

[大数据面试题]storm核心知识点
1.storm基本架构
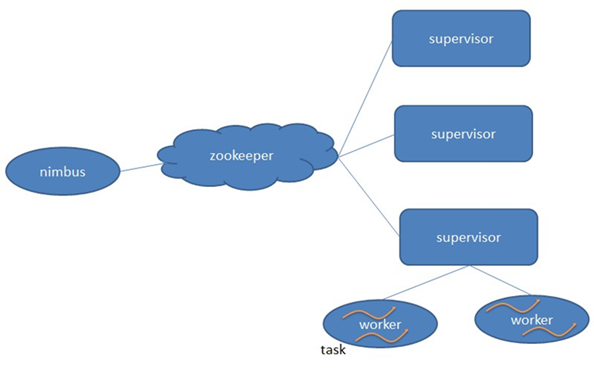
storm的主从分别为Nimbus、Supervisor,工作进程为Worker.

2.计算模型
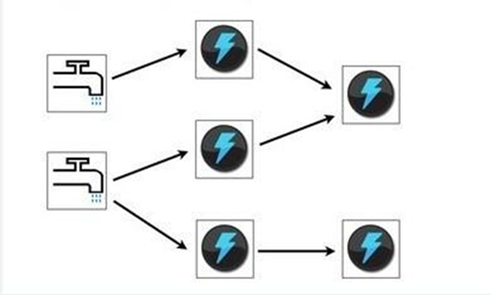
Storm的计算模型分为Spout和Bolt,Spout作为管口、Bolt作为中间节点,数据传输的单元为tuple,每个tuple都有一个值列表,
需要注意这个值列表是带name列表的,Bolt只需要订阅Bolt/Spout的值列表的某些name,就能获得该Bolt/Spout传过来的相应字段的数据。
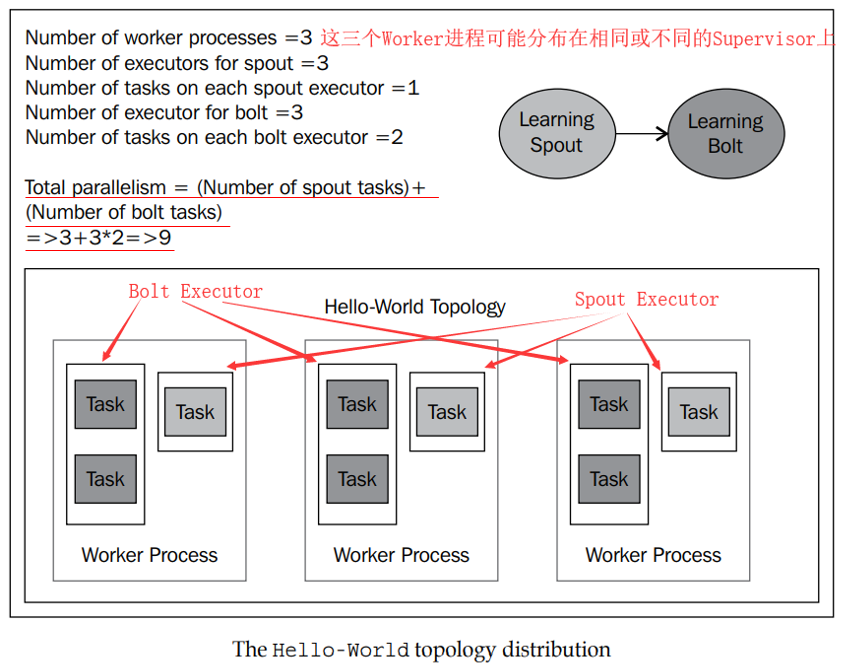
需要清楚并行度是怎么计算的,并行度其实就是Task的数目(也就是Bolt/Spout的具体实例数)。
总并行度 = Spout的executor线程数 * Spout的每个executor的task数目 + ABolt的executor线程数 * ABolt的每个executor的task的数目 + BBolt的executor线程数*BBolt的每个task的数目 + ....
3.流式计算框架对比
流计算框架按数据流的粒度不同分为两种:
1)原生的流处理,这种以消息/记录为传输处理单位进行挨个处理
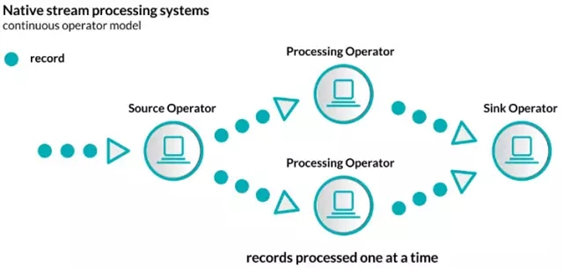
以消息/记录为单位进行处理 : Storm 、Samza 、Flink
2)微批处理,这种以一批消息/记录为单位进行小批次的批处理
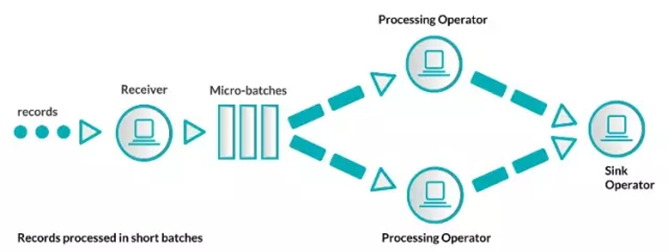
以小批次消息/记录为单位进行小批次批处理:Storm Trident 、Spark Streaming
使用这两种方式,导致本质上,原生的流处理比微批处理的方式延时更低一些。
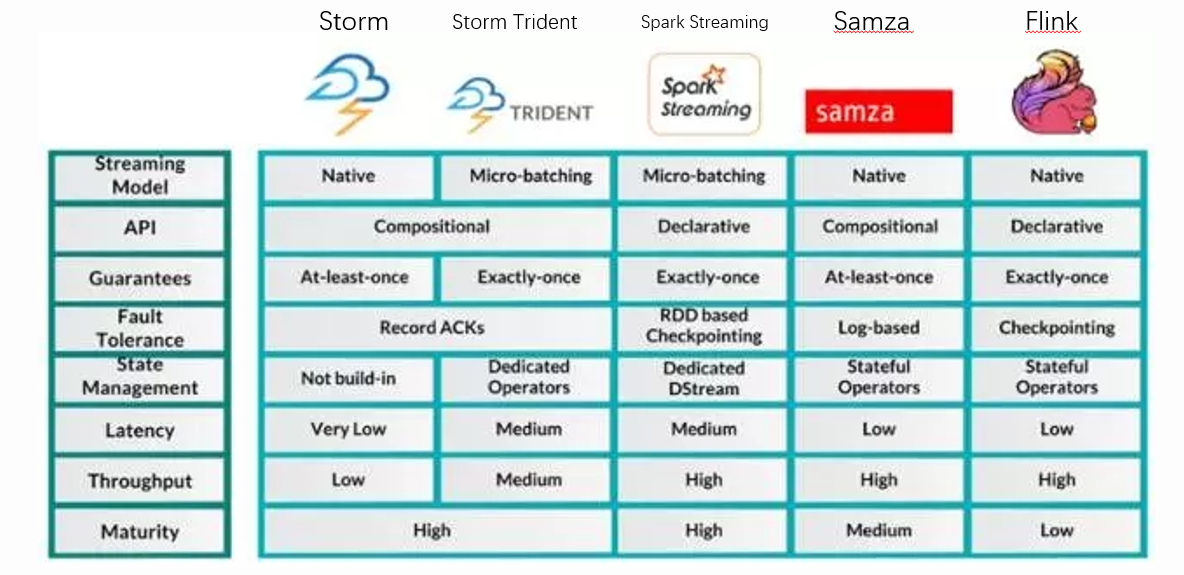
其中:
1)Storm、Samza、Flink因为其使用原生的流处理,因此Latency都很低。而使用微批处理的Storm Trident以及Spark Streaming延时不是很低。
2)关于数据传输可靠性,有“At-least-once"至少一次、”Exactly-once"精确一次、“At-most-once"至多一次三种语义。
可靠性排序: 精确一次 > 至少一次 -> 至多一次
3)对于流处理框架的选择,在不同的场景下会有不同
3.1 : 可靠性优先,必须保证“精确一次”: 这时,我们会从Storm Trident 、Spark Streming 以及 Flink当中选取,但是Storm Trident和Spark Streaming是微批处理的,所以延时相对原生批处理的Flink高。
而且Flink的吞吐量与Spark Streaming都是比较高的。因此采用Flink是可靠性优先的最优选择。
3.2 : 实时性优先,要求超低延时: 这时,我们只能选择Storm,Storm 底层采用ZeroMQ,处理速度是常见的MQ中最快的。但是这个选择一是状态管理需要自行完成,二是可靠性只能到“至少一次”级别,需要自己处理到“精确一次”,三是吞吐量很低。
4.常用的API

