02 . Elasticsearch集群搭建

Elasticsearch发展历史
从开源到上市

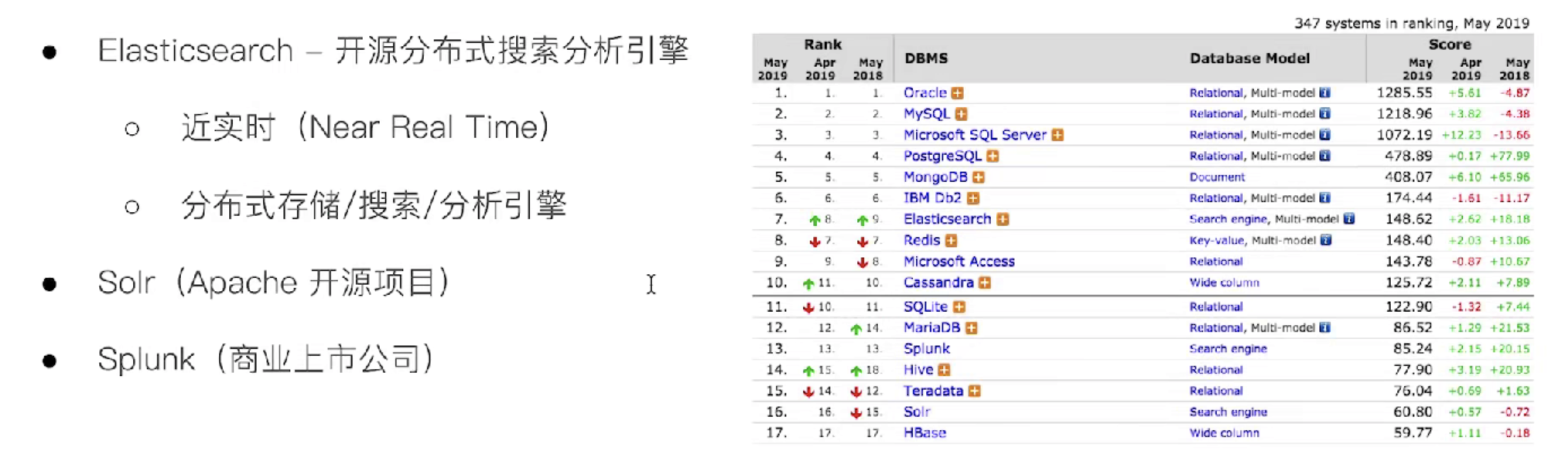
同类型产品
起源

Elasticsearch诞生

Elasticsearch分布式架构

Elasticsearch支持多种接入方式

Elasticsearch主要功能
市场反应

Elasticsearch5.x新特性

Elasticsearch6.x新特性

Elasticsearch7.x新特性

Elasticsearch家族成员
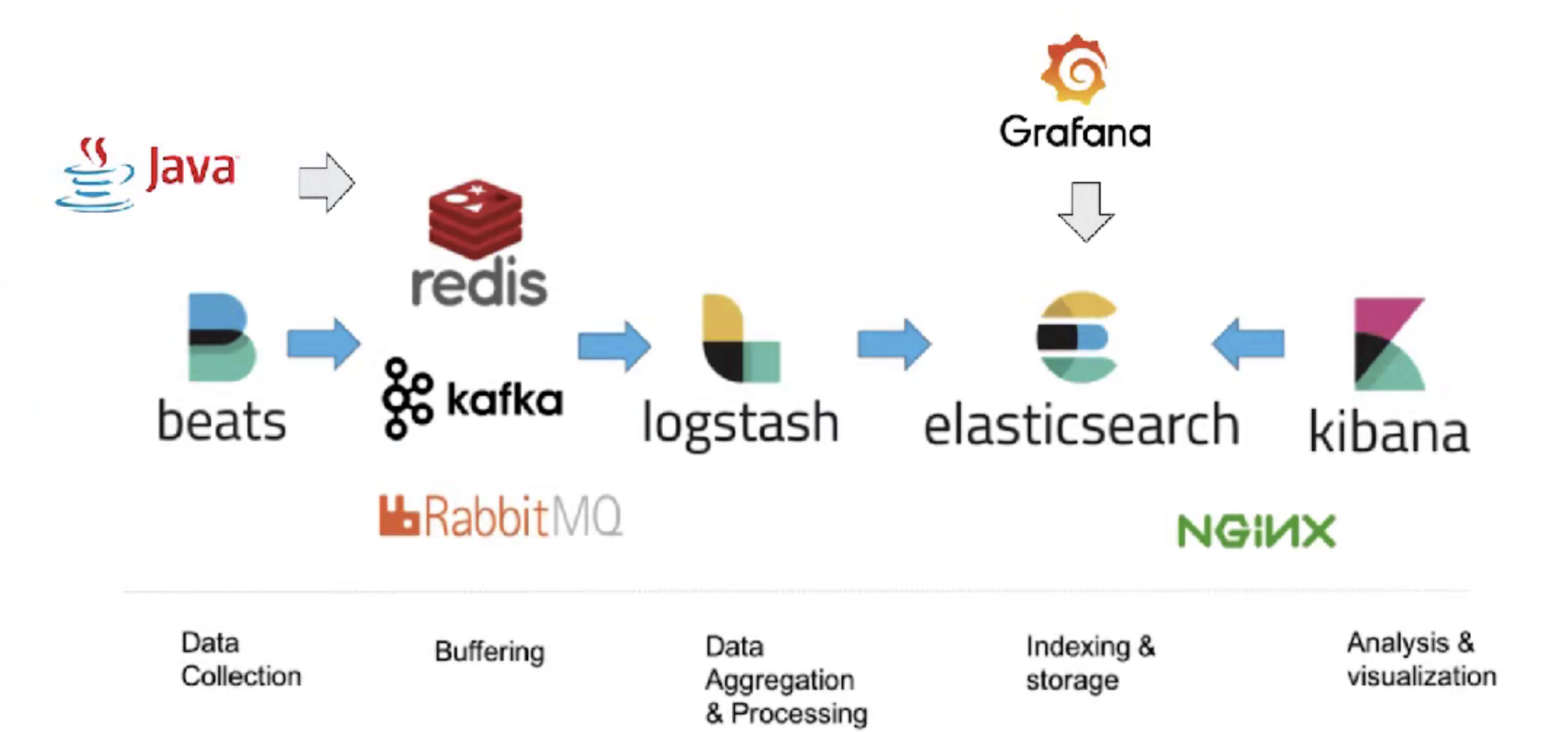
Elastic Stack生态圈

Logstash:数据处理管道

主要特性
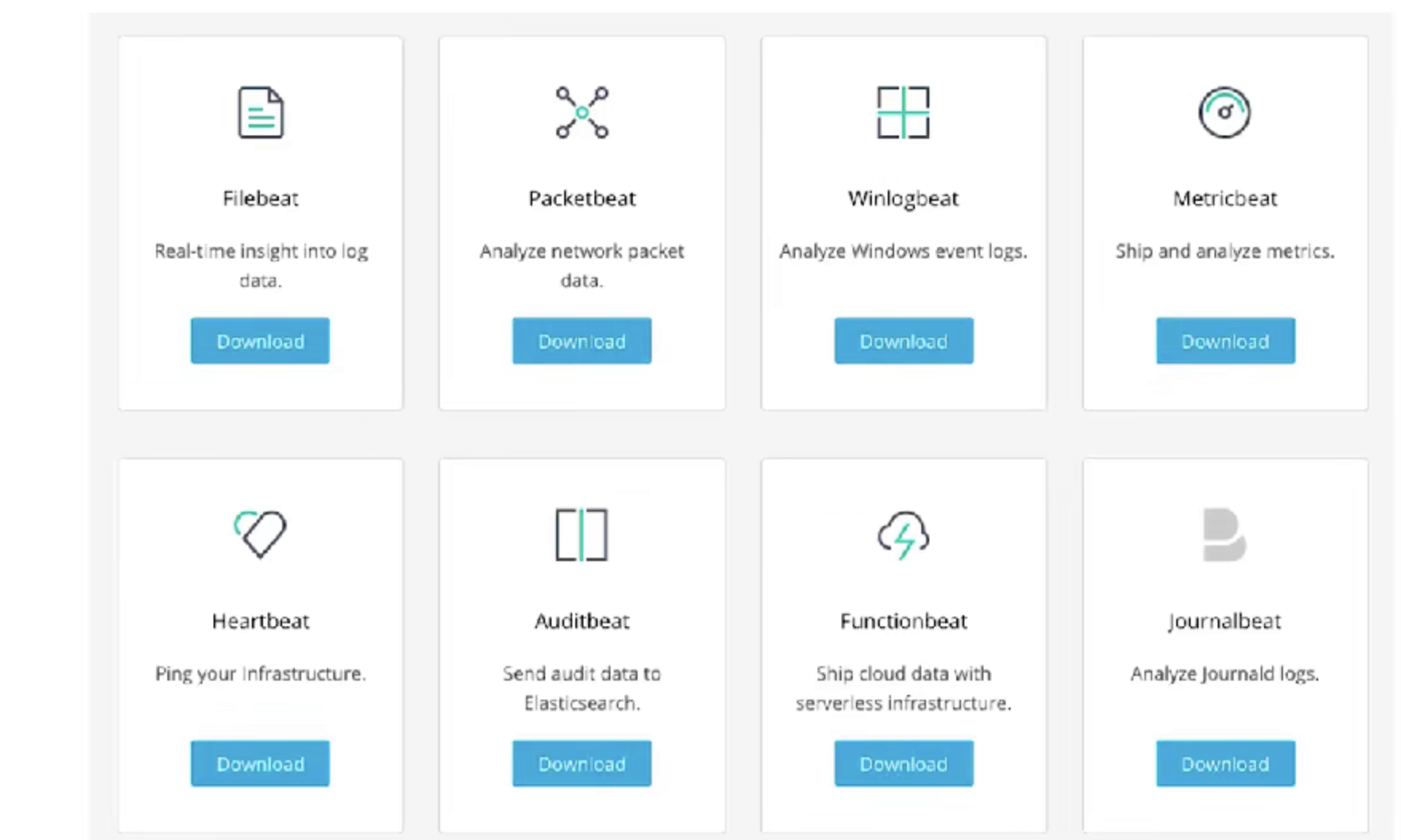
Beats
ELK用户及应用场景

Elasticsearch与数据库的集成

日志分析/指标分析
ES概念简介
Elasticsearch是一个高度可扩展RESTful风格的开源全文搜索和分析引擎,基于JAVA语言编写,它内部使用的是Apache Lucene做索引功能。
Apache Lucene是一款高性能的、可扩展的信息检索工具库,提供索引功能的信息检索工具库。同样由Java语言开发、自由开源的搜索类库,基于Apache协议授权。Lucene只是一个软件类库,如果要发挥Lucene的功能,还需要开发一个调用Lucene类库的应用程序。但是Apache Lucene已被集成在Elasticsearch当中,所以我们并不需要去单独配置Apache Lucene
Cluster 集群
一个 Elasticsearch 集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识
Node节点
一个 Elasticsearch 实例即一个 Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同的机器上。 Elasticsearch 的配置文件中可以通过 node.master、 node.data 来设置节点类型
node.master:表示节点是否具有成为主节点的资格
# true代表的是有资格竞选主节点
# false代表的是没有资格竞选主节点
node.data:表示节点是否存储数据
# true代表存储数据
# false代表不存储数据
Node节点组合
主节点+数据节点(master+data)
# 节点即有成为主节点的资格,又存储数据
node.master: true
node.data: true
数据节点(data)
# 节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
客户端节点(client)
# 不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
node.master: false
node.data: false
分片
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片( primary shard)和复制分(replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复制分片,一个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个节点上.
