【数据仓库】|1 所以,什么是数据仓库
声明:
1. 本栏是个人总结,如有错漏,请指正2. 数据仓库的构建目前业界只有指导方案,并没有统一的标准,每个公司都可以按照实际情况进行设计3. 本总结参考《阿里巴巴大数据之路》、《数据仓库工具箱》
产生背景
你以为我又要从OLTP\OLAP进化史开始巴拉巴拉?不了,浪费时间。数据仓库,其实也就是一群SQL Boy,提数员为了应付业务方各种需求,提前建立的一个集中型的数据集市,减少数据重复开发,建立数据统一口径,解决业务方多维度、多粒度的数据需求。数仓四个特性必须了解:
面向主题
数据在仓库里必须有规范、有条理保存。就像是超市里的商品,热销品摆在最显眼位置,促销摆在中央人流经过最频繁的区域,除此还分日用、食品、饮料、冷藏冰鲜等等。所以,数据分门别类,按照主题整合存放,最顶层的好处是,作为开发人员,当数据需求来了,我们可以随时找到有哪些数据,都存放在哪,快速响应。
集成
说的是解决数据孤岛的问题。将关系型数据库数据、流式数据、日志等等结构化或非结构化的数据都经过数仓统一接入和管理。企业数据经过集成和整合后,更容易通过数据目录,知道自己的数据资产有多少。
稳定
数据在数仓中不容易丢失,允许一定的冗余,面向下游服务不容易出现数据异常等情况。目前的数据仓库一般都是保存在HDFS\S3等存储中,容易备份和恢复。即使下游数据万一真的丢失,也可以通过重跑数据的方式恢复数据。
随时间变化
数据会随着时间的变化而变化,且会按照需要的时间粒度,保存历史变化。T+1日或者T+0日 的数据不断涌入数仓,数据需要定期更新相应的变化。具体保存时间的粒度由业务决定,比如秒、分、天、周等。
方法论
数仓界大佬有两个人必须了解,其各自提出的方法论都已自己名字命名。注意:数仓之父是Inmon,也是他定义了数据仓库的特性。
怎么比对两者的方法论呢?假设有简单的三层 : 数据源 ==> 数据仓库 ==> 数据集市
Inmon
走瀑布模型,开发方向从数据源》数据仓库》数据集市。在源头探索性地获取符合预期的数据表,经过规则清洗后,以实体-关系建模方式输入数据仓库层,再通过集市输出到BI系统。
