01 . 分布式存储之FastDFS简介及部署

分布式存储简介
现代的互联网已经进入大数据时代,每天都有数以万计的数据产生,这些数据的规模轻轻松松地可以达到几P的级别,传统的的单机存储早已捉襟见肘,根本无法满足大数据对存储系统的要求。这时,各种分布式系统才应运而生。
其实分布式的概念,早在很多年前,就有人提出和进行相关研究,但是由于当时的网络数据很少,分布式无用武之地,一直不温不火,一至到大数据时代的来临,才陆陆续续被人们应用到工程实践中。
概念
分布式存储系统,是将数据分散存储在多台独立的设备上。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
特性
可扩展
分布式存储系统可以扩展到几百台甚至几千台的集群规模,而且随着集群规模的增长,系统整体性能表现为线性增长。
低成本
分布式存储系统的自动容错、自动负载均衡机制使其可以构建在普通的PC机之上。另外,线性扩展能力也使得增加、减少机器非常方便,可以实现自动运维。
高性能
无论针对整个集群还是单台服务器,都要求分布式存储系统具备高性能
易用
分布式存储系统需要能够提供易用的对外接口,另外,也要求具备完善的监控、运维工具,并能够文玩与其他系统集成.
技术难点
分布式存储系统的挑战主要在于数据、状态信息的持久化,要求在自动迁移、自动容错、并发读写的过程中保证数据的一致性。分布式存储涉及的技术主要来自两个领域:分布式系统以及数据库。
数据分布
如何将数据分布到多台服务器才能保证数据分布均匀?数据分布到多台服务器后如何实现跨服务器读写操作?
分布式系统区别于传统单机系统在于能够将数据分布到多个节点,并在多个节点之间实现负载均衡。分布式存储系统的一个基本要求就是透明性,包括数据分布透明性, 数据迁移透明性,数据复制透明性还有数据故障透明性。
哈希分布
哈希分布的方法很常见,其方法是根据数据的某一特征计算哈希值,并将哈希值与集群中的服务器建立映射关系,从而将不同哈希值的数据分布到不同的服务器上。如果哈希函数的散列性很好,哈希方式可以将数据比较均匀地分布到集群中去,而且哈希方式需要记录的元信息也很简单,每个节点只需要知道哈希函数的计算方式以及模的服务器的个数就可以计算出处理的数据应该属于哪台机器。
传统的哈希分布算法有一个问题,当服务器上线或者下线时,N值发生变化,数据映射会被打乱。为解决这个问题,一个办法是不再简单地将哈希值和服务器个数做除法映射,而是将哈希值与服务器的对应关系作为元数据,交给专门的元数据服务器来管理。还有一个办法是采用一致性哈希算法。
一致性哈希(Distributed Hash Table,DHT)算法。算法思想:给系统中每个节点分配一个随机token,这些token构成一个哈希环。执行数据存放操作时,先计算Key的哈希值,然后存放到顺时针方向第一个大于或者等于该哈希值的token 所在的节点。一致性哈希值的优点在于加入或删除时只会影响到在哈希环中相除的节点,而对其它节点没影响。
哈希存储引擎是哈希表的持久化实现,支持增、删、改,以及随机读取操作,但不支持顺序扫描,对应的存储系统为键值(Key-Value)存储系统,如 Bitcask。它仅支持追加操作,删除也只是通过标识 value 为特殊值,通过定期合并(Compaction)实现垃圾回收。
顺序分布
哈希散列破坏了数据的有序性,只支持随机读取操作,不能支持顺序扫描。而且这种方式可能出现某些用户的数据量太大的问题,由于用户的数据限定在一个存储节点,无法发挥分布式存储系统的多机并行处理能力。
一致性
如果将数据的多个副本复制到多台服务器,即使在异常情况下,也能够保证不同副本之间的数据一致性。同一份数据的多个副本往往有一个副本为主副本,其他副本为备副本,由主副本将数据复制到备份副本。复制协议分为两种,强同步复制以及异步复制,二者的区别在于用户的读写请求是否需要同步到备副本才可以返回成功。假如备份副本不止一个,复制协议还会要求写请求至少需要同步到几个备副本。当主副本出现故障时,分布式存储系统能够将服务自动切换到某个备副本,实现自动容错。
一致性和可用性是矛盾的,强同步复制协议可以保证主备副本之间的一致性,但是当备副本出现故障时,也可能阻塞存储系统的正常写服务,系统的整体可用性受到影响;异步复制协议的可用性相对较好,但是一致性得不到保障,主副本出现故障时还有数据丢失的可能。
强复制与异步复制
分布式存储系统中数据保存多个副本,一般来说,其中一个副本为主副本,其他副本为备副本,常见的做法是数据写入到主副本,由主副本确定操作的顺序并复制到其他副本。
客户端将写请求发送给主副本,主副本将写请求复制到其他备副本,常见的做法是同步操作日志(Commit log)。主副本首先将操作日志同步到备副本上备副本回放操作日志,完成后通知主副本。接着主副本修改本机,等到所有的操作都完成后再通知客户端写成功。这里要求主备同步成功后才可以返回客户端写成功,这种协议称为强同步协议。强同步协议提供了强一致性,但是,如果备副本出现问题将阻塞写操作,系统可用性较差。
与强同步对应的复制方式是异步复制。在异步模式下,主副本不需要等待备副本的回应,只需要本地修改成功就可以告知客户端写操作成功。另外,主副本通过异步机制,比如单独的复制线程将客户端修改操作推送到其他副本。异步复制的好处在于系统可用性好,但是一致性差,如果主副本发生不可恢复故障,可能丢失最后一部分更新操作。
强同步复制和异步复制都是将主副本的数据以某种形式发送到其他副本,这种复制协议称为基于主副本的复制协议。这种方法要求在任何时刻只能有一个副本为主副本,由它来确定写操作之间的顺序。如果主副本出现故障,需要选举一个备副本成为新的主副本,这步操作称为选举,如Paxos协议。除此外还有基于多个存储节点的复制协议(比较少见)。
操作日志的原理很简单:为了利用好磁盘的顺序读写特性,将客户端的写操作先顺序写入到磁盘中,然后应用到内存中,由于内存是随机读写设备,可以很容易通过各种数据结构,比如B+树将数据有效地组织起来.当服务器宕机重启时,只需要积攒一定的操作日志再批量写入到磁盘中,这种技术一般称为成组提交。
CAP原理
CAP即一致性(Consistency)、可用性(Availablility)以及分区可容忍性(Tolerance of network Partition)三者不能同时满足。
一致性:读操作总是能读取到之前完成的写操作结果,满足这个条件的系统称为强一致性系统,这里的“之前”一般对同一个客户端而言。
可用性:读写操作在单台机器发生故障的情况下仍然能够正执行,而不需要等待发生故障重启或者其上的服务迁移到其他机器。
分区可容忍性:机器故障、网络故障、机房停电等异常情况下仍然能够满足一致性和可用性。
分布式存储系统要求能够自动容错,分区容忍性总是要满足的,因此,一致性和写操作的可用性不能同时满足。存储系统设计时需要在一致性和可用性之间权衡,在某些场景下,不允许丢失数据,在另外一些场景下,极小概率丢失部分数据是允许的,可用性更加重要。
容错
如何检测到服务器故障?如何自动将出现故障的服务器上的数据和服务器迁移到集群中的其它服务器?