TODO
5.Grouping机制 - 分组策略
TODO
6.事务
TODO
7.DRPC
TODO
8.Trident
TODO
9.实际问题
1)pv计算,典型的聚合场景
Spout消费MQ中的数据并发送出去。
第一个Bolt进行分词和提取,判断每条数据记录,如果是访问记录,则emit出去1。
第二个Bolt进行局部的聚合,计算本地PV,并发送(thread_id,pv)标志线程级别的唯一性。
第三个Bolt进行全局聚合,计算总PV,这个全局聚合只能有一个,内部维护一个Hash<Long,Long>的数据结构(thread_id,pv),收到数据后实时更新,然后实时/每隔一段时间对pv进行求和。
2)UV计算,典型的去重聚合场景
常规思路:与之前PV计算类似
Spout消费MQ中的数据并发送出去。
第一个Bolt进行一些预处理,将(session_id,1)为单位发送出去。
第二个Bolt订阅第一个Bolt的数据,内部维护一个HashMap<String,Long>的结构存储局部的(session_id,count)信息。然后把(thread_id,hashmap)发送出去。
第三个Bolt进行全局聚合,计算总的UV,这个全局聚合只能有1个,内部维护一个HashMap<Long,HashMap<String,Long>>的结构存储(thread_id,hashmap(session_id,count)),
收到数据后实时进行更新,然后实时/每隔一段时间对UV进行session粒度的聚合。
特殊思路:我们可以想到在WordCount场景下不一定全局聚合只可以一个Bolt实例。完全可以通过hash(session_id)的方式,把相同的session_id控制在同一个的Bolt实例内。
Spout消费MQ中的数据并发送出去。
第一个Bolt进行一些预处理,将(hash_session_id,session_id,1)发射出去。
第二个Bolt注意要使用fieldsGrouping的方式,指定hash_session_id为grouping的依据字段,也就是说第一个Bolt发出的数据,只要hash_session_id相同,就会被发送到同一个Bolt实例。
第二个Bolt直接对session_id进行全局聚合,因为同一个session_id只会被发送到同一个Bolt实例,因此数据是准确的。内部直接维护一个HashMap<String,Long>的格式(session_id,count)。
这个Bolt实例可以有多个,将它们的数据分别持久化就可以了。