这种方法要求数据需求十分明确,而且有强力的建模团队支撑,在数据需求变化不大的情况下输出整个数仓符合3NF的E-R模型,对数仓有居高临下的统筹。但因为实际数据需求变化太快,如果用此理论建设数仓,会花费很大人力在前期基础搭建上,一般公司领导或者业务部门不会接受。
Kimball
走敏捷开发,开发方向从数据集市》数据仓库》数据源。从实际需求出发,在数据源头寻找若干相关的表后,通过ETL转化到数据仓库,而数据仓库一般采用维度建模(事实表+维表)方式构建,最后抽到数据集市满足数据需求。
这种方法能快速交付,适应需求变化,不会导致前期投入太大导致人力浪费。在目前受到大部分互联网公司的推崇,而维度建模,称为绝大部分公司数据仓库的首选。
一言蔽之
|
特性
|
Kimball
|
Inmon
|
|
时间
|
快速交付
|
路漫漫其修远兮
|
|
开发难度
|
小
|
大
|
|
维护难度
|
大
|
小
|
|
技能要求
|
入门级
|
专家级
|
|
数据要求
|
特定业务
|
企业级
|
数据仓库与数据湖区别
看到这里引入一个新词:数据湖。数据湖不会很难理解,我们可以直接从数据类型的角度解释。
假设:数据仓库 = 关系型数据 + 系统日志数据 + 埋点数据那么:数据湖 = 支持所有数据查询(结构化数据+非结构化数据)如json、流、视频音频等等
关于数据仓库与数据湖,网上的争论很多,不外乎以下几点:
- 数据湖是数据仓库的升级版
- 数据湖代替数据仓库
- 当代企业数据服务中台 = 数据仓库 + 数据湖
- 其他
所以,我们姑且可以这么认为,数据湖 = 传统数仓(结构化数据) + 非结构化数据。两者不是非此即彼的关系,而是相互相成、互为补充。
数据仓库和数据中台的区别
数据中台是阿里铁军引入的,通俗理解,数据中台注重的是数据资产化、数据服务化这一重点功能,着重对外输出数据能力。
数据中台 = 数据仓库 + 大数据中间件(计算、研发、分析工具)+数据资产管理
如果不太理解服务化这个概念,其实单纯把它理解成把数据仓库的所有表,分门别类形成数据资产,再通过接口(Restful等)变成一个个灵活的、外部可访问的、可灵活组合的数据瑞士军刀。
