SQL优化案例分享
使用with表视图对SQL进行优化
问题重现:
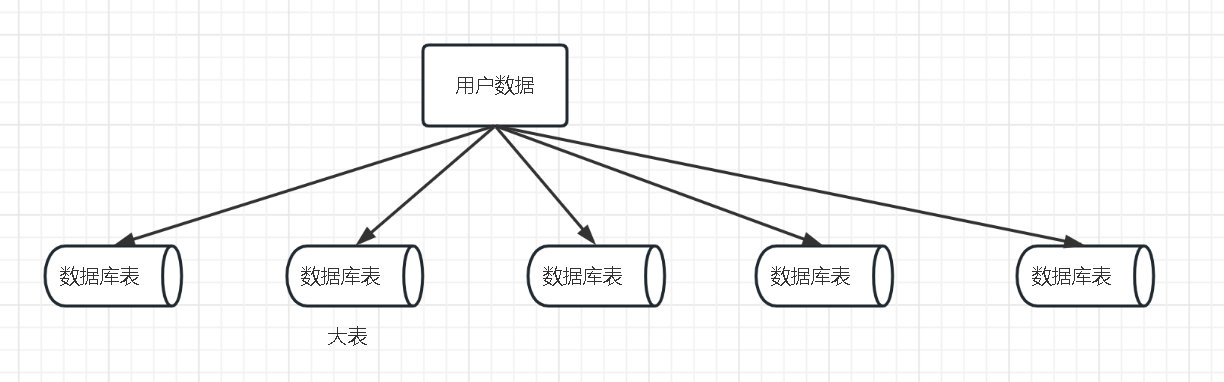
用户数据落库到多个子表
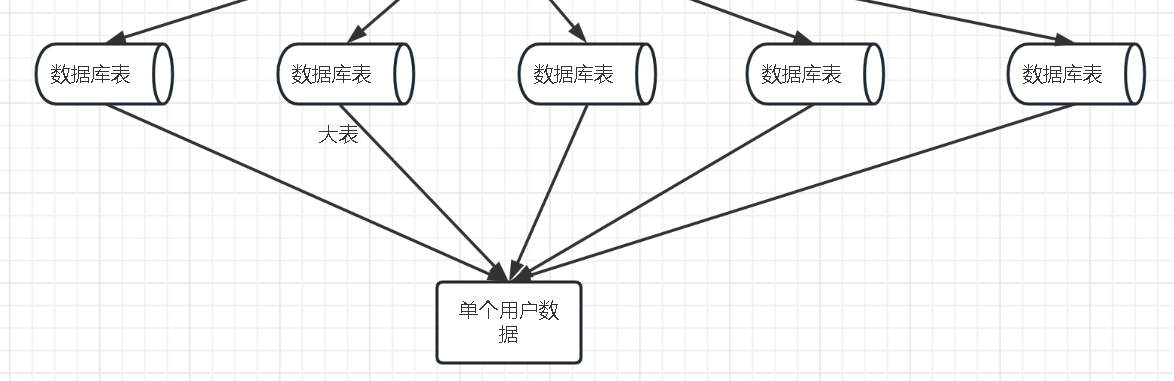
从多个子表加工单个用户数据到一起
问题解释:
oracle中有一个大sql,逻辑如上图,查询需要5分钟以上。
优化的第一步是解释SQL语句,查询中有全表扫描的问题,根据全表扫描的表,再查看这些表的数据量,有超过千万的级别。有表的join和分组取极值的复杂操作,从解释语句中不好分辨处理速度。
问题分析:
当时想了几个方案,但是也有对应问题。
1.对全表扫描的表加对应主键:由于表数量比较多,占用空间大,加索引对数据库的空间损坏比较大。
2.归档数据,从数据量的角度考虑问题,因为表的数据量已经是千万级别,归档数据如果下降到一半的情况
数据查询速度肯定会提升:指标不治本,后续查询还是会慢慢变慢,而且提升不大。
最终方案:
因为从业务角度看,这个sql加工数据逻辑其实就涉及单个用户数据,和其他很多数据没有直接关联。当时就想,如果单独把这些数据拿出来处理,那么就可以解决该问题。sql确实提供了这样的功能,使用with语句创建视图,用这些视图替代后面的表,比如
with
table_view as (select * from table t where t.query_id='2f11f5e9a5d04a26a0ab3eefc2901111')
使用这个处理有个前提,数据都是可以通过主键或者索引query_id把单个用户数据提取出来。
结果:
从原先的5分钟,变成了后面的几秒钟,效率大大提升。
