文本处理工具
文本编辑工具之神-VIM
vi/vim 的使用
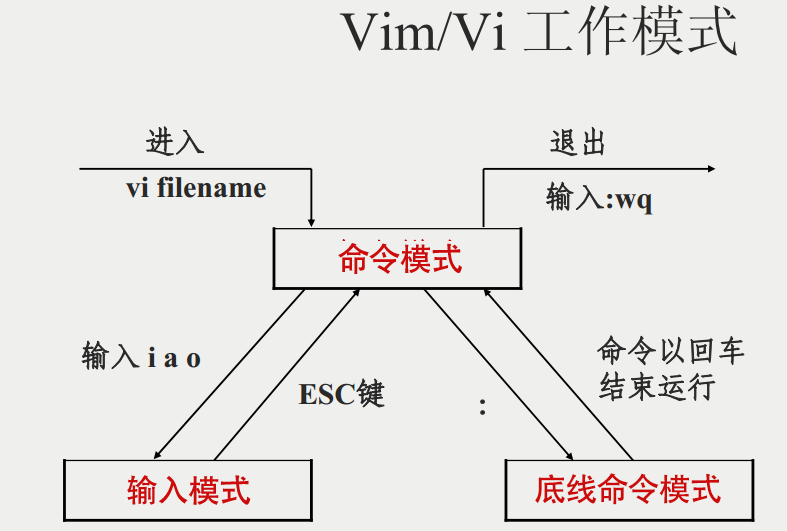
基本上 vi/vim 共分为三种模式,命令模式(Command Mode)、输入模式(Insert Mode)和命令行模式(Command-Line Mode)。
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被 Vim 识别为命令,而非输入字符,比如我们此时按下 i,并不会输入一个字符,i 被当作了一个命令。
以下是普通模式常用的几个命令:
- i -- 切换到输入模式,在光标当前位置开始输入文本。
- x -- 删除当前光标所在处的字符。
- : -- 切换到底线命令模式,以在最底一行输入命令。
- a -- 进入插入模式,在光标下一个位置开始输入文本。
- o:在当前行的下方插入一个新行,并进入插入模式。
- O -- 在当前行的上方插入一个新行,并进入插入模式。
- dd -- 剪切当前行。
- yy -- 复制当前行。
- p(小写) -- 粘贴剪贴板内容到光标下方。
- P(大写)-- 粘贴剪贴板内容到光标上方。
- u -- 撤销上一次操作。
- Ctrl + r -- 重做上一次撤销的操作。
- :w -- 保存文件。
- :q -- 退出 Vim 编辑器。
- :q! -- 强制退出Vim 编辑器,不保存修改。