随着集群规模变得越来越大,故障发生的概率也越来越大,大规模集群每天都有故障发生。容错是分布式存储系统设计的重要目标,只在实现了自动化容错,才能减少人工成本,实现分布式存储的规模效应。
故障检测
单台服务器故障的概率是不高的,然而,只要集群的规模足够大, 每天都有机器故障发生,系统需要能够自动处理。首先,分布式存储系统需要能够检测到机器故障,在分布式系统中,故障检测往往通过租约(Lease)协议实现。接着,需要能够将服务器复制或者迁移到集群中的其他正常服务的存储节点。
租约机制就是带有超时间的一种授权。假设机器A需要检测机器B 是否发生故障,机器A 可以给机器B 发放租约, 机器B 持有的租约在有效期内才允许提供服务,否则主动停止服务。机器B 的租约快要到期时向机器A 重新申请租约。正常情况下,机器B 通过不断申请租约来延长有效期,当机器B 出现故障或者与机器A 之初蝗网络发生故障时,机器B 租约将过期,从而机器A 能够确保机器B 不再提供服务,机器B 的服务可以被安全地迁移到其他服务器。
故障恢复
单层结构和双层结构的故障恢复机制有所不同。
单层结构。单层结构的分布式存储系统维护了多个副本,主备副本之间通过操作日志同步。节点下线分为两种情况:一种是临时故障,节点过一段时间将重新上线;另一种情况是永久性故障,比如硬盘损坏。
双层结构。双层结构的分布式存储系统会将所有的数据持久化写入底层的分布式文件系统,每个数据片同一时刻只有一个提供服务的节点。

节点故障会影响系统服务,在故障检测以及故障恢复的过程中,不能提供写服务以及强一致性读服务。停服务时间包含两个部分,故障检测时间故障恢复时间。故障检测时间一般在几秒到十几秒, 这和集群规模密切相关,集群规模越大,故障检测对总控节点造成的压力就越大,故障检测时间就越长。故障恢复时间一般很短,单层结构的备副和主副本之间保持实时同步,切换为主副本的时间很短;双层结构故障恢复往往实现成只需要将数据的索引,而不是所有的数据加载到内存中。
总控节点自身也可能出现故障,为了实现总控节点的高可用性,总控节点的状态也将实时同步到备机,当故障发生时, 可以通过外部服务选举某个备机作为新的总控节点,而这个外部服务也必须是高可用的。为了进行选主或者维护系统中重要的全局信息,可以维护一套通过Paxos 协议实现的分布式锁服务, 如Zookeeper。
负载均衡
新增服务器和集群正常运行过程中如何实现自动负载均衡?数据迁移过程中如何保证不影响已有服务?
分布式存储系统的每个集群中一般有一个总控节点,其他节点为工作节点,由总控节点根据全局负载信息进行整体调度。工作节点刚上线时,总控节点需要将数据迁移到该节点上,另外,系统运行过程中也需要不断地执行迁移任务,将数据从负载较高的工作节点迁移到负载较低的工作节点。
工作节点通过心跳包,将节点负载相关的信息,如CPU、内存、磁盘及网络等资源使用率,读写次数及读写数据量等发给主控节点。主控节点计算出工作节点的负载信息以及需要迁移的数据,生成迁移任务放入迁移队列中等待执行。
负载均衡需要执行数据迁移操作。在分布式存储系统中往往会存储数据的多个副本,一个为主副本,其他为备副本,由主副本对外提供服务。迁移备副本不会对服务造成影响,迁移主副本也可以首先将数据的读写服务切换到其他备副本。整个迁移过程可以做到无缝,对用户完全透明。
分布式协议
分布式系统涉及的协议很多,例如租约、复制协议、一致性协议等等,其中以两阶段提交协议和Paxos 协议最具有代表性。两阶段提交协议用于保证跨多个节点操作的原子性,即跨多个节点的操作要么在所有节点上全部执行成功,要么全部失败。Paxos 协议用于确保多个节点对某个投票(如选取某个节点为主节点)达成一致。
两阶段提交协议
两阶段提交协议(Two-phase Commit,2PC)经常用来实现分布式事务,在两阶段协议中,系统一般包含两类节点:一类为协调者(coordinator),通常一个系统中只有一个;另一类为事务参与者(participants,cohorts或者workers),一般包含多个。协议中假设每个节点都会记录操作日志并持久化到非易失性存储介质,即使节点发生故障日志也不会丢失。执行过程如下:
-
第一阶段,准备阶段。协调者通知事务参与者准备提交或者取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策,同意(事务参与者本地执行成功)或者取消(事务参与者本地执行失败)。可以进一步将准备阶段分为以下三个步骤:
- 协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
- 参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
- 各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
-
第二阶段,提交阶段。协调者将基于第一个阶段的投票结果进行决策,提交或者取消。当且仅当所有的参与者同意提交事务协调者才通知所有的参与者提交事务,否则协调者通知所有的参与者取消事务。参与者在接收到协调者发来的的消息后将执行相应的操作。
提交:
- 调者节点向所有参与者节点发出”正式提交(commit)”的请求。
- 参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
- 参与者节点向协调者节点发送”完成”消息。
- 协调者节点受到所有参与者节点反馈的”完成”消息后,完成事务。
取消:
- 协调者节点向所有参与者节点发出”回滚操作(rollback)”的请求。
- 参与者节点利用之前写入的Undo信息执行回滚,并释放在整个事务期间内占用的资源。
- 参与者节点向协调者节点发送”回滚完成”消息。
- 协调者节点受到所有参与者节点反馈的”回滚完成”消息后,取消事务。
二阶段提交看起来确实能够提供原子性的操作,但是不幸的事,二阶段提交还是有几个缺点的:
- 同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
- 单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
- 数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
- 二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交(三阶段提交也是不完美的,这里不再赘述)。
Paxos协议
Paxos 协议用于解决多个节点之间的一致性问题。多个节点之间通过操作日志同步数据,如果只有一个节点为主节点,那么,很容易确保多个节点之间操作日志的一致性。只要保证了多个节点之间操作日志的一致性,就能够在这些节点上构建高可用的全局服务,如分布式锁服务,全局命名和配置服务等。
为了实现高可用性,主节点往往将数据以操作日志的形式同步到备节点。如果主节点发生故障,备节点会提议自己成为主节点。Paxos 协议保证,即使同时存在多个proposer,也能保证所有节点最终达到一致,选举出唯一的主节点。下面引用网上一篇博客的内容来讲述Paxos协议。
在paxos算法中,分为4种角色:Proposer(提议者)、Acceptor(决策者)、Client(产生议题者)和Learner(最终决策学习者)。其中提议者和决策者是很重要的,其他的2个角色在整个算法中应该算做打酱油的,Proposer就像Client的使者,由Proposer使者拿着Client的议题去向Acceptor提议,让Acceptor来决策。这里上面出现了个新名词:最终决策。现在来系统的介绍一下paxos算法中所有的行为:
- Proposer提出议题
- Acceptor初步接受 或者 Acceptor初步不接受
- 如果上一步Acceptor初步接受则Proposer再次向Acceptor确认是否最终接受
- Acceptor 最终接受 或者Acceptor 最终不接受
上面Learner最终学习的目标是Acceptor们最终接受了什么议题?注意,这里是向所有Acceptor学习,如果有多数派个Acceptor最终接受了某提议,那就得到了最终的结果,算法的目的就达到了。过程如下图:

现在通过一则故事来学习paxos的算法的流程(2阶段提交),有2个Client(老板,老板之间是竞争关系)和3个Acceptor(政府官员)。
第一阶段:
- 现在需要对一项议题来进行paxos过程,议题是“A项目我要中标!”,这里的“我”指每个带着他的秘书Proposer的Client老板。
- Proposer当然听老板的话了,赶紧带着议题和现金去找Acceptor政府官员。
- 作为政府官员,当然想谁给的钱多就把项目给谁。
- Proposer-1小姐带着现金同时找到了Acceptor-1~Acceptor-3官员,1与2号官员分别收取了10比特币,找到第3号官员时,没想到遭到了3号官员的鄙视,3号官员告诉她,Proposer-2给了11比特币。不过没关系,Proposer-1已经得到了1,2两个官员的认可,形成了多数派(如果没有形成多数派,Proposer-1会去银行提款在来找官员们给每人20比特币,这个过程一直重复每次+10比特币,直到多数派的形成),满意的找老板复命去了,但是此时Proposer-2保镖找到了1,2号官员,分别给了他们11比特币,1,2号官员的态度立刻转变,都说Proposer-2的老板懂事,这下子Proposer-2放心了,搞定了3个官员,找老板复命去了,当然这个过程是第一阶段提交,只是官员们初步接受贿赂而已。故事中的比特币是编号,议题是value(这个过程保证了在某一时刻,某一个proposer的议题会形成一个多数派进行初步支持)。
现在进入第二阶段提交:
- 现在proposer-1小姐使用分身术(多线程并发)分了3个自己分别去找3位官员,最先找到了1号官员签合同,遭到了1号官员的鄙视,1号官员告诉他proposer-2先生给了他11比特币,因为上一条规则的性质proposer-1小姐知道proposer-2第一阶段在她之后又形成了多数派(至少有2位官员的赃款被更新了);此时她赶紧去提款准备重新贿赂这3个官员(重新进入第一阶段),每人20比特币。刚给1号官员20比特币, 1号官员很高兴初步接受了议题,还没来得及见到2,3号官员的时候。
- 这时proposer-2先生也使用分身术分别找3位官员(注意这里是proposer-2的第二阶段),被第1号官员拒绝了告诉他收到了20比特币,第2,3号官员顺利签了合同,这时2,3号官员记录client-2老板用了11比特币中标,因为形成了多数派,所以最终接受了Client2老板中标这个议题,对于proposer-2先生已经出色的完成了工作;
- 这时proposer-1小姐找到了2号官员,官员告诉她合同已经签了,将合同给她看,proposer-1小姐是一个没有什么职业操守的聪明人,觉得跟Client1老板混没什么前途,所以将自己的议题修改为“Client2老板中标”,并且给了2号官员20比特币,这样形成了一个多数派。顺利的再次进入第二阶段。由于此时没有人竞争了,顺利的找3位官员签合同,3位官员看到议题与上次一次的合同是一致的,所以最终接受了,形成了多数派,proposer-1小姐跳槽到Client2老板的公司去了。
Paxos过程结束了,这样,一致性得到了保证,算法运行到最后所有的proposer都投“client2中标”所有的acceptor都接受这个议题,也就是说在最初的第二阶段,议题是先入为主的,谁先占了先机,后面的proposer在第一阶段就会学习到这个议题而修改自己本身的议题,因为这样没职业操守,才能让一致性得到保证,这就是paxos算法的一个过程。原来paxos算法里的角色都是这样的不靠谱,不过没关系,结果靠谱就可以了。该算法就是为了追求结果的一致性
易用
如何设计对外接口使得系统容易使用?如何设计监控系统并将系统的内部状态以方便的形式暴露给运维人员?
