03 . Elasticsearch概念及Search和Analyzer简单使用

分布式系统的可用性与扩展性
高可用性
# 服务可用性 - 允许所有节点停止服务
# 数据可用性 - 部分节点丢失,不会丢失数据
可扩展性
# 请求量提升 / 数据的不断增长(将数据分布在所有节点上)
分布式特性
Elasticsearch分布式架构的好处
# 存储的水平扩容
# 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
Elasticsearch的分布式架构
# 不同的集群通过不同的名字来区分,默认名字"elasticsearch"
# 通过配置文件修改,或者在命令行中 - E claster.name=geektime进行设定
# 一个集群可以有一个或者多个节点
倒排索引
# 图书
# 正排索引 - 目录页
# 倒排索引 - 索引页
# 搜索引擎
# 正排索引 - 文档ID到文档内容和单词的关联
# 倒排索引 - 单词到文档ID的关系.
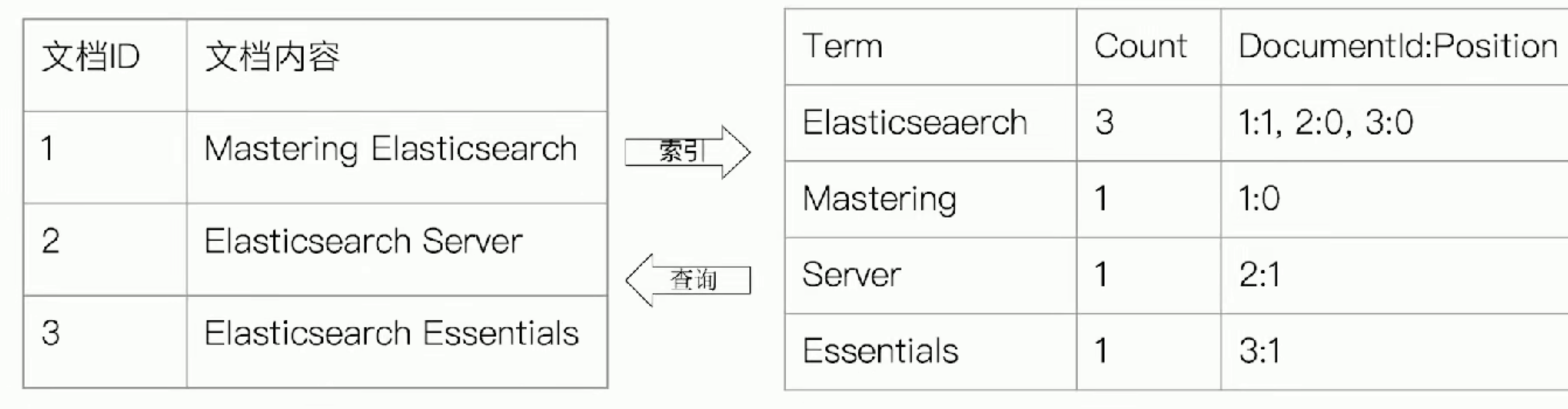
倒排索引的核心组成
单词词典(Term Dictionary)
记录所有文档的单词,记录单词到倒排列表的关联关系, 单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足性能的插入与查询.
倒排列表(Posting List)
记录了单词对应的文档结合,由倒排索引项组成
倒排索引项(Posting)
# 文档ID
# 词频 TF - 该单词在文档中出现的次数,用于相关性评分
# 位置(Position) - 单词在文档中分词的位置,用于语句搜索(phrase query)
# 偏移(Offset) - 记录单词的开始结束为止,实现高亮显示
优点缺点
# Elasticsearch 的JSON文档中的每个字段,都有自己的倒排索引
# 可以指定对某些字段不做索引
# 优点: 节省存储空间
# 缺点: 字段无法被搜索
Analyzer分词
Analysis与Analyzer
# Analysis - 文本分析是把全文本转换一系列单词(term / token)的过程,也叫分词
# Analysis是通过Analyzer来实现的
# 可使用Elasticsearch内置的分析器/或者按需定制化分析器
# 除了在数据写入时转换词典,匹配Query语句时也需要用相同的分析器对查询语句进行分析

Analyzer的组成
分词器是专门处理分词的组件, Analyzer由三部分组成:
Character Filters (针对原始文本处理,例如去除html) / Tokenizer(按照规则切分为单词) / TokenFilter(将切分的单词进行加工, 小写,删除stopwords,增加同义词)