若想要编辑文本,只需要启动 Vim,进入了命令模式,按下 i 切换到输入模式即可。
命令模式只有一些最基本的命令,因此仍要依靠底线命令行模式输入更多命令。
输入模式
在命令模式下按下 i 就进入了输入模式,使用 Esc 键可以返回到普通模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底线命令模式
在命令模式下按下 :(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
- :w:保存文件。
- :q:退出 Vim 编辑器。
- :wq:保存文件并退出 Vim 编辑器。
- :q!:强制退出Vim编辑器,不保存修改。
按 ESC 键可随时退出底线命令模式。
简单的说,我们可以将这三个模式想成底下的图标来表示:
vi/vim 使用实例
使用 vi/vim 进入一般模式
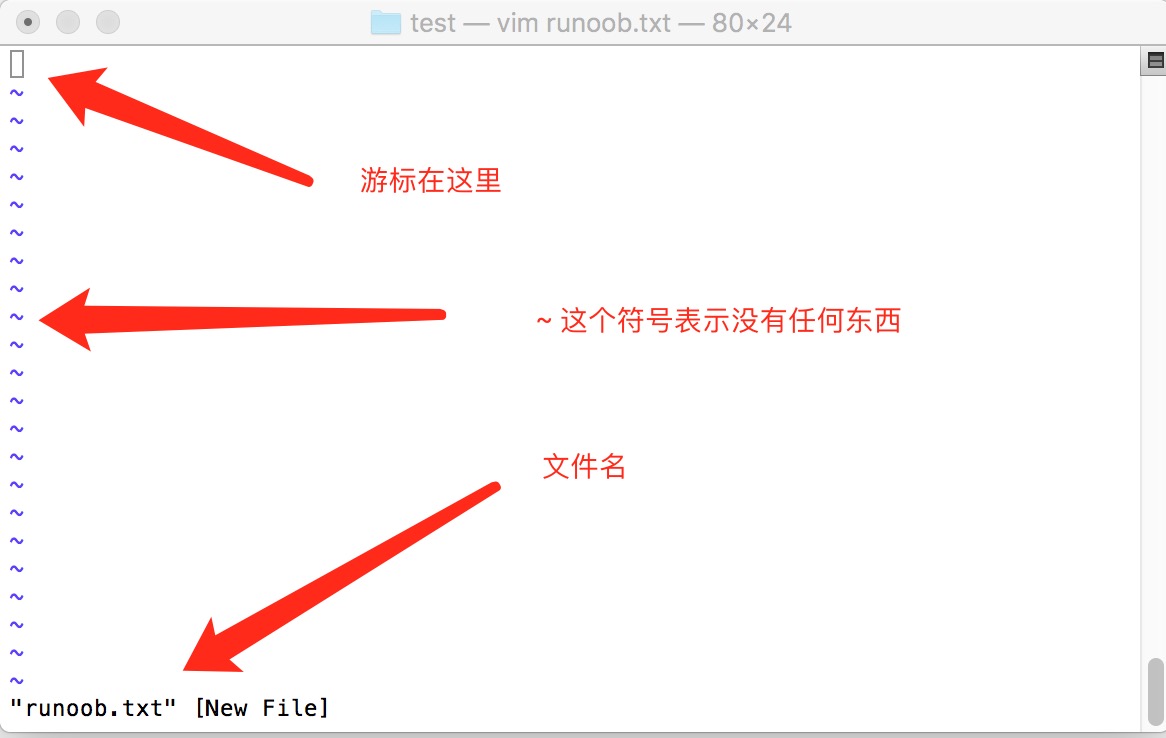
如果你想要使用 vi 来建立一个名为 runoob.txt 的文件时,你可以这样做:
vim runoob.txt
直接输入 vi 文件名 就能够进入 vi 的一般模式了。请注意,记得 vi 后面一定要加文件名,不管该文件存在与否!
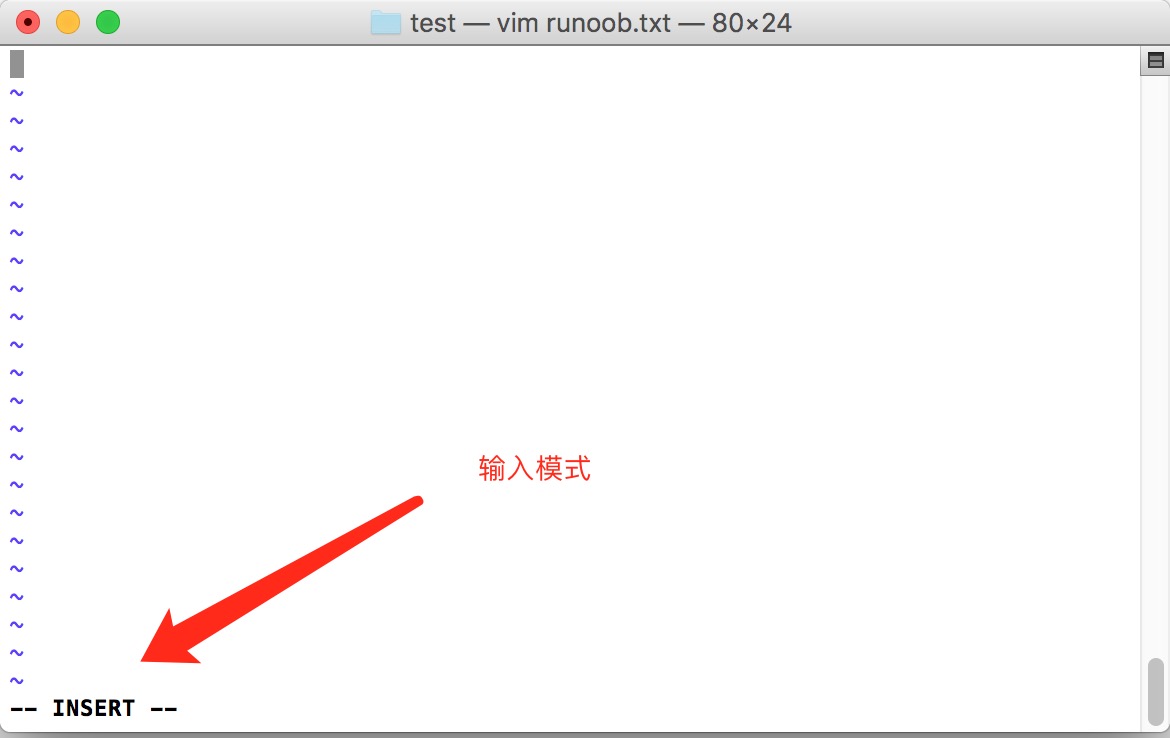
按下 i 进入输入模式(也称为编辑模式),开始编辑文字
在一般模式之中,只要按下 i, o, a 等字符就可以进入输入模式了!
