04 . Docker安全与Docker底层实现

Docker安全
Docker安全性时,主要考虑三个方面
# 1. 由内核的名字空间和控制组机制提供的容器内在安全
# 2. Docker程序(特别是服务端)本身的抗攻击性
# 3. 内核安全性的加强机制对容器安全性的影响
内核命名空间
Docker容器和LXC容器很相似,所提供的安全特性也差不多。当用docker run启动一个容器时,在后台Docker为容器创建了一个独立的命名空间和控制组集合。
命名空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发 现和作用。
每个容器都有自己独有的网络栈,意味着它们不能访问其他容器的sockets或接口。不过,如果主机系统上做了相应的设置,容器可以像跟主机交互一样的和其他容器交互。当指定公共端口或使用links来连接2个容器时,容器就可以相互通信了(可以根据配置来限制通信的策略).
从网络架构的角度来看,所有的容器通过本地主机的网桥接口相互通信,就像物理机器通过物理交换机通信一样。
那么,内核中实现命名空间和私有网络的代码是否足够成熟?
内核名字空间从2.6.15版本(2008年7月发布)之后被引入,数年间,这些机制的可靠性在诸多大型生产系统中被实践验证。
实际上,名字空间的想法和设计提出的时间要更早,最初是为了在内核中引入一种机制来实现 OpenVZ 的特性。而OpenVZ项目早在2005年就发布了,其设计和实现都已经十分成熟。
控制组
控制组是Linux容器机制的另外一个关键组件,负责实现资源的审计和限制.
它提供了很多有用的特性;以及确保各个容器可以公平地分享主机的内存、CPU、磁盘IO等资源;当然,更重要的是,控制组确保了当容器内的资源使用产生压力时不会连累主机系统。
尽管控制组不负责隔离容器之间相互访问、处理数据和进程,它在防止拒绝服务(DDOS)攻击方面是必不可少的。尤其是在多用户的平台(比如公有或私有的PaaS)上,控制组十分重要。例如,当某些应用程序表现异常的时候,可以保证一致地正常运行和性能。
控制组始于2006年,内核从2.6.24版本开始被引入.
Docker服务端的防护
运行一个容器或应用程序的核心是通过Docker服务端。Docker服务的运行目前需要root权限,因此其安全性十分关键。
首先,确保只有可信的用户才可以访问Docker服务。Docker允许用户在主机和容器间共享文件夹,同时不需要限制容器的访问权限,这就容易让容器突破资源限制。例如,恶意用户启动容器的时候将主机的根目录/映射到容器的 /host目录中,那么容器理论上就可以对主机的文件系统进行任意修改了。这听起来很疯狂?但是事实上几乎所有虚拟化系统都允许类似的资源共享,而没法禁止用户共享主机根文件系统到虚拟机系统
这将会造成很严重的安全后果。因此,当提供容器创建服务时(例如通过一个web服务器),要更加注意进行参数的安全检查,防止恶意的用户用特定参数来创建一些破坏性的容器
为了加强对服务端的保护,Docker的REST API(客户端用来跟服务端通信)在0.5.2之后使用本地的Unix套接字机制替代了原先绑定在 127.0.0.1 上的TCP套接字,因为后者容易遭受跨站脚本攻击。现在用户使用Unix权限检查来加强套接字的访问安全。
用户仍可以利用HTTP提供REST API访问。建议使用安全机制,确保只有可信的网络或VPN,或证书保 护机制(例如受保护的stunnel和ssl认证)下的访问可以进行。此外,还可以使用HTTPS和证书来加强 保护。
最近改进的Linux名字空间机制将可以实现使用非root用户来运行全功能的容器。这将从根本上解决了容器和主机之间共享文件系统而引起的安全问题。
终极目标是改进 2 个重要的安全特性:
- 将容器的root用户映射到本地主机上的非root用户,减轻容器和主机之间因权限提升而引起的安全问题;
- 允许Docker服务端在非root权限下运行,利用安全可靠的子进程来代理执行需要特权权限的操作。这些子进程将只允许在限定范围内进行操作,例如仅仅负责虚拟网络设定或文件系统管理、配置操作等。
- 最后,建议采用专用的服务器来运行Docker 和相关的管理服务(例如管理服务比如ssh监控和进程监控、管理工具nrpe、collectd等)。其它的业务服务都放到容器中去运行。
内核能力机制
能力机制(Capability)是Linux内核一个强大的特性,可以提供细粒度的权限访问控制。 Linux内核自2.2版本起就支持能力机制,它将权限划分为更加细粒度的操作能力,既可以作用在进程上,也可以作用在文件上。
例如,一个Web服务进程只需要绑定一个低于1024的端口的权限,并不需要root权限。那么它只需要被授权 net_bind_service能力即可。此外,还有很多其他的类似能力来避免进程获取root权限。
默认情况下,Docker启动的容器被严格限制只允许使用内核的一部分能力.
