

Attention 2015-今
现在attention的热度已经过去了,基本上所有的attention都是transformer的kqv形式的,甚至只要说道attention,默认就是transformer的attention。
为避免遗忘历史,我这里做一个小总结。繁杂的att我就不去了解了,只了解下经典的。
以下以
鼻祖Bahdanau Attention
2015,Bengio组。文章https://arxiv.org/pdf/1409.0473.pdf。
att的获得
att的使用
即加权平均:
其中
func的形式
也就是att系数的获得方式。
形式1
其中
可参考实现:https://github.com/mhauskn/pytorch_attention/blob/main/model.py
形式2
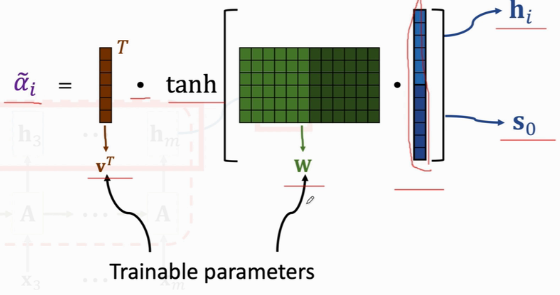
然后对各个
出自视频:https://www.bilibili.com/video/BV1YA411G7Ep
可参考实现:https://github.com/lukysummer/Bahdanau-Attention-in-Pytorch/blob/master/Attention.py
形式3
然后softmax。
其中
注:此Transformer模式本质上与此方式一致。
不同的是,Transformer直接把


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)