采用 Velocity、Freemaker 等模板引擎。使用了这些模板引擎,可以使得开发过程中的人员分工更加明确,还能提高开发效率。
那么,在这个时期,开发方式有如下两种:
方式一
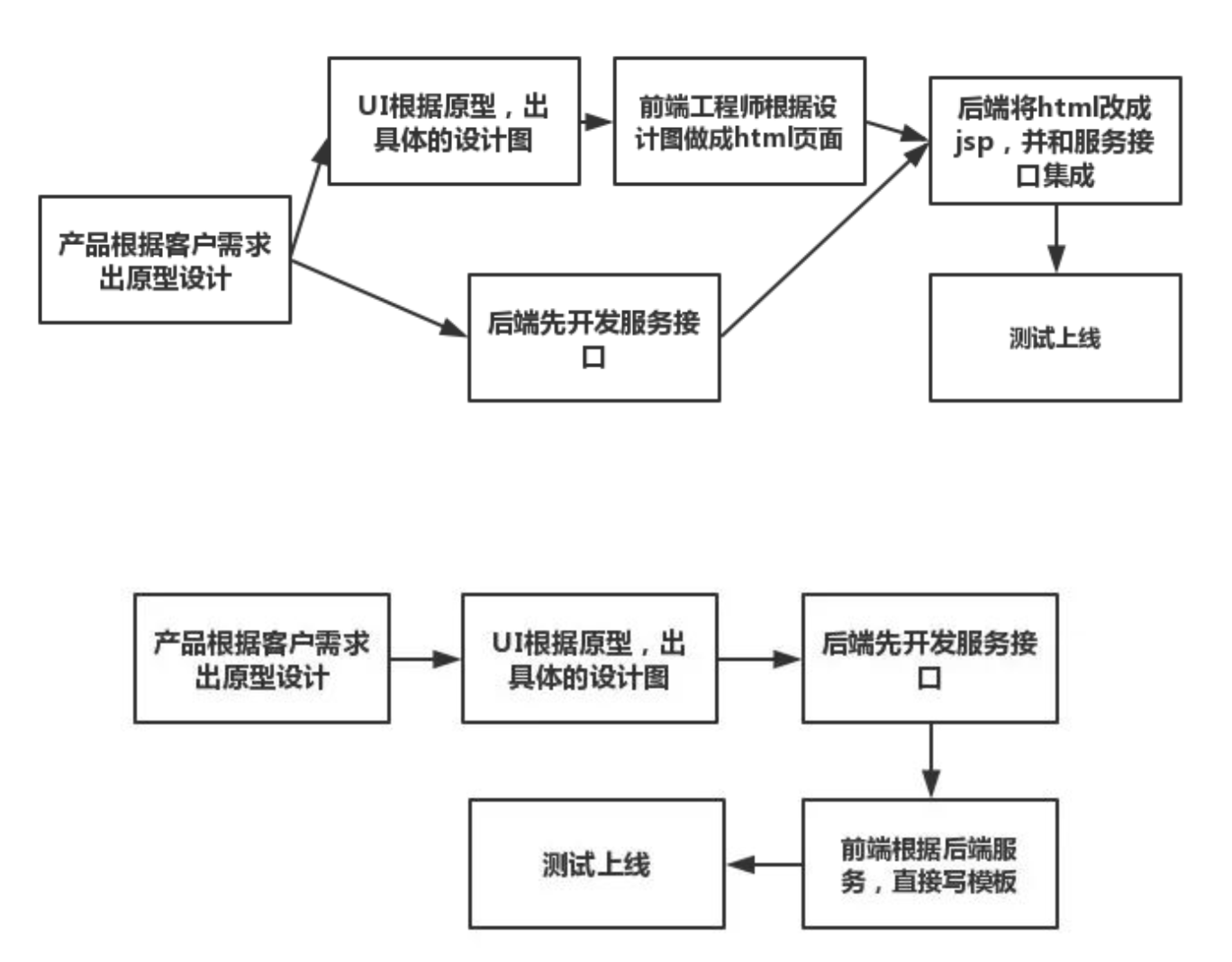
方式二
方式二已经逐渐淘汰。主要原因有两点:
这种方式耦合性太强。那么,就算你用了freemarker等模板引擎,不能写Java代码。那前端也不可避免的要去重新学习该模板引擎的模板语法,无谓增加了前端的学习成本。正如我们后端开发不想写前端一样,你想想如果你的后台代码里嵌入前端代码,你是什么感受?因此,这种方式十分不妥。
3、JSP本身所导致的一些其他问题 比如,JSP第一次运行的时候比较缓慢,因为里头包含一个将JSP翻译为Servlet的步骤。再比如因为同步加载的原因,在JSP中有很多内容的情况下,页面响应会很慢。

1|3前后端未分离
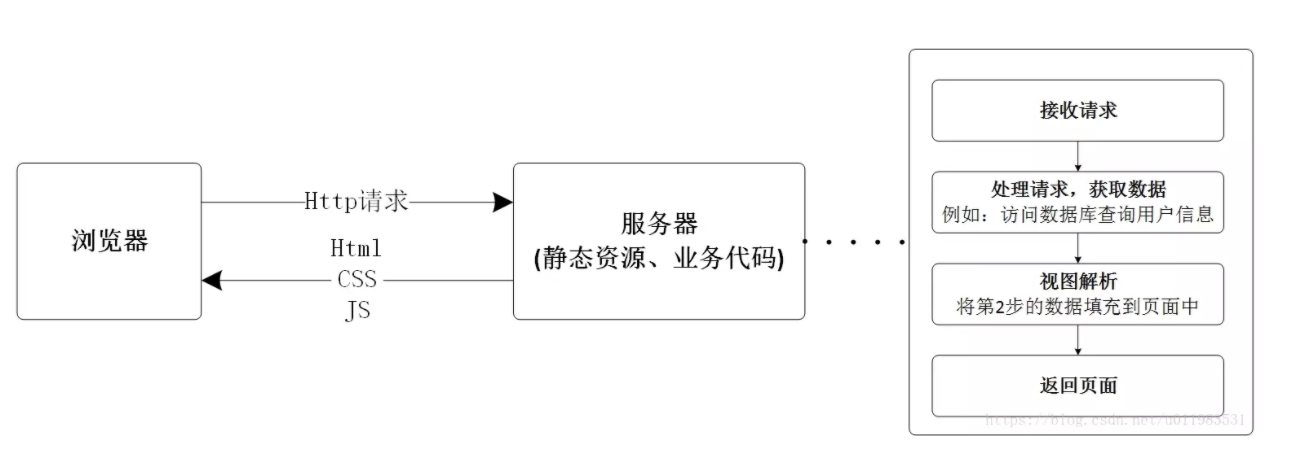
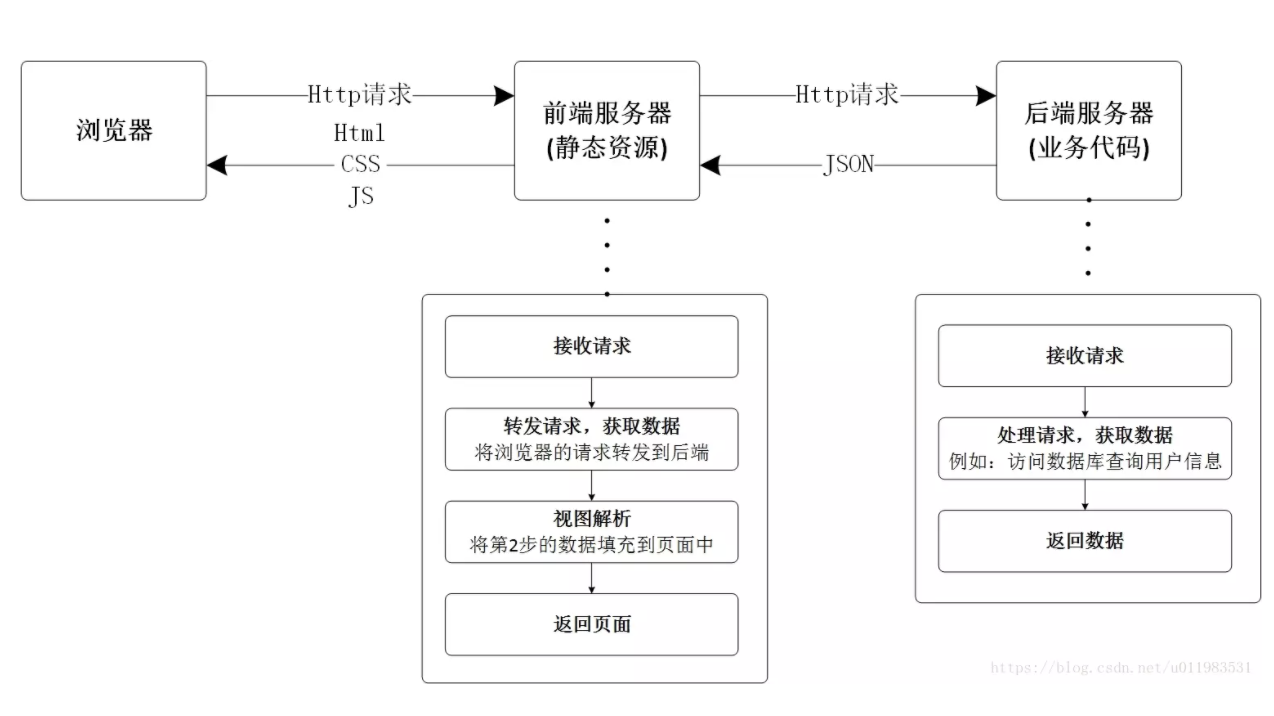
在前后端不分离架构中,所有的静态资源和业务代码统一部署在同一台服务器上。服务器接收到浏览器的请求后,进行处理得到数据,然后将数据填充到静态页面中,最终返回给浏览器。
1|4半分离时代
前后端半分离,前端负责开发页面,通过接口(Ajax)获取数据,采用Dom操作对页面进行数据绑定,最终是由前端把页面渲染出来。这也就是Ajax与SPA应用(单页应用)结合的方式,其结构图如下:
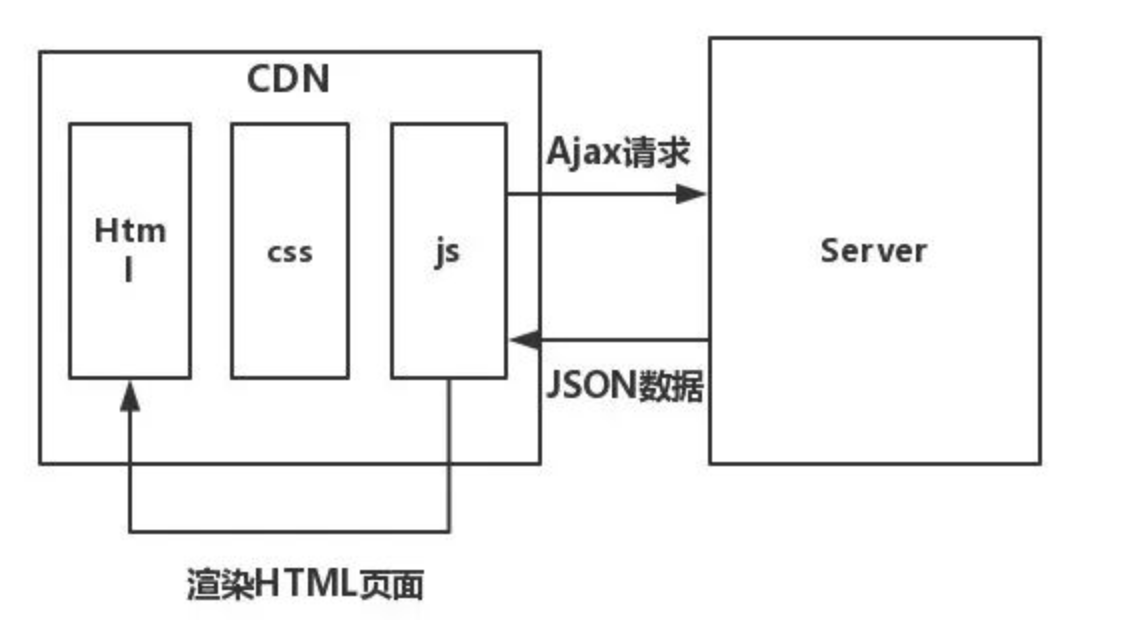
步骤如下
后端提供的都是以JSON为数据格式的API接口供Native端使用,同样提供给WEB的也是JSON格式的API接口。
那么意味着Web工作流程是
这些步骤都由用户所使用的设备中逐步执行,也就是说用户的设备性能与APP的运行速度联系的更紧换句话说就是如果用户的设备很低端,那么APP打开页面的速度会越慢。