数据仓库的架构演变
数据仓库从1990年开始发展到今天,经历了传统数仓(基于关系型数据库如oralce、mysql等),到大数据架构数仓(Hive\Impala等)再到 Lambda 架构、Kappa 架构以及 Flink 的火热带出的流批一体架构,数据架构技术不断演进,本质是在往流批一体的方向发展,让用户能以最自然、最小的成本完成实时计算。这是数据仓库发展的终极青铜门。
传统数仓 - 离线
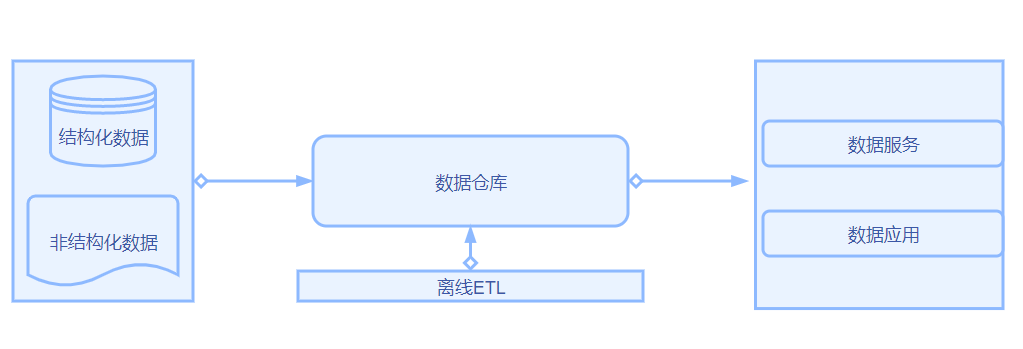
传统数仓一般是基于当时流行的大型关系型数据库如oralce、sqlserver、DB2等创建的。通过定期加载数据到数据仓库后再通过ETL整合,最后交由前端调用。
大数据架构数仓 - 离线
可以理解为,把传统数据仓库的存储数据库换到Hadoop架构、或MPP数据库中,使用大集群分布式计算能力加工数据,技术从原来的关系型数据库转为诸如Hadoop+Hive\Spark,Greenplum等。
Lambda架构
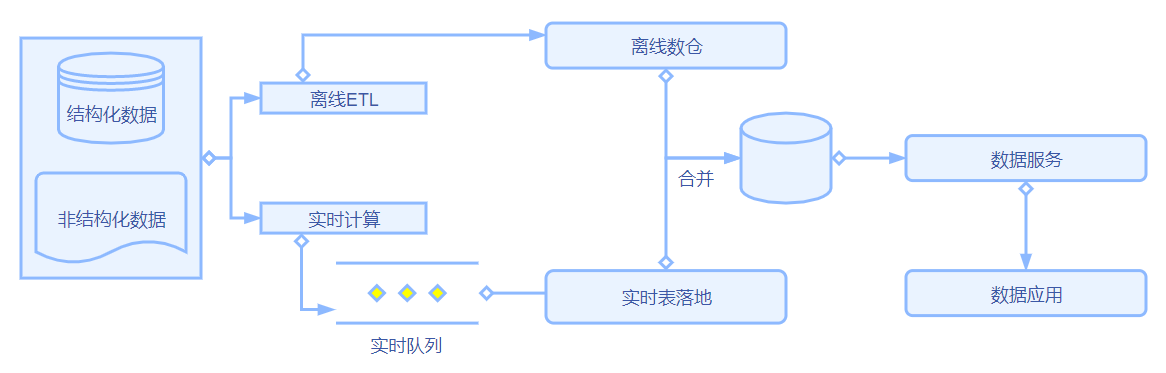
简单理解为离线数据ETL+实时数据ETL分线路执行,最后查询的时候在作汇总。这种方式减轻了数仓的压力,预先批处理好T+1的数据,而T+0当日实时数据在查询时,再并入离线一起输出。但这需要实时和离线两套一模一样的表结构,也会有两套一模一样逻辑的ETL脚本,维护起来算是比较麻烦。讲这么复杂还是没有一步到位,直接实时计算,少数有能力的公司直接把两套代码全部变成实时加工,就又多出了一种架构:Kappa架构。
Kappa架构
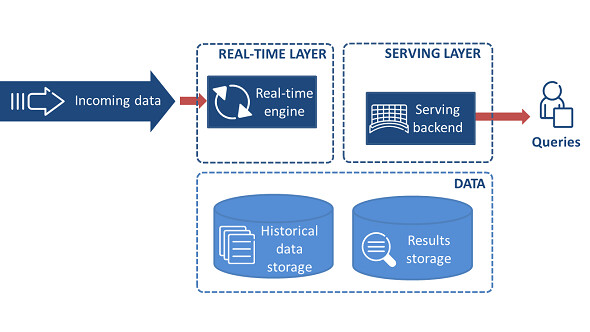
动用资本的力量后,架构变成了所有数据统一走实时。在数据需要重新处理或发生数据变更时,可通过历史数据重新处理来完成。Kappa架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