压缩与解压缩
如何根据数据的特点设计合理的压缩与解压缩算法?如何平衡压缩算法节省的存储空间和消耗的CPU计算资源。
分布式系统分类
分布式存储系统需要存储的数据多种多样,大致上可分为:非结构化数据,如文本文件、图片、视频和音频等格式;结构化数据,一般存在关系数据库中,可以用二维关系表结构来表示,模式与内容是分开的;半结构化数据,如HTML文档,模式结构与内容是放在一起的。
不同的分布式存储系统适合存储不同的数据
分布式文件系统
互联网应用需要存储大量的图片、照片和视频等非结构化数据对象,这类数据以对象的形式组织,对象之间没有关联,这样的数据一般称为Blob(Binary large object)数据。
分布式文件系统适用于存储 Blob 对象,典型的如谷歌的GFS以及它的开源实现HDFS。在系统实现层面,分布式文件系统内部按照数据块(chunk)来组织数据,每个数据块的大小相同,每个数据块可以包含我个Blob 对象或者定长块,一个大文件也可以拆分成多个数据块。
典型的系统有 Facebook Haystack 以及 Taobao File System(TFS)。分布式文件系统是分布式的基石,通常作为上层系统的底层存储。
总体上看,分布式文件系统存储三种类型的数据 :Blob 对象、定长块以及大文件。在系统实现层面,分布式文件系统内部按照数据块(chunk)来组织数据,每个 chunk 的大小大致相同,每个 chunk 可以包含多个 Blob 对象或者定长块,一个大文件也可以拆分为多个 chunk 。
分布式键值系统
分布式键值系统用于存储关系简单的半结构化数据,它只提供基于主键的 CRUD(Create/Read/Update/Delete)功能。
如Dynamo、Redis和Memcache。从数据结构来看,分布式键值系统与传统的哈希表比较类似,不同的是,分布式系统支持将数据分布到集群中的多个存储结点。分布式键值系统是分布式表格系统的一种简化实现,一般用作缓存。一致性哈希是分布式键值系统中常用的数据分布技术。
典型的系统有 Amazon Dynamo 以及 Taobao Tair。从数据结构的角度看,分布式键值系统与传统的哈希表比较类似,不同的是,分布式键值系统支持将数据分布到集群中的多个存储节点。分布式键值系统是分布式表格系统的一种简化实现,一般用作缓存,比如淘宝 Tair 以及 Memcache。一致性哈希是分布式键值系统中常用的数据分布技术。
分布式表格系统
分布式表格系统用于存储关系较为复杂的半结构化数据,与分布式键值系统相比,分布式表格系统不仅仅支持简单的CRUD 操作,而且支持扫描某个主键范围。分布式表格系统以表格为单位组织数据,每个表格包括很多行,通过主键标识一行,支持根据主键的CRUD功能以及范围查找功能。
分布式表格系统借鉴了很多关系数据库的技术,例如支持某种程度上的事务。典型的系统如Bigtable、HBase和DynamoDB。与分布式数据库相比,分布式表格系统主要针对单张表格的操作,不支持一些特别复杂的操作,比如多表关联、多表连接、嵌套子查询。而且在分布式表格系统中,同一个表格的多个数据行也不要求包含相同类型的列,适合半结构化数据。分布式表格系统是一种很好的权衡,这类系统可以做到超大规模,而且支持较多的功能,但实现往往比较复杂。
分布式表格系统用于存储关系较为复杂的半结构化数据。分布式表格系统以表格为单位组织数据,每个表格包括很多行,通过主键标识一行,支持根据主键的 CRUD 功能以及范围查找功能。
典型的系统包括 Google Bigtable 以及 Megastore,Microsoft Azure Table Storage,Amazon DynamoDB 等。在分布式表格系统中,同一个表格的多个数据行也不要求包含相同类型的列,适合半结构化数据。
分布式数据库
分布式数据库一般是从单机关系数据库扩展而来,用于存储结构化数据。分布式数据库采用二维表格组织数据,提供 SQL 关系查询语言,支持多表关联,嵌套子查询等复杂操作,并提供数据库事务以及并发控制。
典型的系统包括 MySQL 数据库分片(MySQL Sharding)集群,Amazon RDS 以及Microsoft SQL Azure。分布式数据库支持的功能最为丰富,符合用户使用习惯,但可扩展性往往受到限制。当然,这一点并不是绝对的。Google Spanner 的扩展性就达到了全球级,它不仅支持丰富的关系数据库功能,还能扩展到多个数据中心的成千上万台机器。除此之外,阿里巴巴 OceanBase 也是一个支持自动扩展的分布式关系数据库。
FastDFS简介
FastDFS 是一个 C 语言实现的开源轻量级分布式文件系统,作者余庆(happyfish100),支持 Linux、 FreeBSD、 AID 等 Unix 系统,解决了大数据存储和读写负载均衡等问题,适合存储 4KB~500MB 之间的小文件,如图片网站、短视频网站、文档、app 下载站等,UC、京东、支付宝、迅雷、酷狗 等都有使用,其中 UC 基于 FastDFS 向用户提供网盘、广告和应用下载的业务的存储服务, FastDFS 与 MogileFS、HDFS、TFS 等都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务.
