03 . Redis集群

Redis集群方案
Redis Cluster 集群模式通常具有 高可用、可扩展性、分布式、容错等特性。Redis分布式方案一般有两种
客户端分区方案
客户端 就已经决定数据会被 存储到哪个 redis 节点或者从哪个 redis节点读取数据。其主要思想是采用哈希算法将 Redis 数据的 key进行散列,通过 hash函数,特定的 key会 映射到特定的 Redis节点上。
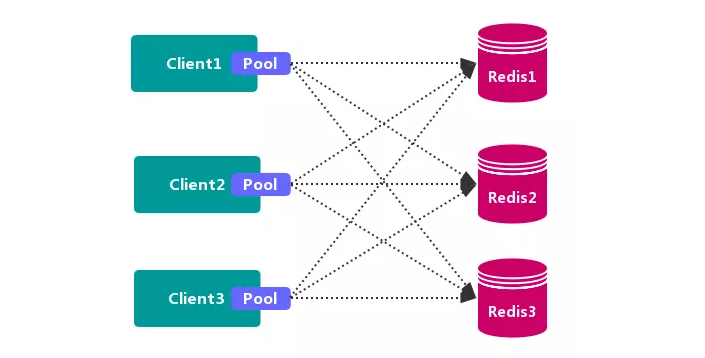
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业界普遍使用的 Redis多实例集群方法。
Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。
优点
不使用第三方中间件,分区逻辑 可控,配置 简单,节点之间无关联,容易 线性扩展,灵活性强。
缺点
客户端 无法动态增删服务节点,客户端需要自行维护分发逻辑,客户端之间 无连接共享,会造成 连接浪费。
代理分区方案
客户端发送请求到一个代理组件,代理 解析 客户端的数据,并将请求转发至正确的节点,最后将结果回复给客户端。
优点:简化客户端的分布式逻辑,客户端透明接入,切换成本低,代理的 转发 和 存储 分离。
缺点:多了一层代理层,加重了架构部署复杂度和 性能损耗。
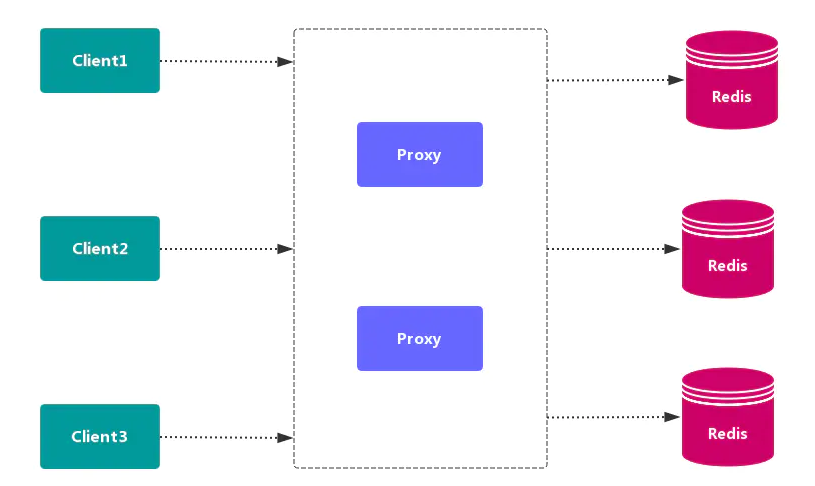
代理分区 主流实现的有方案有 Twemproxy 和 Codis。
Twemproxy
Twemproxy也叫nutcraker,是redis和memcache的 中间代理服务器 程序。Twemproxy作为 代理,可接受来自多个程序的访问,按照 路由规则,转发给后台的各个Redis服务器,再原路返回。Twemproxy存在 单点故障 问题,需要结合Lvs和Keepalived做 高可用方案。

优点
应用范围广,稳定性较高,中间代理层高可用。
缺点
无法平滑地水平扩容/缩容,无可视化管理界面,运维不友好,出现故障,不能自动转移
Codis
Codis是一个 分布式Redis解决方案,对于上层应用来说,连接Codis-Proxy和直接连接 原生的Redis-Server没有的区别。Codis底层会 处理请求的转发,不停机的进行 数据迁移 等工作。Codis采用了无状态的 代理层,对于 客户端 来说,一切都是透明的。
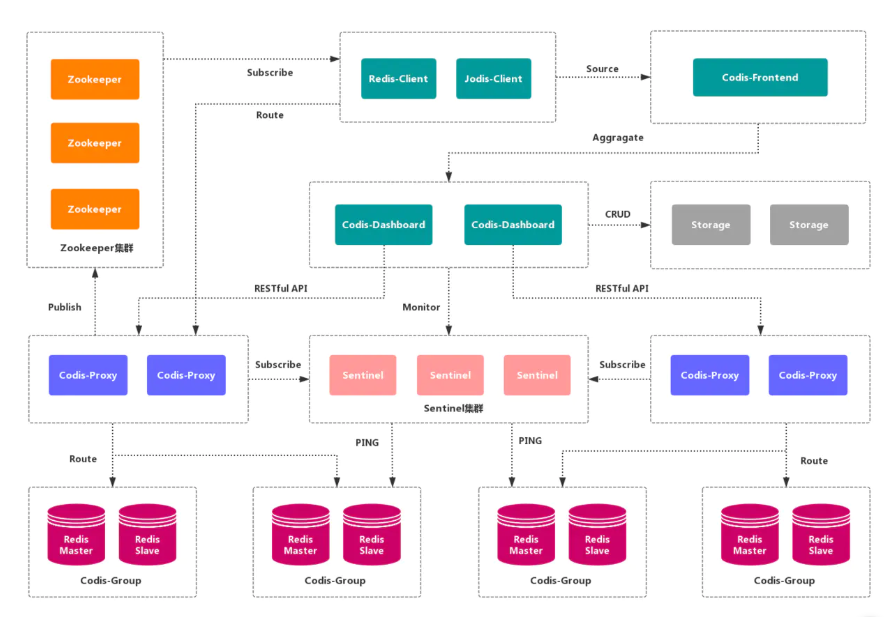
优点
实现了上层
Proxy和底层Redis的 高可用,数据分片 和 自动平衡,提供 命令行接口 和RESTful API,提供 监控 和 管理 界面,可以动态 添加 和 删除Redis节点。
缺点
部署架构和配置复杂,不支持跨机房和多租户,不支持鉴权管理。
查询路由方案
客户端随机地 请求任意一个 Redis 实例,然后由 Redis 将请求 转发 给 正确 的 Redis 节点。Redis Cluster 实现了一种 混合形式 的 查询路由,但并不是 直接 将请求从一个 Redis 节点 转发 到另一个 Redis 节点,而是在 客户端 的帮助下直接 重定向( redirected)到正确的 Redis 节点。
