


遍历文件在Windows下可以用 FindFirstFile/FindNextFile 这组API(另外貌似可以使用SHGetDataFromIDList,也可以使用boost),一般是通过递归实现,比如:
#include "strsafe.h"
bool EnumerateFolder(LPCTSTR lpcszFolder, int nLevel = 0)
{
WIN32_FIND_DATA ffd;
TCHAR szDir[MAX_PATH];
HANDLE hFind = INVALID_HANDLE_VALUE;
StringCchCopy(szDir, MAX_PATH, lpcszFolder);
StringCchCat(szDir, MAX_PATH, TEXT("\\*"));
// Find the first file in the directory.
hFind = FindFirstFile(szDir, &ffd);
if (INVALID_HANDLE_VALUE == hFind)
{
return false;
}
// List all the files in the directory with some info about them.
TCHAR szOutLine[MAX_PATH] = {0};
for (int ii = 0; ii < nLevel; ++ii)
szOutLine[ii] = _T('\t');
do
{
if (ffd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY)
{
if ( _T('.') != ffd.cFileName[0] )
{
_tprintf(TEXT("%s%s <DIR>\n"), szOutLine, ffd.cFileName);
StringCchCopy(szDir+_tcslen(lpcszFolder)+1, MAX_PATH, ffd.cFileName);
EnumerateFolder(szDir, nLevel+1); // recursion here
}
}
else
{
_tprintf(TEXT("%s%s\n"), szOutLine, ffd.cFileName);
}
}
while (FindNextFile(hFind, &ffd) != 0);
FindClose(hFind);
return true;
}
可以看到,递归代码的可读性非常好,递归在很多时候的表现也不错,性能不会太差,其实递归和迭代的差别在很多时候不会很大,但每每要用到递归,还是不免想到可能会因使用栈的空间来保存局部变量(还有参数、返回地址等)而导致的stack overflow的问题。
系统给程序分配的内存有一部分是用来作栈使用的,栈在最大的地址开始,需要“申请”栈的时候就让栈顶指针也就是esp指向更低(往下“走”)的空间,当栈增长太大乃至超过堆(堆是往上“走”的)的范围时就是所谓stack overflow/collide,可以想象的是要么栈破坏堆上存储的数据,要么就是程序“返回”到非法的地址去执行指令,多么可怕啊,不过现在堆栈貌似是被分配在不同内存页上的,操作系统尽了最大的努力对堆栈进行保护,所以其实也不是很恐怖,大不了就是整个进程被操作系统kill掉。
尽管如此,谁也不希望自己的程序这么死掉,那多不给力啊!stack overflow的异常即使用try/catch也不行(C++不能catch这种异常,必须用Windows自己的)递归需要额外的函数调用开销,如果代码是在多线程环境下执行,那还会面临一个系统分配给每个线程的堆栈大小限制的问题,Windows下每个线程默认分配1M的空间。
那看看上面那个递归版本的函数会需要多少局部空间:WIN32_FIND_DATA 的大小是 320,MAX_PATH的buffer是260,其余变量和参数忽略,那么一次函数调用需要580个字节(ANSI环境),也就是说最大能递归多少层?
答案是 1808 层。
换句话说,从根目录开始,最多只能遍历到1907层深的文件夹结构,再深层的文件就遍历不了了。而实际上,我们是没办法创建这么深层次的目录树结构的,试试看就知道Windows会提示超出限制。
其实看看 MAX_PATH 的值就知道了,不是才260么,哪有可能给你弄到1800多层?
NTFS不是据称很先进么,莫非也这么不给力?在多字节字符环境下,这个限制将使得我们最多只能创建一百多层深的文件夹结构。
尽管有人说260个字节在大多情况下都够用了,但也难保会有些BT人士埋怨这个限制,这严重影响了筒子们通过多层文件夹保藏“爱国教育影片”的热情。
翻翻MSDN上关于FindFirstFile的说明,原来微软还留有一手:
In the ANSI version of this function, the name is limited to MAX_PATH characters. To extend this limit to 32,767 widecharacters, call the Unicode version of the function and prepend "\\?\" to the path. For more information, see Naming a File.
