
EnlightenGAN: Deep Light Enhancement without Paired Supervision论文阅读笔记
EnlightenGAN: Deep Light Enhancement without Paired Supervision论文解读
Motivation and introduction
最近在xiajiba看一些论文,看到了关于低光图像增强的无监督学习的一篇论文。如题。
作者题目起的非常低调,大概表达的意思是做了一件事情,之后论文的故事讲的也非常好。
作者在introduction中介绍了现有的一些方法,以及这些方法都是基于paired training。但是paired training
会遇到一些问题,比如
- 对于同一个场景,很难去同时拍摄低光图像和亮光图像(注意,低光图像和亮光图像是一个paired,在以往的方法都是需要的)
- 有些方法是通过合成得到的有损的图像(有雨的,低光的等),但是通过合成数据来制造pair的方法和真实的图片相差甚远
- 尤其是对于低光图像而言,没有一个统一的标准来衡量究竟是增强到多亮才算好。比如傍晚的图像可能是深夜的图像的增强,但是实际上中午的图像也是傍晚的图像的增强。
针对以上问题吧,同时受到一些无监督的图像翻译文章的启发,作者提出了一个轻量级但是非常有效果的单路GAN(说是单路GAN,是相对于cyclegan而言的)
因为缺少paired training data,作者提出了一系列的创新的techniques,比如
- 他们第一次提出了global discriminator以及local discriminator。
- 他们用self-regularized perceptual loss来约束低光和增强之后的图片
- 同时,他们利用低光亮度信息作为特征图的一种attention map,来正则无监督学习
作者实验验证,EnlightenGAN可以很容易增强不同domain的low-light图像
值得一提的是,作者在introduction中介绍了cvpr2019一篇文章,learning to see in the dark.这篇文章非常有意思,和以前做的低光图片增强不同,learning to see in the dark这篇文章提出了一个非常暗的数据集合,以至于单纯的图像亮度调整是不可能的,需要考虑到去噪,以及去马赛克,以后会讲一下这一篇paper
their method
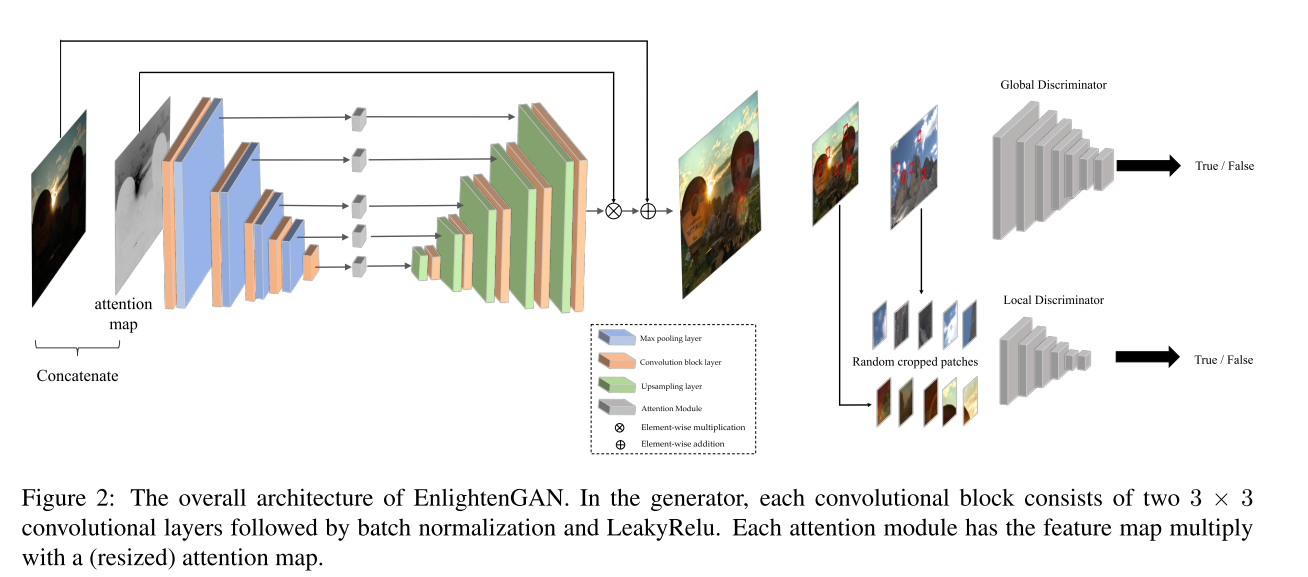
网络图如上,先看G网络,作者用到的生成网络是一个unet256,做了一些稍微的修改是加入了一个attention模块。这个attention模块非常简单,作者的motivation是这样的,对于图像增强这个任务而言,亮的部分,我不希望特别亮,对于暗的部分,我希望能头提亮一些,也就是说我希望网络着重关注于图像中比较暗的部分。所以作者对图像的亮度做了一个减法,就是用\(1-I\)来作为attention map。作者在这里,输入不仅进行了concate,对encoder中的feature用\(1-I\)进行加权,得到的feature map再与decoder中的feature map进行加权。举个例子:
conv7 = F.upsample(conv7, scale_factor=2, mode='bilinear')
conv2 = conv2*gray_2 if self.opt.self_attention else conv2
up8 = torch.cat([self.deconv7(conv7), conv2], 1)
x = self.bn8_1(self.LReLU8_1(self.conv8_1(up8)))
conv8 = self.bn8_2(self.LReLU8_2(self.conv8_2(x)))
gray_2是通过resize之后的attention map和encoder中的feature map进行逐元素相乘,相当于是一个attention。
之后网络输出的部分和attention map相乘得到一个残差,这个残差和原图相加,得到最终的亮度图。