使用能力机制对加强Docker容器的安全有很多好处。通常,在服务器上会运行一堆需要特权权限的进程,包括有ssh、cron、syslogd、硬件管理工具模块(例如负载模块)、网络配置工具等等。容器跟这些进程是不同的,因为几乎所有的特权进程都由容器以外的支持系统来进行管理。
# 1. ssh访问被主机上ssh服务来管理;
# 2. cron通常应该作为用户进程执行执行,权限交给使用他服务的应用来处理;
# 3. 日志系统可由Docker或第三方服务管理;
# 4. 硬件管理无关紧要,容器中也就无需执行udevd以及类似服务;
# 5. 网络管理也都在主机上设置,除非特殊需求,容器不需要对网络进行配置.
从上面的例子可以看出,大部分情况下,容器并不需要真正的root权限,容器只需要少数的能力即可.为了加强安全,容器可以禁用一些没必要的权限:
# 1. 完全禁止任何mount操作.
# 2. 禁止直接访问本地主机的套接字.
# 3. 禁止访问一些文件系统的操作,比如创建新的设备,修改文件属性等.
# 4. 禁止模块加载.
这样,就算攻击者在容器中取得了root权限,也不能获得本地主机的较高权限,能进行的破坏也有限.
默认认情况下,Docker采用 白名单 机制,禁用必需功能之外的其它权限。 当然,用户也可以根据自身需求来为Docker容器启用额外的权限。
其他安全特性.
除了能力机制之外,还可以利用一些现有的安全机制来增强docker的安全性,例如TOMOYO,AppArmor,SELinux,GRSEC等.
Docker 当前默认只开启了能力机制,用户可以采用多种方案来加强Docker主机的安全,例如:
在内核中启用GRSEC和PAX,这将增加很多编译和运行时的安全检查,通过地址随机化避免恶意探测等,并且,启用该特性不需要Docker进行任何配置.
使用一些有增强安全特性的容器模板,比如带AppArmor的模板和Redhat带Selinux策略的模板.这些模板提供了额外的安全特性.
用户可以自定义访问控制机制来定制安全策略.
跟其他添加Docker容器的第三方工具一样(比如网络拓扑和文件系统共享),有很多类似的机制,在不改变Docker内核情况下就可以加固现有的容器.
小结
总体来说,Docker容器还是十分安全的,特别是在容器不使用root权限来运行进程的话.
另外,用户可以使用现有工具,比如Apparmor,SELinux,GRSEC来增强安全性,甚至自己在内核中实现更复杂的安全机制.
Docker底层实现
Docker底层的核心技术包括Linux上的命名空间(Namespaces)、控制组(ControlGroups),Union文件系统(Union file systems)和容器格式(Container format).
我们知道,传统的虚拟机通过在宿主主机中运行hypervisor来模拟一套完整的硬件环境提供给虚拟机的操作系统.虚拟机系统看到的环境是可限制的,也是彼此隔离的,这种直接的做法实现了对资源完整的封装,但很多时候往往意味着系统资源的浪费,例如,以宿主机和虚拟机系统都为linux系统为例,虚拟机中运行的应用其实是可以利用宿主机系统中的运行环境。
我们知道,在操作系统中,包括内核、文件系统、网络、PID、UID、IPC、内存、硬盘、CPU等等,所有的资源都是应用进程直接共享的,要想实现虚拟化,除了要实现对内存、CPU、网络IO、硬盘IO、存储空间等的限制外,还要实现文件系统、网络、PID、UID、IPC等等的相互隔离,前者相对容易实现一些,后者则需要宿主机系统的深入支持.
随着Linux系统对于命名空间功能的完善实现,程序员可以实现上面的所有需要,让某些进程在彼此隔离的命名空间中运行,大家虽然都共用一个内核和某些运行时环境(l例如一些系统命令和系统等),但是彼此却看不到,大家都以为系统中只有自己的存在,这种机制就是容器,利用命名空间来做权限的隔离控制,利用cgroups来做资源分配.
容器的基本架构
Dcoker采用了c/s架构,包括客户端和服务端,Docker守护进程(Daemon)作为服务端接受来自客户端的请求,并处理这些请求(创建、运行、分发容器).
客户端和服务端既可以运行在一个机器上,也可以通过socket或者RESTful API来进行通信.