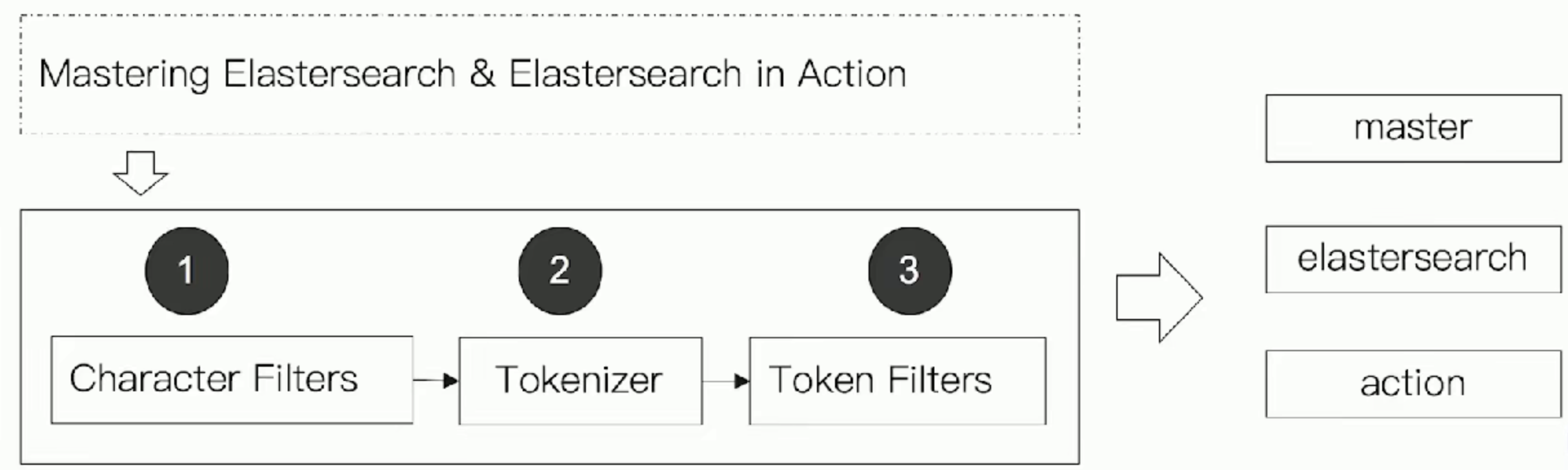
Elasticsearch内置分词器
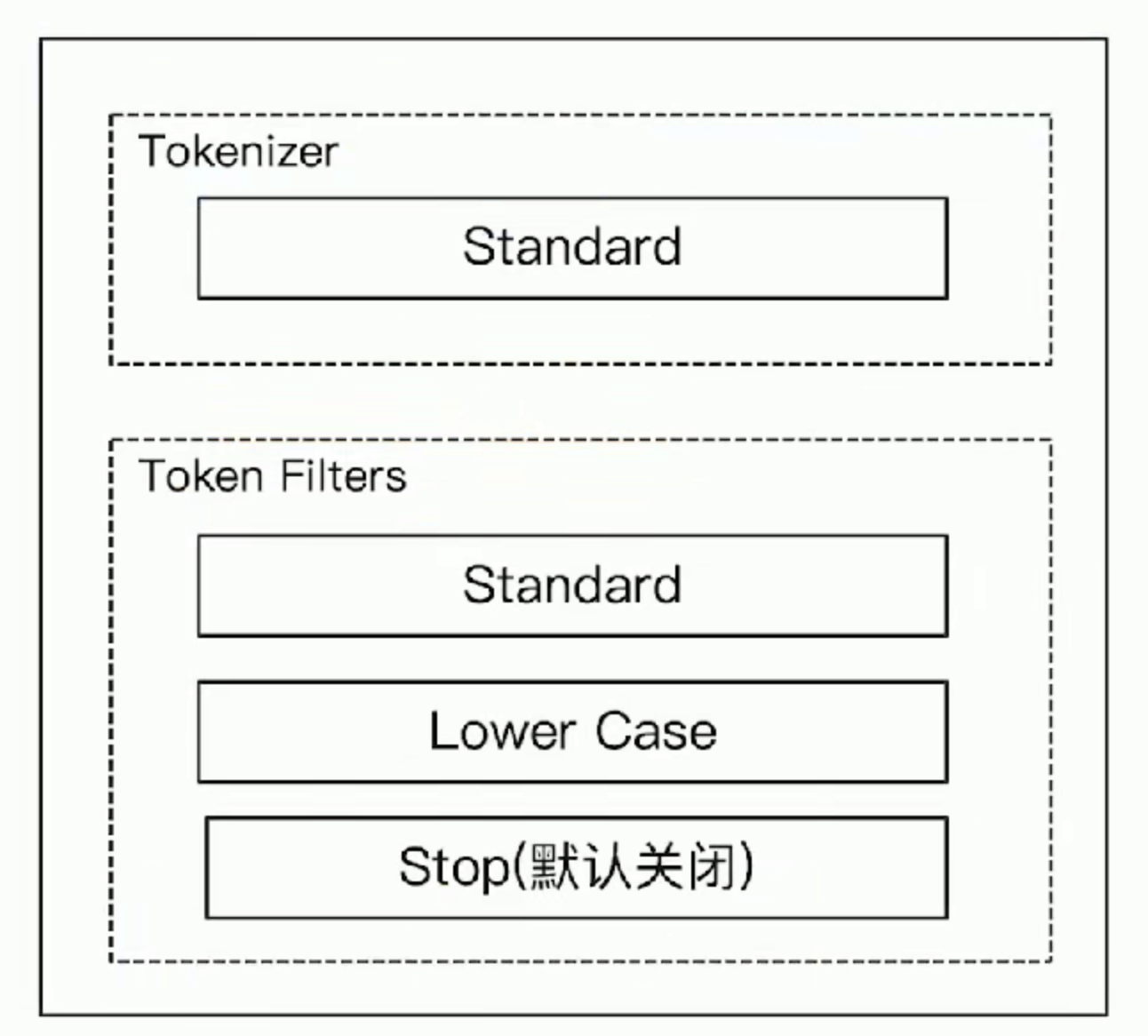
# Standard Analyzer - 默认分词器,按词切分,小写处理
# Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
# Stop Analyzer - 小写处理,停用词过滤(the,a,is)
# Whitespace Analyzer - 按照空格切割,不转小写
# Keyword Analyzer - 不分词,直接将输入当做输出
# Patter Analyzer - 正则表达式,默认\W+ (非字符分割)
# Language - 提供30多种常见语言的分词器
# Customer Analyzer 自定义分词器
使用 _analyzer API
# 直接指定Analyzer进行测试
# 指定索引的字段进行测试
# 自定义分词起进行测试
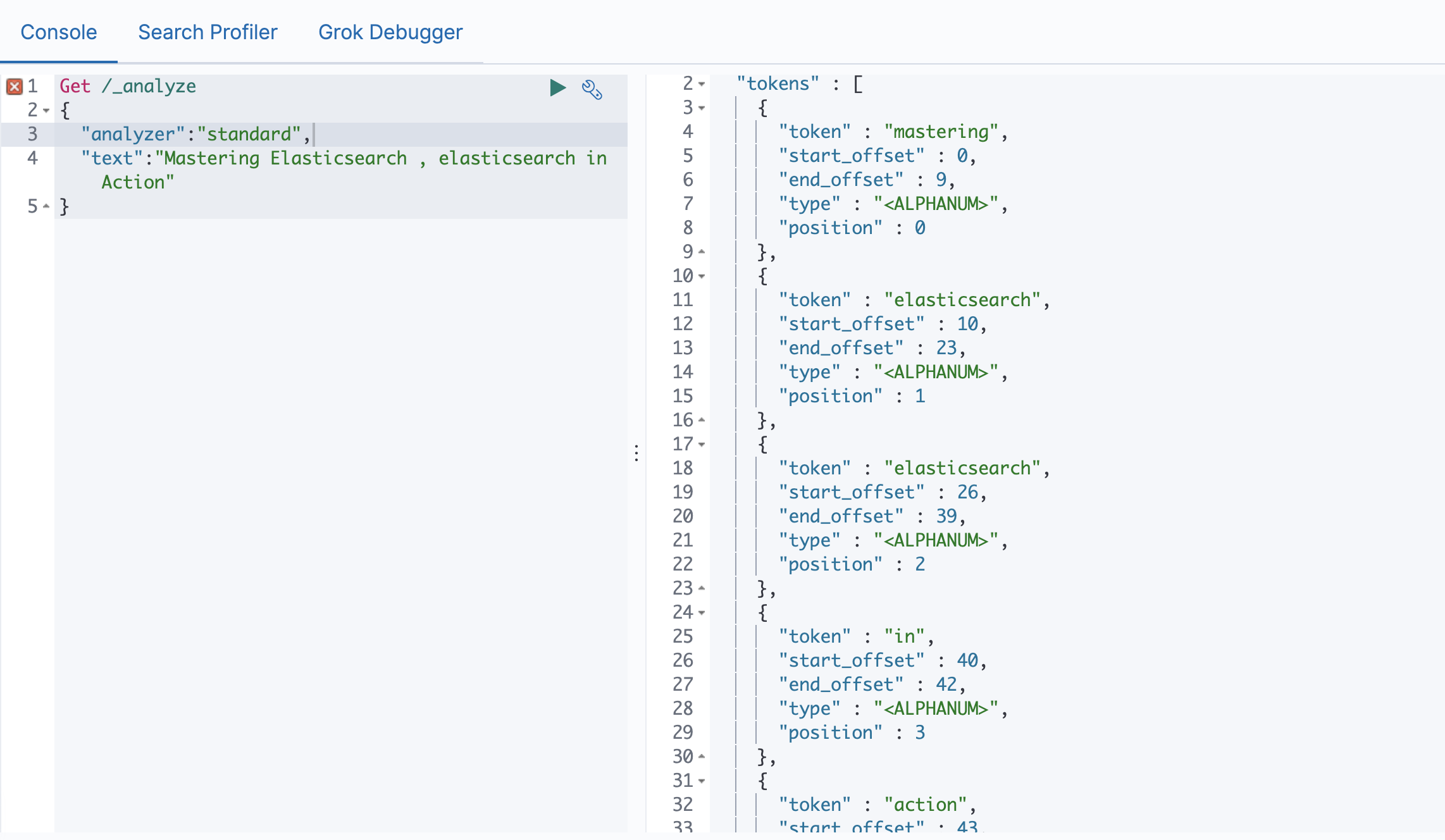
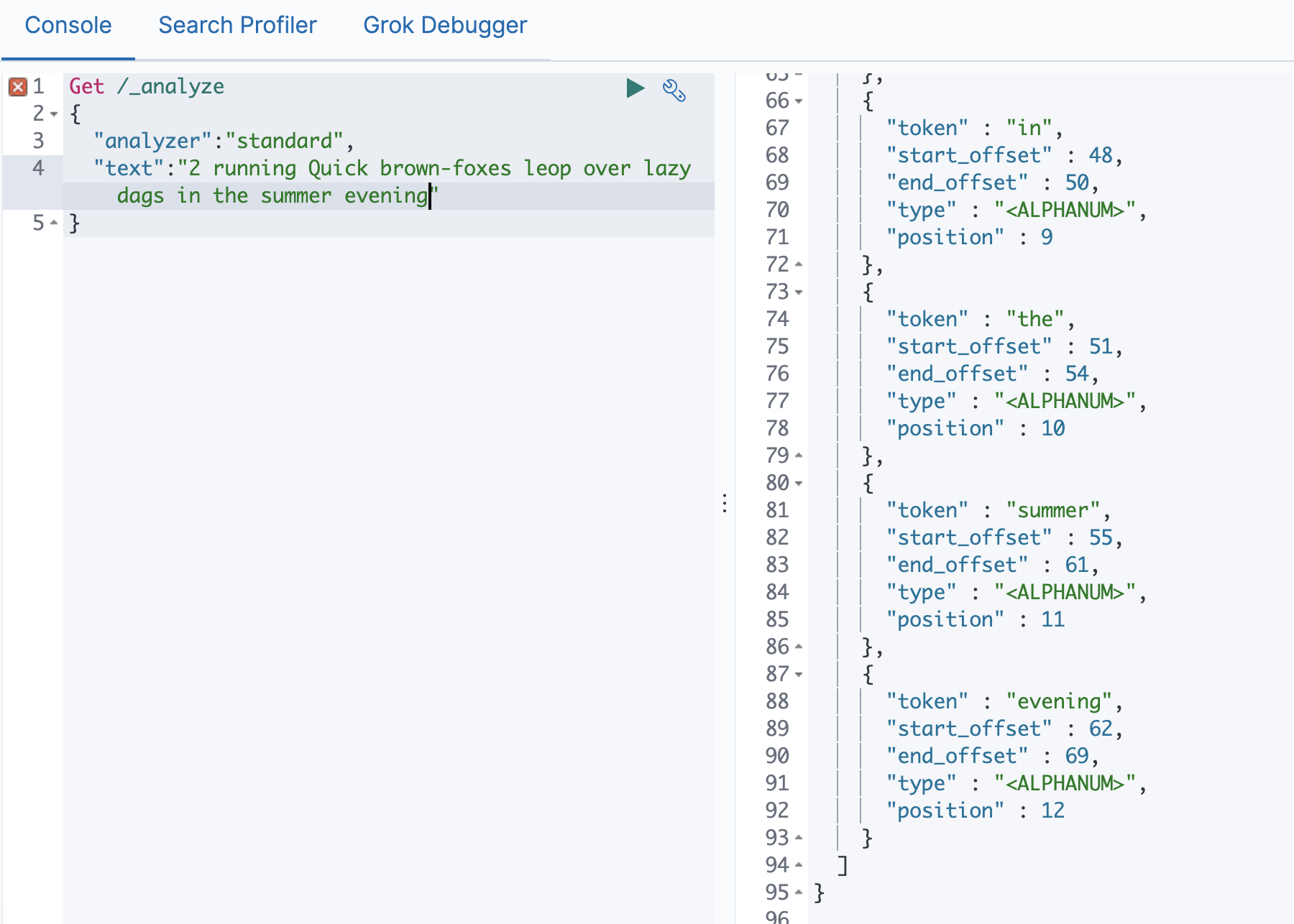
Standard Analyzer
# 默认分词器
# 按词切分
# 小写处理
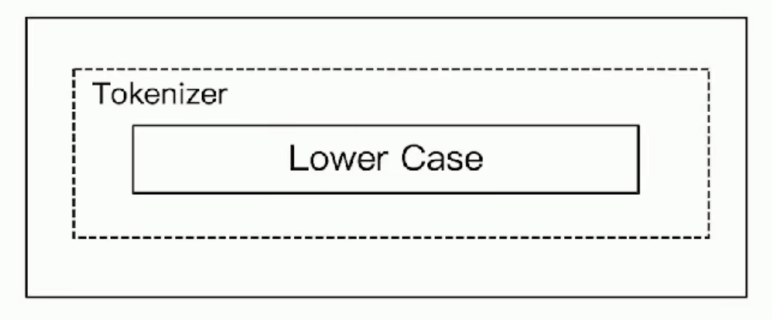
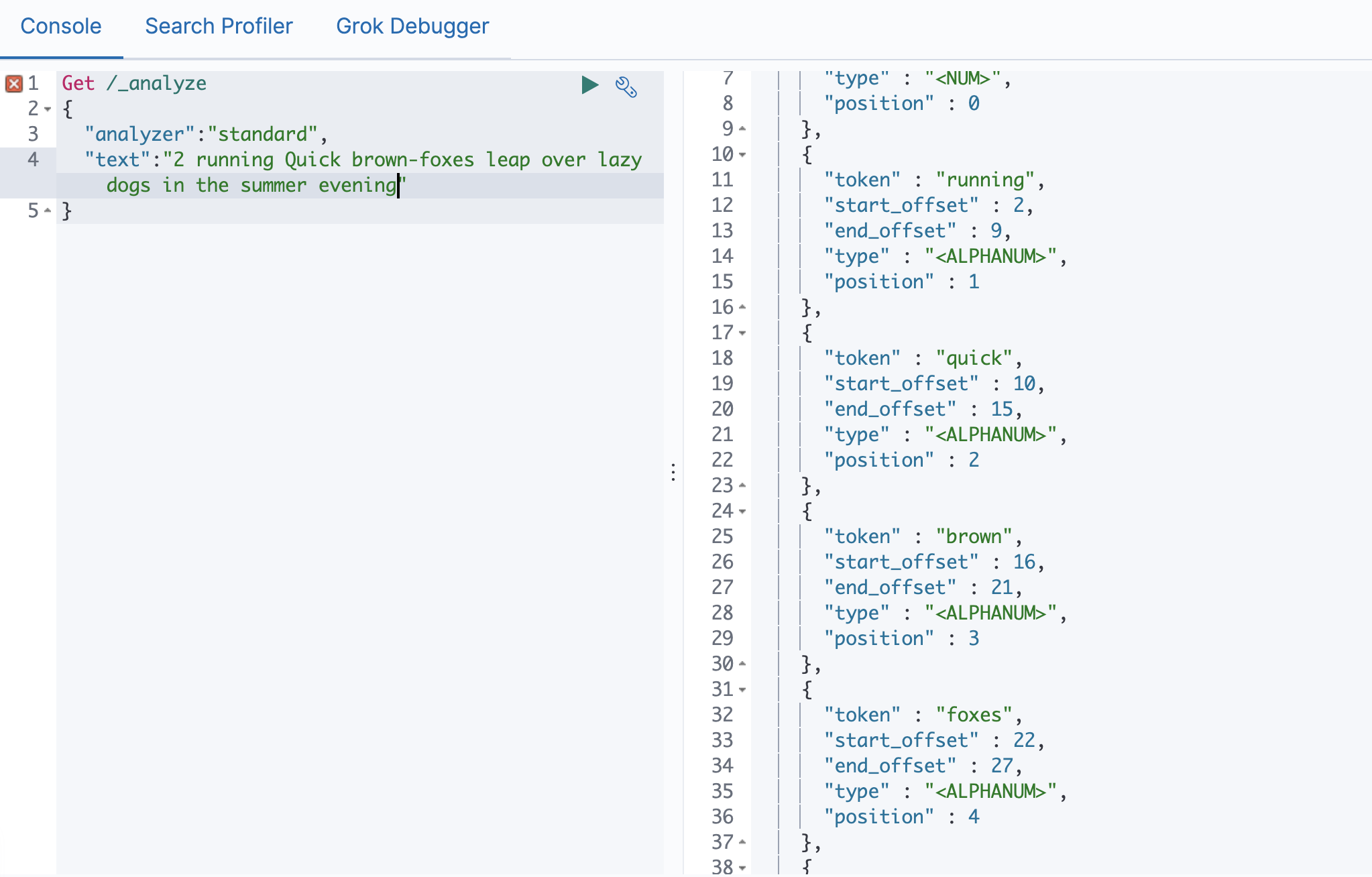
Simple Analyzer
# 按照非字母切分,非字母的都被去除
# 小写处理
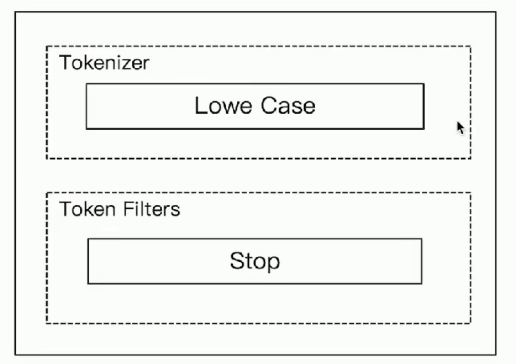
Stop Analyzer
# 相比Simple Analyzer
# 多了Stop Filter
# 会把the, a, is 等修饰性词语去除
5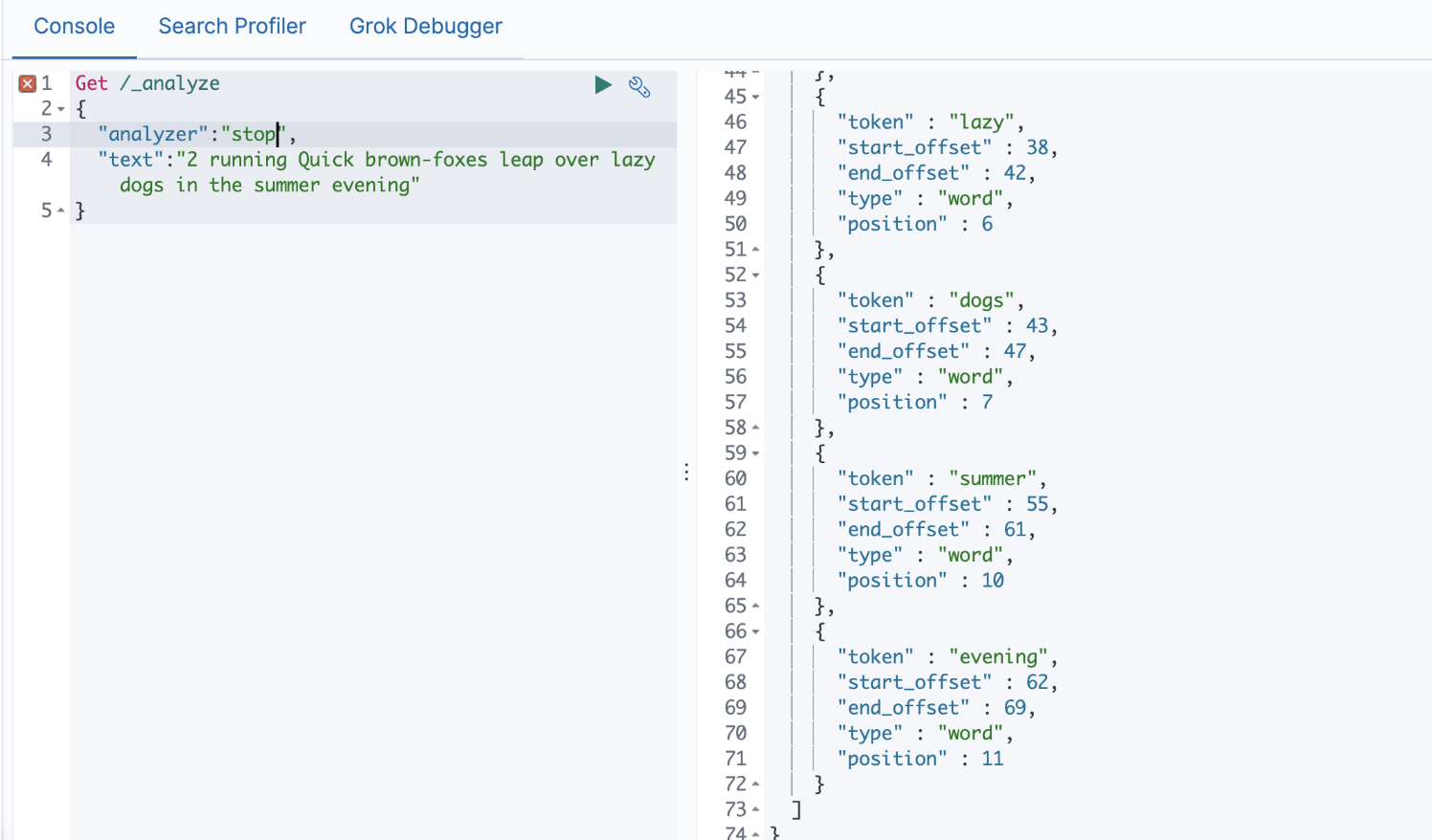
中文分词的难点
# 中文句子,切分成一个一个词(不是一个个字)
# 英文中,单词有自然的空格作为分隔
# 一句中文,有不通的上下文,有不同的理解
# 这个苹果,不太好吃 / 这个苹果,不大,好吃!
# 一些例子
# 他说的确实在理 / 这事的确定不下来
# 可以使用ICU Analyzer
Elasticsearch-plugin install analysis-icu
# 提供了Unicode的支持,更好的支持亚洲语言
# 更多的中文分词器
IK
# 支持自定义词库,支持热更新分词字典
THULAC
# THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
SearchAPI简介
# 分为两大类
# URL Search
# 在URL中使用查询参数
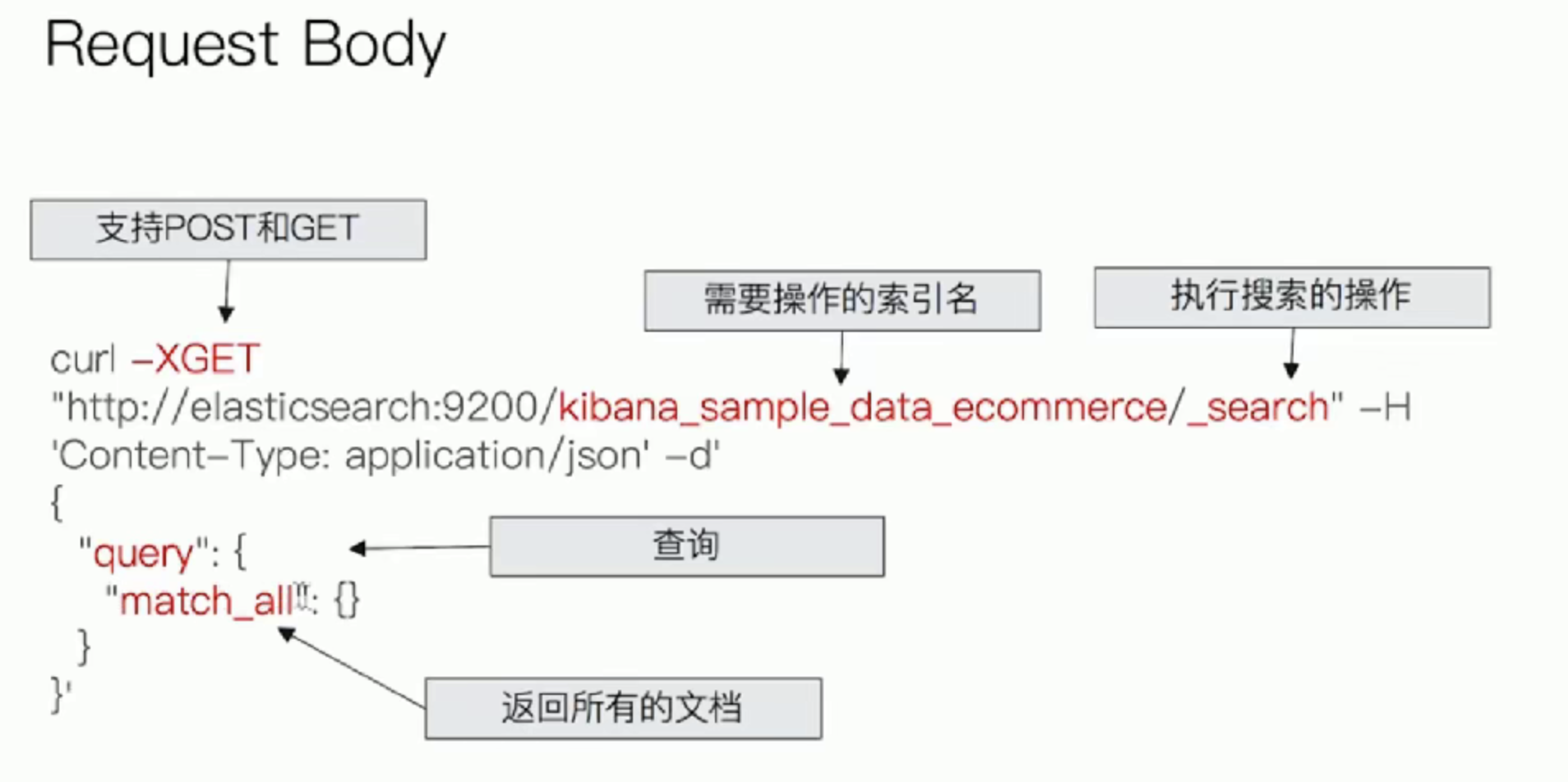
# Request Body Search
# 使用Elasticsearch提供的,基于JSON格式的更加完备的Query Domain Specific Language(DSL)
指定查询的索引
| 语法 | 范围 |
|---|---|
| /_search | 集群上所有的索引 |
| /index1/_search | index1 |
| /index1,index-2/_search | index1和index2 |
| /index*/_search | 以index开头的索引 |
URL查询
# 使用"q", 指定查询字符串
# "query string syntax", KV键值对
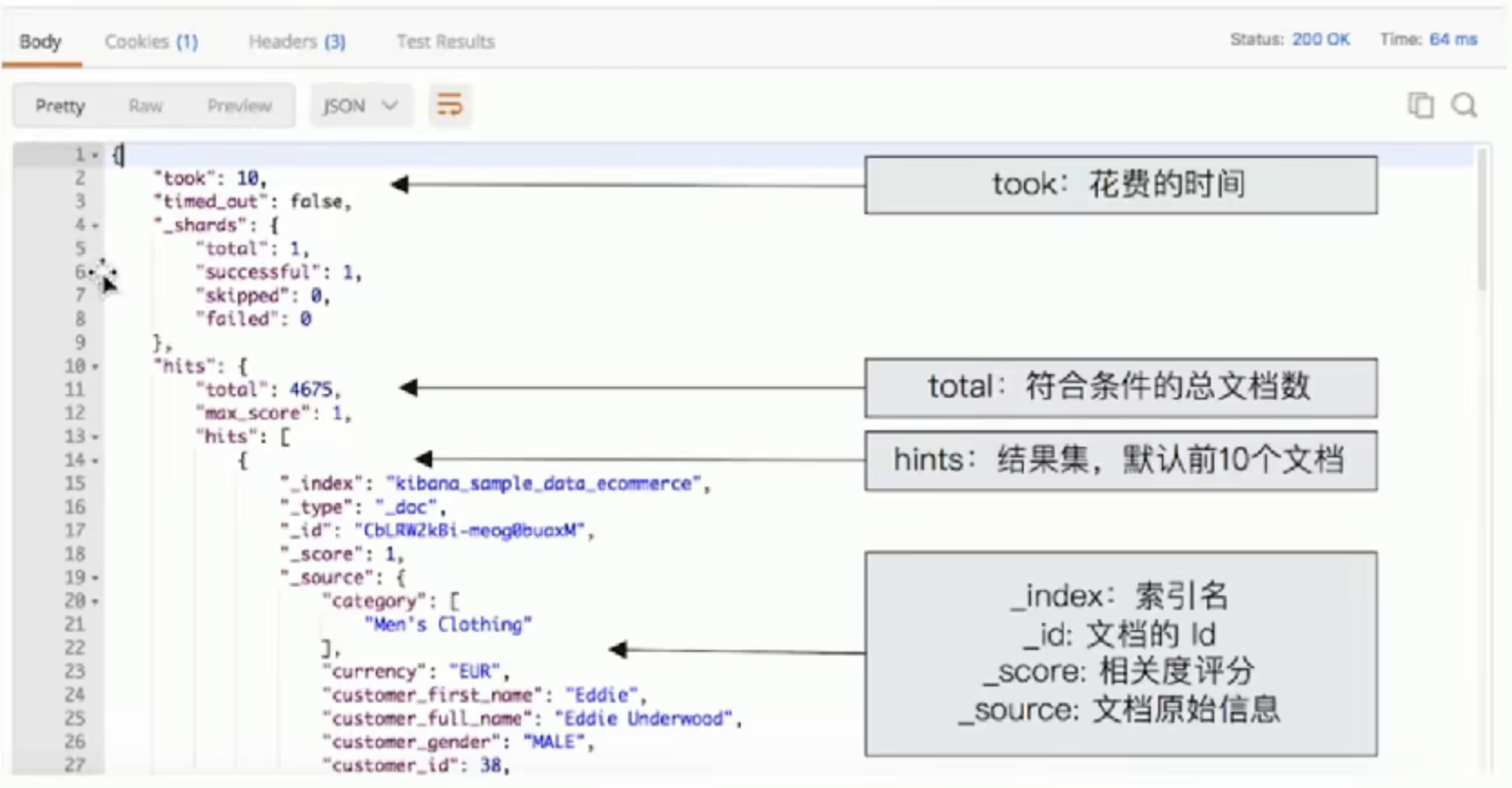
curl -XGET "http://elasticsearch:9200/kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie"
# q表示查询内容
# 搜索叫做Eddie的客户
搜索的相关性Relevance
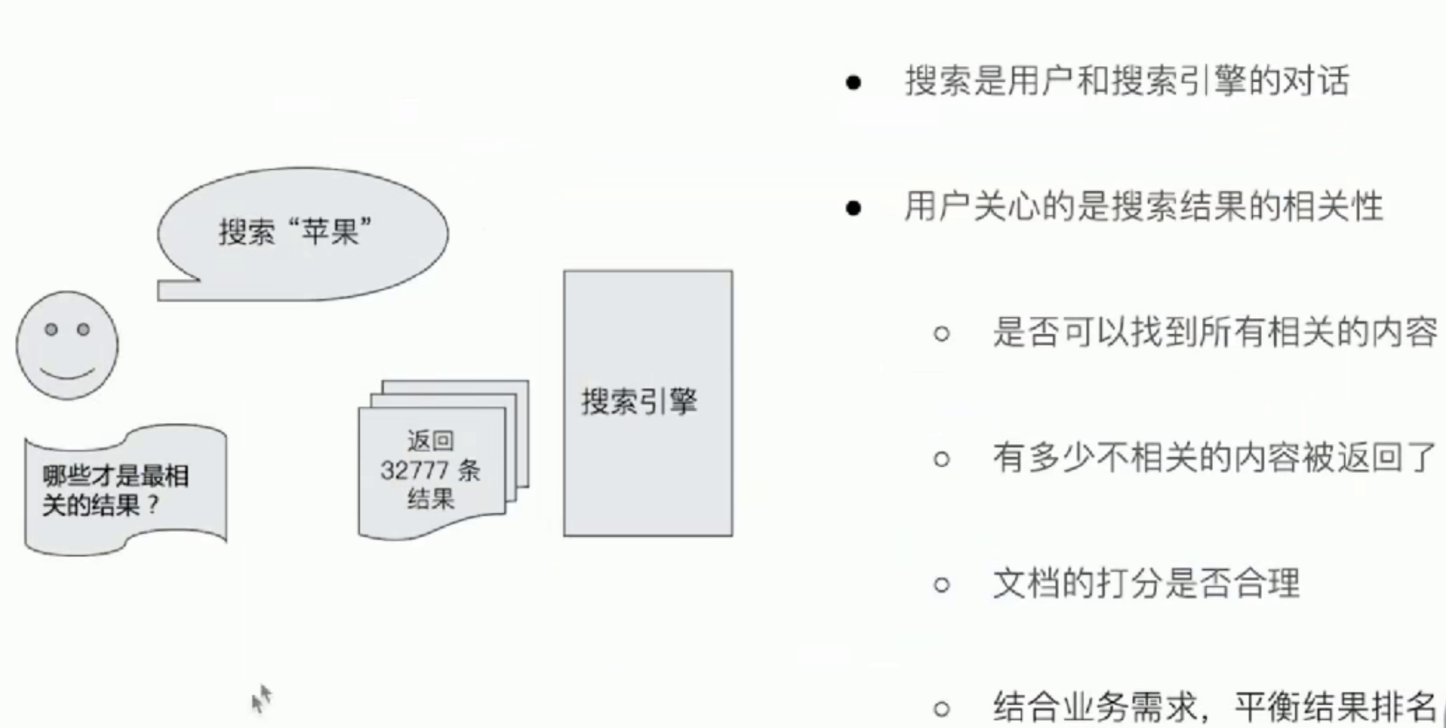
衡量相关性
# information Retrieval
# Precision(查准率) - 尽可能返回较少的无关文档
# Recall(查全率) - 尽量返回较多的相关文档
# Ranking - 是否能够按照相关度进行排序
URL Search
通过URL query实现搜索
# GET /movies/_search?q=2012&df=title&sort=yeas:desc&from=O&size=10&timeout=1s
{
"profile" : true
}
# q 指定查询语句,使用Query String Syntax
# df 默认字段, 不指定时,会对所有字段进行查询
# Sort 排序 / from 和size 用于分页
# Profile 可以查看查询是如何被执行的
删除索引
删除指定索引
# curl -XDELETE -u elastic:changeme http://localhost:9200/acc-apply-2018.08.09
{"acknowledged":true}
删除多个指定索引,中间用逗号隔开