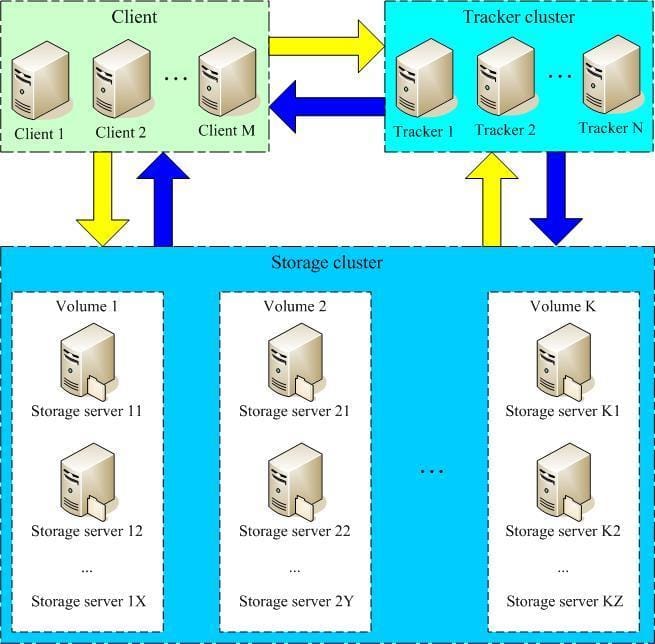
FastDFS原理架构
FastDFS 服务有三个角色
# 跟踪服务器(tracker server)
# 存储服务器(storage server)
# 客户端(client)
tracker server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server 和 group,每个 storage 在启动后会连接 Tracker, 告知自己所属 group 等信息,并保持周期性心跳,Tracker根据 storage 心跳信息,建立 group--->[storage server list]的映射表;tracker 管理 的元数据很少,会直接存放在内存;tracker 上的元信息都是由 storage 汇报的信息生成的,本身 不需要持久化任何数据,tracker 之间是对等关系,因此扩展 tracker 服务非常容易,之间增加tracker服务器即可,所有 tracker 都接受 stroage 心跳信息,生成元数据信息来提供读写服务(与 其他 Master-Slave 架构的优势是没有单点,tracker 也不会成为瓶颈,最终数据是和一个可用的 Storage Server 进行传输的)
storage server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以包 含多台 storage server,数据互为备份,存储容量空间以 group 内容量最小的 storage 为准;建 议 group 内的 storage server 配置相同;以 group 为单位组织存储能够方便的进行应用隔离、负 载均衡和副本数定制;缺点是 group 的容量受单机存储容量的限制,同时 group 内机器坏掉,数据 恢复只能依赖 group 内其他机器重新同步(坏盘替换,重新挂载重启 fdfs_storaged 即可)多个 group 之间的存储方式有 3 种策略:round robin(轮询)、load balance(选择最大剩余空 间的组上传文件)、specify group(指定 group 上传)
group
中 storage 存储依赖本地文件系统,storage可配置多个数据存储目录, 磁盘不做 raid, 直接分别挂载到多个目录,将这些目录配置为 storage 的数据目录即可storage`接受写请求时,会根据配置好的规则,选择其中一个存储目录来存储文件;为避免单 个目录下的文件过多,storage 第一次启时,会在每个数据存储目录里创建 2 级子目录,每级 256 个,总共 65536 个,新写的文件会以 hash 的方式被路由到其中某个子目录下,然后将文件数据直 接作为一个本地文件存储到该目录中
总结:1.高可靠性:无单点故障 2.高吞吐性:只要 Group 足够多,数据流量是足够分散的

FastDFS 提供基本的文件访问接口,如 upload、download、append、delete 等
选择 tracker server
集群中 tracker 之间是对等关系,客户端在上传文件时可用任意选择一个 tracker
选择存储 group
当 tracker 接收到 upload file 的请求时,会为该文件分配一个可以存储文件的 group,目前 支持选择 group 的规则为:
# Round robin,所有 group 轮询使用
# Specified group,指定某个确定的 group
# Load balance,剩余存储空间较多的 group 优先
选择 storage server
当选定 group 后,tracker 会在 group 内选择一个 storage server 给客户端,目前支持选择 server 的规则为:
# Round robin,所有 server 轮询使用(默认)
# 根据 IP 地址进行排序选择第一个服务器(IP 地址最小者)
# 根据优先级进行排序(上传优先级由 storage server 来设置,参数为 upload_priority)
选择 storage path(磁盘或者挂载点)
当分配好 storage server 后,客户端将向 storage 发送写文件请求,storage 会将文件分配一 个数据存储目录,目前支持选择存储路径的规则为:
# round robin,轮询(默认)
# load balance,选择使用剩余空间最大的存储路径
选择下载服务器
目前支持的规则为:
# 轮询方式,可以下载当前文件的任一 storage server
# 从源 storage server 下载
生成 file_id
选择存储目录后,storage 会生成一个 file_id,采用 Base64 编码,包含字段包括:storage server ip、文件创建时间、文件大小、文件 CRC32 校验码和随机数;每个存储目录下有两个 256*256 个子目录,storage 会按文件 file_id 进行两次 hash,路由到其中一个子目录,,然后将文件已 file_id 为文件名存储到该子目录下,最后生成文件路径:group 名称、虚拟磁盘路径、数据两级 目录、file_id

其中,组名:文件上传后所在的存储组的名称,在文件上传成功后由存储服务器返回,需要客户端 自行保存
虚拟磁盘路径:
存储服务器配置的虚拟路径,与磁盘选项store_path参数对应
数据两级目录
存储服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件
同步机制
新增 tracker 服务器数据同步问题
由于 storage server 上配置了所有的 tracker server,storage server 和 tracker server 之间的通信是由 storage server 主动发起的,storage server 为每个 tracker server 启动一个线程进行通信;在通信过程中,若发现该 tracker server 返回的本组 storage server 列表比本机记录少,就会将该 tracker server 上没有的 storage server 同步给该 tracker,这样的机制使得 tracker 之间是对等关系,数据保持一致
新增 storage 服务器数据同步问题
若新增 storage server 或者其状态发生变化,tracker server 都会将 storage server 列表同步给该组内所有 storage server;以新增 storage server 为例,因为新加入的 storage server 会主动连接 tracker server,tracker server 发现有新的 storage server 加入,就会将该组内所有的 storage server 返回给新加入的 storage server,并重新将 该组的 storage server 列表返回给该组内的其他 storage server;
组内 storage 数据同步问题
组内 storage server 之间是对等的, 文件上传、 删除等操作可以在组内任意一台 storage server 上进行。文件同步只能在同组内的 storage server 之间进行,采用 push 方式, 即源服务器同步到目标服务器