为什么说是半分离的?因为不是所有页面都是单页面应用,在多页面应用的情况下,前端因为没有掌握controller层,前端需要跟后端讨论,我们这个页面是要同步输出呢,还是异步Json渲染呢?而且,即使在这一时期,通常也是一个工程师搞定前后端所有工作。因此,在这一阶段,只能算半分离。
首先,这种方式的优点是很明显的。前端不会嵌入任何后台代码,前端专注于HTML、CSS、JS的开发,不依赖于后端。自己还能够模拟Json数据来渲染页面。发现Bug,也能迅速定位出是谁的问题。
然而,在这种架构下,还是存在明显的弊端的。最明显的有如下几点:
1|5前后端分离
大家一致认同的前后端分离的例子就是SPA(Single-page application),所有用到的展现数据都是后端通过异步接口(AJAX/JSONP)的方式提供的,前端只管展现。从某种意义上来说,SPA确实做到了前后端分离,但这种方式存在两个问题:
- WEB服务中,SPA类占的比例很少。很多场景下还有同步/同步+异步混合的模式,SPA不能作为一种通用的解决方案;
- 现阶段的SPA开发模式,接口通常是按照展现逻辑来提供的,而且为了提高效率我们也需要后端帮我们处理一些展现逻辑,这就意味着后端还是涉足了view层的工作,不是真正的前后端分离。
SPA式的前后端分离,从物理层做区分(认为只要是客户端的就是前端,服务器端就是后端)这种分法已经无法满足前后端分离的需求,我们认为从职责上划分才能满足目前的使用场景:
controller层与view层对于目前的后端开发来说,只是很边缘的一层,目前的java更适合做持久层、model层的业务。
在前后端彻底分离这一时期,前端的范围被扩展,controller层也被认为属于前端的一部分。在这一时期:
可是服务端人员对前端HTML结构不熟悉,前端也不懂后台代码呀,controller层如何实现呢?这就是node.js的妙用了,node.js适合运用在高并发、I/O密集、少量业务逻辑的场景。最重要的一点是,前端不用再学一门其他的语言了,对前端来说,上手度大大提高。
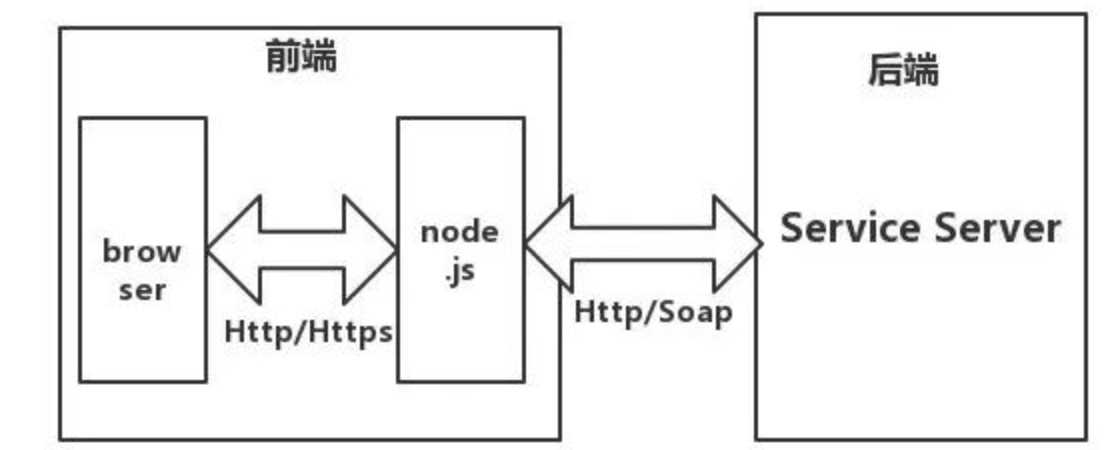