环境及软件
List:
CentOS7.3.1611
elasticsearch-7.2.0-linux-x86_64.tar.gz
jdk-8u121-linux-x64.rpm
cerebro-0.8.3.tgz
# 因为ES7已经内置了所需的java的JDK版本,因此在此不再介绍java安装
# ES7安装方式使用RPM安装方式。
# 架构设计
# ES-Master: 我们设定192.168.0.117为Master节点
# ES-Data: 我们设定192.168.0.115和192.168.0.108专门存储数据节点
ES节点列表
| IP | 节点名 |
|---|---|
| 192.168.43.176 | node-a |
| 192.168.43.164 | node-b |
| 192.168.43.215 | node-c |
准备系统环境
init_security() {
systemctl stop firewalld
systemctl disable firewalld &>/dev/null
setenforce 0
sed -i '/^SELINUX=/ s/enforcing/disabled/' /etc/selinux/config
sed -i '/^GSSAPIAu/ s/yes/no/' /etc/ssh/sshd_config
sed -i '/^#UseDNS/ {s/^#//;s/yes/no/}' /etc/ssh/sshd_config
systemctl enable sshd crond &> /dev/null
rpm -e postfix --nodeps
echo -e "\033[32m [安全配置] ==> OK \033[0m"
}
init_security
init_yumsource() {
if [ ! -d /etc/yum.repos.d/backup ];then
mkdir /etc/yum.repos.d/backup
fi
mv /etc/yum.repos.d/* /etc/yum.repos.d/backup 2>/dev/null
if ! ping -c2 www.baidu.com &>/dev/null
then
echo "您无法上外网,不能配置yum源"
exit
fi
curl -o /etc/yum.repos.d/163.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo &>/dev/null
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo &>/dev/null
yum clean all
timedatectl set-timezone Asia/Shanghai
echo "nameserver 114.114.114.114" > /etc/resolv.conf
echo "nameserver 8.8.8.8" >> /etc/resolv.conf
chattr +i /etc/resolv.conf
echo -e "\033[32m [YUM Source] ==> OK \033[0m"
}
init_yumsource
安装ES7.2.0
Create_UserLogFile()
{
groupadd es
useradd es -g es
mkdir -pv /data/elk/{data,logs}