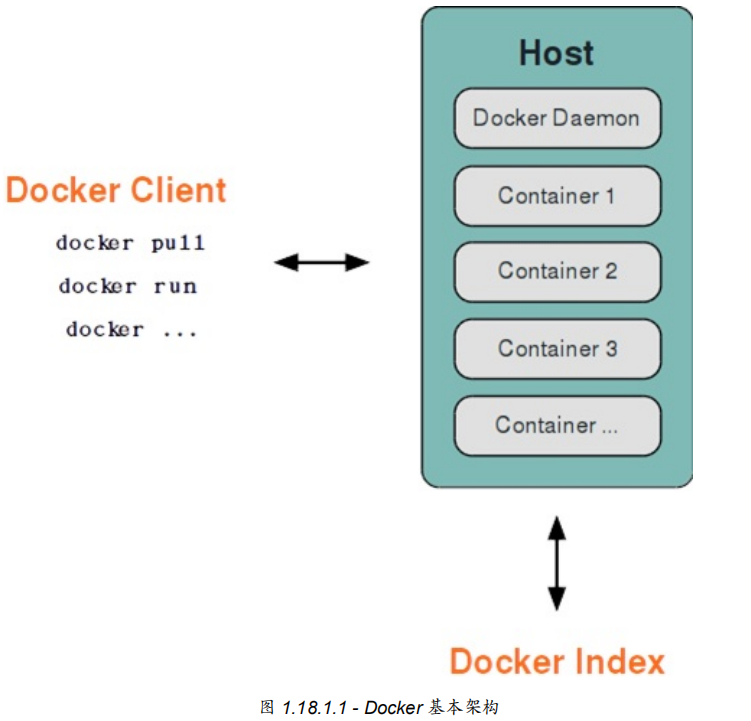
Docker守护进程一般在宿主主机后台运行,等待来自客户端的消息.
Docker客户端则为用户提供一系列可执行的命令,用户用这些命令实现跟Docker守护进程交互.
命名空间
命名空间是Linux内核一个强大的特性,每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统运行一样,命名空间保证了容器之间彼此互不影响.
pid命名空间
不同用户的进程就是通过pid命名空间隔离开的,且不同命名空间可以有相同的pid,所有的LXC进程在Docker中的父进程为Docker进程,每个LXC进程具有不同的命名空间,同时由于嵌套,因此可以很方便的实现嵌套的Docker容器.
net命名空间
有了pid命名空间,每个命名空间的pid能够实现相互隔离,但是网络端口还是共享host的端口,网络隔离是通过net命名空间实现的,每个net命名空间有单独的网络设备,IP地址,路由表,/proc/net目录,这样每个容器的网络就能隔离开来,Docker默认采用veth的方式,将容器中的虚拟网卡host上的一个Docker网桥docker0连接在一起.
IPC命名空间
容器中进程交互采用了Linux常见的进程交互方法,包括信号量,消息队列和共享内存等,然而同VM不同的是,容器的进程交互实际山还是host上具有相同pid命名空间的进程交互,因此需要在IPC资源中申请加入命名空间信息,每个IPC资源有一个唯一的32位id。
mnt命名空间
类似chroot,将一个进程放到一个特定的目录执行,mnt命名空间允许不同命名空间的进程看到的文件结构不同,这样每个命名空间中的进程所看到的文件目录就被隔离开了,同chroot不同,每个命名空间的容器在/proc/mounts的信息只包含所在命名空间的mount point。
uts命名空间
UTS命名空间允许每个容器拥有独立的hostname和domain name,使其在网络上可以被视作一个独立的节点而非主机上的一个进程.
每个容器可以有不同的用户和组id,也就是说可以在容器内用容器内部的用户执行程序而非主机上的用户.
控制组
控制组(cgroups)是一个Linux内核的一个特性,主要用来对资源进行隔离、限制、审计等,只有能控制分配到容器的资源,才能避免当多个容器同时运行时对系统资源的竞争.
控制组技术最早由Google的程序员在2006年提出,Linux内核从2.6.24开始支持.
控制组可以提供对容器的内存、CPU、磁盘IO等资源的限制和审计管理.
联合文件系统
联合文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,他支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统.
联合文件系统是Docker镜像的基础,镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像.
另外,不同Docker容器就可以共享一些基础的文件系统层,同时加上自己独有的改动层,大大提高了存储的效率.
Docker中使用的AUFS就是一种联合文件系统,AUFS支持为每一个成员目录(类似Git的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限,同时AUFS里有一个类似分层的概念,对只读权限的分支可以逻辑上进行增量的修改(不影响只读部分的).
Docker目前支持的联合文件系统包括OverlayFS,AUFS,BtrFS,VFS,ZFS和Device Mapper。
有可能的情况下,推荐使用overlay2存储驱动,overlay2是目前Docker默认的存储驱动,以前是aufs,可以通过配置以上提到的其他类型存储驱动.
容器格式
最初,Docker采用了LXC中的容器格式,从0.7版本开始以后去除LXC,转而使用自行开发的libcontainer,从1.11开始,进一步演进为runC和containerd。
网络实现
Docker的网络实现其实就是利用了Linux上的网络命名空间和虚拟网络设备(特别是vethpair).
基本原理
首先,要实现网络通信,机器需要至少一个网络接口(物理接口或虚拟接口)来收发数据包,此外,如果不同子网之间要进行通信,需要路由机制.
Docker中的网络接口默认都是虚拟的接口,虚拟接口的优势之一就是转发效率较高,Linux通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包直接复制到接收接口的接受缓存中,对于本地系统和容器内系统来看就像是一个正常的以太网卡,只是他不需要真正同外部网络设备通信,速度要快很多.
Docker容器网络就是利用了这项技术,他在本地主机和容器内分别创建一个虚拟接口,并让他们彼此连通(这样的一对接口叫做veth pair).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号