简单说为了让这个限制突破到32767个宽字节字符(说了是宽字符了,那当然得是UNICODE环境下了),就要在路径前加上 \\?\ (这个办法有个缺点,那就是不能访问根目录)。
这下,我们完全有机会遇到1M的线程堆栈限制,虽然搞不懂为什么既然微软已经考虑到并提供了增加文件路径长度的方案,而我们仍然不能创建那么长的路径,但这至少给写个非递归版本的遍历文件函数提供了个理由。
那就动手写个非递归的吧!既然决定不用递归,那保存和恢复遍历信息的工作就交给程序员自己实现了,也就是说要自己模拟一个“栈”,只不过这个“栈”是在堆上的(很显然堆比栈大的多了)。
STL提供了stack,如果每次push/pop都要申请/释放内存空间,那效率自然不好,我不是很清楚STL对于stack的内部实现,如果它足够聪明应该是可以避免这种情况的。
由于不肯定,我选择了用vector来实现,重点就是在需要pop的时候不删除空间,在需要push的时候使用类似SetAtGrow的机制。
11/29/2010 更新:上一个版本的实现是DFS(深度优先搜索,Depth-first search),所以需要自己模拟堆栈,而Ramond Chen 大虾说 breadth-first searching is better for file system tree walking,也就是说对于文件系统树的遍历来说使用广度优先要比深度优先要更好些,理由是:1、DFS每次遇到目录则立即深入搜索,因此需要保存大量句柄,而BFS则避免用太多handle;2、同一个目录下的文件在硬盘的物理结构上更邻近些,所以BFS更快。所以决定更新一些code,增加了BFS的实现,原来的递归以及DFS的代码还在,不过都被我#ifdef掉了,默认是BFS,有需要研究的可以在 FileEnumerator.h 里找到下述代码自行调整测试:
//#define FILEENUMERATOR_RECURSION // 递归的实现,默认关闭 //#define FILEENUMERATOR_DOCOUNTING #ifndef FILEENUMERATOR_RECURSION #define FILEENUMERATOR_BFS // 当不使用递归时默认使用BFS,否则为DFS #endif
首先写个类来稍微封装一下:
class CFileFinder
{
public:
CFileFinder(LPCTSTR lpcszInitDir, FindFileData& fileInfo)
: m_fileInfo(fileInfo)
{
Init(lpcszInitDir);
}
public:
inline bool FindFirst()
{
return EnumCurDirFirst();
}
inline bool FindCurDirNext()
{
bool bRet = ::FindNextFile(m_hFind, &m_fileInfo) != FALSE;
if ( bRet )
{
m_szPathBuffer.resize(m_nFolderLen);
m_szPathBuffer += m_fileInfo.cFileName;
}
else
{
::FindClose(m_hFind);
m_hFind = INVALID_HANDLE_VALUE;
}
return bRet;
}
virtual bool Finish() const
{ return INVALID_HANDLE_VALUE == m_hFind; }
inline LPCTSTR GetPath() const
{return STRBUFFER(m_szPathBuffer) + EXTEND_FILE_PATH_PREFIX_LEN;}
inline const FindFileData& GetFileInfo() const { return m_fileInfo; }
inline bool IsDirectory() const
{ return (m_fileInfo.dwFileAttributes &
FILE_ATTRIBUTE_DIRECTORY) == FILE_ATTRIBUTE_DIRECTORY; }
inline bool IsDot() const
{ return (m_fileInfo.cFileName[0] == '.') &&
((m_fileInfo.cFileName[1] == '.') ||
(m_fileInfo.cFileName[1] == '\0')); }
protected:
virtual bool EnumCurDirFirst()
{
m_szPathBuffer.resize(m_nFolderLen+2);
m_szPathBuffer[m_nFolderLen++] = _T('\\');
m_szPathBuffer[m_nFolderLen] = _T('*');
HANDLE hFind = ::FindFirstFile(STRBUFFER(m_szPathBuffer), &m_fileInfo);
bool bRet = hFind != INVALID_HANDLE_VALUE;
if ( bRet )
{
m_hFind = hFind;
m_szPathBuffer.resize(m_nFolderLen);
m_szPathBuffer += m_fileInfo.cFileName;
}
return bRet;
}
void Init(LPCTSTR lpcszInitDir)
{
