02 . Python之数据类型

变量
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。 因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符.
变量赋值
# Python 中的变量赋值不需要类型声明。
# 每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
# 每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
# 等号(=)用来给变量赋值。
# 等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。例如:
conuter = 100
miles = 1000.0
name = "Json"
print (conuter)
print (miles)
print (name)
多个变量赋值
Python允许你为多个变量赋值,例如.
a = b = c = 1
print (a,b,c)
# 你也可以为多个对象指定多个变量,例如:
a, b , c = 1 , 2, "json"
print(a,b,c)
但是在python中, 程序员不用关心内存溢出等问题,因为python已经帮忙实现了内存管理。
1、引用计数器
2、垃圾回收机制
每个对象都会维护一个自己的引用计数器,每次对其引用,计数器就会加1.当一个对象的计数器为零时,垃圾回收机制就会把他从内存中清除,释放它之前占用的内存空间。
标准数据类型
在内存中存储的数据可以有多种类型.
例如,一个人的年龄可以用数字存储,他的名字可以用字符存储.
Python定义了一些标准类型,用于存储各种类型的数据.
Python有五个标准的的数据类型.
* Numbers(数字)
* String(字符串)
* List(列表)
* Tuple(元组)
* Dictionary(字典)
Python数字(Number)
Python数字类型用于存储数值
数值类型是不允许改变的,这就意味着如果改变数字类型的值,将重新分配内存空间
var1 = 10
var2 = 20
也可以使用del语句删除一些数字对象的引用
del语句的语法是:
del var1[,var2[,var3[....,varN]]]
# 也可以通过del语句删除单个或多个对象的引用,例如:
del var
del var_a,var_b
Python支持三种不同的数值类型
整型(int): 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
浮点型(float): 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数(complex): 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
我们也可以使用十六进制和八进制代表整数:
>>> number = 0xA0F # 十六进制
>>> number
2575
>>> number=0o37 # 八进制
>>> number
31
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3e+18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2E-12 | 4.53e-7j |
Python数字类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,只需要将数据类型作为函数名即可
* int(x) 将x转换为一个整数。
* float(x) 将x转换到一个浮点数。
* complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
* complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
# 以下实例将浮点数变量a转换为整数:
a = 1.0
print (int(a))
1
Python数字运算
Python解释器可以作为一个简单的计算器,您可以在解释器里输入一个表达式,它将输出表达式的值.
表达式的语法很直白: +, -, * 和 /, 和其它语言(如Pascal或C)里一样。例如:
>>> 2 + 2
4
>>> 50 - 5*6
20
>>> (50 - 5*6) / 4
5.0
>>> 8 / 5 # 总是返回一个浮点数
1.6
注意:在不同的机器上浮点运算的结果可能会不一样.
在整数除法中,除法 / 总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // :
>>> 17 / 3 # 整数除法返回浮点型
5.666666666666667
>>>
>>> 17 // 3 # 整数除法返回向下取整后的结果
5
>>> 17 % 3 # %操作符返回除法的余数
2
>>> 5 * 3 + 2
17
# 注意: //得到的不一定是整数类型的数,他与分母分子的数据类型有关系.
>>> 7//2
3
>>> 7.0//2
3.0
>>> 7//2.0
3.0
>>>
等号=用于给变量赋值。赋值之后,除了下一个提示符,解释器不会显示任何结果.
>>> width = 20
>>> height = 5*9
>>> width * height
900
Python可以使用操作进行幂运算**
>>> 5 ** 2 # 5 的平方
25
>>> 2 ** 7 # 2的7次方
128
变量在使用前必须先“定义”(即赋予变量一个值),否则会出现错误
>>> n # 尝试访问一个未定义的变量
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'n' is not defined
不同类型的数混合运算时会将整数转换为浮点数
>>> 3 * 3.75 / 1.5
7.5
>>> 7.0 / 2
3.5
在交互模式中,最后被输出的表达式结果被赋值给变量 _。例如
>>> tax = 12.5 / 100
>>> price = 100.50
>>> price * tax
12.5625
>>> price + _
113.0625
>>> round(_, 2)
113.06
# 此处,_ 变量应被用户视为只读变量
随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数
| 函数 | 描述 |
|---|---|
| [choice(seq)] | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| [randrange ([start,] stop [,step])] | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| [random()] | 随机生成下一个实数,它在[0,1)范围内。 |
| [seed([x])] | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| [shuffle(lst)] | 将序列的所有元素随机排序 |
| [uniform(x, y)] | 随机生成下一个实数,它在[x,y]范围内。 |
Python字符串
字符串是Python中最常用的数据类型,我们可以使用引号('或'')来创建字符串.
