
2.安装Spark与Python
一、安装Spark
1.检查基础环境
启动hdfs查看进程
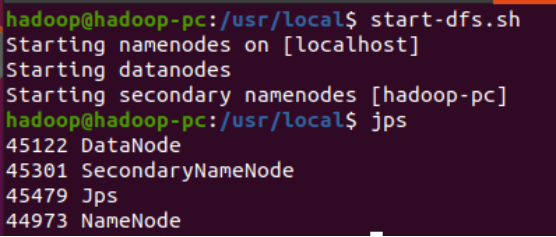
查看hadoop和jdk环境

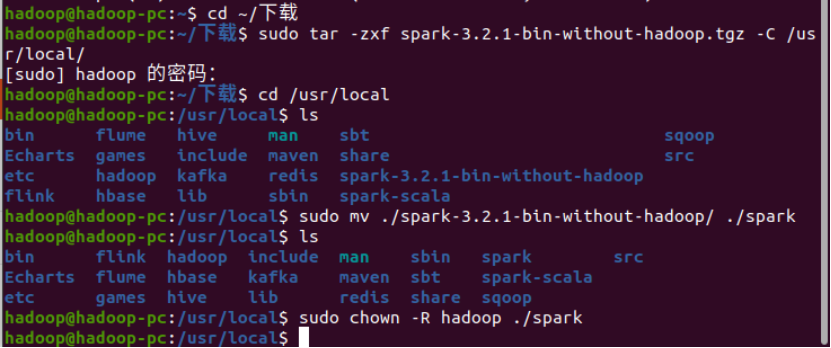
2.下载spark
3.配置环境变量

4.启动spark
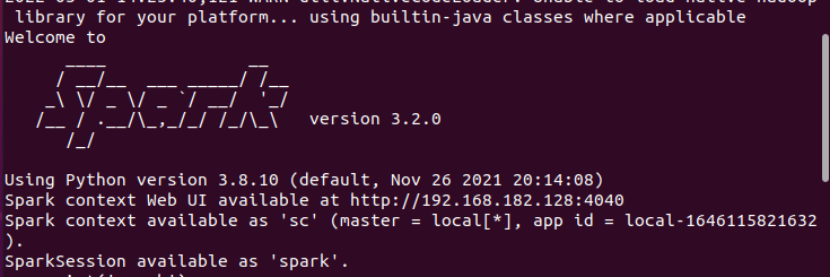
5.试运行python代码


二、Python编程练习:英文文本的词频统计
1.准备文本文件
从网上下载一篇名为《hamlet》的小说,命名为hamlet.txt
2.读文件
txt = open("../../resources/hamlet.txt", "r").read()
读取hamlet.txt英文小说文件并赋值给txt
3.预处理:大小写,标点符号,停用词
txt = txt.lower() #使所有的英文字符变成小写
# 循环把txt中的特殊字符全替换成 空格 for ch in ' !"#$%&()*+-,./:;<=>?@[\\]^_‘{|}~ ': txt = txt.replace(ch, " ")
excludes = {"to", "of", "i", "a"}
for word in excludes: #停用词循环删除
del counts[word]
4.分词
words = hamletTxt.split() # 将字符串中的信息进行分隔,并以列表的形式返回给变量
5.统计每个单词出现的次数
for word in words: # counts.get函数:用来获取某一个键对应的值,即当前给出的键作为索引字,如果在里边,返回 # 它的次数后面再+1,说明这个单词又出现了一次;如果单词不在字典中,则把它加到字典中,并且 # 赋给当前的值为0 counts[word] = counts.get(word, 0) + 1
6.按词频大小排序
# 按照键值对的2个元素的第二个元素进行排序,排序的方式是(reverse=true)由大到小 倒排 items.sort(key=lambda x: x[1], reverse=True)
7.结果写文件
items = str(counts.items()) # 装换成字符串类型 with open("hamlet_wordCount.txt", 'w', encoding='utf-8')as fp: fp.write(items)