在编辑模式当中,你可以发现在左下角状态栏中会出现 –INSERT- 的字样,那就是可以输入任意字符的提示。
这个时候,键盘上除了 Esc 这个按键之外,其他的按键都可以视作为一般的输入按钮了,所以你可以进行任何的编辑。
按下 ESC 按钮回到一般模式
好了,假设我已经按照上面的样式给他编辑完毕了,那么应该要如何退出呢?是的!没错!就是给他按下 Esc 这个按钮即可!马上你就会发现画面左下角的 – INSERT – 不见了!
在一般模式中按下 :wq 储存后离开 vi
OK,我们要存档了,存盘并离开的指令很简单,输入 :wq 即可保存离开!
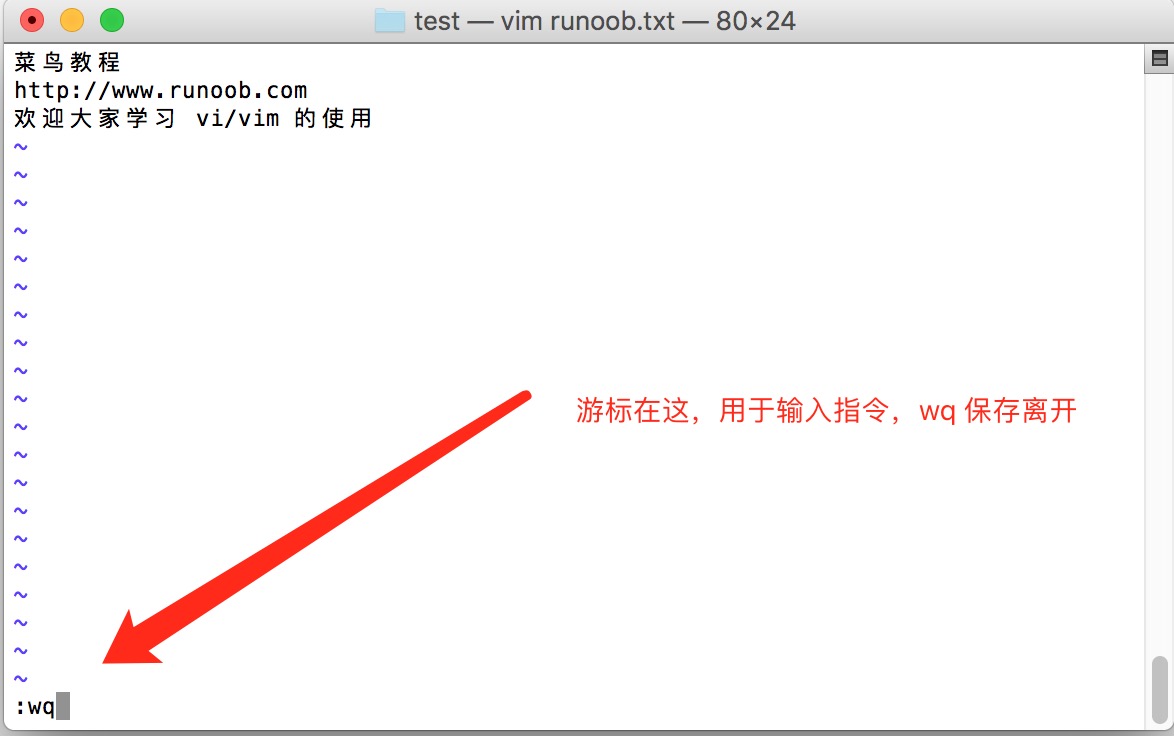
OK! 这样我们就成功创建了一个 runoob.txt 的文件。
vi/vim 按键说明
除了上面简易范例的 i, Esc, :wq 之外,其实 vim 还有非常多的按键可以使用。
第一部分:一般模式可用的光标移动、复制粘贴、搜索替换等
| 移动光标的方法 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符 |
| 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | |
| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
| [Ctrl] + [d] | 屏幕『向下』移动半页 |
| [Ctrl] + [u] | 屏幕『向上』移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n |
那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20 |
| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 移动到这个档案的最后一行(常用) |
| nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu)(常用) |
| gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
| n |
n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
| /word | 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) |
| ?word | 向光标之上寻找一个字符串名称为 word 的字符串。 |
| n | 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N | 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| 使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! | |
| :n1,n2s/word1/word2/g | n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『:100,200s/vbird/VBIRD/g』。(常用) |
| :1,$s/word1/word2/g 或 :%s/word1/word2/g | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) |
| :1,$s/word1/word2/gc 或 :%s/word1/word2/gc | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) |
| 删除、复制与贴上 | |
| x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
| dd | 剪切游标所在的那一整行(常用),用 p/P 可以粘贴。 |
| ndd | n 为数字。剪切光标所在的向下 n 行,例如 20dd 则是剪切 20 行(常用),用 p/P 可以粘贴。 |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除游标所在处,到该行的最后一个字符 |
| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy | 复制游标所在的那一行(常用) |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
| y1G | 复制游标所在行到第一行的所有数据 |
| yG | 复制游标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
| J | 将光标所在行与下一行的数据结合成同一行 |
| c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
| u | 复原前一个动作。(常用) |
| [Ctrl]+r | 重做上一个动作。(常用) |
| 这个 u 与 [Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,你的编辑,嘿嘿!很快乐的啦! | |
| . | 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) |
第二部分:一般模式切换到编辑模式的可用的按钮说明
| 进入输入或取代的编辑模式 | |
|---|---|
| i, I | 进入输入模式(Insert mode): i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 (常用) |
| a, A | 进入输入模式(Insert mode): a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) |
| o, O | 进入输入模式(Insert mode): 这是英文字母 o 的大小写。o 为在目前光标所在的下一行处输入新的一行; O 为在目前光标所在的上一行处输入新的一行!(常用) |
| r, R | 进入取代模式(Replace mode): r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) |
| 上面这些按键中,在 vi 画面的左下角处会出现『--INSERT--』或『--REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时, 一定要在左下角处看到 INSERT 或 REPLACE 才能输入喔! | |
| [Esc] | 退出编辑模式,回到一般模式中(常用) |
第三部分:一般模式切换到指令行模式的可用的按钮说明
| 指令行的储存、离开等指令 | |
|---|---|
| :w | 将编辑的数据写入硬盘档案中(常用) |
| :w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
| :q | 离开 vi (常用) |
| :q! | 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。(常用) |
| 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
| ZZ | 这是大写的 Z 喔!如果修改过,保存当前文件,然后退出!效果等同于(保存并退出) |
| ZQ | 不保存,强制退出。效果等同于 :q!。 |
| :w [filename] | 将编辑的数据储存成另一个档案(类似另存新档) |
| :r [filename] | 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 的内容储存成 filename 这个档案。 |
| :! command | 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
| vim 环境的变更 | |
| :set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :set nonu | 与 set nu 相反,为取消行号! |
特别注意,在 vi/vim 中,数字是很有意义的!数字通常代表重复做几次的意思! 也有可能是代表去到第几个什么什么的意思。
举例来说,要删除 50 行,则是用 『50dd』 对吧! 数字加在动作之前,如我要向下移动 20 行呢?那就是『20j』或者是『20↓』即可。
文本常见处理工具
文件内容查看
cat(熟悉)
cat [OPTION]... [FILE]...