这种residual的思想很值得学习,之前在去模糊以及去雨的相关论文中就有这种介绍,学习一个残差比学习一个完整的去完玉之后的图像要压力小的多,尤其是这种对于图像内容更改不大的任务。不仅仅是学习一个残差这种low-level vision中会采用,最近看了一片关于双目深度估计的一篇paper,也是采用类似的思想,学习一个cost volume,之后会讲到
Self Feature Preserving Loss
挑重要的说,作者采用perceptual loss 来保持自己的特征。作者说对vgg网络而言,输入的图像的亮度改变之后,输出的图像的类别变化很小,所以作者在这里说,希望用vgg约束来保持输入的暗的图像和输出的亮的图像的content不变。这样是比较reasonable的,最初的perceptual loss提出来的时候也是用于风格迁移,保持两张图片的content不变,只改变style。但是作者说了这个和很多low-level的任务不一样,比如去雨,去雾这种。这种去雨去雾的都是对于生成器输出的图像和gt之间的feature进行度量,而不是,对g的输入和g的输出之间的距离进行一个度量。我觉得这个loss可能也只能在亮度增强任务中应用,因为亮度的改变vgg feture之间的距离影响不是特别大,perceptual loss具有保内容性。
golbal and local discriminator
作者发现,最初的判别器在光照变化的区域往往会失效,这个时候对于图像的local区域进行判别显得尤为重要。所以在这里作者用了两个discriminator,一个是global的discriminator,一个是local的discriminator,两个discriminator的作用正如标题所言。作者在使用local discriminator的时候输入的图像是随机的patch。
对于global discriminator,作者采用的是relativistic discriminator,这个discriminator貌似很出名的样子,因为deblur-gan v2也使用了这样的一个gan。不过无论怎样,loss越小,都是g或者d的目标。
对于local discriminator,作者使用的是ls-gan。
每个part的作用
作者详细介绍了,local discriminator,attention模块的作用

local discriminator和attention模块的作用都是减少失真和保持颜色一致性的关键part。
实验数据
因为不是unpaired的图像,所以比较好搜集。作者用了914张low light的图像和1016张normal light的图像。所有图像的尺寸resize到600×400。三块卡上训练,三个小时训完。这里想说一句,大部分low-level的任务,数据集合都是比较小的,所以很多开源的代码,都是单卡上跑的, 作者这里用data parallel多卡并行,看了一下batch size是32,训练速度非常快。之前做畸变的时候就苦于gan很难用多卡一起跑,作者开了一个好头。
实验结果
对于无监督的图像生成,很难用定量的评价指标进行评价,作者这里除了做了定性的ablation study之外,对于和sota结果的比较,作者用了两个评价标准,一个是Human Subjective Evaluation,另外一个是NIQE。第一个是人为的去评价图像质量如何,第二个是,一种通用的图像质量评价方法。值得注意的是,作者这里和cycle-gan进行了对比,感觉结果还不错,综合而言。
总的来说,这篇文章值得借鉴的部分还挺多的,第一个是关于无监督学习的一个motivation以及,一种比cycle-gan更轻量级的gan来进行domain的transfer。local以及discriminator的应用,图像质量评价标准的应用。
给自己挖几个坑
- 将一片iccv上的扶正文章看
- 讲一下双目深度估计相关的paper
- 对于see in the dark这一篇文章,写相关的背景介绍
posted on 2020-01-21 13:21 YongjieShi 阅读(3761) 评论(2) 编辑 收藏 举报