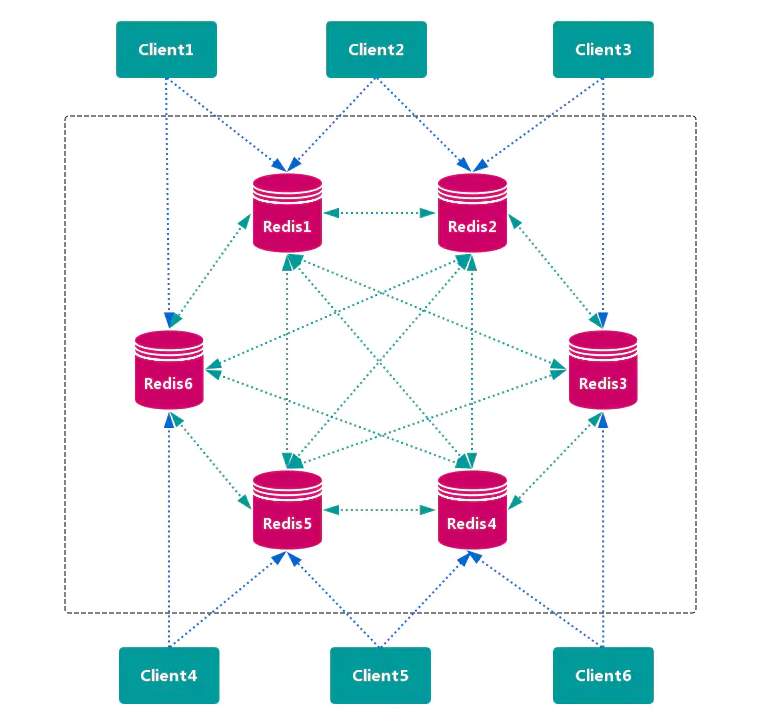
优点
无中心节点,数据按照 槽 存储分布在多个
Redis实例上,可以平滑的进行节点 扩容/缩容,支持 高可用 和 自动故障转移,运维成本低。
缺点
严重依赖
Redis-trib工具,缺乏 监控管理,需要依赖Smart Client(维护连接,缓存路由表,MultiOp和Pipeline支持)。Failover节点的 检测过慢,不如 中心节点ZooKeeper及时。Gossip消息具有一定开销。无法根据统计区分 冷热数据。
数据分布
数据分布理论
分布式数据库 首先要解决把 整个数据集 按照 分区规则 映射到 多个节点 的问题,即把 数据集 划分到 多个节点 上,每个节点负责 整体数据 的一个 子集。
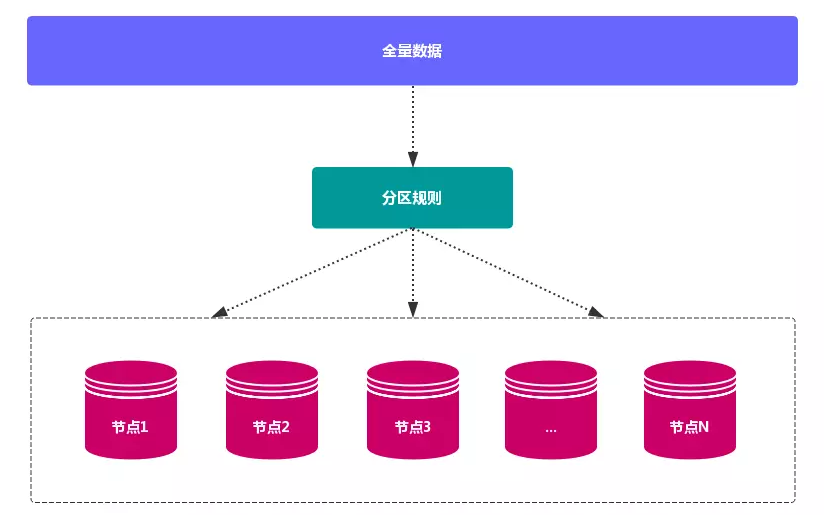
数据分布通常有 哈希分区 和 顺序分区 两种方式,对比如下:
| 分区方式 | 特点 | 相关产品 |
|---|---|---|
| 哈希分区 | 离散程度好,数据分布与业务无关,无法顺序访问 | Redis Cluster,Cassandra,Dynamo |
| 顺序分区 | 离散程度易倾斜,数据分布与业务相关,可以顺序访问 | BigTable,HBase,Hypertable |
由于 Redis Cluster 采用 哈希分区规则,这里重点讨论 哈希分区。常见的 哈希分区 规则有几种,下面分别介绍:
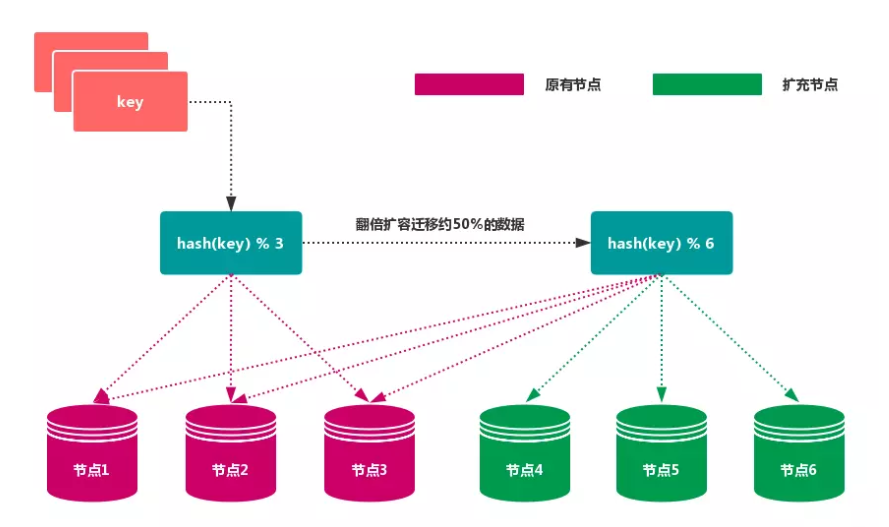
节点取余分区
使用特定的数据,如 Redis 的 键 或 用户 ID,再根据 节点数量 N 使用公式:hash(key)% N 计算出 哈希值,用来决定数据 映射 到哪一个节点上。
优点
这种方式的突出优点是 简单性,常用于 数据库 的 分库分表规则。一般采用 预分区 的方式,提前根据 数据量 规划好 分区数,比如划分为
512或1024张表,保证可支撑未来一段时间的 数据容量,再根据 负载情况 将 表 迁移到其他 数据库 中。扩容时通常采用 翻倍扩容,避免 数据映射 全部被 打乱,导致 全量迁移 的情况。
缺点
当 节点数量 变化时,如 扩容 或 收缩 节点,数据节点 映射关系 需要重新计算,会导致数据的 重新迁移。
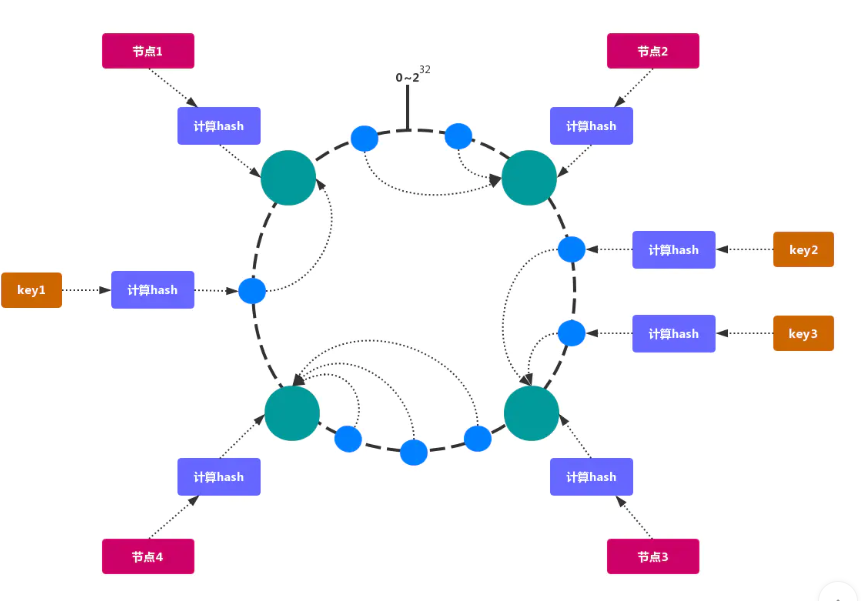
一致性哈希分区
一致性哈希 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 收尾相接 的 Hash 环上,每个 key 在计算 Hash 后会 顺时针 找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
加减节点 会造成 哈希环 中部分数据 无法命中。当使用 少量节点 时,节点变化 将大范围影响 哈希环 中 数据映射,不适合 少量数据节点 的分布式方案。普通 的 一致性哈希分区 在增减节点时需要 增加一倍 或 减去一半 节点才能保证 数据 和 负载的均衡。
注意