chown -R es:es /data/
}
Unpackaged_Authorization()
{
yum -y install ntpdate
rpm -ivh /root/InstallELKB-Shell/jdk-8u121-linux-x64.rpm
tar xvf /root/InstallELKB-Shell/elasticsearch-7.2.0-linux-x86_64.tar.gz -C /opt/
chown -R es:es /opt/elasticsearch-7.2.0/
ntpdate -b ntp1.aliyun.com
}
Set_System_Parameter()
{
cat >> /etc/security/limits.conf <<EOF
* soft nproc 2048
* hard nproc 4096
* soft nofile 65536
* hard nofile 131072
EOF
echo "vm.max_map_count = 262144" >> /etc/sysctl.conf && sysctl -p
cat >> /etc/profile <<EOF
export HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S "
EOF
source /etc/profile
cat >> /opt/elasticsearch-7.2.0/config/elasticsearch.yml <<EOF
cluster.name: elasticsearch
node.name: node-a
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
network.publish_host: 192.168.43.176
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.43.176:9300","192.168.43.164:9300","192.168.43.215:9300"]
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
path.data: /home/es/data
path.logs: /home/es/logs
EOF
nohup runuser -l es -c '/bin/bash /opt/elasticsearch-7.2.0/bin/elasticsearch ' &> /opt/elasticsearch.log &
}
Test_Service()
{
esport=`ss -antp |grep :::9200 | awk -F::: '{print $2}'`
if [ $esport -eq 9200 ];then
echo -e "\033[32m Elasticsearch is OK... \033[0m "
fi
}
main() {
Create_UserLogFile
Unpackaged_Authorization
Set_System_Parameter
Test_Service
}
main
# 其他两个data节点配置文件有点不一样需要注意
# node-b
cluster.name: elasticsearch
node.name: node-b
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