# curl -XDELETE -u elastic:changeme http://localhost:9200/acc-apply-2018.08.09,acc-apply-2018.08.10
模糊匹配删除
# curl -XDELETE -u elastic:changeme http://localhost:9200/acc-apply-*
{"acknowledged":true}
使用通配符,删除所有索引
curl -XDELETE http://localhost:9200/_all
或 curl -XDELETE http://localhost:9200/*
# _all ,* 通配所有的索引
# 通常不建议使用通配符,误删了后果就很严重了,所有的index都被删除了
# 禁止通配符为了安全起见,可以在elasticsearch.yml配置文件中设置禁用_all和*通配符
# action.destructive_requires_name = true
# 这样就不能使用_all和*了
获取当前索引
# curl -u elastic:changeme 'localhost:9200/_cat/indices?v'
定时删除索引,下面是保存10天的
30 2 * * * /usr/bin/curl -XDELETE -u elastic:changeme http://localhost:9200/*-$(date -d '-3days' +'%Y.%m.%d') >/dev/null 2>&1
#!/bin/bash
time=$(date -d '-3days' +'%Y.%m.%d')
curl -XDELETE -u elastic:changeme http://localhost:9200/*-${time}
节点
# 节点是一个Elasticsearch的实例
# 本质上就是一个JAVA进程
# 一台机器上可以运行多个Elasticsearch进程,但是生产环境一般建议一台机器上只运行一个Elasticsearch实例
# 每一个节点都有名字,通过配置文件配置,或者启动时候 -E node.name=node1指定
# 每一个节点在启动之后,会分配一个UID,保存在data目录下.
Master-eligible nodes 和 Master Node