因为一致性哈希分区的这些缺点,一些分布式系统采用虚拟槽对一致性哈希进行改进,比如 Dynamo 系统。
虚拟槽分区
虚拟槽分区 巧妙地使用了 哈希空间,使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(slot)。这个范围一般 远远大于 节点数,比如 Redis Cluster 槽范围是 0 ~ 16383。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽,如图所示:
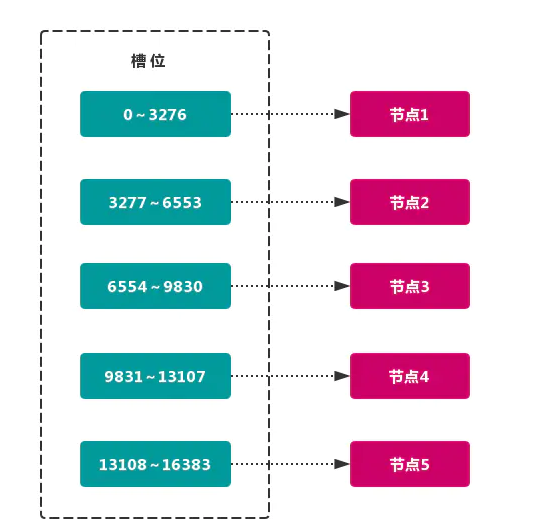
当前集群有
5个节点,每个节点平均大约负责3276个 槽。由于采用 高质量 的 哈希算法,每个槽所映射的数据通常比较 均匀,将数据平均划分到5个节点进行 数据分区。Redis Cluster就是采用 虚拟槽分区。
# 节点1: 包含 `0` 到 `3276` 号哈希槽。
# 节点2:包含 `3277` 到 `6553` 号哈希槽。
# 节点3:包含 `6554` 到 `9830` 号哈希槽。
# 节点4:包含 `9831` 到 `13107` 号哈希槽。
# 节点5:包含 `13108` 到 `16383` 号哈希槽。
这种结构很容易 添加 或者 删除 节点。如果 增加 一个节点
6,就需要从节点1 ~ 5获得部分 槽 分配到节点6上。如果想 移除 节点1,需要将节点1中的 槽 移到节点2 ~ 5上,然后将 没有任何槽 的节点1从集群中 移除 即可。由于从一个节点将 哈希槽 移动到另一个节点并不会 停止服务,所以无论 添加删除 或者 改变 某个节点的 哈希槽的数量 都不会造成 集群不可用 的状态.
Redis的数据分区
Redis Cluster 采用 虚拟槽分区,所有的 键 根据 哈希函数 映射到 0~16383 整数槽内,计算公式:slot = CRC16(key)& 16383。每个节点负责维护一部分槽以及槽所映射的 键值数据,如图所示:
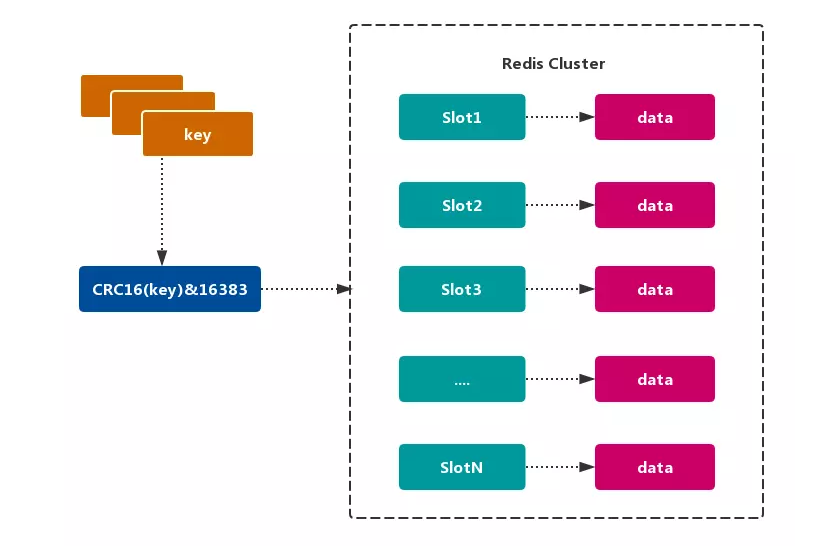
Redis虚拟槽分区的特点
# 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
# 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
# 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景。
Redis集群的功能限制
Redis 集群相对 单机 在功能上存在一些限制,需要 开发人员 提前了解,在使用时做好规避。
key批量操作支持有限
类似
mset、mget操作,目前只支持对具有相同slot值的key执行 批量操作。对于 映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上,因此不被支持。
key事务操作支持有限
只支持 多
key在 同一节点上 的 事务操作,当多个key分布在 不同 的节点上时 无法 使用事务功能。
key 作为数据分区的最小粒度`
不能将一个 大的键值 对象如
hash、list等映射到 不同的节点。