可以就把Nodejs当成跟前端交互的api。总得来说,NodeJs的作用在MVC中相当于C(控制器)。Nodejs路由的实现逻辑是把前端静态页面代码当成字符串发送到客户端(例如浏览器),简单理解可以理解为路由是提供给客户端的一组api接口,只不过返回的数据是页面代码的字符串而已。
用NodeJs来作为桥梁架接服务器端API输出的JSON。后端出于性能和别的原因,提供的接口所返回的数据格式也许不太适合前端直接使用,前端所需的排序功能、筛选功能,以及到了视图层的页面展现,也许都需要对接口所提供的数据进行二次处理。这些处理虽可以放在前端来进行,但也许数据量一大便会浪费浏览器性能。因而现今,增加Node中间层便是一种良好的解决方案。

浏览器(webview)不再直接请求jsp的api,而是
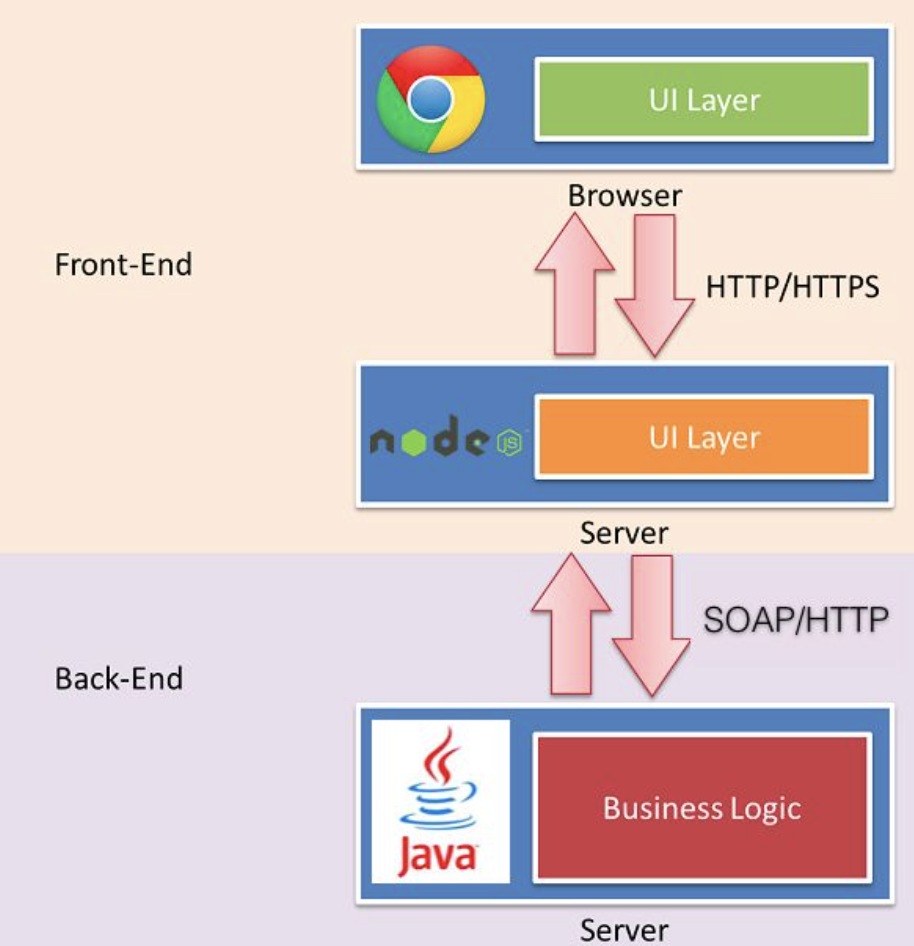
淘宝的前端团队提出的中途岛(Midway Framework)的架构如下图所示:
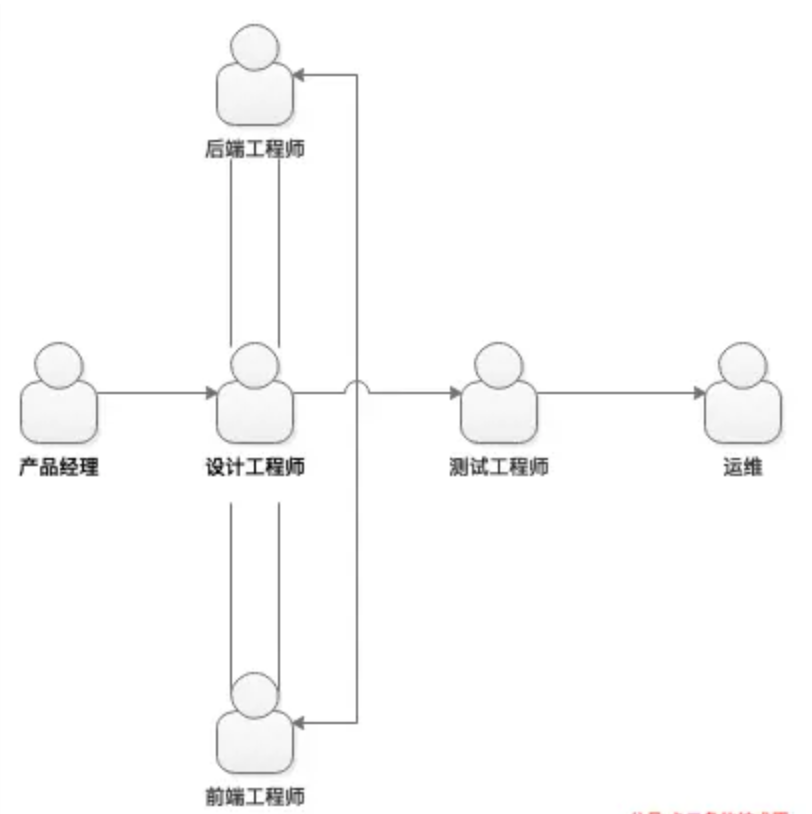
1|6前后端分离的模板探索
做前后端分离时,第一个关注的问题就是渲染, 也就是view这个层面工作
在传统的开发模式中,浏览器端与服务器端是由不同的前后端两个团队开发,但是模版却又在这两者中间的模糊地带。因此模版上面总不可避免的越来越多复杂逻辑,最终难以维护。
而我们选择了NodeJS,作为一个前后端的中间层。试图藉由NodeJS,来疏理 View 层面的工作。
使得前后端分工更明确,让专案更好维护,达成更好的用户体验。
1|7渲染
渲染这块工作,对于前端开发者的日常工作来说,佔了非常大的比例,也是最容易与后端开发纠结不清的地方。
回首过去前端技术发展的这几年, View 这个层面的工作,经过了许多次的变革,像是:
浏览器端渲染的好处
浏览器端渲染的坏处
1|8增加node.js中间层好处
1.适配性提升;我们其实在开发过程中,经常会给PC端、mobile、app端各自研发一套前端。其实对于这三端来说,大部分端业务逻辑是一样的。唯一区别就是交互展现逻辑不同。如果controller层在后端手里,后端为了这些不同端页面展示逻辑,自己维护这些controller,模版无法重用,徒增和前端沟通端成本。 如果增加了node.js层,此时架构图如下:

在该结构下,每种前端的界面展示逻辑由node层自己维护。如果产品经理中途想要改动界面什么的,可以由前端自己专职维护,后端无需操心。前后端各司其职,后端专注自己的业务逻辑开发,前端专注产品效果开发。
2.响应速度提升: 我们有时候,会遇到后端返回给前端的数据太简单了,前端需要对这些数据进行逻辑运算。那么在数据量比较小的时候,对其做运算分组等操作,并无影响。但是当数据量大的时候,会有明显的卡顿效果。这时候,node中间层其实可以将很多这样的代码放入node层处理、也可以替后端分担一些简单的逻辑、又可以用模板引擎自己掌握前台的输出。这样做灵活度、响应度都大大提升。
3.性能得到提升: 大家应该都知道单一职责原则。从该角度来看,我们,请求一个页面,可能要响应很多个后端接口,请求变多了,自然速度就变慢了,这种现象在mobile端更加严重。采用node作为中间层,将页面所需要的多个后端数据,直接在内网阶段就拼装好,再统一返回给前端,会得到更好的性能。
4.异步与模板统一;淘宝首页就是被几十个HTML片段(每个片段一个文件)拼装成,之前PHP同步include这几十个片段,一定是串行的,Node可以异步,读文件可以并行,一旦这些片段中也包含业务逻辑,异步的优势就很明显了,真正做到哪个文件先渲染完就先输出显示。前端机的文件系统越复杂,页面的组成片段越多,这种异步的提速效果就越明显。前后端模板统一在无线领域很有用,PC页面和WIFI场景下的页面适合前端渲染(后端数据Ajax到前端),2G、3G弱网络环境适合后端渲染(数据随页面吐给前端),所以同样的模板,在不同的条件下走不同的渲染渠道,模板只需一次开发。
增加nodejs中间层的前后端职责划分

2|0前后端分离技术分工
以前的JavaWeb项目大多数都是java程序员又当爹又当妈,又搞前端,又搞后端。
随着时代的发展,渐渐的许多大中小公司开始把前后端的界限分的越来越明确,前端工程师只管前端的事情,后端工程师只管后端的事情。正所谓术业有专攻,一个人如果什么都会,那么他毕竟什么都不精。大中型公司需要专业人才,小公司需要全才,但是对于个人职业发展来说,我建议是分开。