m_nFolderLen = _tcslen(lpcszInitDir);
m_szPathBuffer = lpcszInitDir;
if ( m_szPathBuffer[m_nFolderLen-1] == _T('\\') )
{
m_szPathBuffer.erase(m_nFolderLen-1);
--m_nFolderLen;
}
}
protected:
FindFileData& m_fileInfo;
tstring m_szPathBuffer;
UINT m_nFolderLen;
HANDLE m_hFind;
};
然后就是用它们做实事了:如果是要实现DFS,那么由于每次深入遍历子目录的时候都必须保留当前所有已遍历的搜索句柄等信息,其后还要再在回溯的时候继续上一层目录的搜索工作,所以会要用到栈。由于现在是实现广度优先,当遇到一个目录的时候并不用急着深入搜索,而是先把相关信息给记录到一个队列里面,等当前目录的所有文件都访问完后,再pop队列的头(也就是下一个待遍历的目录)继续遍历,从而实现所谓的BFS。
#include
typedef boost::shared_ptr FileFindPtr;
typedef std::queue FileFindQueue;
bool CFileEnumeratorBase::EnumerateBFS( LPCTSTR lpcszInitDir, FindFileData& findFileData, HANDLE hStopEvent /*= NULL*/ )
{
// Breadth-first searching, BFS:
FileFindPtr finder = NULL;
try
{
finder = new CFileFinder(lpcszInitDir, findFileData);
}
catch (bad_alloc&)
{
CFE_ASSERT(0);
return false;
}
bool bRet = true;
FileFindQueue finderQueue;
if ( !finder->FindFirst() )
{
m_dwLastError = ::GetLastError();
OnError(finder->GetPath());
return false;
}
else
{
while( !finder->Finish() && !IsStopEventSignaled() )
{
const FindFileData& fileInfo = finder->GetFileInfo();
if( finder->IsDirectory() )
{
if ( !finder->IsDot() )
{
if ( CheckUseDir(finder->GetPath(), fileInfo) )
{
HandleDir(finder->GetPath(),
fileInfo);
FileFindPtr newFinder = NULL;
try
{
newFinder =
new CFileFinder
(finder->GetPath(),
findFileData);
finderQueue.push
(newFinder);
}
catch (bad_alloc&)
{
CFE_ASSERT(0);
}
}
}
}
else
{
if ( CheckUseFile(finder->GetPath(), fileInfo) )
{
HandleFile(finder->GetPath(), fileInfo);
}
}
if ( !finder->FindCurDirNext() )
{
FinishedDir( finder->GetPath() );
if ( finderQueue.empty() )
break;
else
{
while ( !IsStopEventSignaled() )
{
FileFindPtr nextFinder =
finderQueue.front();
finderQueue.pop();
finder = nextFinder;
if ( !finder->FindFirst() )
{
m_dwLastError =
::GetLastError();
if ( !OnError
(finder->GetPath()) )
{
return false;
}
}
else
break;
}
}
}
}
}
return bRet;
}
“很干净的代码”,没多少注释,这点很是羞愧啊,但限于时间关系只好这样了。
最后想想实际应用,既然已经用AHK做了个文件查找,那就试试看用VC实现吧,和AHK的精短代码比起来,VC实现的代码量实在太惊人了,没办法贴上来了,只好打包。
最终实现效果:
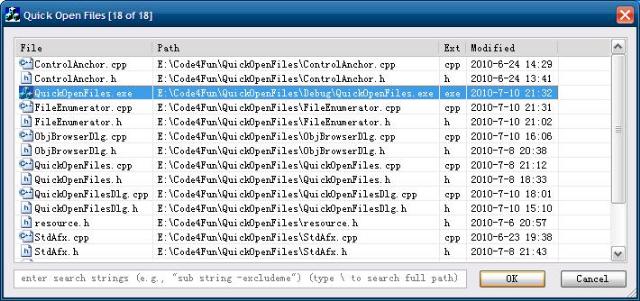

免责声明:
源代码和demo在此提供,没有任何限制,你可以自由地拷贝、分发、修改源代码,也可用于各种邪恶(或善良)用途,但你必须自行承担风险,既然是free的,本人自然不对代码提供任何保证和“售后服务”。
给拷贝/粘贴/转发的:
原作者:yonken
本人不耻,已经将此拙文发到codeproject上了,源代码及示例程序下载请到这个地址下载:
http://www.codeproject.com/KB/files/IterativeFileEnumerator.aspx
参考:
1. http://www.codeproject.com/KB/files/CEnum_enumeration.aspx