network.publish_host: 192.168.43.164
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.43.176:9300","192.168.43.164:9300","192.168.43.215:9300"]
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
path.data: /home/es/data
path.logs: /home/es/logs
# es-node-data-02
cluster.name: elasticsearch
node.name: node-c
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
network.publish_host: 192.168.43.215
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.43.176:9300","192.168.43.164:9300","192.168.43.215:9300"]
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
path.data: /home/es/data
path.logs: /home/es/logs
# 网络绑定,支持外网访问
network.host: 0.0.0.0
http.port: 9200
# 集群发现
discovery.seed_hosts: ["es-node-master-01","es-node-data-01","es-node-data-02"]
# 两个节点分别启动
nohup runuser -l es -c '/bin/bash /opt/elasticsearch-7.2.0/bin/elasticsearch ' &> /opt/elasticsearch.log &
Elasticsearch文件目录结构
| 目录 | 配置文件 | 描述 |
|---|---|---|
| bin | 脚本文件,包括启动elasticsearch,安装插件,运行统计数据等 | |
| config | Elasticsearch.yml | 集群配置文件,user,role based相关配置 |
| JDK | JAVA运行环境 | |
| data | Path.data | 数据文件 |
| lib | Java类库 | |
| logs | path.log | 日志文件 |
| modules | 包含所有ES模块 | |
| plugins | 包含所有已安装插件 |
ES配置文件解读
# ES通过集群名称区分集群,因此集群内所有节点的节点名称必须保持一致。如:
cluster.name: es-cluster
# 集群内节点的名称,同一集群内的节点名称必须保持唯一。如:
node.name: node01
# 机架感知
node.attr.rack: r1
# 标记节点可以选举为master节点。如果集群内的master节点停止,则该节点就会参与选举,可以成为master节点。如:
node.master: true
# 允许该节点存储索引数据(默认).如:
node.data: true
# 此路径是存放es数据的目录,可以任意指定。如果是生产环境建议设置的路径有足够的存储空间,如:
path.data: /datadrive/elasticsearch/data