# 每个节点启动后,默认就是一个Master eligible节点
# 可以设置node.master: false禁止
# Master-eligible节点可以参加主流程,成为Master节点
# 当一个节点启动时候,他会将自己选举成Master节点
# 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息.
# 集群状态(Cluster State), 维护了一个集群中,必要的信息
# 所有的节点信息
# 所有的索引和其相关的Mapping与Setting信息
# 分片的路由信息
# 任意节点都能修改信息会导致数据的不一致性.
Data Node
# 可以保存数据的节点,叫做Data Node, 负责保存分片数据,在数据扩展上起到了至关重要的作用.
Coordinating Node
# 负责接收Client的请求,将请求分发到合适的节点,最终把结果汇集到一起.
# 每个节点默认都起到了Coordinating Node的职责.
Hot & Warm Node
# 不同硬件配置的Data Node,用来实现 Hot & Warm架构,降低集群部署的成本.
Machine Learning Node
# 负责跑机器学习的Job, 用来做异常检测
Tribe Node
# (5.3开始使用Cross Cluster Serarch) Tribe Node连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理.
配置节点类型
# 开发环境中一个节点可以承担多种角色
# 生产环境中,应该设置单一的角色的节点(dedicated node)
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | Node.master | true |
| data | Node.data | true |
| ingest | Node.ingest | true |
| coordinating only | 无 | 每个节点默认都是coordinating节点,设置其他类型全部为false |
| machine learning | node.ml | true(需enable x-pack) |
分片
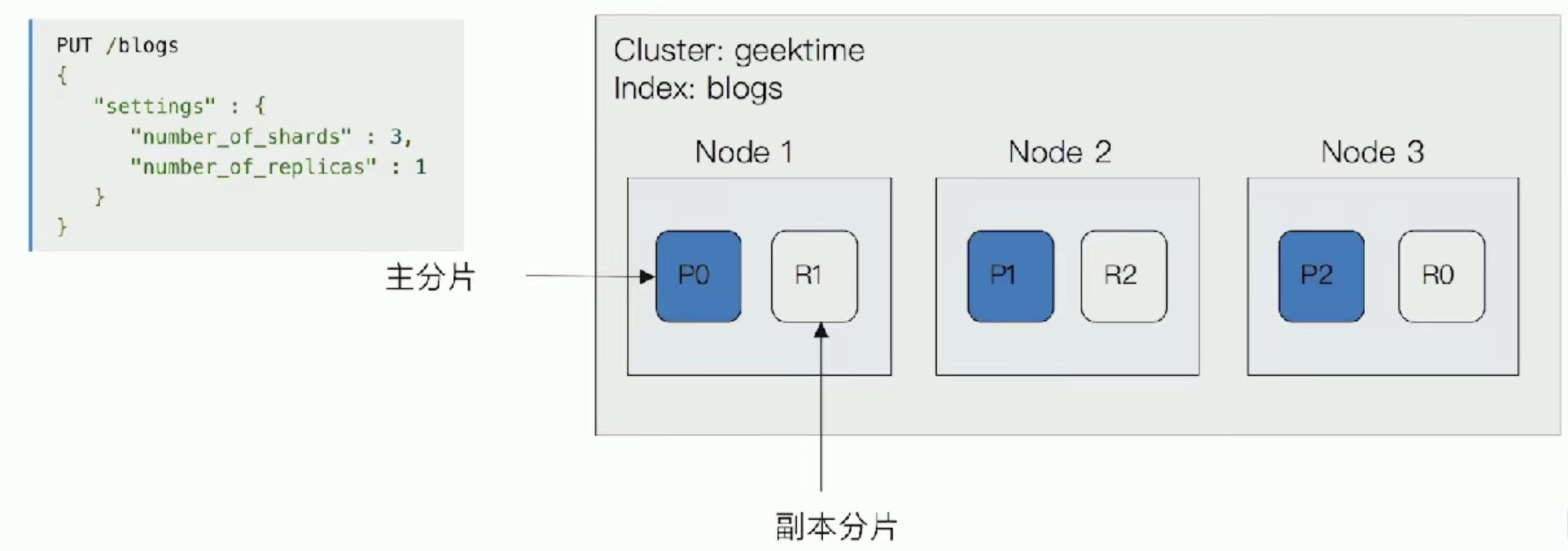
主分片(Primary Shard)
用来解决数据水平扩展的问题,通过主分片,可以将数据分布在集群内的所有节点之上
# 一个分片是一个运行的Lucene的实例
# 主分片数在索引创建时指定,后续不允许修改,除非Reindex
副本(Replica Shard)
用以解决数据高可用的问题,分片是主分片的拷贝
# 副本分片数,可以动态替调整
# 增加副本数,还可以一定程度上提升服务的高可用性(读取的吞吐)
一个三节点的集群中,blogs索引的分片分布情况
增加一个节点或改大主分片对系统的影响?