# 只在同组内的 storage server 之间进行同步
# 源数据才需要同步,备份数据不再同步
# 特例:新增 storage server 时,由其中一台将已有所有数据(包括源数据和备份数据)同步到新增服务器
storage server 的 7 种状态: 通过命令 fdfs_monitor /etc/fdfs/client.conf 可以查看 ip_addr 选项显示 storage
server当前状态INIT: 初始化,尚未得到同步已有数据的源服务器WAIT_SYNC:等待同步,已得到同步已有数据的源服务器SYNCING: 同步中DELETED: 已删除,该服务器从本组中摘除OFFLINE: 离线ONLINE: 在线,尚不能提供服务ACTIVE: 在线,可以提供服务
组内增加 storage serverA 状态变化过程
storage server A主动连接 tracker server,此时 tracker server 将 storage serverA 状态设置为 INIT
storage server A向 tracker server 询问追加同步的源服务器和追加同步截止时间点(当前时间),若组内只有 storage server A 或者上传文件数为 0,则告诉新机器不需要数据同步,storage server A 状态设置为 ONLINE ;若组内没有 active状态机器,就返回错误给新机器,新机器睡眠尝试;否则 tracker 将其状态设置为WAIT_SYNC假如分配了 storage server B 为同步源服务器和截至时间点,那么 storage server B 会将截至时间点之前的所有数据同步给 storage server A,并请求 tracker 设置 storage server A 状态为 SYNCING;到了截至时间点后, storage server B 向 storage server A 的同步将由追加同步切换为正常 binlog 增量同步,当取不到更多的 binlog 时,请求 tracker 将 storage server A 设置为 OFFLINE 状态,此时源同步完成
storage server B向 storage server A 同步完所有数据,暂时没有数据要同步时,storage server B 请求 tracker server 将 storage server A 的状态设置为 ONLINE当 storage server A 向 tracker server 发起心跳时,tracker sercer 将其状态更改为 ACTIVE,之后就是增量同步(binlog)

注释
# 整个源同步过程是源机器启动一个同步线程,将数据 push 到新机器,最大达到一个磁盘的 IO,不能并发
# 由于源同步截止条件是取不到 binlog,系统繁忙,不断有新数据写入的情况,将会导致一直无法完成源同步过程
上传过程

1、Storage Server会定期的向Tracker Server发送自己的存储信息。
2、当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,因此客户端上传时可以选择任意一个Tracker。
3、当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。
4、当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。
5、然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。
下载过程

1、在下载文件时,客户端可以选择任意tracker server。
2、tracker发送下载请求给某个tracker,并携带着文件名信息。
3、tracker从文件名中解析出文件所存储的group、文件大小、创建时间等信息,然后为该请求选择一个storage用来服务下载的请求。
client 发送下载请求给某个 tracker,必须带上文件名信息,tracker 从文件名中解析出文件的 group、大小、创建时间等信息,然后为该请求选择一个 storage 用于读请求;由于 group 内的文 件同步在后台是异步进行的,可能出现文件没有同步到其他 storage server 上或者延迟的问题, 后面我们在使用 nginx_fastdfs_module 模块可以很好解决这一问题

文件合并原理
小文件合并存储主要解决的问题:
# 本地文件系统 inode 数量有限,存储小文件的数量受到限制
# 多级目录+目录里很多文件,导致访问文件的开销很大(可能导致很多次 IO)
# 按小文件存储,备份和恢复效率低
海量小文件存储问题请参考:
FastDFS提供合并存储功能,默认创建的大文件为 64MB,然后在该大文件中存储很多小文件; 大文件中容纳一个小文件的空间称作一个 Slot,规定 Slot 最小值为 256 字节,最大为 16MB,即小于 256 字节的文件也要占用 256 字节,超过 16MB 的文件独立存储;为了支持文件合并机制, FastDFS 生成的文件 file_id 需要额外增加 16 个字节; 每个 trunk file 由一个 id 唯一标识,trunk file 由 group 内的 trunk server 负责创建(trunk server 是 tracker 选出来的),并同步到 group 内其他的 storage,文件存储合并存储到 trunk file 后,根据其文件 偏移量就能从 trunk file 中读取文件
FastDFS 单节点部署(6.06)
环境
[Fastdfs-Server]
主机名 = fastdfs-1
系统 = CentOS7.6.1810
地址 = 121.36.43.223
软件 = libfastcommon-master
nginx-1.14.0.tar.gz
fastdfs-master.zip
fastdfs-nginx-module-master.zip
| 节点名 | IP | 软件版本 | 硬件 | 网络 | 说明 |
|---|---|---|---|---|---|
| fastdfs | 192.168.43.93 | list 里面都有 | 2C4G | Nat,内网 | 测试环境 |
安装相关工具和依赖
mkdir /home/dfs # 创建数据存储目录
cd /usr/local/src # 切换到安装目录准备下载安装包
git clone https://github.com/happyfish100/libfastcommon.git --depth 1
解压编译安装
cd libfastcommon/
./make.sh && ./make.sh install #编译安装
下载安装FastDFS
cd ../ #返回上一级目录
git clone https://github.com/happyfish100/fastdfs.git --depth 1
cd fastdfs/
./make.sh && ./make.sh install #编译安装
#配置文件准备
cp /etc/fdfs/tracker.conf.sample /etc/fdfs/tracker.conf
cp /etc/fdfs/storage.conf.sample /etc/fdfs/storage.conf
cp /etc/fdfs/client.conf.sample /etc/fdfs/client.conf #客户端文件,测试用