-E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
nl(了解)
相当于cat -b
tac(熟悉)
逆向显示文本内容
rev(熟悉)
将一行的内容逆向显示
文件内容分页
more
less
文件内容首尾
head
可以显示文件或标准输入的前面行
head [OPTION]... [FILE]...
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前
- # 同上
tail
tail 和head 相反,查看文件或标准输入的倒数行
tail [OPTION]... [FILE]...
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新
建同名文件,将无法继续跟踪文件
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文
件
tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8无此工具
总结:
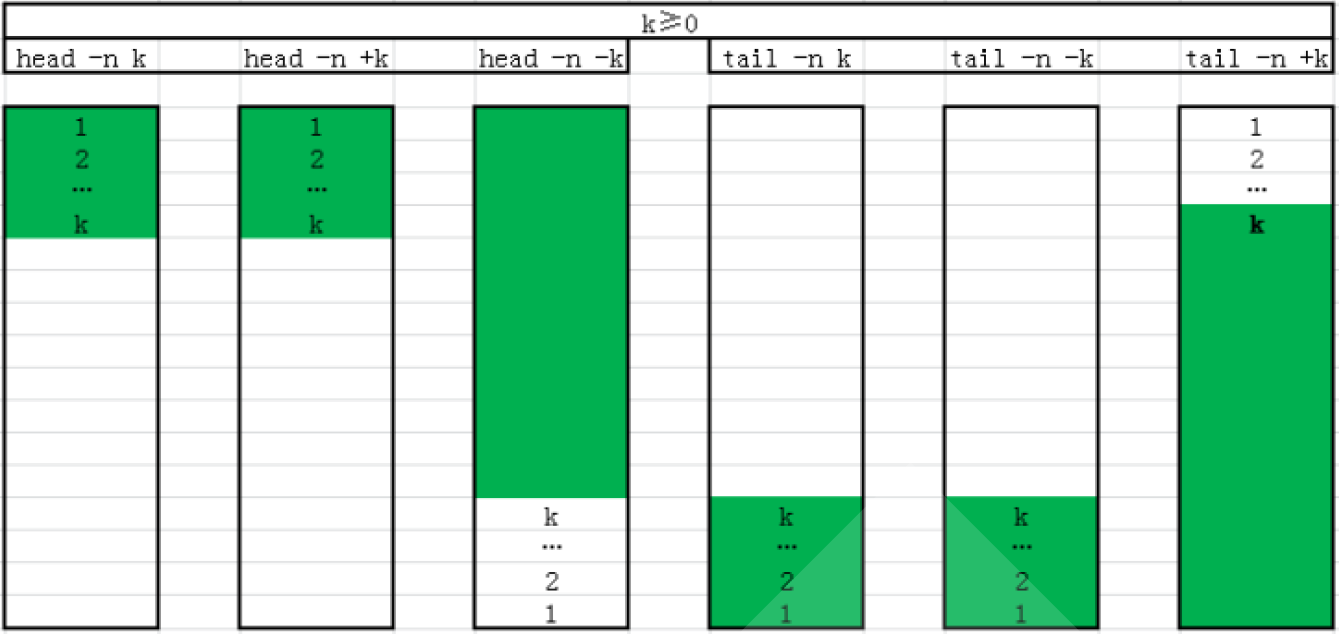
文本分割工具
cut
cut 命令可以提取文本文件或STDIN数据的指定列
cut [OPTION]... [FILE]...
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
paste
paste 合并多个文件同行号的列到一行
paste [OPTION]... [FILE]...
-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
文本分析工具
统计-wc
wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数、
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
排序-sort
把整理过的文本显示在STDOUT,不改变原始文件
-b 忽略每行前面开始出的空格字符。从第一个可见字符开始比较。
-d 排时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,忽略字符大小写.