创建字符串很简单,只要为变量分配一个值即可,例如:
var1 = 'Hello World!' var2 = "Runoob"
Python访问字符串中的值
字符串或串(String)是由数字、字母、下划线组成的一串字符.
一般标记为
s="a1a2···an"(n>=0)
# 他是编程语言中表示文本的数据类型
# Python的字符串有2中取值顺序:
# 从左到右索引默认是0开始的,最大范围是字符串长度为1.
# 从右到左索引默认-1开始的,最大范围是字符串开头
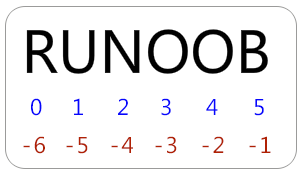
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
比如:
s = 'youmen'
print (s[1:5])
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。

str = 'Hello Wrold'
print (str)
print (str[0])
print (str[2:5])
print (str[2:])
print (str * 2)
print (str + "TEST")
Hello Wrold
H
llo
llo Wrold
Hello WroldHello Wrold
Hello WroldTEST
Python字符串更新
你可以截取字符串的一部分并与其他字段拼接,如下实例:
var1 = 'hello world'
print(var1[:6] + 'Runnob!')
# 上面实例输出结果为
hello Runnob!
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ' | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy 代表的字符,例如:\o12 代表换行,其中 o 是字母,不是数字 0。 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
Python字符串运算符
下表实例变量a值为'hello',b变量值为'Python
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0,2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | 'H' in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | 'M' not in a 输出结果 True |
| % | 格式字符串 | 请看下面 |
Python字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
**在Python中,字符串格式化使用与C中sprintf函数一样的语法.
Example
print('我叫%s 今年 %d 岁!' % ('小明',10))
我叫小明 今年 10 岁!
Python字符串格式化符号
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
Python三引号
**Python三引号允许一个字符串跨多行,字符串中包含换行符、制表符以及其他符号,如下:
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
TAB(\t).
也可以是使用换行符[\n].
"""
print(para_str)
# 以上实例输出结果为
这是一个多行字符串的实例
多行字符串可以使用制表符
TAB( ).
也可以是使用换行符[
].
# 三引号让程序员从引号和特殊字符的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的所见即得格式.
# 一个典型用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义会非常的繁琐.
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。之前我们习惯用百分号 (%):
>>> name = 'Runoob'
>>> 'Hello %s' % name
'Hello Runoob'
# f-string格式和字符串以f开头,后面跟着字符串,字符串中的表达式用大括号{}包起来,
# 他会将变量或表达式计算后的值替换进去,实例如下.
name = 'Runoob'
print(f'Hello {name}')
age = 20
print(f'{age+1}')
w = {'name':'Runoob','url':'www.runoob.com'}
print(f'{w["name"]}:{w["url"]}')
Hello Runoob
21
Runoob:www.runoob.com
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串
Python的字符串内建函数
Python的字符串常用内建函数如下:
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar)返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding="utf-8", errors="strict")Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding='UTF-8',errors='strict')以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False |
| 7 | expandtabs(tabsize=8)把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string))检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string))跟find()方法一样,只不过如果str不在字符串中会报一个异常. |
| 10 | isalnum()如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha()如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| 12 | isdigit()如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 | islower()如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric()如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace()如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle()如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper()如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq)以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar])返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip()截掉字符串左边的空格或指定字符。 |
| 23 | maketrans()创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str)返回字符串 str 中最大的字母。 |
| 25 | min(str)返回字符串 str 中最小的字母。 |
| 26 | replace(old, new [, max])把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string))类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string))类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar])返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip()删除字符串字符串末尾的空格. |
| 31 | split(str="", num=string.count(str))num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends])按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string))检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars])在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase()将字符串中大写转换为小写,小写转换为大写 |