8.运行结果
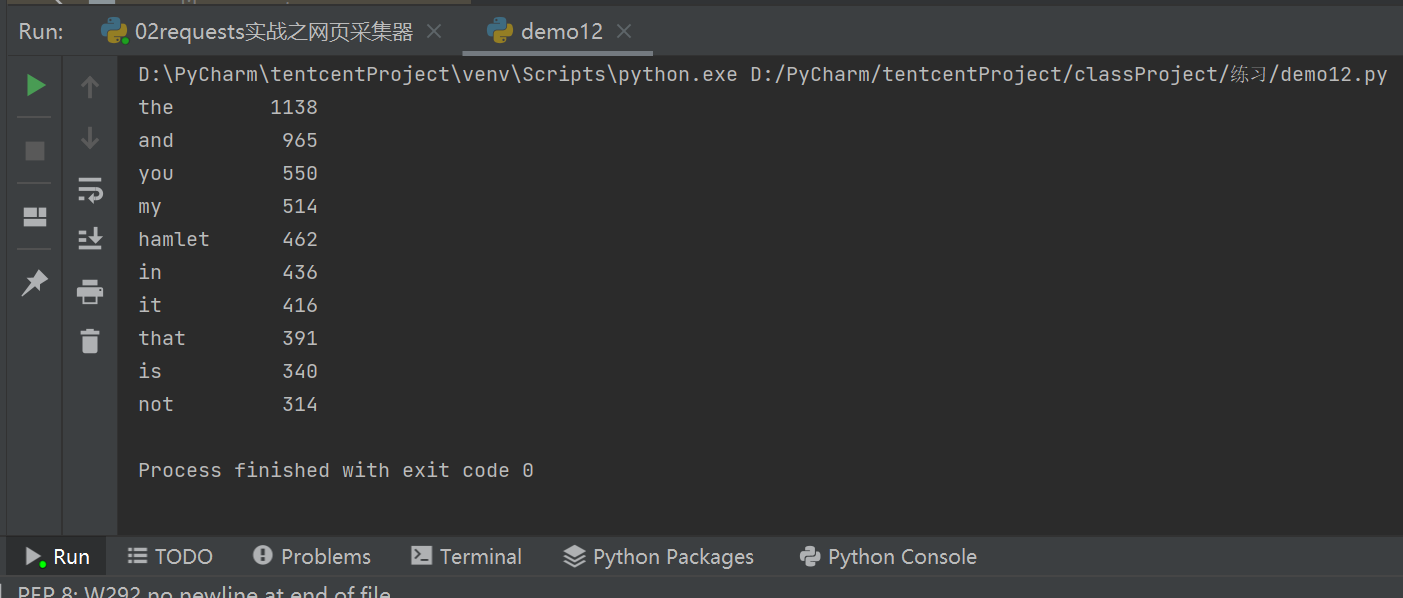

9.全部代码展示
# 组合数据类型,文本词频统计 Hamlet def getText(): txt = open("../../resources/hamlet.txt", "r").read() txt = txt.lower() # 使所有的英文字符变成小写 # 循环把txt中的特殊字符全替换成 空格 for ch in ' !"#$%&()*+-,./:;<=>?@[\\]^_‘{|}~ ': txt = txt.replace(ch, " ") return txt excludes = {"to", "of", "i", "a"} hamletTxt = getText() words = hamletTxt.split() # 将字符串中的信息进行分隔,并以列表的形式 返回给变量 counts = {} for word in words: # counts.get函数:用来获取某一个键对应的值,即当前给出的键作为索引字,如果在里边,返回 # 它的次数后面再+1,说明这个单词又出现了一次;如果单词不在字典中,则把它加到字典中,并且 # 赋给当前的值为0 counts[word] = counts.get(word, 0) + 1 for word in excludes: # 停用词删除 del counts[word] items = list(counts.items()) # 按照键值对的2个元素的第二个元素进行排序,排序的方式是(reverse=true)由大到小 倒排 items.sort(key=lambda x: x[1], reverse=True) # 打印前十个出现最多的单词 以及 它对应的次数 for i in range(10): word, count = items[i] count = str(count) print("{0:<10}{1:>5}".format(word, count)) items = str(counts.items()) # 装换成字符串类型,结果保存文件 with open("hamlet_wordCount.txt", 'w', encoding='utf-8')as fp: fp.write(items)