# 此路径存储es产生的日志,生产环境建议与`path.logs`分开设置。如:
path.data: /datadrive/elasticsearch/logs
node.name: node-3
# 当前节点是否可以被选举为master节点,是:true、否:false
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
bootstrap.memory_lock: true
# 在ES运行起来后锁定ES所能使用的堆内存大小,锁定内存大小一般为可用内存的一半左右;锁定内存后就不会使用交换分区
# 如果不打开此项,当系统物理内存空间不足,ES将使用交换分区,ES如果使用交换分区,那么ES的性能将会变得很差
network.tcp.no_delay: true
# 是否启用tcp无延迟,true为启用tcp不延迟,默认为false启用tcp延迟
transport.tcp.port: 9301
#设置集群节点通信的TCP端口,默认就是9300
transport.tcp.compress: true
#设置是否压缩TCP传输时的数据,默认为false
http.max_content_length: 200mb
#设置http请求内容的最大容量,默认是100mb
http.cors.enabled: true
#是否开启跨域访问
http.cors.allow-origin: "*"
#开启跨域访问后的地址限制,*表示无限制
# SecComp检测,是:true、否:false
bootstrap.system_call_filter: false
# es绑定的地址,支持IPv4和IPv6。是es的监听地址。如果设置具体的地址,则只能通过改地址访问,也可设置`0.0.0.0`则不限制访问地址.如:
network.host: 0.0.0.0
# 外部访问es的http端口,默认`9200`。如:
http.port: 9200
# 集群节点通讯的tcp的端口,默认`9300`。如:
transport.tcp.port: 9300
# 集群搜索的主机列表。由discovery.zen.ping.unicast.hosts:参数改变而来。如:
discovery.seed_hosts: ["192.168.0.117:9300","192.168.0.115:9300","192.168.0.108:9300"]
# 集群主节点初始化列表,master选举列表。
cluster.initial_master_nodes: ["192.168.0.117:9300","192.168.0.115:9300","192.168.0.108:9300"]
| 参数 | 说明 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置 |
| path.logs | 日志文件存放的位置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| bootstrap.system_call_filter | SecComp检测,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| network.publish_host | 可设置成内网ip,用于集群内各机器间通信 |