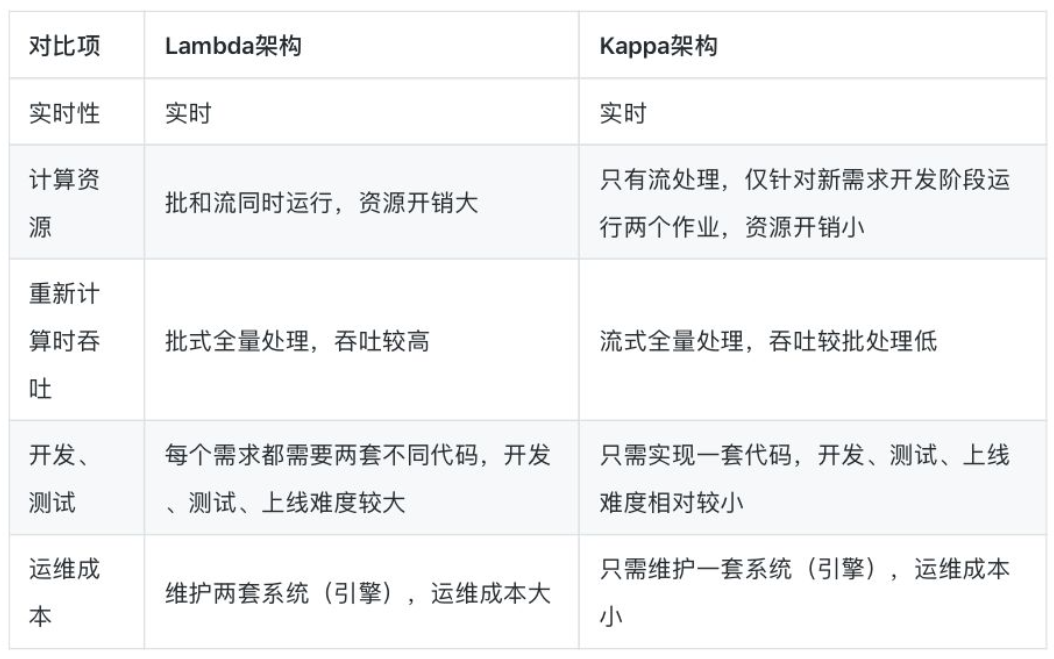
Lambda和Kappa比较
未来的架构
企业对数据的实时加工能力是从来都不减的,未来大厂还是会有自己的一套IDC机房,但是中小型企业会更加偏向于使用云平台(如亚马逊的AWS、阿里云、腾讯云等),把数据加工方案托管出去,数据与计算分离,最后达到湖仓一体化、流批一体化。
技术栈一览
这里列出的技术栈包含了数仓和数仓周边的工具,基本是开源方案,但不是唯一的。
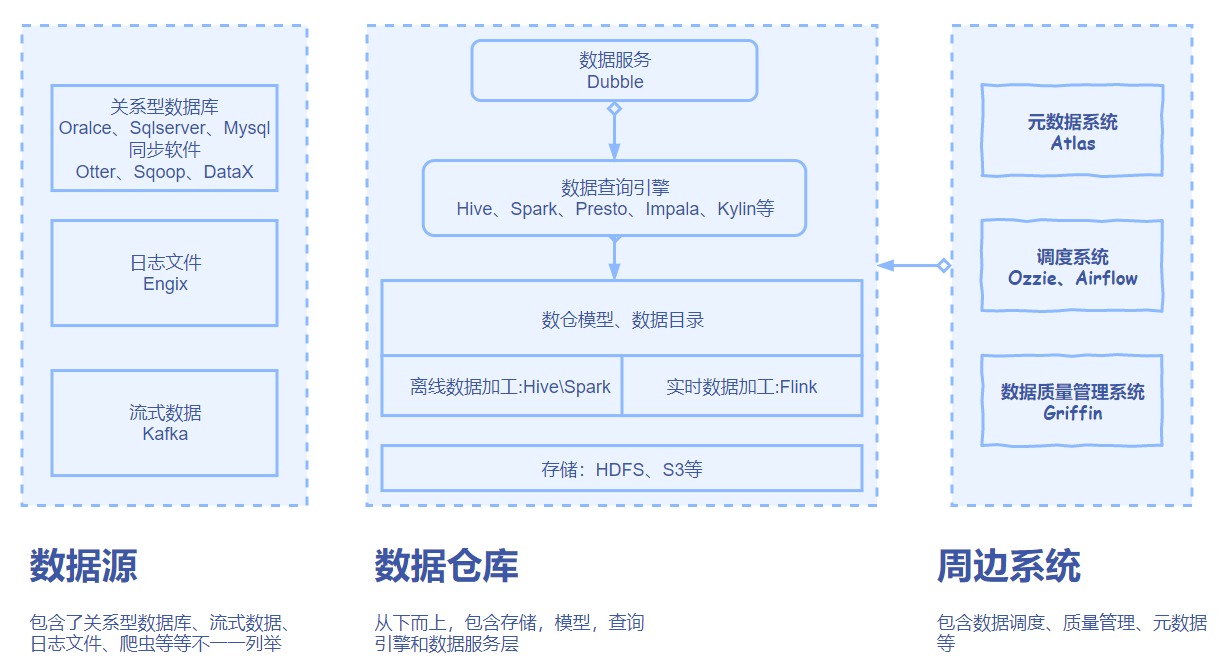
总结
从关系型到大数据平台,从表到数据文件查询,再从离线到实时,无论怎么变,数据仓库最大的价值还是在于数据的输出能力。评价一个数仓是否成功,要取决于用数的人是否方便取数,指标口径是否统一,数据是否稳定,为企业和业务团队创造了多少价值,而不是单纯去讨论技术的前沿性,因为技术还是要为数据服务的。以后的发展趋势很明确,流批一体和湖仓一体必然是潮流,而新技术的加入又增添了数据仓库和数据湖的隐藏风险,如何保持数据高效、准确、稳定地输出依然是数仓建设的基本原则。
当下在很多互联网公司中,“数据仓库”、“ETL”、“数据质量”、“调度”等这些名词似乎都被烙上了“传统数仓”的烙印,对这些名词呼之欲出的人也被称为"传统数仓人",貌似只有“Hadoop”、“Hive”、“离线处理”、"Flink实时流处理"这些标签才表示是大数据圈子里的人,才更高大上。
殊不知,大数据环境下“Hadoop”、“Hive”等这些组件,代表的只是数据源类型更多样、技术工具等上面的升级,这属于“术”(工具和技术)的层面,而数据仓库更重要的是“道”,是集数据接入、存储计算、模型、ETL、调度、数据管理和使用方式一整套的体系和实施方法。
在大数据时代,数据为王,数据即生产力。诚然,Hadoop的兴起无疑为大数据的应用奠定了强大的技术保障。但当热潮后冷静下来,我们更应该考虑的是如何管理好和使用好我们的数据资产。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号