不支持多数据库空间
单机 下的
Redis可以支持16个数据库(db0 ~ db15),集群模式 下只能使用 一个 数据库空间,即db0。
复制结构只支持一层
从节点只能复制 主节点,不支持 嵌套树状复制 结构
Redis集群搭建
Redis-Cluster是Redis官方的一个 高可用 解决方案,Cluster中的Redis共有2^14(16384)个slot槽。创建Cluster后,槽 会 平均分配 到每个Redis节点上。下面介绍一下本机启动
6个Redis的 集群服务,并使用redis-trib.rb创建 3主3从 的 集群。搭建集群工作需要以下三个步骤:
准备节点
Redis集群一般由 多个节点 组成,节点数量至少为6个,才能保证组成 完整高可用 的集群。每个节点需要 开启配置cluster-enabled yes,让Redis运行在 集群模式 下。
Redis集群的节点规划如下
| 节点名称 | 端口号 | 是主是从 | 所属主节点 |
|---|---|---|---|
| redis-6379 | 6379 | 主节点 | --- |
| redis-6389 | 6389 | 从节点 | redis-6379 |
| redis-6380 | 6380 | 主节点 | --- |
| redis-6390 | 6390 | 从节点 | redis-6380 |
| redis-6381 | 6381 | 主节点 | --- |
| redis-6391 | 6391 | 从节点 | redis-6381 |
注意:建议为集群内 所有节点 统一目录,一般划分三个目录:
conf、data、log,分别存放 配置、数据 和 日志 相关文件。把6个节点配置统一放在conf目录下。
创建redis各实例目录
sudo mkdir -p /usr/local/redis-cluster
cd /usr/local/redis-cluster
sudo mkdir conf data log
sudo mkdir -p data/redis-6379 data/redis-6389 data/redis-6380 data/redis-6390 data/redis-6381 data/redis-6391
redis配置文件管理
根据以下 模板 配置各个实例的
redis.conf,以下只是搭建集群需要的 基本配置,可能需要根据实际情况做修改。
# redis后台运行
daemonize yes
# 绑定的主机端口
bind 127.0.0.1
# 数据存放目录
dir /usr/local/redis-cluster/data/redis-6379
# 进程文件
pidfile /var/run/redis-cluster/${自定义}.pid
# 日志文件
logfile /usr/local/redis-cluster/log/${自定义}.log
# 端口号
port 6379
# 开启集群模式,把注释#去掉
cluster-enabled yes
# 集群的配置,配置文件首次启动自动生成
cluster-config-file /usr/local/redis-cluster/conf/${自定义}.conf