| http.port | es对外提供的http端口,默认 9200 |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin | "*" 表示支持所有域名 |
jvm.options配置文件解读
grep -Ev "#|^$"/opt/elasticsearch-7.2.0/config/jvm.options | head -5
#堆内存配置
-Xms16g #Xms表示ES堆内存初始大小
-Xmx16g #Xmx表示ES堆内存的最大可用空间
#GC配置
-XX:+UseConcMarkSweepGC #使用CMS内存收集
-XX:CMSInitiatingOccupancyFraction=75 #使用CMS作为垃圾回收使用,75%后开始CMS收集
-XX:+UseCMSInitiatingOccupancyOnly #使用手动定义初始化开始CMS收集
JVM配置
修改JVM-config/jvm.options
# 7.1下载的默认配置1GB
# Xms和Xms设置成一样
# Xms不要超过机器内存的50%.
# 不要超过30GB, 请看https://www.elastic.co/cn/blog/a-heap-of-trouble
配置ES的Head插件
tar -xvf node-v10.6.0-linux-x64.tar.xz
# 重命名文件夹
mv node-v10.6.0-linux-x64 nodejs
# 通过建立软连接变为全局
ln -s /usr/local/nodejs/bin/npm /usr/bin/
ln -s /usr/local/nodejs/bin/node /usr/bin/
node -v
# v8.16.0
cd /opt/elasticsearch-7.2.0/elasticsearch-head-master/
npm install^C
npm run start
lsof -i:9100
# COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
# grunt 14567 root 12u IPv4 41662 0t0 TCP *:jetdirect (LISTEN)
es2020
ES常规操作
# 所有节点都启动后可以访问任一节点查看集群状态,可以通过浏览器或curl节点地址。如:
curl -XGET 'http://127.0.0.1:9200/_cluster/state?pretty'
curl http://127.0.0.1:9200/_cat/nodes?v
# ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
# 192.168.43.215 10 96 1 0.17 0.13 0.13 mdi - node-c
# 192.168.43.164 10 77 0 0.00 0.01 0.05 mdi * node-b
# 192.168.43.176 6 94 0 0.00 0.01 0.05 mdi - node-a
# 查看节点
curl http://127.0.0.1:9200/_cat/nodes?v #?v人性化显示,*表示主节点
# 查看整个集群索引
curl http://127.0.0.1:9200/_cat/indices
# 查看集群状态
curl http://127.0.0.1:9200/_cat/health
# 查看集群有多少个插件
curl http://127.0.0.1:9200/_cat/plugins