分片的设定
对于生产环境中分片的设定,需要提前走好容量规划
分片数设置过小
# 导致后续无法增加节点实现水平扩展
# 单个分片的数据量太大,导致数据重新分配耗时
分片数设置过大,7.0开始,默认主分片设置成1,解决了over-sharding的问题
# 影响搜索结果的相关性打分,影响统计结果的准确性.
# 单个节点上过多的分片,会导致资源浪费,同时也会影响性能.
查看集群健康状况
# Green - 主分片与副本都正常分配
# Yellow - 主分片全部正常分配,有副本分片未能正常分配
# Red - 有主分片未能分配
# 例如,当服务器磁盘容量超过85%时,去创建了一个新的索引,
文档(Document)
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
# 日志文件中的日志项
# 一本电影的具体信息 / 一张唱片的详细信息
# MP3播放器里的一首歌 / 一篇PDF文档的具体内容
文档会被序列化成JSON格式,保存在Elasticsearch中
# JSON对象由字段组成
# 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
每个文档都有一个Unique ID
# 你可以自己指定ID
# 或者通过Elasticsearch自动生成
JSON文档
一篇文档包含了一系列的字段,类似数据库表中的一条记录
JSON文档,格式灵活,不需要预先定义格式.
# 字段的类型可以指定或者通过Elasticsearch自动推算
# 支持数组 / 支持嵌套

文档的元数据

文档的CRUD操作
| index | PUT my_index/_doc/1 |
|---|---|
| Create | PUT my_index/_create/1{"user":"mike","comment":"You know ,for search"} POST my_index/__doc(不指定ID,自动生成) |
| Read | GET my_index/_doc/1 |
| Update | POST my_index/_update/1 {"doc":{"user":"mike","comment":"You know, Elasticsearch"}} |