| 36 | title()返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars="")根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper()转换字符串中的小写字母为大写 |
| 39 | zfill (width)返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal()检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
Python列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。

此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google','Runoob',1997,2000]
list2 = [1,2,3,4,5]
list3 = ["a","b","c","d"]
# 注意: 后面的例子都是以这里的变量为模板
与字符串的索引一样,列表索引从0开始,列表可以进行截取、组合等
访问列表中的值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:
print("list1[0]", list1[0])
print("list2[1:3]",list2[1:3])
# 以上实例输出结果为:
list1[0] Google
list2[1:3] [2, 3]
更新列表
print('list1第一个元素为:',list1[1])
list1[1] = 'youmen'
print('list1元素为:',list1[1])
# 以上实例输出结果为:
list1第一个元素为: Runoob
list1元素为: youmen
# 也可以使用append()方法
删除列表元素
可以使用del 语句来删除列表的元素,如下实例
list3 = ["a","b","c","d"]
print("原始列表list3",list3)
del list3[0]
print("删除位置第0个元素",list3)
# 以上实例输出结果为
原始列表list3 ['a', 'b', 'c', 'd']
删除位置第0个元素 ['b', 'c', 'd']
# 当然,也可以使用remove()方法删除
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
Python列表的截取与拼接及嵌套列表
Python的列表截取与字符串操作类型,如下所示
L = ['Google','Runoob','Taobao']
print(L[2])
print(L[-2])
print(L[1:])
str1 = [ 1,4,9,13]
str1 += [15,18,20,22]
print(str1)
# 以上实例输出结果为
Taobao
Runoob
['Runoob', 'Taobao']
[1, 4, 9, 13, 15, 18, 20, 22]
嵌套列表
stra = ['a','b','c']
strb = ['d','e','f']
strc = [stra,strb]
print(strc)
print(strc[0])
print(strc[0][1])
# 以上实例输出结果为:
[['a', 'b', 'c'], ['d', 'e', 'f']]
['a', 'b', 'c']
b
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | len(list) 列表元素个数 |
| 2 | max(list) 返回列表元素最大值 |
| 3 | min(list) 返回列表元素最小值 |
| 4 | list(seq) 将元组转换为列表 |
Python包含以下方法
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
加号 + 是列表连接运算符,星号* 是重复操作,如下实例:
list = ['runoob',788,3.14,'youmen',77]
youmen = ['flying']
print(list)
print(list[0])
print(list[2:4])
print(list[2:])
print(list * 2)
print(list + youmen)
# 以上实例输出结果:
['runoob', 788, 3.14, 'youmen', 77]
runoob
[3.14, 'youmen']
[3.14, 'youmen', 77]
['runoob', 788, 3.14, 'youmen', 77, 'runoob', 788, 3.14, 'youmen', 77]
['runoob', 788, 3.14, 'youmen', 77, 'flying']
将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
Example
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
将列表当做队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
Example3>> from collections import deque >> queue = deque(["Eric", "John", "Michael"]) >> queue.append("Terry") # Terry arrives >> queue.append("Graham") # Graham arrives >> queue.popleft() # The first to arrive now leaves 'Eric' >> queue.popleft() # The second to arrive now leaves 'John' >> queue # Remaining queue in order of arrival deque(['Michael', 'Terry', 'Graham'])
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
Example
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
# 我们还可以对他进行幂计算:
>>> [[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
# 可以对之前同样序列每一个元素逐个调用某方法:
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
# 我们还可以使用if子句作为过滤器:
>>> [3*x for x in vec if x > 3]
[12, 18]
>>> [3*x for x in vec if x < 2]
[]
# 以下是一些关于循环和其他技巧的演示:
>>> vec1 = [2, 4, 6]
>>> vec2 = [4, 3, -9]
>>> [x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
>>> [x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
>>> [vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
# 列表推导式可以使用复杂表达式或嵌套函数:
>>> [str(round(355/113, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']
嵌套列表解析
Python的列表还可以嵌套
以下实例展示了3X4的矩阵列表
Example5
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
# 以下实例将3X4的矩阵列表转换为4X3列表
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
# 以下实例也可以使用以下方法实现:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
Python3元组
元组是另一个数据类型,类似于List(列表)
元组用()标识,内部元素用逗号隔开,但使元组不能二次赋值,相当于只读列表
元组是不允许更新的,而列表是允许更新的
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
tup1 = (50)
print(type(tup1))
tup2 = (50,)
print(type(tup2))