# 请求超时,设置10秒
cluster-node-timeout 10000
# aof日志开启,有需要就开启,它会每次写操作都记录一条日志
appendonly yes
- redis-6379.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6379
pidfile /var/run/redis-cluster/redis-6379.pid
logfile /usr/local/redis-cluster/log/redis-6379.log
port 6379
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6379.conf
cluster-node-timeout 10000
appendonly yes
- redis-6389.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6389
pidfile /var/run/redis-cluster/redis-6389.pid
logfile /usr/local/redis-cluster/log/redis-6389.log
port 6389
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6389.conf
cluster-node-timeout 10000
appendonly yes
- redis-6380.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6380
pidfile /var/run/redis-cluster/redis-6380.pid
logfile /usr/local/redis-cluster/log/redis-6380.log
port 6380
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6380.conf
cluster-node-timeout 10000
appendonly yes
- redis-6390.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6390
pidfile /var/run/redis-cluster/redis-6390.pid
logfile /usr/local/redis-cluster/log/redis-6390.log
port 6390
cluster-enabled es
cluster-config-file /usr/local/redis-cluster/conf/node-6390.conf
cluster-node-timeout 10000
appendonly yes
- redis-6381.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6381
pidfile /var/run/redis-cluster/redis-6381.pid
logfile /usr/local/redis-cluster/log/redis-6381.log
port 6381
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6381.conf
cluster-node-timeout 10000
appendonly yes
- redis-6391.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6391
pidfile /var/run/redis-cluster/redis-6391.pid
logfile /usr/local/redis-cluster/log/redis-6391.log
port 6391
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6391.conf
cluster-node-timeout 10000
appendonly yes
安装Ruby环境
wget http://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.5.tar.gz
tar zxvf ruby-2.3.5.tar.gz
cd ruby-2.3.5
./configure --prefix=/opt/ruby
make && make install
ln -s /opt/ruby/bin/ruby /usr/bin/ruby
ln -s /opt/ruby/bin/gem /usr/bin/gem
[root@redis-cluster redis-cluster]# ruby -v
ruby 2.3.5p376 (2017-09-14 revision 59905) [x86_64-linux]
准备rubygem redis依赖
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install -l redis-3.3.0.gem
# 一般会报错以下信息
ERROR: Loading command: install (LoadError)
cannot load such file -- zlib
ERROR: While executing gem ... (NoMethodError)
undefined method `invoke_with_build_args' for nil:NilClass
# 我们做下下面步骤
yum -y install zlib-devel
cd ruby-2.3.5/ext/zlib/
ruby ./extconf.rb
make && make install
gem install -l redis-3.3.0.gem
# Successfully installed redis-3.3.0
# 显示这条信息代表安装成功
拷贝redis-trib.rb到集群根目录
redis-trib.rb是redis官方推出的管理redis集群 的工具,集成在redis的源码src目录下,将基于redis提供的 集群命令 封装成 简单、便捷、实用 的 操作工具。