2|1对于后端java工程师
负责Model层, 业务处理/数据等
把精力放在java基础,设计模式,jvm原理,spring+springmvc原理及源码,linux,mysql事务隔离与锁机制,mongodb,http/tcp,多线程,分布式架构,弹性计算架构,微服务架构,java性能优化,以及相关的项目管理等等。
后端追求的是:三高(高并发,高可用,高性能),安全,存储,业务等等。
2|2对于前段工程师
负责view和controller层
把精力放在html5,css3,jquery,angularjs,bootstrap,reactjs,vuejs,webpack,less/sass,gulp,nodejs,Google V8引擎,javascript多线程,模块化,面向切面编程,设计模式,浏览器兼容性,性能优化等等。
前段追求的是: 页面表现,速度流畅,兼容性,用户体验等等。
术业有专攻,这样你的核心竞争力才会越来越高,正所谓你往生活中投入什么,生活就会反馈给你什么。并且两端的发展都越来越高深,你想什么都会,那你毕竟什么都不精。
通过将team分成前后端team,让两边的工程师更加专注各自的领域,独立治理,然后构建出一个全栈式的精益求精的team。
3|0开发模式
3|1不分离方式
产品经历/领导/客户提出需求=》UI做出设计图 =》前端工程师做html页面=》后端工程师将html页面套成jsp页面(前后端强依赖,后端必须要等前端的html做好才能套jsp。如果html发生变更,就更痛了,开发效率低)=》集成出现问题 ===》前端返工 =》后端返工=》二次集成 ===》集成成功 ==》交付
3|2分离方式
产品经历/领导/客户提出需===》UI做出设计图 ===》前后端约定接口&数据&参数 =》前后端并行开发(无强依赖,可前后端并行开发,如果需求变更,只要接口&参数不变,就不用两边都修改代码,开发效率高)=》前后端集成 ===》前端页面调整 ===》集成成功 ===》交付.