<class 'int'>
<class 'tuple'>
# 元组与字符串类似,下标索引从0开始,可以进行截取,组合等.
访问元组
元组可以使用下标索引来访问元组中的值,如下实例
tuple = ('runoob',788,3.14,'youmen',77)
youmen = (123, 'flying')
print(tuple)
print(tuple[0])
print(tuple[2:4])
print(tuple[2:])
print(tuple * 2)
print(tuple + youmen)
# 以上实例输出结果
('runoob', 788, 3.14, 'youmen', 77)
runoob
(3.14, 'youmen')
(3.14, 'youmen', 77)
('runoob', 788, 3.14, 'youmen', 77, 'runoob', 788, 3.14, 'youmen', 77)
('runoob', 788, 3.14, 'youmen', 77, 123, 'flying')
修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例
tup1 = (1,2,3)
tup2 = ('flying','youmen')
tup3 = tup1 + tup2
print(tup3)
(1, 2, 3, 'flying', 'youmen')
删除元组
元组中的元素是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例
tup = ('Google','Runoob',1999,2000)
print(tup)
del tup
print("删除后的元组tup:")
print(tup)
('Google', 'Runoob', 1999, 2000)
删除后的元组tup:
Traceback (most recent call last):
File "c:\Users\You-Men\.vscode\extensions\ms-python.python-2019.11.50794\pythonFiles\ptvsd_launcher.py",
# 以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
删除后的元组 tup :
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (tup)
NameError: name 'tup' is not defined
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print (x,) | 1 2 3 | 迭代 |
元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:元组:
tup = ('Google','Runoob',1999,2000)
print(tup[2])
print(tup[-2])
print(tup[1:])
# 以上实例输出结果
1999
1999
('Runoob', 1999, 2000)
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Runoob' | 读取第三个元素 |
| L[-2] | 'Taobao' | 反向读取;读取倒数第二个元素 |
| L[1:] | ('Taobao', 'Runoob') | 截取元素,从第二个开始后的所有元素。 |
元组内置函数
Python3元组包含了以下内置函数
| 序号 | 方法及描述 | 实例 |
|---|---|---|
| 1 | len(tuple)计算元组元素个数 | tuple1 = ('Google','Runoob') ; len(tuple1) ;2 |
| 2 | max(tuple) 返回元组中元素最大值。 | tuple2=('5','4','3') ;max(tuple2); 5 |
| 3 | min(tuple) 返回元组中元素最小值 | tuple3 = ('5','4','8');min(tuple3);4 |
| 4 | tuple(seq) | list1=[1,2,3]; tuple4=tuple(list1);tuple4 |
关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的地址地址值不同.
>>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g' # 不支持修改元素
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> id(tup) # 查看内存地址
4440687904
>>> tup = (1,2,3)
>>> id(tup)
4441088800 # 内存地址不一样了
不可变并不是坏事,比如我们把数据传给一个不了解的API时,可以确保我们的数据不会被修改。同样地,如果我们操作一个从函数返回的元组,可以通过内建List()函数把它转换成一个列表。
Python字典
字典是另一种可变容器模型,且可存储任意类型对象
字典的每个键值(key=> value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号中({}),格式如下所示:
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
访问字典里的值
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
# Example1
youmen = {'name':'tom','code':6379,'youmen':'flying'}
print(youmen['name'])
print(youmen['code'])
tom
6379
# Example2
dict = {'Alice': '1234','youmen':'22','Cecil':'3258'}
print("dict[Alice]",dict['Alice'])
print('dict[youmen]',dict['youmen'])
dict[Alice] 1234
dict[youmen] 22
修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Alice': '1234','youmen':'22','Cecil':'3258'}
dict['Alice'] = 1
dict['youmen'] = 22
print(dict['Alice'])
print(dict['youmen'])
# 以下为实例输出结果
1
22
删除字典元素
能删单一的元素也能清空字典,清空只需一项操作
显示删除一个字典用del命令,如下实例:
dict = {'Alice': '1234','youmen':'22','Cecil':'3258'}
del dict['Alice']
dict.clear()
del dict
print(dict['Alice'])
# 此时运行以上实例会报错,引发一个异常,因为用执行del操作后字典不再存在:
字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Alice': '1234','youmen':'22','Cecil':'3258','Alice':'小菜鸟'}
print("dict['Alice']:",dict['Alice'])
# 以上实例输出结果为
小菜鸟
2) 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
dict = {[Alice]: '1234','youmen':'22','Cecil':'3258','Alice':'小菜鸟'}
# 以上实例输出结果:
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Runoob', 'Age': 7}
TypeError: unhashable type: 'list'
字典内置函数&方法
Python包含了以下内置函数:
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> len(dict) 3 |
| 2 | str(dict) 输出字典,以可打印的字符串表示。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> str(dict) "{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> type(dict) <class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | radiansdict.clear() 删除字典内所有元素 |
| 2 | radiansdict.copy()返回一个字典的浅复制 |
| 3 | radiansdict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | radiansdict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | radiansdict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | radiansdict.keys() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 8 | radiansdict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | radiansdict.values() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的最后一对键和值。 |
Python3集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
basket = {'apple','orange','apple','pear','orange','banana'}
print(basket)
print('apple' in basket)
# 以上实例输出结果为
{'apple', 'banana', 'orange', 'pear'}
True
# 下面展示两个集合间的运算
a = set('admin')
b = set('youmen')
print(a - b)
print(a ^ b)
print(a | b)
print(a & b)
# 下面为实例的输出结果
{'i', 'd', 'a'} # 集合a中包含b中不包含的元素
{'u', 'd', 'i', 'y', 'a', 'e', 'o'}
{'a', 'u', 'e', 'o', 'n', 'm', 'i', 'd', 'y'} # 集合a和b都包含了的元素
{'n', 'm'} # 集合a和b中都包含了的元素.