cp /usr/local/src/fastdfs/conf/http.conf /etc/fdfs/ #供nginx访问使用
cp /usr/local/src/fastdfs/conf/mime.types /etc/fdfs/ #供nginx访问使用
安装fastdfs-nginx-module
cd ../ #返回上一级目录
git clone https://github.com/happyfish100/fastdfs-nginx-module.git --depth 1
cp /usr/local/src/fastdfs-nginx-module/src/mod_fastdfs.conf /etc/fdfs
tracker配置
cd /etc/fdfs/
ls
client.conf.sample storage_ids.conf.sample
storage.conf.sample tracker.conf.sample
vim /etc/fdfs/tracker.conf
#需要修改的内容如下
port=22122 # tracker服务器端口(默认22122,一般不修改)
base_path=/home/dfs # 存储日志和数据的根目录
storage配置
vim /etc/fdfs/storage.conf
#需要修改的内容如下
port=23000 # storage服务端口(默认23000,一般不修改)
base_path=/home/dfs # 数据和日志文件存储根目录
store_path0=/home/dfs # 第一个存储目录
tracker_server=192.168.43.93:22122 # tracker服务器IP和端口
http.server_port=8888 # http访问文件的端口(默认8888,看情况修改,和nginx中保持一致)
配置nginx访问
wget http://nginx.org/download/nginx-1.15.4.tar.gz #下载nginx压缩包
tar -zxvf nginx-1.15.4.tar.gz #解压
cd nginx-1.15.4/
#添加fastdfs-nginx-module模块
./configure --add-module=/usr/local/src/fastdfs-nginx-module/src/
make && make install #编译安装
vim /etc/fdfs/mod_fastdfs.conf
#需要修改的内容如下
tracker_server=192.168.0.104:22122 #tracker服务器IP和端口
url_have_group_name=true
store_path0=/home/dfs
#配置nginx.config
vim /usr/local/nginx/conf/nginx.conf
#添加如下配置
server {
listen 8888; ## 该端口为storage.conf中的http.server_port相同
server_name localhost;
location ~/group[0-9]/ {
ngx_fastdfs_module;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
启动tracker与storage
/etc/init.d/fdfs_trackerd start
/etc/init.d/fdfs_storaged start
/usr/local/nginx/sbin/nginx
配置client上传文件测试
vim /etc/fdfs/client.conf
#需要修改的内容如下
base_path=/home/dfs
tracker_server=192.168.43.93:22122
fdfs_upload_file /etc/fdfs/client.conf /root/1.png
group1/M00/00/00/wKgrXV8O-PWAC-0PAAztU0U_j-g582.png
# 浏览器输入IP:8888/(此处复制上面出现的一个路径)

FastDFS 单节点部署(5.09)
环境
[Fastdfs-Server]
主机名 = fastdfs-1
系统 = CentOS7.6.1810
地址 = 192.168.242.128
软件 = libfastcommon-master
nginx-1.8.0.tar.gz
fastdfs_v5.05.tar.gz
fastdfs-nginx-module_v1.16.tar.gz
| 节点名 | IP | 软件版本 | 硬件 | 网络 | 说明 |
|---|---|---|---|---|---|
| fastdfs | 192.168.242.128 | list 里面都有 | 2C4G | Nat,内网 | 测试环境 |
安装相关工具和依赖
yum install git gcc gcc-c++ make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim libevent -y
解压编译安装
wget https://github.com/happyfish100/libfastcommon/archive/master.zip
unzip master.zip
cd libfastcommon-master/
./make.sh && ./make.sh install
下载安装FastDFS
wget https://github.com/happyfish100/fastdfs/archive/V5.09.tar.gz
tar xf V5.09.tar.gz
cd fastdfs-5.09/
./make.sh && ./make.sh install
cp conf/http.conf /etc/fdfs/
cp conf/mime.types /etc/fdfs/
tracker配置
mkdir /home/fastdfs
cp /etc/fdfs/tracker.conf.sample /etc/fdfs/tracker.conf
vim /etc/fdfs/tracker.conf
#需要修改的内容如下
port=22122 # tracker服务器端口(默认22122,一般不修改)
base_path=/home/fastdfs # 存储日志和数据的根目录
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf restart
storage配置
cp /etc/fdfs/storage.conf.sample /etc/fdfs/storage.conf
vim /etc/fdfs/storage.conf
#需要修改的内容如下
port=23000 # storage服务端口(默认23000,一般不修改)
base_path=/home/fastdfs # 数据和日志文件存储根目录
store_path0=/home/fastdfs # 第一个存储目录
tracker_server=192.168.242.128:22122 # tracker服务器IP和端口
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf restart
安装fastdfs-nginx-module