| Delete | DELETE my_index/_doc/1 |
# Type名, 约定都用_doc
# Create - 如果ID已经存在,会失败
# index - 如果ID不存在,创建新的文档,否则,先删除现有的文档,再创建新的文档,版本会增加
# Update - 文档必须存在,更新只会对相应字段做增量修改.
Create创建一个文档
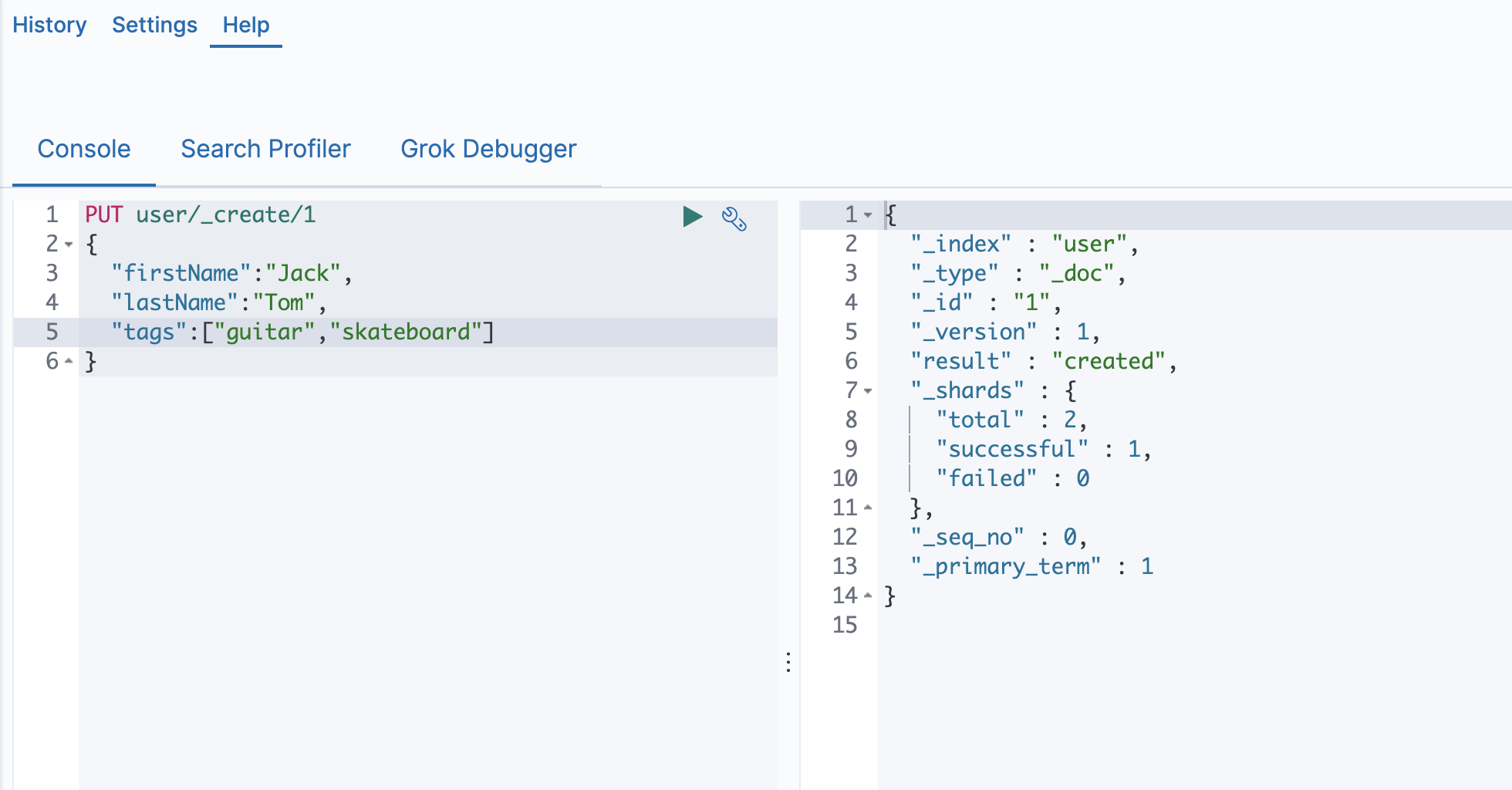
# 支持自动生成文档id和指定文档id两种方式
# 通过调用"post /users/_doc"
# 系统会自动生成 document Id
# 使用HTTP PUT user/_create/1创建时,URL中显示指定_create,此时如果该id文档已经存在,操作失败.
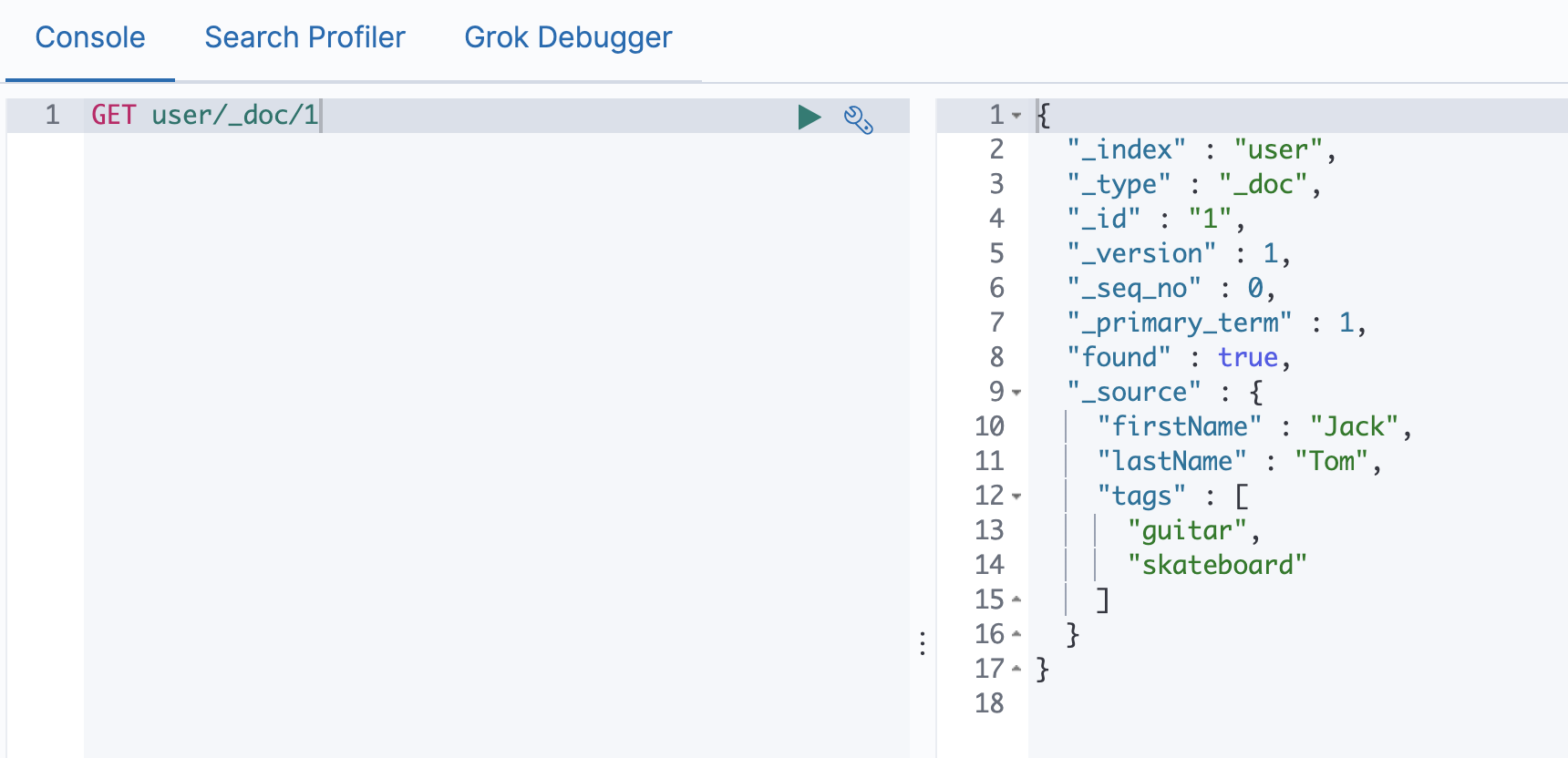
# 找到文档,返回HTTP 200
# 文档元信息
# _index/_type/
# 版本信息,同一个id的文档,即使被删除,Version号也会不断增加
# _souece中默认包含了文档的所有原始信息
# 找不到文档返回404
Update文档
# Update 方法不会删除原来的文档,而是实现真正的数据更新
# Post方法/Payload需要包含在"doc"中
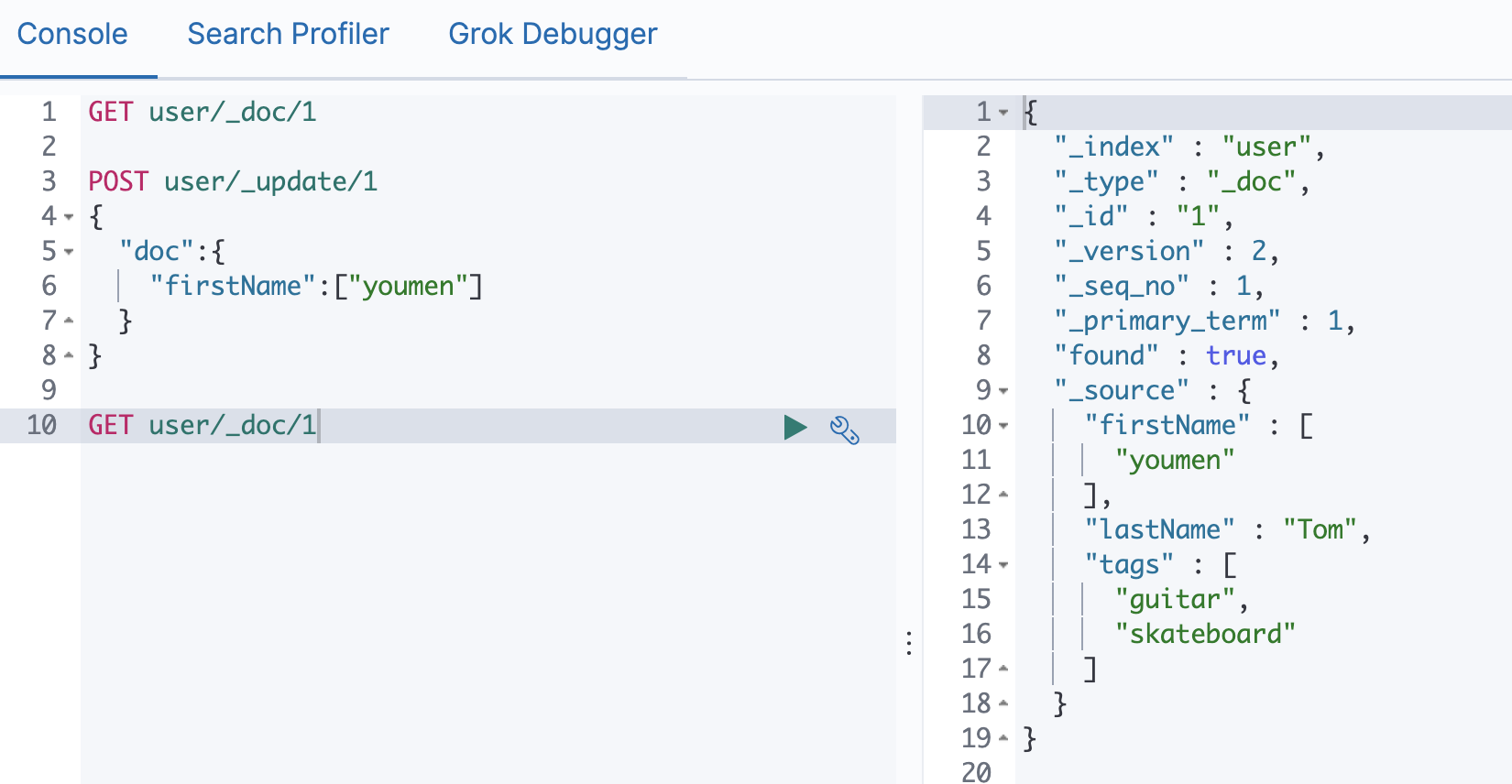
Index文档
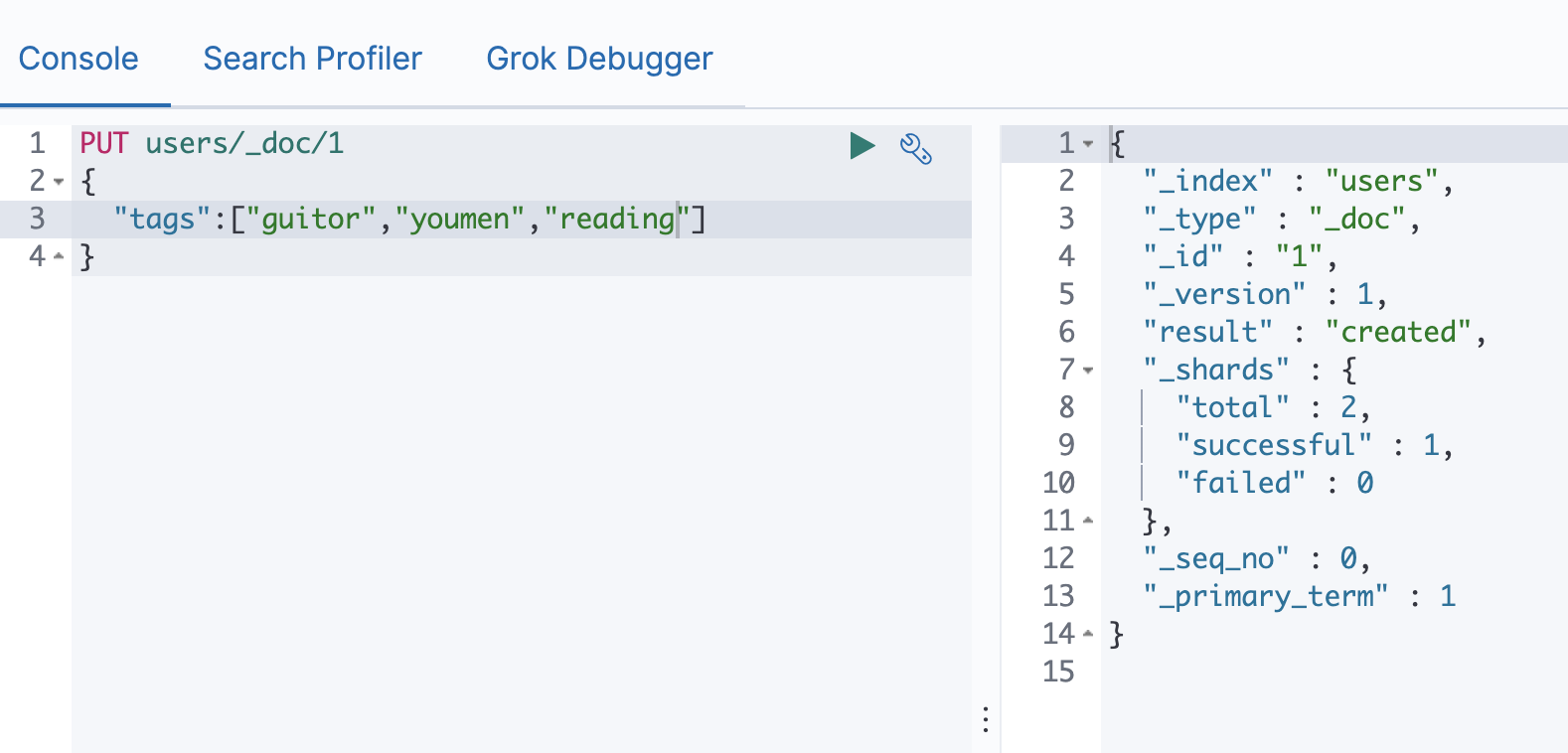
Index和Create不一样的地方: 如果文档不存在,就索引新的文档,否则现有文档会被删除,新的文档被索引,版本信息+1
Bulk API