4|0请求方式
4|1不分离方式
4|2分离方式
大量并发浏览器请求 ---> web服务器集群(nginx) ---> 应用服务器集群(tomcat),文件/数据库/缓存/消息队列服务器集群同时又可以玩分模块,还可以按业务拆成一个个的小集群,为后面的架构升级做准备
5|0前后端分离优势
5|1可以实现真正的前后端解耦
前端服务器使用nginx。前端/WEB服务器放的是css,js,图片等等一系列静态资源(甚至你还可以css,js,图片等资源放到特定的文件服务器,例如阿里云的oss,并使用cdn加速),前端服务器负责控制页面引用&跳转&路由,前端页面异步调用后端的接口,后端/应用服务器使用tomcat(把tomcat想象成一个数据提供者),加快整体响应速度。(这里需要使用一些前端工程化的框架比如nodejs,react,router,react,redux,webpack)
5|2发现bug
发现bug,可以快速定位是谁的问题,不会出现互相踢皮球的现象。页面逻辑,跳转错误,浏览器兼容性问题,脚本错误,页面样式等问题,全部由前端工程师来负责。接口数据出错,数据没有提交成功,应答超时等问题,全部由后端工程师来解决。双方互不干扰,前端与后端是相亲相爱的一家人。
5|3大并发情况可以水平扩展前后端服务器
在大并发情况下,我可以同时水平扩展前后端服务器,比如淘宝的一个首页就需要2000+台前端服务器做集群来抗住日均多少亿+的日均pv。(去参加阿里的技术峰会,听他们说他们的web容器都是自己写的,就算他单实例抗10万http并发,2000台是2亿http并发,并且他们还可以根据预知洪峰来无限拓展,很恐怖,就一个首页。。。)
5|4减少后端服务器的并发/负载压力
减少后端服务器的并发/负载压力。除了接口以外的其他所有http请求全部转移到前端nginx上,接口的请求调用tomcat,参考nginx反向代理tomcat。且除了第一次页面请求外,浏览器会大量调用本地缓存。
5|5及时后端服务器暂时超时或者宕机,前端页面也会正常访问,只不过数据刷不出来而已
5|6多端应用
也许你也需要有微信相关的轻应用,那样你的接口完全可以共用,如果也有app相关的服务,那么只要通过一些代码重构,也可以大量复用接口,提升效率。(多端应用)
5|7页面显示的东西再多也不怕,因为是异步加载.
5|8nginx支持页面热部署,不用重启服务器,前端升级更无缝
5|9增加代码的维护性&易读性
前后端耦在一起的代码读起来相当费劲
5|10提升开发效率
因为可以前后端并行开发,而不是像以前的强依赖
5|11在nginx中部署证书,外网https访问,只开放443和80,其他端口一律关闭(防止黑客端口扫描),内网使用http,性能和安全都有保障
5|12前端大量的组件代码得以复用,组件化,提升开发效率,抽出来
6|0前后端分离注意事项
1.在开需求会议的时候,前后端工程师必须全部参加,并且需要制定好接口文档,后端工程师要写好测试用例(2个维度),不要让前端工程师充当你的专职测试,推荐使用chrome的插件postman或soapui或jmeter,service层的测试用例拿junit写。ps:前端也可以玩单元测试吗?
2.上述的接口并不是java,go里的interface,说白了调用接口就是调用你controler里的方法。
3.加重了前端团队的工作量,减轻了后端团队的工作量,提高了性能和可扩展性。
4.我们需要一些前端的框架来解决类似于页面嵌套,分页,页面跳转控制等功能。(上面提到的那些前端框架).
5.如果你的项目很小,或者是一个单纯的内网项目,那你大可放心,不用任何架构而言,但是如果你的项目是外网项目...
6.以前还有人在使用类似于velocity/freemarker等模板框架来生成静态页面,仁者见仁智者见智。
7.这篇文章主要的目的是说jsp在大型外网java web项目中被淘汰掉,可没说jsp可以完全不学,对于一些学生朋友来说,jsp/servlet等相关的java web基础还是要掌握牢的,不然你以为springmvc这种框架是基于什么来写的?