sudo cp /usr/local/redis-4.0.11/src/redis-trib.rb /usr/local/redis-cluster
查看redis-trib.rb命令环境是否正确,输出如下:
./redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
redis-trib.rb 是 redis 作者用 ruby 完成的。redis-trib.rb 命令行工具 的具体功能如下:
| 命令 | 作用 |
|---|---|
| create | 创建集群 |
| check | 检查集群 |
| info | 查看集群信息 |
| fix | 修复集群 |
| reshard | 在线迁移slot |
| rebalance | 平衡集群节点slot数量 |
| add-node | 将新节点加入集群 |
| del-node | 从集群中删除节点 |
| set-timeout | 设置集群节点间心跳连接的超时时间 |
| call | 在集群全部节点上执行命令 |
| import | 将外部redis数据导入集群 |
启动redis服务节点
运行如下命令启动6台redis节点
sudo redis-server conf/redis-6379.conf
sudo redis-server conf/redis-6389.conf
sudo redis-server conf/redis-6380.conf
sudo redis-server conf/redis-6390.conf
sudo redis-server conf/redis-6381.conf
sudo redis-server conf/redis-6391.conf
启动完成后,redis以集群模式启动,查看各个redis节点的进程状态
[root@redis-cluster redis-cluster]# ps -ef |grep redis-server
root 4694 1 0 10:48 ? 00:00:01 redis-server 127.0.0.1:6380 [cluster]
root 4770 1 0 10:49 ? 00:00:01 redis-server 127.0.0.1:6379 [cluster]
root 4803 1 0 10:50 ? 00:00:01 redis-server 127.0.0.1:6381 [cluster]
root 4874 1 0 10:50 ? 00:00:01 redis-server 127.0.0.1:6389 [cluster]
root 4913 1 0 10:50 ? 00:00:01 redis-server 127.0.0.1:6390 [cluster]
root 4952 1 0 10:51 ? 00:00:01 redis-server 127.0.0.1:6391 [cluster]
在每个
redis节点的redis.conf文件中,我们都配置了cluster-config-file的文件路径,集群启动时,conf目录会新生成 集群 节点配置文件。查看文件列表如下:
tree -L 3 .
.