# 查看集群有多少个线程池
curl http://127.0.0.1:9200/_cat/thread_pool
ES索引操作
创建文档,生成索引
curl -H "Content-Type:application/json" -XPUT 'http://127.0.0.1:9200/index_name/type_name/1?pretty' -d '
{ "name": "xuwl", "age": 18, "job": "Linux" }'
# 命令介绍:
# -H:指定内容类型
# -X:指定http请求方式,这里为PUT上传方式
# http://10.211.55.10:9201:指定一台es服务器对外的http端口
# /index_name:文档的索引名称,必须小写
# /type_name:文档的类型名称,必须小写
# /1:文档的ID编号
# ?pretty:人性化创建索引
# -d:指定使用JSON方式来撰写上传文档
# { "name": "xuwl", "age": 18, "job": "Linux" }':使用JSON格式来撰写上传文档内容
创建索引为index_name文档
curl -H "Content-Type:application/json" -XPOST 'http://127.0.0.1:9200/index_name/index_type/1?pretty' -d '{"name":"es-cluster","type": "data_index"}'
{
"_index" : "index_name",
"_type" : "index_type",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
查看索引
curl -XGET "http://127.0.0.1:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open index_name irYekUV4S12knIDbE85WUA 1 1 1 0 8.1kb 4kb
查看分片
curl -XGET "http://127.0.0.1:9200/_cat/shards?v"
index shard prirep state docs store ip node
index_name 0 p STARTED 1 4kb 192.168.0.119 es1
index_name 0 r STARTED 1 4.1kb 192.168.0.101 192.168.0.101
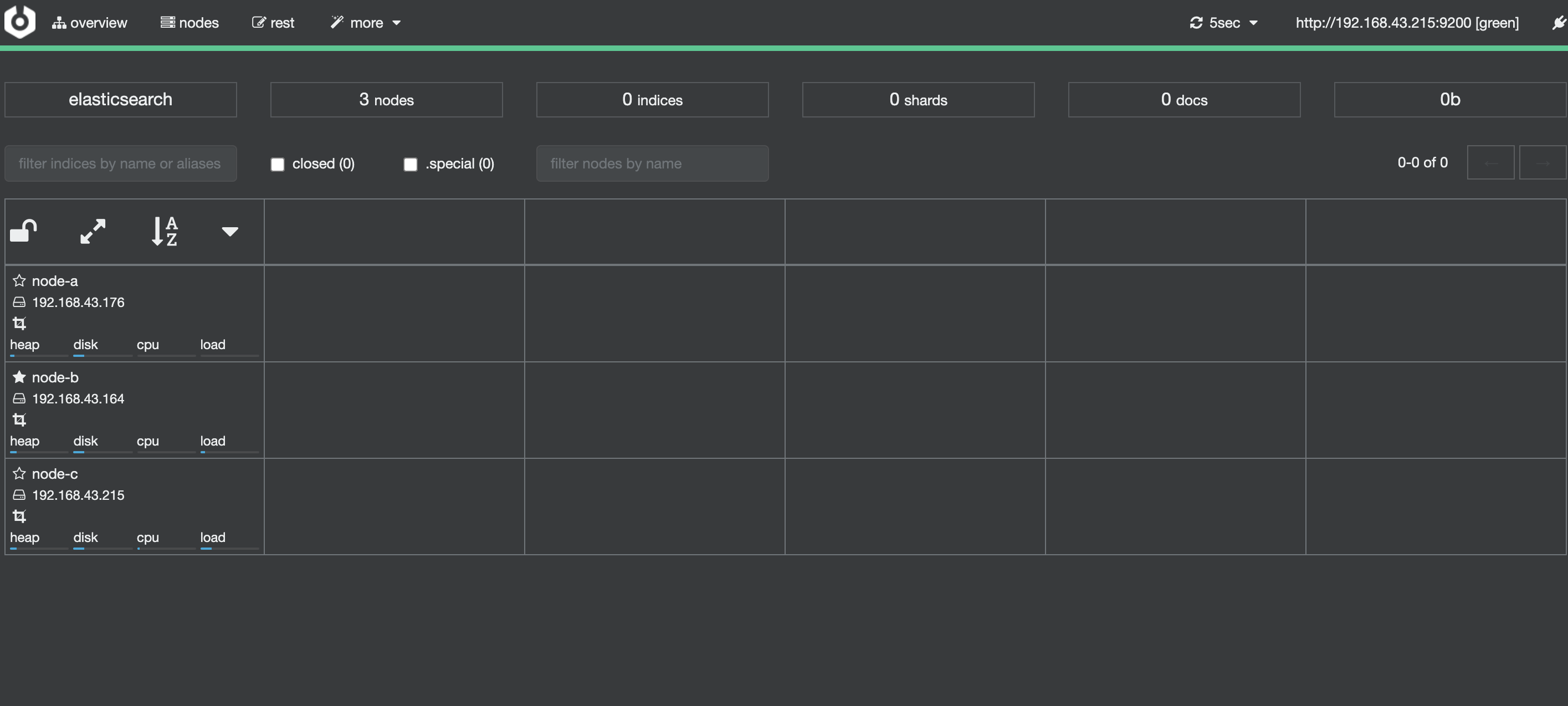
安装Elasticsearch的cerebro插件
cerebro简介
tar xvf cerebro-0.8.3.tgz -C /opt/
cat << EOF >> /opt/cerebro-0.8.3/conf/application.conf
hosts = [
{
host = "http://192.168.0.119:9200"
name = "ES-Cluster"
},
]
EOF
nohup /opt/cerebro-0.8.3/bin/cerebro -Dhttp.port=1234
# cerebro访问测试
# 浏览器输入http://IP:1234



 浙公网安备 33010602011771号
浙公网安备 33010602011771号