# 支持在一次API调用中,对不同的索引进行操作
# 支持四种数据类型操作
# Index
# Create
# Update
# Delete
# 可以在URL中指定Index,也可以在请求的Payload中
# 操作中单条操作失败,并不会影响其他操作
# 返回结果包括了每一条操作执行的结果
批量操作
可以减少网络连接所产生的开销,提升性能
索引

# Index - 索引是文档的容器,是一类文档的结合
# Index体现了逻辑空间的概念: 每个索引都有自己的Mapping定义,用于定义包含文档的字段名和字段类型
# Shard体现了物理空间的概念: 索引中的数据分散在Shard上
# 索引的Mapping与Settings
# Mapping定义文档字段的类型
# Setting定义不同的数据分布
索引的不同语意
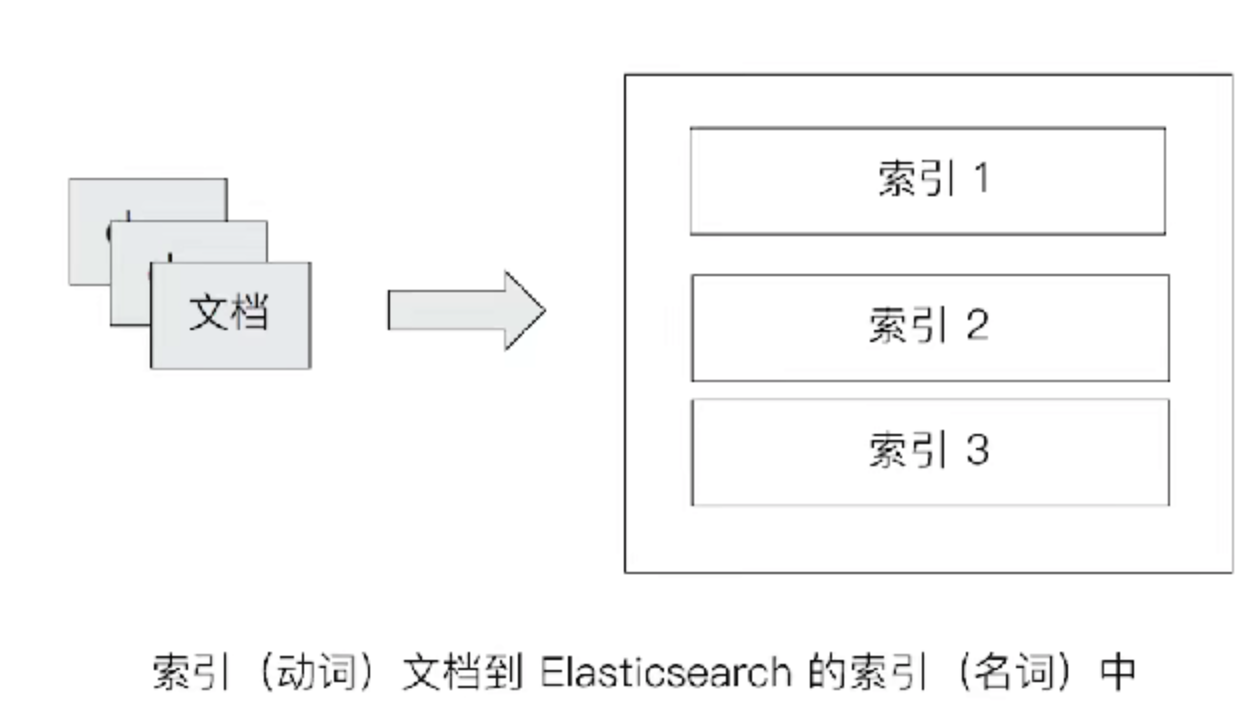
# 名词: 一个Elasticsearch集群中,可以创建很多个不同的索引
# 动词: 保存一个文档到Elasticsearch过程也叫索引(indexing)
# ES中, 创建一个倒排索引的过程
# 名词: 一个B树索引,一个倒排索引.
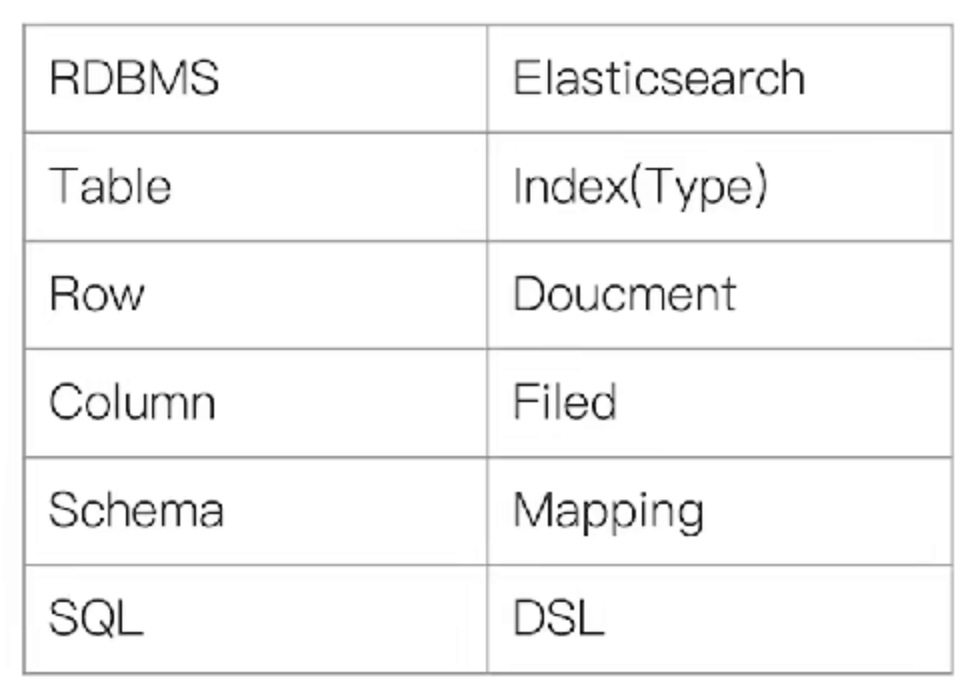
Type
# 在7.0之前,一个Index可以设置多个Types
# 6.0开始,Type已经被Deprecated,7.0开始,一个索引只能创建一个Type - "_doc"
# 传统关系型数据库和Elasticsearch的区别
# Elasticsearch - Schemaless / 相关性 / 高性能全文检索
# RDMS - 事务性 / Join
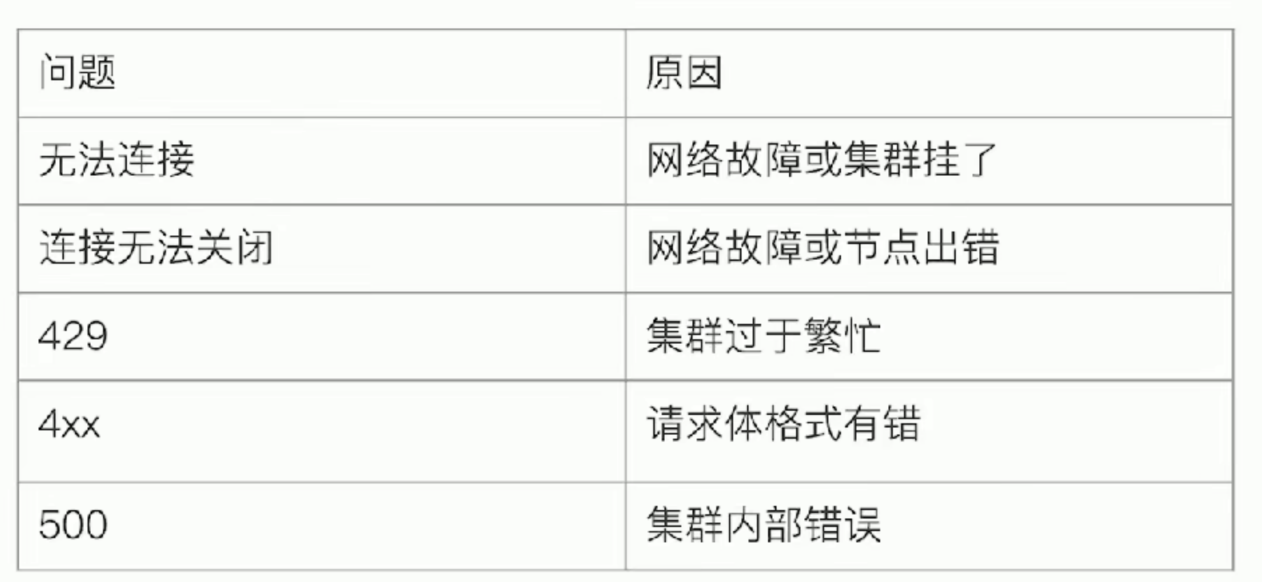
常见错误返回

 浙公网安备 33010602011771号
浙公网安备 33010602011771号