海量数据处理问题
1.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
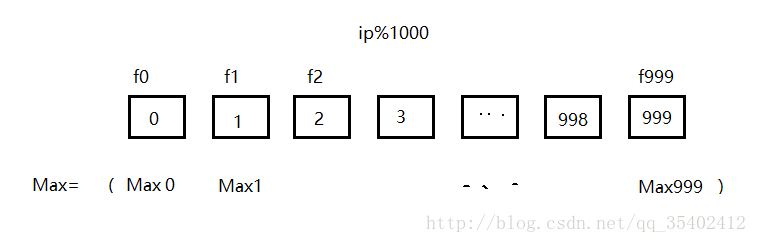
将100G的log file分成1000份
相同的Ip必定会在同一个小文件里
在每个文件里找出出现次数最多的ip
将找出来的1000个最多ip进行比较,找出最多的一个
2.给定100亿个整数,设计算法找到只出现一次的整数
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
在位图中,每个元素为“0”或“1”,表示其对应的元素不存在或者存在。
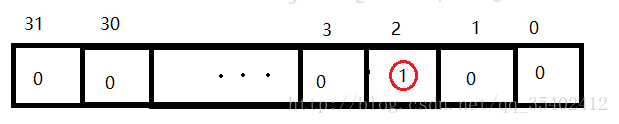
找到出现次数不超过2次的所有整数,变形位图,让每个数用两位来标记:
00:0个 01:1个 10:2个 11:多个
使用位图以及位图的变形:http://blog.csdn.net/qq_35402412/article/details/79415172
3.给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
精确算法
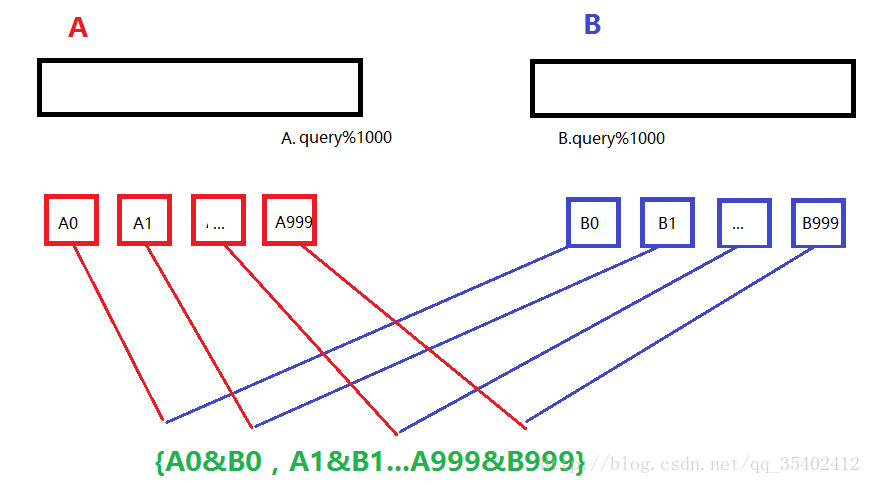
假设1个query只有30bites,100亿个为300G,我们只有1G内存,并且有两个文件,将两个文件分别切分1000份;
相同的ip%1000,必定会放到相同小文件中,则相交的结果即 {A0&B0,A1&B1...A999&B999}
近似算法
使用布隆过滤器,将A切分后存入布隆过滤器,用B来依次进行对比,若找到,则这个query为交集
如何扩展BloomFilter使得它支持删除元素的操作
对每一位引用计数,删除后只要改它的计数
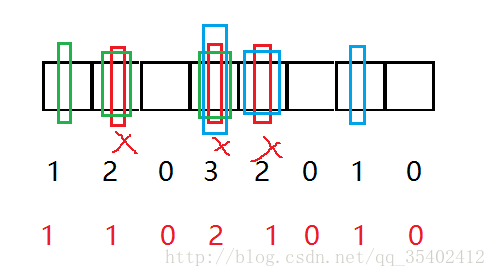
如何扩展BloomFilter使得它支持计数操作
引入计数,则不能使用位图,将BitMap _bm改为size_t *_bm;- typedef struct{
- //BitMap _bm;
- size_t *_bm;
- HASH_FUNC hashfunc1;
- HASH_FUNC hashfunc2;
- HASH_FUNC hashfunc3;
- }BloomFilter;
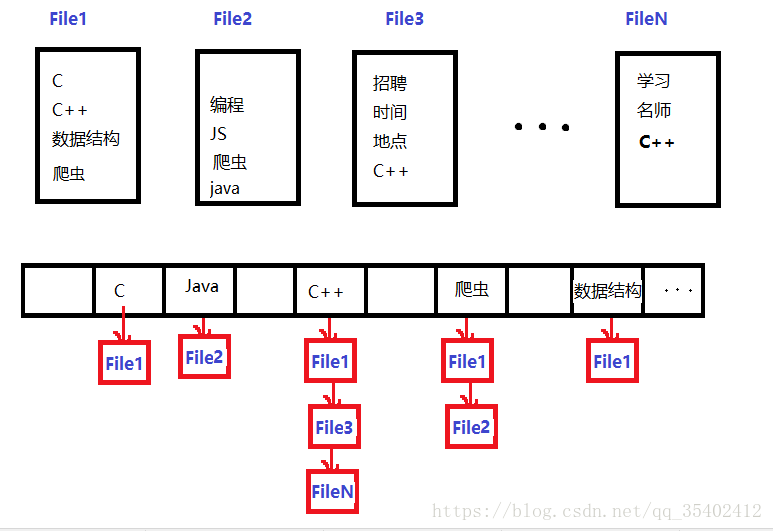
倒排索引
给上千个文件,每个文件大小为1K—100M。给n个设计算法对每个词找到所有包含它的文件,你只有100K内存
搜索引擎的方法,将文件中的词存入哈希表,在找到的文件链到相应名词上