


SPADE阅读笔记
SPADE阅读笔记
同样的,作者提出一个simplt but effective layer,给定一张分割的图,作者能够合成photorealistic images.作者说,normalization layer能够wash way semantic information.为了解决这个问题,作者propose using input layout for modulating the activations in normalization layers through a spatially-adaptive, learned transormation.
作者的方法
假设语义分割mask为\(\mathbf{m} \in \mathbb{L}^{H \times W}\), H和W分别为图像高宽,m中的每一个元素代表其所属类别。作者的目标就是学习一个mapping function能够convert an input segmentation mask \(m\) to a photorealistic image.
spatial-adaptive denormalization
让\(h^i\)表示\(i\)-th layer的激活,一个mini-batch有\(N\)个samples;\(C^i\)表示一共有\(C^i\)个channel。\(H^i\)和\(W^i\)表示activation map的高和宽,作者提出了一个新的conditional normalization method called spatial-adaptive denormalization (SPADE)。和BN很相似的是,在channel的维度对激活进行规划,然后modulated with学习的尺度和偏置。SPADE的设计如下图所示:
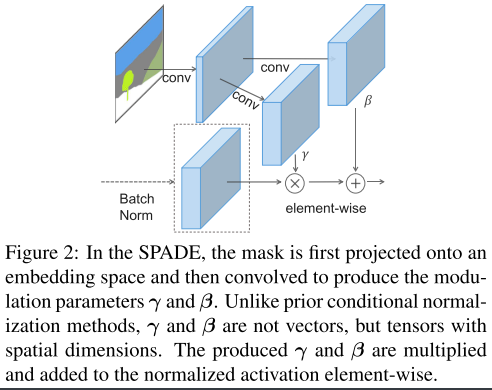
如title所说,mask首先经过卷积到embedding space,然后得到modulation parameters \(\gamma\)和\(\beta\)。和之前的conditional nomalization methods不一样的是,这里的\(\gamma\)和\(\beta\)不是vector,而是有spatial dimension的tensor。产生的\(\gamma\)和\(\beta\)然后先乘在假造normalized activation.
在site\(\left(n \in N, c \in C^{i}, y \in H^{i}, x \in W^{i}\right)\)的激活是
其中,\(h_{n, c, y, x}^{i}\)表示在normalization之前的激活,\(\mu_{c}^{i}\)和\(\sigma_{c}^{i}\)是channel c的均值和方差:
其中,\(\gamma_{c, y, x}^{i}(\mathbf{m})\)和\(\beta_{c, y, x}^{i}(\mathbf{m})\)是学习到的modulation parameters of normalization layer. 和BN不同的是,\(\gamma\)和\(\beta\)取决于segmentation mask,以及不同的位置,也不一样。作者说,他使用两层简单的网络来提取\(\gamma\)和\(\beta\)。
SPADE generator
使用spade,没有必要将segmentationmap输入到网络的第一层,因为学习到的modulation parameters 已经编码了label layout的足够的信息。因此,作者discard generator的encoder的part,这将会得到一个更加轻量级的网络,而且可以输入任意的噪声。
作者的网络结构如下所示
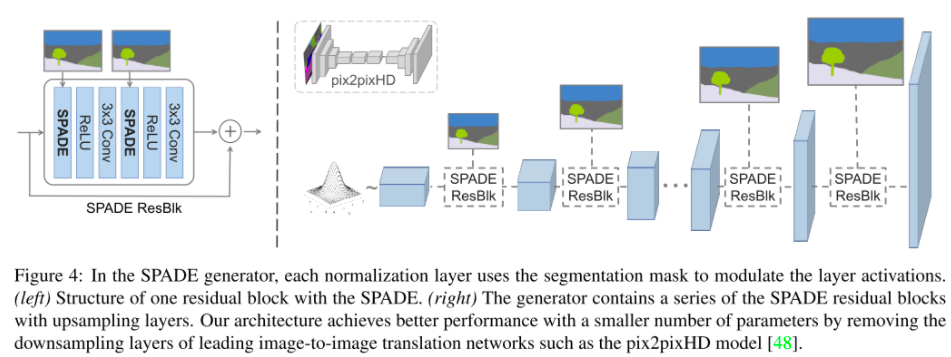
作者说他的训练方式和pix2pixHD一样,只是用hinge loss取代了最后的MSE loss
为啥SPADE work better?
作者说,SPADE能够保留semantic information against common normalization layers. 因为传统的BN,或者是IN能够对于输入的segmentation mask进行wash away semantic information. 作者假设了一种case,输入都只是一种label,那么经过IN之后,输出都为0.但是对于spade,则能够避免这种case
posted on 2021-06-02 14:35 YongjieShi 阅读(318) 评论(0) 编辑 收藏 举报