tar xf fastdfs-nginx-module_v1.16.tar.gz -C /usr/local
cd /usr/local/fastdfs-nginx-module/src/
cp mod_fastdfs.conf /etc/fdfs/
vim /etc/fdfs/mod_fastdfs.conf
base_path=/home/fastdfs
tracker_server=192.168.242.128:22122
url_have_group_name=true #url中包含group名称
store_path0=/home/fdfs_storage #指定文件存储路径(上面配置的store路径)
cp /usr/lib64/libfdfsclient.so /usr/lib/
配置nginx访问
tar xv nginx-1.12.0.tar.gz
tar xf fastdfs-nginx-module_v1.16.tar.gz -C /usr/local
mkdir /usr/local/nginx
cd nginx-1.12.0/
./configure --prefix=/usr/local/nginx --add-module=/usr/local/fastdfs-nginx-module/src
make && make install
cp /usr/local/fastdfs-nginx-module/src/mod_fastdfs.conf /etc/fdfs/
make && make install
mkdir /usr/local/nginx/logs # 创建logs目录
cd /usr/local/nginx/conf/
vim nginx.conf
user root;
pid /usr/local/nginx/logs/nginx.pid;
server_name 192.168.242.128;
location /group1/M00/ {
root /home/fstdfs/data;
ngx_fastdfs_module;
}
此处可能会编译报错ngninx在gmake时可能出现找不到fdfs_define.h问题
错误信息
root/fastdfs-nginx-module/src//common.c:21:25: fatal error:
fdfs_define.h: No such file or directory
#include "fdfs_define.h"
添加如下配置
# 把/usr/lib64/libfdfsclient.so库拷贝到/usr/lib/目录下:
# sudo cp /usr/lib64/libfdfsclient.so /usr/lib/
配置/usr/local/fastdfs-nginx-module/src/目录下的config文件, 把CORE_INCS和CORE_LIBS的所有路径都修改为/usr/include和/usr/lib:
vim /usr/local/src/fastdfs-nginx-module/src/config
CORE_INCS="$CORE_INCS /usr/include/fastdfs /usr/include/fastcommon/"
CORE_LIBS="$CORE_LIBS -L/usr/lib -lfastcommon -lfdfsclient"
启动tracker与storage
fdfs_storaged /etc/fdfs/storage.conf start
fdfs_trackerd /etc/fdfs/tracker.conf start
/usr/local/nginx/sbin/nginx
配置client上传文件测试
vim /etc/fdfs/client.conf
#需要修改的内容如下
base_path=/home/fastdfs
tracker_server=192.168.242.128:22122
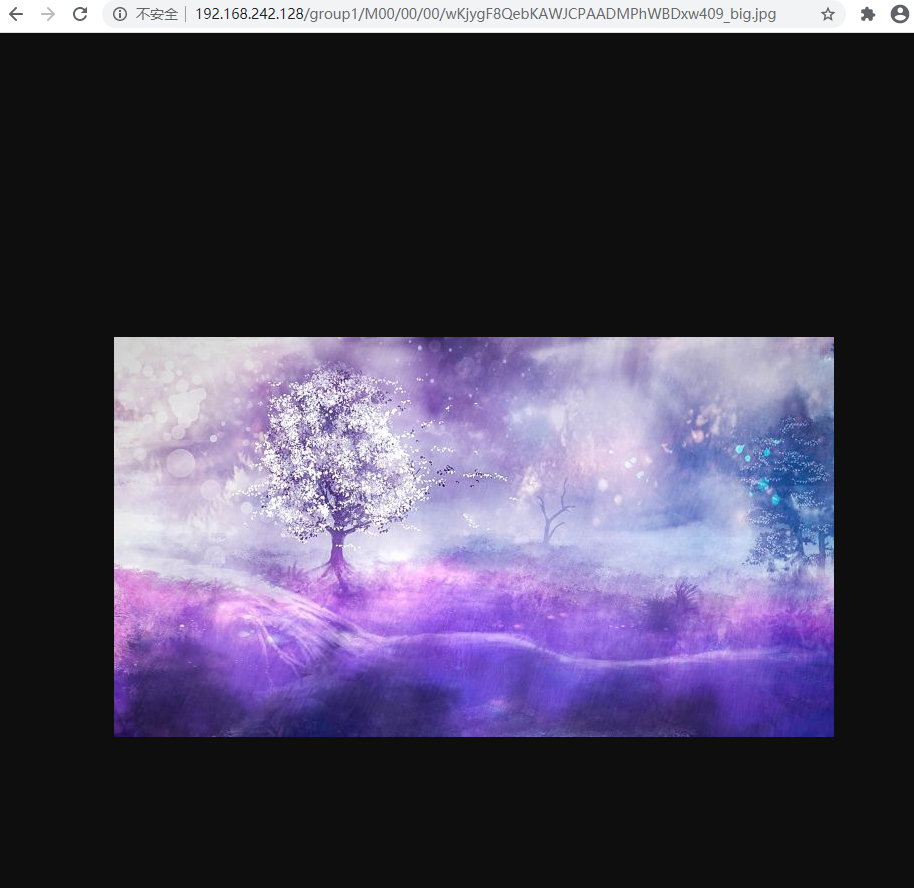
[root@tracker1 sbin]# fdfs_test /etc/fdfs/client.conf upload /root/1.jpg
This is FastDFS client test program v5.05
Copyright (C) 2008, Happy Fish / YuQing
FastDFS may be copied only under the terms of the GNU General
Public License V3, which may be found in the FastDFS source kit.
Please visit the FastDFS Home Page http://www.csource.org/
for more detail.
[2020-07-17 00:00:50] DEBUG - base_path=/home/fastdfs, connect_timeout=30, network_timeout=60, tracker_server_count=1, anti_steal_token=0, anti_steal_secret_key length=0, use_connection_pool=0, g_connection_pool_max_idle_time=3600s, use_storage_id=0, storage server id count: 0
tracker_query_storage_store_list_without_group:
server 1. group_name=, ip_addr=192.168.242.128, port=23000
group_name=group1, ip_addr=192.168.242.128, port=23000
storage_upload_by_filename
group_name=group1, remote_filename=M00/00/00/wKjygF8QebKAWJCPAADMPhWBDxw409.jpg
source ip address: 192.168.242.128
file timestamp=2020-07-17 00:00:50
file size=52286
file crc32=360779548
example file url: http://192.168.242.128/group1/M00/00/00/wKjygF8QebKAWJCPAADMPhWBDxw409.jpg
storage_upload_slave_by_filename
group_name=group1, remote_filename=M00/00/00/wKjygF8QebKAWJCPAADMPhWBDxw409_big.jpg
source ip address: 192.168.242.128
file timestamp=2020-07-17 00:00:50
file size=52286
file crc32=360779548
example file url: http://192.168.242.128/group1/M00/00/00/wKjygF8QebKAWJCPAADMPhWBDxw409_big.jpg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号