添加元素
将元素x添加到a集合中
thisset = set(('admin','Google','Taobao'))
thisset.add('youmen')
print(thisset)
thisset.update('flying')
print(thisset)
# 以上实例输出结果
{'Taobao', 'Google', 'youmen', 'admin'}
{'admin', 'n', 'Taobao', 'y', 'f', 'Google', 'l', 'youmen', 'g', 'i'}
移除元素
将元素x从集合a中移出去,如果不存在就会报错
thisset = set(('admin','Google','Taobao'))
thisset.remove("Taobao")
print(thisset)
# 以上实例输出结果
{'admin', 'Google'}
计算集合元素个数和清空集合
# 计算集合元素个数
thisset = set(('admin','Google','Taobao'))
print(len(thisset))
3
# 清空集合
thisset.clear()
print(thisset)
set()
# 判断元素是否在集合中存在
x in thisset
thisset = set(('admin','Google','Taobao'))
print('admin' in thisset)
True
集合也支持推导式
>>> a = {x for x in 'YouMen' if x not in 'o'}
>>> a
{'e', 'u', 'Y', 'n', 'M'}
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
遍历技巧
在字典中遍历时,关键字和对应的值可以使用items()方法同时解读出来:
>>> dict = {'nginx':80,'tomcat':8080,'Mysql':3306}
>>> for i,k in dict.items():
... print(i,k)
...
nginx 80
tomcat 8080
Mysql 3306
# 遍历序列可以使用enumerate()函数
>>> for i ,v in enumerate(['tic','tac','toe']):
... print(i,v)
...
0 tic
1 tac
2 toe
# 如果要反向遍历一个序列,首先指定这个序列,然后调用reversed()函数:
>>> for i in reversed(range(1,10,2)):
... print(i)
...
9
7
5
3
1
# 按顺序遍历一个序列,使用sorted()函数返回一个已排序的序列,并不修改原值:
>>> dict = {'nginx':80,'tomcat':8080,'Mysql':3306,'Redis':6379,'NTP':123}
>>> dict
{'nginx': 80, 'tomcat': 8080, 'Mysql': 3306, 'Redis': 6379, 'NTP': 123}
>>> for i in sorted(set(dict)):
... print(i)
...
Mysql
NTP
Redis
nginx
tomcat
Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值.
| col1 | col2 |
|---|---|
| 函数 | 描述 |
| [int(x [,base])] | 将x转换为一个整数 |
| [long(x [,base] )] | 将x转换为一个长整数 |
| [float(x)] | 将x转换到一个浮点数 |
| [complex(real [,imag])] | 创建一个复数 |
| [str(x)] | 将对象 x 转换为字符串 |
| [repr(x)] | 将对象 x 转换为表达式字符串 |
| [eval(str)] | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| [tuple(s)] | 将序列 s 转换为一个元组 |
| [list(s) | 将序列 s 转换为一个列表 |
| [set(s)] | 转换为可变集合 |
| [dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| [frozenset(s)] | 转换为不可变集合 |
| [chr(x)] | 将一个整数转换为一个字符 |
| [unichr(x)] | 将一个整数转换为Unicode字符 |
| [ord(x)] | 将一个字符转换为它的整数值 |
| [hex(x) | 将一个整数转换为一个十六进制字符串 |
| [oct(x)] | 将一个整数转换为一个八进制字符串 |
内存管理
* 变量无须事先声明,也不需要指定类型
* 动态语言的特性
* 编程中一般无须关心变量的存亡,也不用关心内存的管理
* Python使用引用计数记录所有变量的引用数.(引用计数器,垃圾回收机制)
* 当变量引用数变为0,他就可以被垃圾回收GC
* 计数增加: 赋值给其他变量就增加引用计数,例如x=3,y=x
* 计数减少:
* 函数运行结束时,局部变量会被自动销毁,对象引用计数减少
* 变量被赋值给其他对象,例如x=3;y=x;x=4
* 有关性能的问题,需要考虑变量的引用问题,但是该释放内存,还是尽量不释放内存,看需求.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号