├── appendonly.aof
├── conf
│ ├── node-6379.conf
│ ├── node-6380.conf
│ ├── node-6381.conf
│ ├── node-6389.conf
│ ├── node-6390.conf
│ ├── node-6391.conf
│ ├── redis-6379.conf
│ ├── redis-6380.conf
│ ├── redis-6381.conf
│ ├── redis-6389.conf
│ ├── redis-6390.conf
│ └── redis-6391.conf
├── data
│ ├── redis-6379
│ ├── redis-6380
│ ├── redis-6381
│ ├── redis-6389
│ ├── redis-6390
│ └── redis-6391
├── log
│ ├── redis-6379.log
│ ├── redis-6380.log
│ ├── redis-6381.log
│ ├── redis-6389.log
│ ├── redis-6390.log
│ └── redis-6391.log
└── redis-trib.rb
9 directories, 20 files
redis-trib关联集群节点
按照从主到从的方式从左到右依次排列 6个redis节点`
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6389 127.0.0.1:6390 127.0.0.1:6391
# 集群创建后,redis-trib会先将16384个哈希槽分配到3个主节点,即 redis-6379,redis-6380和redis-6381。然后将各个从节点指向主节点,进行数据同步。
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:6379
127.0.0.1:6380
127.0.0.1:6381
Adding replica 127.0.0.1:6390 to 127.0.0.1:6379
Adding replica 127.0.0.1:6391 to 127.0.0.1:6380
Adding replica 127.0.0.1:6389 to 127.0.0.1:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: ad7c4eb8209adff15b273f27b2e540f84a3489c1 127.0.0.1:6379
slots:0-5460 (5461 slots) master
M: e4a47642b1eca92ecedbcfcbcfda6ad2c80b8c61 127.0.0.1:6380
slots:5461-10922 (5462 slots) master
M: 16edddbdaed76241ebe575f997f72e0bb769e19f 127.0.0.1:6381
slots:10923-16383 (5461 slots) master
S: 865a7074db84ba0377373aaefa31767260ed1dc7 127.0.0.1:6389
replicates e4a47642b1eca92ecedbcfcbcfda6ad2c80b8c61
S: 065d548e79b4aecdee54629921e7fd3c7443deda 127.0.0.1:6390
replicates 16edddbdaed76241ebe575f997f72e0bb769e19f
S: 4a2b0d3cffd931aec5d140549e4333b8b1455584 127.0.0.1:6391
replicates ad7c4eb8209adff15b273f27b2e540f84a3489c1
Can I set the above configuration? (type 'yes' to accept): yes
# 此时会产生一个交互,我们输入yes,redis-trib.rb开始执行节点握手和槽分配.
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 最后出现上面四行信息代表成功
redis集群完整性检测
使用
redis-trib.rb check命令检测之前创建的 两个集群 是否成功,check命令只需要给出集群中 任意一个节点地址 就可以完成 整个集群 的 检查工作,命令如下:
redis-trib.rb check 127.0.0.1:6379
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: ad7c4eb8209adff15b273f27b2e540f84a3489c1 127.0.0.1:6379
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 065d548e79b4aecdee54629921e7fd3c7443deda 127.0.0.1:6390
slots: (0 slots) slave
replicates 16edddbdaed76241ebe575f997f72e0bb769e19f
M: e4a47642b1eca92ecedbcfcbcfda6ad2c80b8c61 127.0.0.1:6380
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: 16edddbdaed76241ebe575f997f72e0bb769e19f 127.0.0.1:6381
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 865a7074db84ba0377373aaefa31767260ed1dc7 127.0.0.1:6389
slots: (0 slots) slave
replicates e4a47642b1eca92ecedbcfcbcfda6ad2c80b8c61
S: 4a2b0d3cffd931aec5d140549e4333b8b1455584 127.0.0.1:6391
slots: (0 slots) slave
replicates ad7c4eb8209adff15b273f27b2e540f84a3489c1
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 执行 集群检查,检查各个 redis 节点占用的 哈希槽(slot)的个数以及 slot 覆盖率。16384 个槽位中,主节点 redis-6379、redis-6380 和 redis-6381 分别占用了 5461、5461 和 5462 个槽位。