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-c 检查文件是否已经按照顺序排序。
-m 将几个排序好的文件进行合并。
-M 前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o <输出文件> 将排序后的结果存入指定的文件。
-r 降序排列(默认是升序)。
-t <分隔字符> 指定排序时所用的栏位分隔字符。
-k field1[,field2] 按指定的列进行排序。
-u 排序
--help 显示帮助。
--version 显示版本信息。
默认排序方式:
- 排序时,默认是按每行/每个域的首字符排序,数字的优先级要大于字符的优先级
- 不指定升序还是降序时,默认是升序
常见用法:
sort test.txt # 按照默认升序排序
sort -r test.txt # 降序排序
sort -t ' ' -k 2 test.txt # 按照指定分隔符-t和指定域-k,默认升序排序
sort -t ' ' -n -k 3r -k 2 test.txt # 先按照第3域降序,对于第3域相同的,按第2域升序
在sort排序中,如果用 > 重定向来把结果输出到源文件,源文件会被置为空。
sort -t' ' -k 3r s.txt -o s.txt
sort -t ' ' -k 2n test.txt
sort排序的时候,-u不配合其他任何参数时,只有完全相同的重复行才会被消除。
sort -u salary.txt #去除重复行
sort -t' ' -u -k 1,1 salary.txt #按第一个域,消除后面的重复行
去重-uniq
uniq命令从输入中删除前后相接的重复的行
uniq [OPTION]... [FILE]...
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
常见案例
cut -d" " -f1 access_log |sort |uniq -c|sort -nr |head -n 3
ss -nt|tail -n+2 |tr -s ' ' : |cut -d: -f6|sort|uniq -c|sort -nr |head -n2
cat test1.txt test2.txt | sort |uniq -d
cat test1.txt test2.txt | sort |uniq -u
文本转置工具
tr
tr -d '[:space:]' #删除匹配的字段
tr '[:upper:]' '[:lower:]' #大小写转换
tr -s ' ' ':' # 用:替换空格
fold
fold -wn #拆分每n个字符作为一个单独的行
正则表达式
基本正则表达式
字符匹配
. #匹配任意单个字符,可以是一个汉字
[] #匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] #匹配指定范围外的任意单个字符,示例:[^wang]
[:alnum:] #字母和数字
[:alpha:] #代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] #小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] #大写字母
[:blank:] #空白字符(空格和制表符)
[:space:] #包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] #不可打印的控制字符(退格、删除、警铃...)
[:digit:] #十进制数字
[:xdigit:]#十六进制数字
[:graph:] #可打印的非空白字符
[:print:] #可打印字符
[:punct:] #标点符号
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意
Unicode #正则表达式会匹配全角空格符
匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* #任意长度的任意字符
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
位置锚定
位置锚定可以用于定位出现的位置
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行
^$ #空行
^[[:space:]]*$ #空白行
\< 或 \b #词首锚定,用于单词模式的左侧
\> 或 \b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词
#注意: 单词是由字母,数字,下划线组成
分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
注意:\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
或者
或者:|
a\|b #a或b
C\|cat #C或cat
\(C\|c\)at #Cat或cat
拓展正则表达式
拓展正则表达式与基本正则表达式的不同就是,不用加转义字符**\**
字符匹配
. 任意单个字符
[wang] 指定范围的字符
[^wang] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
次数匹配
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
位置锚定
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
分组或者
() 分组
后向引用:\1, \2, ...
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
文本处理三剑客之-grep
格式:
grep [OPTIONS] PATTERN [FILE...]
常见选项:
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
脚本示例:
# 取两个文件相同行
grep -f /data/f1.txt /data/f2.txt
# 分区利用率最大的值
df |grep '^/dev/sd' |grep -oE '\<[0-9]{,3}%'|grep -Eo '[0-9]+' |sort -nr|head -n1
# 哪个IP和当前主机连接数最多的前三位
ss -nt | grep "^ESTAB" |tr -s ' ' : |cut -d: -f6|sort |uniq -c|sort -nr|head -n3
# 连接状态的统计
ss -nta | grep -v '^State' |cut -d" " -f1|sort |uniq -c
# 算出所有人的年龄综合
cut -d"=" -f2 age.txt |tr '\n' + | grep -Eo ".*[0-9]"|bc
grep -oE '[0-9]+' age.txt | tr '\n' + | grep -Eo ".*[0-9]"|bc
文本处理三剑客之-sed
官网
http://sed.sourceforge.net/
sed工作原理
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器
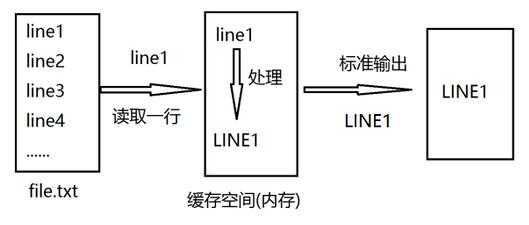
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到
最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(Pattern
Space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下
一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快
帮助参考网站:http://www.gnu.org/software/sed/manual/sed.html
sed基本用法
格式:
sed [option]... 'script;script;...' [inputfile...]