8.如果页面上有一些权限等等相关的校验,那么这些相关的数据也可以通过ajax从接口里拿。
9.对于既可以前端做也可以后端做的逻辑,我建议是放到前端,为什么?因为你的逻辑需要计算资源进行计算,如果放到后端去run逻辑,则会消耗带宽&内存&cpu等等计算资源,你要记住一点就是服务端的计算资源是有限的,而如果放到前端,使用的是客户端的计算资源,这样你的服务端负载就会下降(高并发场景)。类似于数据校验这种,前后端都需要做!
10.前端需要有机制应对后端请求超时以及后端服务宕机的情况,友好的展示给用户
7|0前后端接口联调
7|1前言
以JC同事为例,他公司为前后端分离架构,前端vue全家桶;前后端人员开会协商数据接口后(主要是定义传输的数据和API接口),前后端并行开发;因为后台此时无法提供后端数据,所以前端需要用mock模拟假数据,管理API接口,获取数据,到时接口联调时连接后端服务器,访问后端数据即可。
但是JC同事的ajax的借口写的是与后端叔叔商量好的绝对路径(域名+请求路径+请求参数,跨域问题已解决),因为这是以后真正的请求路径,所以JC同事又不像先写本地相对路径,后期再来修改(万一后台叔叔开发的慢了,鬼知道有多少接口要修改呀)。于是他就迷茫了。。。
仔细看看这其实就是前后端分离中的mock数据和联调的问题,就现在来说能解决的方式有很多种。先说mock数据,gulp,webpack, fekit (去哪儿网的一款前端自动化构建工具,据说历史比webpack和gulp都要久远)等等自动化构建工具都有mock数据的功能,这不是问题;再说绝对路径的问题,其实只需要做一个host的映射就行了。
7|2什么是前后端接口联调
之前开发写代码的时候,所有的ajax数据都不是后端返回的真实数据,而是我们自己通过接口mock模拟的假数据,当前端的代码编写完毕,后端的接口也已经写好之后,我们就需要把mock数据干掉,尝试使用后端提供的数据,进行前后端的一个调试,这个过程我们就把它称之为前后端的接口联调。
为什么要联调 本地的mock数据是JC同事自己写的,肯定符合前端需求,但是后端接口首先需要测试通不通,还需要测试数据格式对不对,还有后端有没有填写足够的数据,比如写列表页,前端想分页,如果后端就写了两条测试数据,你咋整? 所以,Jack需要根据后端对接口的调整,不断地来回切换url,这样岂不是还在受后端的影响,还谈什么毛线的前后端分离,名存实亡嘛!
7|3如何实现前后端接口联调
首先,我们已经知道,目前的前后端分离的架构应用分为两种情况:
前后端完全分离,前后端分别拥有自己的域名和服务器
前后端开发分离,但是部署时是一个域名和一台服务器
虽然架构可以采用前后端分离,但是部署有可能就不一样了,这和项目的大小,公司的情况等等都有关系了,一个百八十人用的小系统,还得两台服务器两个域名,你不觉着浪费吗?两种不同的部署情况直接导致了前期在设计联调方案的时候就不同了.
如果你们公司的项目在部署时是两台服务器对应两个域名,恭喜你,这是最nice的方案,也是联调最舒服的方式。第二种情况,也就是开发时前后端分离,部署时是一个域名和一台服务器。知道这个之后,他就明白接下来该怎么操作了。JC同事之前在项目根目录static文件夹下新建了一个mock文件夹,里面写了一些json文件,当我们做联调的时候,这些mock数据就没用了,我们要把mock数据切换成后端提供给我们的真实的数据。
当我的朋友Jack把static文件夹下的mock数据删除之后,在运行项目,发现报错了,浏览器告诉他,你访问的mock下面的index.json文件找不到404。
我们平时本地前端开发环境dev地址大多是 localhost:8080,而后台服务器的访问地址就有很多种情况了,比如 后端程序猿本地IP(127.0.0.1:8889),或者外网域名,当前端与后台进行数据交互时,自然就出现跨域问题(后台服务没做处理情况下)。axios不支持jsonp, 所以我们就要使用http-proxy-middleware中间件做代理。
现在通过在前端修改 vue-cli 的配置可解决: vue-cli中的 config/index.js 下配置 dev选项的 {proxyTable}:
如果你想在公司的vue项目中实现前后端联调,不需要再使用类似于fiddler charles的抓包代理工具了,你只需要使用proxyTable这个配置项,把你需要请求的后端的服务器地址写在target值里就OK了。
解决完跨域问题后,接下来Jack该想想怎么在一台服务器一个域名下进行联调的问题了。比较常见的做法是前端在本地修改,本地查看,测试好了以后上传到服务器,看看线上环境可不可以,OK的话一切都好;不行就本地接着改,然后在上传。
联调完之后,如何将前端打包的项目文件发给后端,这里也需要注意两点:
1.css,js和图片等静态文件
这时候的静态文件在开发阶段不需要任何考虑,按照你喜欢的相对路径或者相对于项目的根路径的形式写就行了,因为早晚还得交给后端。但是,需要注意:
如果你采用 相对项目根路径的书写方式来写你的静态文件路径 时,一定要先和后端商量好,将来项目部署的时候他会把你的前端整个项目放在哪里?如果不是根目录下,你就挂了。比如:你的reset.css的路径是 /exports/styles/common/reset.css ,后端把你前端项目放在了根目录下的 frontEnd 文件夹下, reset.css 文件就报404了。
如果后端采用的java,你需要特别注意的是, tomcat的根目录 并不是 webapps 文件,而后端项目默认是部署在 webapps/ROOT 文件下的,所以你如果使用了相对项目根路径的书写方式来写你的静态文件路径时,对不起又是404了。
2.ajax后端数据
因为现在唯一的一台服务器还是在后端程序猿那里,所以此时你还是可以写绝对路径(域名+请求路径),利用hosts文件来改变域名映射实现联调。
7|4接口问题排错
1.查看接口日志,查看是否有任何异常信息,还有请求参数
