

hadoop之数据压缩与数据格式
* 注:本文原创,转载请注明出处,本人保留对未注明出处行为的责任追究。
a.数据压缩
优点: 1.节省本地空间 2.节省带宽
缺点: 花时间
1.MR中允许进行数据压缩的地方有三个:
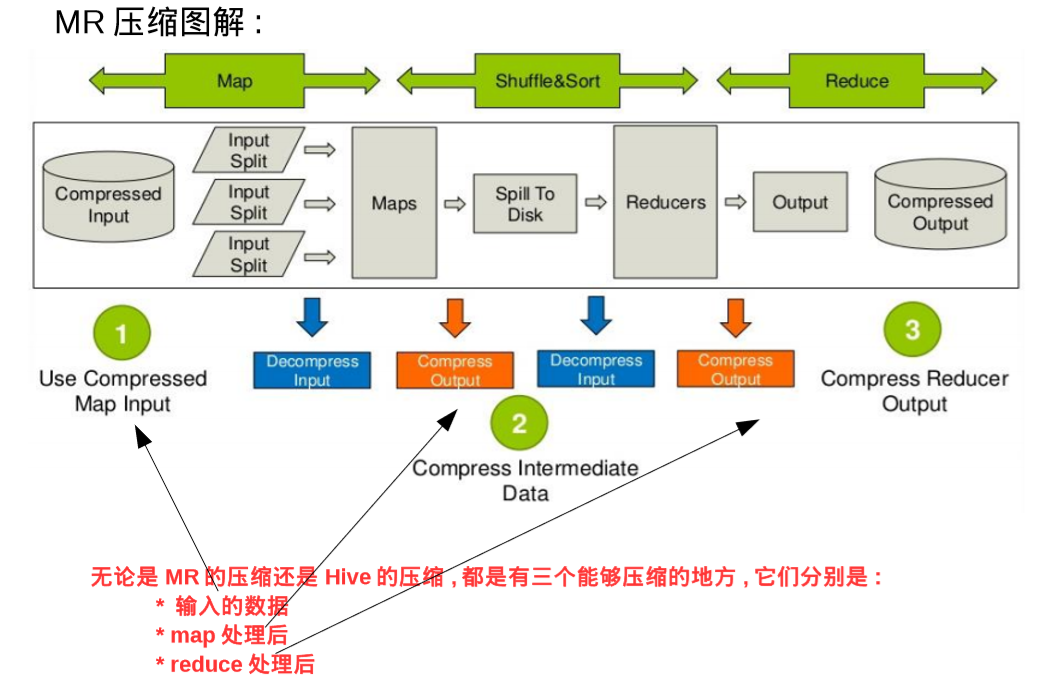
1)input起点 2)map处理之后 3)reduce处理之后进行存储
2.压缩格式
常见的压缩计数有bzip2、gzip、lzo、snappy.它们之间的性能比较如下:
压缩比 : bzip2>gzip>lzo = snappy ,bzip2最节省空间
解压速度 :lzo = snappy > gzip > bzip2 , lzo解压速度是最快的
另外Google研发的snappy的压缩格式,嵌入在hadoop中,因为其可靠性和性能的均衡性,非常受到大家欢迎。
snappy压缩格式的性能与lzo差不多,都是属于压缩解压块,但是压缩比高的类型。以下是它们的一些详细参数:
| 压缩比 | 压缩速率 | 解压速率 | |
| gzip/deflate | 13.4% | 21MB/s | 118MB/s |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s |
| lzo | 20.5% | 135MB/s | 410MB/s |
| snappy | 22.2% | 172MB/s | 409MB/s |
(本表数据来源于博客: https://blog.csdn.net/zhouyan8603/article/details/82954459 , 感谢玉羽凌风!)
3.mr中如何使用数据压缩?
刚才谈到了三个可以进行压缩的地方,这里分别说明:
1)输入时,hadoop依据文件格式进行自动识别并解压,这个是自动的,不需要关心太多
2)在map之后有一个可以压缩的点,需要配置以下两个参数进行压缩:
mapreduce.map.output.compress - false/true - 在 map处理后是否启用压缩
mapreduce.map.output.compress.codec – 选择编解码器
3)在reduce之后有一个可以压缩的点,需要配置以下三个参数进行压缩:
mapreduce.output.fileoutputformat.compress – false/true – 在 reduce后是否压缩
mapreduce.output.fileoutputformat.compress.codc – 选择编解码器
mapreduce.output.fileoutputformat.compress.type – RECORD/BLOCK/NONE 其中RECORD是针对记录的压缩,BLOCK是针对块的压缩
其中使用RECORD压缩率比较低,因此一般使用BLOCK。
**注:hadoop支持的编解码器 - 配置中需要用到:
Zlib → org.apache.hadoop.io.compress.Default.Codec
其中Zlib是MR使用的默认压缩格式,当指定上面的bool值为true且没有指定codec的情况下,默认使用这个Codec
Gzip → org.apache.hadoop.io.compress.GzipCodec
Bzip2 → org.apache.hadoop.io.compress.BZip2Codec
Lzo → com.hadoop.compression.lzo.LzoCodec
Lz4 → org.apache.hadoop.io.coompress.Lz4Codec
Snappy → org.apache.hadoop.io.compress.SnappyCodec
其他关于压缩问题的补充: https://www.cnblogs.com/ggjucheng/archive/2012/04/22/2465580.html
4.hive中如何使用数据压缩?

(注:本图引自北风网)
1)Input处的数据压缩,需要在创建表的时候指定
2)map之后的数据压缩需要设置三个参数:
hive.exec.compress.intermediate - true
mapred.map.output.compress.codec – 选择编解码器
mapred.map.output.compress.codec - RECORD/BLOCK
3)reduce之后的数据压缩需要设置三个参数:
hive.exec.compress.output - true
mapred.output.compression.codec - 编解压器
mapred.output.compression.type - RECORD/BLOCK
b.数据存储格式
在创建Hive表的时候,我们可以用STORED AS关键字来指定数据存储格式。
Hadoop支持的常见的存储格式有以下几种:

1.hadoop支持的文件存储格式,比较典型的有(需要记住):
* 按行存储
SEQUENCEFILE TEXTFILE
* 按列存储
RCFILE ORC PARQUET
2.行式存储与列式存储的比较
1)列式存储每一列单独摘出来存放,行式存储按行存放。
这就导致行式存储进行查询时,需要把每一行完整的读进去。而列式存储只需要找到指定的几行,读这几行就可以。
2)因此列式存储不适用于更新多,整表查询的场景,适用于只查询不更新,并且查询主要集中于某几列的场景。因此其常用于OLAP业务。
行式存储在只查询几列数据的时候,性能不如列式 存储。但是它灵活可以变动,适用于修改、实时交互的场景。因此常用于OLTP业务。
* 注意:HBase 的“列式数据库”是指数据的逻辑模型是支持列可扩展的,而实际的存储模型是JSON实现的行式存储。
企业里用的比较多的列式压缩式ORC以及Apache的Parquet.

(来源:https://hortonworks.com/blog/orcfile-in-hdp-2-better-compression-better-performance/)
在上图中,我们可以看到不同存储格式,占用的存储空间不同。
3.ORCFile的存储格式
感谢 https://www.cnblogs.com/ITtangtang/p/7677912.html !
4.Parquet存储格式
TODO