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流
#说明:
-ir 不支持
-i -r 支持
-ri 支持
-ni 会清空文件
script格式:
'script'
地址
1. 不给地址:对全文进行处理
2. 单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/
#,/pat/
/pat/,#
4. 步进:~
1~2 奇数行
2~2 偶数行
命令
p # 打印当前模式空间内容,追加到默认输出之后
Ip # 忽略大小写输出
d # 删除模式空间匹配的行,并立即启用下一轮循环
a # [\]text 在指定行后面追加文本,支持使用\n实现多行追加
i # [\]text 在行前面插入文本
c # [\]text 替换行为单行或多行文本
w # file 保存模式匹配的行至指定文件
r # file 读取指定文件的文本至模式空间中匹配到的行后
= # 为模式空间中的行打印行号
! # 模式空间中匹配行取反处理
q # 结束或退出sed
查找替代
s/pattern/string/修饰符 # 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g # 行内全局替换
p # 显示替换成功的行
w # /PATH/FILE 将替换成功的行保存至文件中
I,i # 忽略大小写
sed高级用法(了解)
sed 中除了模式空间,还另外还支持保持空间(Hold Space),利用此空间,可以将模式空间中的数
据,临时保存至保持空间,从而后续接着处理,实现更为强大的功能。
常见的高级命令
P 打印模式空间开端至\n内容,并追加到默认输出之前
h 把模式空间中的内容覆盖至保持空间中
H 把模式空间中的内容追加至保持空间中
g 从保持空间取出数据覆盖至模式空间
G 从保持空间取出内容追加至模式空间
x 把模式空间中的内容与保持空间中的内容进行互换
n 读取匹配到的行的下一行覆盖至模式空间
N 读取匹配到的行的下一行追加至模式空间
d 删除模式空间中的行
D 如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使
用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
sed练习范例
df | sed -rn 's/^\/dev\/sd.* ([0-9]+)%.*/\1/p'
# 不显示/etc/httpd/conf/httpd.conf文件中空行和注释
grep -vE "^#|^\s$|.*#" /etc/httpd/conf/httpd.conf
sed '/^#/d;/^\s$/d;/.*#/d' sed -ri.bak "/^#|.*#/d" httpd.conf
# 删除所有以#开头的行
sed -ri.bak "/^#|.*#/d" httpd.conf
# 只显示非#开头的行
sed -n '/^#/!p' httpd.conf
# 修改网卡配置
sed -Ei.bak '/^GRUB_CMDLINE_LINUX/s/(.*)(")$/\1net.ifnames=0\2/' /etc/default/grub
# 获取分区利用率
df | sed -rn 's/^\/dev\/sd.* ([0-9]+)%.*/\1/p'
# 取IP 地址
ifconfig eth0 | sed -nr '2s/.*inet ([0-9.]+).*/\1/p'
# 取文件的前缀和后缀
ll | sed -nr 's/.* ([a-zA-Z]+)\.([a-zA-Z]+)/\1 \2/p'
ll | grep -oE '[a-zA-Z]+\..*'
# 将非#开头的行加#
sed -rn 's/^[^#]/#&/p' httpd.conf.bak
# 将#开头的行删除#
sed -rn 's/^#(.*)/\1/p' httpd.conf.bak
文本处理三剑客之-wak
待补充...
参考:
https://blog.csdn.net/qq_45206551/article/details/104498965
Tip
请,本文为笔者整理的学习笔记,仅供个人参考和梳理思路,错漏之处请多多指导。
如,本文参考各种资源整理未,因此未申请原创声明,如有侵权请联系删除。
若,如果需要转载请各位大佬标明出处,园子不大多多捧场。
另,本文仅做学习使用,请勿用于非法途径。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号