2.让前端调用接口地址改为我本地服务器接口地址,进行测试,如果本地没问题而且远程代码和本地代码一样,就可以排除代码同步问题
3.查看接口代码,看哪个地方有可能出现异常,并且异常被捕获没被处理,很有运行过程出错了,但是异常被吃掉,导致保存附件失败并且没有任何异常信息
4.登录测试服务器,查看该服务器是否能访问保存附件的云端服务器地址,如果不能则测试服务器网络问题,有可能是权限问题,被限制访问
5.登录测试服务器查看日志文件,看是否有异常信息
8|0接口规范
8|1后端需给出固定的路径
比如 /xxapi
8|2后端返回的基本数据结构
默认的数据结构应该至少有这3个属性,如果没有数据则
data为null;success属性是方便前端判断响应结果是否为成功的状态,比如登录页需要响应给前端的错误信息有很多种,而前端首先需要知道是成功还是失败来进行逻辑编码;如果失败,前端可直接将message显示给用户。
8|3后端返回的列表页数据结构
total为记录总数,current为当前第几页,默认显示数前后端应商定好,比如20条,写到各自工程的配置参数。
8|4后端返回的详情页数据结构
8|5前端提交的新建 / 修改页数据结构
8|6后端返回的基础(单个)柱图、饼图、折线图的图表数据结构
8|7后端返回的多条折线图的图标数据结构
9|0常见接口报错及解决方案
在前端页面访问后端接口的时候,如果后端或服务器端未做一些设置,会造成页面访问接口失败,在浏览器的控制台会显示报错信息。下面针对一些常见的错误,列出了解决方案。
9|1不通端口或不同域名产生的跨域问题
Failed to load ... : No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://...' is therefore not allowed access. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
出现这个错误是因为前端页面跟后端接口在不同的端口或IP或域名下面,也就是跨域。关于跨域你可能需要详细了解 跨域资源共享 CORS。跨域产生的原因是浏览器遵循的基本安全策略 - [MDN web docs浏览器的同源策略]。
解决方案
如果后端是Java项目,一般是在开发环境服务器的nginx配置文件中添加上面几项来统一配置,而不是在后端代码里配置。添加完后重启nginx,然后在浏览器的响应头里应该可以看到刚才配置的几项,说明配置成功。这里
Access-Control-Allow-Origin设置为*表示允许所有的域,也可以根据具体的环境来设置具体的IP或域名。
9|2请求头类型的错误
这个错误当前请求Content-Type的值不被支持。可能前端发送的请求头类型有
application/json,这个请求涉及到预检请求,可参看 HTTP访问控制(CORS)。
解决方案
nginx配置文件中添加这项配置,表示接收前端的
Content-Type。
9|3携带cookie设置问题
Failed to load ... : Response to preflight request doesn't pass access control check: The value of the 'Access-Control-Allow-Credentials' header in the response is '' which must be 'true' when the request's credentials mode is 'include'. Origin 'http://...' is therefore not allowed access.
出现这个错误是因为前端请求接口的时候在请求头里加了
credentials: 'include'参数携带cookie信息,而后端未做接收cookie的设置。
解决方案
nginx配置文件中添加这项配置,表示接收前端携带的cookie信息。只有前后端都设置,跨域携带cookie请求才能成功。详细的了解可参看 [MDN web docs Access-Control-Allow-Credentials]
9|4自定义响应头解决方案
在独立的前端工程中,用户访问到的虽然是静态页面,而实际上现在的前端页面已经有了自己的路由、权限控制等等。
在独立的前端工程工程中同样会碰到一个问题:前端页面如何比较好的获取用户超时状态来退出登录?本文介绍使用自定义响应头字段来解决这个问题。
解决方案
1.后端在响应头里增加属性, 例如
后端代码通过增加
x-session-expired为1来告诉前端当前用户超时了。然后在浏览器的响应里应该能看到上面这个配置。但是前端在跨域请求情况下默认只能获取到响应头里的Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma6个基本字段,如果要获取到刚增加的x-session-expired字段,需要进行下一步。
2.后端增加以下配置
该配置的作用是指定哪些首部可以作为响应的一部分暴露给外部,这样前端才能获取到上面一步添加的
x-session-expired字段及其值。
3.前端在fetch请求时候获取自定义响应头字段
可以看到上面代码的
headers.has('x-session-expired'),前端通过has方法来获取响应头里是否有x-session-expired字段,来判断是退出还是解析数据。至此,后端设置自定义响应头字段且前端获取该字段的问题解决了。该方法也同样适用于添加其他的响应头字段,解决无权限或其他问题。
10|0前端性能优化
10|1内容优化
10|2服务器优化
10|3css优化
10|4javascript优化
10|5图像优化
10|6前端安全问题
__EOF__

本文链接:https://www.cnblogs.com/you-men/p/14081203.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类